Medical Image Segmentation
Medical image segmentation leverages deep learning to partition medical images into meaningful regions like organs, tissues, and abnormalities. This report explores key segmentation models such as U-Net, U-Net++, and nnU-Net, detailing their architectures, challenges, comparative performance, and practical applications in clinical and research settings.
Introduction
Our group explored medical image segmentation, an increasingly critical tool in healthcare that has been used for decades to help doctors and researchers analyze medical scans like MRIs, CT scans, and X-rays. In the past, segmentation was done either manually — requiring painstaking effort from medical professionals — or using basic computer algorithms that often lacked precision. These traditional methods struggled with issues like the variability between different patients’ scans, the complexity of human anatomy, and the quality of the images, which could be blurry or noisy.
However, the rise of deep learning in recent years has transformed the field of medical image segmentation. Deep learning models can automatically analyze thousands of images and learn to identify patterns, making the segmentation process faster and more accurate. This has led to significant improvements in the ability to detect tumors, delineate organs, and monitor diseases. Deep learning can adapt to different types of medical images and handle the natural variability found in human tissues more effectively than older methods.
While challenges like image noise and medical uncertainty still exist, deep learning has pushed the boundaries of what medical image segmentation can achieve. With continued research and better data, this technology holds great promise for improving patient care and advancing medical knowledge.
Definition
Medical image segmentation is a technique used to partition medical images, such as MRI or CT scans, into regions of interest. These regions can include organs, tissues, tumors, and other abnormalities. However, regardless of what region, accurate segmentation is essential for a wide range of applications in clinical practice and medical research.
Medical image segmentation differs from standard image classification because it requires high precision and accuracy due to the nuanced nature of medical diagnosis. Misclassifications can lead to incorrect treatment plans or flawed research conclusions.
Given a 2D or 3D medical image, the objective is to generate a segmentation mask with the same dimensions. Each pixel or voxel in the mask is assigned a label corresponding to predefined categories, such as organs, lesions, or background.
Applications
This kind of segmentation has a profound impact on both clinical and research settings. In clinical practice, it enhances the precision of diagnostic procedures, treatment planning, and disease monitoring. For instance, accurate tumor segmentation can significantly improve the outcomes of radiotherapy by targeting cancerous tissues while sparing healthy ones. In research, segmentation facilitates the creation of high-quality datasets for training machine learning models, advancing our understanding of various diseases, and developing new therapeutic strategies.
-
Clinical Applications:
- Tumor Detection: Identifying the presence and extent of tumors.
- Treatment Planning: Assisting in radiotherapy and surgical procedures.
- Disease Monitoring: Tracking changes in pathology over time.
-
Research Applications:
- Machine Learning: Preparing datasets for training and evaluating AI models.
- Disease Analysis: Understanding the progression of diseases such as cancer or neurodegenerative disorders.
- Monitoring Disease Progression: In oncology, segmentation helps track changes in tumor size or shape across multiple scans. For instance, sequential MRI scans can be segmented to visualize and quantify how a tumor responds to chemotherapy.
Other examples include:
- Surgical Planning: Segmenting organs and tissues to assist surgeons in planning minimally invasive procedures.
- Radiotherapy: Accurately delineating tumor boundaries to target radiation precisely while sparing healthy tissue.
Deep Learning-Based Solutions
U-Net
U-Net is a widely used convolutional neural network (CNN) architecture designed for image segmentation tasks. It has become a cornerstone in medical image segmentation due to its effectiveness, especially with limited datasets.
Key Features
- Data Augmentation: Enhances performance on small datasets.
- Detailed Masks: Produces segmentation masks with high accuracy.
- Flexibility: Applicable to both 2D and 3D image segmentation tasks.
- Simplicity and Robustness: Easy to implement and train.
Architecture
U-Net follows an encoder-decoder structure that captures both spatial context and fine-grained details:
-
Encoder (Contracting Path):
- The encoder uses convolutional and pooling layers to systematically extract features from the input image while progressively reducing the spatial dimensions. This process allows the network to capture essential details at different levels of abstraction. As the spatial dimensions decrease, the feature depth increases, enabling the model to learn and represent more complex, hierarchical information about the image.
