Independent Causal Mechanism for Robust Deep Neural Networks
In order to generalize the machine learning models and solve the “Distribution Shift” problem, we want to propose a different solution with independent mechanisms. We want to find effective independent mechanisms or experts to help us generalize across human faces. With the casual mechanisms we implemented, we can use them to detect human faces more robustly.
Introduction
Almost all machine Learning models have issues with generalization that stems from a phenomenon called distribution shift. This problem is due to the difference between the testing and training distributions which could both be subsequently different from the final real world data distribution. There are several well known approaches to improving model generaliztion including but not limted to, adding more data, balancing catgeories in the datasets, and data augmentation. Despite the improvements made by these approaches, one can easy find examples of real world data or through techniques like advesarial learning that can still fool the model. The issue could be due to not considering the causal effects on data generation [1].
We want to combine casual mechanism into our project. The goal of this project is to try and identify the mechansims that effect the distribution of human faces.The distribution of human faces contains a variety of unqiue features that can be driven by genetics (hair, eye color, shape, etc), by culture (Turban, Hijab, etc), personality (beards, glasses, masks, etc), etc. These features can be thought of as “augmentations” that are driven by causal mechansims which effect the distribution of inherent human features(features all humans share). Finding these causal mechanisms could lead to greater ability to generalize across human faces.
Related works
[1] In this paper, the authors propose an insight that could potentially lead to broad improvements in machine learning. It requries a shift in perspective and thinking about the causal effects that produce the distribution itself. In causal modeling, “the structure of each distribution is induced by physical mechanisms that give rise to dependences between observables.” These mechanisms or experts have several unique properties of interest. First, they are independent and do not inform one another. Second, they are autonomous generative models effecting the distribution itself which grants them the ability transfer between problems.
