Object Removal using combination of segmentation and image inpainting
The project mainly focuses on the problem of object removal using a combination of segmentation and image inpainting techniques. We plan to develop a system that automatically detects target objects to remove using weakly supervised language-driven semantic or instance segmentation models and remove the object to recover the background image with image inpainting techniques.
Key words
Object removal, language-driven semantic segmentation/instance segmentation, image inpainting
Introduction
Object removal techniques are widely used to remove unwanted objects. Nowadays, lots of Apps and picture tools can be found online to remove objects. Howevers, most of them are designed to let users select image regions to remove and replace them with corresponding backgrounds. For example, users need to manually draw a boundary or to select target regions, which is time-consuming. Our project aims at developing an algorithm to automatically detect the regions to remove using segmentation technique. We would explore image inpainting since it plays an important role in applications such as photo restoration, image editing, especially object removal.
We explore language-driven segmentation methods to detect the target objects. Existing semantic segmentation methods require human annotators to label each pixel to create training dataset which is labor intensive and costly, while the language-driven models ([1], [2]) label the image with only words or phrases describing specific objects and relationships between them to reduce the cost of annotation.
Inpainting projects nowadays require the whole mask generated by manually selecting the whole region by users, which is very labor-consuming and time-consuming. As shown in the figure 1, the user need to depict the whole area of the two people on the rightside to select the target region for inpainting. Assuming one minute for selecting the inpainting target region for one image, selecting target regions for thousands of image requires long hours and costs lots of labor. Besides, the depiction may be inaccurate, which may cause a drop on the inpainting accuracy.

*Fig 1. A demonstration of how the user usually selected the inpaiting regions
In order to solve these problem, we designed a system with segmentation as the earlier stage ahead the inpainting stage. The involvement of segmentation address these limitations by automatically generating masks as input to the inpainting stage. Instead of delecting the target region manually by users, the system automatically generates the mask of the region to reduce the cost and time and labor. In addition, we involve human-AI collaboration using this method: the input of the whole system is designed to be either a text of phase describing a specific object or a point of mask position, both of which given by the user.
Related Works
Segmentation
Early to 2015, [3] proposes U-Net for biomedical image segmentation and achieves a best performance at that time on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks. The U-Net consists of an encoder and a decoder with shortcut between same level layers. In 2016, SegNet[4] improves the decoder by using pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling, which eliminated the learning for upsample. Different from semantic segmentation mentioned above, instance segmentation can provide the mask in instance level. There are two general methods for instance segmentation: two-stage method and query-based method. Two-stage method [5], [6], [7], [8] first detects bounding boxes and then apply segmentation in each ROI region. Query-based method [9], [10], [11] represents the object to be segmented by queries and perform classification, detection and mask regression jointly.
Language referring image segmentation is segmenting object given a word or sentence. Most pipelines have two stages: (1) extracting features from language and image, (2) fusing two features. In 2016, [12] proposes the LSTM-CNN model: a combination of a recurrent LSTM used for encoding language input and a fully convolutional network to extract feature from image input. For the second stage feature fusion, [13] propose the first baseline based on the concatenation operation and more work such as [14], [15], give a better performance by introducing sentence structure and syntactic structures.
Inpainting
Traditional methods for image inpainting method, such as [16], propagate neighboring undamaged information to the holes based on diffusion. However, these methods are limited to extract low-level understandings, which may prevent them produce semantically reasonable contents. Deep learning methods achieves great success in image inpainting. [17], [18] are all variants of the U-Net structure. In addition, multiple new convolution algorithms are proposed for image inpainting, such as partial convolution [19] and gated convolution [20]. Recent work focuses on different aspect of image inpainting to improve the performance, such as high-resolution problem [21], [22] and large hole problem [23], [24].
Methodology
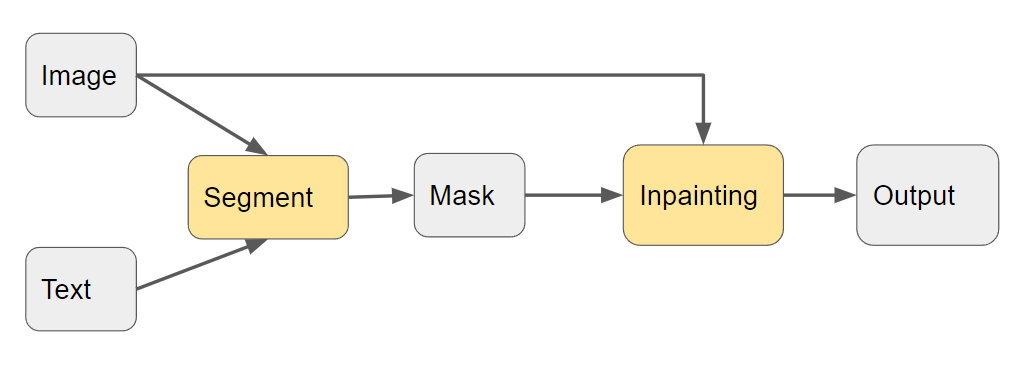
*Fig 2. Main process for the object removal task
As shown in figure 2, the proposed method can be formulated as follows: given an image Ix and a sentence or a phase describing an object, our model outputs a reconstructed image without the object Iy. There are two stages of our model: segmentation part and inpainting part. We plan to work on two stages separately and then combine them into one model. A visualization of the end-to-end design of the system is shown in figure 3. A pipeline of the designed system with details of how human-AI collaboration is involved is shown in figure 4.
