Understanding GPT-4o: Capabilities, Trade-offs, and Real-World Utility
This blog aims to provide a comprehensive analysis of GPT-4o by examining both its technical architecture and real-world usability. It explores GPT-4o’s multimodal capabilities—spanning text, image, and audio processing—and situates them within the broader evolution of reasoning-enhanced and multimodal language models. Through a combination of literature review, system-level speculation, and a user survey of early adopters, the blog investigates how GPT-4o is actually used in practice, what trade-offs it introduces in terms of speed, reasoning fidelity, and interactivity, and whether its multimodal design represents a genuine leap or a transitional phase in LLM development. Ultimately, it seeks to bridge the gap between technical potential and lived user experience, offering insights into the future trajectory of multimodal AI systems.
- 1. Introduction
- 2. Technical Background
- 3. User Survey: How Are People Actually Using GPT-4o?
- 4. Under the Hood: Hypothesizing the Architecture of GPT-4o
- 5. GPT-4o vs GPT-4 Turbo: What Changed?
- 6. Conclusion: Efficient, Unified, But Still Evolving
- 7. Future Work
- 8. Reference
1. Introduction
Since its release in May 2024, GPT-4 [1] has attracted widespread attention as OpenAI’s first truly multimodal model, capable of processing text, images, and audio seamlessly in real time. Marketed as faster, more affordable, and more interactive than its predecessors, GPT-4o also became the first GPT-4-class model made available to free tier users, marking a major shift in accessibility and user expectations.
But as the hype settles, important questions arise: How do people actually use GPT-4o? Is its multimodal ability just a novelty, or a real need? How does it compare to past versions in practical use? To better understand its impact, I conducted a small-scale user survey, asking people how often they use GPT-4o’s different modalities and how useful they find them in daily tasks.
In this blog, I present insights from that survey alongside a broader discussion of GPT-4o’s potential internal architecture, performance trade-offs, and reasoning abilities. By combining technical context with user perspectives, I aim to explore not just what GPT-4o can do, but what people are actually doing with it, and whether multimodality is the future of LLMs or just a stepping stone.
2. Technical Background
In parallel with the rise of general-purpose LLMs, there has been significant progress in reasoning-enhanced language models, which aim to solve complex tasks through multi-step, interpretable chains of logic. Approaches like Chain-of-Thought prompting [2], Tree-of-Thoughts [3], and Program-aided Language Models [4] enable models to decompose tasks into subgoals, improving performance on mathematical reasoning [5], symbolic manipulation [6], and multi-hop QA tasks [7]. These reasoning-focused paradigms have become essential in pushing LLMs toward higher factual accuracy and interpretability, especially when combined with reinforcement learning techniques [8].
Simultaneously, multimodal generation has emerged as a central direction in frontier AI systems, extending the capabilities of LLMs beyond pure text. Recent models like Flamingo [9], Kosmos-2 [10], Gemini 1.5 [11], and Claude 3 [12] demonstrate impressive results in cross-modal understanding and generation, enabling applications in visual QA, diagram interpretation, and image-conditioned storytelling [13]. Additionally, systems such as GILL [14] and LLaVA [15] show how visual context can enhance reasoning and factual consistency, particularly in open-ended generative tasks.
The convergence of multimodal inputs with structured reasoning not only expands the functional reach of LLMs, but also introduces new challenges in efficiency, inference latency, and interpretability—areas where models like GPT-4o aim to strike a balance through optimization and system-level integration [1, 16].
3. User Survey: How Are People Actually Using GPT-4o?
To better understand GPT-4o’s real world impact, especially its multimodal capabilities, I conducted an online survey with 34 participants, the majority of whom are college students who use AI tools frequently in their academic or creative work.
3.1. Participant Overview
- 34 total respondents
- 27 are current college students
- 21 actively use OpenAI products
- 18 said they default to GPT-4o when using ChatGPT
This audience represents a group of highly engaged AI users, ideal for exploring how GPT-4o is being adopted in practice.