[2] In this paper, the authors propose Recurrent Independent Mechanisms (RIMs), a new recurrent architecture in which multiple groups of recurrent cells operate with nearly independent transition dynamics. It uses an attention mechanism to train the RIMS effectively. And empirically, the authors found that if the learned mechanisms are too complex, it is easy for an individual mechanism to dominate. But if the learned mechanisms do not have enough capacity, then different RIMS have to work together. With Competitive Learning, multiple RIMS can be active, interact and share information.
Experiments
In order to build and train the model, we borrowed some boiler plate code from the licms[3] repository. It contained an implementation of the model described in the paper [1]. However, several modifications needed to be made in order to make the model work for us. The changes are listed below.
- Condensed the code: We reduced the code such that the model and data are defined and trained in a single file. The goal was to keep it simple and easy to integrate with Google Colab.
- Adapted Data loaders: We defiend custom data loader classes to work for our specific datasets.
- Changed the Models: The model implemented in licms was desgined to work for a different dataset than ours and needed to be adapted.
- Changed the training algorithm: Although the initial code was working, we found ways to improve its efficiency by powering logical operations using torch rather python code.
The changes were made based on the dataset we were working on. Our different experiements and the subsequent results for each is given below.
MNIST
Model/Data
Initially, the goal was to replciate the results seen in paper [1] by training on MNIST. this would allow us to confirm that both our code was working and that the results in the paper were sound. In order to do this, we updated the code to use the expert and descriminator architectures describe in the paper. The details are given below.
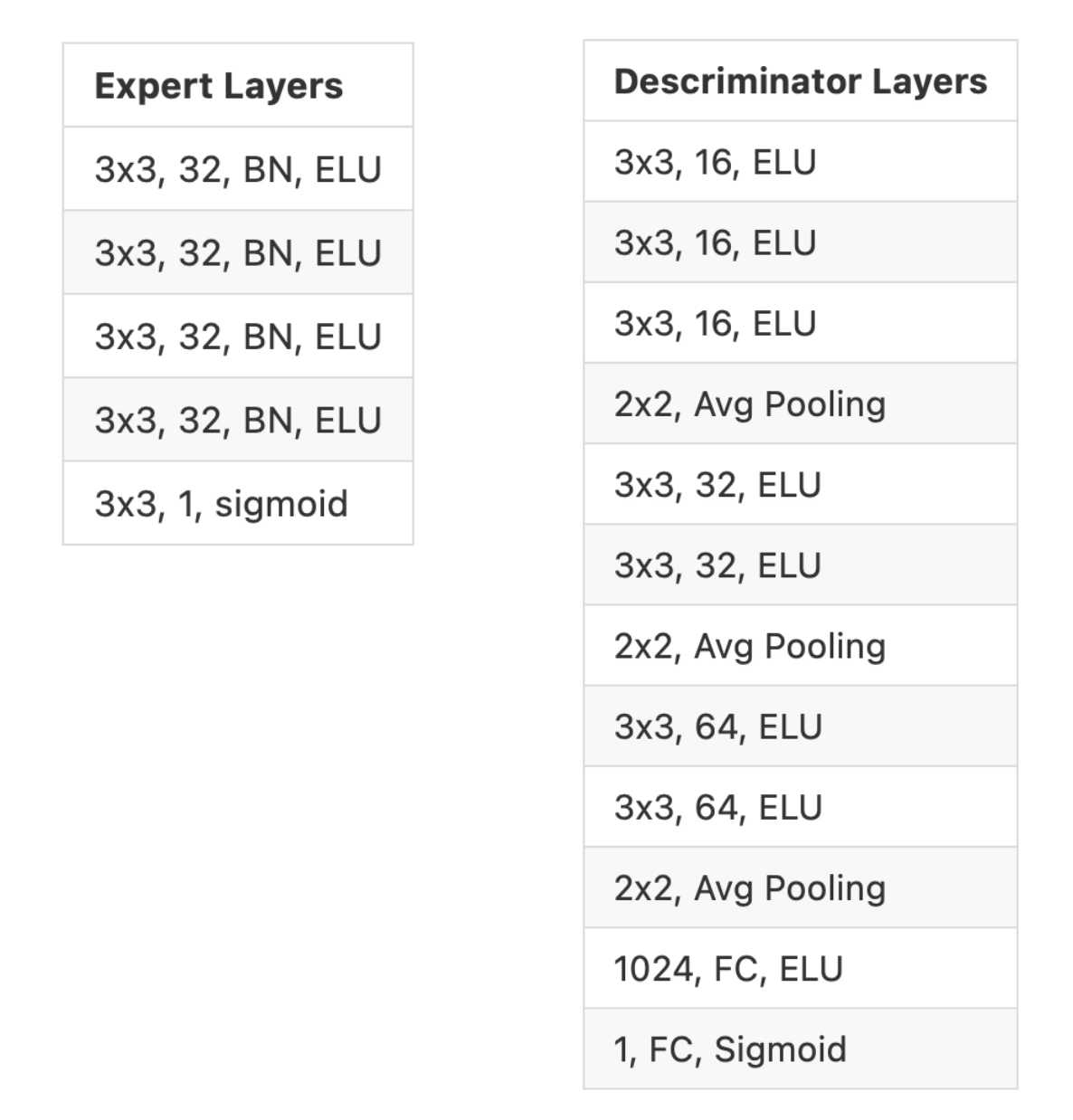
