The Frontier of Image and Video Generation Models.
Recent advances in deep learning have revolutionized image generation, from traditional Generative Adversarial Networks (GANs)-based models to diffusion-based and more recent black box models, to produce increasingly photorealistic visuals. These image generation advances allow for the generation of faithful, realistic, and high-resolution visual contents based on textual instructions, and have found success in domains like digital art, advertising, and prototyping. Furthermore, to achieve utility in more dynamic storytelling and immersive content creation, researchers further studied video generation for creating coherent, temporally consistent motion content directly from data. This paves the way for new applications in filmmaking, virtual reality, marketing, and beyond. However, generating videos introduces new challenges far beyond those faced in static image synthesis: models must not only render realistic frames, but also capture motion dynamics, long-range temporal dependencies, and scene coherence. Moreover, obtaining large-scale, high-quality video data for training remains a bottleneck, and quality control becomes more complex when both spatial and temporal dimensions are involved. Along similar lines, the further incorporation of audio effects with video generation has also become an emerging research field. As research pushes the boundary of what’s possible, video generation has become one of the most exciting—and demanding—frontiers in AI-driven content creation.
- Introduction
- Prior Works on Image Generation
- Prior Works on Video Generation
- Extra Credit Task: Implementation and Experiments
- Conclusion
- References
Introduction
Using AI models for generating faithful, stylistic, and high-resolution multimodal visual contents has become an increasingly important research topic. Recent AI community has witnessed groundbreaking multimodal generative models such as OpenAI’s DALL-E 3 [1] and Google’s Veo-3 [2]. With the rise of a myriad of state-of-the-art approaches, this blog aims at introducing representative works in the image and video generation domain, as well as summarizing the advantages and disadvantages of these prior approaches. Additionally, we conduct scientific experiments to explore one of the crucial limitations on compositionality in image generation models.
Image Generation
Many previous research have approached the task if image generation with different model structures. In this blog, we focus on 3 representative structures in the history of research on image generation: Generative Adversarial Networks (GANs), diffusion models with U-Net Backbones, and transformer-based diffusion models.
GAN‑Based Models. GANs are among the earliest and most influential approaches to image generation. A typical GAN framework consist of two neural networks components: a generator and a discriminator. During training, the generator is optimized to produce synthetic data samples, whereas the discriminator is trained to distinguish the synthetic generated samples from real data. This adversarial training strategy allows the generator to gradually learn to create increasingly realistic visual outputs.
Diffusion Models with U-Net Backbones. Diffusion models gained significant attention for their ability to generate high-quality samples with improved training stability. The diffusion process gradually stacks Gaussian noise on training data, until it becomes indistinguishable from random noise. Then, a U-Net-based neural network is then trained to reverse the noising process to denoise and reconstruct the clean data from noisy inputs step by step. At inference time, the model starts from a fully noisy input and gradually refines it into a realistic visual sample.
Diffusion Models with Transformers. Recent research introduce Diffusion Transformers (DiTs), a new class of diffusion models based on the Transformer architecture. DiT structure replaces the previously-adopted convolutional U-Net backbone with a transformer, which operates on latent patches. This approach achieves unprecedented performance in high-quality image generation.
Video Generation
Similar to image generation, we introduce 3 representative structures in video generation models: Generative Adversarial Networks (GANs), diffusion models with U-Net Backbones, and transformer-based diffusion models.
GAN‑Based Models. Early work in video generation extended the GAN framework—originally designed for images—to the spatiotemporal domain. Models like VGAN, TGAN, and MoCoGAN employed convolutional architectures that generated short clips by jointly optimizing a frame-wise video generator and a discriminator that assesses both spatial realism and temporal coherence. These methods were groundbreaking but suffered from limitations: temporal artifacts, mode collapse, and difficulties scaling to longer durations or higher resolutions due to the adversarial training instability and limited capacity to model complex motion patterns.
Diffusion Models with U-Net Backbones. The arrival of diffusion models brought significant improvements. Inspired by DDPMs, video diffusion models iteratively denoise frames using U‑Net architectures conditioned on neighboring frames and noise timesteps. State-of-the-art frameworks—such as those behind Imagen Video and VideoFusion—either operate in pixel space with 3D U-Nets or in latent spaces with cascaded upscaling, offering enhanced spatial fidelity and smoother temporal dynamics en.wikipedia.org. These models, however, remain computationally intensive, often requiring cascaded training pipelines and careful temporal alignment to retain consistency across frames.
Diffusion Models with Transformers. More recent works explored transformer-based approaches for photorealistic video generation with diffusion models. This is usually achieved by extending ViT blocks in transformer-based image diffusion models with temporal attention layers, which adds a temporal dimension to the generated outcome and allows for the generation of consistent videos.
Prior Works on Image Generation
Generative Adversarial Networks (2014) [3]
Generative Adversarial Networks (GANs) revolutionized AI image generation by creating realistic and high-quality images from random noise. Generative Adversarial Networks (GANs) consist of two neural networks–the Generator and the Discriminator–that compete with each other. The generator creates images from random noise while the Discriminator evaluates images to classify them as real or fake which leads to continuous improvement in the quality of generated samples. The Discriminator starts by being trained on a dataset containing real images. Its goal is to differentiate between these real images and fake images generated by the Generator. Through backpropagation and gradient descent it adjusts its parameters to improve its ability to accurately classify real and generated images. In parallel, Generator is trained to produce images that are increasingly difficult for the Discriminator to distinguish from real images. Initially it generates random noise but as training progresses it learns to generate images that resemble those in the training dataset. Generator’s parameters are adjusted based on the feedback from the Discriminator helps in optimizing the Generator’s ability to create more realistic and high-quality images.
