Module 6: Weak supervision and self supervision - Topic weakly supervised segmentation
We perform research on weakly supervised semantic segmentation with image level annotation. Six papers are introduced and compared to explore the common pipeline of weakly supervised semantic segmentation.
- Introduction
- Literature Review and Comparision
- Fully Convolutional Multi Class Multiple Instance Learning (FCN-MIL)
- Distinct Class Specific Saliency Maps for Weakly Supervised Semantic Segmentation (DCSSM)
- WILDCAT: Weakly Supervised Learning of Deep ConvNets for Image Classification
- Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation (Affinity)
- Deep clustering for weakly-supervised semantic segmentation in autonomous driving scenes.(Deep clustering)
- Weakly-Supervised Semantic Segmentation by Iterative Affinity Learning
- Comparison
- Experiment Result
- Conclusion
- Reference
Introduction
Semantic segmentation is vital in computer vision. This aims at categorizing each pixel of the image into certain label. Because no pixel-by-pixel label information is available for training, weakly-supervised semantic segmentation is a challenging process. Traditional algorithms of semantic segmentation are trained from convolutional neural networks, which needs pixel-level annotations. This is time consuming for human labor. Therefore, methods using weak labels exits. It includes image level annotation([6], [7], [8], [9], [10]), bounding box level annotation([4], [5]), and scribbles([2], [3]). Among them, methods using image level annotation are most popular and have most connection with traditional machine learning methods to elaborate features.
This report mainly summarizes some papers of weak supervised semantic segmentation, especially using image level annotations. They seek to learn a semantic segmentation model from just weak image-level labels.
Literature Review and Comparision
Fully Convolutional Multi Class Multiple Instance Learning (FCN-MIL)
This paper proposes a novel MIL formulation of multi-class semantic segmentation learning by a fully convolutional network. According to Pathak[6], fully convolutional network generates output map for every pixel. It can take any size input and give corresponding size output. The input image only signals presence or absence of an object. The output is a map for every pixel and loss map for every pixel. The paper specifically designs a multi class MIL loss. It ignores non-maximally scoring points so that the bias of FCN to background can be avoided. Semantic segmentation can be generated by taking the top-class prediction in the coarse prediction.
Distinct Class Specific Saliency Maps for Weakly Supervised Semantic Segmentation (DCSSM)
DCSSM [7] first using network forward to predict multi-label classification. Then with the predicted class labels, it calculates the derivative of back-propagation. The derivatives of class score will be processed by aggregating on multiple feature layers to generate saliency maps. Because the saliency maps of different classes are overlapped in terms of most saliency regions, model will subtract saliency maps of other candidate classes from saliency maps of target class. Because saliency maps obtained only represent the target class probability on each pixel. There is no information about the object boundary. In the end, conditional random field CRF [1] will be applied to estimate object boundaries.
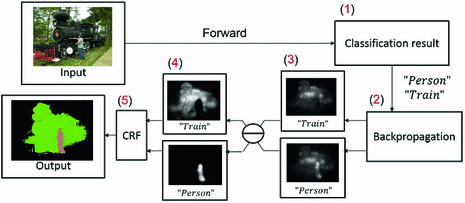
Fig 1. DCSSM’s structure[7]
The novelty of this method replies on estimating distinct class saliency maps. It uses backward propagation derivatives to generate feature maps of middle layers. Then subtraction and aggregating are applied to generate a final class saliency map.
WILDCAT: Weakly Supervised Learning of Deep ConvNets for Image Classification
WILDCAT [8] uses FCN as backbone. The second step is to apply a multi-map transfer layer. By 1*1 convolutions, the FCN result can be encoded into M feature maps. The M modalities show different class-specific features.
