CamoNet
We used a GAN approach to generate optimal camouflage patterns for individual scenes.
Motivation
Generative artificial intelligence has exploded over the past few years. Camouflage patterns are designed and evaluated manually. We want to apply modern approaches to create an optimal camouflage for unique environments.
A background on GAN camouflage generation:
Generative Adversarial Networks (Goodfellow et al. 2014)
Generative Adversarial Networks (GANs) are a strong method for adversarial image generation.
Adversarial networks leverage two models, a generative model, and an adversary, which tries to identify whether the generation is a real image from the sample data or a “counterfeit” generation.
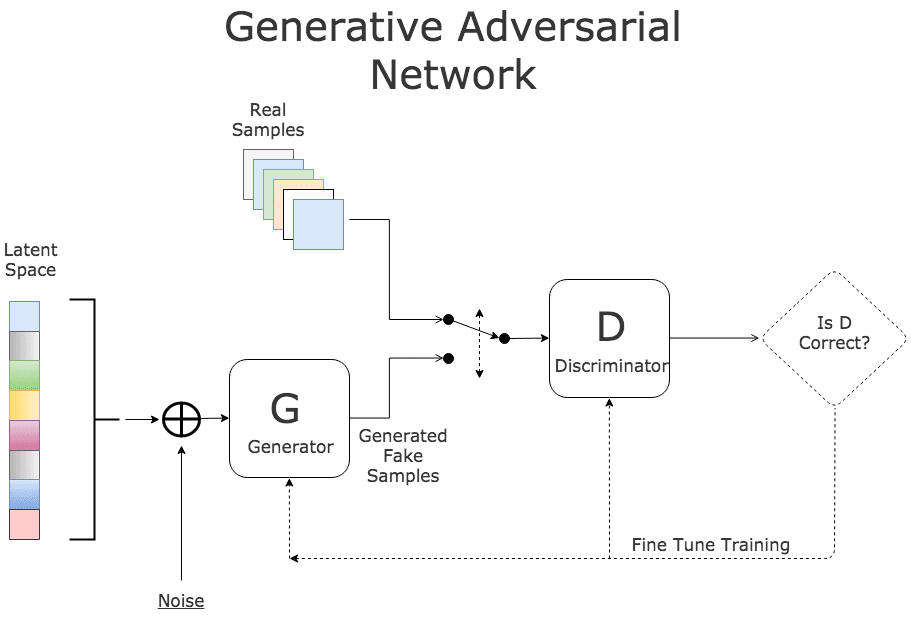
In the case of GANs, a generator model G forms images based on the sample data, and a discriminator model D assigns a probability of an image coming from the sample data instead of G. This is defined as a minimax game with the function:
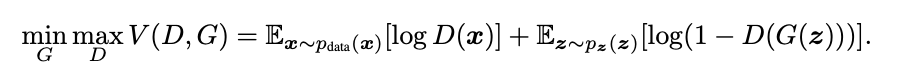
D is trained to maximize the probability of assigning the correct label to batches containing both sample data and generated samples from G, $log D(x)$. G is concurrently trained to minimize $log(1 - D(G(z)))$.
CamoGAN: Evolving optimum camouflage with Generative Adversarial Networks (Talas et al. 2019)
In the context of camouflage generation, the GAN has been utilized to create biologically-relevant patterns from natural images. Researchers created CamoGAN, a GAN that generates a camouflage mask for a triangle target, and uses a discriminator to evaluate whether a background contains the camouflaged target or not.
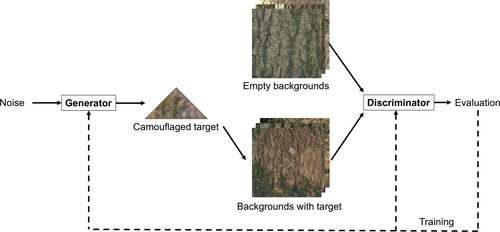
In this network, the generator used fully connected layers, batch normalization, and convolution transpose layers to compose a two-dimensional image. The discriminator was a simple convolutional neural network (CNN), which allowed the network to learn feature maps to identify whether the triangle was in the image. Using binary cross entropy as the loss function, ten networks were trained, and target patterns were extracted over time steps of 500, 2500, 5000, 7500, and 10000.