-
Decoder (Expanding Path):
- The decoder restores the spatial dimensions of the feature maps by using upsampling, specifically through transposed convolutions. During this process, the decoder integrates features from the encoder using skip connections, which help retain important details lost during the downsampling phase. This combination of upsampling and skip connections refines the segmentation mask, ensuring that fine-grained details and spatial context are preserved.
Visualization
The U-Net architecture can be visualized as a U-shaped design that combines feature extraction in the encoder path with upsampling in the decoder path. Below is a diagram illustrating the architecture:
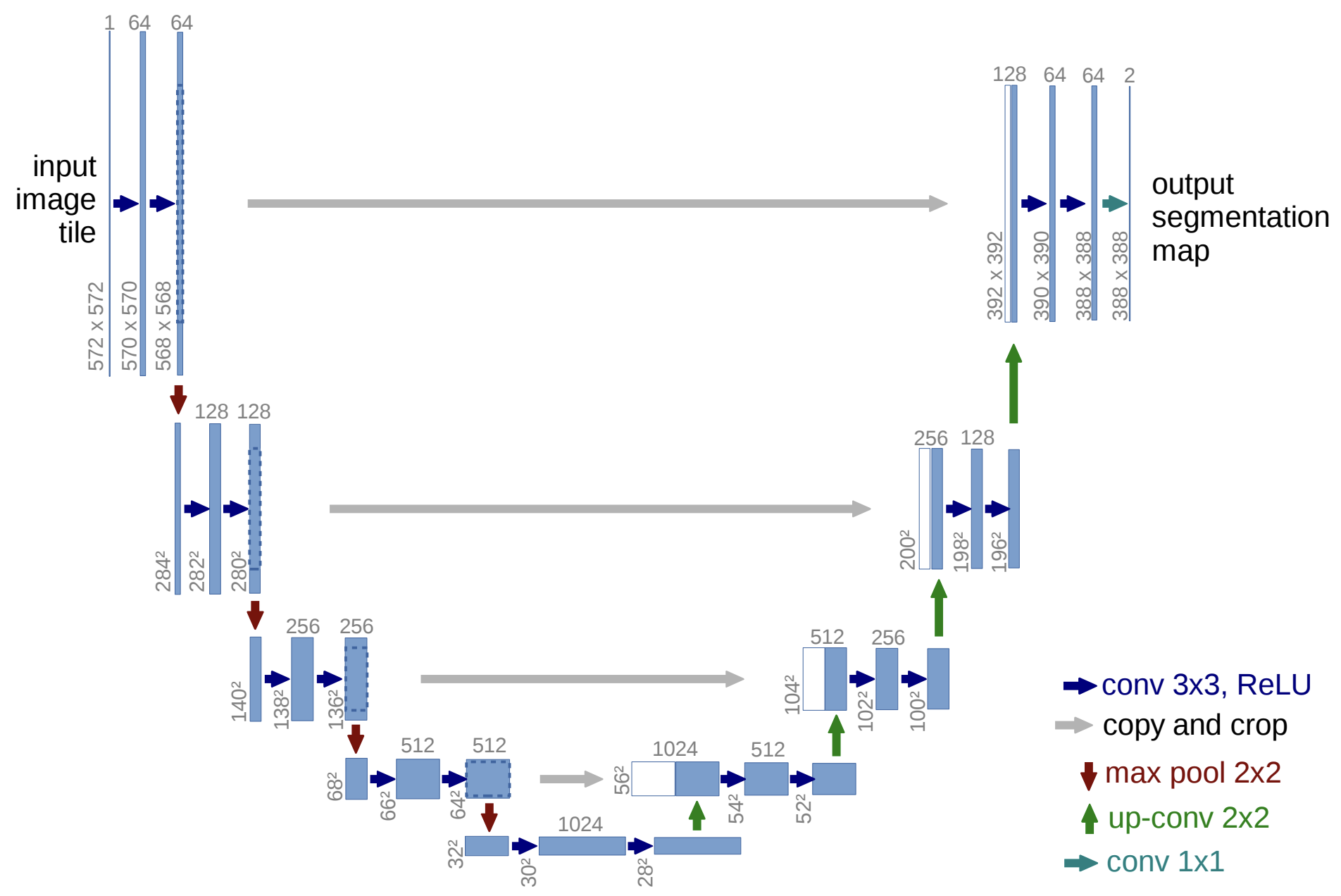
Fig. 1. Illustration of the U-Net architecture with its characteristic encoder-decoder structure. The encoder extracts features through convolution and pooling, while the decoder restores spatial dimensions using up-convolutions and skip connections to produce the segmentation map. Dimensions of feature maps and key operations are annotated for clarity. Adapted from Ronneberger et al., 2015 [1]
Training Process
- Data Preparation: Labeled images are preprocessed through resizing, normalization, and augmentation.