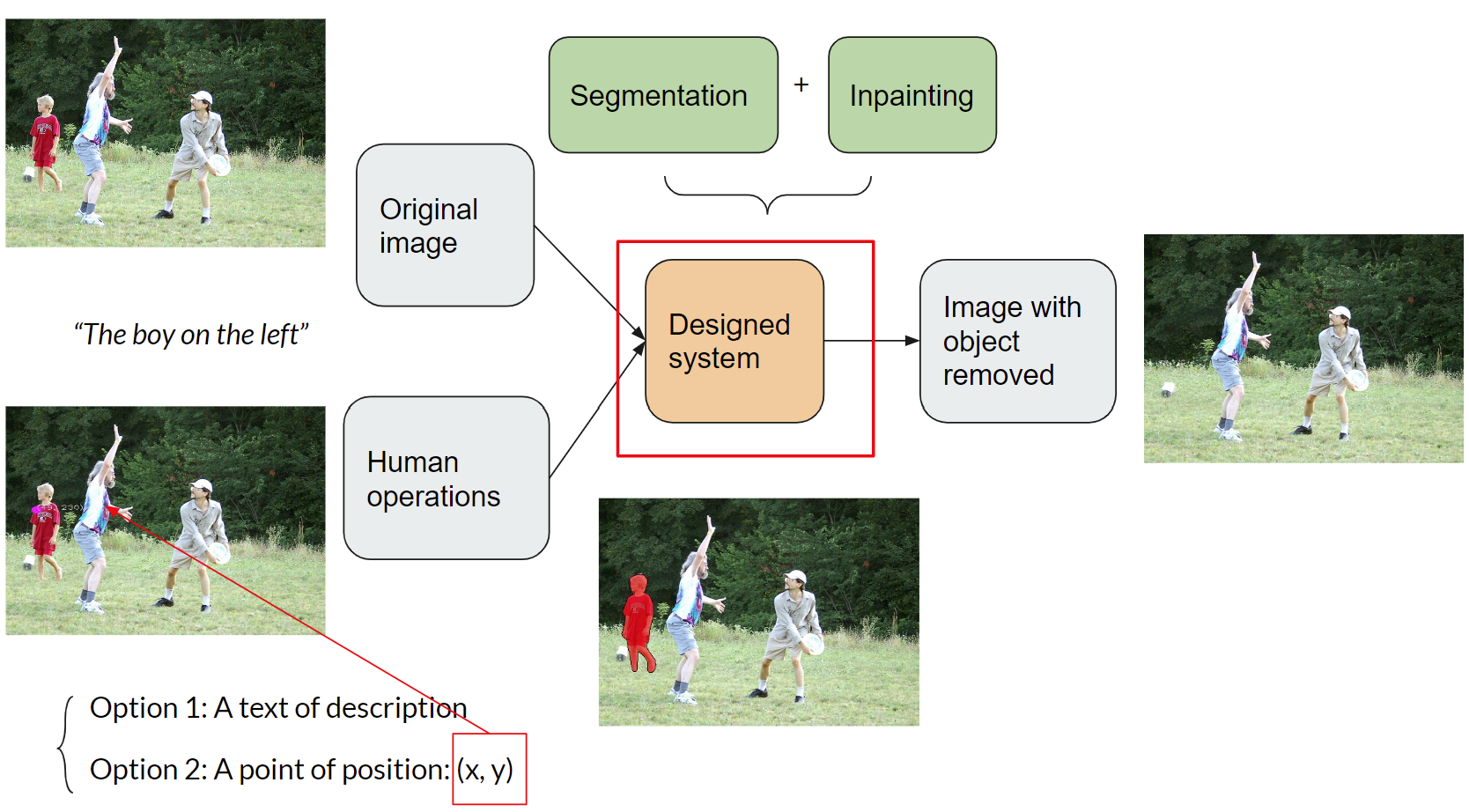
*Fig 3. A visualization of the end-to-end design of the system
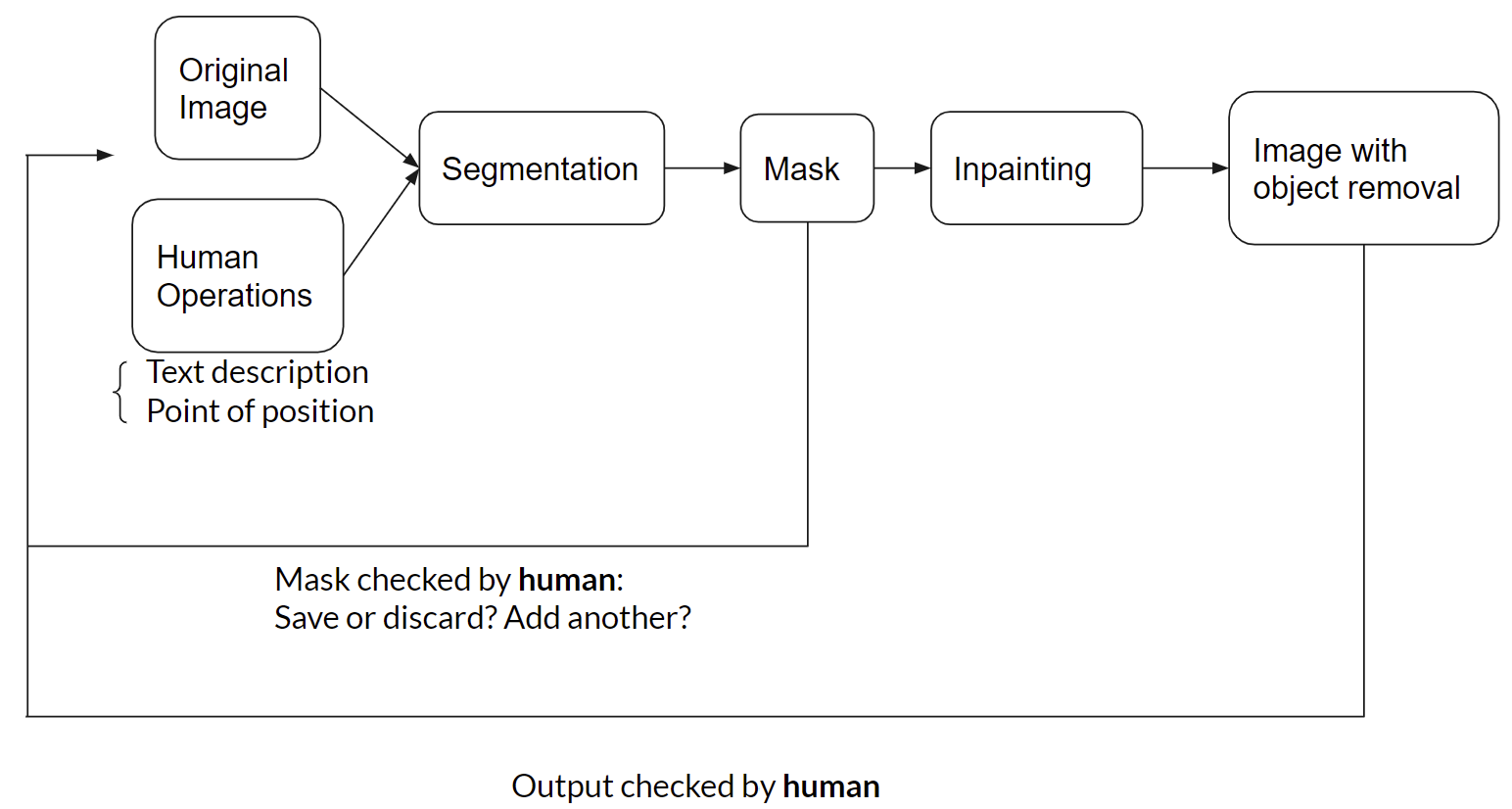
*Fig 4. Pipeline with details of how human-AI collaboration is involved
As shown in figure 3, the original image with human operations are input into the segmentation system. The user is given two options: the first option is to input a text of phrase or sentence presenting the concepts of entities, actions, attributes, positions, etc., organized by syntactic rules, e.g. “the boy on the left”; the second option is to click on the image to select a coordinate point within the pixel regions of one of the target objects. The segmentation model then take the text description or the given point as input and output a mask of an object corresponding to the input of the user. As shown in figure 4, after the segmented mask is obtained, in a feedback loop generated by the system, the user will be prompted to check the quality the mask and choose to save it if it is satisfied or discard it if not satisfied. After saving the mask, the user will then be prompted whether to add another mask or not. After all iterations within the loop, all the saved masks would then be input into the inpainting system. The inpainting model works by removing all the targets objects based on the saved masks. Finally, the resulting image with all the target objects removed would then be visually checked by the user again to decide whether to run the whole process again.