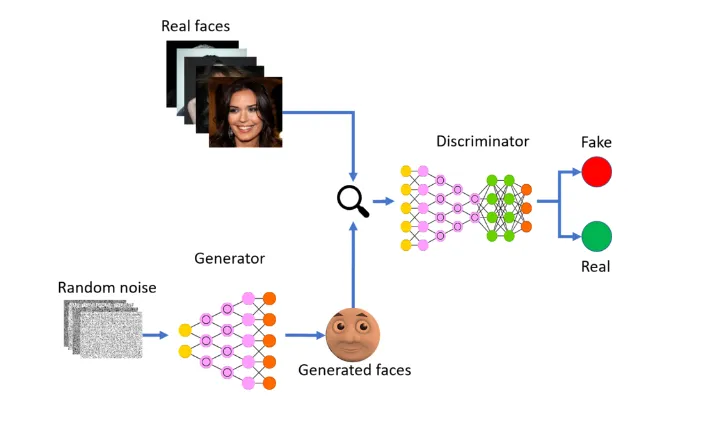
Example of the training pipeline of using GANs to generate images of facees. The generator learns to create realistic depictions that are as indistinguishable from real images as possible, as judged by the discriminator.
- Advantages:
- Earliest attempts to produce high-quality and realistic images.
- Allowing flexible applications like style transfer and super resolution.
- Disadvantages:
- Model Collapse. The generator creates limited or repetitive outputs, failing to capture the variety of the training data.
- Training Instability. The training process could become unstable, causing the generator and discriminator to diverge or fluctuate instead of improving together.
- Hyperparameter Sensitivity: Model performance is very sensitive to choices of hyperparameters like learning rate and optimizer settings. This requires careful tuning at the risk of model collapse during training.
High-Resolution Image Synthesis with Latent Diffusion Models (2021) [4]
The first generation of diffusion-based models, which usually adopt a U-Net-based structure, offer an efficient and scalable approach to generative modeling by operating in a compressed latent space rather than pixel space. This design dramatically reduces the computational cost of high-resolution image synthesis while preserving visual fidelity. The model uses a U-Net architecture as the denoiser within a diffusion process, enabling it to iteratively refine noisy latent representations into coherent image features. By combining the strengths of autoencoding for dimensionality reduction and diffusion for high-quality generation, latent diffusion models achieve state-of-the-art performance in generating detailed and diverse images across various conditioning tasks.
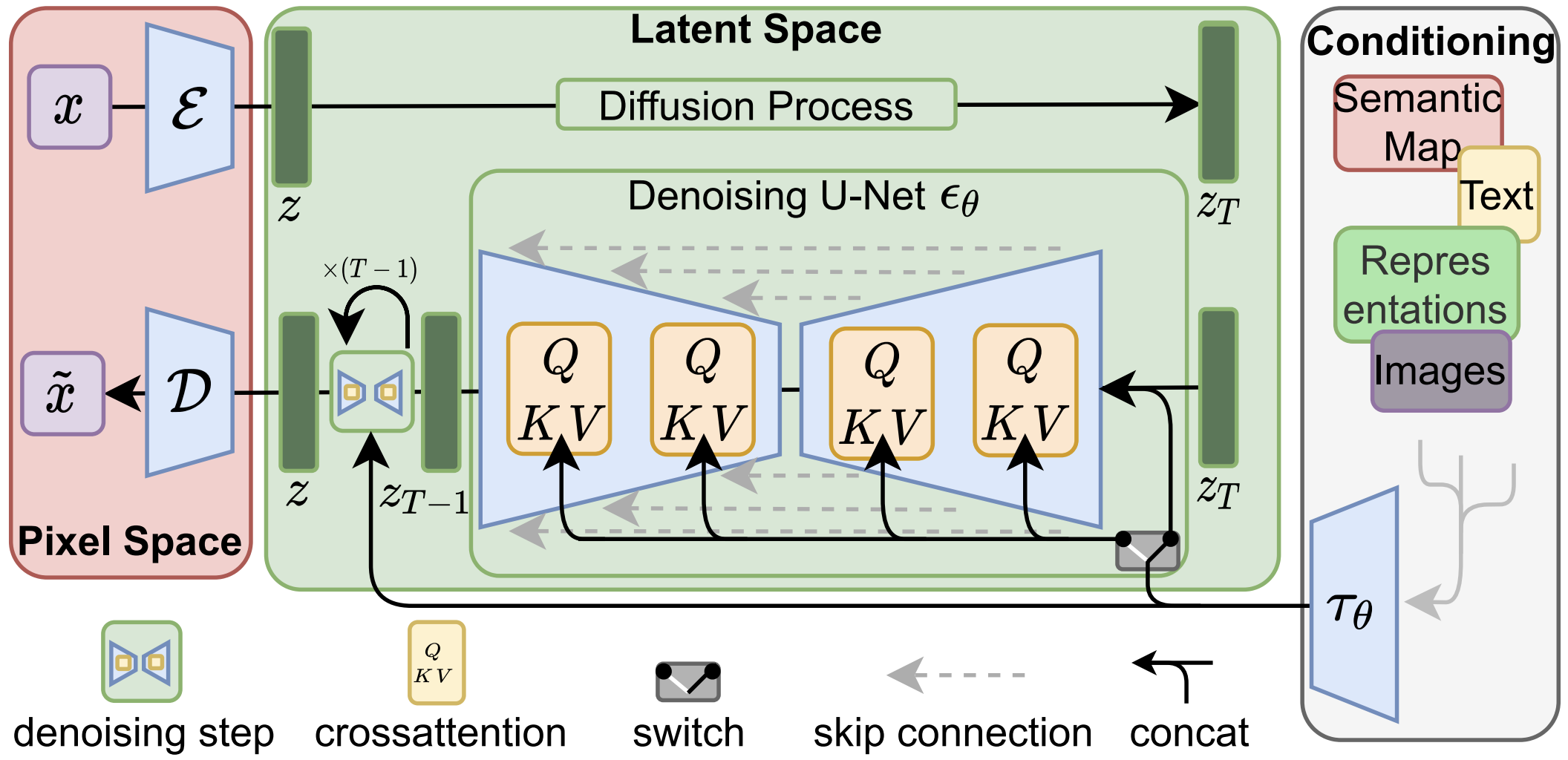
Example of how to condition Latent Diffusion Models (LDMs) for text-to-image generation, either via concatenation or by a more general cross-attention mechanism.