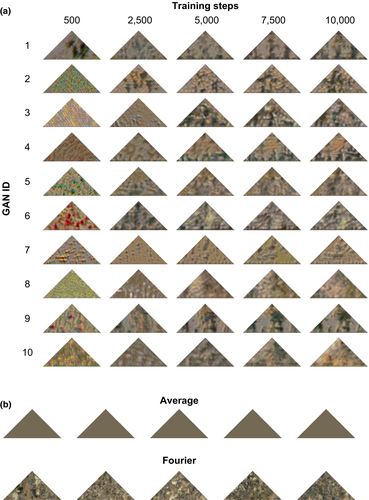
These GAN generated patterns were validated against two control methods, “Average” and “Fourier”. The “Average” targets took the average pixel color of the initial images, while the “Fourier” targets were generated using two-dimensional Fourier transformations using energy and phase decomposition.
To validate the quality of camouflage created by CamoGAN, participants were asked to click on the masked triangle in background images, and times were recorded for each type of generation. Targets produced by GANs after longer training steps were the hardest to find, and therefore this method of camouflage generation showed promising results.
GANmouflage: 3D Object Nondetection with Texture Fields (Guo et al. 2023)
One of the more recent works on camouflage is the GANmouflage paper, which extends the problem of object non-detection to objects in a 3D world space. This novel approach leverages adversarial learning and neural texture fields to create object-specific camouflage that adapts to varying viewpoints.
