Action Localization
Final Report
Action Localization for Emergency Detection
(Portions of) the research in this paper used the NTU RGB+D (or NTU RGB+D 120) Action Recognition Dataset made available by the ROSE Lab at the Nanyang Technological University, Singapore.
Table of Contents
Abstract
A brief description of what you did in the project and the results observed.
In this project, we wanted to achieve action localization that works well with emergency situations such as medical emergency or robbery. To accomplish the goal, we compared two ST-GCN models that has difference of existence of transformers. We compared the ST-GCN and ST-GCN+transformer model’s performance on THUMOS14 dataset to observe the difference transformers make in regular action localization. Afterwards, we used NTU RGB+D dataset on ST-GCN model to be able to infer ST-GCN+transformer model’s performance based on the statistics we computed. We came to a conclusion that use of transformers improves the performance of the model.
Introduction
introduce the task you are working on, e.g. semantic segmentation, and image generation, and what is the project goal or your hypotheses.
Action Localization
Temporal Action Localization detects and identifies actions within a video and provides the timestamps of the actions. Our aim of the project was not to simply recognize the actions but to observe the performance of the model in emergency situations. If a model can properly recognize emergency situations fast, there will be no delay in responding to the situation. For example, if there is model specialized at recognizing medical emergency constantly observing security cameras, it will call 911 faster than anyone if someone collapses on the ground due to seizure. Thus, we want the action localization models that can perform recognizing and classifying emergency situations well. Action localization focuses on 18 key points to accurately identify human actions. The 18 key points are: nose, left eye, right eye, left ear, right ear, left shoulder, right shoulder, left elbow, right elbow, left wrist, right wrist, left hip, right hip, left knee, right knee, left ankle, right ankle, and neck. Below, Figure 1 portrays the visualization of 18 keypoints (17 exactly in the picture as it does not show the neck).
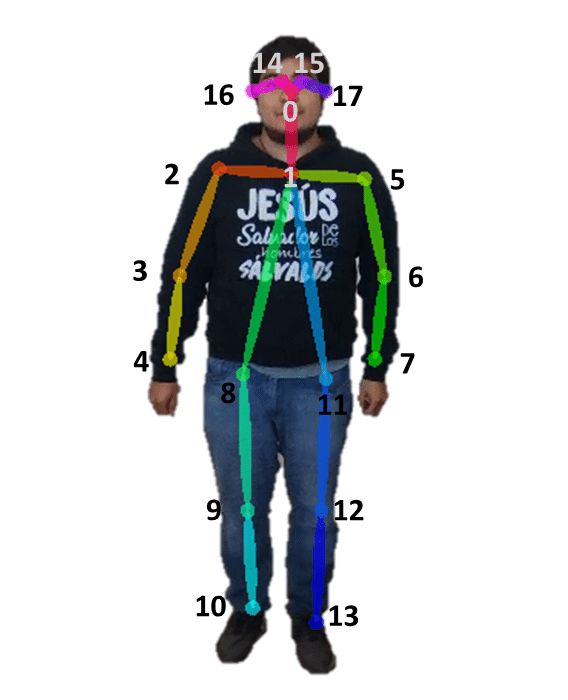
Figure 1: 17 keypoints of human body
Method
What is the model your used/modified/designed?
Datasets
We obtained the dataset by requesting NTU RGB+D dataset from Rapid-Rich Object Search (ROSE) Lab in Singapore [3]. The dataset contains 114,480 video samples and 120 classes of various actions:punching, wielding a knife, shooting a gun, falling down, staggering, etc. We’ll filter the dataset to extract class examples that fit our needs of identifying medical emergencies and hostile behavior such as those listed above. The dataset contains video samples with multiple filters: RGB, depth maps, 3D skeletal data, and infrared (IR) videos which we can use use to train a robust model that has some invariance to video quality. Since the original dataset exceeds 2 TB, we requested a subset of the dataset around 15 GB. The dataset we received contains following actions: hopping, punch/slap, kicking, pushing, hit with object, wield knife, knock over, shoot with gun. The action “hopping” was sent by the mistake on the Lab’s side; however, we decided to use it for the possible noise to keep the dataset from consisting only of emergency situations. We also used THUMOS14 dataset obtained from [4], and it contains 20 classes and 16 frame videos. It has classes like baseball pitch, basketball dunk, billiards, cliff diving, diving, golf swinging, etc. We use about 413 videos obtained from THUMOS14 dataset.