There were several issues we faced when trying to train this model. The main problem was due to training time requried to pretrain the experts on the transformed data. Each expert needed to first process the entire MNIST dataset before attempting to specialize with the help of the descriminator. This process is detialed more clearly in paper [1]. Due to our computational limintations, we decided to experiement on only three different transformations on the data: right translation, down translation, inversion. Additionally, we further simplified the problem by working on a single image class rather than the entire MNIST dataset. This reduced the MNIST dataset size from 60k to around 10k and significantly reduced the training time required for our model. We felt that these changes do not significantly alter the results we saw after training. This data preprocessing was done using torch’s builtin image transformation operations.
Finally, the experts and discriminator in this case were trained using binary cross entropy loss and Adam optimizer for 3000 iterations.
Results
The resulting loss and scores for the experts are given in the images below.
The following figures show case the loss for the 3 experts for 3k iterations.



The folloiwng figures show case the experts score against the discriminator. Note that fooling the discriminator means a greater expert score.
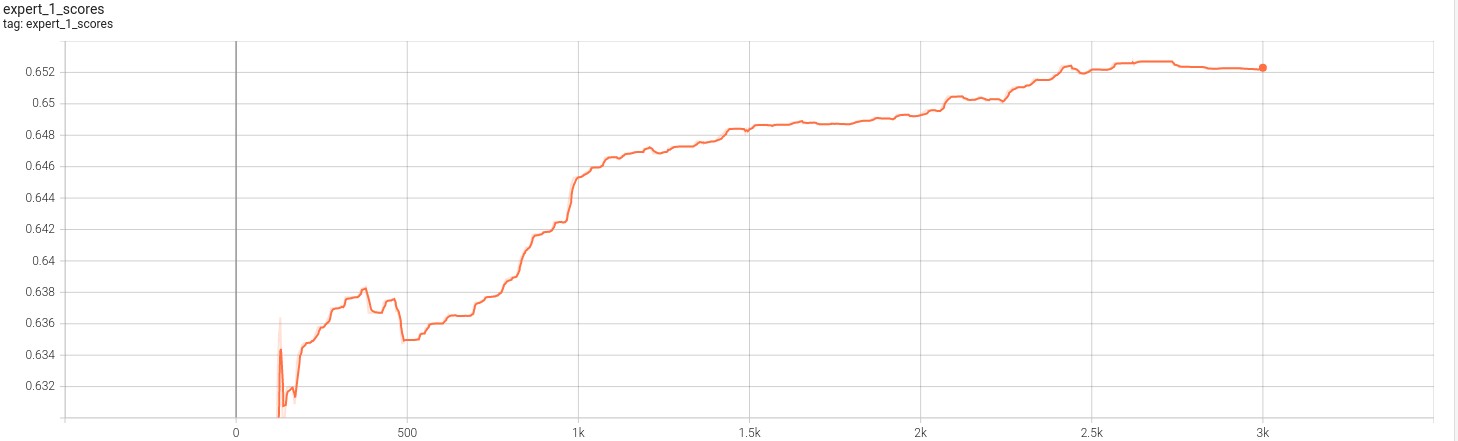
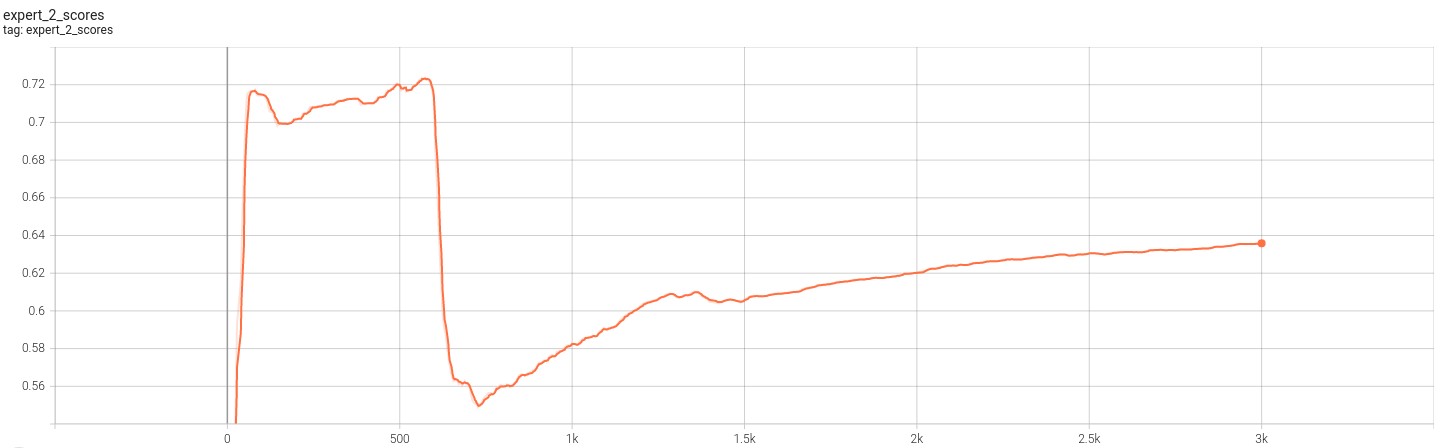
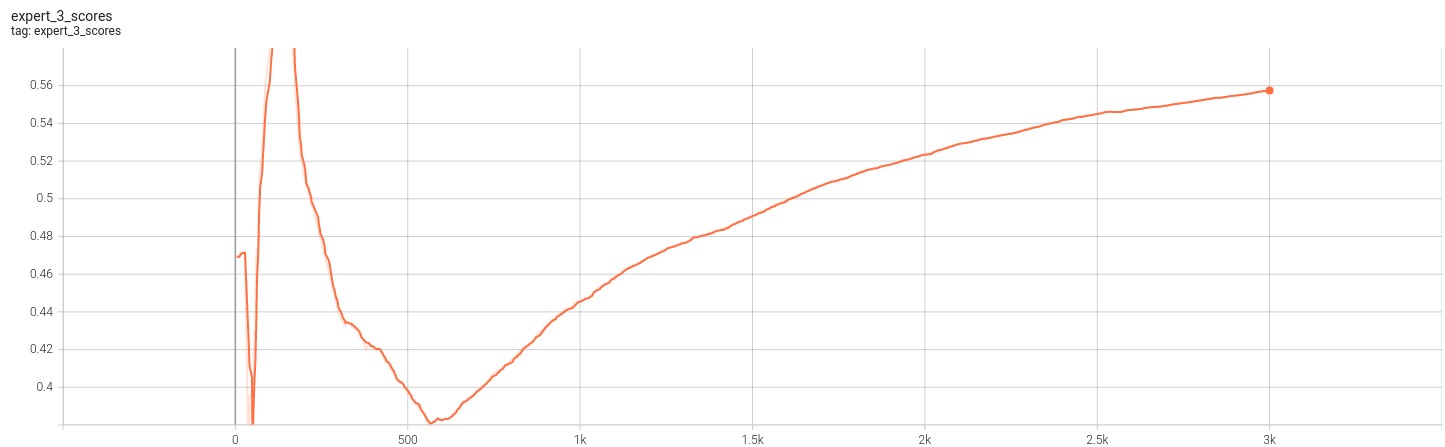
Based on the two different sets of figures above, we can verify that the model is able to effective trian to find the mechanisms that drive the transformations. This is because the loss fucntion for all three experts appear to become smaller while their scores against the discriminators rises till convergence. This result is consistent with those we see in paper [1] and therefore gives us confidence that the code and model works as expected. Finally the folloiwng figure further reinforces this fact.

In the image above, we have five different samples for the number 6. The first column is the MNIST image, second column contians the transformed image (right, down, inversion), third column is the expert which specialized on inversion, fourth column is the expert that specialized on down translation and finally fifith column is the expert that specialized on right translation.