Segmentation
In this part, the original image Ix and the sentence s is fed into the text-based segmentation model. The output is a mask m, which is a binary image. We mainly take use of two segmentation models, LAVT [25] and Mask Transfiner [26]corresponding to the two user input options (a text description or a point of position) respectively.
LAVT model
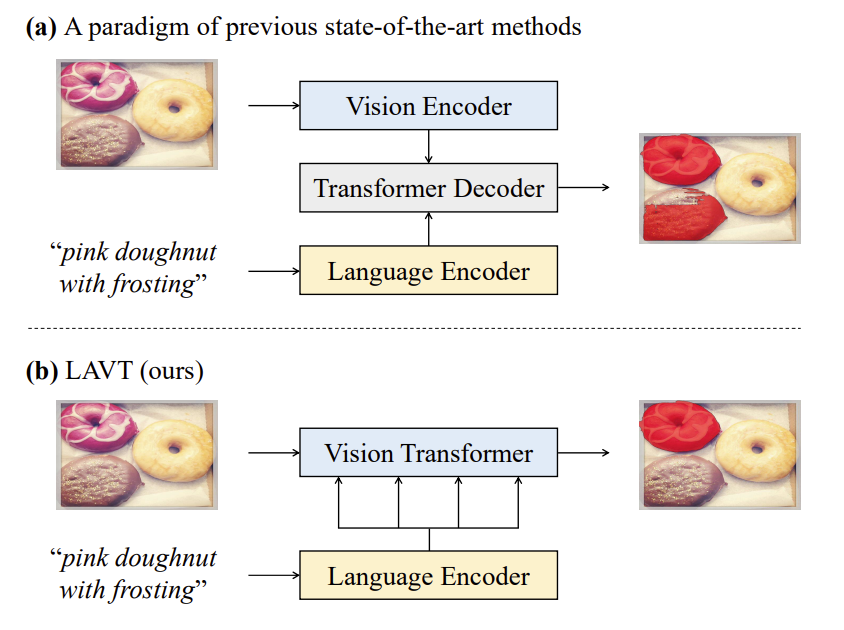
*Fig 5. A visualization of the overall working mechanism of LAVT [25]
Figure 5 shows the overall working machanism of the LAVT (Language-Aware Vision Transformer), which is a transformer based deep learning model for referring image segmentation. The input is a free-form text expression, including words, phrases or sentences using various concepts of entities, attributes etc. to describe the target object. The key point is to exploit visual features that are relevant to the given text conditions. A widely adopted paradigm is to extract independently visual features from a vision encoder and linguistic features from a language encoder fuse them together with a transformer decoder as shown in part (a). However, the paradigm fails to leverage the rich transformer layers in the encoder for excavating helpful multi-modal context. The LAVT model address this limitation by perform earlier fusion of vision and linguistic features in the intermediate layers of a Vision Transformer shown in part (b). In our project, we leverage the LAVT model for the first user option, i.e. let the user input a text description. As a result, the model is capable of generating a segmented mask corresponding the description.