Models
The NTU RGB+D dataset was originally trained and tested on the spatial temporal graph convolutional networks (ST-GCN) model. As the name suggests, the model has features that can record both spatial configuration and the temporal dynamics of the joints to fully understand the human body communication using the convolutional neural networks (CNN). ST-GCN takes joint coordinate vectors as inputs, apply spatial-temporal graph convlolution operations throughout the layers, and apply SoftMax at the end to obtain action category value. Inputs are gained from the dataset, which already constructed a spatial temporal graphs from the given videos of human actions using pose estimation. Operations that are applied thorughout the network includes sampling function, weight function, Spatial Graph Convolution equations, and Spatial Temporal Modeling equations. All details as to what exactly the functions and operations are well-described in [1]. Below, Figure 2 is an image that portrays the overview of the pipeline of the model.
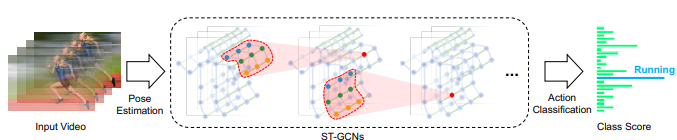
Figure 2: pipeline of ST-GCN
The model we will use is not just ST-GCN as we want to compare the performance to other models in order to observe and analyze the difference in performance between models. Thus, we train the NTU RGB+D dataset with the model ActionFormer. ActionFormer uses ST-GCN with transformers for temporal action localization that bases on 3 important steps: feature extraction, feature fusion, action localization with ActionFormer [5]. Feature extraction uses SlowFast’s and Omnivore’s features without finetuning along with EgoVLP’s pretrained weights. Feature fusion uses linear projections in order to decrease feature dimensions before ActionFormer operates on it. It reduces dimensions of the features and concatnates it. The ActionFormer consists of 6-level feature pyramid with transformers that has 16 attention heads layers. Below, Figure 3 is an image to portray the overview of ActionFormer.
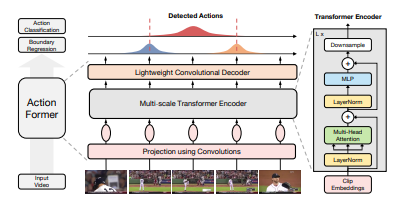
Figure 3: pipeline of ActionFormer
Transformer
Transformers are the type of neural network architecture that utilizes self-attention mechanism. The mechanism allows the network to selectively focus on different parts of the input sequence. One main benefit of transformers is that it processes input sequence in parallel manner unlike Recurrent Neural Networks (RNNs), so the computation is very fast and efficient. Moreover, the model can weigh the significance of the input element by measuring attention scores. Transformers calculate attention scores in 4 main steps. First, it generates query, key, and value matrices. Second, it takes dot product of query and key vector to generate vectors of scores. The vector represents how relevant the element is to the query vector. Third, it runs softmax normalization to the vector to make it a probability distribution vector. Finall,y it multiplies the probability distribution with value vector to get weighted sum of the input sequence which is the attention score. Through the attention score calculations, transformers can detect which element is more significant over others. Normally, transformers are more specialized in tasks like text classifications, but it can also be used for object detection and action localization also. Below, Figure 4 shows the overall structure of transformers and Figure 5 shows attention score calculation.