3.2. Survey Questions and Responses
3.2.1. “How do you feel about GPT-4o’s multimodal capabilities?”
- Most respondents acknowledged the innovation, but only a few found themselves using multimodal features regularly.
- Common sentiments:
- “It’s cool but I forget it exists.”
- “I mostly use it like a regular text chatbot.”
- “Image input is useful for graphs or screenshots, but I haven’t used audio or video.”
3.2.2. “How often do you use the image/voice/video input features?”
- Image input: ~35% said they had used it occasionally, especially for interpreting visuals (e.g., math problems, diagrams).
- Voice input: Only about 15% had tried it, mostly out of curiosity.
- Video: Usage was almost nonexistent. Most users weren’t even aware of this capability or said it felt awkward to use in practice.
3.2.3. “How do you rate its reasoning ability compared to earlier models?”
- Most users described GPT-4o as on par or slightly better than GPT-4-turbo in speed and responsiveness.
- However, around 20% noted occasional lapses in logical reasoning or hallucinations that felt more noticeable than with GPT-4.
- Comments included:
- “It answers faster but sometimes seems less careful.”
- “Great for brainstorming, but I double check it for factual stuff.”
Multimodal usage is limited, even among highly active users. While image inputs have found niche use cases, voice and video modes are still underutilized, likely due to lack of habit, technical friction, or unclear benefits in most workflows.
GPT-4o is appreciated for its speed and free tier availability, but users are mixed on whether its reasoning ability is an upgrade from previous versions.
Overall, users treat GPT-4o like a faster, more accessible version of GPT-4, but the promise of multimodality hasn’t yet translated into widespread behavior change.
4. Under the Hood: Hypothesizing the Architecture of GPT-4o
While OpenAI has not released detailed architecture documentation for GPT-4o, we can piece together a plausible structure based on available demos, past papers (like Whisper and GPT-4), and community reverse engineering.
