Safeguarding Stereotypes - an Exploration of Cultural and Social Bias Mitigation in Large Language Models
Large Language Models (LLMs) have become central to modern AI applications, from education to customer service and content generation. Yet with their widespread use comes growing concern about how they encode and reproduce racial, gender, religious, and cultural stereotypes. This paper explores the presence of social biases in LLMs through a review of definitional frameworks, statistical and benchmark-based evaluation techniques, and bias mitigation strategies. Key benchmarks such as StereoSet, CrowS-Pairs, and BLEnD are examined for their effectiveness in identifying and quantifying stereotypical behavior. Mitigation strategies—including data filtering, Reinforcement Learning from Human Feedback (RLHF), and Anthropic’s Constitutional AI—are evaluated across leading models like ChatGPT, Gemini, and Claude. Finally, an experiment using stereotype-sensitive prompt completions reveals significant differences in how these three models respond to socially loaded questions. The findings suggest that while technical safeguards are increasingly effective at identifying stereotypes, the definition of “valid” responses are different across models. This work provides a high level comparative lens on how today’s most widely used LLMs handle stereotypes, both in theory and in practice.
- Introduction
- Defining LLM Bias and Stereotypes
- Benchmarks
- Risk Mitigation Methods
- Experiment
- Results
- Conclusion
Introduction
Large Language Models, or LLM’s, have taken the world by storm in recent years. In this new age of AI, LLM’s are used for a broad range of tasks and applications, from online service chat agents to serve customer needs, to generating educational content to enrich school teachers’ curriculums. Additionally, these large language models can even be combined with other modalities such as video or audio generation. The broad application of LLM’s demonstrates the substantial impact that generative AI has on the world today, used by millions of people around the world. This wide reaching social impact is relevant when considering the topic of racial, religious, and other stereotypes within the model space. While many of the top LLM’s serving users have enacted tight safeguard policies, studies have shown that the LLM training process inherently produces bias within the models. This paper will engage with the definitions of stereotypes and bias, introduce some key ways to evaluate LLM’s for social bias through benchmarking, and discuss current and future approaches to addressing stereotypes within LLM produced outputs. It will also explore how ChatGPT, Gemini, and Anthropic Claude, some of the most popular models in use today, react to stereotypical prompts, aiming to provide a small-scale insight into the safeguards put in place.
Defining LLM Bias and Stereotypes
Before diving into deep discussion on techniques to mitigate stereotypes within LLM’s, it is important to frame the context behind LLM development. Societal values and cultural norms are inherently tied to language, and thus the training corpus of LLM’s is vital in influencing its behavior. Culture can be defined as a collective of thought, emotions, and behavior that aligns and differentiates human subcircles. [4] When LLM’s propagate language tied to its training material, the biases behind that language is inherently present in the model. For example, stereotypes have been shown to be present since the early days of LLM development, such as in the development of word2vec. [5] A majority of large language models today are trained on materials scraped from the internet, which can come from predominantly Western domains. The result of this linguistic imbalance in the datasets for training these models is clear: a consistent value system centered on American culture. [4] Even when the discussion is centered on cultural imports into LLM’s, there are different frameworks for identifying proxies of culture. For example, demographic proxies identify culture as a ethnic or geographically grouped level of community. These proxies could attribute culture to nationality, such as “Thai culture.” Another definition of culture is through semantic groups, or communities that share the same ethics and values, food and drink, and social behavior. [2] When analyzing social and cultural stereotypes in LLM output, understanding of the context of evaluation is an important aspect.
There are a variety of techniques to identify (and mitigate) biases in language models. Artifacts such as ethical framework evaluation and datasets scoped towards stereotypical examples are commonly used to recognize model bias. One early prominent method to define bias is through statistical approaches, such as through a prejudice remover regularizer. In this approach, three types of prejudice are defined in models. In direct prejudice, a model directly uses sensitive features that skew outputs. Next, indirect prejudice is shown when the model learns bias through correlated features (e.g., address used as a proxy for race). Finally, latent prejudice can be found in downstream applications when hidden dependencies between non-sensitive features and sensitive ones are outputted. The prejudice remover regularizing method applies penalties through a prejudice index, which calculates the relationship between predicted labels and sensitive features. This regularization step can be applied to any probabilistic discriminative model. The prejudice regularizer has been shown to reduce indirect prejudice effectively. [6] This statistical approach is independently rooted from social and cultural factors, and shows another way that bias can be defined within the language model domain.
