GAN Network Application towards Face Restoration
Analyzing the Application of Generative Adversarial Networks For Face Restoration
- Main Content
- Main Focus
- Algorithms
- Examples of Output
- Future Projects and Improvements
- Presentation
- Codebase
- Most Relevant Research Papers
- Most Relevant Code
- Reference
Main Content
My project is to study the overall architecture and application of Generative Adversarial Networks, and in particular the style-based GAN architectures, in order to generate photorealistic images with some noise involved, that allows it to be utilized in the application of face restoration. The models we will analyze will have been trained particularly on the human face, allowing it to enhance the image quality of real-world inputs.
Main Focus
The main focus of this project is to explore GAN architectures improvements and additions have been made upon GAN architectures in order to generate high-quality images from low-quality images that could have different defects such as blur, omission of certain pixels in the image, and low-resolution. In particular, GPEN and Real-ESRGAN are two such architectures that hopes to resolve most, if not all of these issues, in the wild, or in real-world scenarios, and not specially curated images. We will compare the techniques both of these architectures utilize in order to achieve super-resolution, as well as present a method of comparing the observed performance of two architectures by manipulating the low-resolution test image and also by running the same low-resolution test image through the same model multiple times.
Algorithms
This section will focus on the algorithms within each generative adversarial network, along with diagrams of their architectures. Since GPEN uses previous GAN models as a prior, the section will start with the DCGAN model as the foundation of a simple GAN leading into StyleGAN2-ADA, then illustrating how GPEN is able to take the previously mentioned GAN models and build upon it to work on the issue of Blind Face Restoration in the Wild.
DCGAN
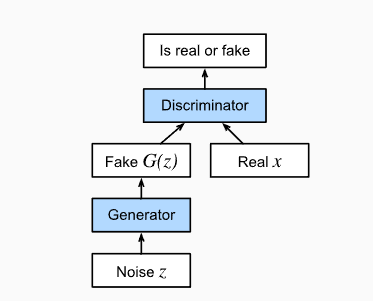
DCGAN (and in general most GAN’s) make use of the max-min loss function concept, where the generator focuses on maximizing the cross-entropy loss while the discriminator focuses on minimizing the cross-entropy loss. Therefore, we are pitting the generator and discriminator against one another in the hopes that as both get better, the discriminator will be able to tell generated models from real models, but our generator becomes so good at generating fake models that appear real. Depending on the end application use, we can either take the generator model and use it to create fake images based around the dataset it had been trained on, or we can take the discriminator model and possibly use it to test if images are real or fake (of course depending on if the GAN was trained on such similar images).
Below is a picture of the min-max loss function where it details how the generator is looking to maximizing the cross-entropy function while the discriminator is looking to minimize it.
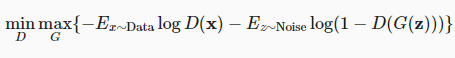
Pictured below is a simplified look at the full DCGAN architecture, where we can see the generator part of the model to the left of the middle “lesion” and the discriminator to the right of the model.
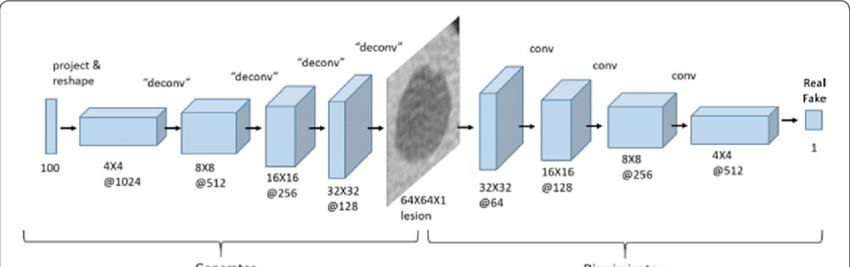
DCGAN makes full use of strided convolutions by replacing older GAN architectures method of spatial downsampling of pooling (such as maxpooling). The reason for this switch to strided convolutions is so that the generator is able to learn and train its own spatial downsampling due to the fact that strided convolutions have parameters that can be optimized while most pooling methods do not have such trainable parameters.
Batch normalization also played a large effect on improving this model and future models as it assisted in the learning process. The purpose of batch normalization is to reduce the internal covariance shift that occurs when the change in network parameters during training affects the change in the distribution of network activations.[11] The paper claims that including batch normalization allows for much higher learning rates, the removal of dropout layers, and less care about the initialization of the model. All of these aspects stem from batch normalization making training of models more resilient to the scale of its parameters in each layer as it helps tackle the issue of vanishing gradient and model explosion that many models have, especially GANs.
From DCGAN, future GANs will be created where the models will be optimized to focus on certain characteristic features on the pictures they are meant to train on. This will in turn spawn numerous different style-based architectures.