Mask Transfiner model
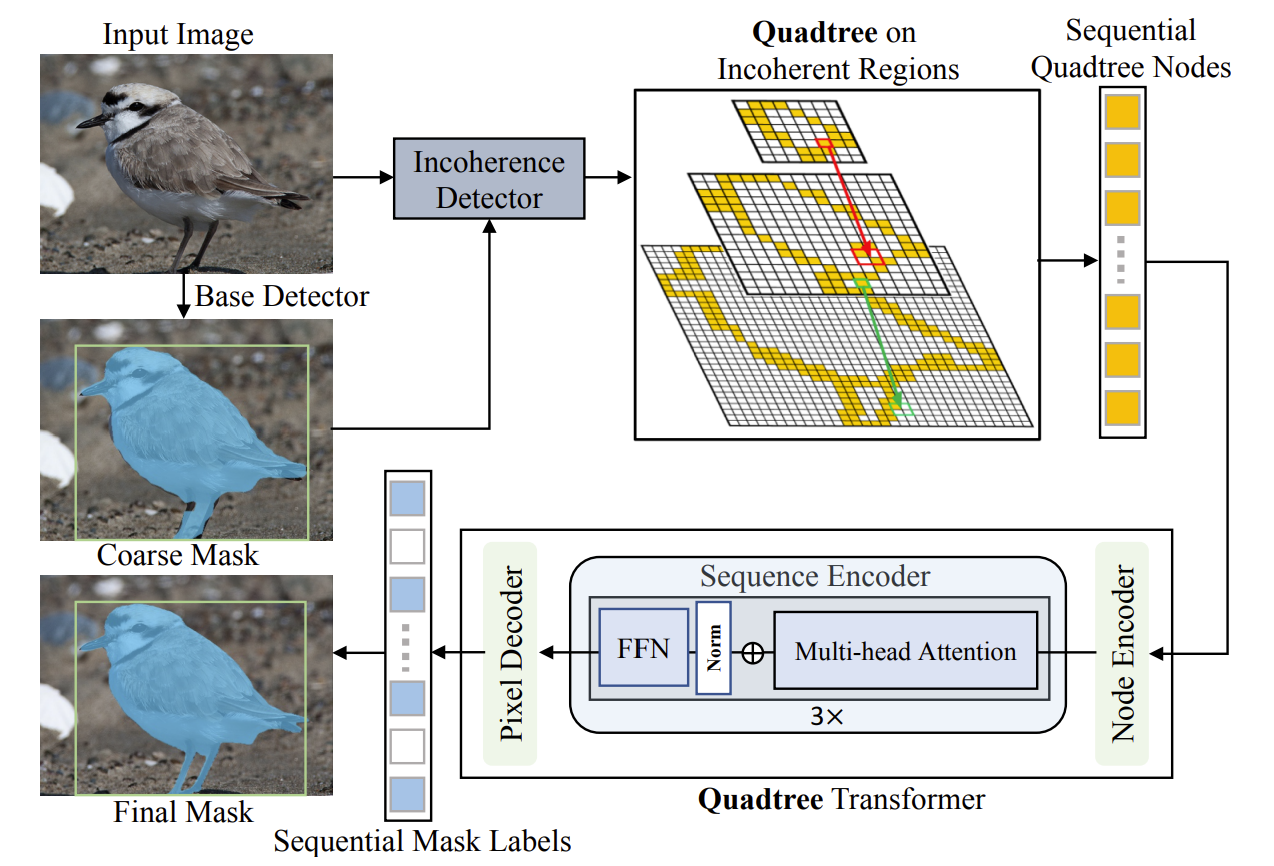
*Fig 6. A visualization of the overall working mechanism of Mask Transfiner for high-quality instance segmentation [26]
Figure 6 shows the overall working machanism of the Mask Transfiner for high-quality instance segmentation. The traditional segmentation methods tend to generate relative coarse segmented masks. Besides, there exists a signigicant gap between the detected bounding box and segmented mask performances of the recent state-of-the-art methods. The Mask Transfiner model is proposed to address these issues. As shown in figure 6, this approach firstly identifies error-prone regions. These regions represented by a coarse mask mostly correspond to the object boundaries or regions with high frequency. Then a base detector is used to detect incoherent regions between the original image and the coarse mask. The incoherent regions are defined by the loss of information due to downsampling the coarse mask. Although the incoherent pixels only consists of a small portion of the total pixels, the they are shown to be crucial to the segmentation performance. The system then builds a quadtree on the incoherent regions on the RoI pyramid then jointly refines all tree nodes using the refinement transformer with quadtree attention. In our project, this model plays a role of segmentation with the clicked point on the image as input. The main algorithm for obtaining the segmented mask covering the user clicking point is to iterate all the segmented masks, then for each mask detect whether the point is within the pixel regions of the mask. For the mask which the point is inside, we output the mask in visualization.
Inpainting
After obtaining the mask of the object in sentence s, the inpainting model can output Iy from input image Ix and mask m. We plan to use the model LaMa[28] to do image inpainting. To improve the performance, we will try to give the more information by inputting the sentence s.
LaMa model
LAMA[27], is an inpainting model designed for large mask. LAMA takes the advantage of fast Fourier convolutions (FFCs)[28]. FFC does convolution in frequency domain, and thereby it has a reception field of the whole image even in early stage. This leads to a both perceptual quality and training efficiency gain. [27] also proposes a new perceptual loss based on a semantic segmentation with high receptive filed, promoting the consistency of global structures and shapes. They also propose an aggressive large mask generation strategy (large masks wide or large masks box in figure 7), which benefits the inpainting system.

*Fig 7. Large masks wide or large masks box generated by LaMa
The pipeline of LAMA is shown in figure 8. LaMa has a ResNet-like architecture with 3 downsampling blocks, 9 residual blocks, and 3 upsampling blocks. The residual block consists of two FFC module and a shortcut. The FFC module block has two paths: local path and global path. In global path, real FTT2d and inverse real FFT2d are applied, so the global information is extracted because of the large reception filed of Fourier Transform in spatial domain. Finally, the outputs from two paths are concatenated to be the output of the FFC module.
