Sign Language Recognition
Sign language recognition is task that can solve by applying computer vision principles. This post will explore various methods and an implementation of a solution.
- Introduction
- Discussion of Existing Literatures
- Our Solution: EfficientNet-B0 Implementation
- Conclusion
- Reference
Introduction
Sign Language Recognition (SLR) involves using computer vision systems to classify hand gestures representing ASL letters and key characters. It is an important issue because it can improve accessibility and bridge communication gaps for those who need to use sign language. There are several major technological solutions capable of interpreting sign language and translating it into text or speech in real time, and recent advancements in deep learning have enabled more robust, scalable systems that can handle the complexities of sign language recognition, including hand gestures and body movements.
Pose-based approaches have gained prominence for their ability to represent sign language through the extraction of keypoints, offering a compact and semantically meaningful input. Meanwhile, RGB-based models, leveraging raw video frames, capture richer spatial-temporal information but often require larger datasets and higher computational resources. Recent innovations have also incorporated transformer architectures—known for their success in natural language processing—to model temporal dependencies and context in sign language sequences. This article delves into several state-of-the-art approaches in sign language recognition, exploring their architectures and performance, and it discusses our own implementation of a sign language recognition model as well.
Discussion of Existing Literatures
SignBERT: A Self-Supervised Pre-Training Framework for Sign Language Recognition
This research paper presents SignBERT, a novel self-supervised pre-training framework specifically designed for sign language recognition (SLR). The study incorporates a model-aware hand prior to overcome challenges in recognizing fine-grained hand gestures and temporal dynamics in sign language.
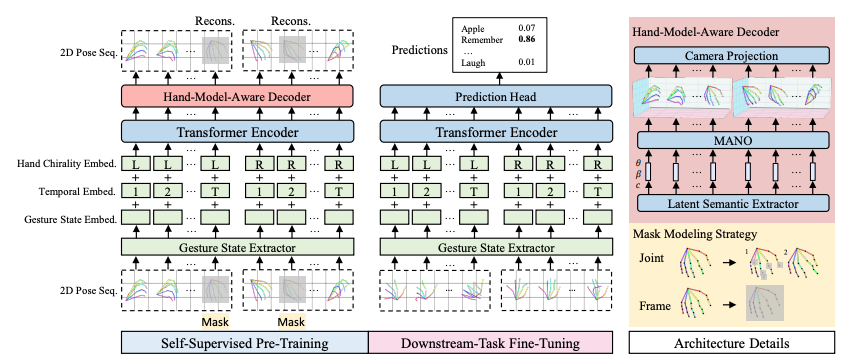 Figure 1.1: The model framework consists of two stages, self-supervised pre-training and fine-tuning [1].
Figure 1.1: The model framework consists of two stages, self-supervised pre-training and fine-tuning [1].
1. Introduction to the Problem
Sign language recognition is a challenging task due to:
- Limited data availability.
- Complexity of hand gestures.
- Sparse and noisy representation.
Pose-based methods often fall behind RGB-based learning methods in performance.
SignBERT: A Self-Supervised Pre-Training Framework for Sign Language Recognition
The research paper presents SignBERT, a novel self-supervised pre-training framework specifically designed for sign language recognition (SLR). The study incorporates a model-aware hand prior to overcome challenges in recognizing fine-grained hand gestures and temporal dynamics in sign language.
2.1 Model Architecture
2.1.1 Self-Supervised Pre-Training
SignBERT takes hand pose sequences derived from sign language videos and views them as visual tokens, uses a transformer encode and hand-model-aware decoder, and reconstructs masked visual tokens using hierarchical context. Hand poses are viewed as visual tokens, and they consist of a gesture state embedding, temporal embedding, and a hind chirality embedding. These hand pose tokens are then fed into the transformer encoder with a multi-head attention module and a feedforward neural network. Then, the hand-model-aware decoder reconstructs the masked input sequence to convert the feature representations to the pose sequence. performs masked joint modeling, masked frame modeling, and identity modeling. Masked joint modeling randomly masks hand joints to mimic detection failures, masked frame modeling masks entire hand poses to enforce reconstruction based on context from other frames or hands, and identity modeling makes the unchanged token fed into the framework. The decoder uses MANO, a statistical model that provides a mapping from a pose to a hand mesh, to perform reconstruction and get projected hand poses.
2.1.2 Fine-Tuning
After pre-training, we need to adapt the pre-trained model for downstream SLR tasks by replacing the decoder with a prediction head. The input hand pose sequence is all unmasked, and we evaluate output using cross-entropy loss.
2.2 Evaluation and Results
2.2.1 Datasets
SignBERT was evaluated on four SLR datasets:
- NMFs-CSL: Chinese sign language with 1,067 words and over 30,000 samples.
- SLR500: A smaller CSL dataset with 500 words.
- MSASL: American sign language captured under challenging recording conditions.
- WLASL: A large-scale ASL dataset with unconstrained web videos.
