MMDetection
In this article, we investigate state of the art object detection algorithms and their implementations in MMDetection. We write an up-to-date guide for setting up and running MMDetection on a structured COCO-2017 dataset in Google Colab based on our experience. We analyse and classify the key component structure (detection head/neck/backbone) of MMdetection models. After which, we reproduce the object detection task for popular models on main-stream benchmarks including the COCO-2017 dataset and construct a datailed interactive table. In the last part of our work, we use signature object detection algorithms on real-live photos and videos taken at UCLA campus and provide error analysis. Finally, we perform basic adversarial attacks on our models using representave photos and evaluate their effects.
Video 1. Spotlight Overview.
- 1. Introduction
- 2. MMdetection Setup and Data Preparation
- 3. Model Structure and Classification
- 4. Model Evaluation
- 5. Interactive Framework/Backbone Results Table
- 6. Photo/Video Demo and Error Analysis
- 7. Adversarial Attacks and Error Analysis
- 8. Demo Links
- Reference
1. Introduction
Stemming from image classification and object localization, Object Detection is one of the core up-stream descriminative tasks in computer vision. Object Detection forms the basis of many other down-stream tasks such as semantic segmentation, instance segmentation, and image captioning. Therefore making it one of the fundamental building blocks towards modern applications including Face Detection and Autonomous Driving. Due to its high level of generality and wide applications, object detection has become one of the most well-studied topics in computer vision over the past 20 years. To assist researchers in evaluating and applying state of the art object detection algorithms, The MMDetection library was created as a gereral toobox library that contains a rich set of object detection and instance segmentation methods as well as related components and modules. Derived from its flexible-modular implementation in PyTorch, it is considered a great improvement over the previous caffe-based Facebook Detectron Library both in its model zoo size and overall performance.
| Object Detection | Adversarial Attack |
|---|---|
 |
 |
2. MMdetection Setup and Data Preparation
2.1 Environment Setup
Environment building and version control is usually the most time-consuming step if not done well. So here we write an up-to-date colab setup guide and our experience dealing with problems in the MMDetection offcial setup docs.
- In your google drive, create a new .ipynb file for environment setup, here I name it “SETUP.ipynb”. In SETUP.ipynb do the following environment setup
-
First mount your google drive
import os from google.colab import drive drive.mount('/content/drive') -
Here I create a new directory named “MMDet1” and cd into it
! mkdir MMDet1 %cd /content/drive/My Drive/MMDet1 -
Now we can use pip to install the mmdetection package and other dependencies
I made some adjustments to the official colab tutorial at:
https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb
# install dependencies: (use cu101 because colab has CUDA 10.1) !pip install -U torch==1.5.1+cu101 torchvision==0.6.1+cu101 -f https://download.pytorch.org/whl/torch_stable.html # install mmcv-full thus we could use CUDA operators !pip install mmcv-full # Install mmdetection !rm -rf mmdetection !git clone https://github.com/open-mmlab/mmdetection.git %cd mmdetection !pip install -e . # install Pillow 7.0.0 back in order to avoid bug in colab !pip install Pillow==7.0.The above installation command does not specify version of MMCV, this could lead to confusing error messages later on. it would also result in an unusually long download time. So here I change the original implementation to specify version details:
# install dependencies: (use cu101 because colab has CUDA 10.1) !pip install -U torch==1.8.1+cu111 torchvision==0.9.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html # install mmcv-full thus we could use CUDA operators # !pip install mmcv-full !pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html # Install mmdetection !rm -rf mmdetection !git clone https://github.com/open-mmlab/mmdetection.git %cd mmdetection !pip install -e . # install Pillow 7.0.0 back in order to avoid bug in colab !pip install Pillow==7.0.0Executing the above block takes about 5 minutes for me.
-
Next we import the installed packages. (remember to set your runtime to GPU) Print package version to verify that we installed correctly:
# Check Pytorch installation import torch, torchvision print(torch.__version__, torch.cuda.is_available()) # Check MMDetection installation import mmdet print(mmdet.__version__) # Check mmcv installation from mmcv.ops import get_compiling_cuda_version, get_compiler_version print(get_compiling_cuda_version()) print(get_compiler_version())if everything is correct, this block should output:
1.8.1+cu111 True 2.21.0 11.1 GCC 7.3
2.2 Dataset Preparation
Next we prepare the Pascal_VOC and COCO-2017 datasets in our mmdetection folder, we need to setup the datasets in given structure so that mmdetection knows how to read them.
I wrote a colab tutorial on this part at: Google Colaboratory
-
First setup drive environment by installing mmdetection and going into the folder we created last time:
%load_ext autoreload %autoreload 2import os from google.colab import drive drive.mount('/content/drive', force_remount=True)# install dependencies: (use cu101 because colab has CUDA 10.1) #!pip install -U torch==1.5.1+cu101 torchvision==0.6.1+cu101 -f https://download.pytorch.org/whl/torch_stable.html !pip install -U torch==1.8.1+cu111 torchvision==0.9.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html # install mmcv-full thus we could use CUDA operators # !pip install mmcv-full # !!!!!!!!!!remember to install with specific version number!!!!!!!!!!! !pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html # Install mmdetection !rm -rf mmdetection !git clone https://github.com/open-mmlab/mmdetection.git %cd mmdetection !pip install -e . # install Pillow 7.0.0 back in order to avoid bug in colab !pip install Pillow==7.0.0 -
Dataset download: COCO-2017