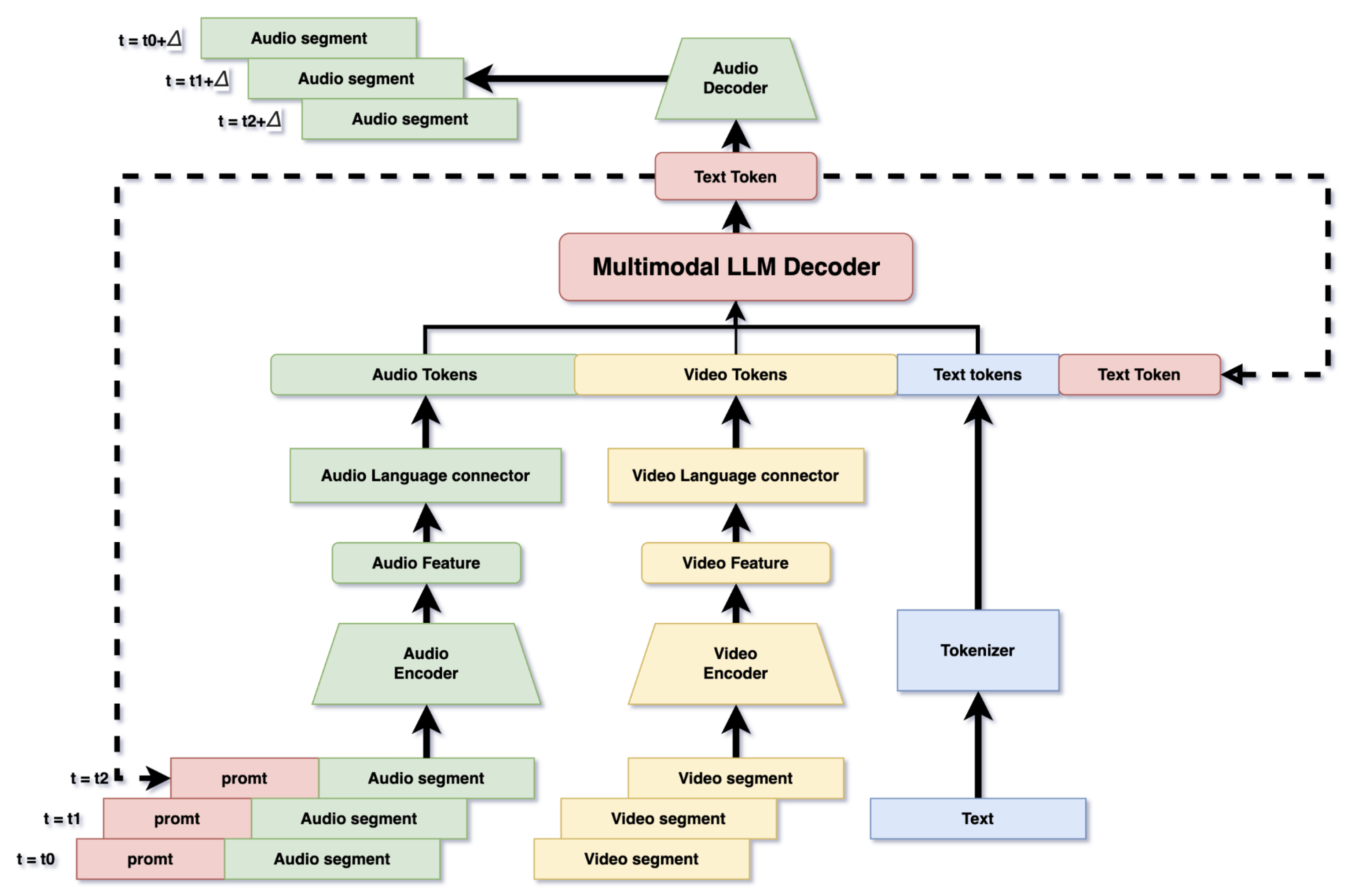
Fig. 1: GPT-4o Architecture.
4.1. Decoder Core: Text First Autoregression
- GPT-4o behaves like a traditional autoregressive language model for text input:
- Text is tokenized and passed into a stack of transformer decoders (no encoder-decoder cross attention).
- Tokens are decoded one by one, with each output token appended to the input stream and shifted right.
- Positional encoding is required to preserve order.
- Likely optimizations:
- Highly efficient attention implementations (e.g., FlashAttention-style)
- Parallel token streaming
- Memory reuse and fused operations
4.2. Audio Input: Streaming, Segment Based Processing
- GPT-4o can process long, uninterrupted audio without pauses.
- Input is chunked into audio segments over time (e.g., every 0.1 seconds).
4.2.1. Audio Processing Flow:
- Audio Encoder: Receives a segment and extracts low-level audio features (phonemes, speaker tone, etc.) using convolutional or transformer layers.
- Audio Language Connector: Maps continuous audio features into discrete audio tokens, making them compatible with the LLM token space.
- MLLM Decoder: Combines audio tokens with prior text tokens (which act as prompts or context) and outputs the next text token.
This is similar to Whisper, where past outputs are used as prompts for contextual understanding. In GPT-4o, it’s likely these text prompts provide continuity and memory between audio segments.
4.3. Voice Output: Cascaded System?
- The model likely still uses a cascade system for audio output.
- The audio decoder takes the generated text tokens and converts them into synthetic audio segments, which are concatenated to produce fluent speech.
- The voice styles are fixed, indicating it’s not personalized or generated from raw latent speech representations (yet).
4.4. Why Text as the Central Output?
- Text is computationally cheap to generate and easy to post-process.
- LLMs are deeply trained on language; leveraging this avoids retraining entire modalities from scratch.
- Downstream systems (like voice synthesis) can easily operate off text output.