- Forward Pass: The input image is passed through the network to produce a segmentation map.
- Loss Calculation: The predicted segmentation map is compared with the ground truth using a loss function such as Dice Loss.
- Backward Pass: The model’s parameters are updated using gradient descent and an optimizer like Adam.
- Training Loop: The process is repeated over multiple epochs to minimize loss.
- Validation and Testing: The model’s accuracy is evaluated on unseen data.
Limitations of U-Net
- Conceptual Gap: Encoder captures low-level details, while the decoder captures high-level semantics, making integration challenging.
- Skip Connection Issues: Direct skip connections may lead to poor feature fusion, affecting segmentation accuracy.
Implementation
import torch
import torch.nn as nn
import torch.nn.functional as F
class UNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super(UNet, self).__init__()
# Encoder layers
self.enc1 = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU()
)
self.pool1 = nn.MaxPool2d(2)
self.enc2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU()
)
self.pool2 = nn.MaxPool2d(2)
# Decoder layers
self.up2 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec2 = nn.Sequential(
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU()
)
self.final = nn.Conv2d(64, out_channels, kernel_size=1)
def forward(self, x):
# Encoder
e1 = self.enc1(x)
p1 = self.pool1(e1)
e2 = self.enc2(p1)
p2 = self.pool2(e2)
# Decoder
up2 = self.up2(e2)
merge2 = torch.cat([up2, e1], dim=1)
d2 = self.dec2(merge2)
out = self.final(d2)
return out
This implementation of U-Net creates the essential encoder-decoder structure of U-Net with skip connections. It can be expanded with various optimization techniques, such as adding more layers, data augmentation, and further.
Literature on U-Net
The architecture of U-Net was designed to address the challenges of medical image segmentation, where annotated data is often scarce. Ronneberger and colleagues demonstrated that U-Net could achieve state-of-the-art results by using extensive data augmentation techniques, such as elastic deformations, to compensate for the lack of training samples. Their network successfully outperformed the prior best methods in the ISBI 2012 challenge for neuronal structure segmentation in electron microscopy images and won the ISBI 2015 cell tracking challenge for light microscopy datasets [1].
Key innovations highlighted in their work include:
Symmetrical Encoder-Decoder Structure: U-Net’s encoder-decoder design allows it to capture contextual information while retaining high-resolution details through skip connections. This combination ensures precise localization of segmented regions, making it highly suitable for biomedical tasks.
Data Efficiency: The network was shown to be trainable end-to-end with only a few annotated images, leveraging data augmentation to improve robustness to variations like deformations and gray-scale changes [1].
Fast Inference: U-Net’s efficient architecture enables the segmentation of a 512x512 image in less than a second on a modern GPU, making it practical for real-world clinical applications [1].
The original implementation, based on Caffe, and the trained networks were made publicly available, accelerating further research and adoption in the medical imaging community.
While we only briefly extrapolated these concepts, it provided a basis of understanding and we highly recommend their paper for those who would like more details.
U-Net++
U-Net++ improves upon U-Net by introducing dense, nested skip connections, refining the encoder’s features before they are passed to the decoder. Its enhanced structure leads to improved segmentation performance, particularly in complex medical scenarios [2].
- Feature Refinement: Intermediate convolutional layers progressively refine encoder features before passing them to the decoder.
- Modular Design: Easily integrates with other deep learning techniques for enhanced performance.
