Back-N-Forth (BNF): A Self-diagnosing Mechanism for Human-Collaborating ML Systems
For interactive ML systems, we’d expect a reliable, controllable model to:
- “To admit that you know what you know, and admit what you don’t know” - as in Confucianism philosophy.
- Instead of silently producing low-confidence results, try to report the confusion and seek further help from human collaborators
- Use additional human-machine interactions to improve the overall experience from the user’s perspective (including, but maybe not limited to model performance)
In this project, we want to study the design of a special module, that can be injected into any interactive machine learning systems for us to achieve these targets.
Eaxmples and Intuition
The generation of captchas include a lot of geometric distortion, noising and rescaling, of which some could make the resulting captchas extremely hard to recognize.
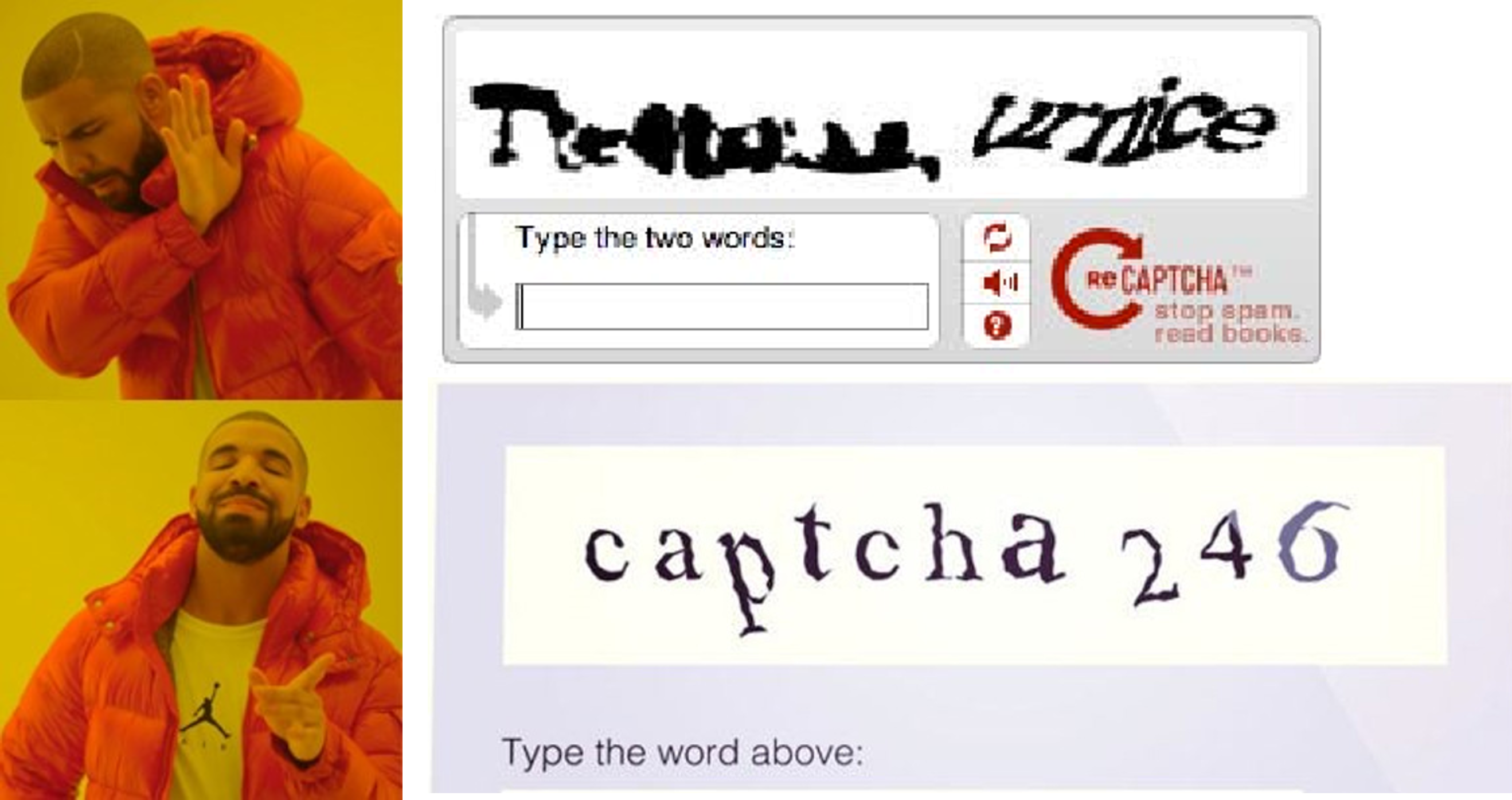
In this case we humans ususally choose to refresh the captcha to get an easier case, instead of racking our brains to predict an unlikely one.