Problem Setup
Next, we tackled the problem that we originally set out to test. In order to do this, we first needed to reimagine the definition of a transformations detailed in the original paper. Unlike MNIST model, the transformation in our faces dataset were intrinsic physical characteristics shared among people of the same race. This allows us to emulate mechanisms that transform an existing probabiltiy distributions which can subsequently learned. We arbitrarily chose “asian” as the canonical probability distribution that is “transformed” by mechanisms to produce transfored distributions representing “white” and “black”. Going forward, we will refer to these distirbutions as canoncail and transformed. In this way, we set up the problem such that an expert can learn to invert the transformation back to the canonical distribution. In the following sections we detail our efforts to trian the model for this purpose.
Datasets
Below is the datasets, we would work on them for training our mechanisms.
- Face pictures with featuress driven by genetics and culture
- UTKFace

- The dataset is a large-scale face dataset with long age span (range from 0 to 116 years old). The dataset consists of over 20,000 face images with annotations of age, gender, and ethnicity.
- FaceARG

- The dataset contains 175,000 facial images from the Internet and used four independent human subjects to label the images with race information. It gathered the largest available face database (of more than 175000 images) annotated with race, age, gender and accessories information.
- UTKFace
Faces Classifier
First, we needed an effective way to measure the performance of our experts after they have spspecalized to invert the transformations. For this purpose, we decided to train a neural network classifier that is able to distinguish between the canoncail and transformed distributions.Once trained, the objective of the experts would be to invert the transformations such that they are able to trick this model to misclassify expert outputs as having originated from the canoncical distribution. This approach would allow us to measure the trained experts.
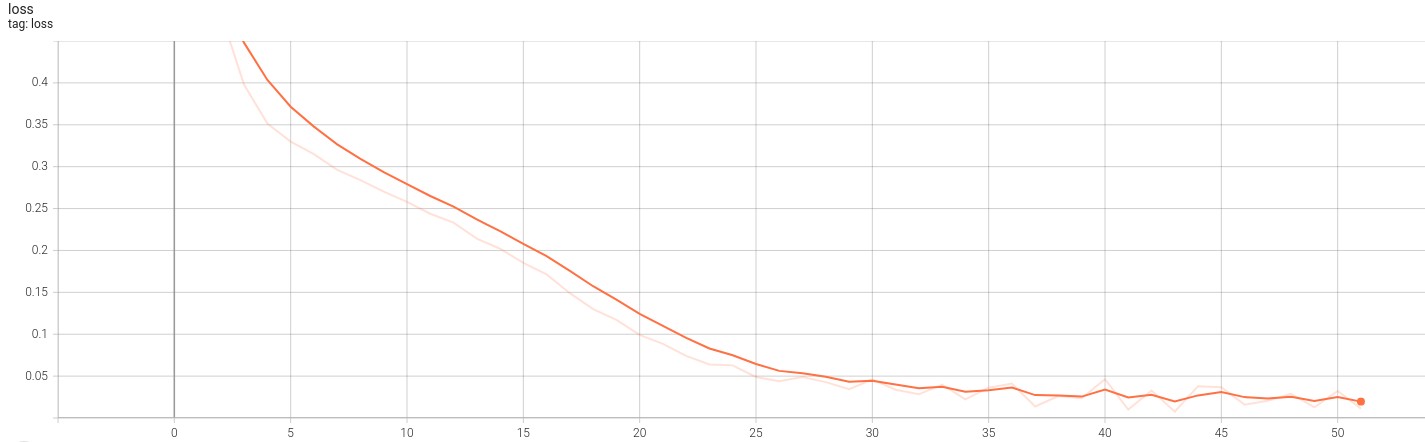
This model, called faces_classifier, was a simple CNN trained with binary cross entropy loss where data from the canoncial distribution was taken to be the positive label while transformed data was negative. We trained this model for 50 epochs at which point the loss function for the model converged.
The figure below shows the loss function for this model. Although we did train this model, we ultimately did not using it given that the results for our experiements were not sufficient to employ it.
Faces
Once we had a classifier, we shifted our focus to model and train the experts to invert the transformations. The model needed several changes from the original MNIST model. First, we needed to make sure that the model can work with RGB datasets. In order to do this, we changed the design of our experts. The details can be found in the table below.

