Anime ViT-StyleGAN2
Generative adversarial network (GAN) is a type of generative nueral network capable of varies tasks such as image creation, super-resolution, and image classifications[1]. This project will explore the usage of GAN model on the specific domain of anime character and try to find improvemnts on current GAN model by using more advanced discriminators.
- Introduction
- A Brief Review of the StyleGAN Architecture
- Further Improvement
- Experiments and Results
- Conclusion and Future Improvement
- Reference
Introduction

Recent progress on anime art generation has sparked a sense of excitement in both the AI and anime community. Many AI generated arts have emerged on the internet. As shown in Fig 1, it is an anime character generated using the online tool WaifuLab[2] which relies on a generator model called GAN. GAN (generative adversarial network) is the base model for many current art generator AIs. The project will explore the usage of GAN on anime character generations and try different variations the discriminator to see the effect of the quality of generated anime styled images. Since the time of this project is limited, the base model used for this project is StyleGan2-ADA, which is the state of art GAN model developed by Karras T. et al and is suitable for using smaller dataset and transfer learning.
A Brief Review of the StyleGAN Architecture
GAN Architecture
GAN is short for generative adversarial network. There are mainly two components in this network: A generator and a descriminator. The generator is responsable for generating “fake” image of the desired type of images, while the descriminator is responsable for telling if the generated images from the generator is the real images that belong to the desired type of image or not. Therefore, in training, the two components are opposing to each other, thus, the model is able to achieve self-supervised, data driven learning.[1]
Style Based Generator
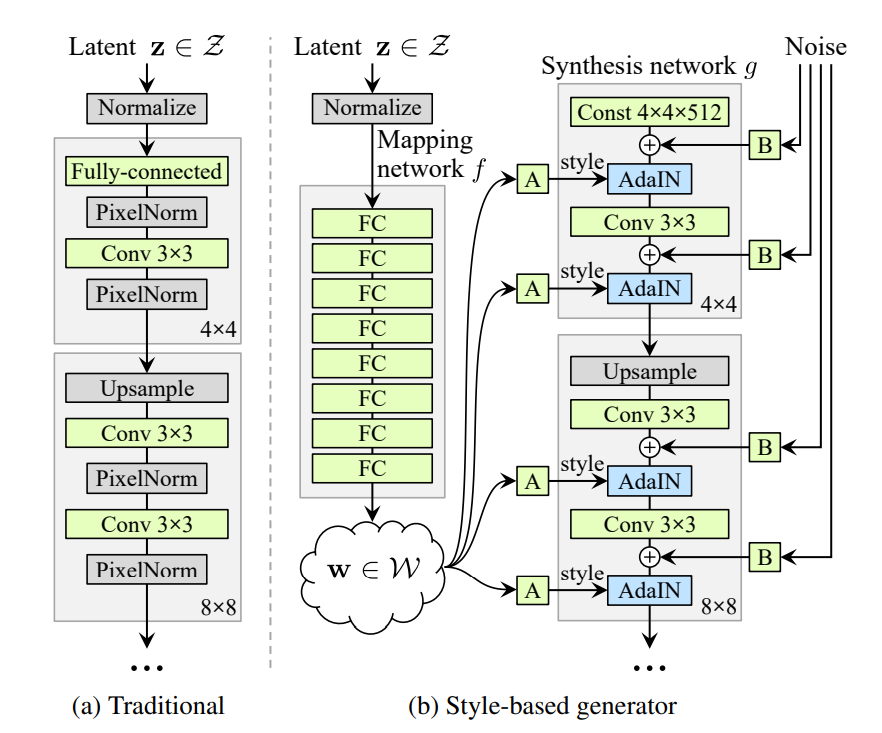
StyleGAN model mainly improves upon the generator components. As illustrated in Figure 2, instead of generating image directly from latent code, the latent code \(z\) is first transformed by the mapping layer consists of fully connected layers into new latent code \(w\), then through affine matrix transformation \(A\), \(w\) is converted into “style”: \(y=(y_s, y_b)\). \(y\) is then mixed into the synthesis network via \(AdaIN\) operation[3]:
From the equation, the feature map \(x\) is first normalized, then the corresponding scale and bias is applied from the style. From the archetecture, each genearted image is based on a collection of style drew from the image samples.[3] This property of the StyleGan is particularly useful for anime character generation, as anime has unique art style and forms a distinct domain. As also described in the paper, “each styles can be expected to affect only certain aspect of the image”, the architecture is capable of generating desired styled anime character as well.