- Advantages:
- The generation of high-resolution image samples.
- More stable training process and less model collapse than GAN-based approach.
- Disadvantages:
- Context Dependency: U-Net-based diffusion models often struggle with capturing long-range dependencies and global context in the input data. This is due to the limited receptive field of convolutional layers.
- Position / Spatial Control: Convolution in U-Nets are translation invariant, trating features as the same regardless of their positions in the image. Therefore, positional and spatial control in generated images are more difficult to achieve.
Scalable Diffusion Models with Transformers (2022) [5]
Transformer-based diffusion models, known as Diffusion Transformers (DiTs), are inspired by the Vision Transformer (ViT) and replace the traditional U-Net backbone in latent diffusion models with a transformer architecture. While being largely similar to standard ViTs, DiTs make key modifications to the structure to effectively handle conditional inputs, like diffusion timesteps, for diffusion-based generation. In their paper ‘Scalable Diffusion Models with Transformers’, the authors discovered that the most effective design leverages adaptive layer normalization (adaLN). adaLN modulates the activations prior to residual connections, and is initialized to behave like an identity function at the beginning of the training process. This simple yet impactful change significantly improves the quality of model-generated outputs as measured by FID scores, showing transformers as a flexible alternative to U-Nets in diffusion-based image synthesis.
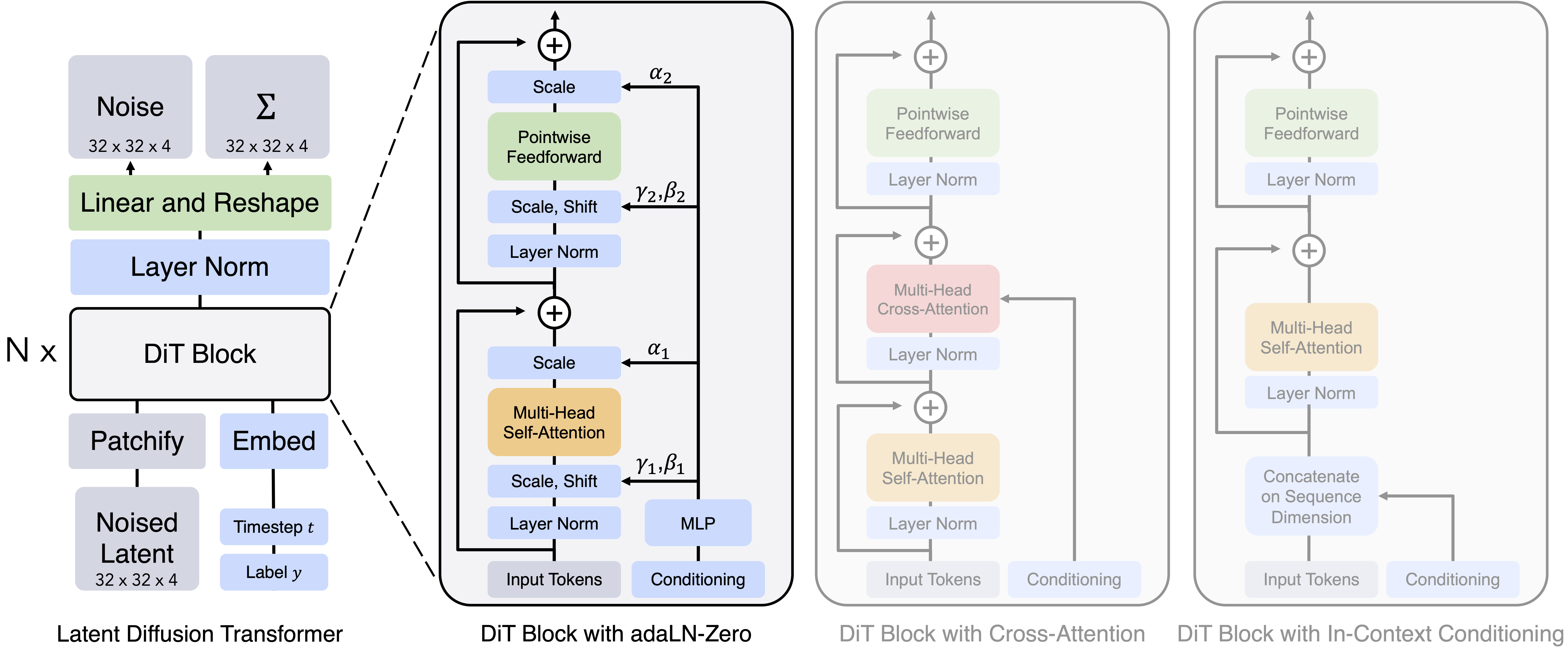
The Diffusion Transformer (DiT) architecture. Left: Conditional latent DiT models. The input latent is decomposed into patches and processed by several DiT blocks. Right: Details of the DiT blocks. After experimenting with variants of standard transformer blocks that incorporate conditioning via adaptive layer norm, cross-attention and extra input tokens, adaptive layer norm is empirically proved to work best.
