Trajectory Prediction in Autonomous Vehicles
In recent years, the computer vision community has became more involved in automonomous vehicle. With evergrowing hardware support on modeling more complicated interactions between agents and street objects, trajectory prediction of traffic flows is yielding more promising results. The introduction of Transformer technique also galvanized the deep learning community, and our team will explore the application of Transformer in trajectory prediction.
In this article, we investigate modern architectures which tackle the trajectory prediction task in autonomous driving. We perform a close-up analysis of Multipath++, a vectorized neural network that approximates the self-attention mechanism using Multi-Context Gating. We improved upon the community implementation of Multipath++(MPA) and observed significant performance gains with our implementation while training with limited samples and epochs. Empirically, our prediction visualization converges faster within a few epochs, outperforming the baseline MPA.
- Introduction
- Existing Works
- Model Selection
- Data Preparation
- Demo
- Multipath++
- Training Objective and Metrics
- MPT: Our Innovation
- Conclusion
- Reference
- Code Bases
Introduction
The computer vision community has become more involved in autonomous vehicles in recent years. With evergrowing hardware support for modeling more complicated interactions between agents and street objects, trajectory prediction of traffic flows is yielding more promising results. The introduction of the Transformer technique also galvanized the deep learning community, and our team will explore the application of the Transformer in trajectory prediction. Specifically, we will modify an established architecture to replace its original encoders with transformers for latent feature representations. We will benchmark our model against established ones for performance analysis.
Existing Works
A typical autonomous vehicle pipeline has three stages: perception, prediction, and planning. We dived into three neural network architectures that tackle these two challenges. In this work, we will focus primarily on the first two stages.
TrafficGen: This paper first trains a generator from the Waymo data to generate more comprehensive training data. In the trajectory prediction task, TrafficGen uses vectorization and Multi-Context Gating (MCG) as the encoder. To decode the information, TrafficGen first uses MLP layers to decide the region of the vehicle, then uses log-normal distribution to generate the vehicle features (i.e., position in region, speed, etc.). After vehicles are generated, TrafficGen uses Multipath++ to predict future trajectories. To scale prediction to a longer horizon, TrafficGen only uses global features as input for trajectory prediction.
Multipath++ Multipath++ first transform the road features into polylines and agent history as a sequence of states encoded by LSTM. It uses a Gaussian Mixture Model as the prior to preserve the multi-modality of the trajectory prediction task. Multipath++ proposes the MCG architecture, which is similar to cross-attention by allowing the vehicle to communicate with road elements and vice versa. Finally, Multipath++ sets anchors in the latent space to guide the vehicles.
LaneGCN LaneGCN is one of the earlier works that proposes using vectorized input instead of pixel input. Unlike the VectorNet paper, LaneGCN extends graph convolutions with multiple adjacency matrices and along-lane dilation and only uses sparse connections between elements.
Model Selection
While works such as TrafficGen and LaneGCN are both popular in the community, we decided to work with Multipath++ in this project. The reasons are:
- Multipath++ shows strong performance in the Waymo 2021 Open Prediction Challenge.
- Multipath++ designs an attention-like and transformer-like architecture, which has the advantage of scaling up. Details are described in the section below.
- The predecessor of Multipath++ is Multipath, which is also highly cited and serves an important role in the community. Together, they show the impact of this series of works. Compared to Multipath which uses pixel inputs, Multipath++ uses vectorized inputs (i.e., objects and roads are represented as points or lines instead of images). Vectorization naturally serves as a feature engineering step and helps with the model training speed.
Data Preparation
We leverage the Waymo Open Motion Dataset v1.1 to replicate and improve our model. In this dataset release in 2021, individual driving scenarios in bird-eye view is stored in TFRecord files. Each file contains physical properties(position, velocity, etc.) of the background(roadmap, etc.) and agents(participants in the background traffic). For one such TFRecord, the original Multipath++ project prerenders it into sets of npz files, each redescribing the same scene from one agent’s perspective. These npz files are the raw forms of the input embeddings.
In this project, we used 40 out of 1000 training records and 5 out of 150 validation records. Note that these data, after preprocessing, already takes up around 100 GiB. Our data is stored in this Goodle Drive folder.
Demo
Please follow this Google Colab link.
Our full source code is available at this Github Repo.
Multipath++
1. Data Representation
Unlike previous models such as Multipath that use pixel inputs, recent models, including Multipath++, start to favor vectorized inputs(prerendered into numpy arrays). The vectorized inputs are denser. Furthermore, it carries richer information by allowing heterogeneous features such as object speed and acceleration.