Adaptive Discriminator Augmentation
The ADA in the name stands for adaptive discriminator augmentation. This is useful for training StyleGAN on small data sets to prevent overfit. Data augmentation is performed on images generated by the generator before feeding into discriminator. The augmentation strength is controlled by the degree of overfitting, hence the method is adaptive.[5] This is useful for the purpose of this project, as collecting large anime pictures and training on large dataset is not feasable because of time constrains and hardware limitations.
Further Improvement
Alternative Discriminators
From the previous section, the StyleGAN2-ADA already has nice properties suitable for training anime style image generative model. The improvement mainly focused on the generater, but it is also important to explore alternative discriminators. The baseline StyleADA2 uses ResNet as the backbone architecture for its discriminator. ResNet is known to be the state of the art CNN models suitable for the classification task[8] here(which is the binary classifcation task of discriminating if the input images are fake or real). Recently, the self-attention model ViT(vision transformer) emerges and shown that it can be better than the Resnet architecture in various image classification tasks[6].
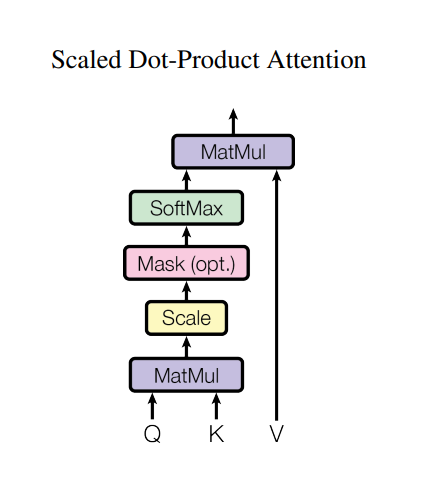
Through self attention mechnism, ViT achieve a global view of the image even in the few earlier layers instead of relying on local features in ResNet(due to convolution operations). This might be helpful in the animate domain, as the intrinsic consistancy of art style and body orientation from the distanced parts of the images is also important for a descent anime style arts.
Attention
The original ViT attention score is computed by:
Where \(W_q\), \(W_k\), and \(W_v\) are projection matrix for \(Q\), \(K\), and \(V\). However, in GAN, it has been shown that the Lipschitz continuity is crucial for the model to reach Nash equilibrium, while the standard dot product voilates the Lipschitz continuity and makes the training unstable. According to the paper “ViTGAN: Training GANs with Vision Transformers”, it is necessary to use L2 attention score calculcation instead of standard dot product to enforce the Lipschitz continuity:
Where \(W_q = W_k\), and \(W_v\) are projection matrix for \(Q\), \(K\), and \(V\) respectively. The dot product is replaced by L2 distance in the formula[10].
Spectual Normalization
The paper “ViTGAN: Training GANs with Vision Transformers” also suggests to further improve the Lipschitz continuety by using spectual normalization on \(W_q\), \(W_k\) and \(W_v\):
The matrix is normaized using the maximum singular value of the matrix (denoted by \(\sigma(.)\)) and multiply by the maximum singular value during initialization. The normalized weight further prevents the unstable training problem[10].
