Exporing Object Detection
Object tracking is a core computer vision tasks that aims to identify and track objects across a sequence of frames. Its applications span anywhere from surveillance to autonomous driving to medical imaging. In this blog like post, we explore object tracking advancements across different frameworks and promising architectures.
- Introduction
- Paper 1: Siam R-CNN
- Paper 2: MITS: A Framework for Unified Visual Tracking and Segmentation
- Paper 3: SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory
- Paper 4: Tracking Meets LoRA
- Conclusions
- References
Introduction
Object tracking is a foundational task in computer vision with applications ranging from surveillance and autonomous driving to augmented reality and medical imaging. It involves continuously identifying and localizing a specific object across a sequence of video frames. These applications often demand real-time processing, adaptability to diverse conditions, and resilience to variability in object appearances and behaviors. The availability of large-scale datasets incorporating multimodal sensors has significantly enhanced the scope of object tracking research. These datasets often integrate RGB, thermal, depth, and LiDAR modalities, allowing for more comprehensive modeling and analysis of dynamic environments. For example, datasets such as MOTChallenge(focusing on multi-object tracking in real-world scenes), KITTI (providing RGB and LiDAR data for autonomous driving applications), and FLIR ADAS (thermal and visible spectrum data for advanced driver-assistance systems) have been pivotal. Similarly, datasets like VisDrone and UAVDT focus on object tracking in drone-captured videos, introducing challenges unique to aerial perspectives. This growing repository of multimodal datasets facilitates the development of tracking algorithms that can adapt to varying conditions, ranging from low-light environments to complex, multi-object scenarios. These datasets provide diverse benchmarks to evaluate performance and push the boundaries of object tracking methodologies.
Challenges: What makes object tracking particularly hard?
Object tracking becomes particularly challenging when we move from a constrained setup where there are known, predetermined parameters to a fully autonomous framework where there are several, unseen unknowns. In essence, the challenges occur when scaling object tracking from a narrow, simple task to more holistic, complex tasks set in real-world, dynamic environments. This scaling requires the consideration of an unknown number of objects in any given frame, unknown movement patterns, and unknown regions of interests
Example: Simple airplane tracking versus pedestrian and traffic tracking.

Jet Bounding-Box Detection |
Motion Tracking |
In the case on the left, we can use several knowns to make our object tracking task easier. We know that there will only be one object (a plane) to track. Additionally, the contrast between the foreground (the plane) and background (the sky) will be obvious. Lastly, the trajectory of an airplane is predictable and linear for the most part. Contrast this to the task on the right. There are many more moving parts, with objects coming in and out of the frame. Additionally, this task is characterized by movement as both the foreground and the background are moving. Lastly, objects themselves are changing directions and speed. Differences in these two tasks highlight the challenges that come with scaling simple object tracking to more complex scenarios.
Additionally, the challenges of object tracking can be categorized into two components – object detection and motion tracking. These challenges are not independent of each other so challenges in object detection can exacerbate challenges in motion tracking and vice versa.
Challenges associated with Object Detection:
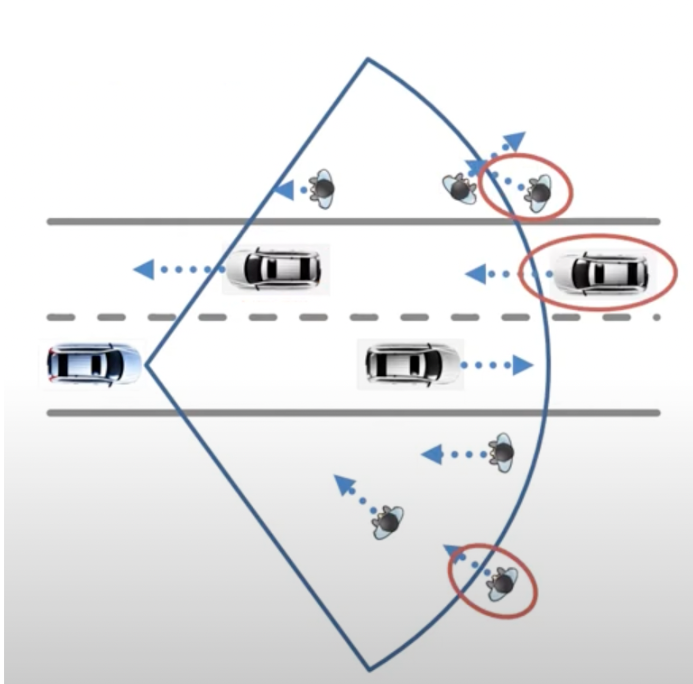
Occlusions: Occlusions occur when an object is partially or fully hidden behind another object or artifact of the environment. In these cases, the object tracking algorithm can struggle to maintain a consistent track.