Consider moving cars as agents, the multimodal data are:
- Agent State History: represented by a sequence of inputs for a fixed time frame. Each timestep includes position, velocity, 3D bounding box, heading angle, and object type information.
- Roads: represented as a set of piecewise linear segments or polylines.
- Agent Interactions: are represented as relative orientation, distance, speed, and historical track.
2. Architecture Glimpse
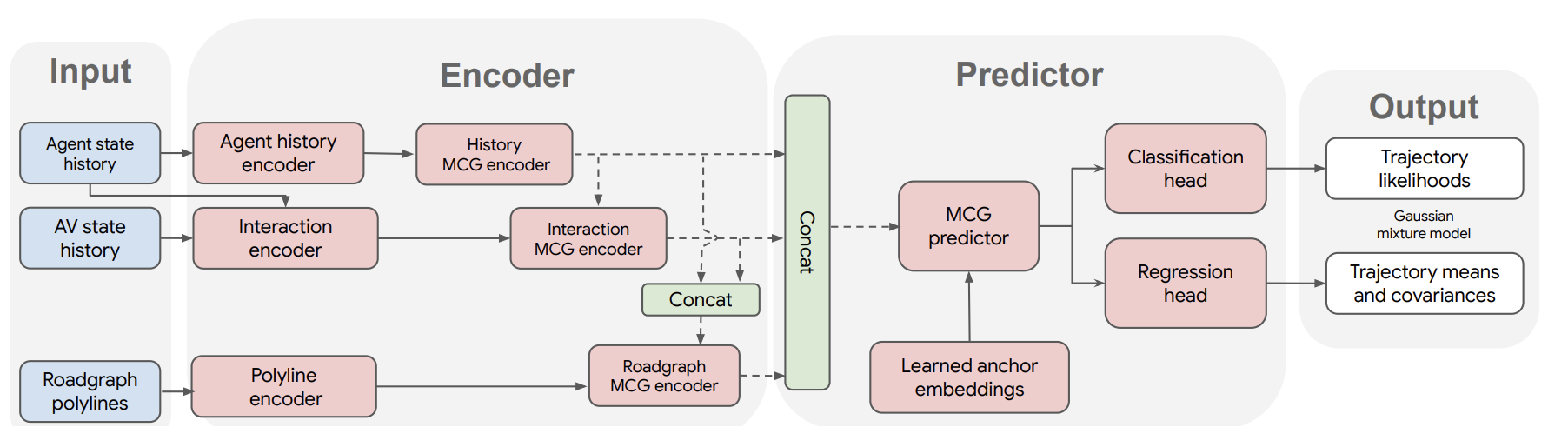
Here is the architecture for Multipath++. In the Encoder part, we can see that it uses multiple encoders to transformer and allows interactions in between. For the Predictor part, we can see it uses Multi-Context Gating (MCG) predictor and regression and classification heads that work similarly to a transformer.
Finally, the learned anchor embeddings represent a target point or checkpoint in a middle way in the latent space. The learned embeddings inherently helps with long-frame prediction.
3. Context Gating (CG)
CG is one of the key innovations of Multipath++. It works like an attention block and empirically enables the communication between different road objects. First, let’s look at a CG block:
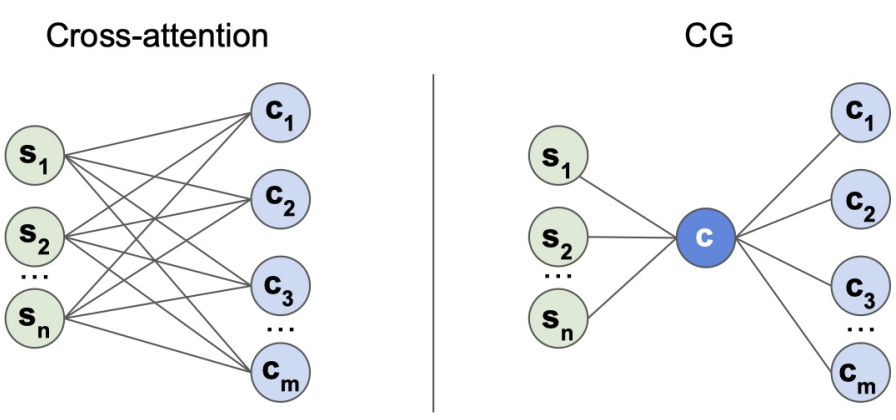
The inputs of a CG block include both n states and m contexts. A CG block passes input states and context information through the respective MLPs. Eventually, it aggregates the element-wise multiplication through mean or max pooling.