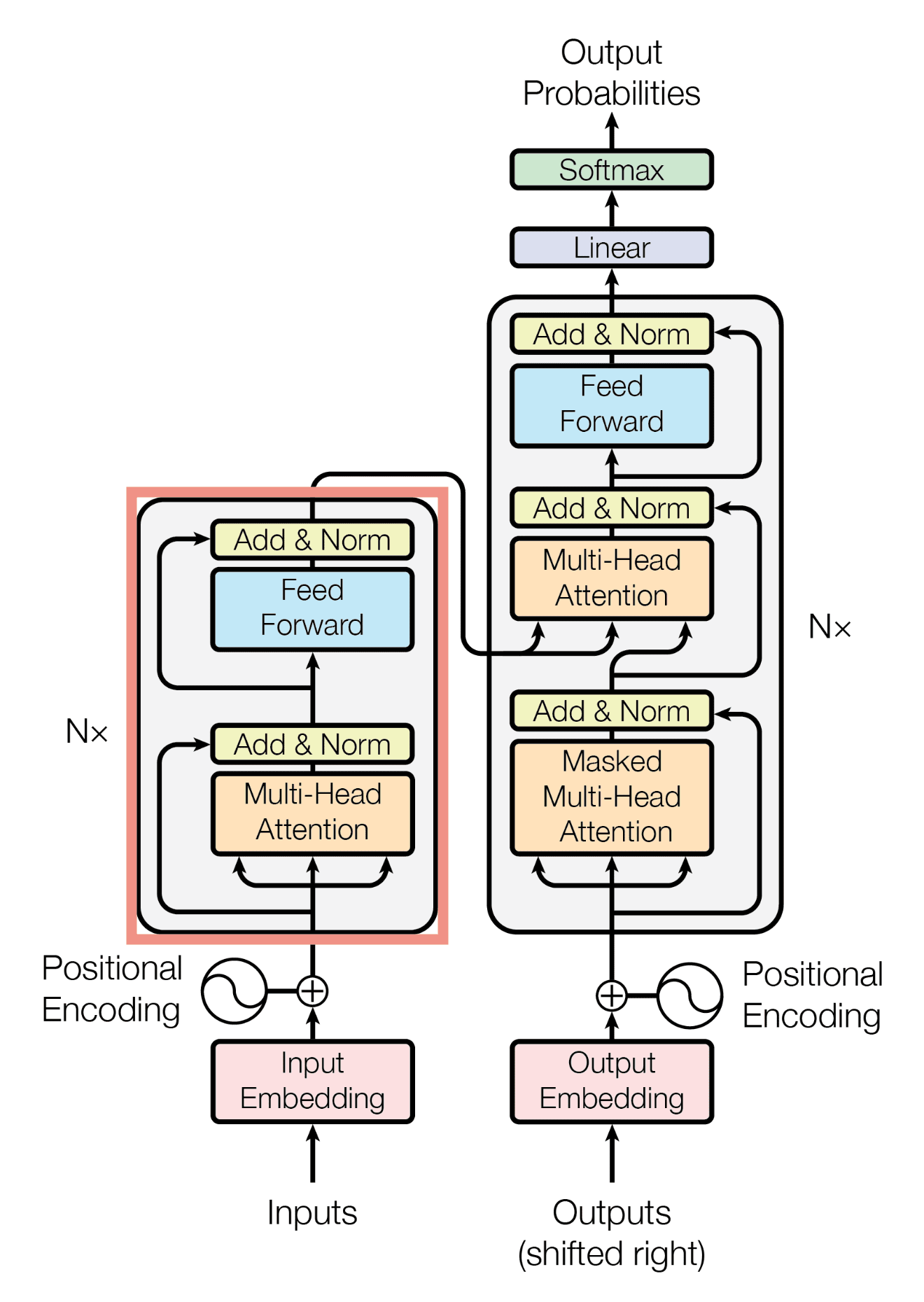
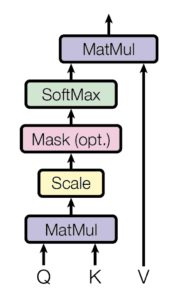
Plan
To compare the models performance, we will run both models through THUMOS14 dataset. After observing the performances, we will use it to infer the performance of ActionFormer on NTU RGB+D dataset. We cannot use the NTU RGB+D dataset on ActionFormer directly due to its difference in data structure. Thus, we compared models’ differences with THUMOS14 dataset as it contains all random actions, so we can infer what ActionFormer will perform on NTU-RGB+D dataset which contains only videos of emergency situations.