Object Birth, Death, Permanence: In dynamic scenarios, objects can appear and disappear unpredictably from the model’s field of view. These are regarded as objects of birth and death respectively. These instances require the model to adequately initialize or terminate a track. Additionally, in relation to occlusions, if an object is hidden but still technically in the region of interest, the model must understand that this object still exists and not prematurely terminate its track.
Environmental Conditions and Artifacts: In addition, variations in the environment like lighting, weather, and sensor noise can change the appearance of an object. This variation can make detection unreliable as the model is unfamiliar with the diversity of settings it is placed in. Additionally, artifacts of sensor errors can block objects in the field of view making detection and tracking inhibited. In the example below, we can see how lighting glare can obstruct the field of view.

Challenges associated with with Motion Tracking:
Unpredictable, Non-Uniform Movement: Objects don’t always follow simple trajectories. Their motion can be erratic, making prediction models struggle to follow and adequately predict the next scene. Tracking in sports is particularly challenging because of this unpredictable, dynamic movement.
Identity Switch and Fragmentation: When objects cross paths or overlap, tracking systems often misidentify them which can lead to errors in trajectory continuity. When two objects are overlapping, it may prematurely terminate a track or assign a track to the incorrect object.
Paper 1: Siam R-CNN
Siam R-CNN: Visual Tracking by Re-Detection
Paul Voigtlaender1 Jonathon Luiten1,2,† Philip H.S. Torr2 Bastian Leibe1
To understand the Siam R-CNN, we can first start by understanding the two major components of the architecture – the Siamese architecture and the R-CNN architecture.
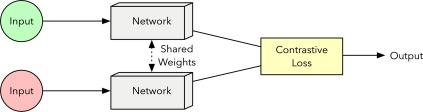
The Siamese architecture is a type of neural network designed to compare two inputs and learn their similarity. It consists of two identical subnetworks that share the same weights and processes the two
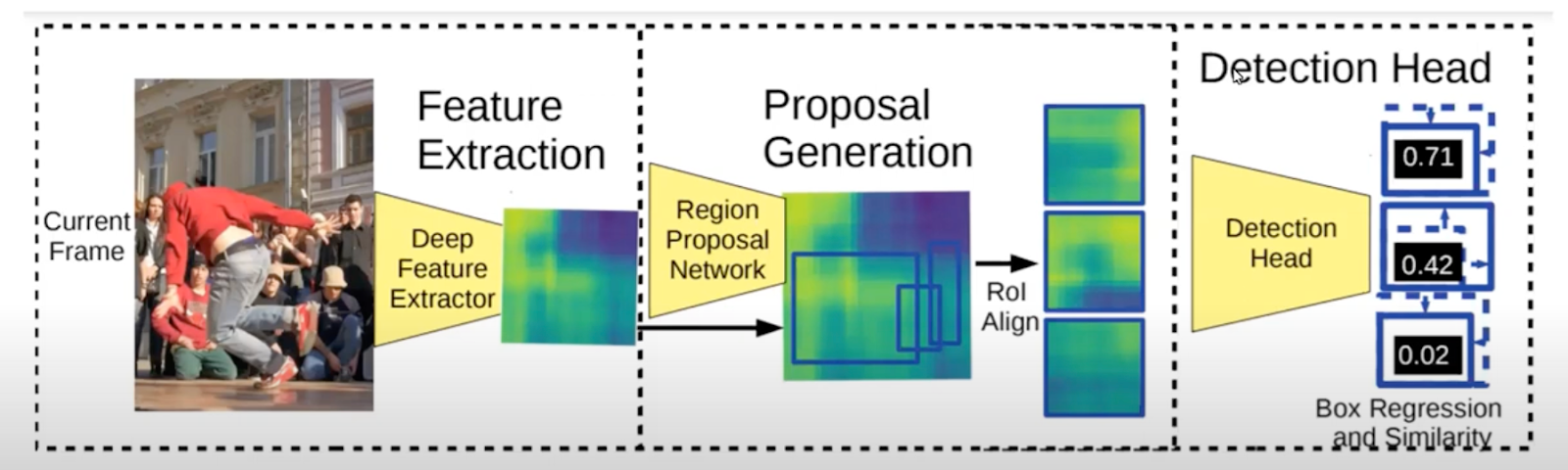
The R-CNN architecture is a Region-based Convolutional Neural Network framework that utilizes the backbone of a CNN to extract deep features. These features are then used by the Regional Proposal Network (RPN) to generate uniformly cropped segments of the feature map that have a high likelihood of containing an object. This region proposal is category agnostic of the object classification task. These cropped feature maps are sent to a detection head and the predicted object classification scores of the bounding boxes are attained.