There are also other cases, like recommended replacements as in usages cases like search engines.
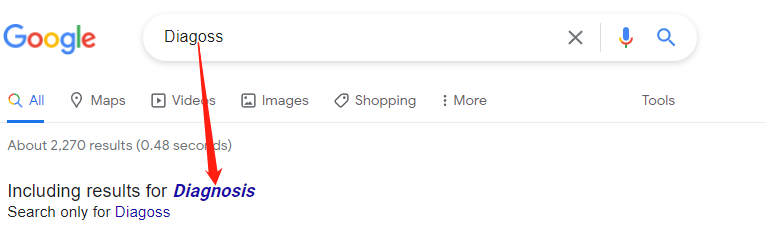
When working with machine learning systems, the existence of such models can be used for diagnosing/correcting the behaviors of our models. For example, in a writing helper system, with BPE (WordPiece) Tokenizers, traditional out-of-vocabulary methods may cease to work.

Although the model can actually not understand the problematic input, since there’s no diagnosis module, it will never the less try to generate contents and produces either completely irrelevant contents, or simply copies the problematic clip here and there, pretending it’s a name for some entities etc.
There are also another class of cases (for computer vision tasks mostly), where a small noise value added to image pixels can actually break the computer vision models and mislead it to generate high-confidence incorrect labels.
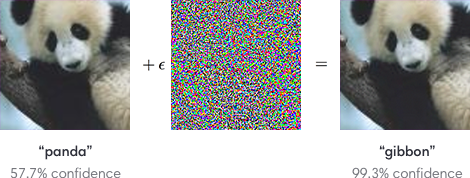
We argue all of these can be resolved in a unified fashion, by introducing a module we call it Back-N-Forth. Back-N-Forth addresses the problem by analyzing the mutual information to decide whether the layer-wise information compression is successful. For first steps, we will try to study the effectiveness on three scenarios:
- Irregular input rejection and correction in image manipulators.
- Out-of-vocabulary and other grammatical typos detection in interactive storytelling systems.
- Adversarial attack diagosis and defense.
Methodology
Formulation
Given input \(X = [x_0, x_1, ..., x_D]\) and target output \(Y = [y_0, y_1, ..., y_M]\) (\(x_i\), \(y_j\) are the individual random variables of the input/output variable groups):
Assuming the injected model is defined as a series of transformations from the input to the output:
\[O_1 = f_1(X) = F_1(X)\] \[O_2 = f_2(O_1); O_2 = F_2(X) = f_2(f_1(X))\] \[O_3 = f_3(O_2); O_3 = F_3(X) = f_3(f_2(f_1(X)))\] \[......\] \[O_N = f_N(O_{N-1}); O_3 = F_N(X) = f_N(f_{N-1}(...f_1(X)...))\]where \(f_i\) indicates the projection by each layer, \(F_i\) indicates the accumulative projection by the first \(i\) layers and \(O_i\) is the intermediate output of \(i\)-th layer.
Given the diagnosed level \(i\), we train an explicit density model (like VAEs / language models) to learn the probabilistic inverse function \(P^{-i}(X\vert F_i(X))\) of the first \(i\) layer for the injected model, such that for the domain \(\mathbf{D}\) where the original model is obtained:
\[\text{argmax}_\theta \mathbb{E}_{X\sim \mathbf{D}}[\log P_\theta^{-i}(X\vert F_i(X))]\]Specially, \(P_\phi^{0}(X\vert F_0(X)) = P_\phi^{0}(X)\) is also trained to obtain the unconditional probability density/mass measure for the input domain.
Ideally, if some input is well understand, the model should be able to generate a representation that compress and preserve its information in the maximum level. Thus, the learned probabilistic model should be significantly more likely to recover the input from the intermediate output \(F_i(X)\). In other words, if such probabilistic reconstruction fails, then either the tranformation compressed too much information in the input, or the transformation produces a representation that shifted far way from the input domain.