- Advantages:
- Better handle long range dependencies in contexts compared to U-Net-based approaches.
- Better control positional and spatial control of generated subjects through positional encodings.
- Better efficiency at inference time.
- Disadvantages:
- Still not the best with positional and spatial control.
Prior Works on Video Generation
Video Generation from Text (2017) [6]
One of the earlier efforts in text-to-video synthesis is the 2017 work titled Video Generation from Text, which introduced a conditional generative model designed to capture both static and dynamic aspects of video content from textual input. The proposed hybrid framework combines a Variational Autoencoder (VAE) with a Generative Adversarial Network (GAN), enabling the model to learn nuanced video representations. In this architecture, static features—referred to as the “gist”—are extracted from the text and used to generate coarse layouts such as background colors and object placements.

Samples of video generation from text. Universal background information (the gist) is produced based on the text. The text-to-filter step generates the action (e.g., “play golf”). The red circle shows the center of motion in the generated video.
Meanwhile, dynamic features are handled by converting the text into an image filter that modulates the temporal evolution of the scene. To train and evaluate the model, the authors constructed a dataset of short video clips collected from YouTube, tailored to align visual content with descriptive captions. This work laid early groundwork for bridging language and temporally consistent visual generation.
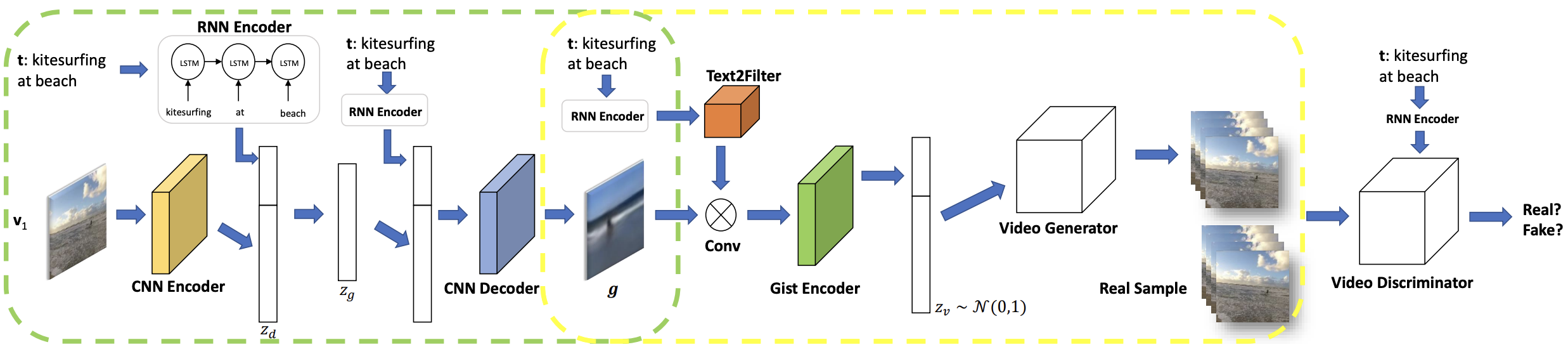
Framework of the proposed text-to-video generation method. The gist generator is in the green box. The encoded text is concatenated with the encoded frame to form the joint hidden representation zd, which further transformed into zg. The video generator is in the yellow box. The text description is transformed into a filter kernel (Text2Filter) and applied to the gist. The generation uses the features zg with injected random noise. Following this point, the flow chart forms a standard GAN framework with a final discriminator to judge whether a video and text pair is real or synthetic. After training, the CNN image encoder is ignored.
- Advantages:
- Earliest attempts to extend image generation in the temporal dimension with promising results.
- Disadvantages:
- Struggled to maintain temporal consistency and realistic motion across frames.
Video Diffusion Models (2022) [7]
The 2022 paper Video Diffusion Models marked a pivotal moment in generative modeling by demonstrating the first successful application of diffusion models to video generation, covering both unconditional and conditional settings. The core architecture employs a 3D space-time U-Net, which directly models the joint spatial and temporal structure of fixed-length video clips. A notable innovation in this work is the use of factorized U-Nets, which not only allow the model to scale to variable sequence lengths but also enable joint training on both video and image data—an approach shown to significantly improve sampling quality. To extend generation beyond fixed durations, the authors propose an autoregressive sampling scheme that conditions on previously generated segments, allowing for the synthesis of longer, coherent video sequences. The model was trained and evaluated on the UCF101 dataset, a benchmark collection of user-uploaded videos depicting 101 different human action categories. This work established diffusion models as a powerful alternative to GAN-based approaches for temporally consistent and high-fidelity video generation. They provide a public demonstration here.