Compared to Cross-Attention on the left, CG is computationally cheaper by summarizing the two kinds of inputs first, then aggregating the summarized value.
class CGBlock(nn.Module):
def __init__(self, config):
super().__init__()
self._config = config
self.s_mlp = MLP(config["mlp"])
self.c_mlp = nn.Identity() if config["identity_c_mlp"] else MLP(config["mlp"])
self.n_in = self.s_mlp.n_in
self.n_out = self.s_mlp.n_out
4. Multi-Context Gating (MCG)
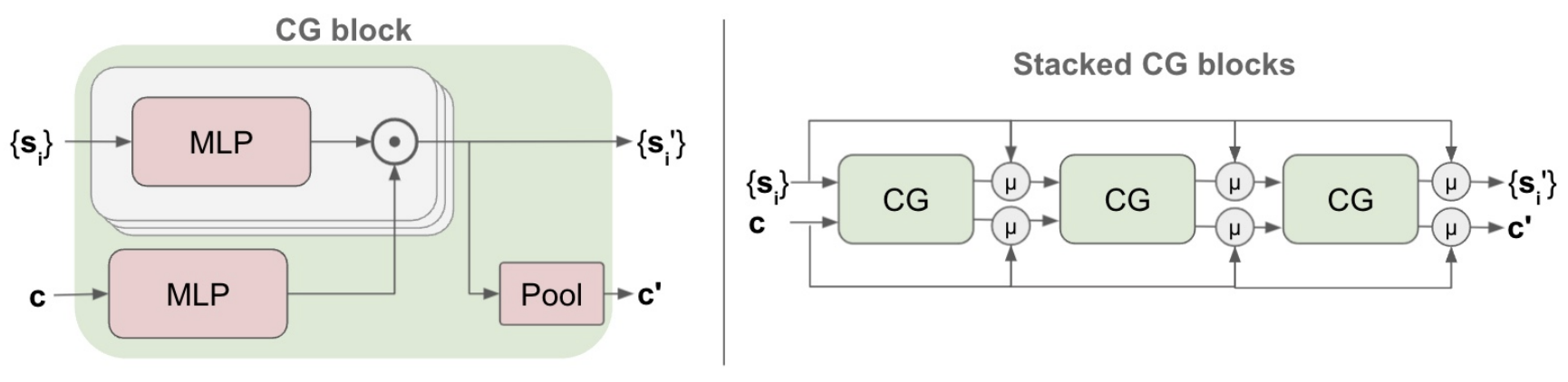
As a single CG Block is comparable to attention, the MCG blocks are comparable to transformer, which simply involves many stacked CG Blocks. However, MCG keeps the running mean or residual network information.
class MCGBlock(nn.Module):
def __init__(self, config):
super().__init__()
self._config = config
self._blocks = []
for i in range(config["n_blocks"]):
current_block_config = config["block"].copy()
current_block_config["agg_mode"] = config["agg_mode"]
self._blocks.append(CGBlock(current_block_config))
self._blocks = nn.ModuleList(self._blocks)
self.n_in = self._blocks[0].n_in
self.n_out = self._blocks[-1].n_out
5. Encoders
We introduce the encoder network architectures:
- Agent History Encoder includes two LSTM networks and one MCG Block.
- One LSTM encodes position data, while the other encodes position difference data.
- The MCG blocks which encode the set of history elements.
- Empirically, two LSTMs might help to capture velocity and accelration.
- Agent Interaction Encoder uses exactly the same architecture as the History Encoder with different specifications. More importantly, the input data are the interaction embedding instead of single-agent representation.
- Roadgraph Encoder consists only of MCG Blocks. The input features are line segments, including features such as starting point, ending point, and road type (crosswalk, yellowline, etc.)
6. Predictors
A decoder unit is primarily MCG Blocks. To make the final predictions, the embeddings are passed through multiple decoders units sequentially. In the last decoder unit, an additional MLP is applied to output the soft prediction of future trajectories distribution.
Finally, an Expectation Maximization (EM) algorithm with Gaussian Mixture Model (GMM) prior is trained on the distribution parameters, including mean, covariance matrix, and probability. Alternatively, the final layer may employ Multi-Head Attention for the same predictions.