StyleGAN2-ADA
StyleGAN2-ADA is an improvement upon StyleGAN2 which itself was an improvement on StyleGAN1. StyleGAN1 is a style-based GAN where unlike DCGAN and previous other GANs, the input latent z code will not be directly fed into the generator/synthesis network but will instead be fed into a mapping network comprised of a number of fully connected layers, and transformed into an intermediate latent code w. This latent code w alongside some noise will be injected into a convolutional block connected to a certain resolution. For example, the convolutonal block responsible for the 4x4 resolution will have its own latent code w and noise then after upsampling occurs, the 8x8 resolution block will have the latent code w and some noise injected into it as well. So, the style-based architecture starts at lower resolutions, then upsamples to higher resolutions while being fed inputs from the latent code w, the output from the lower resolution block before it, and noise. (The first convolutional block will receive a constant input that replaces where the “z” latent code would have been in models like DCGAN.)
Pictured below is a comparison between a traditional GAN generator and a style-based generator.
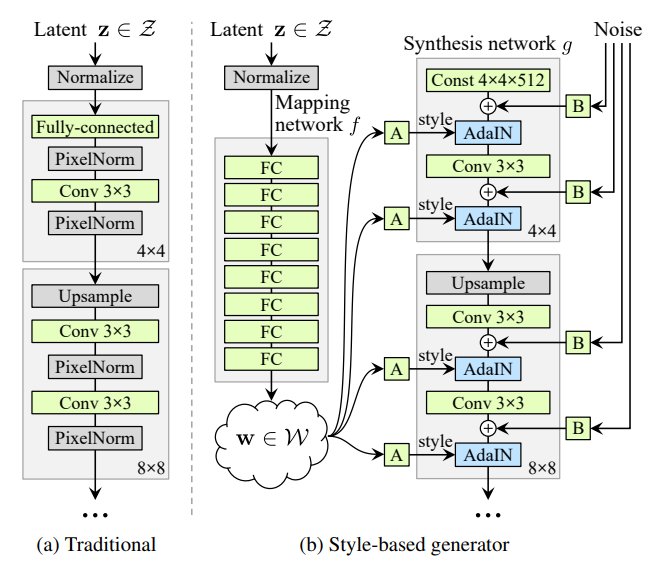
Another different aspect of style-based architectures than that of previous traditional GAN architectures is the inclusion of the Adaptive Instance Normalization block. Adaptive Instance Normalization is meant to align the channel-wise mean and variance of the content input (the input from the lower resolution blocks) and align it to the style input (the input from the latent code w).[12] It will detect the style from the style input and apply it onto the content input while maintaining the spatial information of the content input. This in turn allows styles from the latent code w to be picked up and carried over to the final output. A picture of AdaIN is provided below.
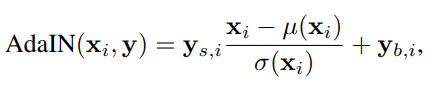
GPEN
GPEN or GAN Prior Embedded Network is a model created to tackle the issue of blind face restoration tasks. Blind face restoration refers to the act of creating a higher-quality image from a lower-quality image that could suffer from a variety of issues, such as blur, noise, and outright missing complete parts of the input.
The model consists of taking a style-based GAN model such as StyleGAN2 (which is what the authors of the paper and model had used, although the underlying generative prior could be any such style-based architecture) and training it to then insert it as a decoder into deep neural network. This method is what is known as GPEN.
The first part of the model consists taking a convolutional neural network encoder which will learn to map a degraded low quality image into a latent code z that will be the latent code input for the GAN network. We need this encoder as unlike previous GAN models we have discussed in this project, they are not given an image as an input as they are meant to simply generate some random image that shouldn’t necessarily be a direct copy of one of the training images. But, the downstream task at hand is to restore a low-quality image, which requires an actual image as input, and therefore requires an encoder to be able to transform that image into some latent code z that will allow the GAN prior to construct a high-quality image that resembles the original input image. This technique is reminiscent of GAN inversion which attempts to take an image and produce a latent code z. The issue discussed in the paper with this is that with GAN inversion, it would be nearly impossible to construct a latent code z from a blind degraded face.[2]
The model is constructed to resemble a U-Net architecture as the paper lists it as as being used in many image restoration tasks and is effective at preserving image details, which is what we want as we don’t want to construct a completely different person than whom is shown in the degraded image.[2]
A picture of the different parts of the GPEN architecture as well as a simplified model of the entire GPEN architecture is shown below.
