Virtual Try-on on Videos
Image-based Virtual Try-On focuses on transferring a desired clothing item on to a person’s image seamlessly without using 3D information of any form. A key objective of Virtual Try-On models is to align the in-shop garment with the corresponding body parts in the person image. The problem at hand becomes challenging due to the spatial misalignment between the garment and the person’s image. With the recent advances of deep learning and Generative Adversarial Networks(GANs), intensive studies were done to accomplish this task and were able to achieve moderately succesful results. The subsequent task in this direction would be is to apply the Virtual Try-On on videos. This has many applications in fashion, e-commerce etc sectors. We have started by using an existing state of the art image virtual tryon model and included various state of the art techniques to improve the performance of the videos. We have included Flow obtained from Flownet model to improve the overall smoothness of the video. Previously in video virtual tryon tasks, depth has never been taken into consideration to improve the video quality. In a novel approach, To improve the fitting of the cloth, we have used depth information and trained on various models including ResNet([7]), DenseNet([8]) and CSPNet([9]). The video quality has improved after adding these training tasks. Finally we have augmented the dataset by adding different backgrounds in the videos and trained on the above models to understand the effect of background in virtual tryon.
- Motivation
- Related Work
- Methodology
- Network architectures
- Datasets
- Results
- Conclusions
- Code
- References
Motivation
With the rise of online shopping and e-retail platforms, Virtual Try-On of clothing garments is a key feature to enhance the experience of the online shoppers. Many intensive studies are done to solve this problem. Some initial methods focussed on image to image translation models without spatial aligment. Later some studies addressed the spatial alignment by performing garment warping using local appearance flow. One of latest studies also proposed a global appearance flow using StyleGANs for better spatial adjustment. So overall, a lot of work has been done in the are of image based Virtual Try-On and results have suprassed the minimum satisfiable requirements. While there are still room for improvement in image based Virtual Try-On methods, generating videos with Virtual Try-On is also very relevant in e-commerce and should be addressed hand in hand with image based approaches. Most existing video-based virtual try-on methods usually require clothing templates and they can only generate blurred and low-resolution results. Very few methods exist which uses relatively new versions of GAN to solve the video-based virtual try-on problem. Hence in this project, we would like to address this problem by taking a closer look of existing approaches and solving the problems with them.
Related Work
Recently there has been lot of work on Virtual Tryon. Initial models try to just overlap the cloth to the person without much spacial alignment. Later methods incorporated garment warping techinic using local flow estimation of cloth and that has improved the virtual tryon output. Recently, the “Style Flow” ([1]) method focuses on finding a global appearance flow of cloth based on person pose and use that for Virtual Tryon. This method handles difficult body poses, occlusions and misalignments between person and garment better. We have used this model as our baseline to start from and then we explored various approaches to further improve the Virtual Tryon.
