Street-View Semantic Segmentation
[Project Track: Street-View Semantic Segmentation] In this project, we implemented and evaluated semantic segmentation models on the Cityscapes dataset to enhance pixel-level understanding of urban scenes for autonomous driving; we also built a car to evaluate our models in real-world scenarios.
- Introduction
- Baseline CNN Model
- SAM/SAMV2 + Baseline CNN
- Apply CRF and Grounded SAM on Baseline CNN
- Real-World Testing
- Conclusion
- Reference
- Code
Introduction
Semantic segmentation is a fundamental computer vision task that assigns a class label to every pixel in an image, forming the basis for scene understanding in applications such as autonomous driving, medical imaging, and robotics. In autonomous vehicles, accurate street-level semantic segmentation is critical for identifying drivable surfaces, obstacles, pedestrians, and traffic infrastructure in real-time. This project implements and compares semantic segmentation models on the Cityscapes dataset, a benchmark dataset containing 5,000 high-resolution urban street scenes with fine pixel-level annotations across 19 object categories.
Baseline CNN Model
Our baseline model employs Fully Convolutional Networks (FCN) with a ResNet50 backbone, an architecture commonly used for semantic segmentation. The model consists of a ResNet50 encoder pretrained on ImageNet, followed by a fully convolutional decoder that upsamples features from the encoder to produce pixel-wise predictions. To better fit the Cityscapes dataset which corresponds to 19 classes, we modified the final classifier layer to output 19 classes. The model was initialized with COCO pretrained weights and followed up with some light training so the model can slightly fit better with Cityscapes. For this section of the project, we only trained the new classifier layer to get the baseline CNN for Cityscapes. Further improvements were made with more advanced strategies.
Training was performed with a batch size of 2 due to GPU memory constraints, using the Adam optimizer over 2 epochs. Images were resized to 512x1024 pixels and normalized using ImageNet statistics. After training, the baseline achieved a validation mIoU of approximately 0.234. When visualizing the results, we noticed that the model performed poorly on small, thin objects and when there is a slight gap between objects. Due to the CNN’s architecture, downsampling causes thin structures to disappear in low-res feature maps.
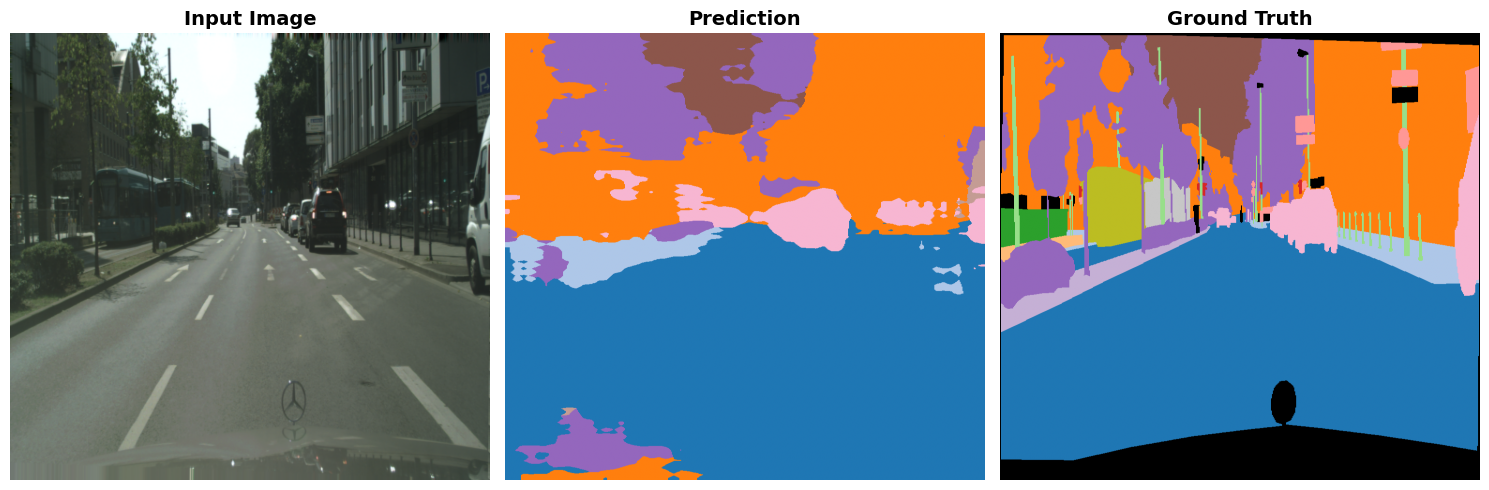
Fig 1. Baseline Model (FCN-ResNet50) Results.
