Module 6: Weak supervision and self supervision - Semantic Segmentation with Scribbles
In this survey report we will be exploring the advances in semantic segmentation with scribbles. We will be focusing on three major papers in this area including the first major investigation on this topic as well as two more recent papers which represent the current developments in this area.
Introduction
In recent years, fully-supervised Convolutional Neural Networks (CNN) have become state-of-the-art for semantic segmentation. However, these models require pixel-wise annotation which is expensive and time consuming to acquire. Thus, prior work has explored using weak annotations, defined as noisier, lower-quality annotations [1]. For semantic segmentation, researchers have explored using image tags, bounding boxes, points, and scribbles [2]. Image tags and bounding boxes are an example of coarse labels: labels that lack precise pixel localization. Points and scribbles are an example of sparse labels: labels that lack broad region coverage. In this survey, I will be focusing on using sparse labels, scribbles.
Literature Review
As was mentioned, the fundamental issue with scribbles is the sparse annotation: the vast majority of image pixels are unannotated. Thus the major issue is how to propogate the scribbles’ labels to the rest of the image.
ScribbleSup
The first major paper to use scribbles for semenatic segmentation was “ScribbleSup: Scribble-supervised convolutional networks for semantic segmentation” [3]. In their paper, they generate an oversegmentation using [4]. They then assign labels to the segments based on the minimization of the following objective function
\[\sum_{i}\psi_i(y_i|X,S) + \sum_{i,i}\psi_{i,j}(y_i,y_j|X,S)\]where \(\psi_i = \psi^{scribble}+\psi^{net}\), \(X\) is the set of segments, \(S\) is the set of scribbles and scribble category labels, and the set of \(y_i\) are the label assignments for segment \(i\).
If the scribbles intersect with the segment, \(\psi^{scribble}\) is \(0\); otherwise each label has an equal positive value. \(\psi^{net}\) represents the deep learning network probability for the label. For segments with the different labels, the value of \(\psi_{i,j}\) increases depending on how close the segments are in appearance (measured in terms of color and texture). This results in the following objective
\[\sum_{i}\psi_i^{scribble}(y_i|X,S) + \sum_{i,i}-logP(y_i|\Theta,X)+ \sum_{i,i}\psi_{i,j}(y_i,y_j|X,S)\]where \(\Theta\) are the network parameters. This results in two sets of variables to be optimized: \(Y\) for the label segments and \(\Theta\) for the deep learning network’s parameters. In the paper, the researchers propose an alternative optimization framework, in which they fix \(Y\) or \(\Theta\) and optimize the other.
One major contribution of this paper was the dataset, in which they used the Amazon Mechanical Turk (AMT) platform to obtain scribble annotations on the PASCAL VOC datasets. The PASCAL-Scribble dataset is now publicly available and used by researchers to compare their approaches.
On Regularized Losses for Weakly-supervised CNN Segmentation
Similar to the previous work, the “On Regularized Losses for Weakly-supervised CNN Segmentation” [5] also proposes an alternating optimization scheme. However, rather than fixing the oversegmentation like in the previous work, the researchers propose using a Dense Conditional Random Field (CRF) loss (and other similar losses) based on pairwise affinities between pixels to generate labels for unlabeled pixels. Thus, the proposal groundtruth are used to optimize the network parameters and network outputs are used to optimize the groundtruth proposal. The objective for the network parameters is
\[arg\,min_{\theta} \sum_{p \in \Omega_{L}}H(Y_p,S_p)+\sum_{p \in \Omega_{U}}H(X_p,S_p)\;\;S \equiv f_{\theta}(I)\]where \(Y\) are the set of labeled pixels, \(X\) is the set of proposed groundtruth, \(f_{\theta}(I)\) is the network outputs, \(\Omega_{L}\) are the set of labeled pixels, \(\Omega_{U}\) are the set of unlabeled pixels, and \(H\) is the standard cross entropy loss. As discussed before, \(X\) is fixed. The objective for the groundtruth proposal is
\[arg\,min_{X} \sum_{p \in \Omega_{U}}H(X_p,S_p) + \lambda R(X)\]where \(R\) is the dense CRF loss and the other terms are defined as before. In this case, we fix the network parameters and optimize for the groundtruth proposals.
Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation
Similar to the previously mentioned paper, in “Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation” [6], the researchers also separate optimization of labeled and unlabeled pixels. However, rather than using an alternating optimization framework, their approach is trained end-to-end. Specifically, while the loss for labeled pixels involve a standard cross-entropy loss (\(L_{seg}\)), network predictions for unlabeled pixels are evaluated based on a novel tree loss.
In the tree loss, the image pixels are represented as a vertices in a graph with edges to four adjacent pixels. In order to capture low-level and high-level information, there are two sets of edge weights. In the first set, the difference between the pixel intensities is obtained. In the second set, the difference between the network outputs (prior to softmax) is obtained. A minimum spanning tree is then obtained, pruning edges between dissimilar pixels. A matrix of path distances between is then obtained between pixels for the low-level and high-level features and then an element-wise sigmoid function is applied to generate an affinity matrix for low-level and high-level features.
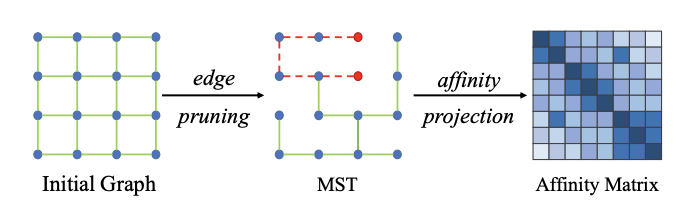
An image describing the generation of the affinity matrix can be seen above. The red lines represent the optimal path between two nodes which is used to generate the affinity matrix. Notably, while the low-level affinity matrix is static, the high-level affinitry matrix dynamically changes as the network training progresses. Finally. the pseudo labels are obtained with
\[\tilde{Y} = F(F(P, A_{low}), A_{high})\]where \(A^{*}\) are the affinity matrices and \(F\) is a filtering function defined as
\[F(P, A) = \frac{1}{z_{i}}\sum_{\forall j \in \Omega}A_{i,j}P_j\]where \(\Omega\) is the set of all pixels and \(z_{i}\) is a normalization term. \(\tilde{Y}\) is treated as pseudo groundtruth and the network predictions are evaluated against these with an L1 Loss. Thus, the overall loss is
\[L = L_{seg} + L_{tree}\]Comparison of Recent Work
The metric results for three different approaches can be seen here on PASCAL VOC 2012 utilizing the scribbles generated from ScribbleSup.
| Approach | mIoU |
|---|---|
| ScribbleSup [3] | 63.1 |
| DenseCRF Loss [5] | 75.0 |
| TEL [6] | 77.3 |
As can be seen, the ScribbleSup results are outperformed by the more recent papers. One noticable shift in recent papers is the emphasis on generating pixel-wise groundtruth proposals (DenseCRF Loss and TEL) rather than segment-wise groundtruth proposals (ScribbleSup). Additionally, ScribbleSup’s reliance on static segments may have been detrimental: both DenseCRF Loss and TEL are not limited in this way.
TEL performs slightly better than DenseCRF Loss though the results are similar. However, TEL does not require alternating optimization and has a simpler training procedure. While both approaches generate pixel-level groundtruth proposals, TEL also utilizes both high-level and low-level semantic features to generate these while the DenseCRF Loss approach relies on only low-level features. This suggests future models will also consider how to creatively utilize low-level and high-level image features to boost model performance.
Conclusion
This report outlines the recent developments in weakly supervised semantic segmentation using scribbles. We discussed methodological developments as well as the experimental results from recent models.
Reference
[1] Ratner, Alexander, et al. “Snorkel: Rapid training data creation with weak supervision.” Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases. 2017.
[2] Jia Xu, Alexander G Schwing and Raquel Urtasun, “Learning to segment under various forms of weak supervision.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[3] Lin, Di, et al. “Scribblesup: Scribble-supervised convolutional networks for semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
[4] Felzenszwalb, Pedro F., and Daniel P. Huttenlocher. “Efficient graph-based image segmentation.” International Journal of Computer Vision. 2004.
[5] Tang, Meng, et al. “On regularized losses for weakly-supervised cnn segmentation.” Proceedings of the European Conference on Computer Vision. 2018.
[6] Liang, Zhiyuan, et al. “Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation.” Conference on Computer Vision and Pattern Recognition (2022).