# here we download the dataset inside our mmdetection folder !python3 tools/misc/download_dataset.py --dataset-name coco2017 # remember that the command only downloads the zip files containing the coco dataset # to actually use the dataset, we need to unzip first -
Unzip the coco dataset. This may take approximately 2 hours, do not close browser during any part of this process!!!!
!unzip "data/coco/annotations_trainval2017.zip" -d "data/coco/" !unzip "data/coco/test2017.zip" -d "data/coco/" !unzip "data/coco/train2017.zip" -d "data/coco/" !unzip "data/coco/val2017.zip" -d "data/coco/" -
Dataset download: Pascal_VOC 2007
# here we download the dataset inside our mmdetection folder !python3 tools/misc/download_dataset.py --dataset-name voc2007 # remember that the command only downloads the zip files containing the coco dataset # to actually use the dataset, we need to unzip first -
Unzip the PASCAL-VOC dataset. This is quicker than the coco dataset due to smaller size and tar over zip, again, remebmder not to close browser during any part of this process!!!!
# voc is faster to load because of its smaller size and the fact that it uses tar instead of zip !tar -xvf "data/voc/VOCdevkit_08-Jun-2007.tar" -C "data/voc/" !tar -xvf "data/voc/VOCtest_06-Nov-2007.tar" -C "data/voc/" !tar -xvf "data/voc/VOCtrainval_06-Nov-2007.tar" -C "data/voc/" -
Now just wait a few hours for google drive to load all the images and you are good to go! You can also run the detection now using the images stored in Cache(wierd drive memory).
3. Model Structure and Classification
3.1 Model Structure
There is a popular paradigm for deep learning-based object detectors: the backbone network (typically designed for classification and pre-trained on ImageNet) extracts basic features from the input image, and then the neck (e.g., feature pyramid network) enhances the multi-scale features from the backbone, after which the detection head predicts the object bounding boxes with position and classification information. Based on detection heads, the cutting edge methods for generic object detection can be briefly categorized into two major branches. The first branch contains one-stage detectors such as YOLO, SSD, RetinaNet, NAS-FPN, and EfficientDet. The other branch contains two-stage methods such as Faster R-CNN, FPN, Mask RCNN, Cascade R-CNN, and Libra R-CNN. Recently, academic attention has been geared toward anchor-free detectors due partly to the emergence of FPN and focal Loss, where more elegant end-to-end detectors have been proposed. On the one hand, FSAF, FCOS, ATSS and GFL improve RetinaNet with center-based anchor-free methods. On the other hand, CornerNet and CenterNet detect object bounding boxes with a keypoint-based method.
reference: https://arxiv.org/pdf/2107.00420.pdf
3.2 Model Components in MMdetection
Based on the information above, we can better understand how MMDetection constructs its models. In MMDetection, models are constructed using the following three components as the main building blocks:
- Backbone: First MMdetection uses a FCN backbone network to extract feature maps from images. This part has the largest influence on prediction results.
- Neck: Then the neck enhances the multi-scale features from the backbone. This is the part between backbones and heads, usually models just use FPN as default method.
- Detection Head: After the input image processed by the backbone and neck parts, MMdetection passes the results to detection heads to perform specific tasks such as bounding box prediction and mask prediction.
In addition, the following two components are customizable within each model:
- ROI Extractor: this part extracts features from feature maps
- Loss: the component in head for calculating losses
3.3 Examples for Each Component
Main Components:
- Backbone: ResNet, VGG, ResNeXt, SWIN, PVT
- Neck: FPN, CARAFE, ASPP
- Detection Head: bbox prediction, mask prediction
Sub-Components:
- ROI Extractor: RoI Pooling, RoI Align
- Loss: L1Loss, L2Loss, GHMLoss, FocalLoss
3.4 Model Classification:
3.4.1 Detection Frameworks:
We categorize MMdetection frameworks into two categories based on their detection heads, there are: 1-stage detection model and 2-stage detection models.
Popular frameworks that we hope to investigate are listed below:
- 1-stage detection models:
- YOLO-X
- YOLOv2
- YOLOv3
- SSD
- DSSD
- RetinaNet
- NAS-FPN
- EfficientDet
- 2-stage detection models:
- R-CNN
- Fast-R-CNN
- Faster-R-CNN
- FPN
- Mask-R-CNN
- Cascade-R-CNN
- Libra R-CNN
- SPP-Net
3.4.2 Backbones:
MMdetection Backbones can also be categorized into two categories based on whether they predominately use Convolutional Neurel Networks or the Encoder-Decoder Transformer structure to perform feature extraction.
Popular frameworks that we hope to investigate are listed below:
- CNN-Based Backbones:
- VGG (ICLR’2015)
- ResNet (CVPR’2016)
- ResNeXt (CVPR’2017)
- MobileNetV2 (CVPR’2018)
- HRNet (CVPR’2019)
- Generalized Attention (ICCV’2019)
- GCNet (ICCVW’2019)
- Res2Net (TPAMI’2020)
- RegNet (CVPR’2020)
- ResNeSt (ArXiv’2020)
- Transformer-Based Backbones:
3.4.3 Necks:
At last, here is a list of Necks commonly used in MMDetection. Due to its limited influence over detection results, we do not focus on the effects of different necks on detection results. We only use PAFPN in our investigations of Model Backbone and Detection Framework.
Popular necks in MMDetection are listed below:
4. Model Evaluation
4.1 Config Name Style
When using or contributing to the MMDetection library, the most important file that the user will call/customize is the model config file. It is very important that we have a good understanding of the config file naming convention before we perform actual tasks with MMDetection, so that we can configurate the model to be just what we have in mind. First, lets take a look at the universal config file name:
**{model}_[model** **setting]_{backbone}_{neck}_[norm** **setting]_[misc]_[gpu** **x** **batch_per_gpu]_{schedule}_{dataset}**
Now, given that we understood the Model Structure in MMDetection writen above, we can better understand the various config naming components[8] listed below:
{xxx} is required field and [yyy] is optional.