SAM/SAMV2 + Baseline CNN
In this part of the project, the baseline CNN-based semantic segmentation model is extended by applying the Segment Anything Model (SAM) and Segment Anything Model V2 (SAM V2) as post-processing refinement modules. All implementations and experiments described in this section are directly based on the code written and executed in the Jupyter Notebook (.ipynb file). The purpose of this integration is to evaluate whether using large, pretrained segmentation foundation models can improve the quality of the segmentation masks produced by a conventional CNN.
The baseline model used in the notebook is a pretrained Fully Convolutional Network (FCN) with a ResNet-50 backbone. This model is loaded from standard deep learning libraries and applied directly to the dataset to generate initial semantic segmentation masks. The typical CNN-based segmentation model uses an encoder that repeatedly downsampled the image and the decoder then upsample these rough features into a dense segmentation mask where each pixel gets a class score. However, downsampling causes thin structures like poles or fences disappear in low-res feature maps. Visual inspection in the notebook shows that this in turn results in blurring or blending the small objects to its surrounding pixels.
The Segment Anything Model (SAM) is then applied on top of the baseline CNN predictions. In the notebook, SAM is loaded using the official implementation and pretrained weights provided by the SAM GitHub repository [1], which is linked directly in the code. The corresponding model configuration files are also taken from the same repository to ensure correct model initialization. The baseline CNN output is used to guide SAM by defining regions of interest, and SAM generates refined segmentation masks for these regions. This process allows SAM to leverage its strong generalization ability while still being guided by the CNN’s semantic predictions.
Segment Anything Model V2 (SAM V2) is applied in a similar manner in the notebook. The SAM V2 model and its configuation files are obtained from the official SAM V2 GitHub repository [2], which is also referenced in the notebook. Compared to the original SAM, SAM V2 provides more stable mask predictions and improved handling of complex scenes. When applied to the CNN-generated masks, SAM V2 produces cleaner segmentation outputs with better-defined object boundaries and reduced background noise.
To quantitatively evaluate whether SAM and SAM V2 improve segmentation performance, the mean intersection over union (mean IoU) metric is used in the notebook. Mean IoU measures the overlap between the predicted segmentation masks and the ground truth masks across all classes. For each class, IoU is computed as the ratio between the intersection and the union of the predicted and the ground truth regions, and the final mean IoU is obtained by averaging over all classes. By comparing the mean IoU values of the baseline CNN, CNN + SAM, and CNN + SAM V2 (Table 1), the notebook evaluates whether the refined masks produced by SAM-based models lead to measurable improvements.
The experimental results show that applying SAM and SAM V2 on top of the baseline CNN leads to identical or even higher mean IoU scores, indicating better alignment between predicted masks and ground truth (See Figure 1.1 ad 1.2). Among the tested approaches, the CNN combined with SAM V2 achieves the best overall performance, both qualitatively and quantitatively. These results suggest that SAM-based refinement is an effective way to enhance CNN-based semantic segmentation without retraining the original model.
| Metric | Baseline CNN | CNN + SAM | CNN + SAM V2 |
|---|---|---|---|
| Mean IoU | 0.2328 | 0.2239 | 0.2446 |
Table 1: Comparing mean IoU between baseline CNN, CNN + SAM, and CNN + SAM V2.

Fig 2.1 Figure showing qualitative performance of CNN + SAM to ground truth.

Fig 2.2 Figure showing qualitative performance of CNN + SAM V2 to ground truth.
Apply CRF and Grounded SAM on Baseline CNN
Another strategy that we experimented with was applying a Dense Conditional Random Field (Dense CRF) to our baseline CNN model. We applied Dense CRF following the approach described in [3] as a post-processing step on the softmax probability outputs to encourage spatial and appearance consistency in the predicted segmentation masks. Validation results showed a modest improvement, with the best mIoU increasing from 0.2336 without CRF to 0.2368 with CRF. While this suggests that CRF can help refine segmentation boundaries, the improvement was relatively small and came at the cost of significantly increased inference time during validation, with the validation time increasing from approximately 1.5 minutes per epoch without CRF to nearly 18 minutes per epoch with CRF. As a result, the practical benefits of Dense CRF appear limited when weighed against its computational overhead.
Since Dense CRF primarily refines predictions that the model already produces, we hypothesized that it would be more effective if the underlying segmentation had stronger object detection. To test this idea, we introduced Grounded SAM [4] to provide additional supervision for smaller and harder-to-segment objects such as pedestrians, vehicles, poles, and traffic-related elements, including traffic lights and traffic signs. Grounded SAM was used to generate bounding boxes for a selected subset of classes, which served as prompts for the model. An example of the bounding boxes produced by Grounded SAM is shown in the figure given below:

Fig 3. Figure depicting bounding boxes generated by Grounded SAM.