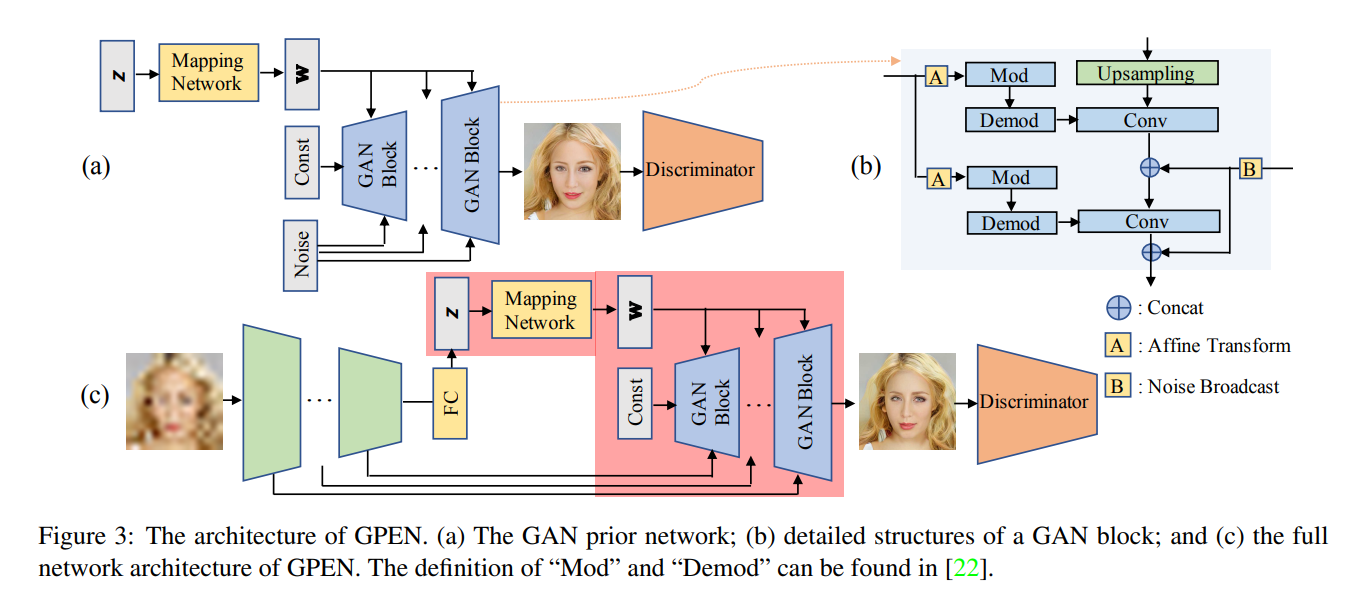
We can see in Figure 3c that the degraded image is the original input to the model, and from there, will be downsampled (as this is the first part to the U-Net architecture that the GPEN model is based on), but the shallower features of the encoder will be sent to the GAN prior network so as to retain the features of the original image, such as the background of the face image and overall structure of the face. We can see in the picture that the deeper features of the encoder will be sent to the fully connected layer and converted into an intermediate latent code z, as discussed above.
Training the GPEN model begins with first training the GAN prior on high-quality images (essentially the same as StyleGANv2 and other style-based architectures), but then when the GAN prior is embedded into the deep neural network, it must then be trained by a series of synthesized low-quality and high-quality images in order to finetune it for blind-face restoration. Three loss functions are implemented in order to finetune the model: the adversarial loss, the content loss, and the feature matching loss.
The adversarial loss comes from the GAN prior network and is:
\[L_A={min\atop{G}}{max\atop{D}}E_{(X)}log(1+exp(-D(G(\tilde{X}))))\]The content loss is calculated from comparing the generated high-quality image and the actual ground-truth image that isn’t degraded using the L1-norm distance. This loss is meant to preserve the color information of the original image and the fine features.
The feature matching loss is similar to a perceptual loss where a perceptual loss is used to compare high-level differences such as style and the overall content of the image. This is different than other loss functions that only compare pixel to pixel which may output a huge loss between a generated image and the ground truth image if the generated image is only slightly shifted/translated but still retains most of the original features of the ground truth image. This is an issue as we are more focused on preserving the overall features of the low-quality image and enhancing them in the generated high-quality image. The formula for it is:
\[L_F={min\atop{G}}E_{(X)}(\sum^{T}_{i=0}||D^i(X)-D^i(G(\tilde{X}))||_2)\]All three loss functions are then combined into one final output function:
\[L=L_A + \alpha L_C+\beta L_F\]Alpha and Beta are hyperparameters to set, and in the GPEN paper, they empirically set alpha = 1 and beta = 0.02.