ShineOn ([2]) is a model that performs virtual video tryon. The model uses a UNET based architecture at the core that does the cloth warping on the image of the person. The UNET based model is connected with a flow based architecture that helps the model gain better flow in the videos compared to simply appending the frames one after the other. There were few issues with the model where the neck part of the image was disappearing when the images were zoomed in while trying to generate the output. In our work we try to extract few interesting aspects of the ShineOn model like including flow for frame generation.
Methodology
Inference on existing models
Basic approach - Using Image virtual Tryon model:
We have mentioned StyleFlow model in the related work that it has better performance than existing UNET based models in terms of image virtual tryon. Existing Video virtual tryon models make use of the UNET model as the core to perform the cloth warping. Hence we decided to use the latest StyleFlow model as the core of our model to perform the image virtual tryon. For the baseline model, we have split the input videos into multiple image frames. These input image frames are passed to the StyleFlow model and an output frame is received that has the new cloth on the image. All these output image frames are then combined into corresponding output videos. The StyleFlow model, as we have discussed earlier, estimates the dense pose of the person and warps the cloth to that pose very well and hence image outputs will be of very high qulaity for eeach frame. We have observed that these videos were very smooth compared to what we have expected. The main reason might be due to the fact that these videos were not very fast moving and had perfect backgrounds that helped the output videos to be smooth. Then we have tried with videos that are not very ideal with different backgrounds and speeds. We found that the output videos are now having many artefacts and there is a scope of improvement. For this reason we have come up with the following approaches to improve the performance of our model.
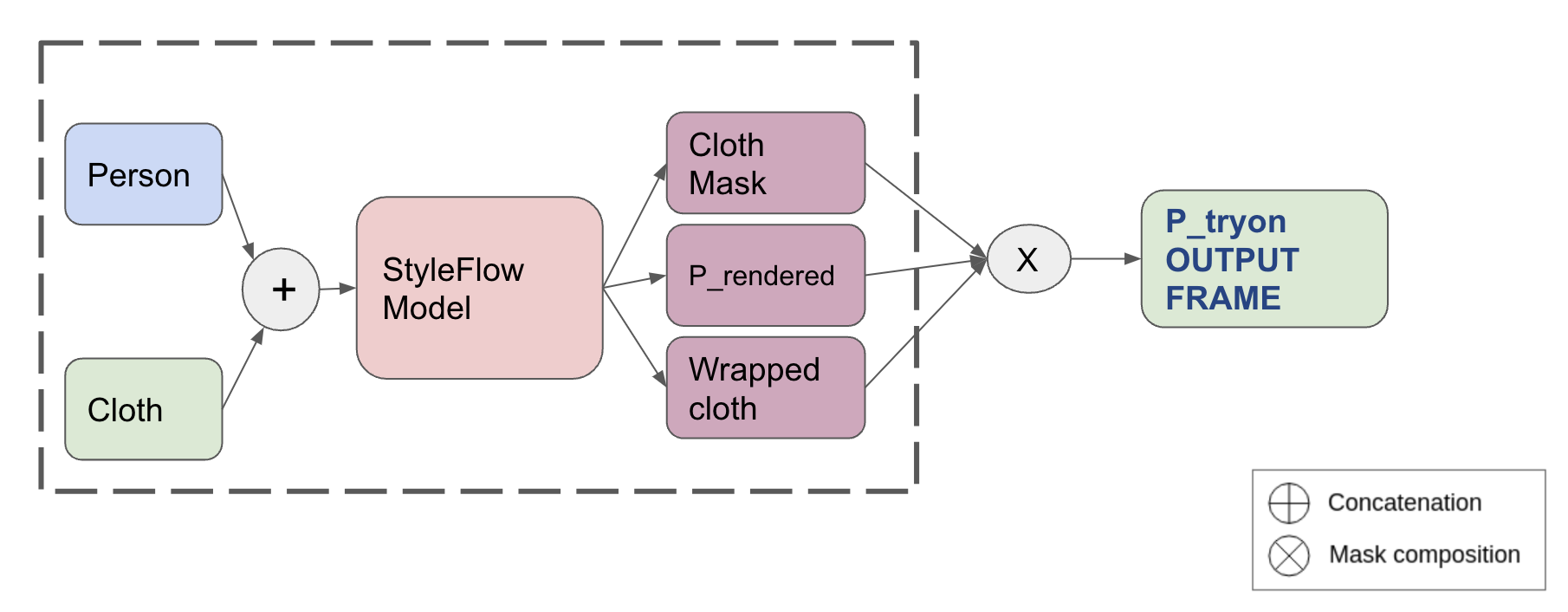
Using Flow - Trying to improve overall flow of the model:
To improve the videos generated using the baseline method given above, we have tried out Flow which is generated by Flownet 2 model between images. Theoretically flow should improve the video quality as we do not expect the image to make drastic movement in the virtual tryon task. First we compute the output image for a frame as discussed above in the baseline method. Then we calculate the flow between two consective input images. This flow along with the output frame generated in the previous time instance is used to resample to generate an expected output frame in the current time instance. This resampled target output is then clubbed with the output image generated from the StyleFlow model so that the cloth region of the image is picked up from the output image and the rest of the part is mainly from the flow sampling. This helps to improve the flow of the background along with the person and the cloth will be generated as per the densepose recognized by the StyleFlow model.