Architecture and Methodology
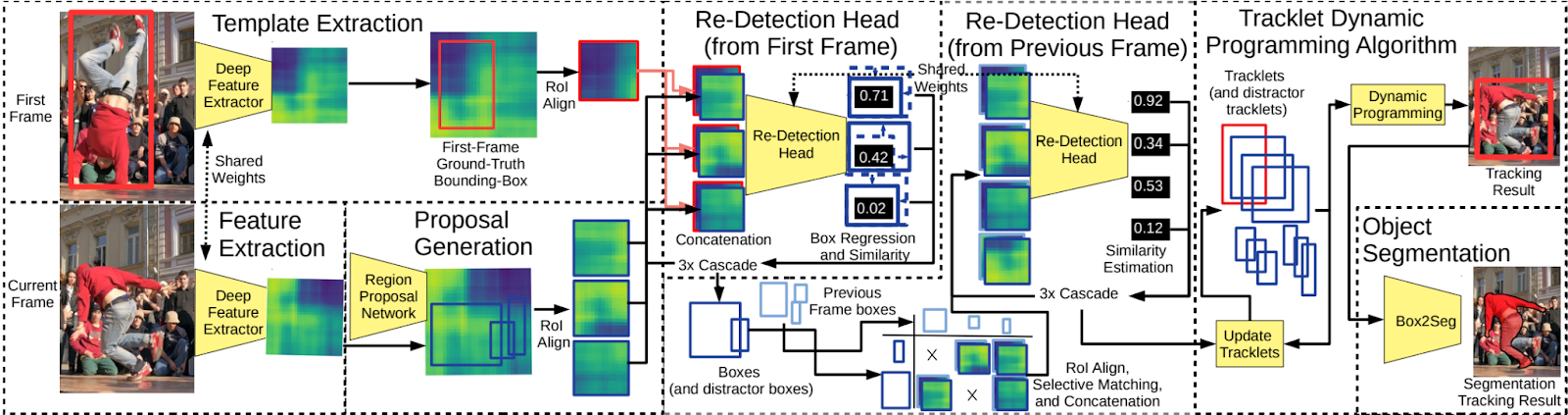
Now with a general understanding of the two major components of Siam R-CNN, Siamese architecture and R-CNN architecture, we can dive more deeply into the Siam R-CNN architecture. This Siam R-CNN architecture is a two-stage detection framework that utilizes a template, candidate alignment, progressive refinement, and re-detection. These refinements enable the model to address many of the object tracking challenges such as long-term tracking, occlusions, appearance changes, and cluttered backgrounds.
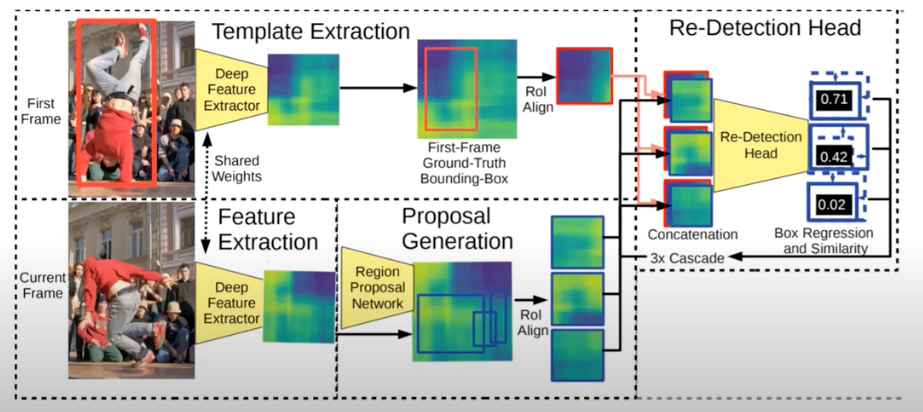
Utilizing the parallelization of the Siamese architecture, the Siam R-CNN architecture has two inputs. The first input is the first frame of the video with a ground-truth bounding box of the object. The second input is the current frame of interest. The two inputs go through the same deep feature extraction process to produce their respective feature maps. The first frame feature map is uniformly cropped to capture the information of the ground-truth bounding box. The current frame feature map is processed by RPN to generate candidate regions of interest. These candidates are concatenated with the first-frame cropped feature map and together, they are inputted into a re-detection head. The re-detection head classifies whether the candidate region of interest contains the same object as the first-frame ground-truth bounding-box. Progressive refinement is achieved through the cascade network that sends these similarity scores back for improved updates on the RPN. This cascade loop occurs 3 times in the Siam R-CNN network. Through this progressive refinement, the Siam R-CNN model can output both regressed, accurate bounding boxes of the tracked object and classification scores on the confidence of whether the candidate region contains the object of interest.