Visualization
The architecture of U-Net++ is illustrated in the following figure:
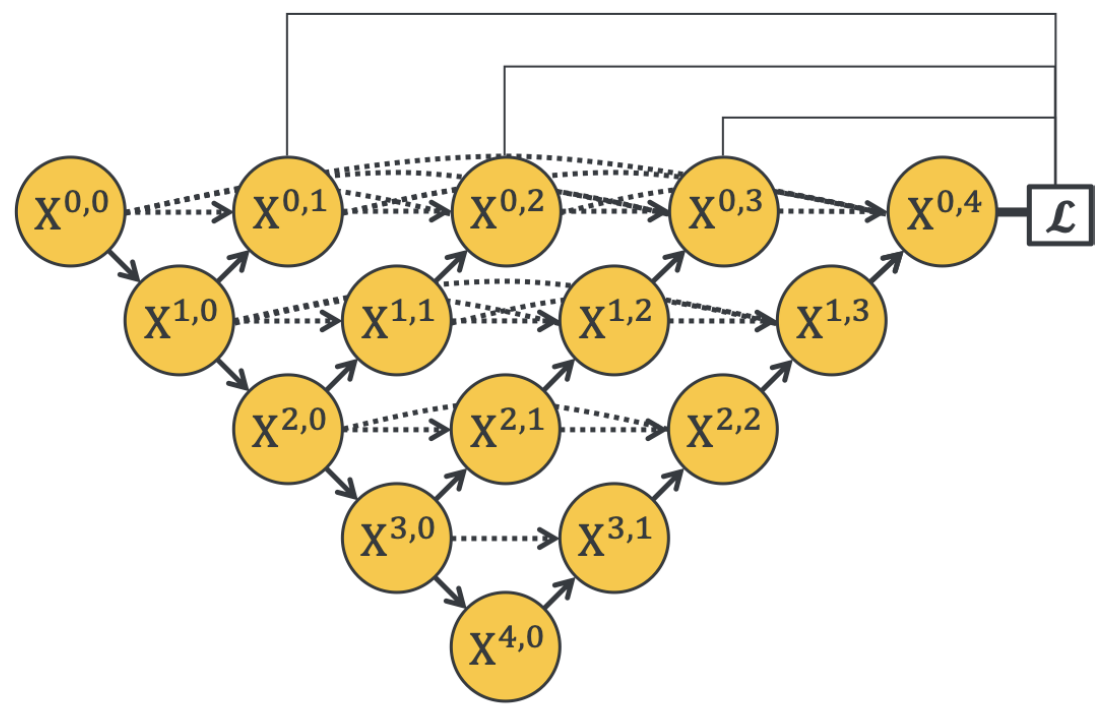
Fig. 2. Illustration of the U-Net++ architecture with its encoder-decoder structure connected through nested dense convolutional blocks. These redesigned skip pathways reduce the semantic gap between the feature maps of the encoder and decoder, allowing for more effective feature fusion. Adapted from Zhou et al., 2020 [2].
Multi-Dimensional U-CNN
The Multi-Dimensional U-Convolutional Neural Network further refines U-Net++ by:
- Horizontal Refinement: Adding convolution layers between encoder and decoder features to improve feature alignment.