Main Novelty: Adding depth to enhance performance
(a) Including depth maps/ creating new models For creating virtual tryons with depth we have created our own tweaked models. As previously stated, according to our knowledge this is the first work to use depth features for virtual tryons. We introduce ResTryon, DenseTryOn and CSPTryOn, which do use ResNet, DenseNet and CSP Net as inspirations.
ResTryOn is a simple combination of three residual blocks. The architectures are created in such a way that they can flexible to take inputs of any number of channels which makes the model very flexible for future research purposes too.
Their architectures as stated below:
Network architectures

Figure: Model architecture using Depth
DenseTryon
| Input | Output | Kernel Size | #input channels | #output channels | Stride | Activation | |
|---|---|---|---|---|---|---|---|
| DenseBlock1 | RGBs | conv1 | 3 | 64 | 32 | 1 | ReLU |
| DenseBlock1 | conv1 | conv2 | 3 | 32 | 32 | 1 | ReLU |
| DenseBlock1 | conv1,conv2 | conv3 | 3 | 64 | 32 | 1 | ReLU |
| DenseBlock1 | conv1,conv2,conv3 | conv4 | 3 | 96 | 32 | 1 | ReLU |
| DenseBlock1 | conv1,conv2,conv3,conv4 | conv5 | 3 | 128 | 32 | 1 | ReLU |
| TransitionLayer1 | conv5 | conv6 | 1 | 160 | 128 | 1 | ReLU |
| TransitionLayer1 | conv6 | avgpool1 | 2 | 128 | 128 | 2 | - |
| DenseBlock2 | avgpool1 | conv7 | 3 | 128 | 32 | 1 | ReLU |
| DenseBlock2 | conv7 | conv8 | 3 | 32 | 32 | 1 | ReLU |
| DenseBlock2 | conv7,conv8 | conv9 | 3 | 64 | 32 | 1 | ReLU |
| DenseBlock2 | conv7,conv8,conv9 | conv10 | 3 | 96 | 32 | 1 | ReLU |
| DenseBlock2 | conv7,conv8,conv9,conv10 | conv11 | 3 | 128 | 32 | 1 | ReLU |
| TransitionLayer2 | conv11 | conv12 | 1 | 160 | 128 | 1 | ReLU |
| TransitionLayer2 | conv12 | avgpool2 | 2 | 128 | 128 | 2 | - |
| DenseBlock3 | avgpool2 | conv12 | 3 | 128 | 32 | 1 | ReLU |
| DenseBlock3 | conv12 | conv13 | 3 | 32 | 32 | 1 | ReLU |
| DenseBlock3 | conv12,conv13 | conv14 | 3 | 64 | 32 | 1 | ReLU |
| DenseBlock3 | conv12,conv13,conv14 | conv15 | 3 | 96 | 32 | 1 | ReLU |
| DenseBlock3 | conv12,conv13,conv14,conv15 | conv16 | 3 | 128 | 32 | 1 | ReLU |
| TransitionLayer3 | conv16 | conv17 | 1 | 160 | 64 | 1 | ReLU |
| TransitionLayer3 | conv17 | avgpool3 | 2 | 128 | 64 | 2 | - |
CSPTryon
| Input | Output | Kernel Size | #input channels | #output channels | Stride | Activation | |
|---|---|---|---|---|---|---|---|
| RGBs | conv1 | 7 | 12 | 64 | 1 | LeakyReLU | |
| conv1 | maxpool1 | 2 | 64 | 64 | 2 | - | |
| CSPBlock1 | maxpool1 | conv2 | 1 | 64 | 128 | 1 | LeakyReLU |
| CSPBlock1 | maxpool1 | conv3 | 1 | 64 | 128 | 1 | LeakyReLU |
| CSPBlock1 | conv3 | conv4 | 1 | 128 | 128 | 1 | LeakyReLU |
| CSPBlock1 | conv2,conv4 | conv5 | - | - | - | - | - |
| TransitionLayer1 | conv5 | conv6 | 1 | 128 | 128 | 1 | LeakyReLU |
| TransitionLayer2 | conv6 | conv7 | 3 | 128 | 128 | 1 | LeakyReLU |
| CSPBlock2 | conv7 | conv8 | 1 | 128 | 256 | 1 | LeakyReLU |
| CSPBlock2 | conv7 | conv9 | 1 | 128 | 256 | 1 | LeakyReLU |
| CSPBlock2 | conv9 | conv10 | 1 | 256 | 256 | 1 | LeakyReLU |
| CSPBlock2 | conv8,conv10 | conv11 | - | - | - | - | - |
| TransitionLayer3 | conv11 | conv12 | 1 | 256 | 256 | 1 | LeakyReLU |
| TransitionLayer4 | conv12 | conv13 | 3 | 256 | 256 | 1 | LeakyReLU |
| CSPBlock3 | conv13 | conv14 | 1 | 256 | 512 | 1 | LeakyReLU |
| CSPBlock3 | conv13 | conv15 | 1 | 256 | 512 | 1 | LeakyReLU |
| CSPBlock3 | conv15 | conv16 | 1 | 512 | 512 | 1 | LeakyReLU |