Thus, by combining \(P_\theta^{-i}(X\vert F_i(X))\) and \(P_\phi^{0}(X)\), we can obtain the information tranformed rate factor (ITR) \(\eta\) for the input random variables \(X=[x_0, x_1, ..., x_D]\). We can caculate \(\eta^{-i}(X) = \log P_\theta^{-i}(X\vert F_i(X)) - \log P_\phi^{0}(X)\). The baseline \(P_\phi^{0}(X)\) is serving as the baseline to distinguish the concept of being incorrect or rare.
The ITR factor \(\eta\) can be used in three levels:
-
Use \(\eta^{-i}(X)\) as a metric to accept/reject in-domain/out-of-domain inputs.
-
For cases where the inverse function is obtained from a factorizable tractable density model, \(\eta\) then could also be factorized as \(\eta^{-i}(X) = [\eta^{-i}(x_0), \eta^{-i}(x_1), ..., \eta^{-i}(x_D)]\). This will help us to locate part of our input that cased the most confusion.
-
For cases where the inverse function can only give likelihood estimation but the domain is on Riemann manifold i.e. gradients are available, backpropogating \(\eta^{-i}(X)\) to \(X\) could be helpful for auto-denoising the adversarial inputs and defend the adversarial attacks.
Experimental Setup
Human-in-the-loop Correction of OOV in Human-AI Collaborating Writing System
We inject our module to some previously published human-in-the-loop storytelling systems like Plan-And-Write. The experiments consist of two parts.
- Evaluate whether the module can detect the out-of-vocabulary and/or grammatical typos, by passing some mistakenly-altered-on-purpose samples to the module and see if those mistakes are well recognized.
- Launch the system w/-w/o BNF, collect human feedbacks and compare with each other.
Dataset Selection and Creation
We evaluate our model on a long story generation dataset Reddit Scary story.
We construct the corrupted data from the story titles in two aspects:
- wrong spelled words, and
- easily confused words.
Specifically, we first crawled 4,000 <story, title> pairs from reddit. For the first type of corruption, we only misspell nouns and adjectives, as these two groups contribute most to the semantic meaning. We also filter out nouns/adjectives that are shorter than 5 characters so that reconstruction from spelling is more feasible. Table 1 lists several examples for Spelling Corruptions.
| Original Title | Corrupted |
|---|---|
| The Vampire Hooker | The Vampire Hookeeer |
| Through the window | Through the wwwindow |
| Why Won’t You Stay Dead? | Why Won’t You Stay Dad? |
As for the second type, we hypothesize that easily confused words either sound similar (and are thus spelled similarly). Such characteristics align with a form of word play called puns, which exploits multiple meanings of a term, or of similar-sounding words (e.g., hear and here), for an intended humorous or rhetorical effect. To this end, we propose to extract pun word pairs from the Semeval 2017 Homophonic Pun dataset [10]. We then pollute the original correct story titles by replacing them with their similar-sounding words. Table 2 lists several examples for Confusion Corruptions.
| Original Title | Corrupted |
|---|---|
| Can you hear me? | Can you here me? |
| Just taking a break | Just taking a brake |
| First a blackout then an earthquake | First a blackout than an earthquake |
Model Setup
We finetine the backbone story generation model from a pretrained GPT-2 checkpoint in the Plan-And-Write paradigm. Specifically, we first extract keywords from the sentences in the stories and connect them as a storyline. Then we train a model to model the sequence distribution of the following prompt:
$ <Title> # <Storyline> # <Story, "\n" separated> </s>
The resulting model will be capable of doing three things:
- Calculating the unconditional step-wise probability of any given title
- Given a title, generate a storyline/evaluate the likelihood of a given storyline
- Given a title and a storyline, generate the corresponding story.
In addition, we also train a probabilistic inverse of the model to actually perform the proposed Back-N-Forth algorithm. Specifically, the inverse module is trained to model the distribution of the following prompts:
$ <Storyline> # <Title> </s>
Quantitative Evaluation
As part of the quantitative evaluation, we evaluate the BNF framework as an unsupervised corrupted sequence classifier. Specifically, for each <original/corrupted> title pair \(\mathbf{s} / \mathbf{s}^{\sim}\) in the two scenarios, we calculate \(\eta^{-i}(\mathbf{s})\) and \(\eta^{-i}(\mathbf{s}^{\sim})\). We call a pair of corrupted sequence is separated, if \(\eta^{-i}(\mathbf{s}) - \eta^{-i}(\mathbf{s}^{\sim}) \geq \Delta\), where \(\Delta\) is a hyperparameter that controls the sensitivity of the decision-making boundary marginalization.