2.2.2 Results
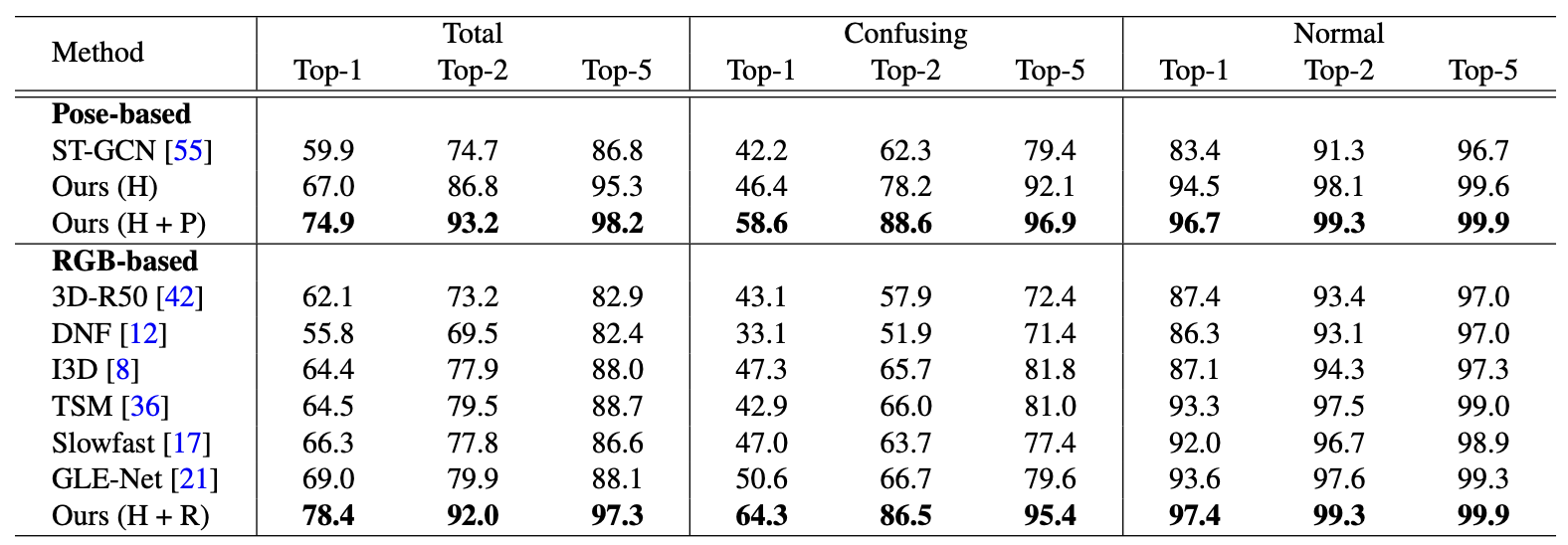 Figure 1.2: Accuracy comparison on NMFs-CSL dataset. The rows labeled Ours correspond to SignBERT.
[1].
Figure 1.2: Accuracy comparison on NMFs-CSL dataset. The rows labeled Ours correspond to SignBERT.
[1].
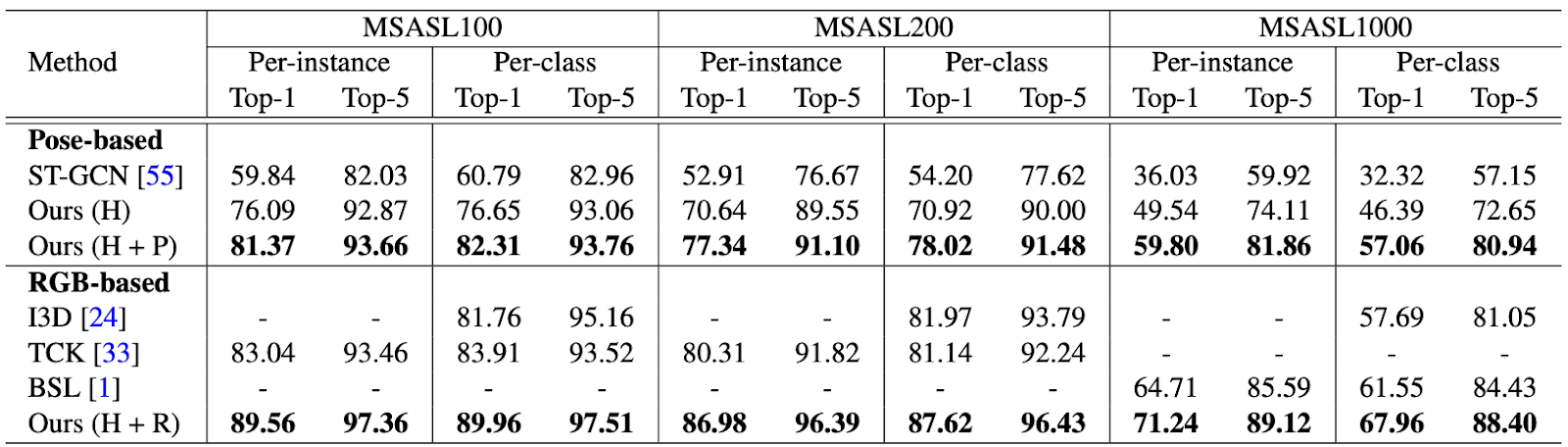 Figure 1.3: Accuracy comparison on MSASL dataset. The rows labeled Ours correspond to SignBERT [1].
