Image Super-Resolution: A Brief Overview
Image Super-Resolution (SR) is a technique in computer vision that reconstructs a high-resolution (HR) image from one or more low-resolution (LR) images. In this bloc post, we aim to provide an overview of both fundamental and recent state-of-the-art (SOTA) machine learning models within this field.
Introduction
Super-resolution (SR), the process of reconstructing a high-resolution image from its low-resolution counterpart, represents a pivotal challenge in computer vision. The ill-posed nature of this problem, where multiple plausible high-resolution outputs may correspond to the same low-resolution input, demands sophisticated approaches that blend mathematical rigor with computational efficiency. Over the decades, SR has transitioned from traditional model-based methodologies to state-of-the-art learning-based frameworks, driven by advancements in deep learning, neural network architectures, and optimization techniques.
We will explore three landmark contributions to the field of SR: (1) Super-Resolution Convolutional Neural Network (SRCNN), a pioneering approach in leveraging deep learning for SR; (2) Dense-Residual-Connected Transformer (DRCT), which integrates Vision Transformers to address long-range dependencies; and (3) Unfolding Super-Resolution Network (USRNet), a hybrid model bridging learning-based and model-based paradigms for enhanced flexibility and adaptability. Together, these works illuminate the evolving landscape of SR and its convergence toward versatile, high-performance solutions.
Foundations
SR traditionally relied on sparse-coding-based methods, which utilized dictionaries to encode and reconstruct image patches. While effective, these techniques often required extensive preprocessing, separate optimization of each pipeline component, and were computationally intensive. The advent of convolutional neural networks (CNNs) revolutionized this paradigm, enabling end-to-end training that jointly optimized all layers and components for superior speed and accuracy.
SRCNN exemplifies this transformation, demonstrating that sparse coding can be reinterpreted as a deep CNN pipeline, eliminating the need for explicit dictionary learning. This method also highlighted the capacity of CNNs to extend SR capabilities to multi-channel (e.g., RGB) images, setting the stage for further exploration of deep learning-based SR.
Recent Breakthroughs
The progression from SRCNN to DRCT and USRNet highlights the field’s dynamic evolution, driven by technological advancements and application demands. Future directions may include:
Multi-task Learning: Integrating SR with other vision tasks (e.g., segmentation, detection) for holistic model design. Self-Supervised Training: Leveraging unlabeled data to enhance model robustness and generalizability. Edge Deployment: Optimizing SR models for deployment on resource-constrained devices, expanding their real-world applicability. By uniting theoretical insights with practical innovations, SR continues to push the boundaries of what is possible in image restoration and enhancement.
Super Resolution Convolutional Neural Network
The Super Resolution Convolutional Neural Network (SRCNN) is one of the first deep learning models created to perform single-image super-resolution. It directly maps low-resolution (LR) images to high-resolution (HR) through an end-to-end convolutional network, bypassing complicated steps such as manually designing image filters or using iterative optimization algorithms for each individual image.
Architecture
The architecture of the SRCNN mimics the steps of traditional image super-resolution pipelines and combines them into a single deep learning frame work. The model uses only three convolutional layers, making it computationally efficient and lightweight. Each layer models one of the three key operations–patch extraction and representation, non-linear mapping, and reconstruction.
Patch Extracting and Representation
The first layer extracts overlapping patches from the input LR image and represents each patch as a high-dimensional feature vector. This step convolves the image with a set of learnable filters:
\(F_1(Y) = \max(0, W_1 \ast Y + B_1)\)
Here, W~1~ and B~1~ denote the convolutional filters and biases, respectively, applied to the input Y. ReLU activation ensures non-linearity.
Non-linear Mapping
The extracted filters are then non-linearly mapped to a different set of high-dimensional filters, which are intermediate representations of the HR image: \(F_2(Y) = \max(0, W_2 \ast F_1(Y) + B_2)\) This layer enables the network to learn the complex mappings critical for SR tasks.
Reconstruction
Finally, the high-dimensional mapped features are aggregated to reconstruct the HR image:
\(F(Y) = W_3 \ast F_2(Y) + B_3\)
This layer ensures that the outputted HR image closely aligns with the ground truth.