Instead of a 2D object in an image, a 3D object mesh is placed in a set of background images with corresponding camera angles. This provides the geometric and visual context for camouflage generation. The model extracts multi-resolution image features using a U-Net with a ResNet-18 backbone, creating a tensor representation that aligns image textures with 3D object surfaces.
The texture field is parameterized by a multi-layer perceptron (MLP) that maps a 3D query point to an RGB color.
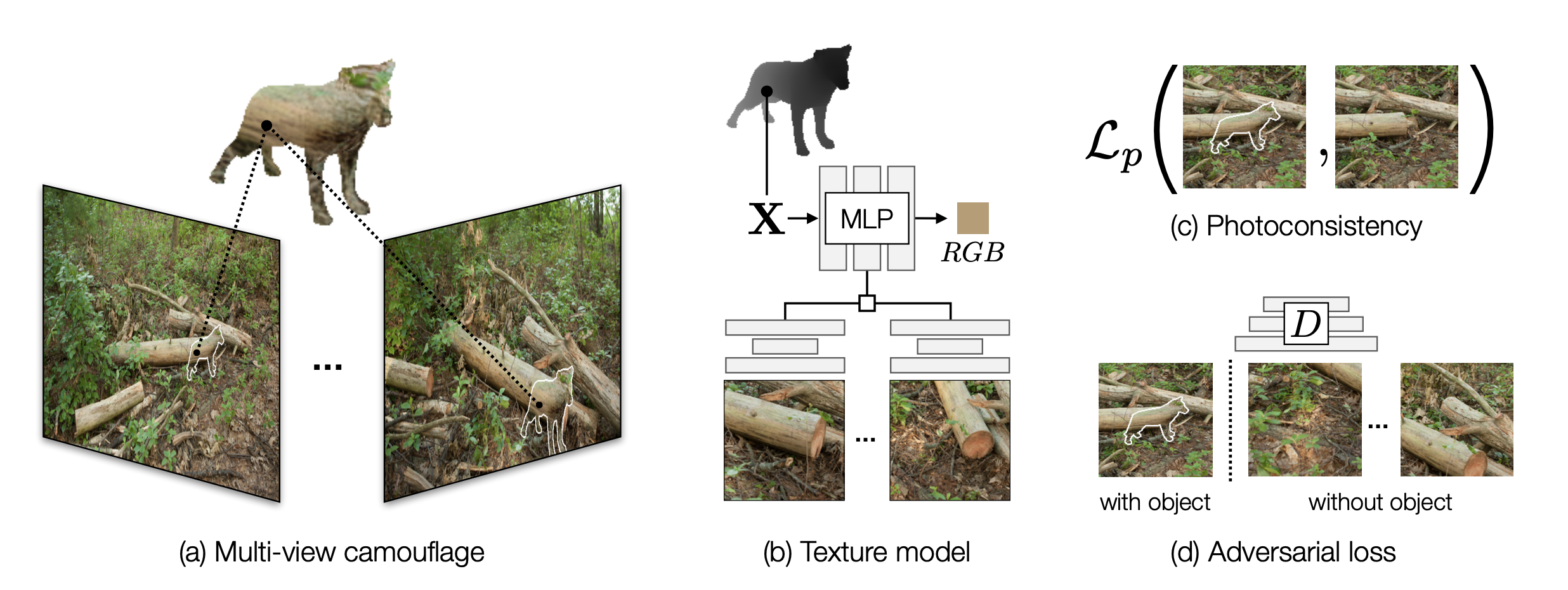
There are two loss functions used in this framework, photo-consistency loss and adversarial loss. Photo-consistency loss captures how aligned the generated texture is with the background image. A perceptual loss, $L_{photo}$ is computed based on the distance between activations of layers of a ImageNet pre-trained VGG-16 network:
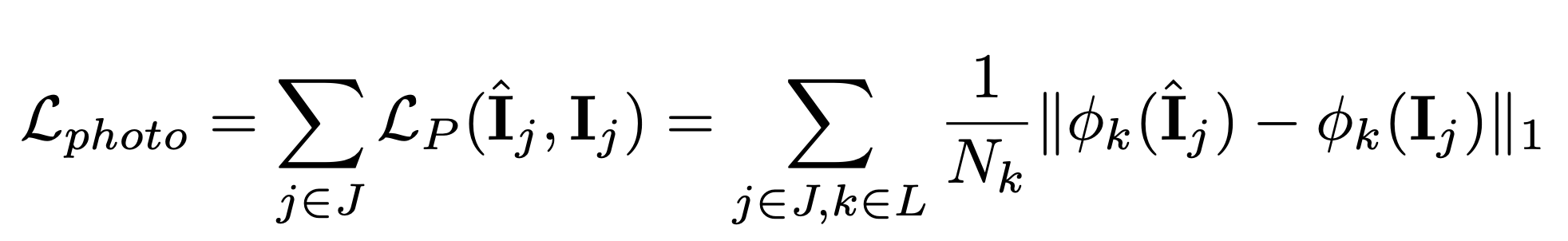
Adversarial loss further improves the non-detection of the 3D object. This is the classic GAN implementation, using a fully convolutional neural network as a discriminator, and the trained texturing function as a generator.