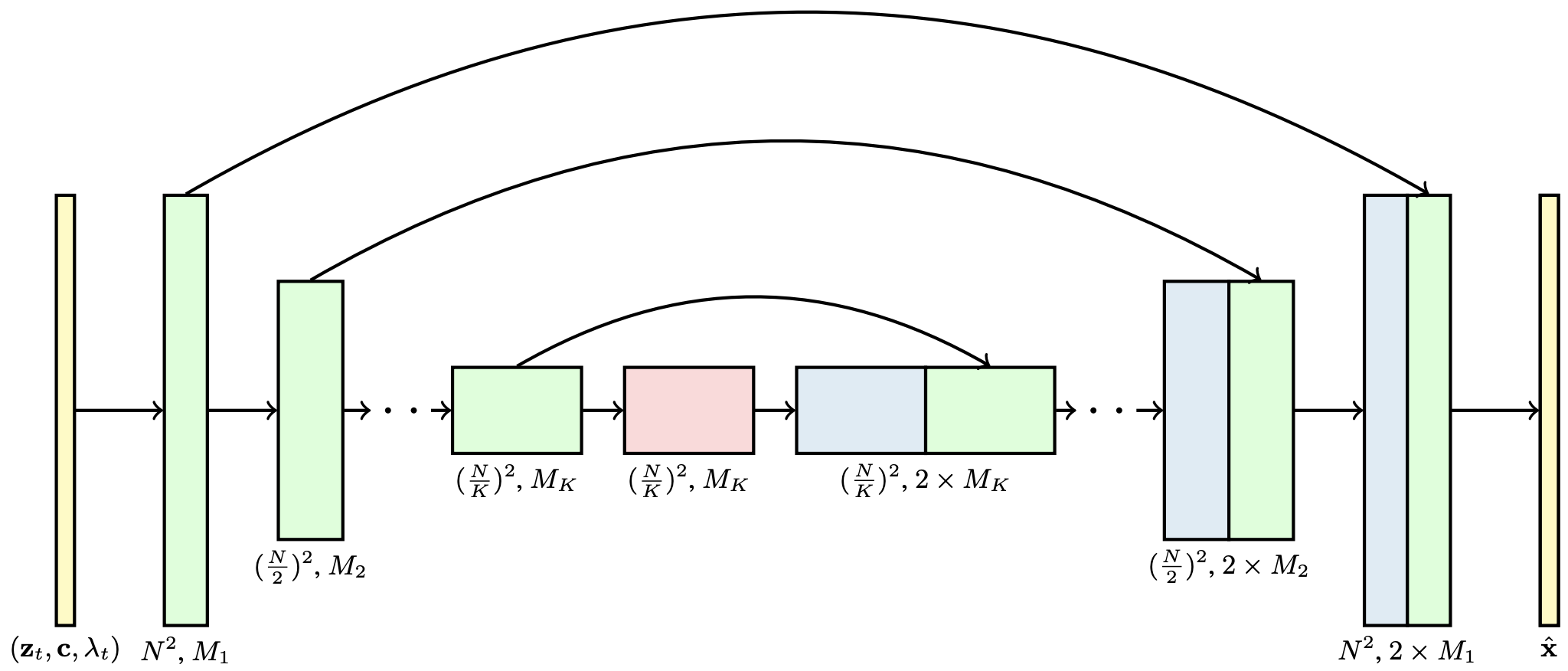
The 3D U-Net architecture for x^θ in the diffusion model. Each block represents a 4D tensor with axes labeled as frames × height × width × channels, processed in a space-time factorized manner as described in Section 3. The input is a noisy video zt, conditioning c, and the log SNR λt. The downsampling/upsampling blocks adjust the spatial input resolution height × width by a factor of 2 through each of the K blocks. The channel counts are specified using channel multipliers M1, M2, ..., MK, and the upsampling pass has concatenation skip connections to the downsampling pass.
- Advantages:
- Improve fidelity and consistency of generated videos.
- Disadvantages:
- Short duration of generated videos (usually a couple seconds).
- Low resolution of generated videos.
- Temporal incoherence. Generated videos often suffer from flickering artifacts, inconsistent object appearances, or morphing structures that undermine realism.
- Unrealistic motion. Characters or objects exhibit physically implausible behavior and lacking an intuitive grasp of cause-and-effect relationships in dynamic scenes.
- Limited understanding of prompts, especially when tasked with generating nuanced actions, complex interactions, or scenes involving multiple entities.
Photorealistic Video Generation with Diffusion Models (2023) [8]
The December 2023 paper Photorealistic Video Generation with Diffusion Models introduced a transformer-based architecture, Window Attention Latent Transformer (W.A.L.T.), designed to advance photorealistic video synthesis through diffusion modeling. At the heart of the approach is a causal encoder that compresses both images and videos into a shared latent space, allowing unified training across modalities and facilitating seamless transition between image and video generation tasks. To address the computational challenges of high-dimensional video data, the model incorporates a specialized window attention mechanism that efficiently captures both spatial and temporal dependencies. The full system is implemented as a cascaded framework for text-to-video generation, consisting of a base latent video diffusion model followed by two successive video super-resolution diffusion stages. This multi-stage design allows the model to progressively refine outputs to high visual fidelity. The training data includes a diverse set of text-image and text-video pairs sourced from the internet and proprietary datasets, enabling the model to generalize across a wide range of visual concepts and motion patterns.
