Cosmos-Transfer1: Conditional World Generation
In this report, we present Cosmos-Transfer1, a conditional world generation model that enables the spatiotemporal control for state-of-the-art world models. We first introduce several prior works, including world models and controllable generation, which laid the foundation for this work. Then, we study how Cosmos-Transfer1 integrates these two methods to achieve controllable world generation. Through the experiments, we concluded some key insights about the model and its performance, with visualization from reproducing their release model. Finally, we discuss the future work and potential improvements for Cosmos-Transfer1.
Introduction
With recent advancements in the world model, they have been trained on large-scale image and video datasets, enabling the generation of high-quality images and videos with real-world dynamics. However, these models are often trained in an unconditional manner, which limits their ability to generate content that is tailored to specific requirements or preferences. Many downstream applications, such as autonomous driving and robot manipulation, require explicit and fine-grained control over the scene layout and dynamics, which the existing world model fails to provide. To address this limitation, NVIDIA proposed Cosmos-Transfer1 [1], a conditional world generation model that enables spatiotemporal control for state-of-the-art world models.
Related Works
World Foundation Models
World foundation models are neural networks that simulate real-world environments as videos and predict accurate outcomes based on text, image, or video input. They are generative AI models that are trained on large-scale, diverse image and video datasets, which enables them to learn and understand the real-world dynamics, such as physics laws and spatial awareness. Given the learned physical prior incorporated in the pre-trained model weights, they can simulate realistic and physics-grounded scenarios, which can be used as synthetic training data for various robotics downstream tasks, including robot manipulation and autonomous driving.

Overall architecture of the world model Cosmos-Predict1.
Behind the world foundation models lies the heart of all diffusion-based generation models, the denoising diffusion probabilistic models [3], which determine vectors in latent pixel space by predicting noise. The noise-predicting network \(D\) predicts the noise based on the noisy input latent \(\mathbf{x}_\sigma\) and noise scale \(\sigma\) follows
\[\mathbf{\hat{n}} = D(\mathbf{x}_\sigma, \sigma)\]and the network is optimized following the loss between the predicted and actual noise, defined as
\[L(D, \sigma) = \mathbb{E}_{\mathbf{x}_0, \mathbf{n}} \left[\| D(\mathbf{x}_0 + \mathbf{n}, \sigma) - \mathbf{n} \|_2^2 \right]\]The noise-predicting network initially followed a U-Net structure, but was later replaced with Diffusion Transformers (DiT) [4], which benefits from the great scalability of multiple transformer blocks. Through experiments on 3D consistency (e.g., geometric consistency, view synthesis consistency) and physical alignment, the pre-trained world models demonstrated great visual quality on par with real-world videos and some extent of physical grounding. However, these world models have limited control over the content and spatiotemporal layout of the generated content, which makes the downstream deployment of them limited and less practical.
Controllable Generation
To enable the controllable generation for the latest generation models, researchers designed various approaches to add spatial conditioning controls to pre-trained diffusion generative models. Given various modalities of pixel-wise conditions, such as segmentation map, depth map, edge map, or original image [6], these approaches define specifics of the generated content at spatial locations and timestamps that follow the conditions.

Conditional image generation based on various spatial condition modalities.
Among these approaches, the ControlNet architecture [5] stands out for its flexibility and effectiveness. Given a pre-trained diffusion-based generation model, it freezes the base model’s parameters to preserve the learned knowledge. A separate control branch, which consists of several transformer blocks that share the same architecture as the former blocks of the base model, is created to process the input spatial conditions. The control branch is initialized from the pre-trained model, and its output is added to the activation of the base model to inject the control signals. Through this paradigm, the spatial conditions can be incorporated into the generative model while preserving the generation quality and learned priors of the base model, including the real-world dynamics in the world models.