Leveraging this same workflow, the Siam R-CNN architecture not only compares the current frame with the first frame but also the current frame with the previous frame. Similar to the concatenation method for the first and current frame features, the predicted, refined candidate ROIs from the previous frame are concatenated to the current frame’s candidates’ ROIs. The progressive refinement is conducted again using a 3x cascade. The final output is a single, high-confidence bounding box prediction for the target object in the current frame.
Siam R-CNN combines the strengths of Siamese and R-CNN networks, enabling robust, accurate, and long-term object tracking. Its exceptional performance is enabled by template matching, feature concatenation, and progressive refinement through a cascading classifier. While Siam R-CNN improves long-term tracking, it comes with certain trade-offs. The increased computational cost and memory requirements can limit its real-time applicability, and its dependence on pre-trained components may hinder adaptation to novel domains without further fine-tuning. In addition, this network is for single-object tracking and the computational overhead to scale this method to multi-object cases is computationally expensive.
Paper 2: MITS: A Framework for Unified Visual Tracking and Segmentation
Integrating Boxes and Masks: A Multi-Object Framework for Unified Visual Tracking and Segmentation
Yuanyou Xu1,2† , Zongxin Yang1, Yi Yang1‡
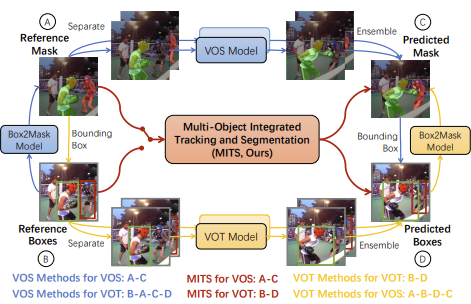
Other existing works have focused on attempting to unify object tracking and segmentation tasks. This endeavor has proven to be difficult across previous works due to the limitations of box or mask initializations, finite compatibility/flexibility for outputs, and most significantly, focusing on single object tracking scenarios. MITS, or Mask-box Integrated framework for unified Tracking and Segmentation, tackles these challenges by creating an end-to-end pipeline for visual object tracking and visual object segmentation. This is achieved through a novel unified identification module and a pinpoint box predictor.
Architecture and Methodology
Before exploring the technicalities, we must acknowledge that MITS can be broken down into a simple formula: encode, propagate, and decode. With this in mind, we can walk through the whole pipeline in three different steps.
Unified Box-Mask Encoding
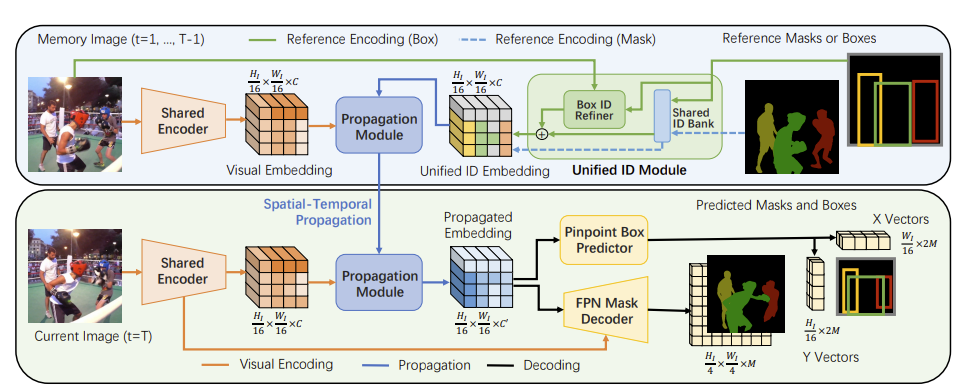
A ResNet-50 backbone encoder takes in a reference/memory frame represented by \(\mathbf{I}_m \in \mathbb{R}^{H_I \times W_I}\) and encodes the frame into a visual embedding represented by \(\mathbf{X}_m \in \mathbb{R}^{HW \times C}\) . The Unified Identification module also encodes all reference masks \(\mathbf{Y}_m \in \mathbb{R}^{HW \times N}\) for the boxes representing $N$ objects into a Unified Identification Embedding, \(\mathbf{E}_{\text{id}} \in \mathbb{R}^{HW \times C}\) .
The Unified Identification module is expanded upon in a later section. The visual embedding is then distributed to the propagation module. It’s worth noting that an ID embedding can be obtained by assigning ID vectors to N objects for an ID bank that can store M learnable ID vectors.
Spatial-Temporal Propagation
The embedding for the current frame gets transformed into the query:\(\mathbf{Q}_t \in \mathbb{R}^{THW \times C}\) along with the memory embedding, which becomes the key \(\mathbf{K}_m \in \mathbb{R}^{THW \times C}\) and the value, \(\mathbf{V}_m \in\mathbb{R}^{THW \times C}\) . The propagation module then fuses the ID embedding \(\mathbf{E}_{\text{id}} \in \mathbb{R}^{THW \times C}\) with the value Vm and propagates it to the current frame by utilizing the attention mechanism:
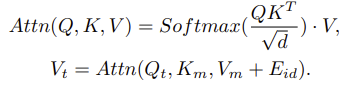
This is the case for any frame with predicted boxes/masks extended to T memory frames.