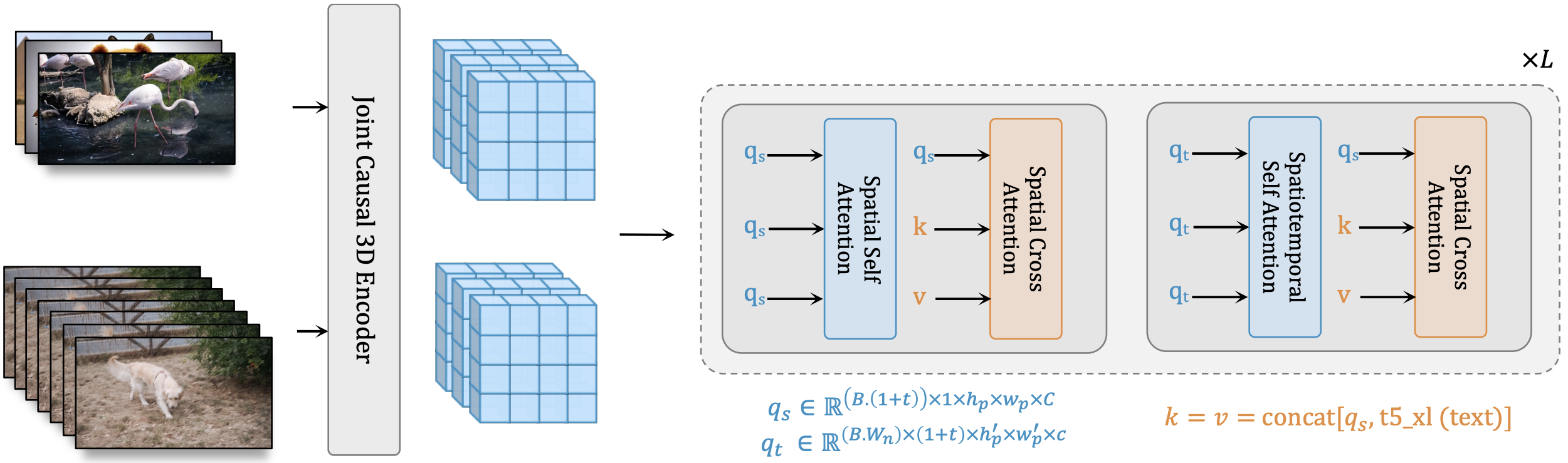
W.A.L.T. We encode images and videos into a shared latent space. The transformer backbone processes these latents with blocks having two layers of window-restricted attention: spatial layers capture spatial relations in both images and video, while spatiotemporal layers model temporal dynamics in videos and passthrough images via identity attention mask. Text conditioning is done via spatial cross-attention.
- Advantages:
- Higher resolution of generated videos.
- Better ability to capture long-range dependencies in temporal dimension.
- Disadvantages:
- Still struggles with unrealistic motion and prompt understanding.
Google’s Veo Models
Google’s Veo models marks a significant advancement in video generation. However, due to their black-box nature, we are not able to analyze their model structure. Here, we discuss the capabilities of Veo models as introduced by their release blog post.
Veo-2
In its initial release, Veo-2 demonstrates the ability to follow both simple and complex instructions, effectively interpreting nuanced prompts involving detailed actions, multi-entity interactions, and scene composition. The model also shows a stronger grasp of real-world physics, producing motion that respects physical plausibility—such as natural object trajectories, weight shifts, and environmental responses. Additionally, Veo-2 can render a diverse range of visual styles, offering greater creative flexibility. It also supports video generation from both text and image prompts, enabling users to specify scenes through rich textual descriptions or visual references.
The latest release of Veo-2 introduces a suite of powerful new capabilities: for instance, reference-powered video generation allows users to guide the model using images of scenes, characters, styles, or objects—akin to in-context learning for visuals. This allows for better temporal and visual consistency across frames. Advanced camera controls enable users to specify cinematic movements between angles. Seamless transitions between provided start and end frames are also enabled, producing temporally smooth videos that reflect coherent narrative arcs. Additionally, the new generation of Veo-2 supports both outpainting—extending content beyond the original frame—and inpainting, allowing for the insertion or removal of objects from existing videos, paralleling image editing capabilities in the video domain. For dynamic content, Veo-2 offers character movement control through reference videos and a tool where users can select specific objects and define their movement paths.
Veo-3
Google’s new Veo-3 model further elevates the realism, controllability, and quality of video generation. Veo-3 introduces the native generation of synchronized audio, allowing users to specify ambient sounds—such as birdsong or rustling leaves—directly within the prompt. In terms of physics and realism, Veo-3 achieves more lifelike motion for people, animals, and objects, exhibiting a deeper understanding of how entities interact with their environments in ways that adhere to physical laws. Additionally, Veo-3 demonstrates an enhanced comprehension of textual prompts, accurately translating subtle emotional cues, narrative tones, and complex instructions into coherent visual and auditory outputs.
- Advantages:
- State-of-the-art performance in generating high-quality, natural, and coherent videos.
- More realistic movements following real-world physics laws.
- Earliest attempt to simultaniously generate video and corresponding audio.
- Allow for precise prompt control of objects, motions, and audios in model generations.
- Disadvantages:
- Still struggle a little with naturalistic transitions between scenes in generated videos.
- Room for improvement with audio generation and incorporated in generated videos.