{model}: model type likefaster_rcnn,mask_rcnn, etc.[model setting]: specific setting for some model, likewithout_semanticforhtc,momentforreppoints, etc.{backbone}: backbone type liker50(ResNet-50),x101(ResNeXt-101).{neck}: neck type likefpn,pafpn,nasfpn,c4.[norm_setting]:bn(Batch Normalization) is used unless specified, other norm layer type could begn(Group Normalization),syncbn(Synchronized Batch Normalization).gn-head/gn-neckindicates GN is applied in head/neck only, whilegn-allmeans GN is applied in the entire model, e.g. backbone, neck, head.[misc]: miscellaneous setting/plugins of model, e.g.dconv,gcb,attention,albu,mstrain.[gpu x batch_per_gpu]: GPUs and samples per GPU,8x2is used by default.{schedule}: training schedule, options are1x,2x,20e, etc.1xand2xmeans 12 epochs and 24 epochs respectively.20eis adopted in cascade models, which denotes 20 epochs. For1x/2x, initial learning rate decays by a factor of 10 at the 8/16th and 11/22th epochs. For20e, initial learning rate decays by a factor of 10 at the 16th and 19th epochs.{dataset}: dataset likecoco,cityscapes,voc_0712,wider_face.
4.2 Evaluate Verifocal-Net with ResNet-50 Backbone on COCO-2017
Now that we undstand the model config files, we can use them to customize and evaluate the models and backbones of our choice. Here is an example of evaluating the Verifocal-Net framework with a ResNet-50 Backbone (FPN neck) on the COCO-2017 dataset. We provide model setting file routes and complete execution results below.(Execution takes approx 20 min on 1 Nvidia T-100 GPU):
4.2.1 Model settings:
!python3 tools/test.py \
configs/vfnet/vfnet_r50_fpn_1x_coco.py \
checkpoints/vfnet_r50_fpn_1x_coco_20201027-38db6f58.pth \
--eval bbox proposal \
--eval-options "classwise=True"
4.2.2 Execution Results:
<p> /content/mmdetection/mmdet/utils/setup_env.py:33: UserWarning: Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
f'Setting OMP_NUM_THREADS environment variable for each process '
/content/mmdetection/mmdet/utils/setup_env.py:43: UserWarning: Setting MKL_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
f'Setting MKL_NUM_THREADS environment variable for each process '
loading annotations into memory...
Done (t=2.28s)
creating index...
index created!
load checkpoint from local path: checkpoints/vfnet_r50_fpn_1x_coco_20201027-38db6f58.pth
[>>] 5000/5000, 4.0 task/s, elapsed: 1239s, ETA: 0s
Evaluating bbox...
Loading and preparing results...
DONE (t=1.29s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=46.34s).
Accumulating evaluation results...
DONE (t=13.19s).
| category | IoU | Area | category | AP |
|-------------------------|----------------|-------------|----------------|-------|
Average Precision (AP) @|[ IoU=0.50:0.95 | area= all | maxDets=100 ] | 0.408 |
Average Precision (AP) @|[ IoU=0.50 | area= all | maxDets=1000 ] | 0.587 |
Average Precision (AP) @|[ IoU=0.75 | area= all | maxDets=1000 ] | 0.441 |
Average Precision (AP) @|[ IoU=0.50:0.95 | area= small | maxDets=1000 ] | 0.244 |
Average Precision (AP) @|[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] | 0.450 |
Average Precision (AP) @|[ IoU=0.50:0.95 | area= large | maxDets=1000 ] | 0.526|
Average Recall (AR) @|[ IoU=0.50:0.95 | area= all | maxDets=100 ] | 0.598 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area= all | maxDets=300 ] | 0.598 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area= all | maxDets=1000 ] | 0.619 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area= small | maxDets=1000 ] | 0.401 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] | 0.650 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area= large | maxDets=1000 ] | 0.757 |
| category | AP | category | AP | category | AP |
|---------------|-------|--------------|-------|----------------|-------|
| person | 0.557 | bicycle | 0.305 | car | 0.445 |
| motorcycle | 0.407 | airplane | 0.654 | bus | 0.644 |
| train | 0.599 | truck | 0.375 | boat | 0.274 |
| traffic light | 0.275 | fire hydrant | 0.682 | stop sign | 0.632 |
| parking meter | 0.461 | bench | 0.219 | bird | 0.352 |
| cat | 0.654 | dog | 0.620 | horse | 0.583 |
| sheep | 0.498 | cow | 0.585 | elephant | 0.637 |
| bear | 0.704 | zebra | 0.679 | giraffe | 0.676 |
| backpack | 0.169 | umbrella | 0.403 | handbag | 0.123 |
| tie | 0.325 | suitcase | 0.389 | frisbee | 0.655 |
| skis | 0.239 | snowboard | 0.274 | sports ball | 0.462 |
| kite | 0.428 | baseball bat | 0.273 | baseball glove | 0.349 |
| skateboard | 0.509 | surfboard | 0.335 | tennis racket | 0.485 |
| bottle | 0.394 | wine glass | 0.386 | cup | 0.434 |
| fork | 0.310 | knife | 0.162 | spoon | 0.136 |
| bowl | 0.413 | banana | 0.239 | apple | 0.209 |
| sandwich | 0.358 | orange | 0.335 | broccoli | 0.237 |
| carrot | 0.225 | hot dog | 0.307 | pizza | 0.495 |
| donut | 0.461 | cake | 0.354 | chair | 0.270 |
| couch | 0.405 | potted plant | 0.288 | bed | 0.326 |
| dining table | 0.178 | toilet | 0.585 | tv | 0.558 |
| laptop | 0.585 | mouse | 0.613 | remote | 0.284 |
| keyboard | 0.534 | cell phone | 0.344 | microwave | 0.576 |
| oven | 0.316 | toaster | 0.372 | sink | 0.360 |
| refrigerator | 0.533 | book | 0.148 | clock | 0.511 |
| vase | 0.386 | scissors | 0.261 | teddy bear | 0.469 |
| hair drier | 0.093 | toothbrush | 0.234 | None | None |
Evaluating proposal...
Loading and preparing results...
DONE (t=0.56s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=75.46s).
Accumulating evaluation results...
DONE (t=12.70s).
| category | IoU | Area | category | AP |
|-------------------------|----------------|-------------|----------------|-------|
Average Precision (AP) @|[ IoU=0.50:0.95 | area= all | maxDets=100 ] | 0.453 |
Average Precision (AP) @|[ IoU=0.50 | area= all | maxDets=1000 ] | 0.678 |
Average Precision (AP) @|[ IoU=0.75 | area= all | maxDets=1000 ] | 0.486 |
Average Precision (AP) @|[ IoU=0.50:0.95 | area= small | maxDets=1000 ] | 0.296 |
Average Precision (AP) @|[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] | 0.522 |
Average Precision (AP) @|[ IoU=0.50:0.95 | area= large | maxDets=1000 ] | 0.633 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area= all | maxDets=100 ] | 0.619 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area= all | maxDets=300 ] | 0.619 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area= all | maxDets=1000 ] | 0.619 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area= small | maxDets=1000 ] | 0.448 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] | 0.691 |
Average Recall (AR) @|[ IoU=0.50:0.95 | area= large | maxDets=1000 ] | 0.820 |