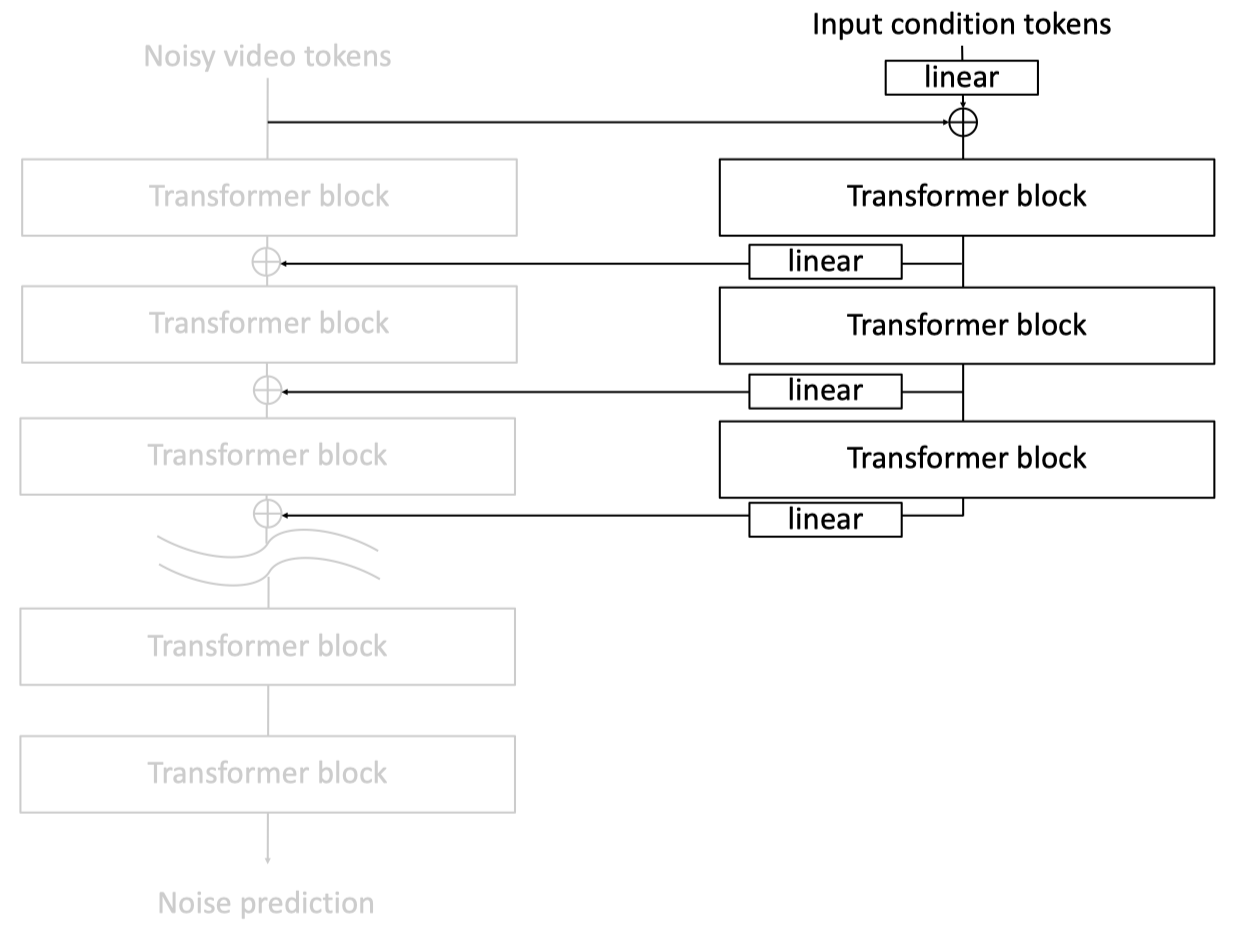
ControlNet architecture.
Method
The Cosmos-Transfer1 model starts from a pre-trained Cosmos-Predict1 world foundation model [2] and adds various control branches corresponding to different condition modalities. Given the diffusion backbone pre-trained on large-scale image and video data, each control branch is trained separately using the paired data of input conditions and the original images.