Dual-Branch Decoding
The last part of the pipeline is to forward the embedding to two branches that deal with predictions: one for predicting masks with a feature pyramid network and the other for predicting boxes through a transformer-based pinpoint box head.
The branch in charge of predicting the mask applies a softmax function on N out of M channels, where the predicted logits are \(\mathbf{S}_m \in\mathbb{R}^{H_s \times W_s \times M}\) with probability \(\mathbf{P}_m \in \mathbb{R}^{HW \times N}\) .Similarly, the box branch uses the probability vectors \(\mathbf{P}_b^{x_1, x_2} \in \mathbb{R}^{H \times 2M}\) and \(\mathbf{P}_b^{y_1, y_2} \in\mathbb{R}^{H \times 2M}\) to select N boxes from the M-formed boxes. Putting it all together, the resulting pipeline is characterized by the following image:
Novel Module Contributions: Unified Identification Module
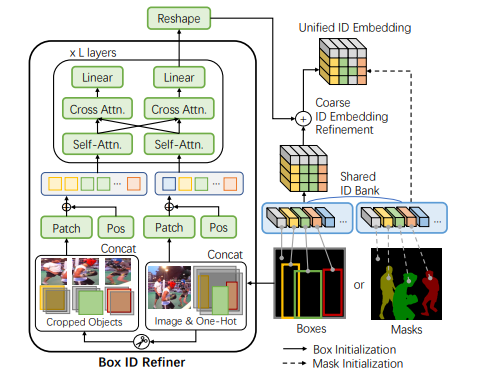
The MITS framework argues previous visual object segmentation models suffer from performance degradation when they use a bounding box to initialize or that the naive solution to train an extra model to generate segmentation masks from boxes is expensive to train and optimize. To combat these shortcomings, the Unified Identification module is integrated into the pipeline to support both bounding-box and mask initialization, can encode multiple objects, and can be directly trained as part of the VOS model. The module consists of two parts: the global ID bank and the box ID refiner.
The unified identification embedding can be simplified to a simple if condition. If the reference is a mask, the shared ID bank will generate an ID embedding directly from the masks. Else if the reference is a bounding box, the box must first be converted into a box-shaped mask, and then a corse ID embedding will be generated by the shared ID bank. This coarse ID embedding will be used by the box ID refiner to generate a finer ID embedding with richer object details.
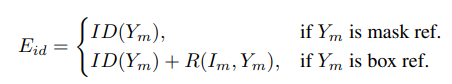
The box ID refiner within the module is a transformer made up of self-attention and cross-attention layers that lead to two paths. The first is a global image information collection path that can determine the position, shapes, and objects. The second is a local object information extraction path that can capture information for each object and within interacting objects for cases like occlusion.
In light of I representing the image path and O representing the object path, the two cross-attention layers are used to exchange information between the two paths in the following matter:
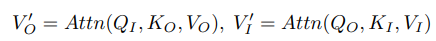
The architecture of this module helps generate finer ID embeddings while also helping get better object discriminative information to be used for multi-object case scenarios. The refinement embedding goes through multiple of these transformer blocks and is eventually sent to the propagation part of the pipeline.
Novel Module Contributions: Pinpoint Box Predictor
MITS also incorporates a new detection mechanism they dub pinpoint box detection. Keypoint-based box detection is a popular object detection mechanism that predicts the top left, bottom right, and center points of a bounding box to be able to detect an object. A drawback however is that this puts more emphasis on exterior points that don’t necessarily need to be inside the object, which can lead to incorrect frame segmentations for this pipeline. MITS pinpoint box predictor helps with this by being able to determine the bounding box and edge features of an object by localizing designated pinpoints through transformer layers with self-attention.
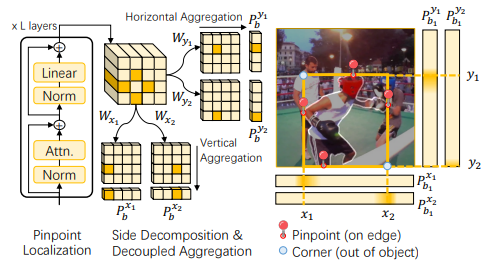
To prevent requiring supervised annotations to detect pinpoints as prior work has done, MITS uses decoupled aggregation. In reality, this predicts the bounding box of an object by extracting the 4 points from the top, bottom, left, and right boundaries. These are labeled as side-aligned coordinates.