Note that the single most important statistic we use to for ranking the algorithm is the “Average Precision (AP) @[IoU=0.50:0.95 where area=all and maxDets=100]”. Here, the mean average precision of Verifocal-Net with ResNet-50 Backbone on COCO-2017 is 40.8%. Some of the other statistics that are of importance are “Average Recall (AR) @[ IoU=0.50:0.95 area=all maxDets=100 ] => 0.598 “, “Average Precision (AP) @[ IoU=0.50:0.95 area=small maxDets=1000 ] => 0.244”, “Average Precision (AP) @[ IoU=0.50:0.95 area=medium maxDets=1000 ] => 0.450”, and “Average Precision (AP) @[ IoU=0.50:0.95 area= large maxDets=1000 ] => 0.526”
5. Interactive Framework/Backbone Results Table
With the above methods of construction and evaluation, we build the following Interactive Framework/Backbone Results Table which compares the performances and memory usage of different detection frameworks and feature extraction backbones on the COCO-2017 dataset. Due to limitations in Markdown iframe embedding, here we can only display the non-interactive version of our results table. To view a color-seperated and interactive version of this table where you can sort and group_by different labels, please refer to our Interactive Table built with the Notion api.
5.1 Non-Interactive Version for Markdown View
This table contains our reproduced results of popular MMDetection frameworks and backbones on the COCO-2017 dataset:
| Model | # Stage | Backbone | Base | Neck | Schedule | Memory | Status | box mAP | box mAR | Small Objects | Medium Objects | Large Objects | MyCode/Results | config | model_url | Scale |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fast R-CNN | 2-Stage | ResNet-50 | CNN | FPN | 1x | N/A | Depreciated | N/A | N/A | N/A | N/A | N/A | N/A | configs/fast_rcnn/fast_rcnn_r50_fpn_1x_coco.py | N/A | |
| Fast R-CNN | 2-Stage | ResNet-101 | CNN | FPN | 1x | N/A | Depreciated | N/A | N/A | N/A | N/A | N/A | N/A | configs/fast_rcnn/fast_rcnn_r101_fpn_1x_coco.py | N/A | |
| Faster R-CNN | 2-Stage | ResNet-50 | CNN | FPN | 1x | 4.0GB | Executable | 0.374 | 0.517 | 0.212 | 0.41 | 0.481 | https://colab.research.google.com/drive/14YV0cGt2tOMpZeNS6V-mN1eNGaXWoNSf?usp=sharing | configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth | |
| Faster R-CNN | 2-Stage | ResNet-101 | CNN | FPN | 1x | 6.0GB | Executable | 0.394 | 0.533 | 0.224 | 0.437 | 0.511 | https://colab.research.google.com/drive/14YV0cGt2tOMpZeNS6V-mN1eNGaXWoNSf?usp=sharing | configs/faster_rcnn/faster_rcnn_r101_fpn_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r101_fpn_1x_coco/faster_rcnn_r101_fpn_1x_coco_20200130-f513f705.pth | |
| VarifocalNet | 2-Stage | ResNet-50 | CNN | FPN | 1x | N/A | Executable | 0.408 | 0.598 | 0.244 | 0.45 | 0.526 | https://colab.research.google.com/drive/1dj94bQ_8u3qzoChjg3KrOcJMshtzNmc_?usp=sharing | configs/vfnet/vfnet_r50_fpn_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/vfnet/vfnet_r50_fpn_1x_coco/vfnet_r50_fpn_1x_coco_20201027-38db6f58.pth | |
| VarifocalNet | 2-Stage | ResNeXt-101 | CNN | FPN | 2x | N/A | Has Bugs | 0.496 | 0.656 | 0.314 | 0.548 | 0.64 | https://colab.research.google.com/drive/1dj94bQ_8u3qzoChjg3KrOcJMshtzNmc_?usp=sharing | configs/vfnet/vfnet_x101_64x4d_fpn_mdconv_c3-c5_mstrain_2x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/vfnet/vfnet_x101_64x4d_fpn_mdconv_c3-c5_mstrain_2x_coco/vfnet_x101_64x4d_fpn_mdconv_c3-c5_mstrain_2x_coco_20201027pth-b5f6da5e.pth | |
| Mask R-CNN | 2-Stage | Swin-T | Transformer | FPN | 1x | 7.6GB | Executable | 0.427 | 0.559 | 0.265 | 0.459 | 0.566 | https://colab.research.google.com/drive/1aggq_JyvM4JpVp_EvsPkikYBwki_gxUe?usp=sharing | configs/swin/mask_rcnn_swin-t-p4-w7_fpn_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-t-p4-w7_fpn_1x_coco/mask_rcnn_swin-t-p4-w7_fpn_1x_coco_20210902_120937-9d6b7cfa.pth | |
| Mask R-CNN | 2-Stage | Swin-T | Transformer | FPN | 3x | 7.8GB | Executable | 0.46 | 0.595 | 0.314 | 0.493 | 0.593 | https://colab.research.google.com/drive/1aggq_JyvM4JpVp_EvsPkikYBwki_gxUe?usp=sharing | configs/swin/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco_20210908_165006-90a4008c.pth | |
| Mask R-CNN | 2-Stage | Swin-S | Transformer | FPN | 3x | 11.9GB | Executable | 0.482 | 0.604 | 0.321 | 0.518 | 0.627 | https://colab.research.google.com/drive/1aggq_JyvM4JpVp_EvsPkikYBwki_gxUe?usp=sharing | configs/swin/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco_20210903_104808-b92c91f1.pth | |
| YOLOv3 | 1-Stage | MobileNetV2 | CNN | None | 300e | 5.3GB | Executable | 0.239 | 0.374 | 0.106 | 0.251 | 0.349 | https://colab.research.google.com/drive/178sU_2FkqzRww05knIigsLRrA_ed7P82?usp=sharing | configs/yolo/yolov3_mobilenetv2_mstrain-416_300e_coco.py | https://download.openmmlab.com/mmdetection/v2.0/yolo/yolov3_mobilenetv2_mstrain-416_300e_coco/yolov3_mobilenetv2_mstrain-416_300e_coco_20210718_010823-f68a07b3.pth | 416 |
| YOLOv3 | 1-Stage | DarkNet-53 | CNN | None | 273e | 2.7GB | Executable | 0.279 | 0.395 | 0.105 | 0.301 | 0.438 | https://colab.research.google.com/drive/178sU_2FkqzRww05knIigsLRrA_ed7P82?usp=sharing | configs/yolo/yolov3_d53_mstrain-608_273e_coco.py | https://download.openmmlab.com/mmdetection/v2.0/yolo/yolov3_d53_mstrain-608_273e_coco/yolov3_d53_mstrain-608_273e_coco_20210518_115020-a2c3acb8.pth | 608 |
| YOLOX | 1-Stage | YOLOX-x | CNN | None | 300e | 28.1GB | Executable | 0.506 | 0.636 | 0.32 | 0.556 | 0.667 | https://colab.research.google.com/drive/178sU_2FkqzRww05knIigsLRrA_ed7P82?usp=sharing | configs/yolox/yolox_x_8x8_300e_coco.py | https://download.openmmlab.com/mmdetection/v2.0/yolox/yolox_x_8x8_300e_coco/yolox_x_8x8_300e_coco_20211126_140254-1ef88d67.pth | 640 |
| RetinaNet | 1-Stage | ResNet-50 | CNN | FPN | 1x | 3.8GB | Executable | 0.365 | 0.54 | 0.204 | 0.403 | 0.481 | https://colab.research.google.com/drive/1XmgSOg9U7UhK5rc3bYfQVBVtvBupDIk5?usp=sharing | configs/retinanet/retinanet_r50_fpn_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_r50_fpn_1x_coco/retinanet_r50_fpn_1x_coco_20200130-c2398f9e.pth | |
| RetinaNet | 1-Stage | ResNet-101 | CNN | FPN | 1x | 5.7GB | Executable | 0.385 | 0.554 | 0.217 | 0.428 | 0.505 | https://colab.research.google.com/drive/1XmgSOg9U7UhK5rc3bYfQVBVtvBupDIk5?usp=sharing | configs/retinanet/retinanet_r101_fpn_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_r101_fpn_1x_coco/retinanet_r101_fpn_1x_coco_20200130-7a93545f.pth | |
| RetinaNet | 1-Stage | ResNeXt-101 | CNN | FPN | 1x | 10.0GB | Executable | 0.41 | 0.569 | 0.239 | 0.452 | 0.54 | https://colab.research.google.com/drive/1XmgSOg9U7UhK5rc3bYfQVBVtvBupDIk5?usp=sharing | configs/retinanet/retinanet_x101_64x4d_fpn_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_x101_64x4d_fpn_1x_coco/retinanet_x101_64x4d_fpn_1x_coco_20200130-366f5af1.pth | |