Code Implementation
The modfified ViT discriminator is adapted from the original ViTGAN code repository and integrated into the official pytorch implementation of StyleGAN2. The ViT discriminator version of the StyleGAN2 is implemented and can be found in this code repository. There were several issues that occured during integration. The major one was related to image patches. To better relate each image patch to each other, unlike the tranditional ViT, the patches have overlaps. This step was not implemented corretly in the original repository and had to be changed in order for it to work properly. Below are the changed code for the initial step of getting image patches:
img_patches = img.unfold(2, self.patch_size, self.stride).unfold(3, self.patch_size, self.stride)
Experiments and Results
Dataset

All experiment will use a relatively small dataset obtained from Kaggle consists of 2434 \(256\times256\) anime faces of different styles. The dataset is first converted to .jpg format and preprocessed by using the dataset_tool.py utilities provided in the StyleGAN2-ADA code repository.
Training Environment
All model will be trained on a single Tesla T4 GPU, using docker environment provided in the code repository.
Baseline Results

The above results are obtained by doing transfer learning using the original StyleGAN2 model and the model is trained for ~800K iterations. The base model used is the pretrained ffhq-256 model from NVIDIA which generate realistic human faces(a completely different domain from anime).
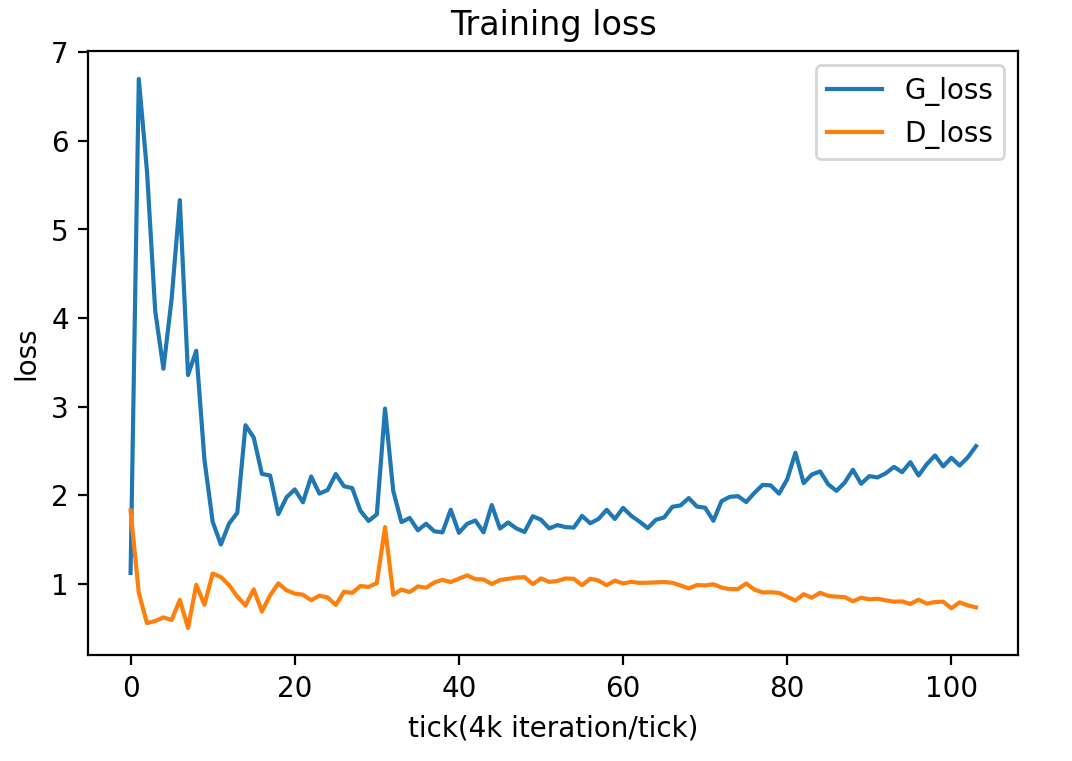

The above results are abtained using the default unmodified paper256 config of StyleGAN2. The outputs were obtained after ~400k iterations.