The discriminator minimizes $L_D$:
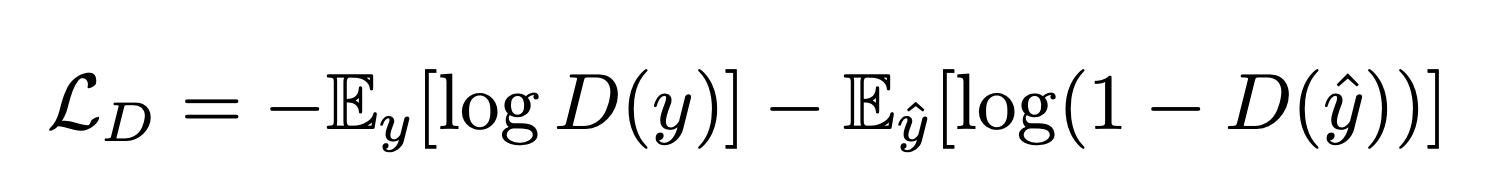
While the texturing function minimizes $L_{adv}$:
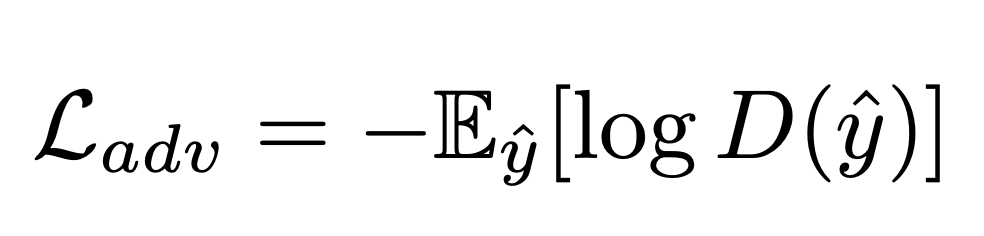
The model as a whole minimizes the combined losses, where $λ_{adv}$ controls the importance of the two losses:
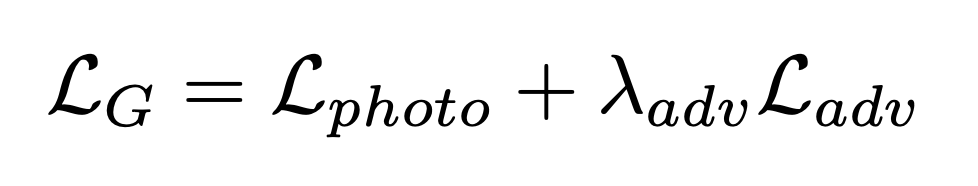
Custom Optimization Task
Our approach aims to learn from the research discussed above, by applying a GAN framework to generate a camouflage mask for 2D scenes. Unlike previous approaches, our method seeks to achieve camouflage patterns that are placement invariant and generalizable to a scene composing of various textures.
We designed our two-player zero-sum game around this goal. The Discriminator is a binary image classifier that takes in crops of scene images as input and is tasked with determining whether the crops include a foreign camouflaged object or not. The Generator is tasked with generating fixed-size camouflage patterns. Each generation is conditioned on a scene image which the Generator take in as input.
Architecture
Our architecture utilizes concepts and models of Vision Transformers (ViT) and the DCGAN architecture. An overview of both is seen below.
Vision Transformer (ViT):
The Vision Transformer (ViT), introduced by Google’s research team in the paper “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale,” has quickly become a foundational architecture for a wide array of computer vision tasks. ViT adapts the Transformer—originally designed for natural language processing—to images, leveraging the self-attention mechanism that has revolutionized NLP to handle visual inputs.
In contrast to convolution-based models, ViT avoids the need for custom-designed layers to capture spatial relationships. Instead, an image is divided into a sequence of fixed-size patches, each treated as a “token” analogous to a word in NLP. These patches are then linearly projected into a high-dimensional embedding space. Because the Transformer itself is agnostic to sequence order, ViT incorporates explicit positional embeddings to maintain spatial awareness, enabling the model to understand how patches relate to each other within the original image grid.
The resulting sequence of patch embeddings, augmented by their positional information, is passed through a standard Transformer encoder composed of multi-head self-attention and feed-forward layers. Through this process, ViT learns a set of global relationships without relying on handcrafted convolutional operations. The architecture is shown in the figure below.