These bounding boxes were then mapped to their corresponding Cityscapes labels and converted into coarse segmentation masks. The resulting pseudo-labels were combined with the original Cityscapes training data to augment the training set. Training with this augmented dataset led to a clear improvement over the baseline model. Without applying CRF, the model achieved a best validation mIoU of 0.2428, compared to 0.2336 when trained without the Grounded SAM pseudo-labels. This improvement suggests that the additional object-level cues helped the model better capture classes that are underrepresented or difficult to segment using pixel-level supervision alone. When Dense CRF was applied on top of the Grounded SAM–augmented model, the gains were again marginal, with the best validation mIoU reaching 0.2423, while incurring a significant increase in inference time.
Overall, these results indicate that improving the training data through pseudo-labeling had a larger impact on performance than applying CRF as a post-processing step. While CRF can provide some boundary refinement, its benefits diminish once the model’s predictions are strengthened by better object detection. For this task, these findings suggest that focusing on improving label quality and coverage is more effective than relying on computationally expensive post-processing techniques.
Real-World Testing
To further compare each model, we built a car and conducted a real-world test. As showcased below, we equipped the car with an ESP-32 cam, a Raspberry Pi Pico2w, and two pairs of L298N motors with attached wheels.



Fig 4. Car model from different angles.
Additionally, we uploaded the saved weights from each of our models to a Google Cloud virtual machine. For SAM/SAM V2, we redownloaded the publicly available weights.
We implemented a hybrid interaction sequence where a user could manually start the car (forward only) or stop the car. Our tech interactions occured as follows:
- Our laptop waits for user input, then sends an appropriate instruction to the car. If asked, it additionally sends an image and query to our virtual machine, then sends an instruction to the car based on the result.
- The car receives an instruction from our laptop. If asked, the ESP-32 cam additionally sends an image to our laptop.
- The virtual machine receives an image from our laptop, analyzes it using the specified model, and sends the result back to our laptop.
To better portray the car's perspective, we considered a center cropping of the image for decision making.
Our decision making was simple:
If we detect a person or pole, turn the car to prevent collision.
Otherwise, continue moving forward.
This wouldn't directly incorporate the improvements we made when it came to preserving thin features, as any object directly in front of the car would typically be large enough for each of the models to decipher. However, we would still be able to observe any performance differences evident between the models.
Demo and Results
Due to hardware bottlenecks, we had to make some adjustments during testing. The configuration of the on-campus wifi did not support communication across our devices, and our phone hotspot was too unstable to use as backup. So, we conducted our tests from home using preloaded images instead of the camera capture.
Additionally, we ran out of batteries to support both sets of motors. To account for this, we only operated the front pair of motors and manually lifted the back of the car in a wheelbarrow-style fashion.
However, even with these limitations, we were able to produce meaningful results. In the videos below, the car stopping represents us querying the virtual machine. Its next action is based on the results of applying one of our models.
From top to bottom, left to right: CNN based model detecting no obstacles, SAM based model detecting no obstacles, CNN based model detecting a person, SAM based model detecting a person.
Performance was similar between all versions that built off the baseline CNN. However, there was a meaningful difference in the time it took to analyze using the SAM/SAM V2 models. The pause during decision making was noticeably longer, increasing from about a second with the CNN based model to several seconds using SAM. This, combined with the similar results of the decision making, indicated that SAM was not a good fit in this particular instance.
Conclusion
Through this project, we explored several differences between the models used. The baseline CNN was quick to implement but still took some time to train. The SAM/SAM V2 models were also quick to implement and came pretrained. SAM performed similar to baseline when comparing segmentation labels, and SAM V2 outperformed the baseline. However, they performed worse during our real-world test. The CNN with CRF/Grounding modifications improved on the baseline when it came to preserving thin features during segmentation. On the other hand, it was complicated to implement and performed relatively similar to the baseline in our real-world test. These results demonstrate several considerations, including the speed of implementation, performace, and type of problem, that must be made when determining a model to use.
Reference
[1] Facebookresearch/Segment-Anything. 23 Mar. 2023, Jupyter Notebook. Meta Research, 14 Dec. 2025. GitHub, https://github.com/facebookresearch/segment-anything.
[2] Facebookresearch/Sam2. 29 July 2024, Jupyter Notebook. Meta Research, 13 Dec. 2025. GitHub, https://github.com/facebookresearch/sam2.
[3] L. B. Eyer. “pydensecrf: Python wrapper for DenseCRF.” GitHub repository. 2015. [Online]. Available: https://github.com/lucasb-eyer/pydensecrf
[4] Hugging Face. “Grounding DINO.” Hugging Face Transformers Documentation. 2023. [Online]. Available: https://huggingface.co/docs/transformers/en/model_doc/grounding-dino
Code
Colab for comparing segmentation performance across models
Code used in real-world testing