Advantages and Performance
The SRCNN has several significant advantages over traditional image super-resolution methods. Unlike traditional methods which optimize each pipeline component separately, SRCNN unifies all of the steps into a single deep learning pipeline. The model learns the entire process end-to-end and holistically optimizes it to directly map LR images to a higher-resolution. This results in sharper edges, less artifacts, and improved texture details compared to traditional methods. Additionally, using a deep convolutional network over the simpler, linear models allows more complex patterns and subtler textures to be recovered. Figure 1 shows the super resolution results of different approaches. SRCNN produces much sharper edges than the other approaches, without any obvious artifacts across the image.

Figure 1: Super resolution results of different approaches [3]
SRCNN’s lightweight, three-layer architecture is computationally efficient and operates in a feed-forward manner, allowing images to be processed in a single pass without iterative optimization steps like those in sparse coding. The training time compared to other super-resolution models is also relatively fast, despite the intensive requirements (larger datasets and signficicant computational resources) of deep learning models. The model’s architecture, with fewer parameters and layers, results in quicker convergence, allowing the model to reach high-performance levels without requiring extensive training periods.
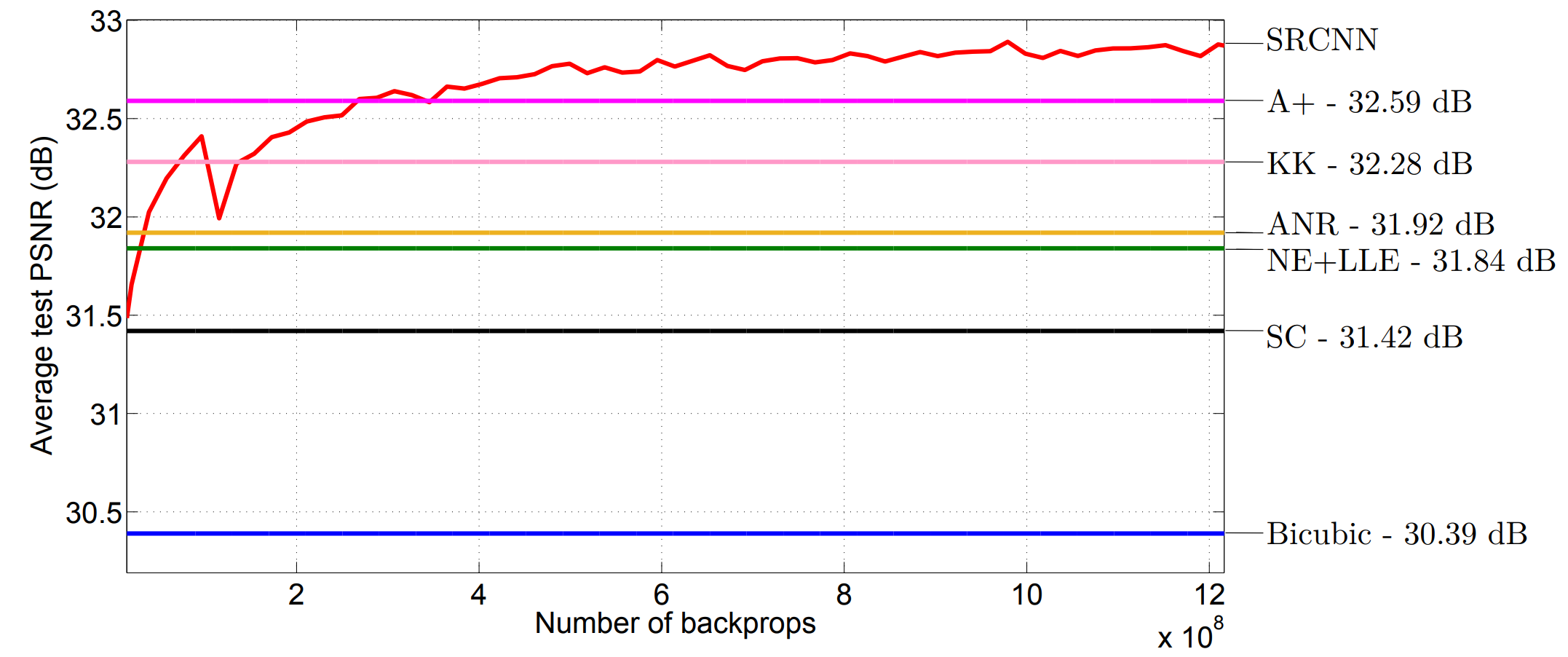
Figure 2: Average PSNR comparison of SRCNN against other super-resolution methods on the Set5 dataset [3]
This efficiency is clearly displayed in the convergence curve shown in Figure 2. Within a relatively small number of backpropagation steps, SRCNN rapidly surpasses the PSNR (common metric to measure quality of reconstructed image relative to its original) performance of other super-resolution methods like A+ (32.59dB) and KK (32.38dB). The convergence curve also demonstrates the model’s stability during training. Even as the number of backpropagation steps increases the PSNR steadily improves and stabilizes, showcasing a low sensitivity to training variations. This, combined with SRCNN’s end-to-end deep learning framework which can efficiently handle a wide range of degradations, demonstrates the models robustness in handling diverse super-resolution tasks and image datasets.