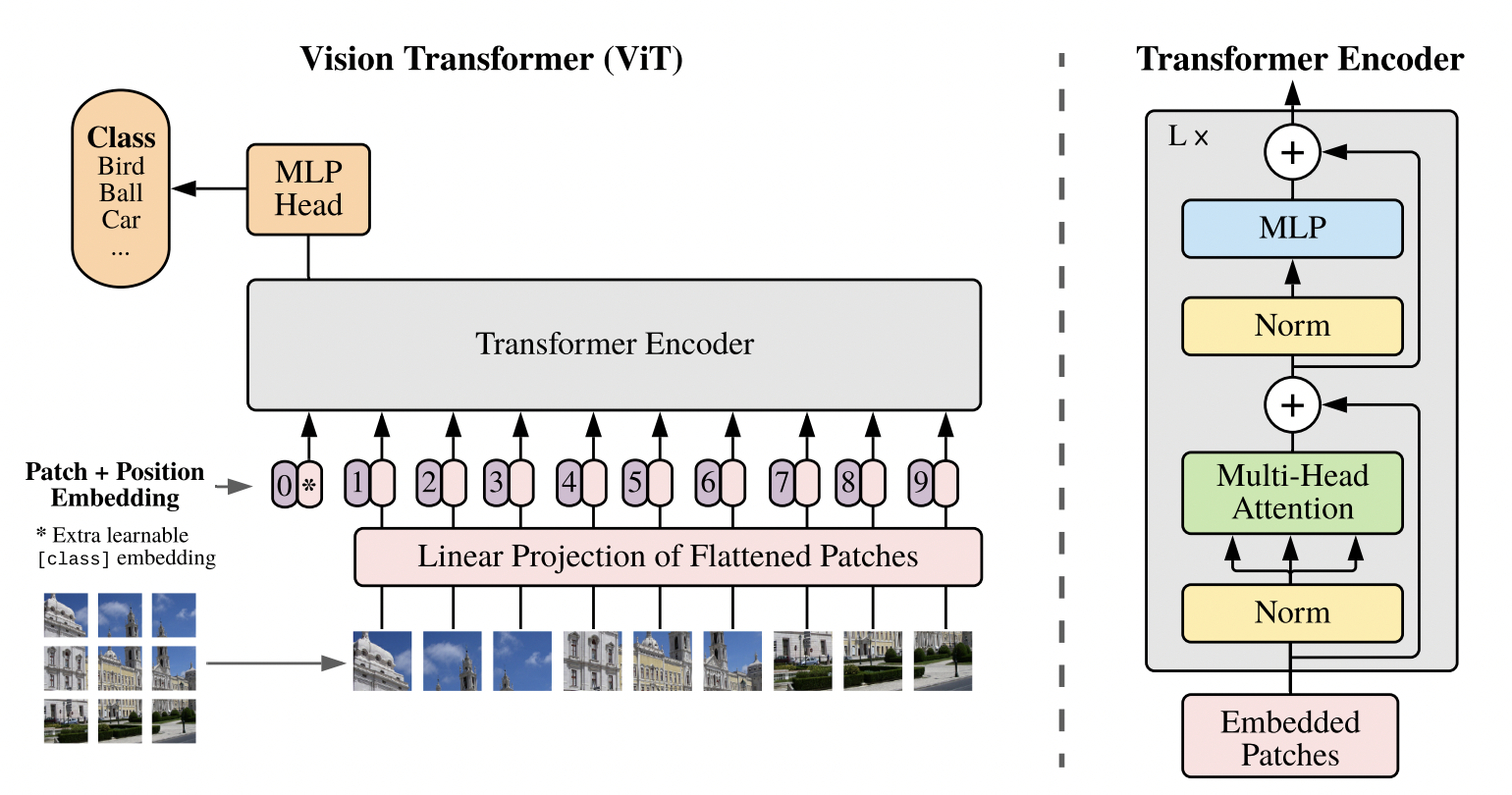
By scaling to large datasets and leveraging massive pretraining, ViT has demonstrated state-of-the-art performance in image classification and shown promise in domains such as object detection, segmentation, and beyond, surpassing previously foundational models.