| CSPBlock3 | conv14,conv16 | conv17 | - | - | - | - | - |
| TransitionLayer5 | conv17 | conv18 | 1 | 512 | 512 | 1 | LeakyReLU |
| TransitionLayer6 | conv18 | conv19 | 3 | 512 | 512 | 1 | LeakyReLU |
| CSPBlock4 | conv19 | conv20 | 1 | 512 | 1024 | 1 | LeakyReLU |
| CSPBlock4 | conv19 | conv21 | 1 | 512 | 1024 | 1 | LeakyReLU |
| CSPBlock4 | conv21 | conv22 | 1 | 1024 | 1024 | 1 | LeakyReLU |
| CSPBlock4 | conv20,conv22 | conv23 | - | - | - | - | - |
| TransitionLayer7 | conv23 | conv24 | 1 | 1024 | 1024 | 1 | LeakyReLU |
| TransitionLayer8 | conv24 | conv25 | 3 | 1024 | 1024 | 1 | LeakyReLU |
| conv25 | conv26 | 1 | 1024 | 512 | 1 | LeakyReLU | |
| conv26 | conv27 | 1 | 512 | 64 | 1 | LeakyReLU | |
| conv27 | conv28 | 1 | 64 | 3 | 1 | LeakyReLU |
Herein, firstly we take the input image and the cloth to be worn. This is both passed to the depth creation module as well the style generation module. The results from the depth module are then split into 2 stacks of 8 channels - each passed to a convolution block to get 3 channel results. The style generation module gives us a body mask and well as warped cloth. The 4 feature maps(12 channel input) are then concatenated and passed onto the “Tryon” model. The tryon model can be either ResTryon, DenseTryOn Or CSPTryon. We have used carbonier loss function between output image and rendered image. In future, one can also experiment with other loss functions like depth based loss functions (SSIM loss function with sharpened depth map) etc.
(b) Frame interpolation Tryon for fast videos: The architecture is a little more complex wherein instead of the previous 12 channel input to the tryon model, we use a 24 channel input to the model (which is a simple concatenation of the two frames to join both the videos) i.e. 12 channels each from frame1 and frame2 which is then passed on to the “tryon” models to get the interpolated frame.
Datasets
-
Original Dataset:
- VVT - dataset designed for video virtual try-on task, contains 791 videos of fashion model catwalk.
- Most widely used videos dataset for virtual try on applications.
- All videos have white background and hence models might overfit the background information while detecting the cloth position.
-
VVT subset dataset used for Training:
Considering the computation power and timelines, we have hand picked 40 videos which has an average of 250 frames per video. So in total we had trained our models on around 10000 frames. Out of which 30 videos data is used for training and 5 videos each are used for validation and test. Frame size in these videos is (256, 192).
-
Augmented VVT dataset with non-plain backgrounds:
All the videos present in the original VVT dataset have white background and hence we have observed many artifacts when we test on outdoor videos. So we have augmented the original VVT dataset by adding different backgrounds. We have trained a
person-segmentationmodel to segment the person in the foreground and thus replacing the background seamlessly with different backgrounds. Here are the details of theperson-segmentationmodel we have trained for foreground-background separation:-
Person Segmentation Model details:
-
ConvNet based model
-
Reference:
[person-segmentation](https://github.com/dkorobchenko-nv/person-segmentation) -
Trained on COCO segmentation (person) dataset for 100 epochs.
-
Here are the results from the person segmentation model:

Figure1: a) Original frame b) Person segmentation result c) foreground mask
Once the foreground mask is detected, we take background from a different image and combine it to result in the new augmented image. Here are some of the augmentation results:

Figure2: a1) original a2) with background b1) original b2) with background
-
-
Generating DepthMap training data: As we said, this is the first work to introduce depth maps for virtual tryons. However, we need a solid depth map generating system which can provide us all the necessary auxiliary information which can help reinforce better virtual tryon systems. For the same, we pass the input body mask image(explained earlier) through the Megadepth hourglass model. The result of this model is then passed through a mononet5 model which in turn does give us a holistic picture having 16 channels. This 16 channels is fully used for our tryon model.
Results
Video tryon comparison
We have compiled the results of directly inferencing on existing StyleFlow model with and without flow for a set of videos. Please find the results in the below link:
https://drive.google.com/drive/folders/1oW_ENuN1hZfwyLPnOnl-UloD4qgNPKVF?usp=sharing
Improving Tryon on non-plain backgrounds
We have used our trained person-segmentation model and segmented out the background and then used Flow-Style model to generated tryon and at the end we have stitched back the background. The results has much less artifacts than the one without background adjustment.
Original video

Result obtained by directly passing through StyleFlow model

Result after removing background

Result after removing background and adding it back after tryon

Depth model generated image comparison
We have masked the cloths from original videos and tried to regenerate the frames using our depth models. The inputs contains (masked_input_image, warped_cloth, depth) and output gives the warped cloth applied on the person in the image. We have ran tests on DenseTryon and CSPTryon models (as described above). Below are some of the results we have obtained:
Comparison of outputs of DenseTryon model at various epochs:

Here we can observe how the model is learning the cloth region in the input image. In the initial epochs, it is trying to locates the edges and then moves towards the center of the cloth. Depth information added will help to cut off the edges perfectly and thus reducing border artifacts.
Comparison of outputs of CSPTryon model at various epochs

Qualitative comparison of DenseTryon and CSPTryon models:


We can observe that CSPTryon model’s output looks much better than DenseTryon as underlying CSPNet is a better model as compared to DenseNet. Also, the model is able to perform well even on the side pose scenarios which are considered to be difficult for various virtual Tryon methods.
On a quantitative note, we use structural similarity index measure(SSIM) to compare the performance
of the models. We compare only between DenseTryOn and CSPTryOn. The reason being ResTryOn has given comparatively poorer results.
The SSIM graph is as follows:

The results is a combination of SSIM scores from 10 unseen videos containing a total of 80 frames each. We can clearly see CSPTryOn does give much better results. Hence, we can say that CSPTryOn can be the best option in case of available hardware resources. If not it is better to use DenseTryOn.
Frame Interpolation

Conclusions
We have started with naive approach of generating videos frame by frame from image tryon models. We have improved the quality of the videos by adding flow to our model and could see a slight improvement qualitatively and quantitatively. From this point we have taken an novel approach of applying depth using depth based models such DenseNet and CSPNet and have included the improved results. Depth provides lot of useful information to obtain the correct garment warping and hence globally improving the Tryon. This is the first work that uses depth based model for Video Virtual Tryon task.
We conclude by saying that we have seen significant improvement in the video quality from the baseline videos that are generated frame by frame considering the limited amount of resources available to us.
Code
References
[1] He, S., Song, Y.-Z., and Xiang, T. Style-based global appearance flow for virtual try-on, 2022.
[2] Kuppa, Gaurav, et al. “ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2021.
[3] Tzaban, R., Mokady, R., Gal, R., Bermano, A. H., and Cohen-Or, D. Stitch it in time: Gan-based facial editing of real videos, 2022. URL https://arxiv.org/abs/2201.08361.
[4] Alaluf, Y., Patashnik, O., Wu, Z., Zamir, A., Shechtman, E., Lischinski, D., and Cohen-Or, D. Third time’s the charm? image and video editing with stylegan3, 2022. URL https://arxiv.org/abs/2201.13433.
[5] Zhong, X., Wu, Z., Tan, T., Lin, G., and Wu, Q. MV-TON: Memory-based video virtual try-on network. In Proceed- ings of the 29th ACM International Conference on Multi- media. ACM, oct 2021. doi: 10.1145/3474085.3475269. URL https://doi.org/10.1145%2F3474085.3475269.
[6] Han, X., Wu, Z., Wu, Z., Yu, R., and Davis, L. S. Viton: An image-based virtual try-on network, 2017. URL https://arxiv.org/abs/1711.08447
[7] He, Kaiming, et al. “Identity mappings in deep residual networks.” European conference on computer vision. Springer, Cham, 2016.
[8] Iandola, Forrest, et al. “Densenet: Implementing efficient convnet descriptor pyramids.” arXiv preprint arXiv:1404.1869 (2014).
[9] Wang, Chien-Yao, et al. “CSPNet: A new backbone that can enhance learning capability of CNN.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2020.