Extra Credit Task: Implementation and Experiments
Due to computational costs, we are not able to run experiments on video generation models. However, we implement multiple state-of-the-art image generation models and explore one of their shared limitations: positional, numerical, and spatial control of generated subjects in compositional image generation.
Task Formulation
Compositional Text-to-Image (T2I) generation tests models’ abilities to accurately and coherently depict multiple concepts in a unified scene based on textual instructions. We experiment with 900 detailed image generation prompts involving multiple objects, 3D-spatial relationships, and precise attributes such as color and texture. We manually define 5 distinct 3D-spatial configurations, escalating in both numerical and spatial complexity: 1 row × 2 subjects, 1 row × 3 subjects, 2 rows × 1 subject, 2 rows × 2 subjects, and 2 rows × 3 subjects. We phrase these positional configurations into natural prompt templates for further combination with generation subjects. For instance, for the configuration with 1 row and 2 subjects, the corresponding prompt template is:
“An image with 2 objects: a {(optional) attribute A} {subject A} on the left, and a {(optional) attribute B} {subject B} on the right.”
Evaluation
Our evaluation framework consists of 3 steps:
- An Atomic Question Decomposition step to divide complex compositional prompts into individual questions that can be judged with binary answers (i.e. “yes” or “no”).
- An Atomic MLLM Feedback step that uses a strong MLLM to judge the depiction accuracy of each decomposed aspect in generated images.
- An Aggregated Compositional Accuracy metric that yields an objective and interpretable quantitative evaluation score for each model generation. We measure the binary feedback for each subquestion and report the proportion of correctly-depicted entities as the Aggregated Compositional Accuracy (ACA) metric.
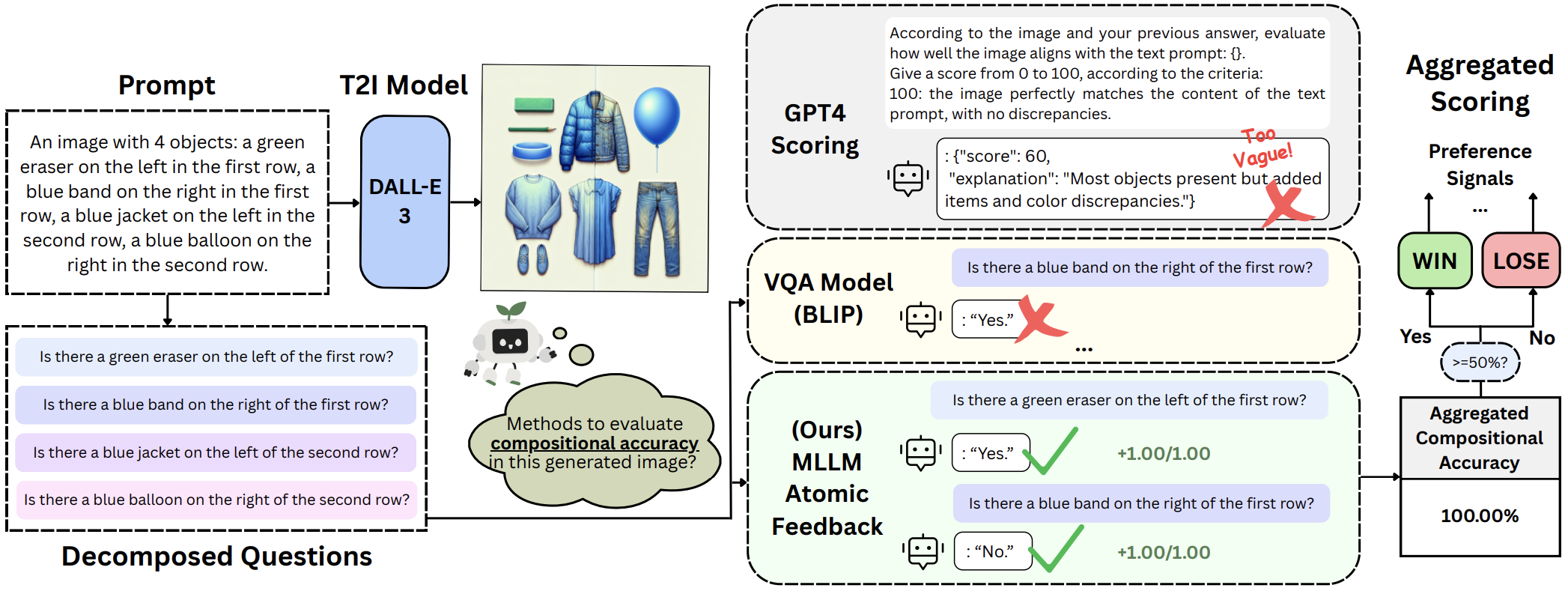
Evaluation Framework. Each compositional prompt is first divided into atomic questions, then answered by a MLLM feedback model, finally aggregated to be an accuracy score.
Results
Experiment results show that open-source diffusion models with U-Net structures, such as SD1.5 and SD2, exhibit limited compositional accuracy (below 50%). Performance improves with model scale, generation, and architecture improvements. For instance, SD3 and SD3.5, which utilize a transformer-based structure to replace U-Nets, both achieve remarkably higher ACA scores than the previous two, reaching above 75%. Among closed-source models, OpenAI’s gpt-image-1-high model leads with 93.51%, outperforming DALL-E 3 and Gemini. While results show promising advances in architectural and training pipelines for T2I models, we also observe a remarkable performance gap between open-sourced and closed-source models.