| RetinaNet | 1-Stage | PVT-Small | Transformer | FPN | 12e | 14.5GB | Executable | 0.404 | 0.563 | 0.248 | 0.432 | 0.548 | https://colab.research.google.com/drive/1XmgSOg9U7UhK5rc3bYfQVBVtvBupDIk5?usp=sharing | configs/pvt/retinanet_pvt-s_fpn_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvt-s_fpn_1x_coco/retinanet_pvt-s_fpn_1x_coco_20210906_142921-b6c94a5b.pth | |
| RetinaNet | 1-Stage | PVT-V2-b0 | Transformer | FPN | 12e | 7.4GB | Executable | 0.371 | 0.544 | 0.234 | 0.404 | 0.492 | https://colab.research.google.com/drive/1Novfkkgq5qQQM3-NRmqEpyWEcxc3b7_p?usp=sharing | configs/pvt/retinanet_pvtv2-b0_fpn_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b0_fpn_1x_coco/retinanet_pvtv2-b0_fpn_1x_coco_20210831_103157-13e9aabe.pth | |
| RetinaNet | 1-Stage | PVT-V2-b4 | Transformer | FPN | 12e | 17.0GB | Executable | 0.463 | 0.607 | 0.29 | 0.501 | 0.627 | https://colab.research.google.com/drive/1Novfkkgq5qQQM3-NRmqEpyWEcxc3b7_p?usp=sharing | configs/pvt/retinanet_pvtv2-b4_fpn_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b4_fpn_1x_coco/retinanet_pvtv2-b4_fpn_1x_coco_20210901_170151-83795c86.pth | |
| Faster R-CNN | 2-Stage | R-50 (RSB) | CNN | FPN | 1x | 3.9GB | Executable | 0.408 | 0.542 | 0.254 | 0.449 | 0.532 | https://colab.research.google.com/drive/1W9MUoQI212ctwwrAn6HeIVKyG6pj03Il?usp=sharing | configs/resnet_strikes_back/faster_rcnn_r50_fpn_rsb-pretrain_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/resnet_strikes_back/faster_rcnn_r50_fpn_rsb-pretrain_1x_coco/faster_rcnn_r50_fpn_rsb-pretrain_1x_coco_20220113_162229-32ae82a9.pth | |
| RetinaNet | 1-Stage | R-50 (RSB) | CNN | FPN | 1x | 3.8GB | Executable | 0.39 | 0.554 | 0.234 | 0.427 | 0.522 | https://colab.research.google.com/drive/1W9MUoQI212ctwwrAn6HeIVKyG6pj03Il?usp=sharing | configs/resnet_strikes_back/retinanet_r50_fpn_rsb-pretrain_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/resnet_strikes_back/retinanet_r50_fpn_rsb-pretrain_1x_coco/retinanet_r50_fpn_rsb-pretrain_1x_coco_20220113_175432-bd24aae9.pth | |
| Mask R-CNN | 2-Stage | R-50 (RSB) | CNN | FPN | 1x | 4.5GB | Executable | 0.412 | 0.549 | 0.248 | 0.453 | 0.539 | https://colab.research.google.com/drive/1W9MUoQI212ctwwrAn6HeIVKyG6pj03Il?usp=sharing | configs/resnet_strikes_back/mask_rcnn_r50_fpn_rsb-pretrain_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/resnet_strikes_back/mask_rcnn_r50_fpn_rsb-pretrain_1x_coco/mask_rcnn_r50_fpn_rsb-pretrain_1x_coco_20220113_174054-06ce8ba0.pth | |
| Cascade Mask R-CNN | 2-Stage | R-50 (RSB) | CNN | FPN | 1x | 6.2GB | Executable | 0.448 | 0.575 | 0.267 | 0.483 | 0.598 | https://colab.research.google.com/drive/1W9MUoQI212ctwwrAn6HeIVKyG6pj03Il?usp=sharing | configs/resnet_strikes_back/cascade_mask_rcnn_r50_fpn_rsb-pretrain_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/resnet_strikes_back/cascade_mask_rcnn_r50_fpn_rsb-pretrain_1x_coco/cascade_mask_rcnn_r50_fpn_rsb-pretrain_1x_coco_20220113_193636-8b9ad50f.pth | |
| Faster R-CNN | 2-Stage | ResNeSt-50 | CNN | FPN | 1x | 4.8GB | Executable | 0.42 | 0.557 | 0.267 | 0.459 | 0.535 | https://colab.research.google.com/drive/1hUmImLvvKOe4e3odyqs2Q52bgbksDQ5p?usp=sharing | configs/resnest/faster_rcnn_s50_fpn_syncbn-backbone+head_mstrain-range_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/resnest/faster_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco/faster_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco_20200926_125502-20289c16.pth | |
| Faster R-CNN | 2-Stage | ResNeSt-101 | CNN | FPN | 1x | 7.1GB | Executable | 0.445 | 0.573 | 0.287 | 0.486 | 0.573 | https://colab.research.google.com/drive/1hUmImLvvKOe4e3odyqs2Q52bgbksDQ5p?usp=sharing | configs/resnest/faster_rcnn_s101_fpn_syncbn-backbone+head_mstrain-range_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/resnest/faster_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco/faster_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco_20201006_021058-421517f1.pth | |
| Mask R-CNN | 2-Stage | ResNeSt-101 | CNN | FPN | 1x | 7.8GB | Executable | 0.452 | 0.582 | 0.29 | 0.489 | 0.584 | https://colab.research.google.com/drive/1hUmImLvvKOe4e3odyqs2Q52bgbksDQ5p?usp=sharing | configs/resnest/mask_rcnn_s101_fpn_syncbn-backbone+head_mstrain_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/resnest/mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco/mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco_20201005_215831-af60cdf9.pth | |
| Cascade Mask R-CNN | 2-Stage | ResNeSt-101 | CNN | FPN | 1x | 10.5GB | Executable | 0.477 | 0.603 | 0.301 | 0.518 | 0.614 | https://colab.research.google.com/drive/1hUmImLvvKOe4e3odyqs2Q52bgbksDQ5p?usp=sharing | configs/resnest/cascade_mask_rcnn_s101_fpn_syncbn-backbone+head_mstrain_1x_coco.py | https://download.openmmlab.com/mmdetection/v2.0/resnest/cascade_mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco/cascade_mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco_20201005_113243-42607475.pth | |
*Our code for each row can be found in the links in the “MyCode/Results” section.
*For performance breakdown on specific object categories, please also refer to the links in the “MyCode/Results” column.
*In the “config” and “model_url” sections, we have collected the respective paths for each of the models we tested, so it would be easier for readers to reproduce our results.
*FPN for Feature Pyramid Network
*PVT for Pyramid Vision Transformers
*RSB for ResNet Strikes Back
5.2 Results Analysis
Among all the small to medium sized prediction models (memory usage under 20GB), the highest performing model uses the SWIN-Small backbone and the Mask-RCNN detection head. This is consistent with the current COCO-2017 leaderboard on https://paperswithcode.com/sota/object-detection-on-coco where 9 out of the top 10 models utilize some form of the SWIN-Large backbone.
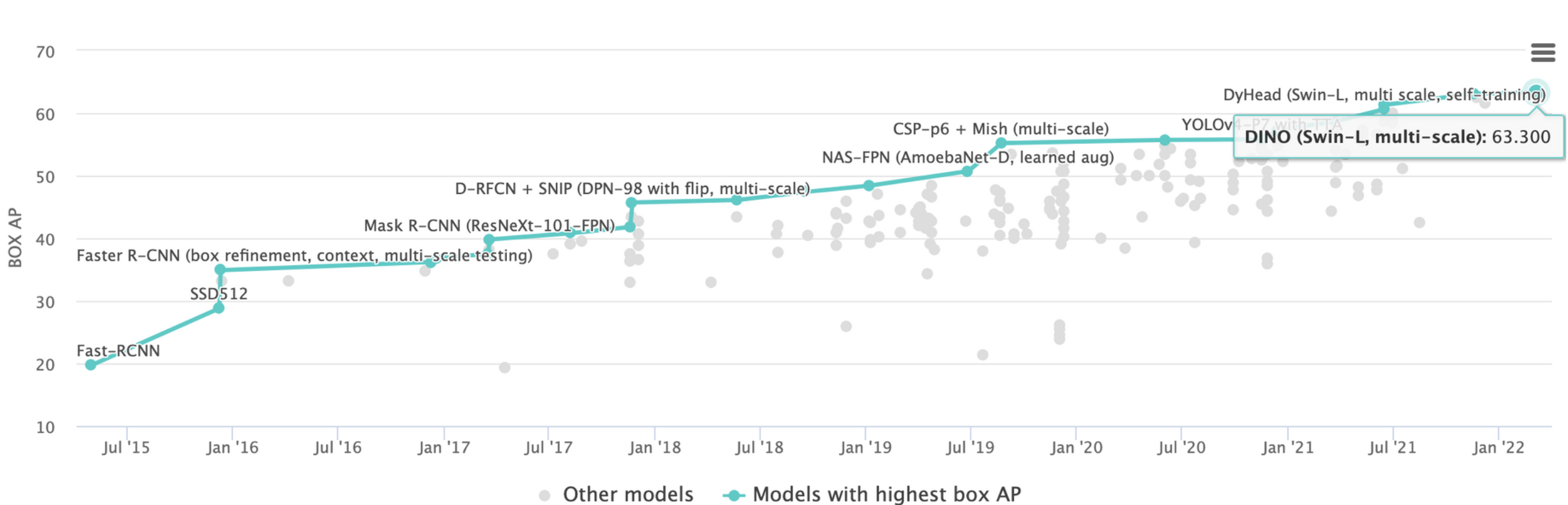
Fig 0. COCO-2017 object detection task leaderboard (updated 03/05/2022).
We observe that our current detection models obtain much lower mAP on detecting Small Objects compared to Large and Medium Objects. While most modern detection models can reach 50-60 percent accuracy on Large Objects, their accuracy on Small Objects stagnates at around 20-30 percent.
| Object Groups by Size | Small Objects | Medium Objects | Large Objects |