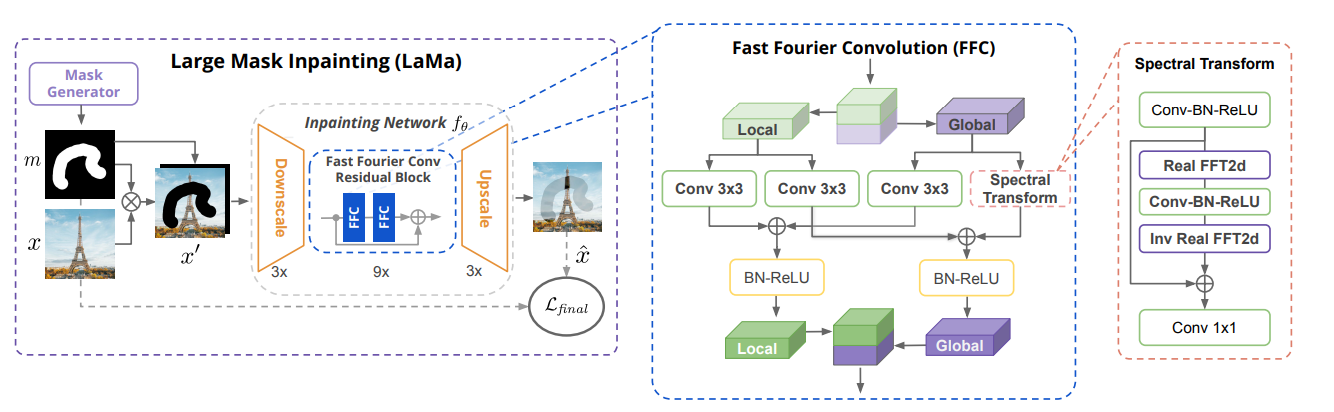
*Fig 8. The pipeline of LaMa [27]
In loss design, LAMA gets rid of conventional pixel-wise MAE or MSE loss, which may lead to averaged blurred image, but uses a high receptive field perceptual loss. The high receptive field perceptual loss is similar to conventional perceptual loss, but is based on a large receptive field model, which is implemented using Fourier or Dilated convolutions, to extract feature. Adversarial loss is also used, but on a local patch-level. The ‘real’ is defined as the known parts of the image and the ‘fake’ is defined as the output patch that intersects with the mask area. The final loss also takes the advantage of feature matching loss [29] to stabilize training and a gradient penalty loss to smooth output image.
MAT model
MAT[30], is a transformer-based inpainting system for high-resolution images. Transformer can model long range dependency benefiting from attention mechanism with a dynamic mask. [30] also proposes a modified transformer block to make training large masks more stable and a style manipulation module to have diverse outputs.
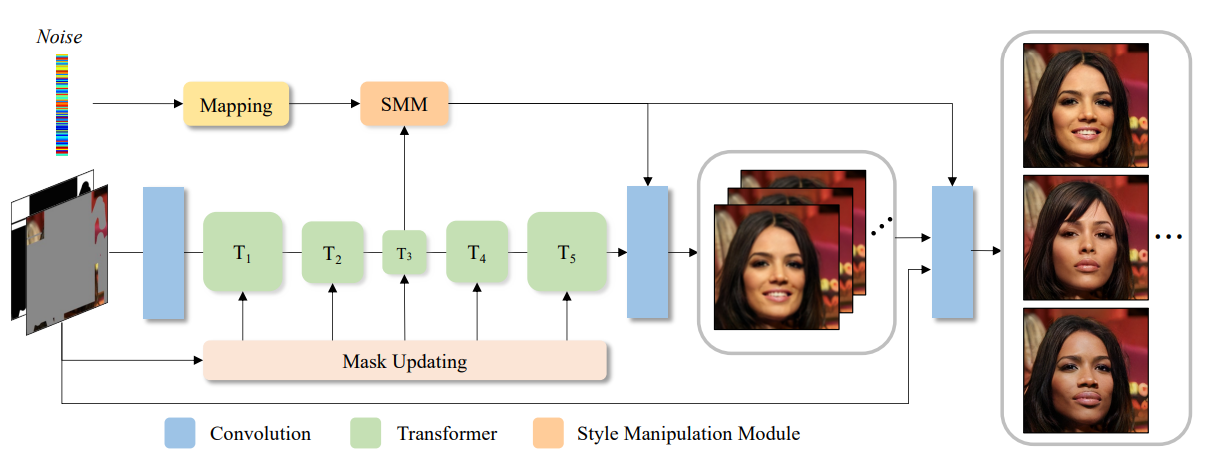
*Fig 9. The pipeline of MAT [30]
Expected output
We expect our model can be end-to-end and can produce both structural and textural images. We hope to achieve SOTA performance in both segmentation and inpainting tasks. Additionally, we want to figure out image inpainting performance with different mask size as text-aided inpainting is good at large masks while traditional inpainting model performs better at small masks. We also want to find the influence on inpainting model performance with soft mask and hard mask.