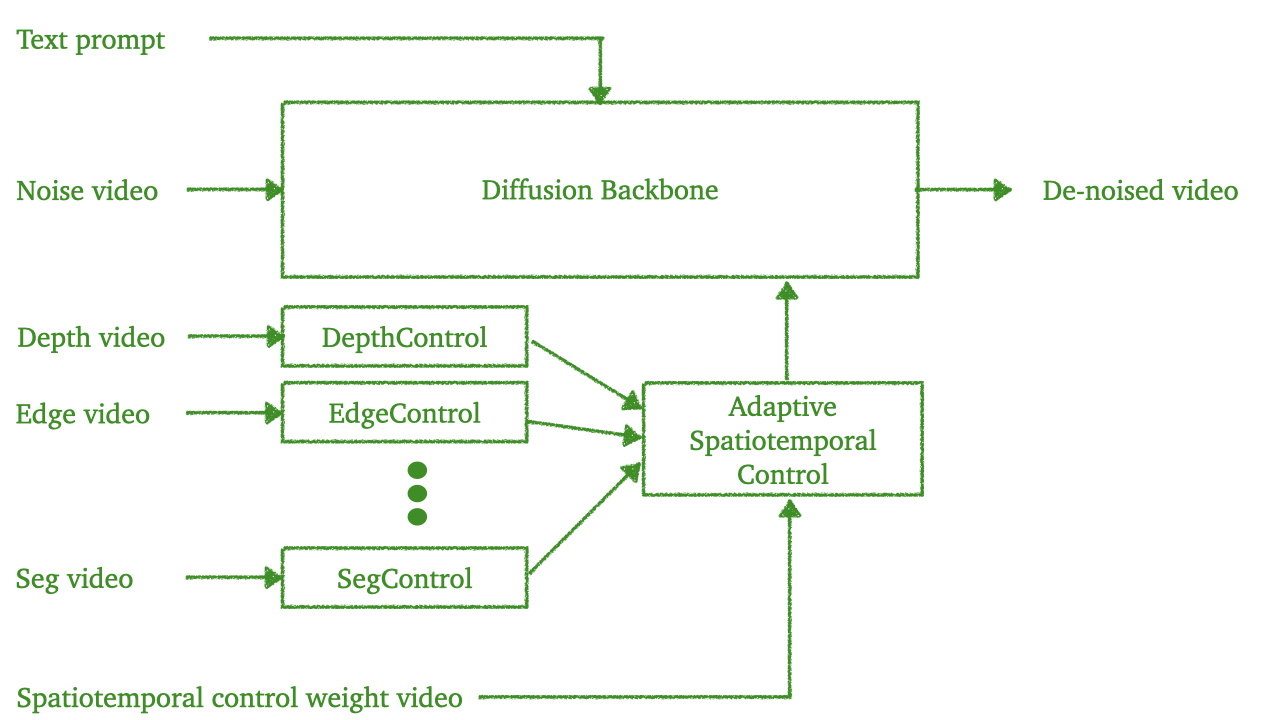
Cosmos-Transfer1 Architecture.
The condition modalities vary from general conditions, including Vis , Edge , Depth , and Segmentation , to conditions specific to autonomous driving, such as HDMap and LiDAR . These conditions can be either extracted from simulators’ sensors, or annotated by applying specific models or processing techniques on realistic images to obtain. Each control branch corresponds to one modality and is trained separately, thus much more memory efficient as only one branch needs to be loaded at a time. This training approach is also more flexible, as only one modality of conditions is required for the training sample pairs which is easier to obtain, and one can select suitable modalities during inference based on their requirements.

Condition modalities used in Cosmos-Transfer1.
To organize the control signal between various conditions modalities, a spatiotemporal control map is proposed and applied to achieve more fine-grained control over the synergy between different conditions. Given a control map \(\mathbf{w} \in \mathbb{R}^{N \times X \times Y \times T}\) that’s been derived manually or by a model, it balances the weight between different conditions at different pixel locations and timestamps. Thus, one can specify which regions at which timestamps should follow more on certain conditions, enhancing the flexibility and customization of the overall framework.