|---|---|---|---|
| Average mAP over all Models | 0.25021 | 0.45029 | 0.54533 |
Given example of the above-mentioned SWIN-S model(0.482-mAP), we can see that while it can predict large objects with 0.627% accuracy, it only achieves 0.321% accuracy on small objects. If we look more closely at the performance breakdown by object category, we can see that detection performance varies hugely between large objects like “airplane (0.728%)”, “bus (0.716%)” and small objects like “hair drier (0.110%)” and “traffic light (0.311%)”.
| category | AP | category | AP | category | AP |
|---|---|---|---|---|---|
| person | 0.583 | bicycle | 0.380 | car | 0.497 |
| motorcycle | 0.501 | airplane | 0.728 | bus | 0.716 |
| train | 0.708 | truck | 0.423 | boat | 0.333 |
| traffic light | 0.311 | fire hydrant | 0.734 | stop sign | 0.679 |
| parking meter | 0.532 | bench | 0.322 | bird | 0.409 |
| cat | 0.726 | dog | 0.692 | horse | 0.646 |
| sheep | 0.574 | cow | 0.623 | elephant | 0.677 |
| bear | 0.764 | zebra | 0.691 | giraffe | 0.697 |
| backpack | 0.232 | umbrella | 0.456 | handbag | 0.241 |
| tie | 0.382 | suitcase | 0.478 | frisbee | 0.710 |
| skis | 0.313 | snowboard | 0.453 | sports ball | 0.478 |
| kite | 0.464 | baseball bat | 0.394 | baseball glove | 0.431 |
| skateboard | 0.608 | surfboard | 0.458 | tennis racket | 0.569 |
| bottle | 0.444 | wine glass | 0.410 | cup | 0.490 |
| fork | 0.459 | knife | 0.307 | spoon | 0.302 |
| bowl | 0.466 | banana | 0.315 | apple | 0.260 |
| sandwich | 0.445 | orange | 0.365 | broccoli | 0.272 |
| carrot | 0.255 | hot dog | 0.436 | pizza | 0.558 |
| donut | 0.539 | cake | 0.453 | chair | 0.364 |
| couch | 0.509 | potted plant | 0.364 | bed | 0.495 |
| dining table | 0.307 | toilet | 0.668 | tv | 0.630 |
| laptop | 0.678 | mouse | 0.652 | remote | 0.432 |
| keyboard | 0.543 | cell phone | 0.415 | microwave | 0.629 |
| oven | 0.392 | toaster | 0.402 | sink | 0.418 |
| refrigerator | 0.645 | book | 0.194 | clock | 0.540 |
| vase | 0.408 | scissors | 0.453 | teddy bear | 0.528 |
| hair drier | 0.110 | toothbrush | 0.384 | None | None |
Similar results can be observed for a state of the art CNN-Based ResNeSt-101 model with comparable overall performance(0.477-mAP): “0.614-Large Objects”, “0.301-Small Objects”, “airplane (0.725%)“, “bus (0.710%) ”, “hair drier (0.065%) ”, “traffic light (0.314%)“. Thus we have reason to believe the both CNN and Transformer architectures suffer from small object detection.
| category | AP | category | AP | category | AP |
|---|---|---|---|---|---|
| person | 0.602 | bicycle | 0.364 | car | 0.510 |
| motorcycle | 0.491 | airplane | 0.725 | bus | 0.710 |
| train | 0.701 | truck | 0.403 | boat | 0.330 |
| traffic light | 0.314 | fire hydrant | 0.727 | stop sign | 0.700 |
| parking meter | 0.502 | bench | 0.297 | bird | 0.409 |
| cat | 0.754 | dog | 0.694 | horse | 0.625 |
| sheep | 0.588 | cow | 0.615 | elephant | 0.697 |
| bear | 0.763 | zebra | 0.725 | giraffe | 0.725 |
| backpack | 0.200 | umbrella | 0.478 | handbag | 0.203 |
| tie | 0.419 | suitcase | 0.458 | frisbee | 0.731 |
| skis | 0.304 | snowboard | 0.486 | sports ball | 0.508 |
| kite | 0.477 | baseball bat | 0.390 | baseball glove | 0.457 |
| skateboard | 0.620 | surfboard | 0.464 | tennis racket | 0.577 |
| bottle | 0.456 | wine glass | 0.421 | cup | 0.486 |
| fork | 0.436 | knife | 0.288 | spoon | 0.249 |
| bowl | 0.466 | banana | 0.292 | apple | 0.253 |
| sandwich | 0.404 | orange | 0.313 | broccoli | 0.267 |
| carrot | 0.270 | hot dog | 0.423 | pizza | 0.570 |
| donut | 0.550 | cake | 0.423 | chair | 0.347 |
| couch | 0.476 | potted plant | 0.321 | bed | 0.493 |
| dining table | 0.324 | toilet | 0.649 | tv | 0.616 |
| laptop | 0.662 | mouse | 0.647 | remote | 0.439 |
| keyboard | 0.566 | cell phone | 0.419 | microwave | 0.606 |
| oven | 0.396 | toaster | 0.340 | sink | 0.412 |
| refrigerator | 0.662 | book | 0.203 | clock | 0.557 |
| vase | 0.414 | scissors | 0.384 | teddy bear | 0.543 |
| hair drier | 0.065 | toothbrush | 0.349 | None | None |
5.3 Current SOTA – SWIN Transformers
Based on our experiments, The SWIN Transformers model currently outperforms CNN models in the object detection task. From on our understanding of the SWIN Transformers paper[1], here we provide a short analysis of SWIN Transformers and why they can outperform CNNs in the Object Detection Task.
Different from the traditional CNN-based architecture, the SWIN Backbone incorporated the Encoder-Decoder structure of Natural Language Transformers into computer vision tasks. Using shifted-windows architecture, SWIN Transformers are able to compute self-attention with great efficiency while also allowing for cross-window connections. Thus, its computational complexity growth can be retained at linear instead of squared with respect to the image size when we do a global attention. The shifted windows can ensure that when we do local self-attention computation, we still consider different parts of the image interactively, similar to the effects of traditional convolutional layers.
6. Photo/Video Demo and Error Analysis
6.1 Building a MMDetection image/video detector
Here’s our code for building a Mask-RCNN + ResNet-50 image detector with MMDetection:
!mkdir checkpoints
!wget -c https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth \
-O checkpoints/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth
from mmdet.apis import inference_detector, init_detector, show_result_pyplot
# Choose to use a config and initialize the detector
config = 'configs/mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco.py'
# Setup a checkpoint file to load
checkpoint = 'checkpoints/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth'
# initialize the detector
model = init_detector(config, checkpoint, device='cuda:0')
import matplotlib.pyplot as plt
import mmcv
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
# Use the detector to do inference
img = mmcv.imread('demo/demo.jpg')
plt.figure(figsize=(15, 10))
plt.imshow(mmcv.bgr2rgb(img))
6.2 Image/Video detection experiments and analysis
Experiment 1: NBA Game image
Fig 1. Experiment 1: NBA Game image.
For this NBA image, which is very crowded with person(s). Many person(s) are detected with high score, but also many person(s) are detected with very low score, which shows a low degree of confidence. Many person(s) are not detected.
Experiment 2: Ackerman Union image