Deep Convolutional Generative Adversarial Networks (DCGAN)
Deep Convolutional Generative Adversarial Networks (DCGANs), introduced by Radford, Metz, and Chintala in their paper “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks,” have significantly influenced the landscape of image synthesis and generative modeling. By combining the framework of Generative Adversarial Networks (GANs)—in which a generator and discriminator are jointly trained to produce and distinguish synthetic images—with the power of deep convolutional neural architectures, DCGANs established a more stable and reliable approach to generating high-quality, diverse images.
Key to this advancement was the replacement of fully connected layers and pooling operations with carefully designed convolutional and strided convolutional (transposed convolutional) layers, as seen below.
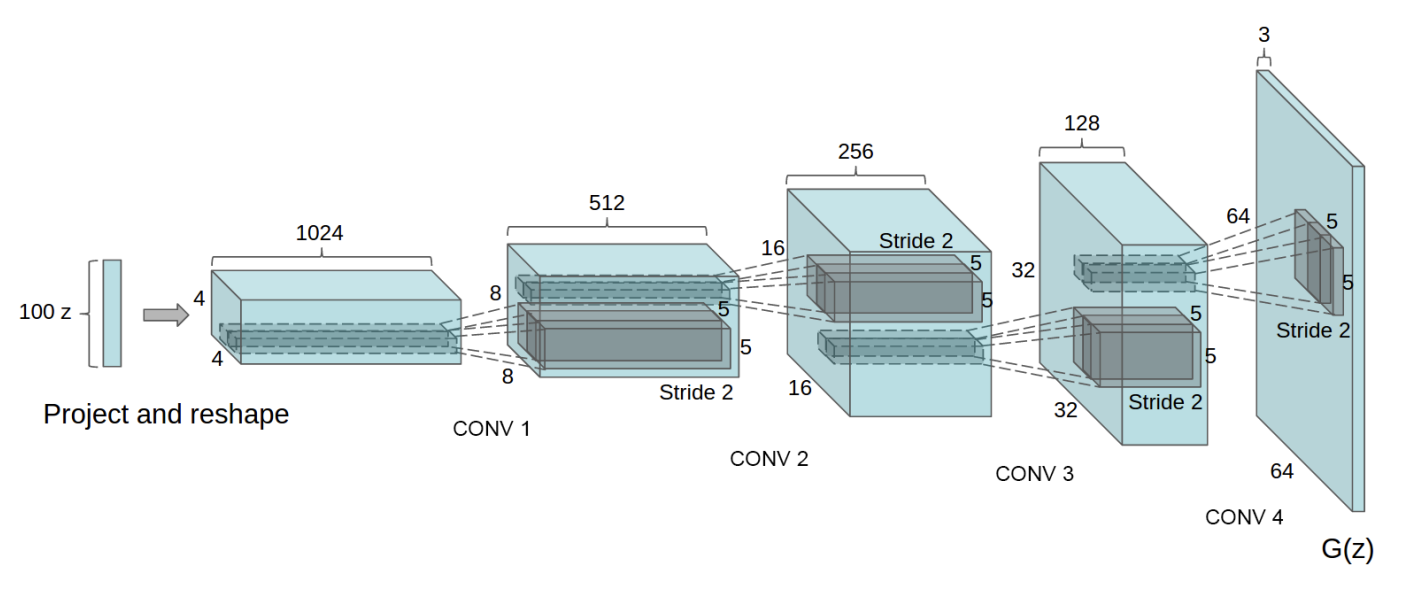
Formally, each transposed convolutional layer is represented:
\[h_{l+1}=BN(ReLU(W_{l+1}^T∗h_l))\]where \(h_l\) is the set of feature maps at layer \(l\) , \(W_{l+1}\) represents the trainable convolutional filters, ( * ) denotes convolution, and BN refers to batch normalization.
The discriminator \(D(x; \theta_d)\) takes an image \(x\) (either generated or real) and outputs a probability \(D(x)\) of the image being real. However, it diverges from the standard GAN implementation by utilizing convolutions with stride to down-sample the input. Additionally, it incorporates batch normalization and LeakyReLU to improve stability and gradient flow.