First, these coordinates are converted into score maps by convolving with layers \(\mathbf{W}_{x_1, y_1, x_2, y_2} \in \mathbb{R}^{C' \times 4M}\), then to probability maps through a softmax, and aggregated into probability vectors via self-attention with the following formula:
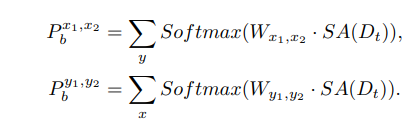
The N bounding boxes for N objects, [x1,x2, y1, y2] , can then be predicted by a soft-argmax
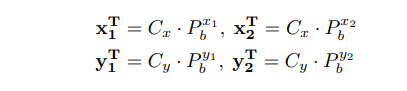
where Cx and Cy are coordinates.

Out of the box, MITS is a fairly robust framework for tracking and segmentation that achieves state-of-the-art performance. Its novel modules allow it to work well for multi-object scenarios while adhering to cases that suffer from occlusion or object overlap. However, the framework is still susceptible to errors that stem from an accurate initialization from either a mask or box. This means a subpar initialization will corrupt the performance for the rest of the pipeline. Additionally, edge cases with non-rigid structures or high levels of occlusions can be an improvement point for the framework, but at least users can fine-tune parts of the pipeline.
Paper 3: SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory
SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory
Cheng-Yen Yang, Hsiang-Wei Huang, Wenhao Chai, Zhongyu Jiang, Jenq-Neng Hwang
Semantic Segmentation explores classifying every pixel into a class.
Meta’s Segment-Anything-Model (SAM) has proved successful in Semantic Segmentation. An iteration of this model, SAM 2, introduces a streaming memory architecture: context is preserved, allowing for sequential video frames to be segmented. Despite success in Visual Object Segmentation, SAM 2 struggles with Object Tracking due to challenges discussed prior. In particular, SAM 2 prioritizes appearance similarity rather than spatial and temporal consistency.
SAMURAI, published November 2024, adapts for Object Tracking. By incorporating temporal motion cues with motion-aware memory selection via a Kalman-filter-based approach, SAMURAI achieves a 7.1% AUC gain on LaSOText and a 3.5% AO gain on GOT-10k.
Architecture and Methodology
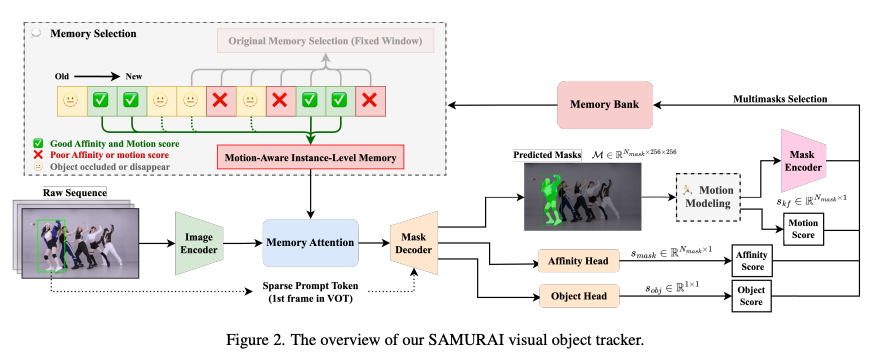
Motion Modeling
A linear-based Kalman filter calculates loss with Intersection-over-Union (IoU) from the ground truth and predicted mask, calculated by the current position and velocities.
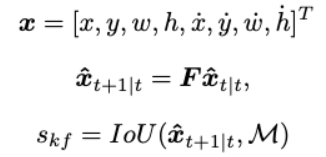
We maximize the KF-IoU Score and original affinity score, updating the state vector.
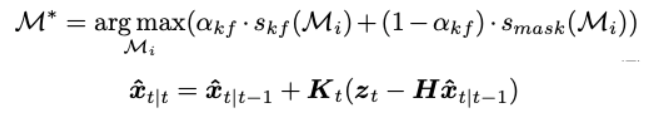
Motion-Aware Memory Selection
SAM 2 selects the N most recent memory frames. However, this cannot handle longer periods of occlusion or object deformation. SAMURAI employs a selective approach based on the mask affinity score, object occurrence score, and motion score, each which is thresholded.
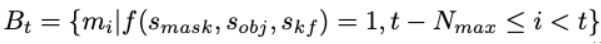
These adjustments are model-agnostic and do not require additional fine-tuning or retraining. The two proposed methodologies do not add computational overhead while maintaining a concept of temporal and spatial locality.