- Vertical Alignment: Feeding feature maps from each layer into the horizontal convolution path for enhanced feature extraction.
Visualization
The architecture of MDU-CNN is illustrated below:
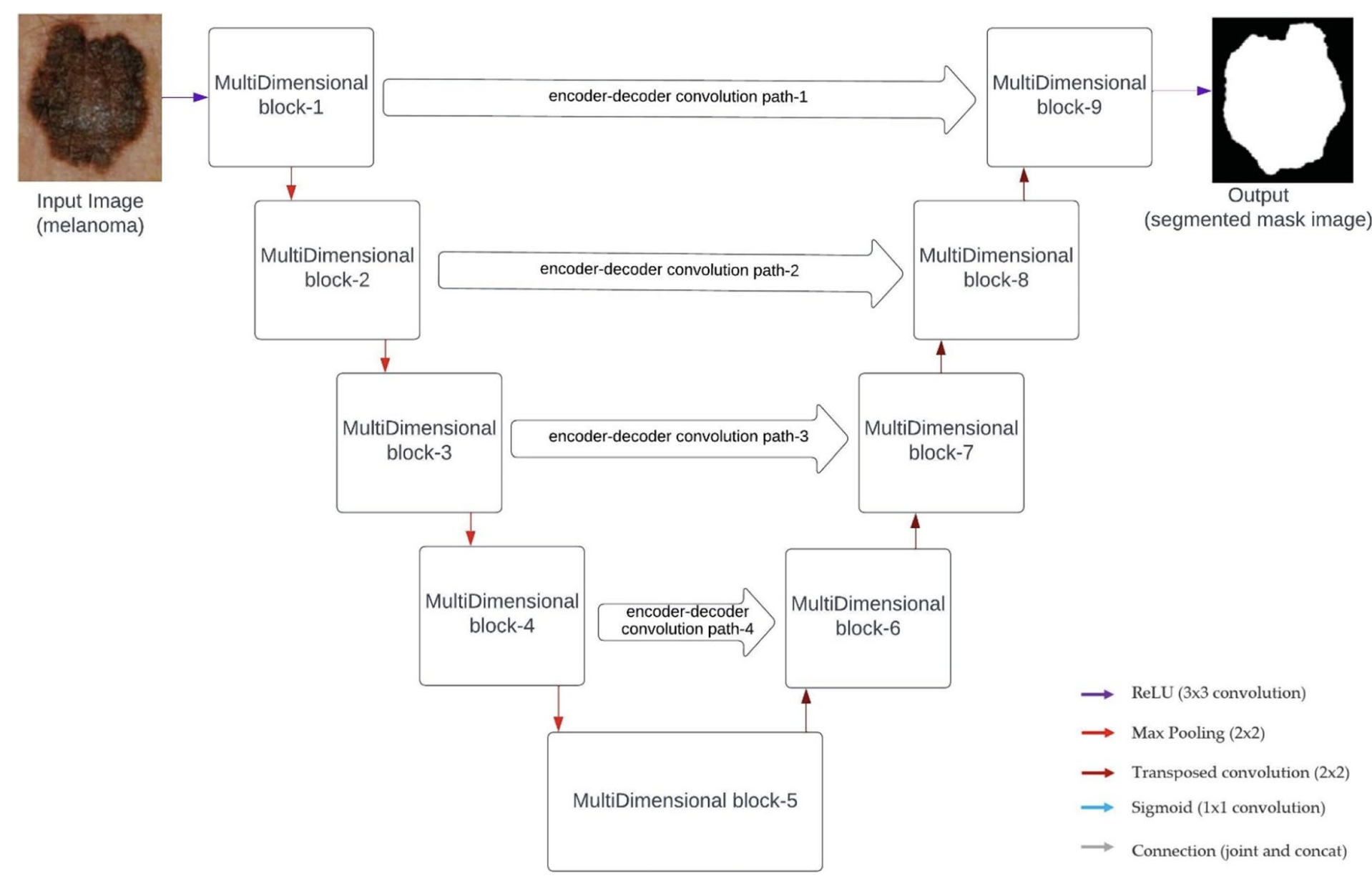
Fig. 3. The architecture of MDU-CNN integrates multi-dimensional blocks with horizontal and vertical refinement mechanisms. This design enhances feature alignment and extraction, resulting in improved segmentation accuracy. Adapted from Srinivasan et al., 2024 [3].
Performance Evaluation
When tested on 5 distinct datasets, each with its own unique challenges, MDU-CNN had a better performance of 1.32%, 5.19%, 4.50%, 10.23%, and 0.87% respectively– a notable improvement upon traditional U-Net architecture [4].