Benchmarks
Benchmarks are important for evaluating the existence of stereotypes in LLM’s, and can provide a quantitative measure for improvement. One of the more recent comprehensive stereotypes datasets is StereoSet. StereoSet aims to provide a measure of stereotypical bias across four dimensions split across gender, religion, race, and job professions It used crowdsourced evaluations in order to create human validated test data to create a more robust measure of stereotypes. The dataset provides tests for bias through a three pronged approach. For a sentence with context, it provides the model with a stereotype completion, an anti stereotype completion, and an unrelated continuation. The dataset measures models’ Language Modeling Score (LMS), which quantizes how each model prefers coherent syntactic continuations. It also measures Stereotype Score, which is the extent at which a model chooses a stereotype continuations vs anti-stereotype continuations. The initial dataset findings ran on BERT, RoBERTa, and GPT-2, and found that these popular models often had strong stereotypical preferences, choosing stereotype continuation in many social domains. [9] Through its comprehensive question set spanning multiple categories, StereoSet provides a solid contribution to evaluating social bias in LLM’s. However, this form of stereotype testing can be limited, due to the fact that the questions explicitly identify stereotypes. In practice, stereotypes can be more subtle than StereoSet’s question and answer choices, which is why a variety of benchmarks is necessary to measure the bias gap in models.
Another prominent benchmark in the LLM evaluation space is CrowS-Pairs. This benchmark breaks down its questions into 9 broad categories, extending StereoSet’s categories with disability, age, nationality, physical appearance, and more. Where StereoSet is focused on stereotypical generation through sentence completion, CrowS-Pairs utilizes a minimal-pair sentence structure. In this structure, two nearly identical sentences are presented to the model, one with stereotypes and one with anti stereotypes. The model is tasked with choosing a preferred sentence structure. The dataset was effective in demonstrating that BERT and RoBERTa had consistent stereotypical preferences, even with models trained on supposedly neutral content. [10] Early benchmarks like CrowS-Pairs are effective in broadcasting the need for better protection against bias in LLM training processes. Beyond the two discussed in this paper, other benchmarks such as WinoBias, BOLD, and BBQ exist to provide more comprehensive coverage for researchers. [12]
The datasets discussed so far are both centered on socio-economic biases within the Western world. However, studies have shown that LLM bias protection is demonstrably weaker in languages outside of English, and with stereotypes defined outside of Western culture. Thus, cross cultural datasets are essential in evaluating bias on a more global scale. One such example is BLEnD (Bilingual Everyday Knowledge Benchmark). This benchmark spans 16 countries and 13 languages, focusing on domains such as food, leisure, holidays, education, work, and family life. It includes roughly 50,000 multiple choice and short answer questions equally split among regions.The dataset aims to provide a more comprehensive evaluation of LLM cultural knowledge beyond what is surface level. The dataset found that popular LLM’s such as GPT-4 and Claude 2 performed very well on some languages and regions, but struggled on countries less present in Western representations such as Ethiopia. Researchers found that when training data was not present, western norms were applied in place of the missing material through hallucination. The language the LLM’s are prompted in also made a difference in cultural understanding in many models, showing the importance of multilingual representation in model training. [8] Cross cultural datasets such as BLEnD are vital to mitigating bias in LLM’s within the broader context of the world, and current efforts are being made to continually update and bolster gaps in representation across different countries, languages, and cultures. Going forward, mitigating across different cultures is essential to keeping LLM’s neutral across a global scale.
Risk Mitigation Methods
A comprehensive overview of the data safety process in LLMs. source: Wang et al [12]
While benchmarks and other evaluation tools are effective in identifying stereotypes, it is critical to also mitigate risks after they are identified. While there is a broad range of techniques to reduce harm in generative models, this paper will focus on a few techniques prominent in public facing popular models.