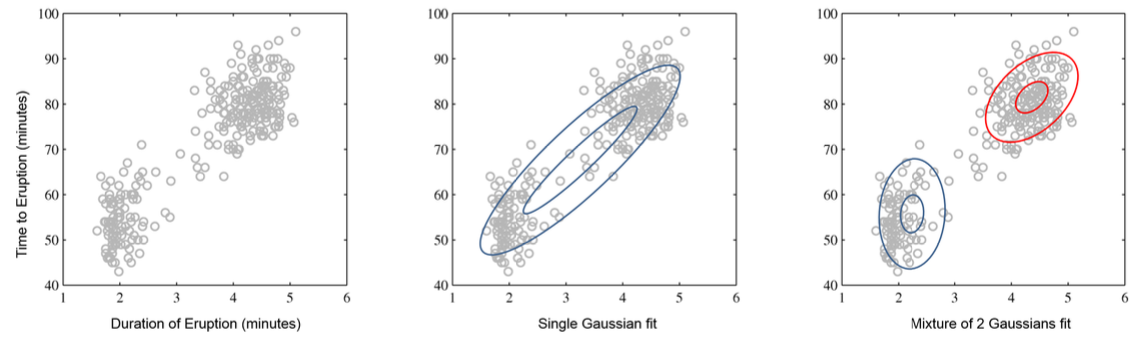
Notice the GMM naturally has multiple local nodes. Therefore, it is similar to how a vehicle can follow any one of the possible paths in reality.
The picture below illustrates Multipath++’s predictions for different WOMD scenes(ablation study). Note that hue indicates the time horizon while transparency indicates predicted probability.
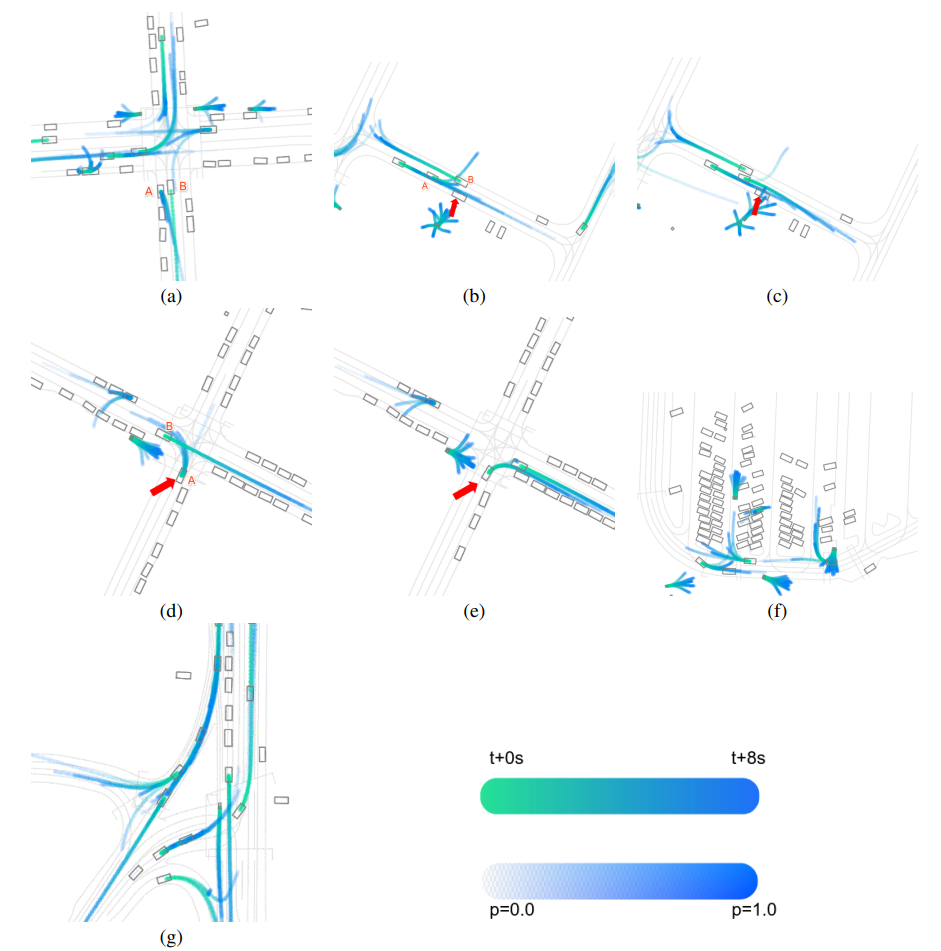
7. Anchor Training
One improvement of Multipath++ from Multipath is leveraging latent anchor embedding in the predictor. Specifically, Multipath++ doesn’t follow the 2-phase training procedure and learns the anchor embedding together with the model.