ViT Discriminator Results
There are several attempts to train using the same dataset with the ViT discriminator and the original paper256 config generator. Below is a brief overview of the generator layers:
Generator Parameters Buffers Output shape Datatype
--- --- --- --- ---
mapping.fc0 262656 - [32, 512] float32
mapping.fc1 262656 - [32, 512] float32
mapping.fc2 262656 - [32, 512] float32
mapping.fc3 262656 - [32, 512] float32
mapping.fc4 262656 - [32, 512] float32
mapping.fc5 262656 - [32, 512] float32
mapping.fc6 262656 - [32, 512] float32
mapping.fc7 262656 - [32, 512] float32
mapping - 512 [32, 14, 512] float32
synthesis.b4.conv1 2622465 32 [32, 512, 4, 4] float32
synthesis.b4.torgb 264195 - [32, 3, 4, 4] float32
synthesis.b4:0 8192 16 [32, 512, 4, 4] float32
synthesis.b4:1 - - [32, 512, 4, 4] float32
synthesis.b8.conv0 2622465 80 [32, 512, 8, 8] float32
synthesis.b8.conv1 2622465 80 [32, 512, 8, 8] float32
synthesis.b8.torgb 264195 - [32, 3, 8, 8] float32
synthesis.b8:0 - 16 [32, 512, 8, 8] float32
synthesis.b8:1 - - [32, 512, 8, 8] float32
synthesis.b16.conv0 2622465 272 [32, 512, 16, 16] float32
synthesis.b16.conv1 2622465 272 [32, 512, 16, 16] float32
synthesis.b16.torgb 264195 - [32, 3, 16, 16] float32
synthesis.b16:0 - 16 [32, 512, 16, 16] float32
synthesis.b16:1 - - [32, 512, 16, 16] float32
synthesis.b32.conv0 2622465 1040 [32, 512, 32, 32] float16
synthesis.b32.conv1 2622465 1040 [32, 512, 32, 32] float16
synthesis.b32.torgb 264195 - [32, 3, 32, 32] float16
synthesis.b32:0 - 16 [32, 512, 32, 32] float16
synthesis.b32:1 - - [32, 512, 32, 32] float32
synthesis.b64.conv0 1442561 4112 [32, 256, 64, 64] float16
synthesis.b64.conv1 721409 4112 [32, 256, 64, 64] float16
synthesis.b64.torgb 132099 - [32, 3, 64, 64] float16
synthesis.b64:0 - 16 [32, 256, 64, 64] float16
synthesis.b64:1 - - [32, 256, 64, 64] float32
synthesis.b128.conv0 426369 16400 [32, 128, 128, 128] float16
synthesis.b128.conv1 213249 16400 [32, 128, 128, 128] float16
synthesis.b128.torgb 66051 - [32, 3, 128, 128] float16
synthesis.b128:0 - 16 [32, 128, 128, 128] float16
synthesis.b128:1 - - [32, 128, 128, 128] float32
synthesis.b256.conv0 139457 65552 [32, 64, 256, 256] float16
synthesis.b256.conv1 69761 65552 [32, 64, 256, 256] float16
synthesis.b256.torgb 33027 - [32, 3, 256, 256] float16
synthesis.b256:0 - 16 [32, 64, 256, 256] float16
synthesis.b256:1 - - [32, 64, 256, 256] float32
--- --- --- --- ---
Total 24767458 175568 - -
However, due to hardware limitation and time constraints, neither attempt gave optimal results. To train the model, adam optimizer is used for both generator and discriminator, initially with a learning rate of 0.0025 which was shown to be too high. As each 1k iterations takes over 4 mins to train, it is very hard to find optimal hyperparameters for the new model given the time and budget constraints for this project. Below are some attempts over the course of over one week.
Initial Attempt
This attempt was before changing the image patch bug, therefore, no meaningful learning was achieved.

The above result show the failed first attempt output after 1403k iterations of training. No meaningful image was produced, as there was an error in the discriminator image patching step.