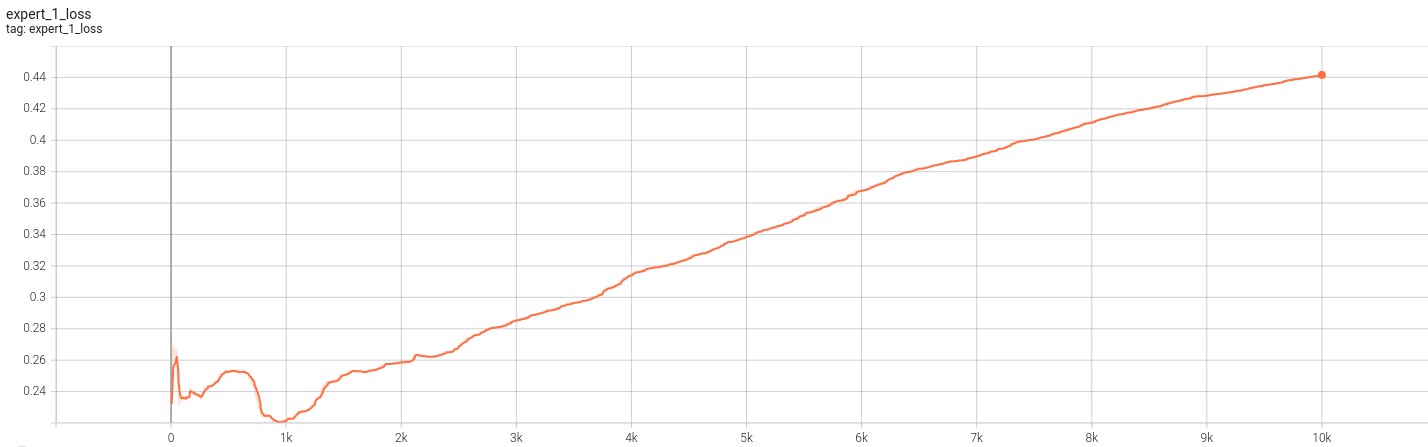
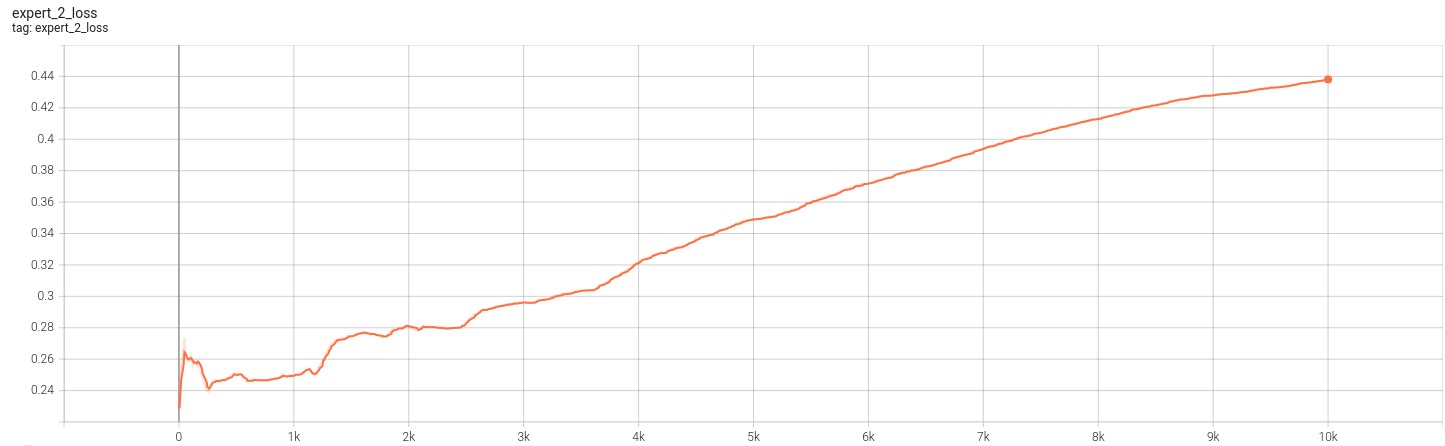
The primary difference was that we modifled the activation function to be Relu rather than ELU. Additionally, the outputs of the experts contained 3 channels for RGB. This changes also required us to make more modifications to our loss functions and the input dataset. We normalized the pixel values in the datasets to between [0,1] and resized the images to match the shape of the MNIST dataset (28x28). This was done for increasing training speed and stability. Second, we used the mean squared error loss as the loss fucntion for training the experts. Finally, note that for this model we only need 2 experts becuase there are 2 “transformed” distributions. After making these changes, we trained the model for approximately 10k iterations.
The following images showcase the loss for the 2 experts for 10k iterations.
The following images showcase the expert score against the discriminator. Note that fooling the discriminator means a greater expert score.