The anchors are initialized following a standard deviation and learned using back-propagation.
# size is embedding dim
self._learned_anchor_embeddings = torch.empty(
(1, config["n_trajectories"], config["size"]))
stdv = 1. / math.sqrt(config["size"])
self._learned_anchor_embeddings.uniform_(-stdv, stdv)
self._learned_anchor_embeddings.requires_grad_(True)
self._learned_anchor_embeddings = nn.Parameter(self._learned_anchor_embeddings)
8. Community Implementation of Multipath++
Since Multipath++ doesn’t have an official repository, we refer to this community implementation. We here discuss the two differences between the community version and the original Multipath++.
First, the community version chooses to use Multi-Head Attention (MHA) instead of GMM to make predictions numerically stabler. To be specific, the author uses six decoder outputs as attention input followed by Max Pooling and MCG Blocks as shown in the following image.
Second, unlike the original version that encodes autonomous vehicles separately, the community version uses the same encoder for all vehicles.
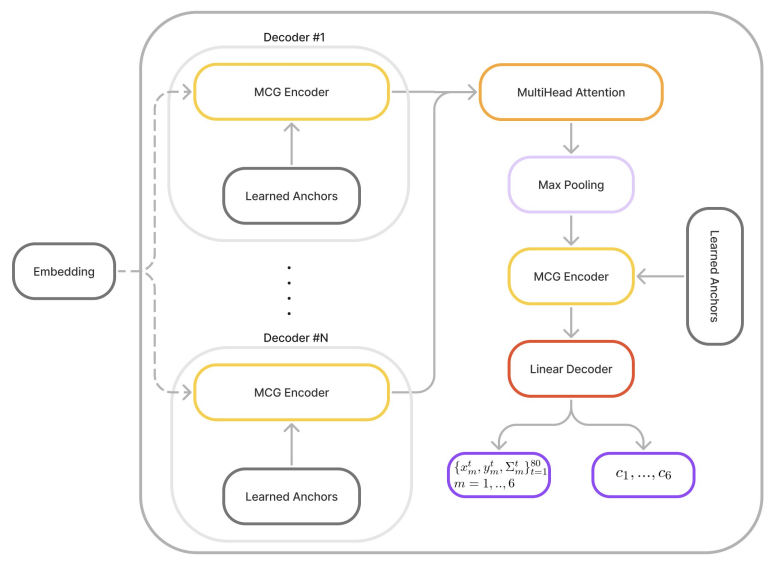
Training Objective and Metrics
1. Loss Function
During training, the model is conditioned on 1 second of moving history to predict the location in the next 8 seconds. We compare the future path predictions with groud-truth to update the model with NLL-loss. The community implementation also involves Covariance as part of the loss function. Essentially, the training objective is to maximize the likelihood of groud-truth.
2. Evaluation Metrics
Numerical metrics include Minimum Average Displacement Error (minADE), Minimum Final Displacement Error (minFDE), and Miss Rate. Due to the community version of Multipath++ doesn’t include metric calculation, please refer to our Colab Demo in metric implementation. Alternatively, you can check our source code here.
2a. minADE & minFDE
There can be many ways to evaluate motion prediction models. However, it is always essential to keep the predicted trajectory close to the ground truth. Note that motion-prediction tasks often come with multiple ground-truths, and staying close to any of them is sufficient.
Consider time steps from 1 to T, s-hat being the predicted location and s being the ground-truth location.
In minADE, we calculate the averaged l2-norm displacement for each trajectory and pick the smallest value.
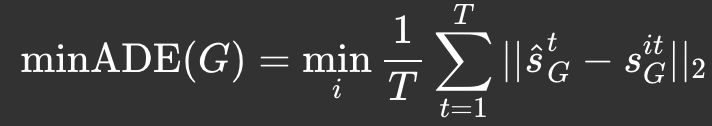
The minFDE metric, on the other hand, only considers the final step displacement.