Figure 1.3: Accuracy comparison on MSASL dataset. The rows labeled Ours correspond to SignBERT [1].
For all the datasets, the masking strategy, model-aware decoder, and transformer layers all showed a greater level of effectiveness than previous conventional methods. The two tables shown above, along with others in the paper, also display SignBERT’s increased performance by a notable margin. The inclusion of hand chirality and gesture state embeddings enriched the token representation, the multiple different masking strategies, and the model-aware decoder’s unique implementation allowed for eased optimization which led to improvements in recognition accuracy.
An Efficient and Robust Hand Gesture Recognition System
This paper compares different deep-learning models, Inception-V3 and EfficientNet-B0, for hand gesture recognition (HGR).
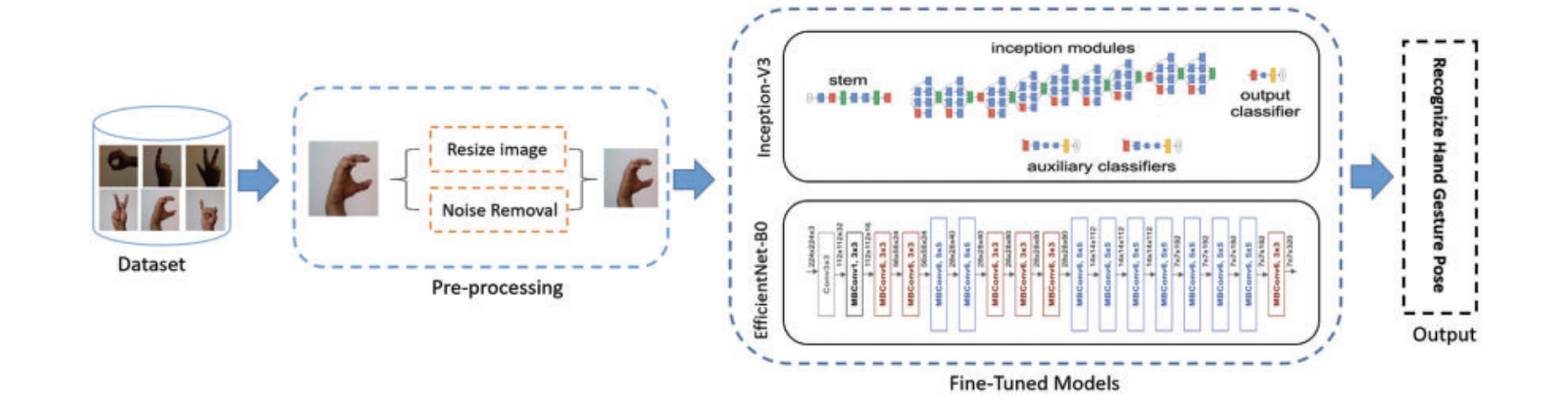 Figure 2.1: Diagram of the model pipeline with Inception-V3 and EfficientNet-B0
[2].
Figure 2.1: Diagram of the model pipeline with Inception-V3 and EfficientNet-B0
[2].
1. Data Collection and Preprocessing
The dataset chosen was the American Sign Language dataset, consisting of 5740 static gesture images with depth maps and covers 37 distinct gestures.
- 10 gestures represent digits 0-9,
- 26 gestures represent the alphabet A-Z,
- 1 gesture represents resting.
The dataset is extremely challenging to learn as it contains human noise and complex backgrounds.
- Images were resized to 224x224.
- Median and Gaussian filters were applied to remove noise.
- Images with 30-degree rotations were included to increase data diversity.
2. Models
2.1 Inception-V3
The Inception-V3 model is an advanced convolutional neural network (CNN) optimized for extracting complex features from images. It improves upon its predecessors (Inception-V1 and V2) with a deeper and more extensive architecture comprising 48 layers. A key feature of Inception-V3 is the inclusion of 1x1 pointwise convolutions, which enable efficient learning of detailed spatial features. The model also employs kernels of varying sizes, applied simultaneously, to capture both fine-grained and broader patterns in data. Transfer learning was used in this study by freezing the top layers of the pre-trained model and fine-tuning new layers to classify hand gestures in the ASL dataset. This approach reduced training time and computational cost while leveraging the model’s ability to handle complex recognition tasks.