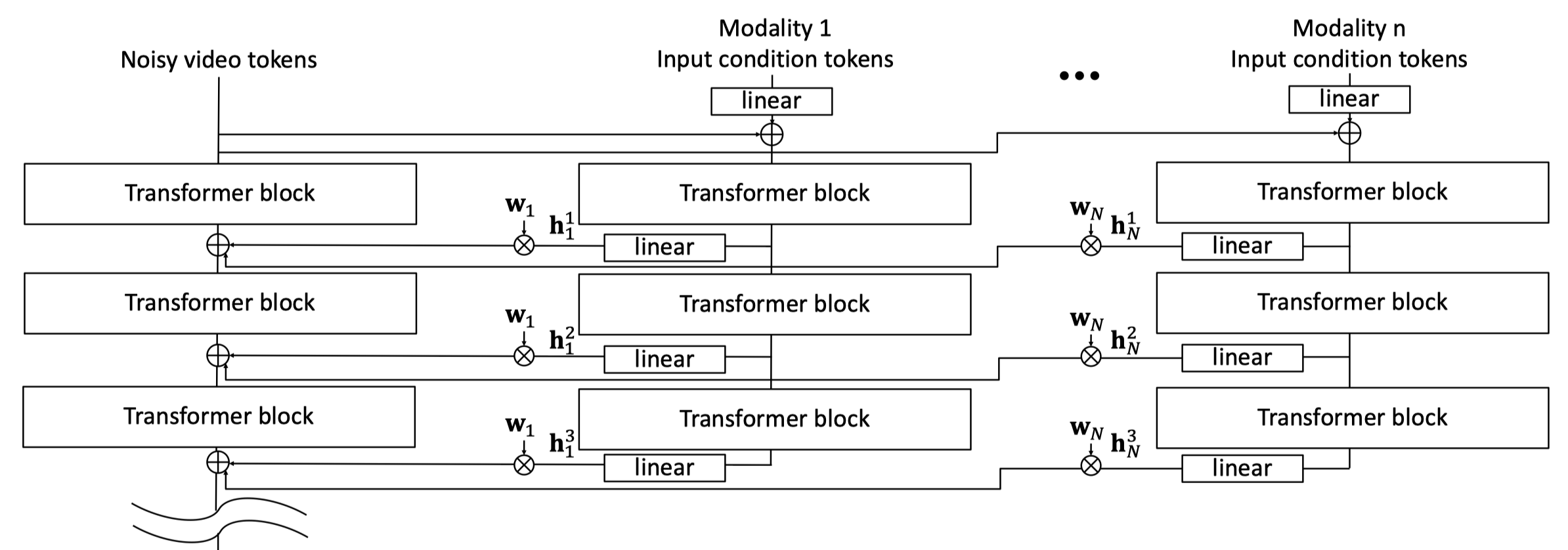
Control branch and spatiotemporal control map of the Cosmos-Transfer1.
The Cosmos-Transfer1 model does not involve too many novelties, but instead tries to combine the latest techniques used in the mainstream generation framework, thus enabling the effective controllable generation for the state-of-the-art world models. Many engineering techniques are employed to make the model effective and efficient for the application of the world models.
Experiments
Extensive experiments have been conducted on the generated output of the Cosmos-Transfer1 model, which evaluates its visual quality, controllability, and diversity.
Evaluation Metrics
For the visual quality, the experiments use the DOVER-technical score to serve as a perceptual metric for assessing aesthetic quality. The controllability is evaluated on different modalities,
- Vis: The
Viscontrollability is evaluated by the Structural Similarity Index Measure (SSIM) between the input video and the generated video by applying the same blurring operation. - Edge: The same Canny edge extraction is applied, and a classification F1 score is computed between the input and output.
- Depth: The scale-invariant Root Mean Squared Error (si-RMSE) between the depth map of the input and output video extracted by the DepthAnythingV2 model is evaluated.
- Segmentation: The mean Intersection over Union (mIoU) between the segmentation masks of input and output videos obtained using GroundingDINO + SAM2 annotation pipeline is used.
The diversity is evaluated by giving the same condition and \(K\) different prompts and computing the LPIPS scores between all the video pairs among the \(K\) generated videos.
Ablation
Condition Modality
By comparing the evaluation metrics between models using a single control condition, multimodal control, and full sets of modalities, the authors discover that the conditions can be classified as dense and sparse conditions. Modalities like Vis and Edge are dense conditions as they provide visual details and a large percentage of active pixels, while Depth and Seg are sparser conditions as Depth are less visible in further regions and Seg only records object classes information but fails to distinguish between different instances.
Through their experiments, they find that:
- Dense conditions achieve the highest respective controllability, and sparse conditions lead to less accurate reconstruction.
- Excluding either condition results in a decrease in the respective metric, and denser conditions yields a lower diversity score.