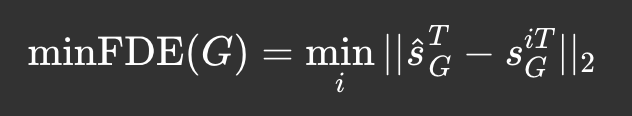
2b. Miss Rate
Oftentimes, vehicles don’t have to stay that close to the ground-truth trajectory. Miss rate is a metric that tolerates errors within a threshold. Empirically, as long as the prediction remains within a threshold, it is “not missed .”Otherwise, the prediction is “missed .”Finally, we report the ratio of missed / (missed + not missed).
On Waymo’s official website, this metric considers both orientational and positional predictions. At the same time, the threshold depends on both the time and initial vehicle speed, as shown below.

MPT: Our Innovation
1. Substitution for Encoders
In this work, we replace the LSTM blocks used in Agent History Encoder and Agent Interaction Encoder with transformer encoders. Specifically, we want to leverage the self-attention mechanism to capture the dependencies among states for each agent of interest. We also hypothesize performance gain from the original architecture due to the inevitable sequential bottleneck in any RNN block.
2. Substitution for Multi-Context Gatings
In addition, we replace the MCG Blocks with transformer encoders. As the input is forwarded in batches containing agents from different scenes, we implemented an iterative method that mimick masked transformer encoder’s behavior. This “masking” is crucial, as agents from different scenes shouldn’t pay attention to each other, inducing unnecessary computational costs.
3. Motion Transformer(MTR)
Prior to this work, transformer architecture has been employed in the trajectory prediction task. One such noticeable work is Motion Transformer(MTR), in which all information available in a scene is encoded and forwarded into a single, expansive transformer network. Our method of employing smaller transformer networks at different abstraction level(for example, roadgraph v.s. target) help localize the attention, resulting in more efficient encoding in terms of computational resource.