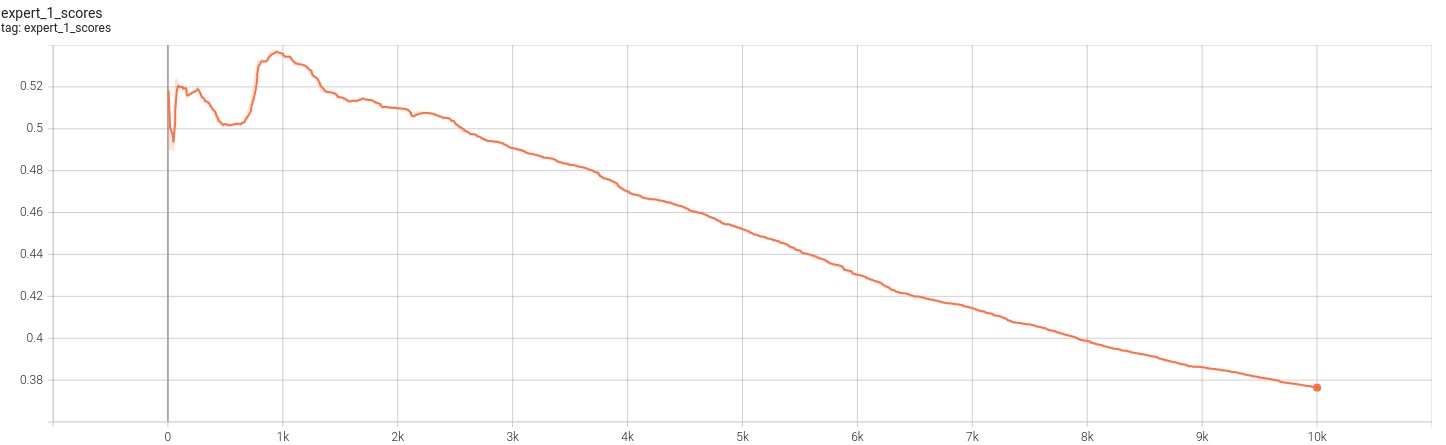
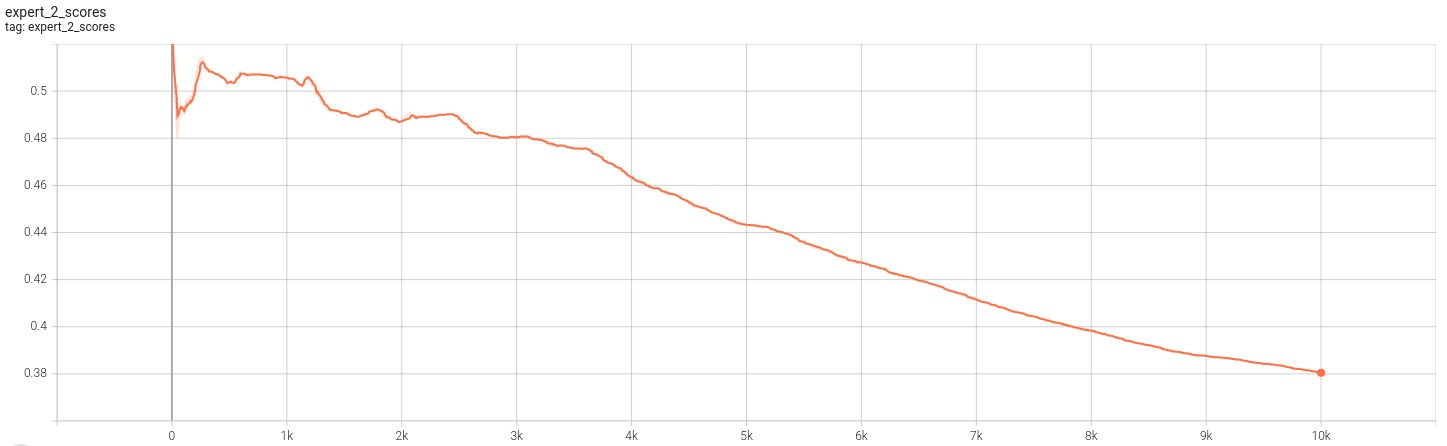
Based on the figures above, we can see that the model has failed to learn the transformations. This is evident from both the divergence of the loss function as well as the converge to zero of each of the experts score. The loss functions indicate that the experts are not able to produce a meaningful inversion of the transformed inputs they receive. The scores indicate that the outputs from the experts do not fool the discriminator. This becomes more clear from the image below.

In the figure above, the first column contains the data from the canoncial distribution, the second from the transformed distribution. The remaining two are images output from each of the experts. As expected from the scores and loss values, neither of these experts produce results that are meaningful. When considering the datasets in detail, these results are not surprising. Both of these datasets have a considerable amount of variation like facial orientations, image lighting, etc that make it very difficult for the experts to converge. Additionally, the architecture of the experts and the mean squared error loss function may not be suffiencet for complex datasets like this. We made several attempts to tune the training process to try to get meaningful results but were ultimately unsuccessful.
VAEExpert
Finally, due to the limitations posed by experts that are simple CNNs, we attempt to see if employing variational autoencoders in or model could yield better results. Variational autoencoders (VAE) are neural networks that are tuned to learn latent space representations of input data. By choose a sufficiently small latent space, the idea was to optimize the VAE to find representations that focus on the facial features but ignore non-essential information like orientation. We used VAEs as experts in our model and the initialization phase invovled training the VAE experts themselves to learn the latent space for the transformed distributions. Then using the descriminator, we attempt to train the experts to specialize.
Training VAEs is tricky and difficult to get right. The loss function for these experts was a combination of the reconstruction error(mean-squared error) and a weighted KLDivergence. This training required tedious hyper parameter tuning to get the experts to initiialize appropriately. The model for the VAE experts is given below.

Once we intialized the experts, we applied the algorithm in paper [1] to finetune the model to special. The resulting loss and scores for the experts are given in the following figures.
The following figues showcase the loss for the 2 VAE experts. Note that training for this model was cut short due to convergence.