Fig 2. Experiment 2: Ackerman Union image.
This result is very good, almost correctly identified every instance, such as “person” and “TV”.
Experiment 3: Social Event Image

Fig 3. Experiment 3: Social Event Image.
Very good results, “cup”, “table”, “fork”, “knife”, “cell phone”, “wine glass”, “bottle”, “couch” are perfectly identified with greater than 0.5 score.
Experiment 4: UCLA Health image

Fig 4. Experiment 4: UCLA Health image.
“traffic light”, car(s), person(s) are correctly identified, pretty good. Other objects such as “tree”s and “street light”s are not identified.
Experiment 5: Concert image

Fig 5. Experiment 5: Concert image.
closer person(s) are identified, but person(s) far away blended with colorful lights are not identified. A human observer can identify those are person(s) due to the semantic background of a concert, but this algorithm cannot do that, it is still mainly depending on pixel-wise image patterns. Also, something on the ceiling is seen as bicycles, which are mistakes, again proving the algorithm is based on shapes and patterns, not meaning and syntax.
Experiment 6: Kitchen Video
We also tested on our own video examples. The algorithm deals with data in .mp4 format. The video is transformed into gif for presentation purpose.

Fig 6. Experiment 6: Kitchen table GIF.
Experiment 7: Street View Video

Fig 7. Experiment 7: result_streets.gif.
Experiment 8: Bruinwalk Video

Fig 8. Experiment 8: bruinwalk1.gif.
Videos Error Analysis
On Bruinwalk, the algorithm has very high accuracy, it is able to recognize persons, trucks, umbrellas, fire hydrants. Interestingly, it mistakenly sees the bruin bear statue as an elephant. Also, it mistakenly sees a banner on the ground as a parking meter. It mistakenly sees an advertising image on the banner as a book, probably because it looks like a book’s cover. Another interesting discovery is that the algorithm recognizes a tree’s mirror image in a building’s window as a [potted plant], it even can detect mirror images! it at an instant mistakenly sees a gap in the tree’s leaves as a car. it mistakenly sees a four-footed banner as a chair. it mistakenly sees a four-footed banner as a chair. it mistakenly sees a handrail of a stair as an airplane. In the Rochester-Midvale street view video, it correctly identifies many potted plants and cars. However, it frequently identifies some gaps in the tree leaves as elephants or horses. In the cooking video, it correclt identifies many bowls, a sink, and carrots, but it mistakenly sees some bowls as clocks or vases, probably due to the shape of these bowls are indeed artistic in a sense. It sees an orange-colored plate as an orange mistakenly. It sees a plate as a frisbee mistakenly. It sees romain hearts as broccoli mistakenly. It sees a pot as a bird mistakenly, very strange. It mistakenly sees a bottled soy sauce and a bottled olive oil as wines. Indeed it’s a hard topic to teach algorithms distinguishing which bottle is soyce sauce, which bottle is wine, oil, vinegar, it does not have taste! It mistakenly sees a pot with a glass lid as a wine glass.
In conclusion, the mistakes made are all reasonable because of the similarity in shape between the object represented by the true label and the object represented by the wrong label, especially given the 2D image or video. The reaction rate of the algorithm is much faster than humans. Given the variety and the large number of objects in the video and such a high speed to change the perspective, a human watcher of the video cannot detect all details, but the algorithm is able to detect almost every small tiny object on the very edge of the image that does not draw a human’s attention.
7. Adversarial Attacks and Error Analysis
7.1 Adversiarial Attacks on the Mask_RCNN + ResNet-50 Image Detector
# Draw a Rectangle in
image = np.zeros((512,512,3), np.uint8)
cv2.rectangle(img, (310,220), (360,270), (0,0,0), -1)
cv2_imshow(img)
cv2.waitKey(0)
cv2.destroyAllWindows()
plt.show()
result = inference_detector(model, img)
# Let's plot the result
show_result_pyplot(model, img, result, score_thr=0.3)
Experiment 1:
cv2.rectangle(img, (310,220), (360,270), (0,0,0), -1)

Fig 9. Black patches Experiment 1.
Experiment 2:
cv2.rectangle(img, (100,100), (300,250), (127,50,127), -1)

Fig 10. Black patches Experiment 2.
Experiment 3:
cv2.rectangle(img, (300,220), (380,270), (0,0,0), -1)

Fig 11. Black patches Experiment 3.
Experiment 4:
cv2.rectangle(img, (280,200), (400,300), (0,0,0), -1)

Fig 12. Black patches Experiment 4.
Experiment 5:
cv2.rectangle(img, (260,190), (410,320), (0,0,0), -1)

Fig 13. Black patches Experiment 5.
Experiment 6:
experiment using our living room’s picture, the little black patch at the top left corner does not catch attention of the algorithm.