4. Result and Visualization Comparison
In this section, we compare model results on 3 metrics in 3 masking configurations (0.05, 0.15, and 0.5). All metrics are the lower the better. We compare two models: MPT is our model that uses Multi-Head Attention inside Multipath++, while LSTM stands for the original Multipath++ baseline.
We train both models using the same data and configurations for 10 epochs and report the result in the last epoch. Due to time and computation resource constraints, we only use 4% of all available training data(from the original Motion Dataset).
4.1 minADE
MPT does better in all settings than the LSTM baseline in minADE.
| Mask | MPT (ours) | LSTM |
|---|---|---|
| 0.05 | 4.030 | 4.181 |
| 0.15 | 4.089 | 4.776 |
| 0.5 | 4.382 | 5.066 |
4.2 minFDE
MPT does better in all settings than the LSTM baseline in minFde.
| Mask | MPT (ours) | LSTM |
|---|---|---|
| 0.05 | 10.777 | 11.343 |
| 0.15 | 10.559 | 12.994 |
| 0.5 | 11.147 | 13.656 |
4.3 Miss Rate
MPT does better when the mask equals 0.05 while LSTM is better in the other two settings.
| Mask | MPT (ours) | LSTM |
|---|---|---|
| 0.05 | 0.309 | 0.316 |
| 0.15 | 0.355 | 0.313 |
| 0.5 | 0.345 | 0.275 |
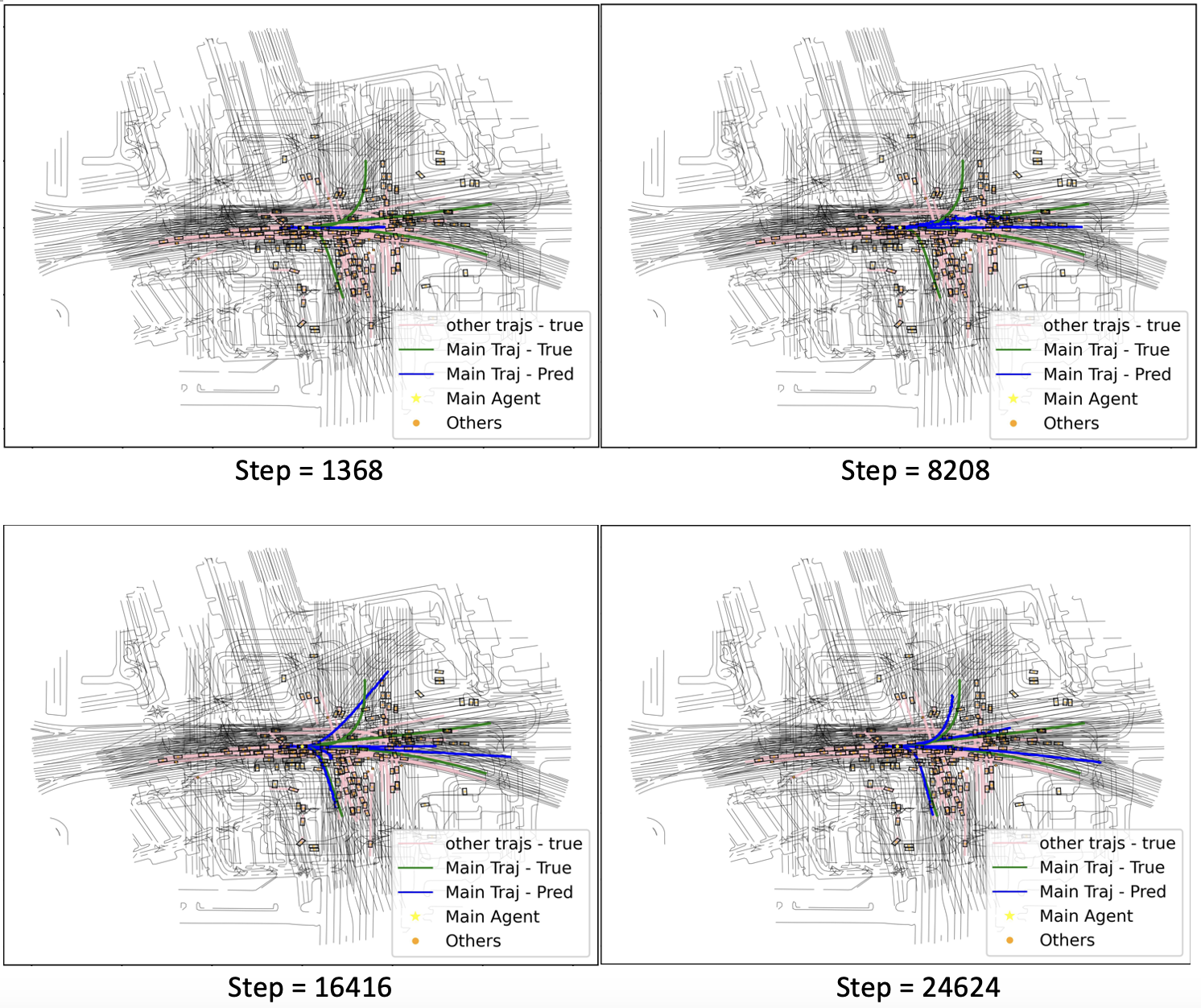
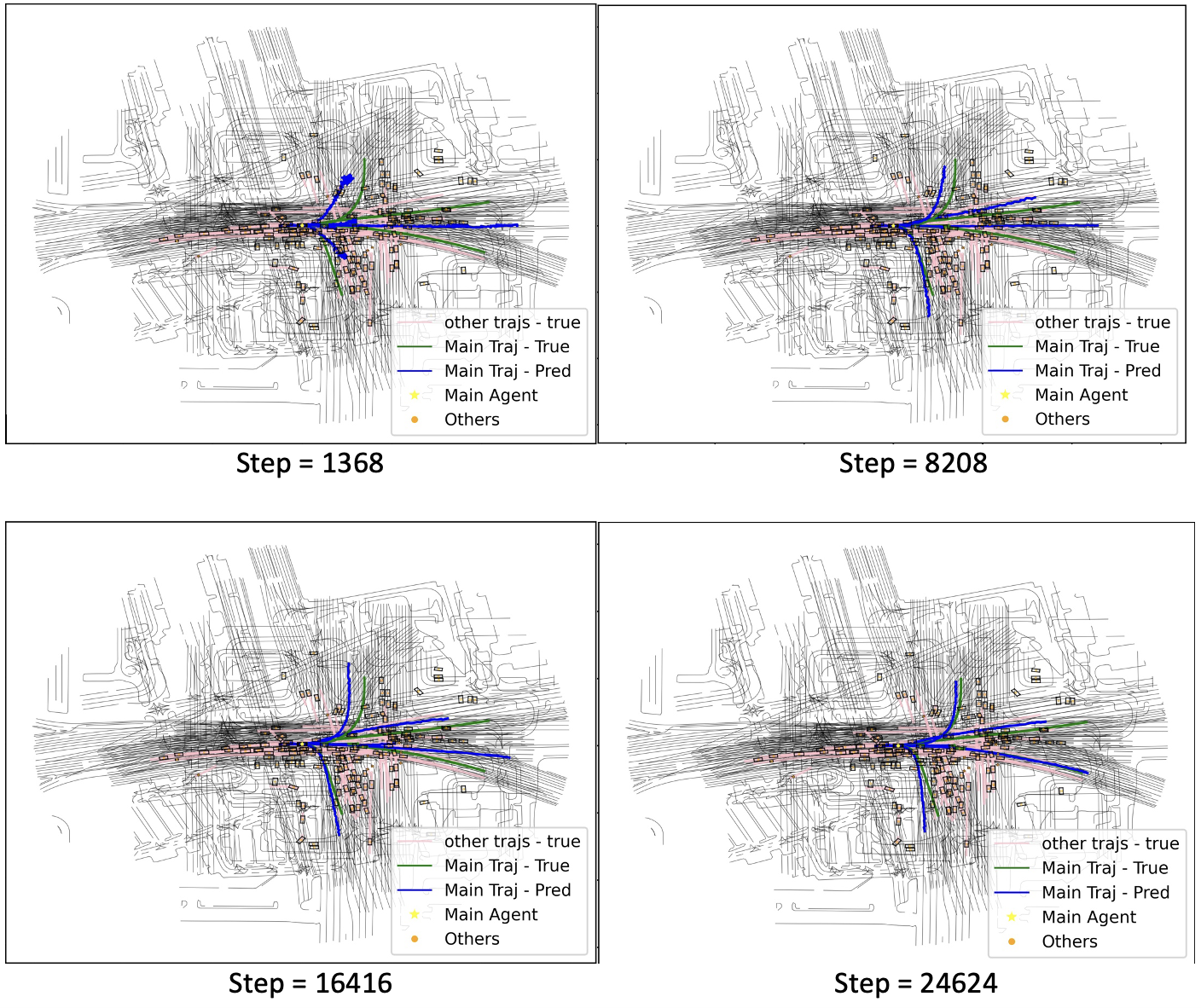
4.4 Scene Visualization
We visualize one scene to provide an empirical comparison between MPT and LSTM. We fix the mask as 0.15 and compare the learning process between the two models.
5. Analysis
As indicated in the figure above, MPT converges faster than the original community implementation of Multipath++ regarding the numerical metrics and visualizations. This improvement stems from the global dependency capturing capability of the attention mechanism that can easily associate states across agents at different timestamps. While the authors of Multipath++ argue MCG Block as an approximation of the attention mechanism, this workaround using MLPs and vector multiplication prove limited in capturing associations in heterogeneous data(differnt types, timestaps, agents, etc.)