Paper 4: Tracking Meets LoRA
Tracking Meets LoRA: Faster Training, Larger Model, Stronger Performance
Liting Lin1 , Heng Fan2 , Zhipeng Zhang3 , Yaowei Wang1,† , Yong Xu4,1 , and Haibin Ling5,†
The second approach introduces LoRAT, an efficient object-tracking framework that integrates Low-Rank Adaptation (LoRA) within Vision Transformers (ViTs). The authors address the challenges of fine-tuning large-scale pre-trained vision models for visual tracking tasks, which often demand significant computational resources. By adapting LoRA for the visual tracking domain, they aim to make advanced tracking methods accessible without the prohibitive cost of large-scale computational infrastructure.
This work bridges the gap between Parameter-Efficient Fine-Tuning (PEFT), a technique popular in language models, and the unique requirements of visual object tracking, achieving state-of-the-art results with reduced resource demands. The study demonstrates the feasibility of employing transformer-based trackers equipped with LoRA on GPUs with limited memory while maintaining or improving performance metrics.
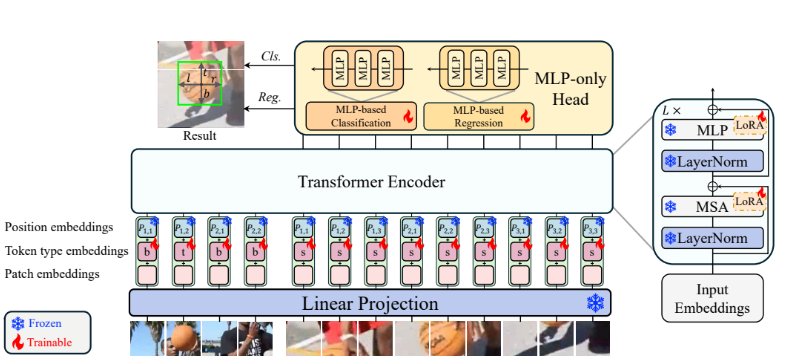
Architecture and Methodology
The proposed method builds upon the one-stream tracking framework (e.g., OSTrack) while introducing innovations tailored to LoRA-based fine-tuning. Below is an architectural overview of the proposed LoRAT tracker.
1. One-Stream Tracking Framework
The one-stream tracking framework is utilized as the baseline due to its minimal disruption to the pre-trained ViT model. LoRAT builds on the one-stream framework, where a template image \(\mathbf{T} \in \mathbb{R}^{H_T \times W_T3}\) (target object) and a search image \(\mathbf{S} \in \mathbb{R}^{H_S \times W_S3}\) (current scene) are processed jointly.
Patch Embeddings
The template image is divided into NT patches, while the search region image is divided into NS patches:
\[N_T = \frac{H_T}{P} \times \frac{W_T}{P}, \quad N_S = \frac{H_S}{P} \times \frac{W_S}{P}\]The patches are then projected into token embeddings, where d represents the hidden dimension of the network:
\[\mathbf{T}_{\text{Tokens}} \in \mathbb{R}^{N_T \times d}, \quad \mathbf{S}_{\text{Tokens}} \in \mathbb{R}^{N_S \times d}.\]Input Embeddings
These token embeddings are combined with positional embeddings ES and ES, respectively, to obtain the template input embedding \(\mathbf{t}_0 \in \mathbb{R}^{N_T \times d}\) :
\[\mathbf{t}_0 = \mathbf{T} + \mathbf{E}_T, \quad \mathbf{s}_0 = \mathbf{S} + \mathbf{E}_S.\]Transformer Encoder
The concatenated embeddings z0 are passed to a L-layer Transformer encoder composed of multi-head self-attention mechanisms and feed-forward neural networks, to jointly extract joint features and fusion. The output zL is the joint feature representation of the template image and search region image. The template image and search region feature representations, denoted as T and S, respectively, are obtained through de-concatenation. The steps can be represented with these equations:
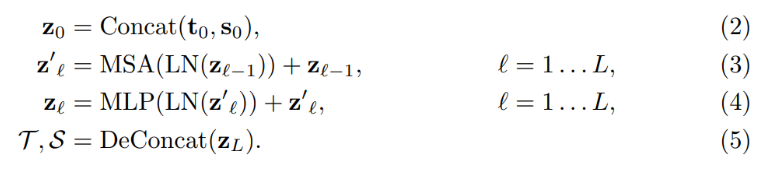
Output: The joint feature representation is processed by an MLP-only Head Network for classification and bounding box regression.
MLP-only Head Network The MLP-only head network replaces traditional convolutional heads to mitigate inductive biases, such as locality assumptions, that can impede convergence in LoRA-based fine-tuning. It consists of two branches: one for classification and another for bounding box regression, each implemented as a three-layer MLP. Operating on the feature map generated by the Transformer encoder, the head adopts a center-based, anchor-free design to accelerate training and enhance tracking performance. By generating a redundant set of bounding boxes with classification scores, the network selects the final bounding box based on the highest score. This approach reduces bias, simplifies training, and improves the efficiency and accuracy of visual object tracking.