Real-ESRGAN, ESRGAN, and SRGAN
This project utilizes an implementation of Real-ESRGAN, which builds upon ESRGAN, and ESRGAN builds upon SRGAN. SRGAN
SRGAN is a generative adversarial network that focuses on super-resolution, or generating/predicting a high-quality image from its low-quality image counterpart. The SRGAN model comprises of a deep residual network (such as ResNet) with skip-connections which also makes use of the perceptual loss function that was discussed above, rather than the pixel-to-pixel loss. [16]
For a short description of ESRGAN, it improves upon SRGAN by replacing the batch normalization layers with residual scaling and smaller initializations, use a discriminator that is focused on determining whether an image is more realistic than the other versus the usual discriminator determining whether an image is fake or not, improving the perceptual loss in SRGAN by using VGG features from after activation to before activation, and introducing a Residual-in-Residual Dense Block. [15] A Residual-in-Residual Dense Block, or RRDB, consists of dense blocks which are multiple convolution layers that take input from all previous convolution layers before it, and combines it with a residual block. The block is meant to make the original SRGAN model more deep and complex, and is made possible without the issues of deep models such as vanishing gradients due to the other optimizations listed before.
Real-ESRGAN focuses on blind-world degradations and the issue that a model like ESRGAN is not complex enough to recognize all of the multitude of degradations that can occur in the real-world, and be able to identify them all. Real-ESRGAN like GPEN both utilize the U-Net architecture, and in Real-ESRGAN’s case it replaces the VGG features in ESRGAN with an U-Net design.
Pictured below is the architecture of Real-ESRGAN:
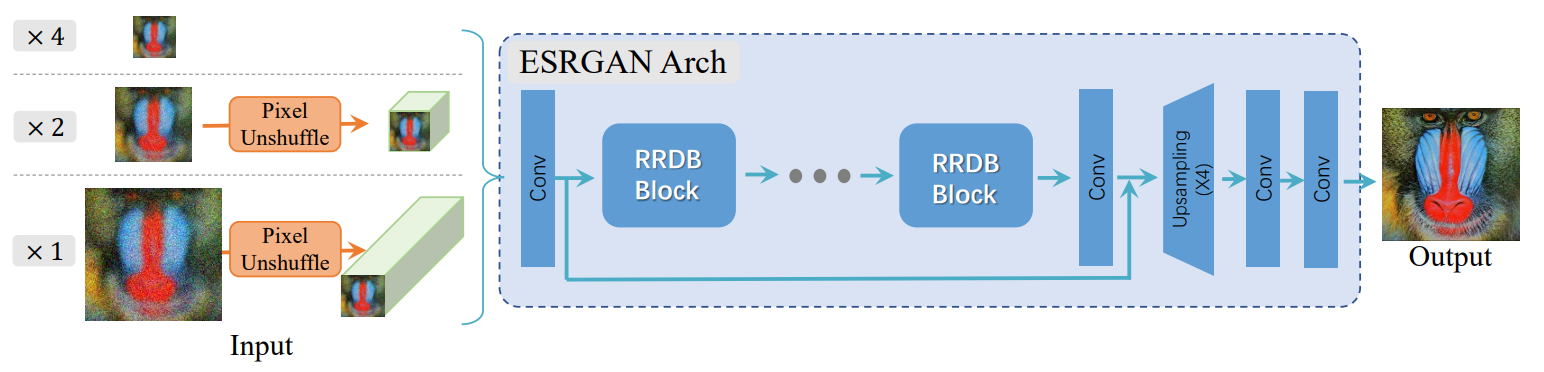
We can see that Real-ESRGAN uses the same RDDB blocks that ESRGAN utilizes as well and overall the same generator network. The pixel-unshuffling at the beginning of the network is to reduce the spatial size of the input image and to resize the information to be compatible in the channel dimension. [14]
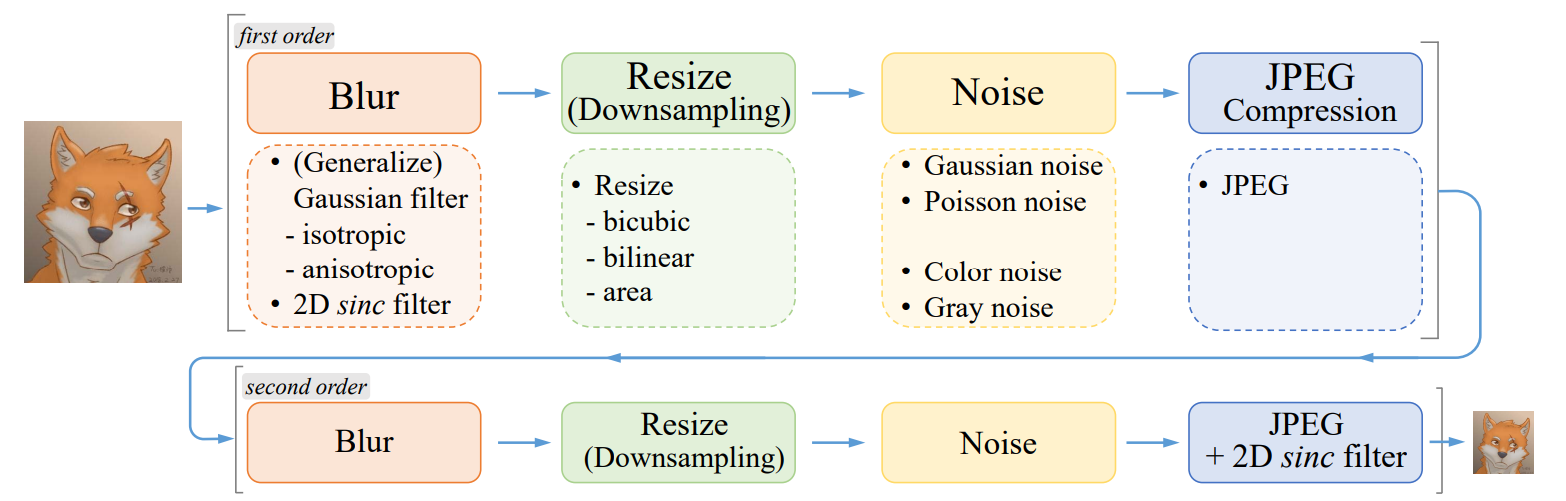
Real-ESRGAN also conducted improvements on the synthesis between the higher-quality ground truth image and the lower-quality image that it is trained on. Below is a diagram of the different operations that result in image degradation, such as compression and noise, that are purposefully used in order for the model to be capable of the different types of degradation in the wild.