Implementation
import torch
import torch.nn as nn
class UNetPlusPlus(nn.Module):
def __init__(self, in_channels=1, out_channels=1, num_filters=64):
super(UNetPlusPlus, self).__init__()
# Initial convolutional layers
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, num_filters, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(num_filters, num_filters, kernel_size=3, padding=1),
nn.ReLU()
)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Sequential(
nn.Conv2d(num_filters, num_filters * 2, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(num_filters * 2, num_filters * 2, kernel_size=3, padding=1),
nn.ReLU()
)
self.pool2 = nn.MaxPool2d(2)
# Decoder layers
self.up2 = nn.ConvTranspose2d(num_filters * 2, num_filters, kernel_size=2, stride=2)
self.conv2_1 = nn.Sequential(
nn.Conv2d(num_filters * 2, num_filters, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(num_filters, num_filters, kernel_size=3, padding=1),
nn.ReLU()
)
self.final = nn.Conv2d(num_filters, out_channels, kernel_size=1)
def forward(self, x):
# Encoder
e1 = self.conv1(x)
p1 = self.pool1(e1)
e2 = self.conv2(p1)
# Decoder with nested skip connection
up2 = self.up2(e2)
merge2 = torch.cat([up2, e1], dim=1)
d2 = self.conv2_1(merge2)
out = self.final(d2)
return out
This basic implementation captures the nested skip connections of U-Net++, which refine features more effectively than the standard U-Net. The model can also be further expanded by adding more layers or blocks to match the full complexity of U-Net++. [2]
Literature on U-Net++
Zhou et al. identified two primary challenges with U-Net: the difficulty in determining optimal network depth and the restrictive nature of same-scale skip connections. To overcome these, U-Net++ introduces the following key innovations:
Redesigned Skip Connections: Instead of direct skip connections between encoder and decoder layers, U-Net++ employs dense, nested skip connections. These connections aggregate features from varying scales, allowing more flexible and effective feature fusion. This design helps in retaining both high-level semantic information and low-level spatial details, resulting in more accurate segmentation maps [2].
Ensemble of U-Nets: U-Net++ embeds multiple U-Nets of varying depths within a single architecture. These U-Nets share a common encoder but have separate decoders, facilitating collaborative learning through deep supervision. This approach mitigates the uncertainty around choosing the optimal depth for the network and improves segmentation quality for objects of different sizes [2].
Pruning for Efficiency: To address computational efficiency, U-Net++ supports a pruning scheme that accelerates inference by removing redundant layers while maintaining performance. This feature makes U-Net++ adaptable to resource-constrained environments without sacrificing segmentation accuracy [2].
Extensive evaluations by Zhou et al. on six medical imaging datasets, including CT, MRI, and electron microscopy, demonstrated that U-Net++ consistently outperforms the original U-Net and other baseline models. The architecture is particularly effective in segmenting fine structures and objects with significant size variations, making it a robust tool for medical image segmentation [2].
nnU-Net
nnU-Net (“no-new-U-Net”) automates the process of adapting U-Net to new datasets, providing a robust and standardized pipeline [5]. By examining properties of the input dataset and adjusting hyperparameters and architectural details accordingly, nnU-Net streamlines preprocessing, architecture selection, training, and post-processing steps. Compared to earlier architectures, it removes much of the trial-and-error involved in configuring segmentation models, allowing for state-of-the-art results across diverse medical imaging tasks without manual tuning.
Configurations
-
Fixed Configurations:
- Learning rate, loss function, and optimizer remain consistent across datasets.
-
Rule-Based Configurations:
- Adjustments for patch size, normalization, and batch size based on dataset properties.
-
Empirical Configurations:
- Fine-tuning and post-processing based on validation performance.
Pipeline
- Data Fingerprinting: Extract image properties like spacing, intensity, and shape.
- Configuration Decisions: Apply rule-based adjustments to network topology.
- Empirical Optimization: Post-processing and ensembling to improve performance.
- Validation: Ensures model robustness and generalization.
Implementation
import torch
import torch.nn as nn
import torch.nn.functional as F
class nnUNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1, num_filters=64):
super(nnUNet, self).__init__()
# Encoder blocks
self.enc1 = self.conv_block(in_channels, num_filters)
self.enc2 = self.conv_block(num_filters, num_filters * 2)
self.enc3 = self.conv_block(num_filters * 2, num_filters * 4)
# Pooling layers
self.pool = nn.MaxPool2d(2)
# Decoder blocks
self.up3 = nn.ConvTranspose2d(num_filters * 4, num_filters * 2, kernel_size=2, stride=2)
self.dec3 = self.conv_block(num_filters * 4, num_filters * 2)
self.up2 = nn.ConvTranspose2d(num_filters * 2, num_filters, kernel_size=2, stride=2)
self.dec2 = self.conv_block(num_filters * 2, num_filters)
# Final output layer
self.final = nn.Conv2d(num_filters, out_channels, kernel_size=1)
def conv_block(self, in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU()
)
def forward(self, x):
# Encoder
e1 = self.enc1(x)
p1 = self.pool(e1)
e2 = self.enc2(p1)
p2 = self.pool(e2)
e3 = self.enc3(p2)
# Decoder
up3 = self.up3(e3)
d3 = self.dec3(torch.cat([up3, e2], dim=1))
up2 = self.up2(d3)
d2 = self.dec2(torch.cat([up2, e1], dim=1))
# Final output
out = self.final(d2)
return out
Literature on nnU-Net
nnU-Net was introduced by Isensee et al., 2018 as a self-adapting framework designed to overcome the limitations of manually configuring U-Net architectures for different medical imaging tasks [5]. The key innovation of nnU-Net lies in its ability to automatically adapt network architecture, preprocessing, and training pipelines based on the characteristics of the input dataset. This automation allows nnU-Net to deliver state-of-the-art performance across a wide range of segmentation tasks without requiring manual adjustments or hyperparameter tuning.