Second Attempt
This attempt fixed the image patches generation with learning rate of 0.0025 set for both discriminator and generator. As the learning rate was set too high for the ViT discriminator, the training failed as well. The ViT discriminator was not optimized. Below is the ViT archetecture used for this attempt:
ViTDiscriminator Parameters Buffers Output shape Datatype
--- --- --- --- ---
project_patches 746928 - [32, 225, 432] float32
emb_dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.0.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.0.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.0.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.0.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.0.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.0 - - [32, 226, 432] float32
Transformer_Encoder.blocks.1.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.1.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.1.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.1.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.1.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.1 - - [32, 226, 432] float32
Transformer_Encoder.blocks.2.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.2.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.2.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.2.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.2.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.2 - - [32, 226, 432] float32
Transformer_Encoder.blocks.3.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.3.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.3.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.3.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.3.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.3 - - [32, 226, 432] float32
Transformer_Encoder.blocks.4.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.4.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.4.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.4.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.4.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.4 - - [32, 226, 432] float32
Transformer_Encoder.blocks.5.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.5.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.5.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.5.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.5.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.5 - - [32, 226, 432] float32
Transformer_Encoder.blocks.6.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.6.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.6.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.6.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.6.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.6 - - [32, 226, 432] float32
Transformer_Encoder.blocks.7.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.7.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.7.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.7.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.7.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.7 - - [32, 226, 432] float32
Transformer_Encoder.blocks.8.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.8.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.8.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.8.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.8.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.8 - - [32, 226, 432] float32
Transformer_Encoder.blocks.9.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.9.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.9.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.9.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.9.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.9 - - [32, 226, 432] float32
mlp_head.0 864 - [32, 432] float32
mlp_head.1 433 - [32, 1] float32
<top-level> 98064 - [32, 1] float32
--- --- --- --- ---
Total 23284369 0 - -
The ViT discriminator is configured to have a patch size of 16 with the extended(overlap with nearby patches) size of 4, each patch is projected to a vector of dim 432. There are 10 transformer encoder block each with a attention block of 6 heads (dimention of the head remain the same size of the patch vector). Minibatch size is set to be 32. The learning rate is set to be 0.0025 which is shown to be too high for the ViT discriminator.
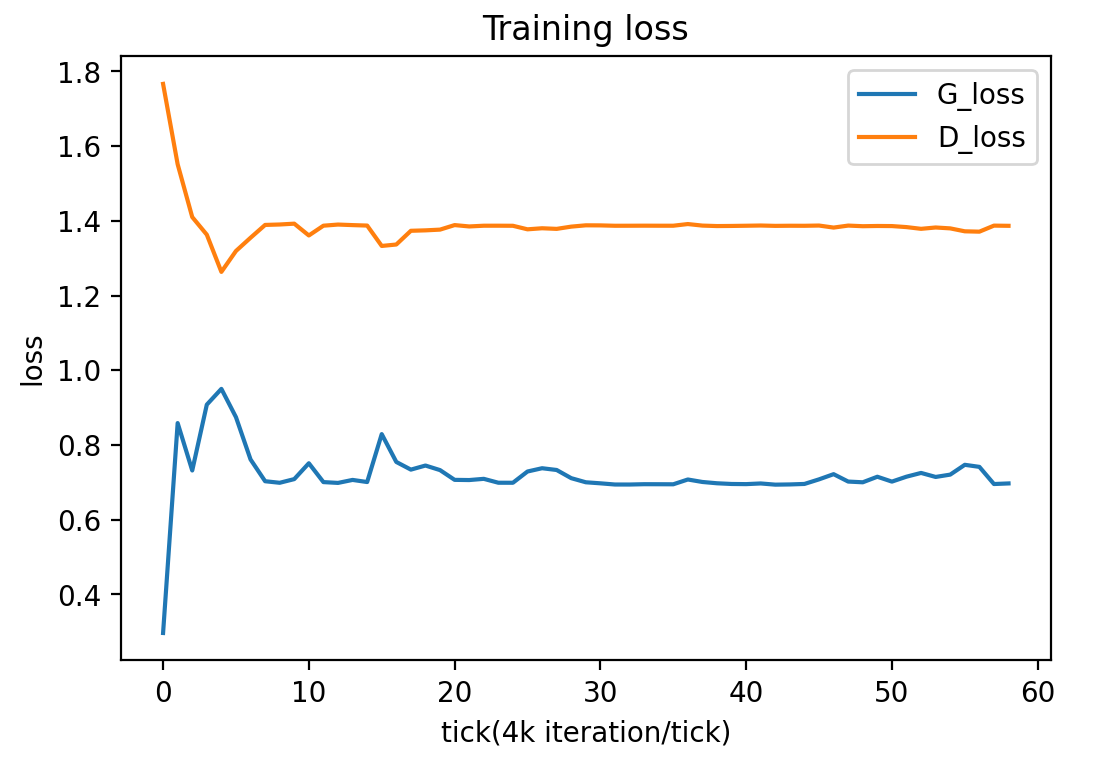

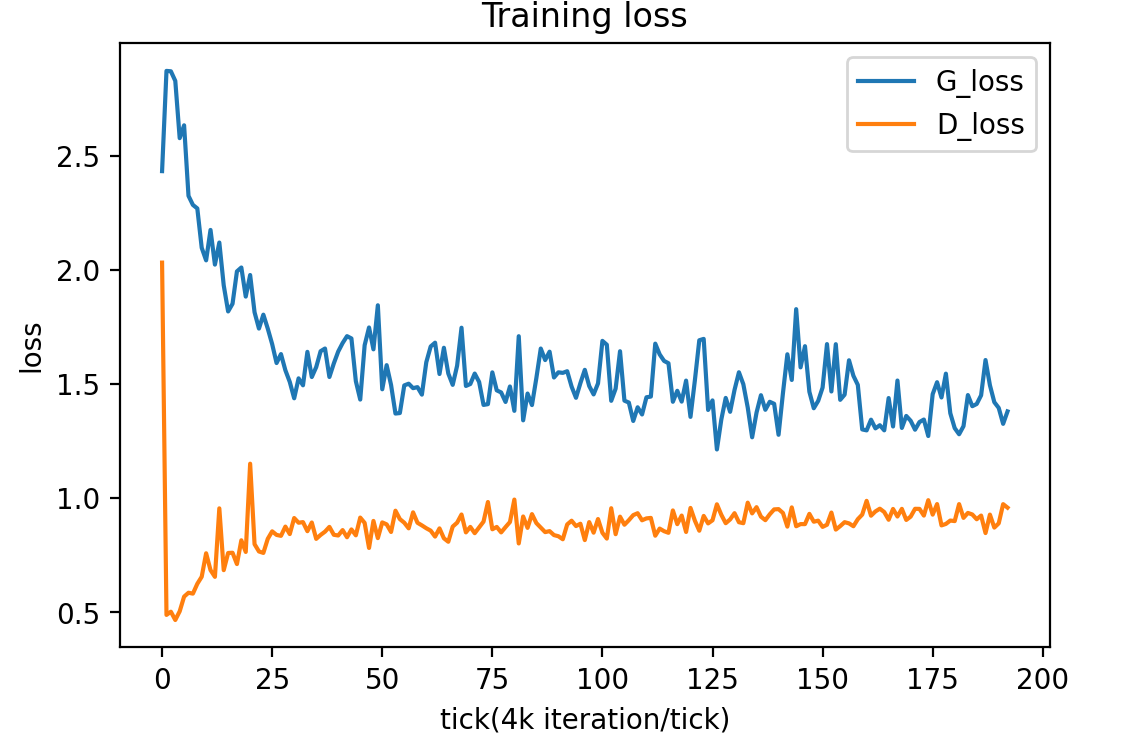
Similar to attempt one, as shown in the above figure, no meaningful image was generated even after ~200k iterations, also noticed from the training loss, the discriminator suffered from a training failure, indicated by a much higher loss than the generator loss. Therefore, it is necessary to change the learning rate which leads to attempt 3.