Examples of Output
DCGAN model
Below is an image of several images that my DCGAN model created when trained on the flowers102 dataset. The input and output of the images are only 32x32, and so limits how much the latent vector is able to capture/control of the outputted image. Due to the low resolution of my model in comparison to StyleGAN which can handle 1024x1024 images, this DCGAN implementation can only capture very broad characteristics, not the minute details/features in the dataset.

Due to several factors such as simplicity of the model, lack of features to help loss convergence, and not enough training time, I noticed that while training my model on the flowers102 dataset, that the discriminator is converging swiftly towards 0 while the generator continues to increase in loss without stopping. Logically this makes sense, as the discriminator is trained to better recognize between generated images and real images, the generator will in turn struggle to trick the discriminator into believing that its own generated outputs are real. However, what we don’t want is for the discriminator to swiftly converge towards 0, which means that the discriminator is near perfect when distinguishing real from fake, and so no learning is occurring for the discriminator. Below is an image of the loss between the generator and discriminator when training on the flowers102 dataset.
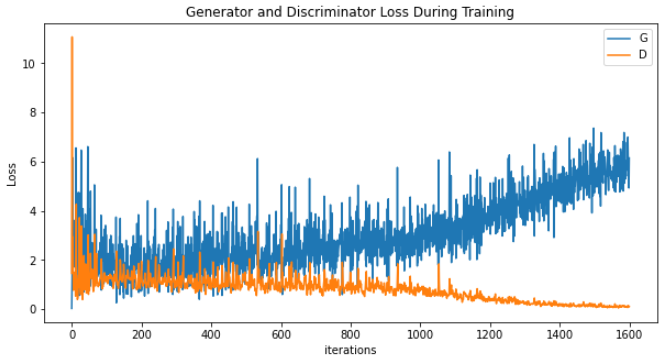
Looking up online, multiple additional methods are suggested that could help the discriminator not converge towards 0, but towards some loss greater than 0, such as implementing dropout into the discriminator architecture, and other methods to fix (or help alleviate) the vanishing gradient problem, mode collapse problem, and other issues.
StyleGAN2-ADA Model
Below is a gif/mp4 of linear interpolation over the z-space of StyleGAN2-ADA and how we can see the change over the different features of the face such as hair, facial expression, clothing, and even the direction of which the person is facing. Throughout the different frames of the GIF, we can see that the output from the model can be considered as generally close to actual human faces (at a quick glance due to the high frame rate of the GIF). However, we can also see issues within each image, especially of blurry splotches around the hair and background. The StyleGAN2 paper addresses these issues and talks about splitting their Adaptive Instance Normalization block/method into separate parts and introducing weights/latent space will be effective at helping erase the blurs, at least better than StyleGAN1 did. These generated frames were based on a pretrained model from this github repo and the specific dataset and weights used were based on the FFHQ dataset but with a 256x256 resolution.