SRCNN is not without its limitations, however. Compared to modern deep learning architectures a three-layer design is relatively shallow. While it ensures efficiency, it does restrict the model’s ability to capture very complex patterns and incredibly fine details in images, especially for any tasks requiring higher scaling factors or images containing intricate textures.
Color
SRCNN’s architecture processess multi-channel images easily, learning the relationships and correlations between color channels during training. This allows it to deliver accurate and consistent color representation, making it particularly effective when trained on RGB images. SRCNN’s architecture can efficiently leverage the high correlation between the R, G, and B channels, ensuring that the super-resolved images retain sharpness and natural colors. SRCNN still effectively handles other color spaces, such as YCbCr space.
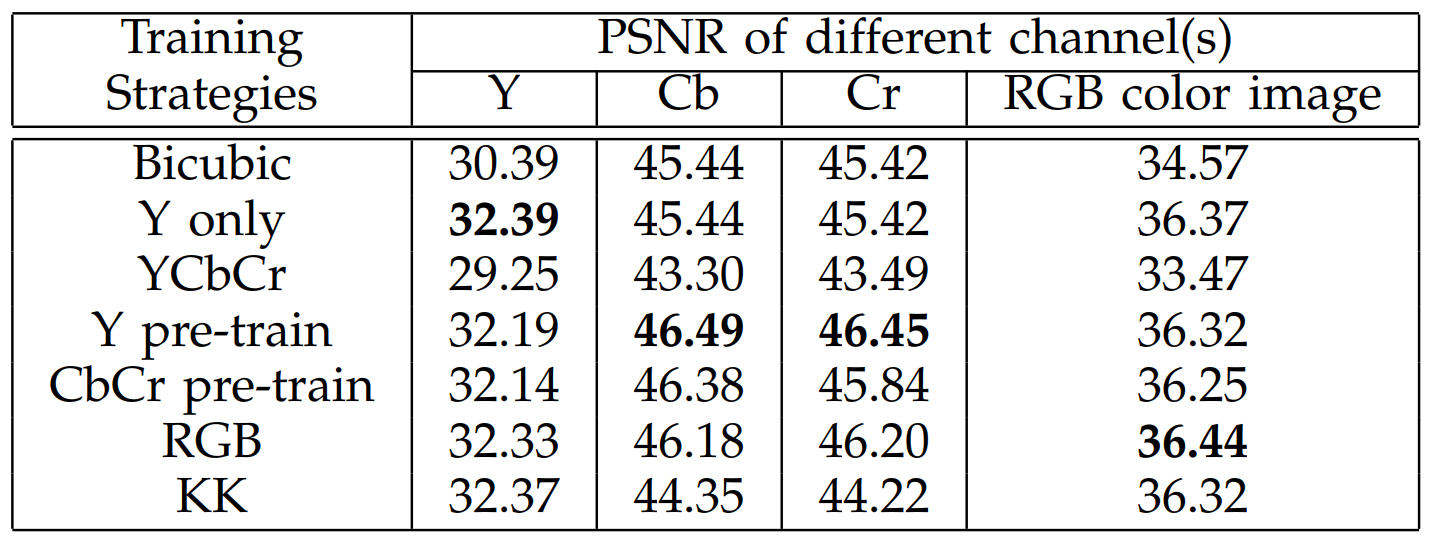
Figure 3: Average PSNR of different channels and training strategies [3]
Despite the advancements in handling color information and its ability to process RGB images, the model’s improvements in color performance is relatively modest compared to its gains in performance. When evaluated against other metrics, such as KK, the difference in PSNR for color super-resolution was only 0.12 dB, as seen in Figure 3. This indicates that while SRCNN improves color representation, there is room for more significant advancements in how color information if reconstructed, particularly within fine color details.