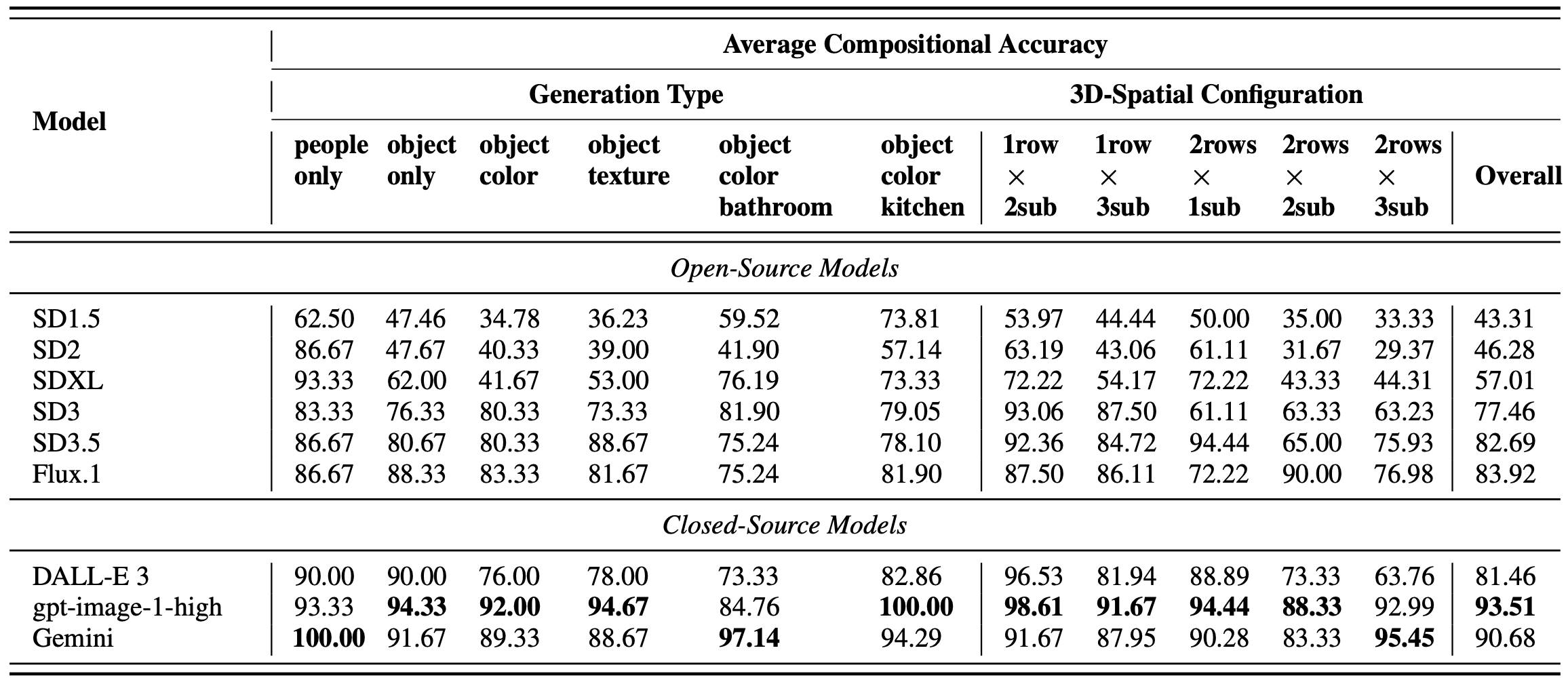
Comprehensive evaluation results across 9 open- and closed-source T2I models. Closed-source commercial models achieve remarkably stronger compositional accuracy, with OpenAI’s gpt-image-1-high as the leading model.
Additionally, qualitative results show that compare to previous evaluation frameworks like T2I-CompBench++, our evaluation setting is more challenging for even strong T2I models, resulting in more failure cases.

Example showing that while T2I models are capable of depicting simple compositional settings in a previous benchmark, they fall short in correctly generating images that accurately conform to complex compositional instructions in our challenging benchmark.
Conclusion
In this blog post, we introduce representative research works in the domain of image and video generation. By analyzing their advantages and disadvantages, we provide a clear overview of what has been done and what can be done in future works in these research directions. Furthermore, we conduct an in-depth analysis of one of the crucial limitations in image generation models: compositional T2I generation. By analyzing 9 state-of-the-art image generation models on our prompts, we discover the persisting pitfalls even for strong T2I models.
References
[1] OpenAI. Dall·e 3 system card, Oct 2023. URL https://openai.com/research/ dall-e-3-system-card.
[2] Google DeepMind. Veo, May 2025. URL https://deepmind.google/models/veo/.
[3] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” 2014
[4] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, June 2022.
[5] W. Peebles and S. Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023. 2, 4, 6, 7, 8
[6] Yitong Li, Martin Min, Dinghan Shen, David Carlson, and Lawrence Carin. 2018. Video generation from text. In Proceedings of the AAAI conference on artificial intelligence, Vol. 32.
[7] Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models. arXiv preprint arXiv:2204.03458, 2022. 2, 15
[8] A. Gupta, L. Yu, K. Sohn, X. Gu, M. Hahn, L. Fei-Fei, I. Essa, L. Jiang, and J. Lezama, “Photorealistic video generation with diffusion models,” arXiv preprint arXiv:2312.06662, 2023. —