Quite counterintuitively, our innovation trains slower than the LSTM + MCG Block design. We argue this is the byproduct of our iterative substitution for masked self-attention: data from different scenes are forwarded into the transformer encoder in a loop. We expect a significant boost in training speed should masked self-attention is implemented in future work.
Conclusion
This article explored previously established works in the trajectory prediction task. We focused on the vectorized representation of the world as proposed in Multipath++. We empirically found significant advantages of transformer architecture over the LSTM and MCG encoders used in the original work. Moreover, we acknowledge the rise in computational burden intrinsic to the transformer architecture, and we conclude that trajectory prediction remains a significant challenge by large.
Reference
[1] Feng, Lan, et al. “TrafficGen: Learning to Generate Diverse and Realistic Traffic Scenarios.” ArXiv, 2022, https://doi.org/10.48550/arXiv.2210.06609. Accessed 29 Jan. 2023.
[2] Varadarajan et al. “MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction.” ArXiv, 2022, https://arxiv.org/abs/2111.14973. Accessed 29 Jan. 2023.
[3]Liang, Ming, et al. “Learning Lane Graph Representations for Motion Forecasting.” ArXiv, 2020, https://doi.org/10.48550/arXiv.2007.13732. Accessed 29 Jan. 2023.
[4] Shi, Shaoshuai, et al. “Motion Transformer with Global Intention Localization and Local Movement Refinement.” ArXiv, 2022, https://doi.org/10.48550/arXiv.2209.13508. Accessed 29 Jan. 2023.
Code Bases
[1] TrafficGen: https://github.com/metadriverse/trafficgen
[2] MultiPath++: https://github.com/stepankonev/waymo-motion-prediction-challenge-2022-multipath-plus-plus
[3] LaneGCN: https://github.com/uber-research/LaneGCN