- The model with the full set of control modalities achieves the highest visual quality with balanced controllability.
Spatiotemporal Control Maps
To employ the control maps for generation, the paper classifies the pixels into foreground and background ones, and applies different strategies for them. They attempted to condition foreground on either dense or sparse conditions, and vice versa for background pixels. Through their ablation, they find that:
- Conditioning foreground/background on dense/sparse conditions leads to better visual quality but less foreground diversity.
- Conditioning foreground/background on sparse/dense conditions results in less background diversity.
- Dense conditions provide denser structural information, precise control, but fewer degrees of freedom compared with sparse ones.
Case Study
The paper studies two different applications, one on robotics manipulation tasks and the other on autonomous driving. Their findings provide useful insights into what condition modalities to use and how to apply them for specific tasks.
Robotics Sim2Real
By generating video based on the simulated environments of robot manipulation, it can be used to train robot policies that can be generalized to various real-world scenarios, thus bridging the Sim2Real gap between the simulator and the real world. Through their experiments, they find that
Segprovides diverse backgrounds but introduces foreground artifacts.Edgecan preserve the robot’s shape.Viscan preserve the appearance of the robot, including color and texture.- Multimodal control with spatiotemporal map achieves overall better visual quality, controllability, and diversity.

Robot manipulation output of Cosmos-Transfer1 model.
Autonomous Driving