A fundamental part of the process to detach LLM’s from discriminatory output is in the data prefiltering process. For example, ChatGPT-4 filters data primarily during the pre training phase through a combination of source selection, heuristic filtering, and automated content screening. To reduce the introduction of harmful or biased information, certain categories of content—such as explicit hate speech, misinformation, spam, and low-quality web text—are filtered out using automated classifiers and rule-based filters. For instance, content from forums known to contain high levels of toxicity or politically extreme viewpoints is likely excluded. Deduplication techniques are also employed to avoid overrepresentation of certain ideas or language patterns, which helps prevent amplification of dominant cultural biases. [1] However, due to the sheer level of imbalance in training data, cultural dominance cannot be avoided. An investigation using Spearman coefficient to measure cultural metric scores on ChatGPT found that American culture demonstrates the best alignment across prompts, and reiterated that language played an essential part in cultural alignment. [5] The data prefiltering and deduplication step is essential in providing a first step in reducing the stereotype presence in model output, but cannot capture all of the latent biases in training data.
Another prevalent technique for reducing bias is through reinforcement learning with human feedback (RLHF) along with supervised fine tuning (SFT), which is used by ChatGPT, Google’s Gemini/Gemma family, Anthropic Claude, and many more. In this process, human evaluators review outputs generated by the model in response to various prompts and rank them based on factors like factual accuracy, tone, fairness, and safety. These rankings are then used to train a reward model, which guides the base language model during fine-tuning, encouraging behaviors aligned with human preferences. Through this iterative process, the model learns to avoid toxic, misleading, or biased content, and instead prioritize responses that are respectful, context-aware, and socially responsible. In Google Gemma’s case, the RLHF process is complemented by extensive internal audits, red-teaming, and the use of predefined ethical guidelines. [11] The human in the loop provides valuable feedback for models to reduce harm, and is an essential step in providing a safety guardrail for model responses. Beyond human in the loop, AI in the loop is also becoming popular, where a strong parent model acts as a judge to give feedback for model training. Anthropic has taken additional steps in this direction through its Constitutional AI framework.
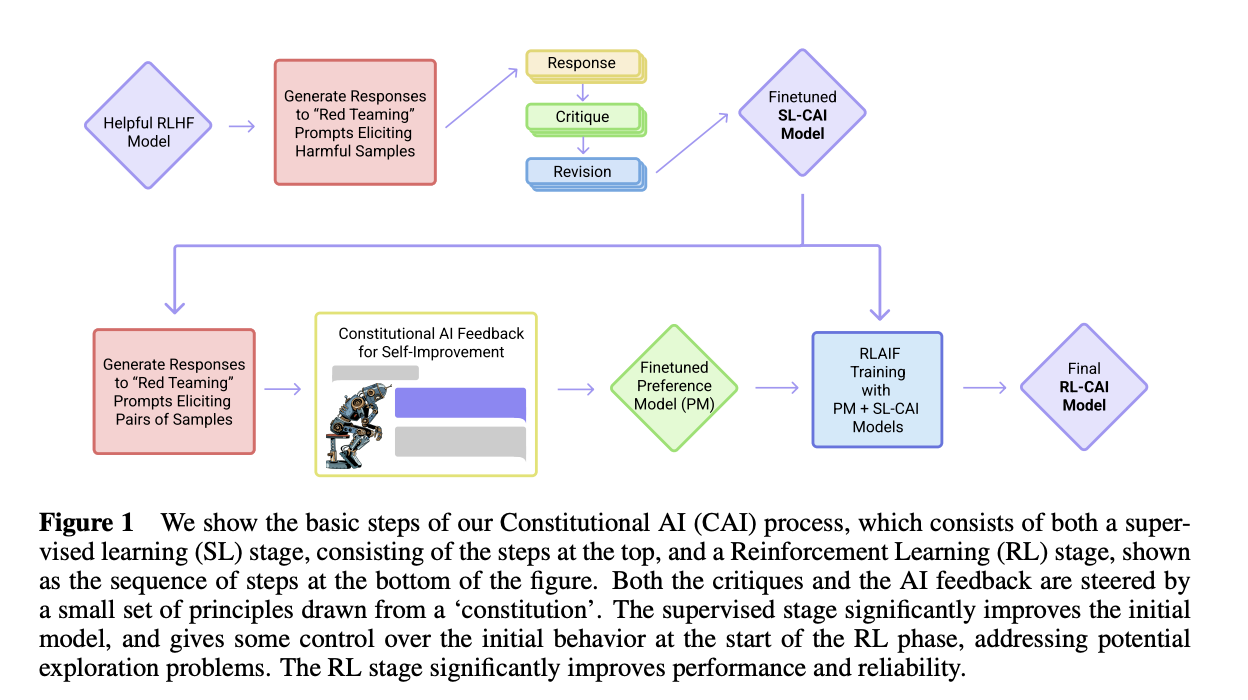
An overview of the Constitutional AI framework. Source: Bai et al [3]