Key Contributions Automated Configuration: nnU-Net evaluates the dataset’s image geometry and automatically selects the optimal U-Net variant (2D U-Net, 3D U-Net, or cascaded U-Net) along with appropriate patch sizes, pooling operations, and batch sizes [5]. This eliminates the need for trial-and-error adjustments, making the framework highly versatile and efficient.
Preprocessing and Training Pipeline: The framework defines a comprehensive pipeline that includes cropping, resampling to a median voxel spacing, intensity normalization (For CT images: clip to [0.5, 99.5] percentile range and z-score normalization; For MRI: z-score normalization after nonzero mean computation), and extensive data augmentation techniques like elastic deformations and gamma correction. These steps are dynamically adapted for each dataset to maximize segmentation performance [5].
Empirical Evaluation: nnU-Net was evaluated in the Medical Segmentation Decathlon, a challenge comprising ten distinct medical imaging tasks. It achieved top rankings across multiple datasets, demonstrating its robustness and generalizability. Notably, nnU-Net outperformed manually optimized architectures by focusing on effective preprocessing, training, and inference strategies rather than introducing novel architectural changes [5].
Ensembling and Post-Processing: To enhance robustness, nnU-Net employs model ensembling and test-time augmentations. Post-processing techniques, such as enforcing single connected components, further refine the segmentation results [5].
This self-configuring approach positions nnU-Net as a powerful benchmark for medical image segmentation, capable of adapting to new challenges with minimal human intervention.
Implementation nnUNetV2 with Bounding Box Prediction for 2D Data
Overview
We utilized the capabilities of the nnUNet framework by integrating bounding box prediction for segmenting 2D medical image data. Using a subset of the BRATS23 dataset, we achieved a test IOU of 0.81, showcasing the efficacy of nnUNet in detecting and delineating brain tumors.
Dataset Setup
The dataset was organized following the nnUNet convention, with specific adjustments for bounding box annotations:
nnUNet/
├── nnUNetFrame/
│ ├── DATASET/
│ │ ├── nnUNet_raw/
│ │ │ ├── Dataset001_MEN/
│ │ │ │ ├── imagesTr/
│ │ │ │ │ ├── BRATS_001_0000.nii.gz
│ │ │ │ │ ├── BRATS_001_0001.nii.gz
│ │ │ │ │ ├── BRATS_001_0002.nii.gz
│ │ │ │ │ ├── BRATS_001_0003.nii.gz
│ │ │ │ │ ├── BRATS_002_0000.nii.gz
│ │ │ │ │ ├── BRATS_002_0001.nii.gz
│ │ │ │ │ ├── BRATS_002_0002.nii.gz
│ │ │ │ │ ├── BRATS_002_0003.nii.gz
│ │ │ │ ├── labelsTr/
│ │ │ │ │ ├── BRATS_001.nii.gz
│ │ │ │ │ ├── BRATS_002.nii.gz
│ │ │ │ └── imagesTs/
│ │ │ │ └──dataset.json
│ │ │ ├── Dataset002_MET/
│ │ │ │ ├── imagesTr/
│ │ │ │ ├── labelsTr/
│ │ │ │ └── imagesTs/
│ │ │ │ └──dataset.json
│ │ ├── nnUNet_preprocessed/
│ │ │ ├── Dataset001_MEN/
│ │ │ ├── Dataset002_MET/
│ │ │ ├── Dataset003_GLI/
│ │ └── nnUNet_trained_models/
│ │ ├── Dataset001_MEN/
│ │ ├── Dataset002_MET/
│ │ └── Dataset003_GLI/
The dataset.json was modified to include bounding box annotations:
{
"channel_names": {
"0": "FLAIR",
"1": "T1w",
"2": "T1gd",
"3": "T2w"
},
"labels": {
"background": 0,
"tumor": 1
},
"bounding_boxes": true,
"numTraining": 32,
"file_ending": ".nii.gz"
}
Training and Results
nnUNetv2_train 4 2d 0 --npz
Inference Pipeline
nnUNetv2_predict -i /path/to/test_data -o /path/to/output -tr nnUNetTrainerV2 -c 2d -p nnUNetPlans -chk checkpoint_best.pth
- Test IOU: 0.81
- Hardware: NVIDIA RTX 3090 with CUDA 11.8
- Training Duration: ~5 hours per fold
- Evaluation Metrics:
- Dice Coefficient
- IOU (Intersection over Union)
Other Specification and Optimizations
-
Patch Size Computation: ps = min(dataset_median_shape * 0.25, max_img_size_memory_constraint, preprocessed_img_size)