2. Low-Rank Adaptation (LoRA)
LoRA is a parameter-efficient fine-tuning technique that introduces trainable low-rank matrices into frozen pre-trained models instead of doing a traditional full forward and backward pass through the network. This enhances model adaptability without being traditionally computationally intensive.
Low-Rank Matrix Decomposition: The key idea is that while pre-trained models have full-rank weight matrices, the task-specific updates required during fine-tuning often lie in a low-dimensional subspace (low “intrinsic dimension”). LoRA updates model weights using smaller matrices to approximate weight changes, significantly reducing trainable parameters \(d \times k\) while preserving performance. LoRA approximates weight matrix updates \(\Delta \Phi_i\) in the network \(\Delta \theta_i\) with:
\[\Delta \theta_i \approx \Delta \Phi_i = \mathbf{B} \mathbf{A}, \text{ where } \mathbf{B} \in \mathbb{R}^{d \times r} \text{ and } \mathbf{A} \in \mathbb{R}^{r \times k}, \text{ with rank } r \ll \min(d, k).\]The low-rank updates are merged with pre-trained weights post-training, ensuring no increase in inference latency. In LoRAT, LoRA is applied to linear layers in the ViT encoder, preserving the model’s foundational structure and enabling efficient fine-tuning for tracking tasks.
3. Decoupled Input Embedding
The Decoupled Input Embedding method addresses inefficiencies in current Vision Transformer (ViT)-based trackers caused by separate positional embeddings for template and search regions, which disrupt the structure of pre-trained models and hinder parameter-efficient fine-tuning (PEFT). The authors introduce Token Type Embeddings and adaptive positional embeddings to resolve these issues.
1) Token Type Embeddings
Originally proposed in BERT, token type embeddings are applied to differentiate between the template and search region tokens. It decouples token identification (template vs. search) from positional embeddings, improving flexibility and parameter efficiency. The paper specifically applies foreground object indication embedding to annotate tokens as foreground or background within templates, mitigating issues like variable aspect ratios, unclear semantics, or indistinguishable backgrounds in the cropped template image.
2) Positional Embedding Adaptation
To handle multi-resolution inputs (template and search regions of different sizes), the authors propose two strategies for adapting the 1D absolute positional embeddings from pre-trained ViTs. This method preserves the positional embedding’s original structure and performs better in experiments.
Interpolation-Based Adaptation Rescales the positional embeddings to match the template size using interpolation. Widely used in existing trackers but suboptimal.
Slicing-Based Adaptation Treats positional embeddings as discrete patch indices and extracts a sub-matrix for the template tokens, corresponding to its size. The paper adopts this method as the primary strategy for adapting position embeddings in their tracker as it outperforms the interpolation-based approach.
3) Final Input Embeddings
The complete input embeddings for both template and search regions add positional embeddings Epos and token type embeddings ET to the patch embeddings.

Conclusions
Complex, dynamic environments (environmental conditions, object occlusions, and erratic movements ) pose a significant challenge to Object Tracking and remain an area of working research.
Targeting the core concept behind tracking an object, Siam-RCNN leverages traditional core concepts in Computer Vision: Siamese Networks and Region-Based CNNs. The network utilizes two parallel networks that share weights. These take consecutive frames (as well as initial vs current) and compare extracted features (through R-CNN) with IoU.
Some current and previous work has attempted to combine commonly separate tasks of Semantic Segmentation and Object Tracking. Take for instance, MITS which encodes the input with a ResNet-50 backbone, then propagates this through Attention layers, and finally decodes it into a feature pyramid network mask predictor and a transformer-based pinpoint box predictor.
Other work aims to adapt Semantic Segmentation for Object Tracking. In particular, SAMURAI adapts Meta’s Segment-Anything-Model 2 (SAM 2) by introducing temporal and spatial consistency through a Kalman-Filter approach and a heuristic memory selection (mask affinity, object occurrence, and motion).
Of course, the Vision Transformer paradigm must be discussed as well. The scalable nature of Transformers and Attention has overturned traditional CNNs. LoRAT introduces trainable low-rank matrices inserted into the latent space of pre-trained models as a method for Parameter-Efficient Fine Tuning (PEFT).
Overall, a variety of approaches have been explored yet Object Tracking remains a challenge due to the unpredictable nature of the dynamic real world.
References
[1] Voigtlaender, Paul, et al. “Siam R-CNN: Visual Tracking by Re-Detection.” 2020.
[2] Xu, Cheng-Yen, et al. “MITS: A Framework for Unified Visual Tracking and Segmentation.” 2023.
[3] Yang, Hao, et al. “SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory.” 2024.
[4] Lin, Liting , et al. “Tracking Meets LoRA: Low-Rank Adaptation for Efficient Visual Tracking.” 2024.