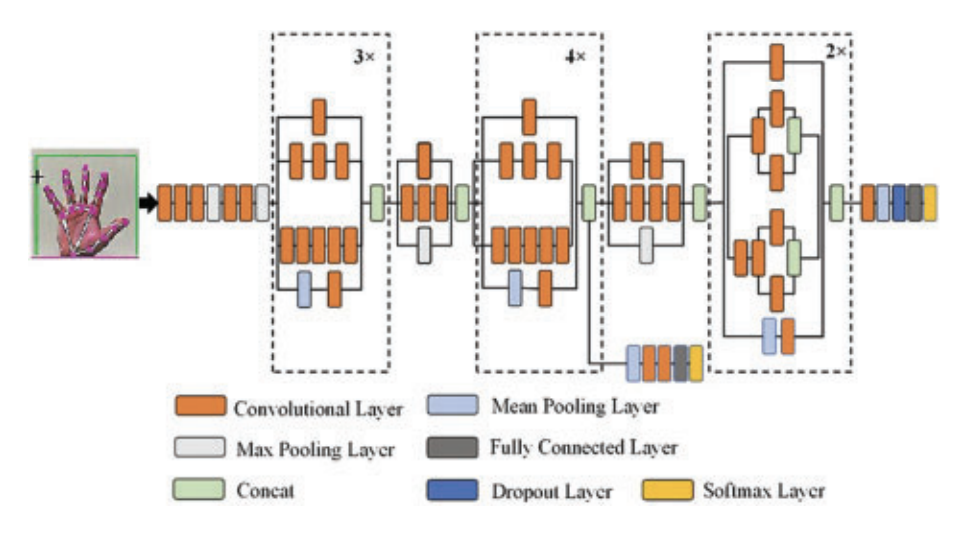 Figure 2.2: Model architecture for Inception-V3
[2].
Figure 2.2: Model architecture for Inception-V3
[2].
2.2 EfficientNet-B0
EfficientNet-B0 is a convolutional neural network (CNN) architecture designed for efficient scaling of network depth, width, and resolution using a compound scaling method. This approach ensures a balanced expansion of the model, enabling it to capture fine-grained features without excessive computational cost. EfficientNet-B0 employs mobile inverted bottleneck convolutions and 3x3 receptive fields to effectively process input images of size 224×224×3. It is the baseline model of the EfficientNet family, which consists of variants from B0 to B7, each with increasing complexity and accuracy. The model is particularly suited for edge devices due to its low memory and computational requirements. In this study, EfficientNet-B0 was fine-tuned for hand gesture recognition using the ASL dataset, demonstrating superior performance in both static and real-time scenarios, achieving higher accuracy and efficiency compared to Inception-V3.
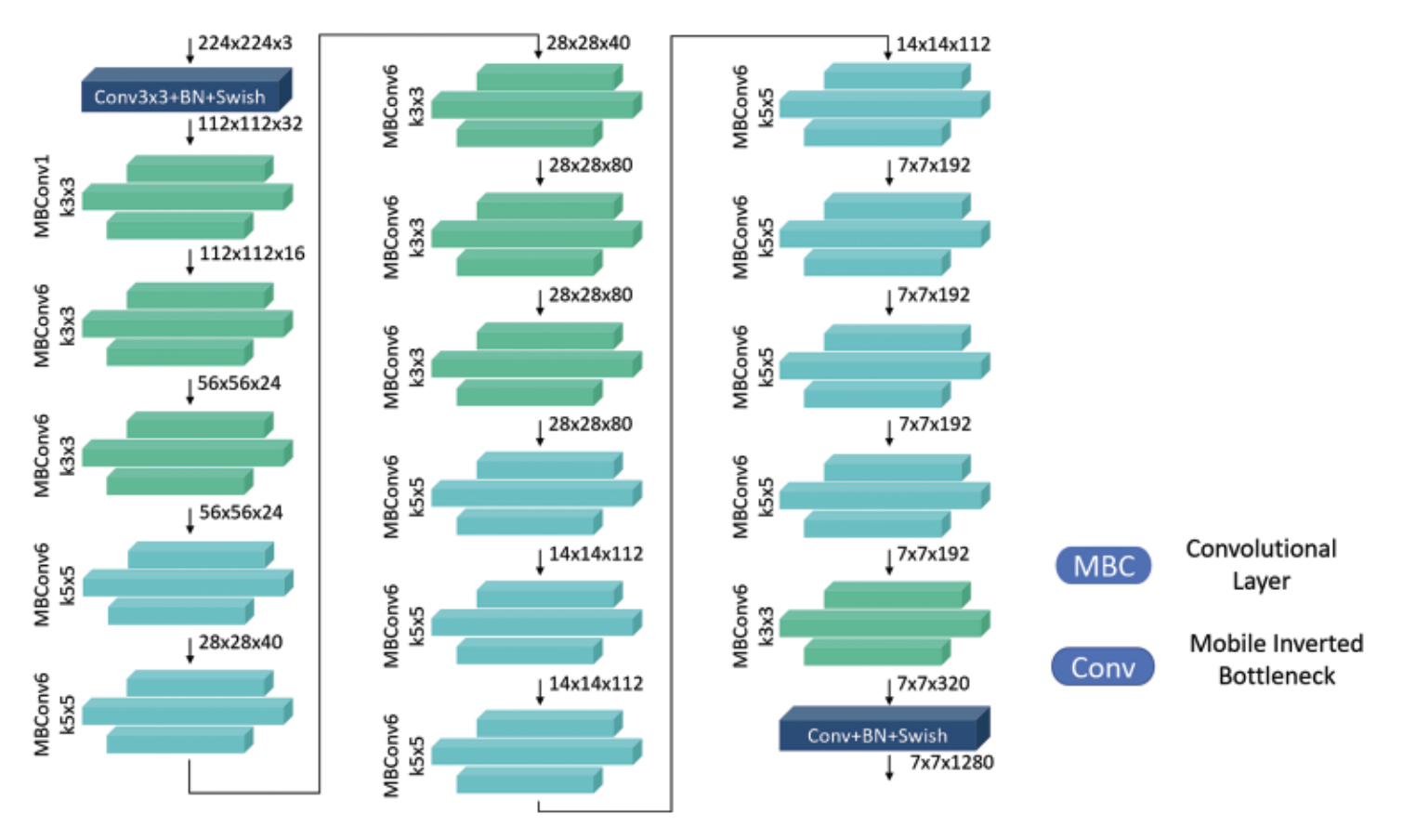 Figure 2.3: Model architecture for EfficientNet-B0
[2].