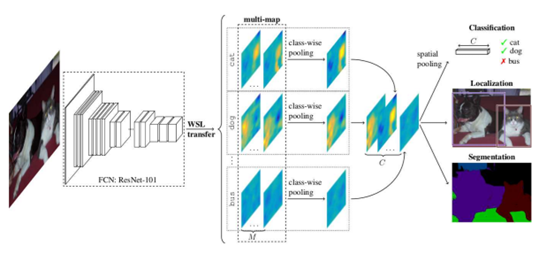
Fig 2. WILDCAT’s structure[8]
With M multi-maps for each category, we perform pooling afterwards, which are class-wise pooling and spatial pooling. Class-wise pooling aggregates M multi-map of one category into one map. Spatial pooling selects the highest activation from input, for each class. For semantic segmentation result, class level feature map will be regarded as semantic segmentation. CRF is also applied to increase the segmentation accuracy.
The novelty of this method lies in the area of multi map WSL transfer layer and aggregating multiple scores into global prediction with spatial pooling.
Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation (Affinity)
The model [9] first generates segmentation labels given image level class labels. Then with the given segmentation labels, it learn a deep neural network for semantic segmentation using three existing models: CAMs, AffinityNet and segmentation model. Specifically, it compute CAMs from a classification network with global average pooling and fully connected layer. Then, AffinityNet predicts semantic affinity between adjacent pixels by aggregating feature maps from multiple levels of backbone network. The output of AffinityNet will be revised CAMs. Using up-sampling and dCRF, the semantic segmentation is supposed to be refined.
The novelty of the method lies on propagating local responses to nearby areas which belongs to the same semantic entity. AffinityNet predicts semantic affinity and use random walk to propagate the result to AffinityNet.
Deep clustering for weakly-supervised semantic segmentation in autonomous driving scenes.(Deep clustering)
Deep clustering [9] first uses CAM method to perform initial localization. Based on the problem background autonomous driving scenes, objects are clustered and have same class similarities. Thus, from coarse and inaccurate localization, the object uses deep clustering to cluster interested target area. In this step, paper segments the images to super pixel regions. Using the learned feature from each region to predict new labels for super pixel regions, whose goal is to maximize the variance among different classes with cross entropy loss and minimize the variance within the same class with center loss. Finally, use previous classes and object regions to supervise training of segmentation network.
The novelty of this method is using initial object localization as guidance and iteratively deep clustering them. In this way, the object region is expanded, and different object are separated more clearly.
Weakly-Supervised Semantic Segmentation by Iterative Affinity Learning
Most of the above papers exploited classification networks, which were used to locate items by selecting regions with a high response rate. While such a response map gives sparse information, natural images contain strong pairwise associations between pixels that can be used to propagate the sparse map to a much denser map. As a result, an iterative affinity learning is proposed to learn such pairwise relations. The framework contain two branches: an unary segmentation network that can generate probability maps for input image, and a pairwise affinity network which learn a affinity matrix using the minded confident regions from the probability map. Then, the affinity matrix is applied to the probability maps to generate refined segementation results which are used as supervision signals to retrain the unary network. These procedures are conducted iteratively.
Comparison
Fully convolutional network[11] is a fundamental work. It introduces pixel wise prediction of image semantic. It is widely used in both fully supervised semantic segmentation algorithms and weakly supervised semantic segmentation algorithms. For weakly supervised semantic segmentation with only image labels, the listed papers rely on FCN or classification saliency map to locate objects. These methods can be regarded as multi instance learning because image is considered as package and pixel is used to decide whether it is known class or not. In the end of model pipeline, normally conditional random field will be applied to improve the localization performance. In simpler words, one common pipeline is to start with FCN and extract a rough segmentation, then perform different refinement work to increase the segmentation, and in the end use CRF to wrap it up. The listed paper diverges from this common pipeline and is discussed as below.