Different from the previous settings, a set of conditions, including HDMap and LiDAR, is introduced for this application. By generating videos based on these conditions, it can enrich and diversify the existing driving scenarios from the simulator and the real world with different weather conditions and lightning conditions that pose challenges to autonomous driving systems. Similar to the Depth and Seg conditions pairs, the HDMap provides semantic information about the road layout, traffic signals, and instance classes, while the LiDAR provides geometric information from the dense depth structure. Through experiments on simulation environments, they also found that though trained on real-world data and annotations, the model can generalize well into synthetic conditions and generate outstanding videos.

Autonomous driving output of Cosmos-Transfer1 model.
Inference Results
To validate the model’s performance and effectiveness, we test the model on some realistic driving videos. By extracting their Depth and Seg condition videos and using them as the input of the model, we obtain generated videos with diversity while following the conditions.
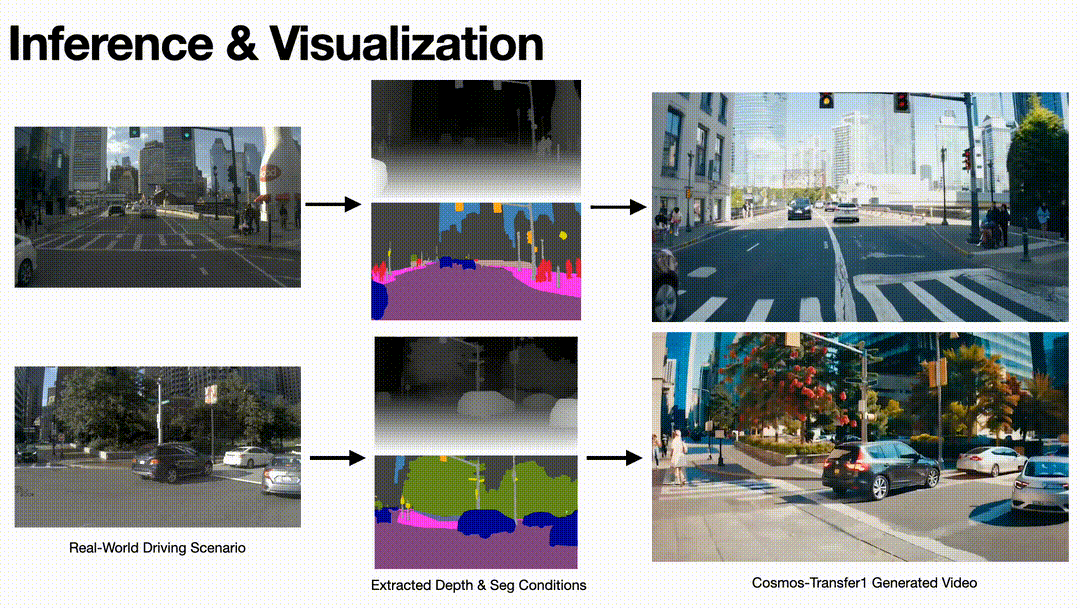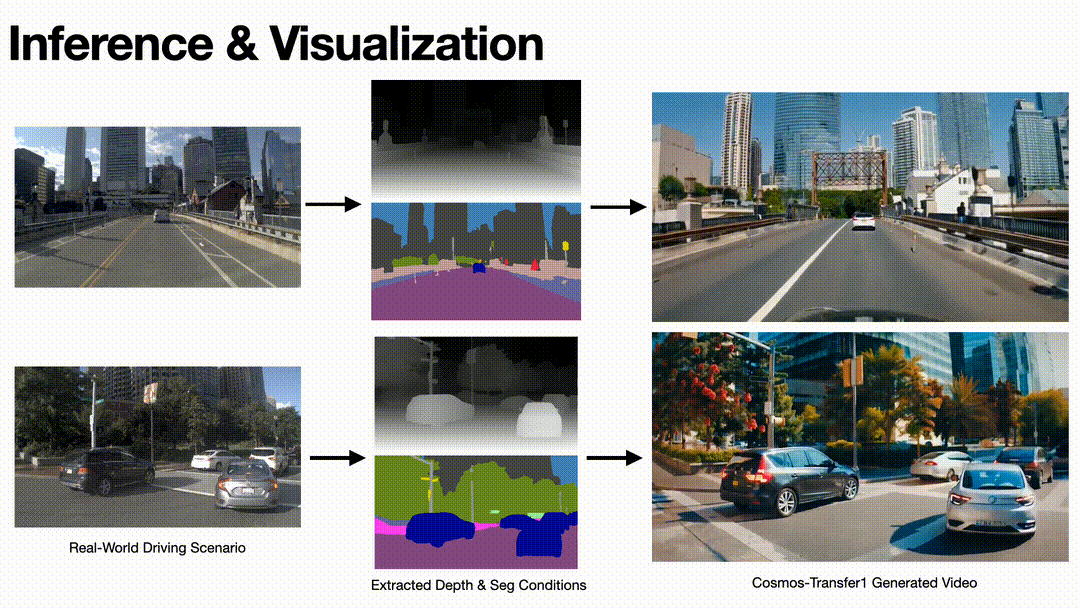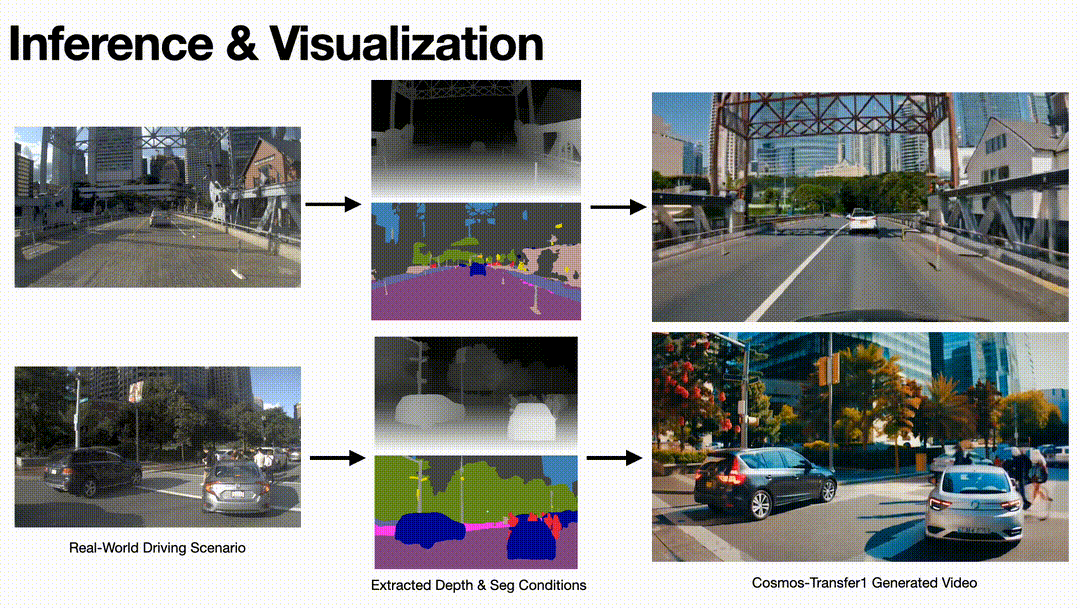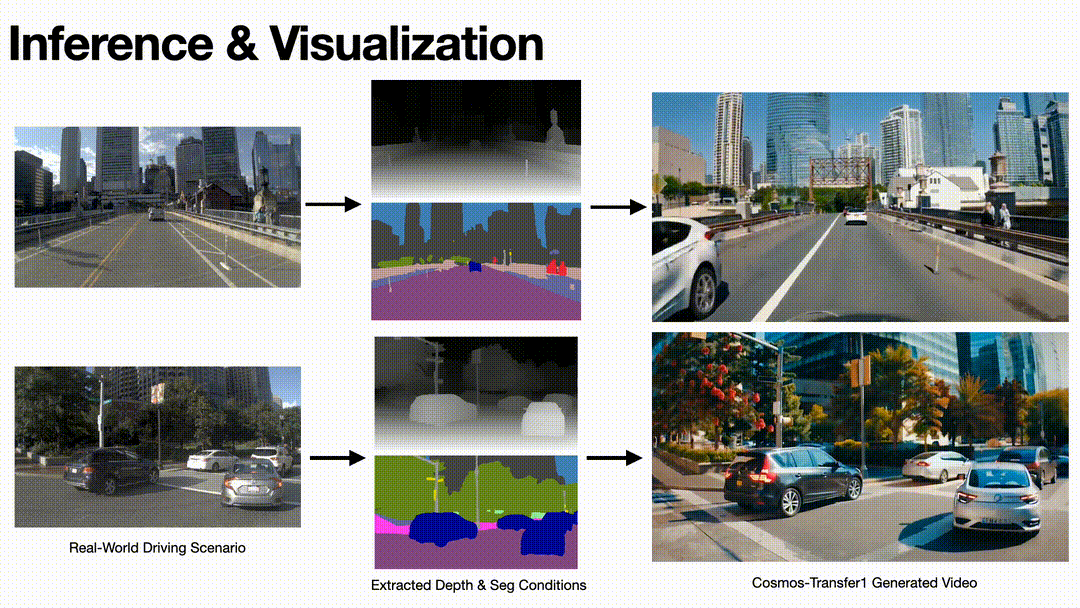
Inference results on driving scenario of Cosmos-Transfer1 model.
Based on the output results, we can see that the Cosmos-Transfer1 model can generate video with strong spatiotemporal consistency with good visual quality.
Discussion
While the Cosmos-Transfer1 model achieves both good visual quality and controllability, one of the bottlenecks for application lies in the generation efficiency. Due to the large computation required by the model, generating 121 frames of video takes more than 10 minutes on a single GPU. According to the