Results
Evaluation metrics
The provided annotations for the ST-GCN model in the NTU-RGB+D 130 dataset include (x,y,z) coordinate values for each of the 18 joints in the skeletal outline and each clip is guaranteed to have at most 2 actors. The authors of the dataset recommended 2 different evaluation benchmarks: cross-subject and cross-view. Cross-subject is where training clips come from one subset of actors and evaluation is done on the other actors. Cross-view is where training clips come from camera views 2 and 3 while evaluation is done on camera view 1. Moreover, the accuracy is measured in top 1 and top 5 where top 1 measures if the top 1 classes predicted is the correct class and top 5 measures if the top 5 classes predicted contains the correct class.
Moreover, ActionFormer measures different from ST-GCN. It instead uses mean Average Precision (mAP) to display the accuracy. mAP takes both precision and recall into account when it is calculting. Precision is an accuracy of positive predictions and recall is measurement of the completeness of the positive predictions. mAP is mean of APs and AP is calculated by area under the precision-recall curve. Higher mAP indicates better performance of the model.
Results
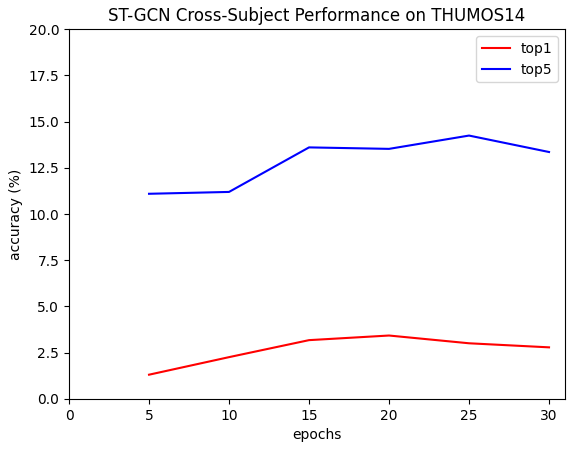
ST-GCN THUMOS14 cross-subject:
Trained with epoch= 30, learning rate=0.1, batch size=16, number of classes=8 Top 1 accuracy: 2.78% Top 5 accuracy: 49.96%
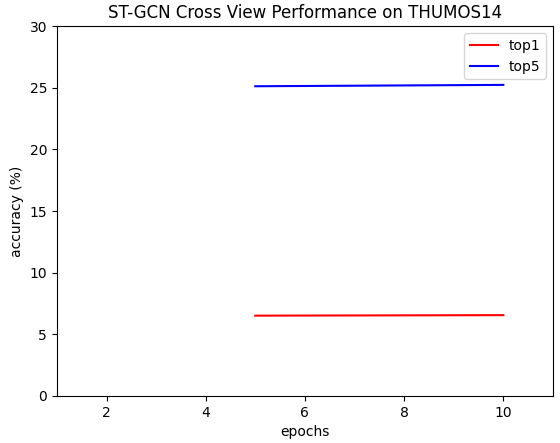
ST-GCN THUMOS14 cross view:
Trained with epoch=10, learning rate=0.1, batch size=16, number of classes=8 Top 1 accuracy: 6.54% Top 5 accuracy: 54.52%
ActionFormer THUMOS14:
Trained with epoch=30, learning rate=0.1, batch size=16, number of classes=20
| Method (IoU) | .1 | .3 | .5 | .6 | .7 | Avg |
|---|---|---|---|---|---|---|
| mAP | 58% | 31% | 13% | 5% | 2% | 22% |
Average mAP = 22%
Highest mAP = 58%
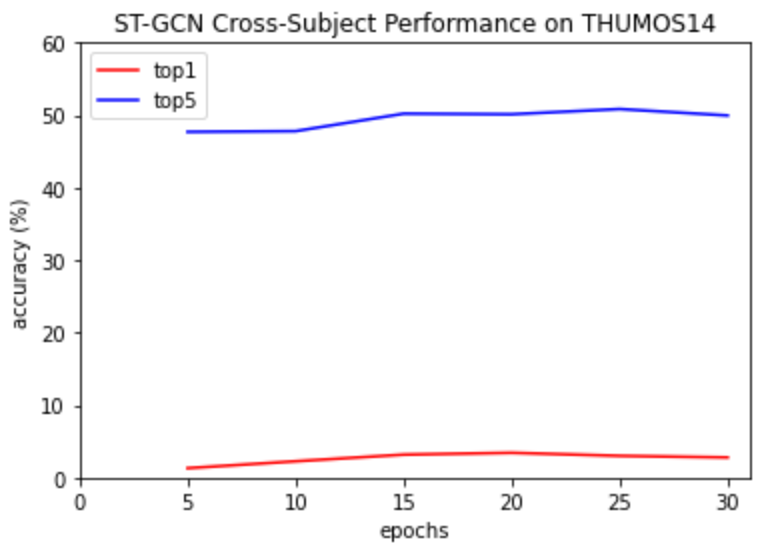
ST-GCN NTU-RGB+D cross-subject:
Trained with epoch= 30, learning rate=0.1, batch size=16, number of classes=8 Top 1 accuracy: 5.89% Top 5 accuracy: 56.04%
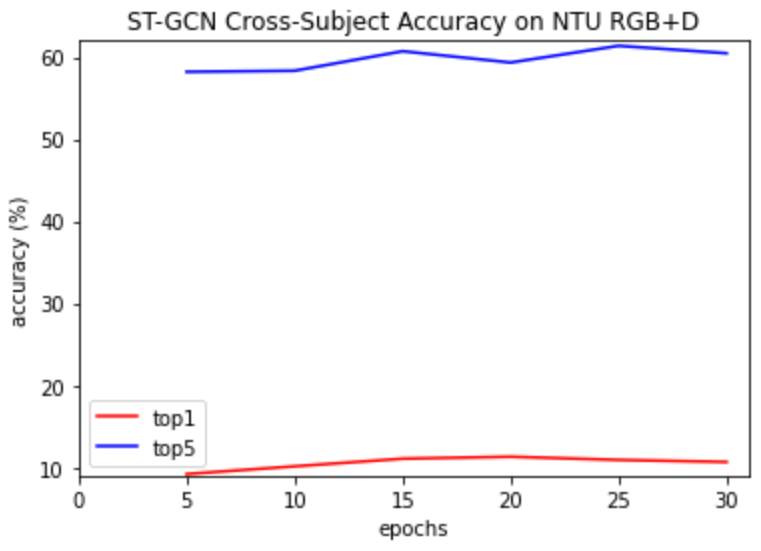
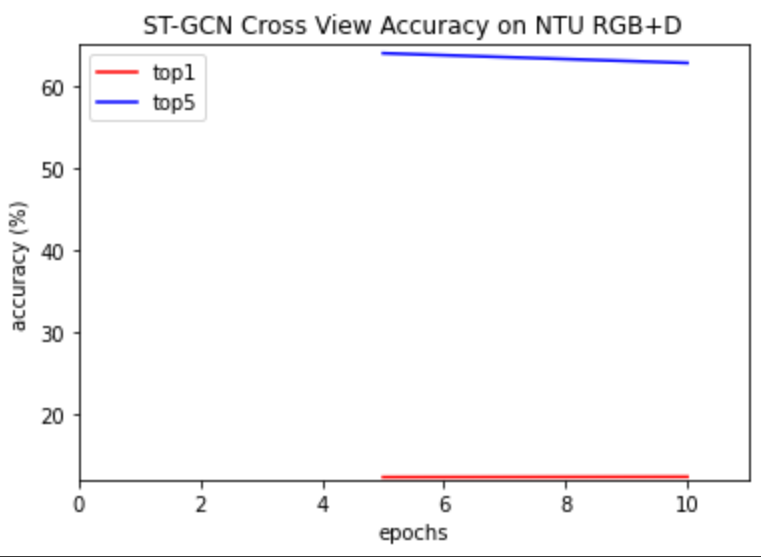
ST-GCN NTU-RGB+D cross view:
Trained with epoch=10, learning rate=0.1, batch size=16, number of classes=8 Top 1 accuracy: 12.34% Top 5 accuracy: 62.78%
Discussion
This should be the most important part of this report. You can discuss insights from your project, e.g., what resulted in a good performance, and verified/unverified hypotheses for why this might be the case. Explain the ablation studies you run and the observations. Some visualization could help!