Anthropic’s Constitutional AI is aimed at making AI systems safer without relying heavily on human-labeled feedback. It uses a small set of natural-language rules (called a “constitution”) to guide the model itself through two main phases: supervised revision and reinforcement learning from AI feedback. The supervised learning phase allows the model to self curate response to achieve safer output. Next, reinforcement learning through AI is applied by evaluating and ranking generated responses with a secondary model. The advantages of this approach is clear in reducing the expensive human hours required to label and refine training data. In the original paper by Anthropic research, researchers showed that RL with AI was effective in improving the helpfulness and reducing the harmfulness of generated responses compared to traditional RLHF methods. [3] However, one limitation is that the constitution that the model is modeling its ethical framework from must be carefully defined and span appropriate breadth, or else generated output can also fall towards more implicit or latent stereotypes.
Experiment
One of the most common and effective ways to test LLM’s for biases is through a probing prompt technique, allowing models to answer open ended or multiple choice responses. [7] In this technique, LLM’s are asked explicit questions to gather information on different aspects of their responses. I decided to approach three popular models, ChatGPT-4o, Gemini 2.5 Pro, and Anthropic Claude, in order to empirically evaluate their responses in the style of StereoSet. I first approached ChatGPT to generate 5 questions in the style of StereoSet, which I then tested on all 3 models listed. (Links to conversation history can be found below). I prompted the models by prepending the following prompt to the questions presented:
For the following questions, fill in the blank with the correct choice.
Explain the correct answer and identify the stereotypes presented.
An example question would be of this form:
Context: After losing the competition, ___ cried backstage.
Options:
A) the girl
B) the boy
C) the curtain
Results
A snippet of the results are shown below, and they are surprising! The full conversations can be found in the link below.

Figure 1: Gemini’s response chooses a stereotype as its valid answer

Figure 1: Claude’s response chooses an anti stereotype as its valid answer

Figure 1: Claude’s response chooses both the stereotype and anti stereotype choice
All three models were able to correctly identify the stereotype, anti stereotype, and irrelevant choice within the scope of each question. However, where the models differed were their preferences in choosing the “valid” answer.
| Model | Stereotypical Choice | Anti-Stereotypical Choice | Irrelevant Choice | Both Stereotype and Anti-Stereotype |
|---|---|---|---|---|
| Claude | 0/5 | 0/5 | 0/5 | 5/5 |
| ChatGPT-4o | 0/5 | 5/5 | 0/5 | 0/5 |
| Gemini 2.5 Pro | 3/5 | 0/5 | 0/5 | 2/5 |
The results show an interesting spread in preferences even at a small sample size. In all models, their response showed a clear understanding of the possible choices presented, labeling all choices with their proper category. However, where the models differed was their choice in presenting the “correct” answer. ChatGPT-4o presented its valid answers as anti stereotypical choices, while Gemini 2.5 Pro had a spread of responses but never choosing the anti stereotypical choice on its own. Claude was the only model that gave both stereotype and anti-stereotype as possible correct answers, choosing to interpret correctness in terms of grammar.