Results
Demonstration video
A demonstration of our project is shown as below:

*Video 1: Overall demo of the project
The demonstration is written in jupyter notebook, and some helper functions are defined firstly. At start of the main junction, we can select which kind of operation to generate the mask. There are two options in our project: click the pixel in the raw image or type in the object that the user wants to remove. After selecting the option, we can get the corresponding mask, which will be shown in red. Then the user can choose whether to save or discard the mask. After process the current mask, we can choose to add one more mask or go to inpainting. If we want to add more mask, we will go back to choose the way to generate mask iteratively. Finally, we can get two output images without the object in mask from two inpainting models.
Qualitative results
Some inpainting results by user click are shown in figure 10.


*Fig 10. Some visualization results of segmentation and inpainting
The user click is shown as a purple point in the second columns images. Our segmentation model works well and the generated mask fits the object accurately. The output image is smooth, natural, structural and textural. To show the effectiveness of removing different objects in one image, we tested inpainting dog and hydrant separately in image 5 and we can find eighter dog or hydrant is removed in the output image.


*Fig 11. Some visualization results of segmentation and inpainting
Similarly, we test the same images with sentence input, which are shown in the second column. The language-aware vision transformer produces accurate and relevant masks. The output image is smooth, natural, structural and textural. In image 5, we provide two object sentences ‘the hydrant’ and ‘the dog’, the output removes hydrant or dog, showing the effectiveness of our model.
Discussion
Model comparison
We use two models for segmentation: one for click model and one for language model. Generally speaking, click model achieves a better performance compared with language model because it is not as accurate as mouse click to describe an object in an image. However, it is also possible that the click model may consider some back objects as background, so language model will help when this happens. Hence, two user options can promote each other to achieve a better segmentation performance.
We also use two inpainting models: LAMA and MAT, both of them achieve good performance. However, when it comes to large masks, MAT will create a more structural patch based on the surrounding pixels and training data whereas LAMA will produce a much smoother result. There is no hard criteria to evaluate these two features because sometimes the structural patch seems more reasonable in some images.
Bad cases
During experiments, we find some failure cases. Sometimes the segmentation model for click input works while the model for language input doesn’t work, especially when the object is hard to describe in language. For example. In case 1, the car in front of the left bottom car is difficult to describe in language. Hence, the segmentation result is not accurate for the language input.

*Fig 12. Bad case 1: The left image is from click model and the right image is from language model with input ‘the middle car’.
It is also possible that the click model view the object as background. In case two, the click model considers the trees behind the motor bike as background. So there is no mask generated for the tree while it is generated by language model. This also shows by giving language input to model helps the model to find object mask.

*Fig 13. Bad case 2: The left image is from click model and the right image is from language model with input ‘the right trees’.
Even when the segmenatiton model performs well, the inpainting model may not produce good result. For example in case 3, there is shadow under the car. This shadow results in a grey area or aritifacts in output images. This is reasonable because the inpainting model generate images based on the neighbor pixels of the mask.

*Fig 13. Bad case 3: Negative inpainting results affected by shadow of the object
Reference
[1] Li, B., Weinberger, K.Q., Belongie, S.J., Koltun, V., & Ranftl, R. (2022). Language-driven Semantic Segmentation. ArXiv, abs/2201.03546.
[2] Wu, C., Lin, Z., Cohen, S.D., Bui, T., & Maji, S. (2020). PhraseCut: Language-Based Image Segmentation in the Wild. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10213-10222.
[3] Ronneberger, O., Fischer, P. and Brox, T., 2015, October. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention (pp. 234-241). Springer, Cham.
[4] Badrinarayanan, V., Kendall, A. and Cipolla, R., 2017. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE transactions on pattern analysis and machine intelligence, 39(12), pp.2481-2495.