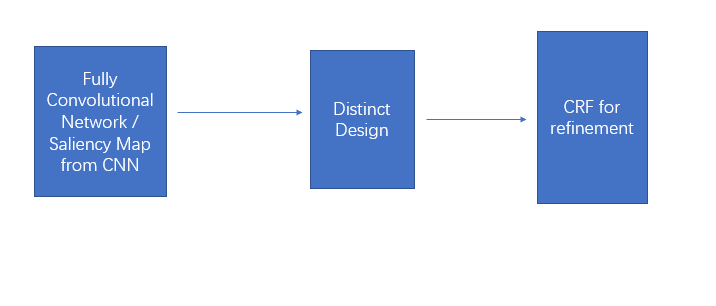
Fig 3. Typical pipeline of weakly supervised semantic segmentation[7]
FCN-MIL [6] is the first work in weakly supervised semantic segmentation. It makes use of FCN. Combined with global max pooling, it generates the class predicted at pixel-level. Compare with FCN-MIL, DCSSM [7] doesn’t directly use FCN. Instead, it uses classification CNN to generate predicted class, and generate saliency map based on the predicted classes. Using subtracting and aggregating to generate the semantic segmentation result. CRF is applied in the end. WILDCAT [8] starts from FCN. It uses the method of WSL transferring and spatial pooling to obtain the feature map. Affinity use CNN and CAM to obtain saliency map. Then AffinityNet is used to revise the CAM by predicting semantic affinity between adjacent pixels. DeepCluster is an exception, which is added to the list to show that dataset characteristics can also play significant role in predicting semantic segmentation. Objects in autonomous driving scenes are normally clustered. Deepcluster makes good use of this characteristic to build iterative cluster method. The result is proved to be better. Other than using classification networks to localize objects, the authors of iterative affinity learning propose an iterative algorithm to learn pairwise relations between pixels in natural images. Experimental results demonstrate that the proposed algorithm can outperform the state-of-the-art methods.
Experiment Result
The six papers make use of dataset PASCAL VOC 2012[12]. It is the default benchmark set for weakly supervised semantic segmentation challenges. The detailed number is shown in the table below.
| Methods | mIoU |
|---|---|
| FCN-MIL | 24.9 |
| DCSM with CRF | 45.1 |
| WILDCAT with CRF | 43.7 |
| Affinity | 63.7 |
| Deep Clustering | 57.2 |
| Iterative Affinity Learning | 63.1 |
Conclusion
This report summarizes six related papers in weakly supervised semantic segmentation area. They all use image level annotation and use multiple instance learning pipeline. The report compares the difference between six models and their relationship with each other. A summary of experiment results are shown as well.
Reference
[1] Krähenbühl, Philipp, and Vladlen Koltun. “Efficient inference in fully connected crfs with gaussian edge potentials.” Advances in neural information processing systems 24 (2011).
[2] Lin, Di, et al. “Scribblesup: Scribble-supervised convolutional networks for semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[3] Çiçek, Özgün, et al. “3D U-Net: learning dense volumetric segmentation from sparse annotation.” International conference on medical image computing and computer-assisted intervention. Springer, Cham, 2016.
[4] Dai, Jifeng, Kaiming He, and Jian Sun. “Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation.” Proceedings of the IEEE international conference on computer vision. 2015.
[5] Papandreou, George, et al. “Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation.” Proceedings of the IEEE international conference on computer vision. 2015.
[6] Pathak, Deepak, et al. “Fully convolutional multi-class multiple instance learning.” arXiv preprint arXiv:1412.7144 (2014).
[7] Shimoda, W., & B, K. Y. Distinct Class-Specific Saliency Maps for Weakly Supervised Semantic Segmentation.
[8] Durand, Thibaut, et al. “Wildcat: Weakly supervised learning of deep convnets for image classification, pointwise localization and segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[9] Ahn, Jiwoon, and Suha Kwak. “Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[10] Wang, Xiang, Huimin Ma, and Shaodi You. “Deep clustering for weakly-supervised semantic segmentation in autonomous driving scenes.” Neurocomputing 381 (2020): 20-28.
[11] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[12] Everingham, Mark, et al. “The pascal visual object classes challenge: A retrospective.” International journal of computer vision 111.1 (2015): 98-136.
[13] X. Wang, S. Liu, H. Ma, and M.-H. Yang, ‘‘Weakly-supervised semantic segmentation by iterative affinity learning,’’ Int. J. Comput. Vis., vol. 128, no. 6, pp. 1736–1749, Jun. 2020.