Third Attempt
This attempt fix the learning rate issue by changing the learning rate for the discriminator to 0.0002, while keeping the learning rate for generator as 0.0025. The ViT discriminator was also slightly changed to have only 6 transformer blocks instead of 10 while keeping the rest of the configurations the same as the second attempt:
ViTDiscriminator Parameters Buffers Output shape Datatype
--- --- --- --- ---
project_patches 746928 - [32, 225, 432] float32
emb_dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.0.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.0.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.0.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.0.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.0.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.0 - - [32, 226, 432] float32
Transformer_Encoder.blocks.1.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.1.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.1.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.1.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.1.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.1 - - [32, 226, 432] float32
Transformer_Encoder.blocks.2.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.2.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.2.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.2.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.2.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.2 - - [32, 226, 432] float32
Transformer_Encoder.blocks.3.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.3.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.3.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.3.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.3.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.3 - - [32, 226, 432] float32
Transformer_Encoder.blocks.4.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.4.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.4.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.4.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.4.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.4 - - [32, 226, 432] float32
Transformer_Encoder.blocks.5.norm1 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.5.attn 746928 - [32, 226, 432] float32
Transformer_Encoder.blocks.5.dropout - - [32, 226, 432] float32
Transformer_Encoder.blocks.5.norm2 864 - [32, 226, 432] float32
Transformer_Encoder.blocks.5.mlp 1495152 - [32, 226, 432] float32
Transformer_Encoder.blocks.5 - - [32, 226, 432] float32
mlp_head.0 864 - [32, 432] float32
mlp_head.1 433 - [32, 1] float32
<top-level> 98064 - [32, 1] float32
--- --- --- --- ---
Total 14309137 0 - -
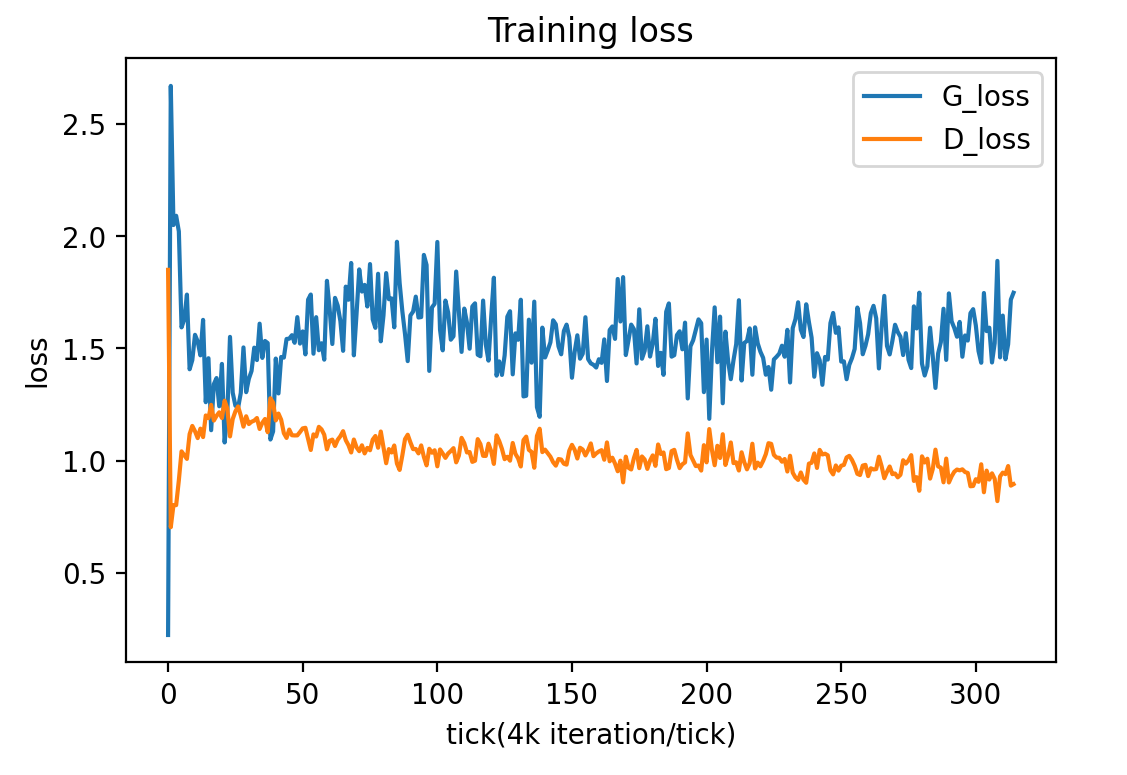

From figure 9.1, the generator was able to generate some meaningful output after over 1000k iterations. However, not only the quality of the generated image is not ideal even compared to Fig 6.1 with a much higher FID score, it also suffers from a mode collapse. The generators learned to generate a few sets of the same faces to fool the discriminator, and the discriminator was unable to learn out of this trap from the generator.