Figure 2.3: Model architecture for EfficientNet-B0
[2].
3. Results
 Figure 2.4: Hyperparamters chosen for each model.
[2].
Figure 2.4: Hyperparamters chosen for each model.
[2].
After 30 epochs of training:
-
EfficientNet-B0:
- Accuracy: 99%
- Precision, Recall, F1-score: ≥98%
- Faster processing in real-time scenarios.
-
Inception-V3:
- Accuracy: 90%
- Precision: 93%
- Recall: 91%
- F1-score: 90%
EfficientNet-B0 showed higher accuracy and efficiency in static and dynamic environments, though limitations like sensitivity to background conditions and hand-camera distance were noted.
Continuous American Sign Language Recognition Using Computer Vision And Deep Learning Technologies
This paper proposes a solution for detecting American Sign Language using a Recurrent Neural Network (RNN) architecture based on Long Short-Term Memory (LSTM) layers,The architecture integrates Google MediaPipe and OpenCV for extracting pose, face, and hand landmarks
1. Data Collection and Preprocessing
The dataset contains 10 different sign classes recorded from four signers.
- Data captured as sequences of images (not videos).
- Each sequence contains 30 frames, totaling 3,750 sequences and 112,500 images.
- Recording distances ranged from 65 cm to 120 cm to simulate realistic signing conditions.
1.1 Google MediaPipe
- Real-time machine learning framework for detecting pose, face, and hand landmarks.
- Tracks and normalizes landmark coordinates (x, y, z) and visibility scores.
1.2 OpenCV
- Converts video streams into individual frames.
- Supports preprocessing tasks like normalization and visualization.
2. Model Architecture
The proposed model uses a Recurrent Neural Network (RNN) architecture, specifically leveraging Long Short-Term Memory (LSTM) layers to handle temporal dependencies in sequential data. The input to the RNN consists of flattened landmark data extracted from video frames. The architecture features three LSTM layers, which are stacked to improve the model’s ability to capture complex temporal patterns. These layers are followed by three Dense layers, which handle classification. Activation functions include ReLU for the LSTM and intermediate Dense layers, and Softmax in the final Dense layer to output probabilities for each class. The model is optimized using the Adam optimizer, ensuring efficient learning. This architecture is robust in processing sequential sign language data, effectively predicting gestures with high accuracy across varying signer conditions.
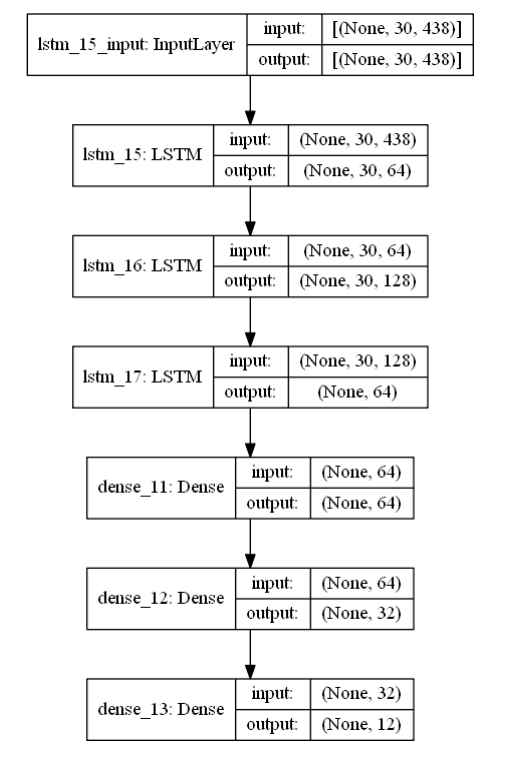 Figure 3.1: RNN architecture utilizing LSTM layers
[3].