ActionFormer had higher accuracy than ST-GCN on THUMOS14 dataset. We can infer the difference in the performance is due to severa reasons. First, ST-GCN is mainly trained to look for only 2 actors while ActionFormer was not. Thus, it can misclassify the action due to wrong selection of the actors in the video as THUMOS14 has more than 2 actors in the video performing actions. Second, the existence of the transformer is what we believe to be the main reason. Transformers are able to model long-term temporal dependencies, so it could have been easier for the model to classify the action based on the history. Moreover, transformers can do feature representation to the frames of the video, which leads to model focusing onto the relevant frames of the video that performs an action. Although not measured with numeric values, ActionFormer computed a lot faster than ST-GCN as transformers can parallel compute; thus, it is more efficient too. As for NTU-RGB+D dataset, ST-GCN showed improvement in both top 1 and top 5 accuracies. NTU-RGB+D dataset provided skeletons for the actions while THUMOS has to extract data and use other models available to create skeletons; thus, there can be a discrepancy in the generation and accuracy of the skeleton of human body within a video itself. Moreover, there are many instances in THUMOS14 dataset that had the subject filmed too close to the camera or very far from the camera, which can result in inaccurate skeleton datas as the camera cannot contain all 18 keypoints within a frame or they are sll clumped together as the subject is too small. NTU-RGB+D dataset also has a low variance for its distribution as all the videos consists fo 2 actors in a isolated room with only the intended actions recorded. THUMOS14 dataset, on the other hand, contained some noises within the videos (such as various objects, people, backgrounds, etc). Therefore, it is reasonable that ST-GCN performed better in the NTU-RGB+D dataset compared to THUMOS14 dataset. As mentioned in previous sections, we cannot run the NTU-RGB+D dataset for ActionFormer as the data structure it requires is incompatible with the dataset from ROSE lab. Thus, we can infer how it will perform. As the statistics show, we believe that the NTU-RGB+D dataset ran by ActionFormer will have better performance than ST-GCN as ActionFormer is ST-GCN model added with transformers. Addition of transformers to the model makes the model efficient and smarter as explained previously. Thus, we predict the performance of ActionFormer to be average mAP>22% and highest mAP>58%.
As we achieved top 5 accuracy to be 62.78% for ST-GCN, our goal to have models detect emergency situations does not seem to be that far away of a concept. If we can get the models to detect more variety of actions with higher accuracy, we can rely on the machines to catch onto emergency situations faster than anyone can. Moreover, if someone is not in a situation to report at the time such as when being held at gunpoint, the model can contact the police for the person. We can improve the model by making the it more complex or modifying hyperparameters like decreasing the learning rate and increasing epochs. Transformers do not solve the issue of vanishing gradients completely, so if one can come up with a neural network that can compute with no vanishing gradient, the performance can be improved a lot too. Data being inconsistent was part of models’ failures in detecting actions accurately, so we can also focus on generating noise free data to the model. Nonetheless, as the idea of emegency specific action localization can save vast amount of people, it is a compelling area of research that is definitely worth diving into.
References
[1] Yan, Sijie, et al. “Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition.” Department of Information Engineering, The Chinese University of Hong Kong, 25 Jan. 2018.
[2] Mercado, Diego. “Location of the 18 Keypoints Defining the User’s Pose, Provided by …” ResearchGate, Mar. 2020, https://www.researchgate.net/figure/Location-of-the-18-keypoints-defining-the-users-pose-provided-by-OpenPose_fig2_339737714.
[3] Patrona, F. “Action Recognition Datasets.” Rose Lab, 2021, https://rose1.ntu.edu.sg/dataset/actionRecognition/.
[4] Jiang, Yu-Gang. Thumos Challenge 2014, UCF, 2014, https://www.crcv.ucf.edu/THUMOS14/home.html.
[5] Zhang, Chenlin, et al. “Actionformer: Localizing Moments of Actions with Transformers.” ArXiv.org, Nanjing University, 28 Aug. 2022, https://arxiv.org/abs/2202.07925.
[6] Cristina, Stefania. “The Transformer Model.” MachineLearningMastery.com, 5 Jan. 2023, https://machinelearningmastery.com/the-transformer-model/.