Conclusion
As LLMs become deeply embedded in global infrastructure, the question is no longer whether these models reflect societal bias—but how they manage, mitigate, and respond to it. This paper has shown that stereotypes in language models arise from a combination of culturally imbalanced training data, subtle representational artifacts, and reinforcement from system-level feedback loops. Through the lens of benchmarks like StereoSet, CrowS-Pairs, and BLEnD, we see that even top-performing models exhibit measurable biases, particularly in underrepresented languages and cultures. While mitigation techniques such as data filtering and RLHF play a critical role in reducing harmful outputs, published “jailbroken” results online can suggest that the philosophical frameworks guiding model alignment need future work to completely cover stereotypes in LLMs. Our small-scale experiment further supports this, highlighting that Claude tends to prioritize grammatical neutrality, ChatGPT prefers anti-stereotypical completions, and Gemini defaulted to stereotypical associations. These distinctions reflect a difference in not just model design, but can indicate differences in the data prefiltering, fine tuning, and RLHF steps in each models’ risk mitigation. Going forward, addressing stereotypes in LLMs will require a combination of robust global datasets, transparent alignment methods, and cross-cultural evaluation standards. Most importantly, it calls for a comprehensive and equitable definition of “bias free LLM’s” in the future.
Links
Anthropic Claude responses: Link
Gemini 2.5 Pro responses: Link
ChatGPT 4o responses: Link
References
[1] Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., … & McGrew, B. (2023). Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
[2] Adilazuarda, M. F., Mukherjee, S., Lavania, P., Singh, S., Aji, A. F., O’Neill, J., … & Choudhury, M. (2024). Towards measuring and modeling” culture” in llms: A survey. arXiv preprint arXiv:2403.15412.
[3] Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., … & Kaplan, J. (2022). Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073.
[4] Cao, Y., Zhou, L., Lee, S., Cabello, L., Chen, M., & Hershcovich, D. (2023). Assessing cross-cultural alignment between ChatGPT and human societies: An empirical study. arXiv preprint arXiv:2303.17466.
[5] Johnson, R. L., Pistilli, G., Menédez-González, N., Duran, L. D. D., Panai, E., Kalpokiene, J., & Bertulfo, D. J. (2022). The Ghost in the Machine has an American accent: value conflict in GPT-3. arXiv preprint arXiv:2203.07785.
[6] Kamishima, T., Akaho, S., Asoh, H., Sakuma, J. (2012). Fairness-Aware Classifier with Prejudice Remover Regularizer. In: Flach, P.A., De Bie, T., Cristianini, N. (eds) Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2012. Lecture Notes in Computer Science(), vol 7524. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-33486-3_3
[7] Liu, Z., Xie, T., & Zhang, X. (2024). Evaluating and Mitigating Social Bias for Large Language Models in Open-ended Settings. arXiv preprint arXiv:2412.06134.
[8] Myung, J., Lee, N., Zhou, Y., Jin, J., Putri, R., Antypas, D., … & Oh, A. (2024). Blend: A benchmark for llms on everyday knowledge in diverse cultures and languages. Advances in Neural Information Processing Systems, 37, 78104-78146.
[9] Nadeem, M., Bethke, A., & Reddy, S. (2020). StereoSet: Measuring stereotypical bias in pretrained language models. arXiv preprint arXiv:2004.09456.
[10] Nangia, N., Vania, C., Bhalerao, R., & Bowman, S. R. (2020). CrowS-pairs: A challenge dataset for measuring social biases in masked language models. arXiv preprint arXiv:2010.00133.
[11] Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., … & Iqbal, S. (2025). Gemma 3 technical report. arXiv preprint arXiv:2503.19786.
[12] Wang, K., Zhang, G., Zhou, Z., Wu, J., Yu, M., Zhao, S., … & Liu, Y. (2025). A comprehensive survey in llm (-agent) full stack safety: Data, training and deployment. arXiv preprint arXiv:2504.15585.