Figure 3.1: RNN architecture utilizing LSTM layers
[3].
3. Results
The architecture achieved high performance across experimental setups:
- Single signer, 10 sign classes:
- Training/Validation Accuracy: 99%
- Two signers, 5 sign classes:
- Validation Accuracy: 96%
- Three signers, 5 sign classes:
- Validation Accuracy: 87%
- Four signers, 5 sign classes:
- Validation Accuracy: 90%
Comparison with other methods:
- SVM: 82% accuracy
- SSD MobileNet v2: 85.45% accuracy
- Pose-GRU: 61.38% accuracy
- Pose-TGCN: 62.24% accuracy
4. Key Findings
The proposed architecture demonstrated superior performance compared to existing approaches across multiple experimental setups. In the first experimental round, using data from a single signer with 10 sign classes, the model achieved 99% training and validation accuracy, showcasing its effectiveness in controlled conditions. As the dataset complexity increased, accuracy declined slightly: the second round (two signers, five sign classes) achieved 96% validation accuracy, while the third round (three signers, five sign classes) achieved 87% validation accuracy. The final round, involving four signers and five sign classes, yielded 90% validation accuracy, indicating strong generalization despite increased signer diversity.
When compared to other approaches, the proposed model significantly outperformed alternatives such as SVM (82% accuracy), SSD MobileNet v2 (85.45% accuracy), and various RNN-based models, including Pose-GRU (61.38% accuracy) and Pose-TGCN (62.24% accuracy) on similar datasets. This highlights the superior design and training of the proposed 6-layer network, which combines LSTM and Dense layers, achieving 90% accuracy on multi-signer datasets. Real-time testing with a virtual camera further validated its robustness, making it a promising tool for continuous ASL recognition in dynamic environments.
Our Solution: EfficientNet-B0 Implementation
1 Data Acquisition and Preprocessing
1.1 Dataset Overview
The dataset used in this project is the ASL Alphabet Dataset, comprising approximately 87,000 labeled images spanning 29 classes. These include the 26 letters of the American Sign Language (ASL) alphabet along with a few additional symbols. The dataset was sourced from Kaggle and programmatically downloaded using the Kaggle API to ensure consistency and reproducibility. After downloading, the dataset was extracted and organized into a structured directory format compatible with TensorFlow data pipelines.
1.2 Image Resizing and Normalization
To prepare the dataset for training, all images were resized to 224x224 pixels, ensuring uniformity across the dataset while aligning with the input requirements of EfficientNet-B0, which is optimized for fixed input dimensions. Following resizing, pixel values were normalized using EfficientNet-B0’s built-in preprocessing function. Normalization standardizes the input distribution, ensuring compatibility with the pretrained model and promoting stable training dynamics.
1.3 Data Augmentation
To enhance the robustness of the model and reduce the risk of overfitting, extensive data augmentation techniques were applied to the training dataset. These augmentations included:
- Random rotations of up to 20 degrees, simulating slight hand tilts.
- Horizontal and vertical shifts of up to 20%, mimicking hands being slightly off-center in the frame.
- Shear transformations to account for perspective distortions.
- Zoom augmentations up to 20% to handle variations in hand-camera distances.
- Brightness adjustments within the range of 0.7 to 1.3 to replicate diverse lighting conditions.
- Random horizontal flips, ensuring the model could handle mirrored gestures.
These augmentations introduced realistic variability into the dataset, allowing the model to generalize effectively to unseen real-world scenarios.
1.4 Dataset Splitting and Batch Size
The dataset was split into 75% training and 25% validation subsets. This partitioning ensured that the model was trained on a majority of the data while reserving a separate portion to evaluate its performance on unseen examples. Training began with a batch size of 64, which was later adjusted to 128 during experimentation. The larger batch size leveraged GPU capabilities more efficiently and provided smoother gradient updates, especially for larger datasets.
1.5 Visualization
To verify the correctness of the preprocessing pipeline, augmented images were visualized. This step served as a qualitative check, ensuring that the transformations were applied as intended and that the augmented samples retained the essential features necessary for accurate ASL recognition.
 Figure 4.1: Visualiation of Data.
Figure 4.1: Visualiation of Data.
1.6 Summary
Through resizing, normalization, augmentation, and splitting, the preprocessing pipeline transformed raw ASL dataset images into a high-quality and diverse dataset optimized for training. These steps were critical in preparing the data for effective learning and generalization, equipping the model to handle real-world challenges such as variations in hand positions, lighting, and camera angles.
2 Results Analysis
2.1 Feature Extraction (No Fine-Tuning)
In the initial phase, EfficientNet-B0 was used as a frozen feature extractor, with its pretrained layers remaining static while only the custom layers were trained. Over five epochs, training accuracy improved significantly, rising from 62.19% to 94.28%. Validation accuracy stabilized at 87%, indicating strong generalization initially.