5. GPT-4o vs GPT-4 Turbo: What Changed?
| Feature | GPT-4 Turbo | GPT-4o |
|---|---|---|
| Input Modalities | Text, Images (GPT-4V only) | Text, Images, Audio (real-time) |
| Output | Text only | Text + Voice (streamed audio) |
| Speed | Moderate | Much faster (lower latency) |
| Reasoning | Very strong | Slightly below GPT-4 Turbo in some benchmarks |
| Availability | Paid tier only | Free for everyone (limited) |
| Use Cases | Research, complex tasks | Conversational, interactive AI |
| Architecture | Likely text decoder only | Multimodal LLM decoder |
6. Conclusion: Efficient, Unified, But Still Evolving
- GPT-4o seems to follow a modular but unified pipeline:
- Different encoders for audio and video.
- A single multimodal transformer decoder that processes tokenized representations from all modalities.
- A text focused generation core, possibly connected to legacy systems for voice output.
This design explains GPT-4o’s responsiveness and versatility, but also its current limitations, such as lack of real time video output or fully personalized speech.
7. Future Work
Looking ahead, the integration of multimodality will increasingly become native to foundational models, as exemplified by emerging systems such as Gemini and Grok. These models are no longer merely adding modalities onto existing language frameworks but are being designed from the ground up to process and reason across text, images, audio, and video in a unified manner. This shift signifies a broader transition toward truly native multimodal architectures, where all modalities are treated as first-class citizens during training and inference.
At the application level, multimodal agent systems are poised to become the dominant framework. These agents will not only perceive and interpret inputs from multiple modalities but also act autonomously in complex, dynamic environments. By combining perception, memory, and decision-making across modalities, multimodal agents will power next-generation applications in digital assistants, robotics, creative tools, and scientific research.
In parallel, the focus of multimodal intelligence will evolve from simple modality fusion to deeper multimodal reasoning. Instead of merely aligning or combining features from different sources, future models will be expected to infer causal relationships, perform abstract reasoning, and maintain consistent semantic understanding across modalities. This requires breakthroughs in architecture design, training paradigms, and data construction.
As a result of these advancements, evaluation standards for multimodal models will need to be redefined. Traditional metrics that assess isolated capabilities within individual modalities will no longer suffice. Instead, future benchmarks must test cross-modal consistency, reasoning depth, and generalization ability across diverse tasks and scenarios. Comprehensive, robust, and aligned evaluation frameworks will be essential to accurately reflect the true intelligence of multimodal systems.
8. Reference
[1] OpenAI, “GPT-4o Technical Report,” 2024.
[2] Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” NeurIPS, 2022.
[3] Yao et al., “Tree of Thoughts: Deliberate Problem Solving with Large Language Models,” arXiv:2305.10601, 2023.
[4] Chen et al., “Program-Aided Language Models,” NeurIPS, 2022.
[5] Lewkowycz et al., “Solving Quantitative Reasoning Problems with Language Models,” arXiv:2206.14858, 2022.
[6] Zhang et al., “Symbolic Reasoning with Large Language Models,” arXiv:2303.09014, 2023.
[7] Khot et al., “Decomposed Prompting: A Modular Approach for Solving Complex Tasks,” EMNLP, 2022.
[8] Ziegler et al., “Fine-Tuning Language Models from Human Preferences,” ICLR, 2020.
[9] Alayrac et al., “Flamingo: A Visual Language Model for Few-Shot Learning,” DeepMind, 2022.
[10] Huang et al., “Language Is Not All You Need: Aligning Perception with Language Models,” Microsoft Research, 2023.
[11] Google DeepMind, “Gemini 1.5 Technical Report,” 2024.
[12] Anthropic, “Claude 3 Model Family,” 2024.
[13] Wang et al., “StoryDALL-E: Adapting Pretrained Text-to-Image Models for Story Continuation,” ICML, 2023.
[14] Dai et al., “GILL: Grounded Image-Language Learning with Multimodal Feedback,” arXiv:2305.12556, 2023.
[15] Liu et al., “Visual Instruction Tuning,” arXiv:2304.08485, 2023.
[16] OpenAI, “GPT-4o System Card,” 2024.