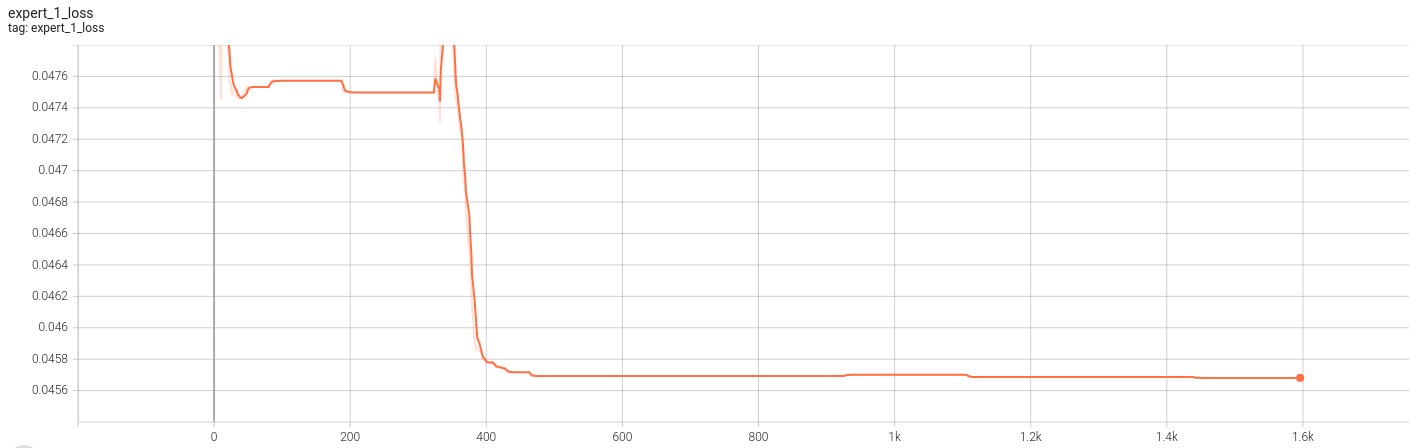
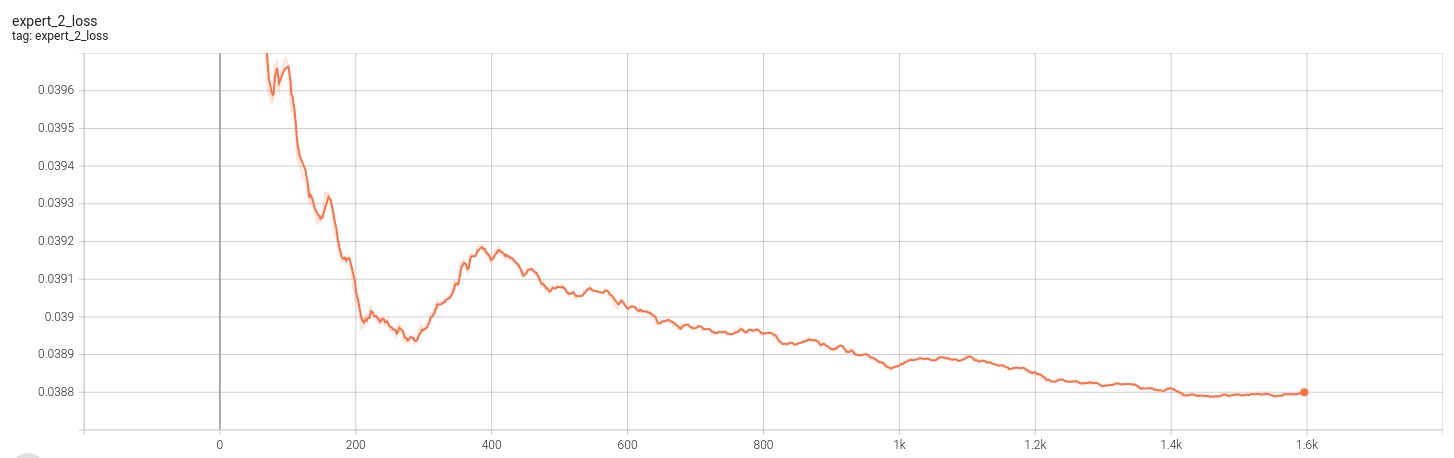
The folloiwng figures showcase the score for the 2 VAE experts. Note that training for this model was cut short due to convergence.