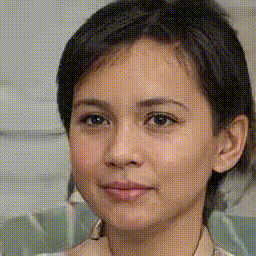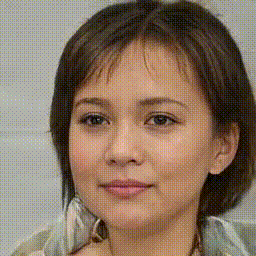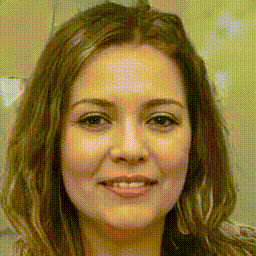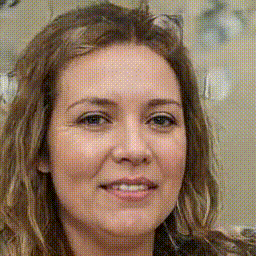
We can see from the change of different features the effect that changing the latent code z has on capturing the different styles that were found during training. This discovery will carry on in both the GPEN model and the Real-ESRGAN model and how they will use the latent code z as a tool to preserve and modify the styles/content in the low-quality image and how it will these features will be propagated to future layers in the model in order to influence the end result.
GPEN Model vs Real-ESRGAN Model
The setup for the comparison between these two models was to download 256x256 images of faces from this Kaggle dataset. For this project, I had only utilized 100 images which is understandably a small amount of samples. I then stack blurred the image on this website in order to obtain the low-quality image that will be the input for both models. To get the generated images using a GPEN model, I used this website and this website as unfortunately their google colab notebook was not working despite my attempts to fix it. To get the generated images using a Real-ESRGAN model, I used this google colab notebook. Using the image quality classification metrics in the python sewar library, I made this google colab notebook in order to retrieve the different scores for the ground-truth images against the stack blurred low-quality image as a baseline, the GPEN generated image, and the Real-ESRGAN generated image. Below is a table with the scores calculated for each image and then averaged. For each of these metrics, the higher the score, the better.
| Blurred | GPEN | Real-ESRGAN | ||
|---|---|---|---|---|
| SSIM | 0.2278 | 0.3290 | 0.6379 | |
| PSNR | 9.406 | 11.93 | 22.20 | |
| UQI | 0.6052 | 0.7211 | 0.9364 |
We can see that both GPEN and Real-ESRGAN both achieved scores in all metrics better than the baseline blurred image that was the input, but Real-ESRGAN achieved much higher scores in SSIM and PSNR, and a slightly higher score in UQI. This was surprising to see as written in the GPEN paper, their metric scores generally scored quite high. There are multiple reasonings to the low scores documented here that could be attributed to how their GPEN demo may only use a commercial version of their model that is weaker than the one in their paper and the small amount of test samples.
Another possible explanation for the difference in performance is due to the GAN prior used in GPEN. The model tested used StyleGANv2 as the generative prior which possibly performed weaker than Real-ESRGAN due to not enough finetuning or the difficulty in handling the latent code generation from StyleGANv2 to generate high-quality features that matches the input image. An interesting interaction between Real-ESRGAN and GPEN is that due to the nature of GPEN and its ability to incorporate generally any GAN as long as it can generated high-quality images and the GAN can be embedded as a decoder, technically Real-ESRGAN could be the generative prior for GPEN which could lead to much higher performance with the combination of the both of them.
Below are some GIFS that showcase the different generated images and the ground truth images for a small sample of the tested data. The order of the GIFS are: Ground Truth, GPEN, and then Real-ESRGAN.
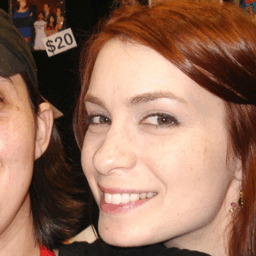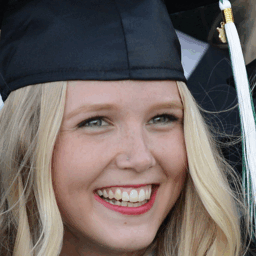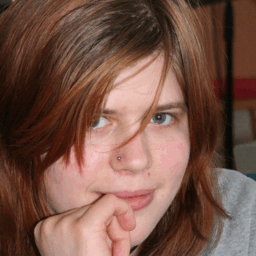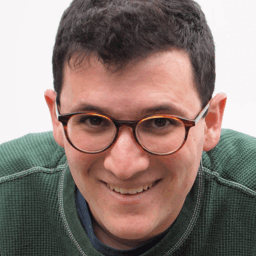


Observing this small sample, we can see that specific features in the person’s face (such as eyes, mouth, and nose) generally appear much more clear than the blurred image, although at times other features such as the hair of the person appears blurred occasionally for both models. From just looking at these outputs, it seems that both models tend to increase the quality of the image mostly around the face, as the hair closest to the face tends to be higher quality than those farther away. Perhaps we could conclude this as a possible issue of the models determining the background from the person’s hair or that when the hair becomes much more “solid” and not just strands of hair, the models method of downscaling and upsampling could have just reduced the hair as a singular color. Also for both models, the background tends to remain blurred even after running through each model.