[5] Yi Li, Haozhi Qi, Jifeng Dai, Xiangyang Ji, and Yichen Wei. Fully convolutional instance-aware semantic segmentation. In CVPR, 2017
[6] Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In CVPR, 2018
[7] Justin Liang, Namdar Homayounfar, Wei-Chiu Ma, Yuwen Xiong, Rui Hu, and Raquel Urtasun. Polytransform: Deep polygon transformer for instance segmentation. In CVPR, 2020
[8] Lei Ke, Xia Li, Martin Danelljan, Yu-Wing Tai, Chi-Keung Tang, and Fisher Yu. Prototypical cross-attention networks for multiple object tracking and segmentation. In NeurIPS, 2021
[9] Bin Dong, Fangao Zeng, Tiancai Wang, Xiangyu Zhang, and Yichen Wei. Solq: Segmenting objects by learning queries. In NeurIPS, 2021.
[10] Yuxin Fang, Shusheng Yang, Xinggang Wang, Yu Li, Chen Fang, Ying Shan, Bin Feng, and Wenyu Liu. Instances as queries. In ICCV, 2021.
[11] Yuqing Wang, Zhaoliang Xu, Xinlong Wang, Chunhua Shen, Baoshan Cheng, Hao Shen, and Huaxia Xia. End-to-end video instance segmentation with transformers. In CVPR, 2021.
[12] Hu, Ronghang, Marcus Rohrbach, and Trevor Darrell. “Segmentation from natural language expressions.” In European Conference on Computer Vision, pp. 108-124. Springer, Cham, 2016.
[13] Ronghang Hu, Marcus Rohrbach, and Trevor Darrell. Segmentation from natural language expressions. In ECCV, 2016.
[14] Shaofei Huang, Tianrui Hui, Si Liu, Guanbin Li, Yunchao Wei, Jizhong Han, Luoqi Liu, and Bo Li. Referring image segmentation via cross-modal progressive comprehension. In CVPR, 2020.
[15] Tianrui Hui, Si Liu, Shaofei Huang, Guanbin Li, Sansi Yu, Faxi Zhang, and Jizhong Han. Linguistic structure guided context modeling for referring image segmentation. In ECCV, 2020.
[16] Coloma Ballester, Marcelo Bertalmio, Vicent Caselles, Guillermo Sapiro, and Joan Verdera. Filling-in by joint interpolation of vector fields and gray levels. TIP, 10(8):1200– 1211, 2001.
[17] Hongyu Liu, Bin Jiang, Yibing Song, Wei Huang, and Chao Yang. Rethinking image inpainting via a mutual encoderdecoder with feature equalizations. In ECCV, pages 725– 741. Springer, 2020.
[18] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia. Image inpainting via generative multi-column convolutional neural networks. NIPS, 2018.
[19] Guilin Liu, Fitsum A Reda, Kevin J Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. Image inpainting for irregular holes using partial convolutions. In ECCV, pages 85–100, 2018.
[20] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang. Free-form image inpainting with gated convolution. In ICCV, pages 4471–4480, 2019.
[21] Yu Zeng, Zhe Lin, Jimei Yang, Jianming Zhang, Eli Shechtman, and Huchuan Lu. High-resolution image inpainting with iterative confidence feedback and guided upsampling. In ECCV, pages 1–17. Springer, 2020.
[22] Haoran Zhang, Zhenzhen Hu, Changzhi Luo, Wangmeng Zuo, and Meng Wang. Semantic image inpainting with progressive generative networks. In ACMMM, pages 1939– 1947, 2018.
[23] Shengyu Zhao, Jonathan Cui, Yilun Sheng, Yue Dong, Xiao Liang, I Eric, Chao Chang, and Yan Xu. Large scale image completion via co-modulated generative adversarial networks. In ICLR, 2020.
[24] Chuanxia Zheng, Tat-Jen Cham, and Jianfei Cai. Tfill: Image completion via a transformer-based architecture. arXiv preprint arXiv:2104.00845, 2021.
[25] Yang, Zhao & Wang, Jiaqi & Tang, Yansong & Chen, Kai & Zhao, Hengshuang & Torr, Philip. (2021). LAVT: Language-Aware Vision Transformer for Referring Image Segmentation.
[26] Ke, L., Danelljan, M., Li, X., Tai, Y., Tang, C., & Yu, F. (2021). Mask Transfiner for High-Quality Instance Segmentation. ArXiv, abs/2111.13673.
[27] Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, Victor Lempitsky: “Resolution-robust Large Mask Inpainting with Fourier Convolutions”, 2021; arXiv:2109.07161.
[28] Lu Chi, Borui Jiang, and Yadong Mu. Fast fourier convolution. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 4479–4488. Curran Associates, Inc., 2020.
[29] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018.
[30] Wenbo Li, Zhe Lin, Kun Zhou, Lu Qi, Yi Wang, Jiaya Jia: “MAT: Mask-Aware Transformer for Large Hole Image Inpainting”, 2022; arXiv:2203.15270.