Loss trends further highlighted this behavior. Training loss decreased sharply from 2.11 to 0.49, while validation loss declined more modestly from 1.12 to 0.66. By the later epochs of this phase, the model began to show signs of overfitting, as evidenced by the widening gap between training and validation performance. This suggested that while the model effectively learned the training set, it struggled to generalize fully to unseen data.
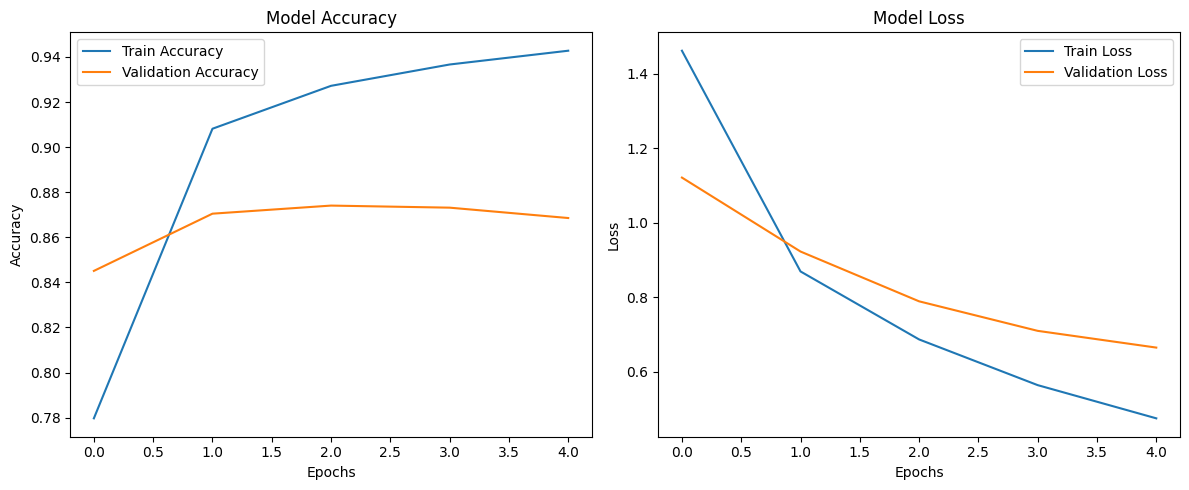 Figure 4.2: Training Results Feature Extraction - Frozen Model.
Figure 4.2: Training Results Feature Extraction - Frozen Model.
2.2 Fine-Tuning (Unfreezing Selected Layers)
Fine-tuning involved unfreezing the last 30 layers of EfficientNet-B0, allowing the model to adapt high-level features specifically to the ASL dataset. While this phase improved training accuracy further, reaching 96.01%, it exacerbated the overfitting observed earlier. Validation accuracy remained relatively stagnant, hovering around 87%-88%, and in some instances decreased slightly compared to the feature extraction phase.
Training loss continued to decline, dropping from 0.37 to 0.34 over three epochs, reflecting the model’s growing ability to fit the training data. However, validation loss exhibited minimal improvement, declining only slightly from 0.61 to 0.59. These results strongly suggest that fine-tuning led to overfitting, with the model focusing excessively on the training set at the cost of generalization. This could be attributed to the limited number of fine-tuning epochs and the relatively small dataset size, which hindered the model’s ability to refine its performance effectively.
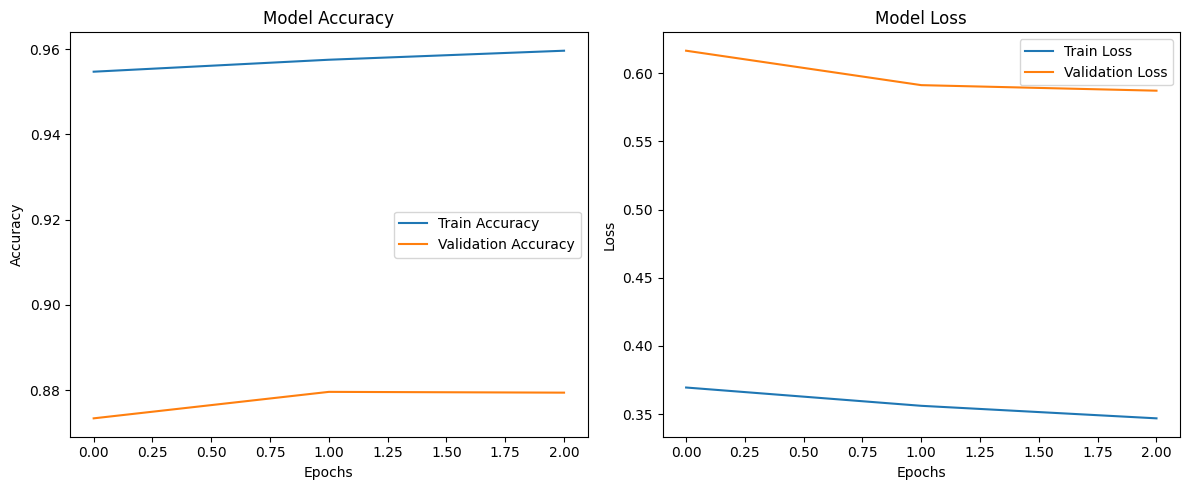 Figure 4.3: Fine Tuning Training Results - after training with feature extraction
.