Multiple Run-Through of Same Image
I wanted to experiment on how these super-resolution models behave when repeatedly running the generated output image as the input image through the same model multiple times, and see what what conclusions we can draw about how these models work.
I selected one blurred image here:

And here is the original high-quality image for reference as well:

I then ran the image through both the GPEN model and the Real-ESRGAN model 10 times and created a GIF to show the change over time of the generated image.
Here is a timeline of the GPEN output:

Here is a timeline of the Real-ESRGAN output:

The Real-ESRGAN output increases in size due to how the Real-ESRGAN output was modified to increase in scale by x1.1 each run.
First, I was very surprised about the outputs of both models. At the beginning of both models, the generated output seems believable enough to the actual ground truth image as it possesses the characteristics that an image of a person should have. What this means is that an image of a person should not have such “solid” colors and appear to have distinct edges to their features, but rather it should be smooth and blend into each other. But, as the later outputs in the GIFs show, this is not the case. This made me curious as my original belief in how these super-resolution models work is to not only generated high-quality images, but also keep the images believable enough to resembling an actual person. But in this case, the later outputs don’t resemble an actual person at all, but rather a more cartoon/drawn/bolded image of a person. If both of these models train on actual images of human beings, then why did the models decide to increasingly bolden the colors and certain features in a manner that would (likely) not reflect any of the training images at all?
Also, although this is just one sample and not necessarily indicative of how these models work on all images, we can see from the GPEN output that, in my opinion, I believe it actually does a better image at trying to retain the image of a person. The gleam/reflection of light from the person’s hair in the GPEN GIF stays fairly consistent throughout the different outputs, but for the Real-ESRGAN output, it becomes this solid cloth on the person’s head. Although for GPEN the colors become much more pronounced as the it runs through the model more and more, different features of the person retain a sense of realness to them such as the hair, since in the Real-ESRGAN output, it looks like strands of color are inserted in her hair. In the summary of ESRGAN earlier in the project, it is stated that the discriminator was modified to determine whether an object is more “realistic” or not. But when doing this experiment, it begs the question as to whether it did a good job at this or not.
Another interesting aspect to this experiment is that it reveals, at least in Real-ESRGAN, the impact of noise and downsampling on the output. If we focus on the mouth of the person, we can see the individual’s teeth until the few last outputs where the lips close gradually over time. This was an interesting revelation to me as I had believed that when repeatedly running the image over and over, the model would pick up on the teeth being present in the image. Perhaps either due to noise, or due to the downsampling nature of the model, it was possible that the latent code corresponding to whether the teeth should be present or not ended up being manipulated towards the end.
It may be possible that with repeated testing of this method on different samples, that we can see what specific features a model focuses on making “high-quality” depending on which features stay more consistent throughout the repeated process versus those that end up less realistic.
Understandably, the outputs do make some sense as the purpose of these models is to simply create high-quality images from degraded images, and not necessarily realistic images of a human face. Passing already high-quality images could have confused the model and caused it to be under the assumption that the input image is degraded, and therefore apply the same/similar methods of creating a higher-quality image on the already HQ input image. From Real-ESRGAN, we can see that it attempts to enhance features that are smaller such as the faint red color on the hair due to light which became very apparent and bold. Perhaps this technique was learned by the model in order to compensate for the low resolution of expected input images and how certain colors are only present in a few pixels. The model learns to bring those colors out by increasing the resolution and perhaps making these colors more vibrant. From GPEN, it seems to possibly be the opposite than Real-ESRGAN as the overall color of the person’s face becomes more and more pronounced over time.
Future Projects and Improvements
Here are a list of some future projects and improvements to the models:
-
Incorporate the annotation of training images and inclusion of textual context surrounding the image to influence the output of the high-quality image. For example, if someone enters in that the gender is male and at a certain age, perhaps the model will take these into account and generate a high-quality image that matches this description. I feel like it would help users when interacting with an application in production as most users likely understand what features the low-quality image has and wants some way to tell the model this information.
-
Produce a model that is capable of producing realistic images given any quality of image, and not just a lower quality degraded image. In my experiment above, it showed the flaws with the models when the input is already high-quality and that it produced less realistic images. Using the discriminator listed in ESRGAN that differentiates between realistic and not realistic, along with training the model with high-quality and low-quality training images could work together in producing this type of model. Although, I imagine that the model would have to be a lot more complex in order to take these improvements into account.
-
Combine a segmentation model with these super-resolution models in order to enhance the accuracy of the segmentation models. This could save a lot of money in hardware as the software would be capable of enhancing the quality and so the older, outdated cameras and equipment would not have to be replaced.
Presentation
Here is a link to the youtube video as well: https://www.youtube.com/watch?v=XVcJwdhvYHA
I also put it in a google drive folder in the case that the embed youtube does not work.