Since we are using an auto-regressive model/formulation for the likelihood function, we can further split the likelihood into step-wise likelihood atoms. By applying different reduction strategies, we can get multiple variants of BNF which could potentially have very different performances. To provide a larger range of comparison, we also present the result of a simpler BNF baseline, which is implemented not in the paradigm of Plan-And-Write but vanilla sequence-to-sequence. Here, the probabilistic inverse of the model takes in the generated full story as the condition instead of the storyline (since there’s no storyline), modeling the following prompts:
$ <Story, "\n" separated> # <Title> </s>
The results are shown in the following Table 3:
| Model/Reduction | Spelling Corruption Acc. | Confusion Corruption Acc. |
|---|---|---|
| \(\eta^{-i}(\mathbf{s})=\inf_t\{\eta^{-i}_t(\mathbf{s})\}\) | 706 / 800 | 260 / 391 |
| \(\eta^{-i}(\mathbf{s})=\sup_t\{\eta^{-i}_t(\mathbf{s})\}\) | 541/800 | 201 / 391 |
| \(\eta^{-i}(\mathbf{s})=\mathbb{E}_t[\eta^{-i}_t(\mathbf{s})]\) | 647 / 800 | 240 / 391 |
| \(\eta^{-i}(\mathbf{s})=\sum_t\eta^{-i}_t(\mathbf{s})\) | 641 / 800 | 241 / 391 |
| Seq2seq | 495 / 800 | 200 / 391 |
Inspecting the failure cases
We are curious about how the sequence to sequence model falls short so drastically compared to the best Plan-And-Write based model variant. We find the following example very expressive to show that, the copy mechanism in powerful models like transformers actually hinders the effective learning of \(\eta^{-i}(\mathbf{s})\):
| Attributes | Value | Description |
|---|---|---|
| title | The littllle things | Typo for “The little things” |
| Seq2seq Generation | Jimmy once met Laura. He told her about the littllle things. The littllle things are so annoying. He chased that thing. The littllle things disappeared. | littllle is copied here and there as if it were a name of something. |
Qualitative Evaluation
In addition, we also pack the model into an interactive demo to conduct human evaluation. The demo is designed as follows:
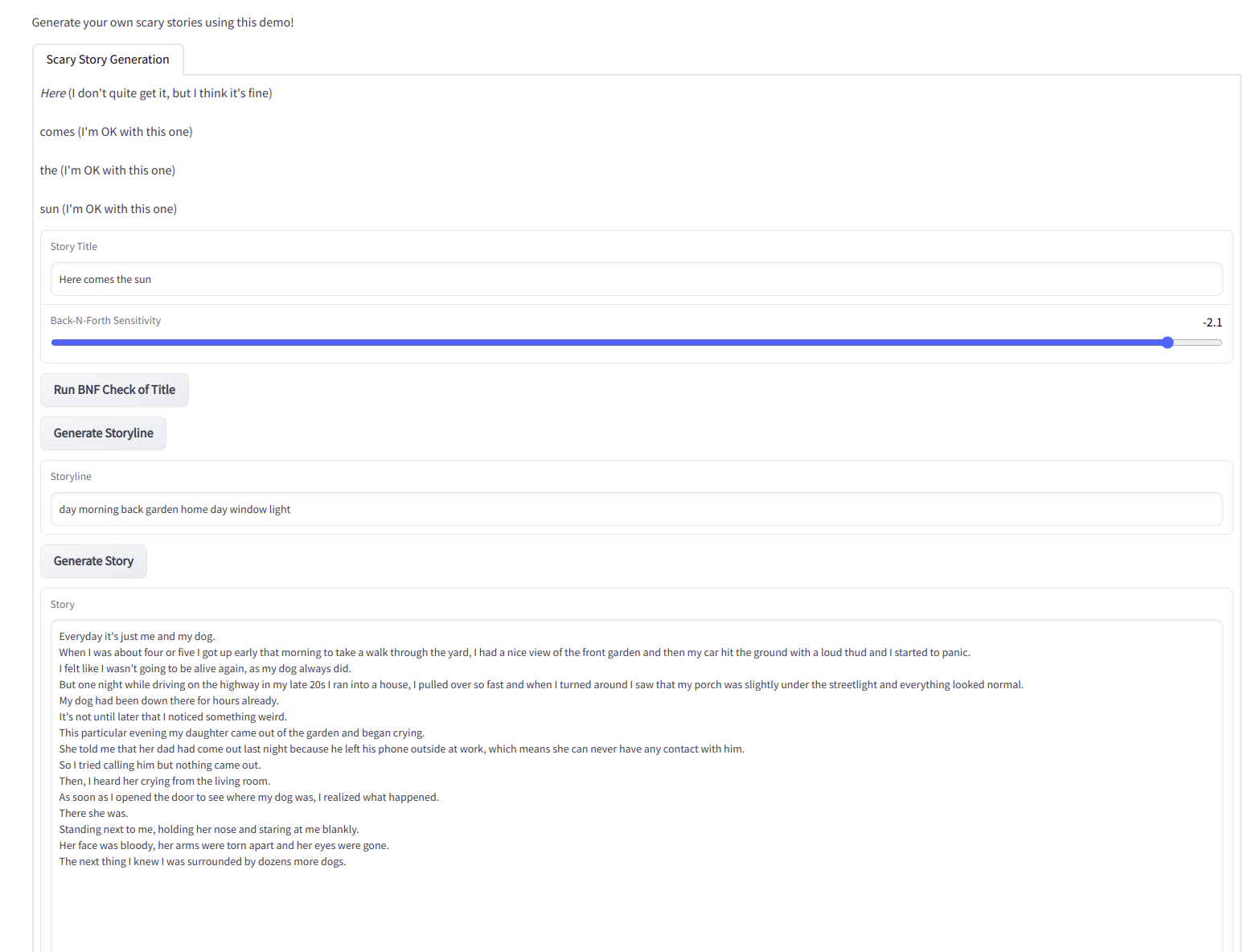
We present the evaluators two version of the demo: with or without the injected BNF module. The user is asked to freely type in the title. Then in the version witht the BNF module, they can use BNF to check whether the model understands well of the input title. After which, The user will be able to collaborate with the machine to cope with the storyline/story generation process in a fully interactive fashion.