Figure 4.3: Fine Tuning Training Results - after training with feature extraction
.
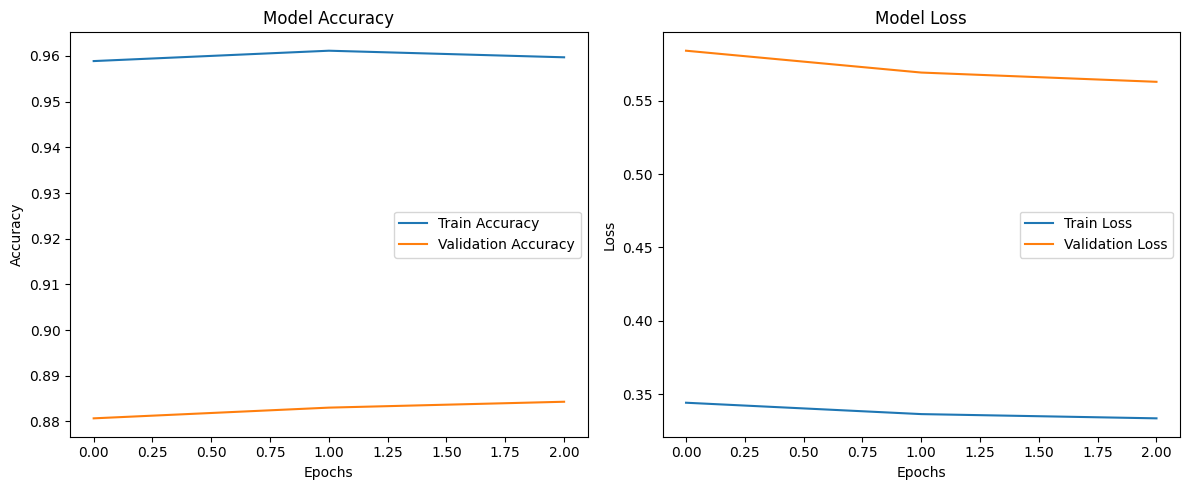 Figure 4.4: Fine Tuning Pt. 2 Training Results
.
Figure 4.4: Fine Tuning Pt. 2 Training Results
.
2.3 Larger Batch Size Experiment
An experiment with a batch size of 128 was conducted to assess its impact on training stability and optimization. The larger batch size facilitated smoother gradient updates, with training accuracy reaching 95.56%. Validation accuracy remained consistent at 87.42%, similar to previous phases. Validation loss improved slightly, declining from 0.89 to 0.63 over three epochs, but these changes were not substantial. The results suggested that while a larger batch size enhanced stability and training efficiency, it did not address the overfitting issues observed during fine-tuning.
2.4 Summary
- Feature Extraction: The model demonstrated strong baseline performance with validation accuracy stabilizing at 87%. However, as training progressed, early signs of overfitting appeared, as evidenced by the widening gap between training and validation performance.
- Fine-Tuning: While training accuracy improved significantly, validation accuracy stagnated and, in some cases, decreased slightly. Validation loss exhibited minimal improvement, highlighting a worsening of overfitting due to fine-tuning.
- Larger Batch Size: Increasing the batch size provided more stable training dynamics without significant changes in validation accuracy or loss, indicating that the dataset size and limited fine-tuning epochs were the primary challenges.
Conclusion
EfficientNet-B0 demonstrated robust feature extraction capabilities, achieving strong performance in the early stages of training. However, the model began to overfit during the feature extraction phase as the gap between training and validation performance widened. Fine-tuning exacerbated this issue, leading to a further decline in generalization performance despite improvements in training accuracy.
The overfitting observed during fine-tuning can be attributed to the limited number of fine-tuning epochs and the relatively small dataset size, which restricted the model’s ability to refine its high-level features effectively. To address these challenges, future work should explore regularization techniques, extended fine-tuning with additional validation monitoring, and dataset augmentation to improve generalization. Despite these limitations, EfficientNet-B0 remains a promising and scalable solution for ASL recognition tasks, particularly in scenarios with sufficient training data and optimized fine-tuning strategies.
You can access the code implementation on Google Colab here.
Reference
[1] Hu et al. “SignBERT: Pre-Training of Hand-Model-Aware Representation for Sign Language Recognition.” 2016. arXiv:2110.05382
[2] Hussain et al. “An Efficient and Robust Hand Gesture Recognition System of Sign Language Employing Finetuned Inception-V3 and Efficientnet-B0 Network. Computer Systems Science and Engineering.” 2023. 10.32604/csse.2023.037258
[3] Senanayaka et al. “Continuous American Sign Language Recognition Using Computer Vision And Deep Learning Technologies.” 2022. 10.1109/TENSYMP54529.2022.9864539