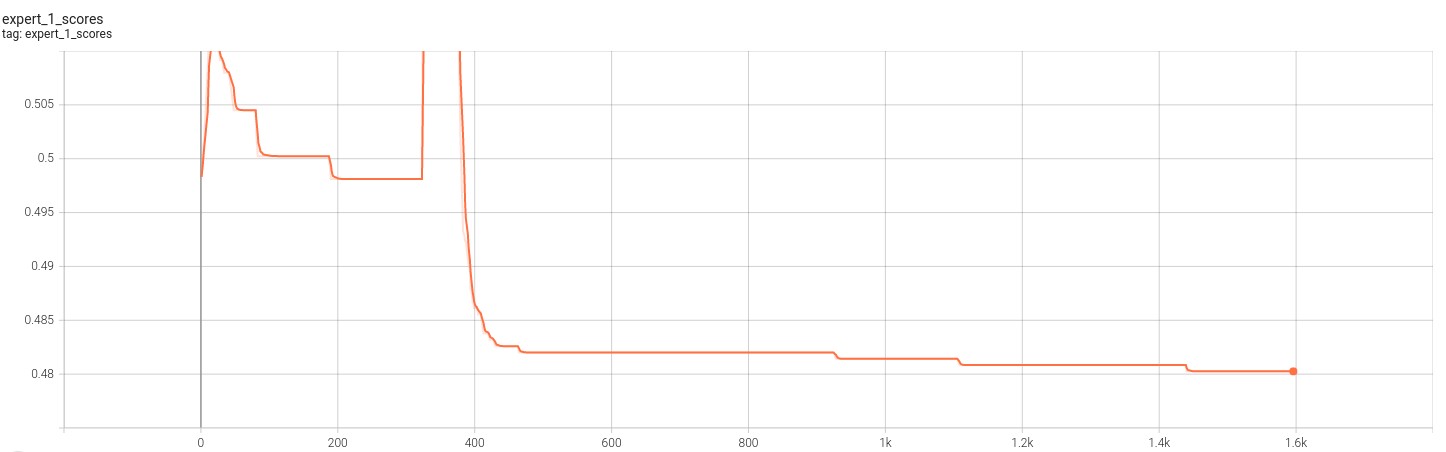
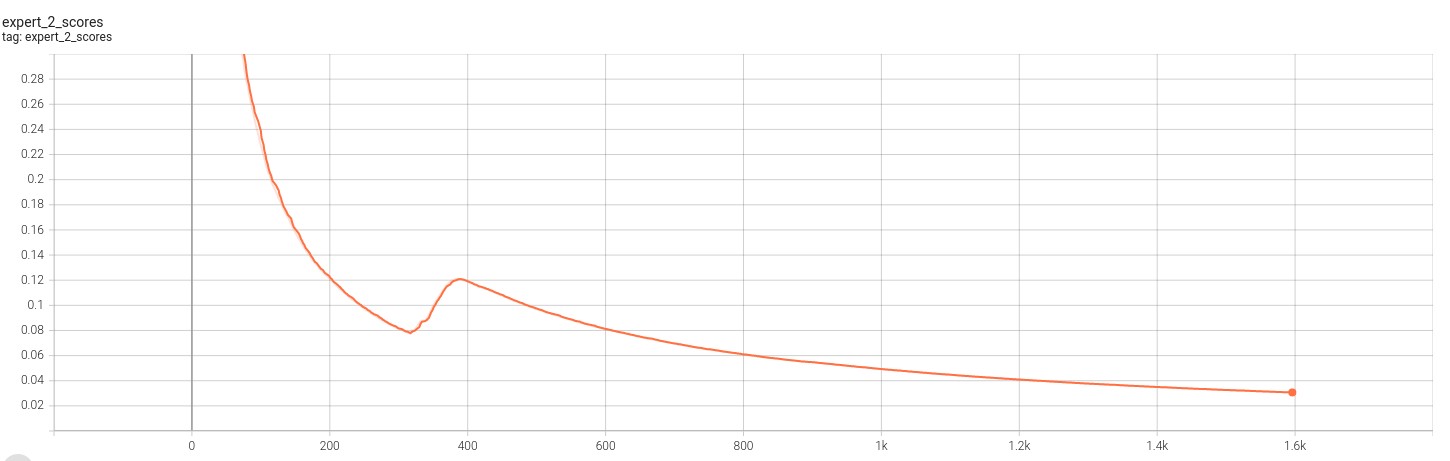
From the above sets of figures, we can see that the loss function for the experts converges as expected. However, the score for each of the loss functions also converges. This indicates that although the experts are able to produce an image that is representative of the transformed distribution, it still is unable to fool the discriminator. This result becomes more clear when we look at the output from the experts which is given in the figure below.

In above, the first column is the canonical distirbutions, the second is the transformed distribution, and the last two are outputs from the experts. In this case, it’s clear that the VAE experts are producing an image that is clearly human. However, this image has the opposite issue: it does not capture enough variation and seems to produce the same output. This observation explains why the loss converges but so do the scores against the discriminator. The VAE loss function is convering but the experts are unable to specialize enough to fool the discriminator. We believe that this problem may be fixable through hyper parameter tuning and using more expressive models like BetaVAE.
Conclusion
We set out to see if we can employ the indepedent causal mechanism principal to its maximum effect by trying to apply the ICM model [1] to a more sophisticated dataset like human faces. We took several steps to try to garner some results but were ultimately limited by the datasets. The issue is due to the complexity of the dataset rather than an issue with the model itself. There exists considerable amount of variation within the canonical/transformed distributions themselves(age, sex, orientation) making the experts in the ICM model difficult to train. We believe that a dataset specifically designed to apply the ICM model may yield better results and could present a possible direction of future study.
We have uploaded our code in this Github repo. Thanks!
Reference
[1] Giambattista Parascandolo, Niki Kilbertus, Mateo Rojas-Carulla, Bernhard Schölkopf. “Learning Independent Causal Mechanisms” Proceedings of the 35th International Conference on Machine Learning, PMLR. 2018.
[2] Goyal A, Lamb A, Hoffmann J, et al. “Recurrent independent mechanisms” arXiv preprint arXiv:1909.10893, 2019.
[3] Evtimova K, licms, 2018, Github Repository, https://github.com/kevtimova/licms