The objective function used is a standard GAN minimax objective:
\[min_Gmax_DV(D,G)=E_{x∼pdata(x)}[logD(x)]+E_{z∼pz(z)}[log(1−D(G(z)))]\]This architectural refinement made the training process more stable and the resulting images more coherent, allowing the DCGAN generator to capture rich hierarchical representations of visual concepts.
Generator
The generator in our architecture begins by utilizing a pretrained Vision Transformer (ViT) model. Instead of starting from random noise, it feeds an input image into the ViT to obtain a high-level, semantically rich feature vector. To achieve this, the ViT’s classification head is replaced with a custom linear layer that outputs a latent vector. Because the ViT is pretrained on large-scale data, it provides a strong, informative representation that encodes global context and abstract concepts from the input image. An input image is provided over random noise to give our model a more robust starting position when competing against the discriminator.
After extracting this latent vector, the generator switches to a DCGAN-inspired approach. The latent vector is reshaped into a small spatial feature map and passed through a series of ConvTranspose2d, BatchNorm2d, and ReLU layers. Each step doubles the spatial resolution and halves the feature depth until the network reaches the final output image size. This progressive upsampling and feature refinement process, originally popularized by DCGAN, is well-known for producing coherent images from latent vectors. The final layer uses a Tanh activation to scale pixel values appropriately, resulting in a synthesized image that attempts to appear realistic.
In short, the generator is a hybrid: it leverages ViT for semantic, globally informed features and DCGAN principles for the final image synthesis and upsampling stages.
Discriminator
Our discriminator follows a traditional DCGAN-style discriminator design. It is composed of a series of convolutional layers, each with stride-2 to downsample the incoming image. These layers are interleaved with BatchNorm and LeakyReLU activations to stabilize training and ensure smooth gradient flow. As the input image is progressively reduced in spatial dimension, the discriminator learns increasingly complex and abstract features that help it distinguish real images from those generated by the hybrid generator.
By maintaining a standard, fully convolutional DCGAN-inspired design, the discriminator remains a stable and reliable component of the adversarial training loop. Its simplicity ensures that it can effectively challenge the complex, ViT-enhanced generator without introducing additional uncertainties or training complexities.
Data
Environment Images
We selected our data with the intent of intuitively simplifying the optimization task without making it trivial. To achieve this, we decided to limit our collection of scene images to a singular category. Inspired by the vibrant natural habitats of Amazonian animals, we chose natural rainforest images from Professor Bolei Zhou’s Places205 Dataset. One observed issue was that many of the scenes included textures that were incongruous with the rest of the environment and unrelated to the rainforest. These textures were introduced by objects such as bridges, cars, and, most notably, the sky. To mitigate sky pollution in our scenes and limit the diversity of textures within a single image, we preprocessed the data to remove the top half of each image.
Camouflage Shapes
For the camouflages shapes, we decided to use vectors of cats in a variety of poses. This choice was made to fulfill the need for asymmetrical natural shapes and also for fun.
Composition of Real Images and Fake Images
To generate real and fake images, we performed the following process using both a camouflage pattern and a background image:
- Take a random 128x128 pixel crop of the background image.
- Apply random flips to the crop.
- At this point, you have a completed real image.
- Randomly select a cat pose from the predefined collection of cat poses.
- Apply random resizing and flipping to the cat pose.
- Use the cat pose to mask the tiled camouflage pattern, producing a camouflaged cat.
- Overlay the camouflaged cat onto the crop in a random position to create a complete fake image.