Codebase
This google colab file is a self-implementation of the DCGAN architecture which was heavily based off of d2l’s own implementation of DCGAN. I created this notebook to better help my understanding on how Generative Adversarial Networks work and also to understand how the different componenents work with on another in order to generate the final images. I had downscaled my architecture from d2l’s 64x64 resolution to 32x32 in order to reduce computational time.
This google colab file is another individual (@Derrick Schultz) implementation of StyleGAN2-ADA which applies a slight modification in the StyleGANv2 architecture and how the Adaptive Instance Normalization is built in. Pretrained weights were loaded into this model taken from this github repo (https://github.com/justinpinkney/awesome-pretrained-stylegan2/#faces-FFHQ-config-e-256x256) where the weights were trained on the FFHQ dataset but with a resolution of 256x256 rather than the original 1024x1024 (once again to save on computation time).
This google colab file is a file that contains a pretrained model of GPEN. This google colab file will (hopefully) be the focus of the project and will also assist in ablation studies along with StyleGAN2-ADA.
This google colab file is what I used to calculate the different image quality assessment metrics between the different generated images and the high-quality ground truth images.
This google colab file is what I used to generate the Real-ESRGAN outputs.
Most Relevant Research Papers
-
This paper talks about utilizing a pre-trained GAN along with “rich and diverse priors” to be restore low-quality inputs.(1)
-
This paper explains how their GAN prior network is capable of being embedded into a U-Shaped DNN, and how their model is capable of restoring images that have degraded over time.(2)
-
This paper talks about the redesigns of the original StyleGAN in order to improve upon its generative image modeling capabilities.
-
This paper talks about the particular StyleGAN2 model that was used in this project which was StyleGAN2-ADA.
-
This paper talks about the DCGAN model.
-
This paper talks about the Real-ESRGAN model.
Most Relevant Code
This github repository contains a list of pretrained weights for the StyleGAN2-ADA model on different datasets.
This github repository is the official repository for the GPEN model.
This github repository is a repository for the Real-ESRGAN model.
This website is a demo for GPEN model.
This website shows off the different other applications of the GPEN model other than face restoration, such as face inpainting and face colorization
Reference
[1] MWang, Xintao, et al. “Towards real-world blind face restoration with generative facial prior.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[2] Yang, Tao, et al. “Gan prior embedded network for blind face restoration in the wild.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[3] Karras, Tero, et al. “Analyzing and improving the image quality of stylegan.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
[4] Brownlee, Jason. “A Gentle Introduction to Stylegan the Style Generative Adversarial Network.” MachineLearningMastery.com, 10 May 2020, machinelearningmastery.com/introduction-to-style-generative-adversarial-network-stylegan/.
[5] Karras, Tero, Samuli Laine, and Timo Aila. “A style-based generator architecture for generative adversarial networks.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
[6] Radford, Alec, Luke Metz, and Soumith Chintala. “Unsupervised representation learning with deep convolutional generative adversarial networks.” arXiv preprint arXiv:1511.06434 (2015).
[7] Dwivedi, Harshit. “Understanding Gan Loss Functions.” Neptune.ai, 30 Jan. 2023, https://neptune.ai/blog/gan-loss-functions.
[8] Karras, Tero, et al. “Training generative adversarial networks with limited data.” Advances in neural information processing systems 33 (2020): 12104-12114.
[9] Radford, Alec, Luke Metz, and Soumith Chintala. “Unsupervised representation learning with deep convolutional generative adversarial networks.” arXiv preprint arXiv:1511.06434 (2015).
[10] Shorten, Connor & Khoshgoftaar, Taghi. (2019). A survey on Image Data Augmentation for Deep Learning. Journal of Big Data. 6. 10.1186/s40537-019-0197-0.
[11] Ioffe, Sergey, and Christian Szegedy. “Batch normalization: Accelerating deep network training by reducing internal covariate shift.” International conference on machine learning. pmlr, 2015.
[12] Huang, Xun, and Serge Belongie. “Arbitrary style transfer in real-time with adaptive instance normalization.” Proceedings of the IEEE international conference on computer vision. 2017.
[13] Johnson, Justin, Alexandre Alahi, and Li Fei-Fei. “Perceptual losses for real-time style transfer and super-resolution.” Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14. Springer International Publishing, 2016.
[14] Wang, Xintao, et al. “Real-esrgan: Training real-world blind super-resolution with pure synthetic data.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[15] Wang, Xintao, et al. “Esrgan: Enhanced super-resolution generative adversarial networks.” Proceedings of the European conference on computer vision (ECCV) workshops. 2018.
[16] Ledig, Christian, et al. “Photo-realistic single image super-resolution using a generative adversarial network.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[17] Miyato, Takeru, et al. “Spectral normalization for generative adversarial networks.” arXiv preprint arXiv:1802.05957 (2018).