- Network Depth Calculation: max_num_pooling = floor(log2(min(patch_size)))
- Training Protocol:
- SGD with Nesterov momentum (0.99)
- Initial LR: 0.01 with poly learning rate policy
- Batch size determined by: max*batch_size = floor(available_gpu_memory / (patch_size * channels _ features_per_voxel))
Evaluation Metrics
Medical image segmentation models are typically evaluated using several key metrics that assess different aspects of segmentation accuracy. The Dice Similarity Coefficient (DSC) measures the overlap between predicted and ground truth segmentations. The Intersection over Union (IoU), or Jaccard Index, provides another measure of overlap that is particularly useful for irregular shapes.
Challenges and Limitations
Despite significant advances, medical image segmentation still faces several key challenges. Data scarcity remains a primary constraint, as acquiring large datasets of professionally annotated medical images is both time-consuming and expensive. Class imbalance is another significant challenge, particularly in pathology detection where the region of interest may comprise only a small portion of the image. Image quality variations, including artifacts, noise, and differences in acquisition protocols across medical facilities, can impact segmentation accuracy. Moreover, the interpretability of deep learning models remains a concern in medical applications where understanding the reasoning behind segmentation decisions is crucial for clinical trust and adoption. There are also computational challenges, as 3D medical images require significant processing power and memory, potentially limiting real-time applications in resource-constrained settings.
Conclusion
Deep learning-based medical image segmentation models like U-Net, U-Net++, and nnU-Net provide robust and efficient tools for clinical and research applications. They have emerged from a rich body of literature, each contributing key innovations: from U-Net’s foundational encoder-decoder design, to U-Net++’s refined nested skip connections, to nnU-Net’s automated, dataset-agnostic approach.Despite challenges related to dataset variability and computational resources, these models represent significant advancements in medical imaging. Looking ahead, several promising directions are emerging in medical image segmentation. Transformer-based architectures are being integrated with CNN-based models, combining the spatial awareness of CNNs with transformers’ ability to capture long-range dependencies. Federated learning approaches are addressing data privacy concerns by enabling model training across multiple institutions without sharing sensitive medical data. Additionally, self-supervised learning techniques are helping to overcome the limitation of scarce labeled medical data by leveraging large amounts of unlabeled images for pre-training. These developments, coupled with advances in hardware acceleration and edge computing, suggest a future where highly accurate, real-time medical image segmentation becomes increasingly accessible in clinical settings.Continued research and innovation will further improve segmentation accuracy and accessibility.
References
[1] Ronneberger, O., Fischer, P., & Brox, T. (2015). “U-Net: Convolutional Networks for Biomedical Image Segmentation.” Medical Image Computing and Computer-Assisted Intervention (MICCAI).
[2] Zhou, Z., Siddiquee, M.R., Tajbakhsh, N., & Liang, J. (2020). “UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation” IEEE Transactions on Medical Imaging.
[3] Srinivasan, S., Durairaju, K., Deeba, K., & et al. (2024). “Multimodal Biomedical Image Segmentation using Multi-Dimensional U-Convolutional Neural Network” BMC Medical Imaging.
[4] Srinivasan, S., et al. (2024). “A Comparison of Medical Image Segmentation Techniques.” BMC Medical Imaging.