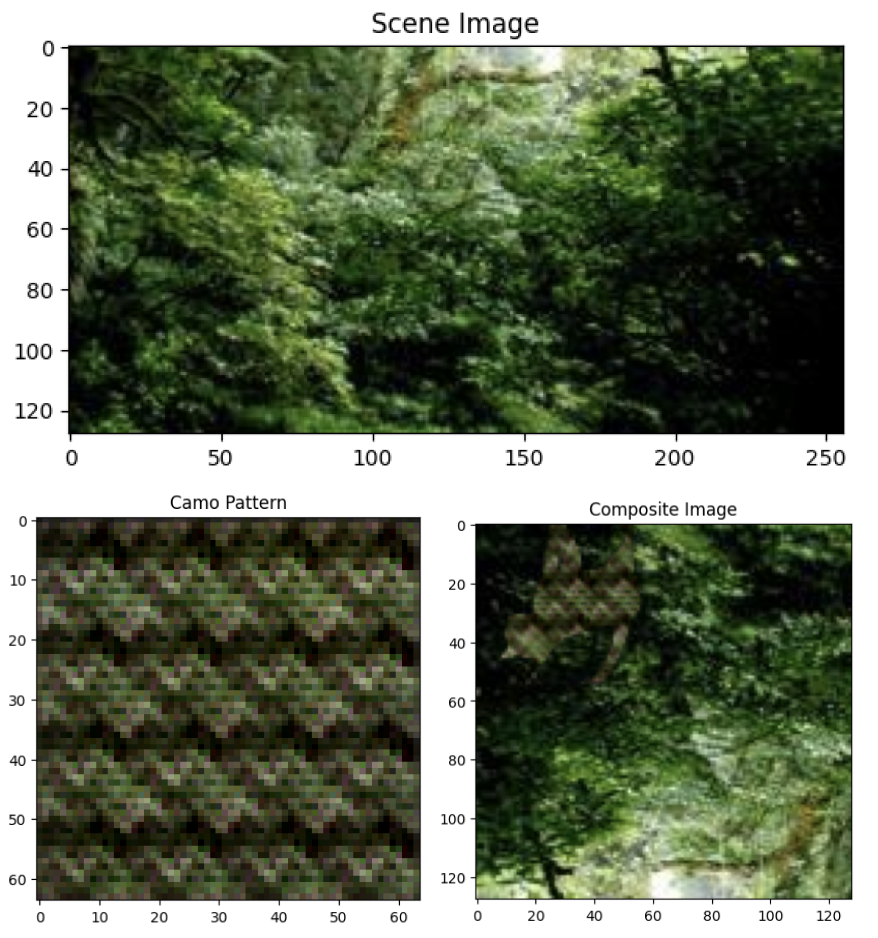
Results
Below is a sample of scene images and their respective generated camouflage patterns. Each of the scenes includes a camouflaged cat ‘hidden’ in the scene.
The following observations can be made:
- Many of the patterns effectively help conceal the cat.
- The performance of the Generator is inconsistent.
- Some patterns are very effective and some patterns are very ineffective.
- The Generator has recurring ‘template’ patterns. These templates have adjusted colors for different scenes.

References
[1] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”; arXiv:2010.11929 [cs.CV]
[2] A. Radford, L. Metz, and S. Chintala, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”; arXiv:1511.06434 [cs.LG]
[3] B. Zhou, A. Lapedriza, J. Xiao, A. Torralba, and A. Oliva. “Learning Deep Features for Scene Recognition using Places Database.” Advances in Neural Information Processing Systems 27 (NIPS), 2014.
[4] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative Adversarial Nets”; arXiv:1406.2661 [cs.LG]
[5] R. Guo, J. Collins, O. Lima, A. Owens, “GANmouflage: 3D Object Nondetection with Texture Fields”; arXiv:2201.07202 [cs.CV]
[6] Talas, Laszlo & Fennell, John & Kjernsmo, Karin & Cuthill, Innes & Scott-Samuel, Nick & Baddeley, Roland. (2019). CamoGAN: Evolving optimum camouflage with Generative Adversarial Networks. Methods in Ecology and Evolution. 11. https://doi.org/10.1111/2041-210X.13334.