NVIDIA experiments, only with more than 32 latest B200 GPUs can the model achieve real-time generation. This poses challenges to applying the model in policy training, where the downstream model would use the generated results as observations and produce output. Without the real-time inference ability, the Cosmos-Transfer1 cannot be combined with the simulator and obtain the rewards required to train the policy. Future techniques such as efficient denoising and distillation may potentially solve the problem, and thus enable the synergy between the simulator and the model.
Conclusion
In this report, we cover the Cosmos-Transfer1 model, a conditional generation world model. Various useful insights have been concluded in the experimental results section, which would better assist in the application of the model. Some future directions for optimizing the model and extending its application have been discussed.
References
[1] Alhaija, H. A., Alvarez, J., Bala, M., Cai, T., Cao, T., Cha, L., … & Zeng, Y. (2025). Cosmos-transfer1: Conditional world generation with adaptive multimodal control. arXiv preprint arXiv:2503.14492.
[2] Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., Cai, T., … & Zolkowski, A. (2025). Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575.
[3] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851.
[4] Peebles, W., & Xie, S. (2023). Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 4195-4205).
[5] Zhang, L., Rao, A., & Agrawala, M. (2023). Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 3836-3847).
[6] Mo, S., Mu, F., Lin, K. H., Liu, Y., Guan, B., Li, Y., & Zhou, B. (2024). Freecontrol: Training-free spatial control of any text-to-image diffusion model with any condition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7465-7475).