Evaluation and Analysis
From the above attempt, we can see that for a relatively small dataset, it is very hard to properly train a GAN model with ViT discriminator even after making necessary modeification of the original ViT. But from the training curve, we can see that the training is relatively stable with the modification, but there are still requirements of training GAN that might not be satisfied by the above experiments:
- The ViT model might not have the same model capacity as the generator, therefore, the the model might tend to suffer from mode collapse.
- The learning rate of the discriminator and the generator need to be carefully chosen to successfully train the model, but the above experiments might be using suboptimal learning rates.
- Training ViT typically works better on larger datasets. With a dataset of only ~3000 images, it is very hard to train the ViT properly from scratch as ViT lacks the inductive bias that convolution based model such as ResNet has.
Conclusion and Future Improvement
The generated anime faces is generally worse than the results obtained from the original archetecture. With limited time and computation budget, it is very hard to train a StyleGAN2 model with ViT discriminator from scratch using a small dataset dispite all the augmentation strategies implemented. It is possible to get better results if better hyperparameters for the model and the optimizer is chosen. It is also possible to get better results if a much larger dataset is used. But all the above options require significantly more computing power. Although, the original goal of improving the quality of generating better anime faces given the nature of ViT is not achieved, the study showed and verified some important properties of StyleGAN2 with ViT discriminator, such as the requirement of different learning rate for generator and discriminator due to different achitecture, requirements of large dataset and longer training time to train ViT as ViT lacks inductive bias, and requirments of a similar model capacity for the generator and the discriminator.
To further improve the result, a proper hyperparameter search needs to be implemented to find better hyperparameters for the model. Also, a larger dataset is needed to train ViT based model from scratch. ViT based generator is also another good option for improvement as suggested by Kwonjoon L. et al.[10].
Reference
[1] Creswell A., White T., et al. “Generative Adversarial Networks: An Overview” in IEEE Signal Processing Magazine, vol. 35, no. 1, pp. 53-65, Jan. 2018, doi: 10.1109/MSP.2017.2765202.
[2] Liu, R. “Welcome to Waifu Labs v2: How do AIs Create?”, Jan, 2022. Retrieved from: https://waifulabs.com/blog/ai-creativity
[3] Karras T., Laine S. & Alia T. “A Style-Based Generator Architecture for Generative Adversarial Networks”
[4] Karras T., et al. “Analyzing and Improving the Image Quality of StyleGAN”
[5] Karras T., Aittala M., et al. “Training Generative Adversarial Networks with Limited Data”
[6] Dosovistskiy A., et al. “AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE”
[7] Vaswani A., et al. “Attention is All You Need”
[8] Kaiming H., et al. “Deep Residual Learning for Image Recognition”
[9] Han Z. et al. “Self-Attention Generative Adversarial Networks”
[10] Kwonjoon L. et al. “ViTGAN: Training GANs with Vision Transformers”