We planned to collect enough feedback from the user. Unfortunately, due to the limited throughput of our backend server, we are unable to present any results with sufficient statistical confidences. We plan to keep this as a scheduled future work when a more stable source of computation power (in addition, they should be safely exposable to the public internet) should be available to us.
Model Playground and Code Release
Most implementation can be found in this repo.
Irregular input rejection in image classifiers
We worked on injecting BNF to some classical image classifiers on domain-shifted cases. We attempted to explore whether the method is able to close the domain shift of one dataset (Caltech-101, cars) over another (ImageNet cars) by gradient ascending along the \(\eta^{-i}(X)\) manifold. We failed to get any reasonable results, unfortunately. For visualization and our attempts’ records, please refer to our code base.
Reference
[1] You C, Robinson D P, Vidal R. Provable self-representation based outlier detection in a union of subspaces, Proceedings of the ieee conference on computer vision and pattern recognition, 2017
[2] Chen Z, Yeo C K, Lee B S, et al. Evolutionary multi-objective optimization based ensemble autoencoders for image outlier detection. Neurocomputing, 2018
[3] Sabokrou M, Pourreza M, Fayyaz M, et al. Avid: Adversarial visual irregularity detection. Asian Conference on Computer Vision, 2018
[4] Yao L, Peng N, et al. Plan-and-write: Towards better automatic storytelling. Proceedings of the AAAI Conference on Artificial Intelligence, 2019
[5] Nayak A, Timmapathini H, et al. Domain adaptation challenges of BERT in tokenization and sub-word representations of Out-of-Vocabulary words, Proceedings of the First Workshop on Insights from Negative Results in NLP. 2020
[6] Bazzi I. Modelling out-of-vocabulary words for robust speech recognition. Massachusetts Institute of Technology, 2002.
[7] Baehrens D, Schroeter T, et al. How to explain individual classification decisions. The Journal of Machine Learning Research, 2010
[8] Hsieh C Y, Yeh C K, et al. Evaluations and methods for explanation through robustness analysis. International Conference on Learning Representations, 2020.
[9] Sundararajan M, Taly A, Yan Q. Axiomatic attribution for deep networks. International conference on machine learning, 2017:
[10] SemEval-2017 Task 7: Detection and Interpretation of English Puns Tristan Miller, Christian Hempelmann, Iryna Gurevych