Fig 14. Black patches Experiment 6.
Experiment 7:
cv2.rectangle(img, (700,800), (1000,1000), (0,0,0), -1)

Fig 15. Black patches Experiment 7.
network is fooled to recognize our black patch as a “TV” with score = 0.63
Experiment 8: bruinwalk image

Fig 16. Black patches Experiment 8: bruinwalk image.
bear, person, and bags are identified correctly.
Experiment 9: bruinwalk images with a black patch

Fig 17. Black patches Experiment 9: bruinwalk image.
bear, person, and bags are identified correctly. The black patch makes the algorithm thinks the bear is an elephant. The algorithm is influenced by the black patch.
7.2 Mask_RCNN + ResNet-50 Experiments Analysis
Static images
The detection algorithm works well on the demo image provided by the MMdetection itself with high accuracy and low error rates. If we set the score threshold to be 0.5, i.e. only display the objects for which the score given to objects category larger than 0.5, we can almost get every object with correct bounding boxes and class labels.
For the customized image, which is not provided by MMDetection but by us, i.e. the living room image, it makes more mistakes. For example, it misrecognize an [orange] to be an [apple]. Also, the [vinyl CDs] are misrecognized as [books]. Probably it is due to the side view of the CDs are indeed very similar to books, and the orange from such a far away point of view looks indeed indistinguishable from an apple, and they are both very likely to placed in plates on the living room table. The mistakes are understandable since a human may even make such misrecognitions given this specific image. The black patches on our customized image, when small, even does not draw attention from the algorithm–it does not give a bounding box, which means it does not assume it to be an object. When the black patch becomes large, the algorithm misrecognizes it as a TV, which is very interesting. This recognition makes very much sense, since a black squared-shape object in side a living room is indeed very likely to be a TV. Although the algorithm is fooled, I think this TV misrecognition, on the contrary, proves the wisdom of the model in a sense.
Images with black patch attacks
For black patches interference experiments, if the black patch is small compared to the size of the object, the detection algorithm is little affected. It still gives correct bounding box and class labels with as high scores as 1.00. However, when the black patch grows in size to about half the size of the object, and blurs certain significant edges and shapes of the object, like in experiment 4 and 5, the algorithm will be fooled.
7.3 Comparison with Mask_RCNN + SWIN Transformers
Since in section 5.2, we observed that among all the small to medium sized prediction models (memory usage under 20GB), the highest performing model uses the SWIN-S backbone combined with the Mask-RCNN detection head, thus is the current SOTA. We replicate our previous experiments but this time equip the detector with the SWIN-S backbone, hoping to potentially see some observable improvements:
!mkdir checkpoints
!wget -c https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco_20210903_104808-b92c91f1.pth \
-O checkpoints/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco_20210903_104808-b92c91f1.pth
from mmdet.apis import inference_detector, init_detector, show_result_pyplot
# Choose to use a config and initialize the detector
config = 'configs/swin/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco.py'
# Setup a checkpoint file to load
checkpoint = 'checkpoints/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco_20210903_104808-b92c91f1.pth'
# initialize the detector
model = init_detector(config, checkpoint, device='cuda:0')
import matplotlib.pyplot as plt
import mmcv
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
# Use the detector to do inference
img = mmcv.imread('demo/demo.jpg')
plt.figure(figsize=(15, 10))
plt.imshow(mmcv.bgr2rgb(img))
# print(img.shape) #(427, 640, 3)
# Draw a Rectangle in
image = np.zeros((512,512,3), np.uint8)
# cv2.rectangle(image, (100,100), (300,250), (127,50,127), -1)
cv2.rectangle(img, (310,220), (360,270), (0,0,0), -1)
cv2_imshow(img)
cv2.waitKey(0)
cv2.destroyAllWindows()
plt.show()
result = inference_detector(model, img)
# Let's plot the result
show_result_pyplot(model, img, result, score_thr=0.3)
To perform object detection on videos with SWIN-S, we specify the following in Colab:
!python demo/video_demo.py demo/cooking.mp4 \
configs/swin/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco.py \
checkpoints/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco_20210903_104808-b92c91f1.pth \
--out swin_result_cooking.mp4
Experiment 10: Ackerman Union Image SWIN-S

Fig 18. Experiment 10: ackerman_swin.png.
Experiment 11: Social Event Image SWIN-S

Fig 19. Experiment 11: birthday_swin.png.
Experiment 12: Concert Image SWIN-S

Fig 20. Experiment 12: concert_swin.png.
Experiment 13: Restaurant Table Image SWIN-S

Fig 21. Experiment 13: eating_swin.png.
Experiment 14: NBA Game Image SWIN-S
Fig 22. Experiment 14: nba_swin.png.
Experiment 15: UCLA Health Image SWIN-S

Fig 23. Experiment 15: uclahealth_swin.png.
The static images results are almost the same as the outputs of Mask_RCNN + ResNet50 detector. Next, we look at videos result detected by our Mask R-CNN framework with a SWIN-S backbone:
Experiment 16: Streets Video SWIN-S
Video 2. Experiment 16: Streets Video SWIN-S.
Experiment 17: Cooking Video SWIN-S
Video 3. Experiment 17: Cooking Video SWIN-S.
Experiment 18: Bruinwalk Video_1 SWIN-S
Video 4. Experiment 18: Bruinwalk Video_1 SWIN-S.
Experiment 19: Bruinwalk Video_2 SWIN-S
Video 5. Experiment 19: Bruinwalk Video_2 SWIN-S.
Experiment 20: Bruinwalk Video_3 SWIN-S
Video 6. Experiment 20: Bruinwalk Video_3 SWIN-S.
For the streets view video, the Mask-RCNN + SWIN-S detector finds an additional stop sign that is not detected by the Mask-RCNN + ResNet-50, but it also wrongly labeled a non-existent umbrella at the end of the video. For other video results, we find no significant difference from Mask-RCNN + ResNet-50.
Although the Swin Transformer is recognized as the state-of-the-art model in computer vision for many tasks, the results of our experiment show little observable difference from the outputs of ResNet-50 – the former state-of-the-art that came out a few years before. This may be an evidence to suggest that in terms of mAP increase, the Object Detection task is indeed stagnating.
Furthermore, in terms of robustness against adversiarial attacks, both models suffer dramaticly from simple black-patch attacks on the real-world images and videos we took in common day-to-day settings. This result demonstrates the vulnerability of current Object Detection models against potential disturbances and human sabotage, highlighting the need to increase adversiarial robustness of such algorithms in real-world applications.
8. Demo Links
For links to our code and Colab demo, please refer to here and here.
For link to the Colored Interactive Framework/Backbone Results Table where you can sort and group_by different labels, please refer to here.
For our recorded spotlight video, please refer to here
Reference
[1] Liu, Ze, et al. “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows.” Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2021.
[2] Wang, Wenhai, et al. “Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions.” Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2021.
[3] He et al. “Deep Residual Learning for Image Recognition.” IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016.
[4] Wang et al. “Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions.” Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2021.
[5] Wang et al. “Pvtv2: Improved baselines with pyramid vision transformer.” arXiv preprint arXiv:2106.13797. 2021.
[6] Zhang, Hang, et al. “ResNeSt: Split-Attention Networks.” arXiv preprint arXiv:2004.08955. 2021.
[7] Gao, Shang-Hua, et al. “Res2Net: A New Multi-Scale Backbone Architecture.” Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI). 2021.
[8] Chen, Kai, et al. “MMDetection: Open MMLab Detection Toolbox and Benchmark. “ arXiv preprint arXiv:1906.07155. 2019.