USRNet
Description
Recent advancements in image super-resolution have seen a convergence of traditional optimization techniques and deep learning. A notable example is the work of Zhang, Van Gool, and Timofte in their paper Deep Unfolding Network for Image Super-Resolution. This paper introduces a novel approach that integrates iterative optimization algorithms with deep neural networks through a process known as “deep unfolding.” By formulating super-resolution as an energy minimization problem, the authors utilize a network architecture that mimics the steps of proximal gradient descent while allowing for learnable parameters at each iteration. Specifically, the complete energy loss can be formalized as: \(E_\mu(x,z)=\frac{1}{2\sigma^2}||y-(z\otimes k )\downarrow_s||^2 + \lambda \Phi(x) + \frac{\mu}{2}||z-x||^2\) The above equation utilizes half quadratic splitting to introduce an additional variable z such that the data term and the prior term are separated. The final term is a penalty term used to bring z and x close in value with $\mu$ representing the tradeoff between the value and eventually becoming infinitely large. Thus, the data and prior terms can be optimized individually and separately which reduces computational load and complexity. Additionally, the separate modules allows for the tasks of removing blur and restoring detail to be optimized separately allowing for greater generalizability and performance. At the same time, USRNet is still trained end-to-end and handles all aspects of this image degradation with a single model.
The value of $\mu$ and the tradeoff generally for $z_k$ and $x_k$ is determined separately using a neural network that takes in noise level and scale factor as inputs and has three fully connected layers. Thus, USRNet is also a non-blind image super resolution as it uses the known blur kernel, scale factor, and noise to upscale the image.
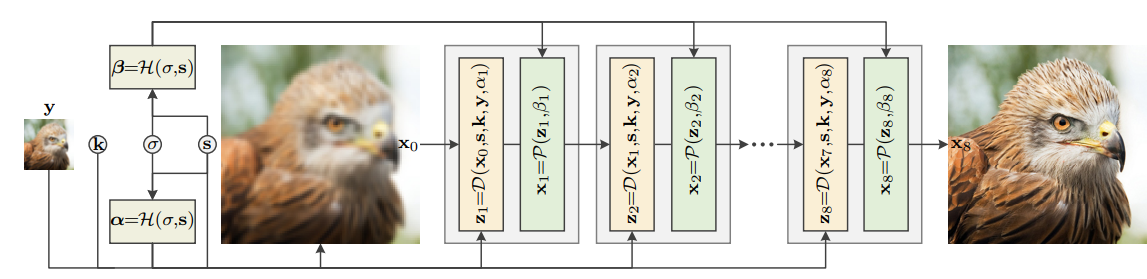
Figure 4: Architecture of USRNet [1]
Data Module
In USRNet, the Data Module ensures that the reconstructed high-resolution image remains consistent with the input low-resolution image. This module directly addresses the degradation model ensuring that the estimated HR image aligns closely with the observed LR input. Formally, the data module attempts to solve this minimization problem and utilizes the x value from the previous iteration. \(z_k=\arg \min_z||y - (z \otimes k) \downarrow s||^2 + \mu \sigma^2||z-x_{k-1}||^2\) A closed form solution for this problem can be found using Fast Fourier Transforms thus resulting in less computational work and space needed.
Prior Module
In the Deep Unfolding Network for Image Super-Resolution, the Prior Module incorporates learned image priors to regularize the high-resolution estimate, ensuring the reconstructed image appears natural and artifact-free. The prior term addresses the challenge of ill-posedness in the super-resolution problem by encouraging plausible solutions. Formally, the prior module attempts to the minimize the following equation: \(x_k = \arg \min _x \frac{\mu}{2}||z_k-x||^2 + \lambda \Phi(x)\) In the deep unfolding framework, the prior module is implemented as a learnable neural network by using ResUNet, a variation of U-Net that utilizes the residual blocks from ResNet. This network learns complex image features, such as textures and edges, directly from training data, effectively acting as a denoiser or enhancer for intermediate HR estimates. By adapting the regularization at each layer of the network, the prior module dynamically refines the reconstruction process, ensuring that details are preserved without introducing unnatural artifacts.
DRCT
A residual-based approach addressing the information loss problem of previous swin-transformer-based models.
Information Loss
For the more recent advancements of Single Image Super-Resolution (SISR), swin-transformer-based models have achieved superior performances, outperforming the traditional CNN-based methods. However, in practice, the swin-transformer-based models have yet reach their potentials with a common information loss problem: when performing SISR tasks with such models on different benchmark datasets, the amplitude of learned latent representation will keep increae as the model is gathering up more information, yet all models undergo a sharp decrease in amplitude towards the end of the transformer network, indicating an information loss.
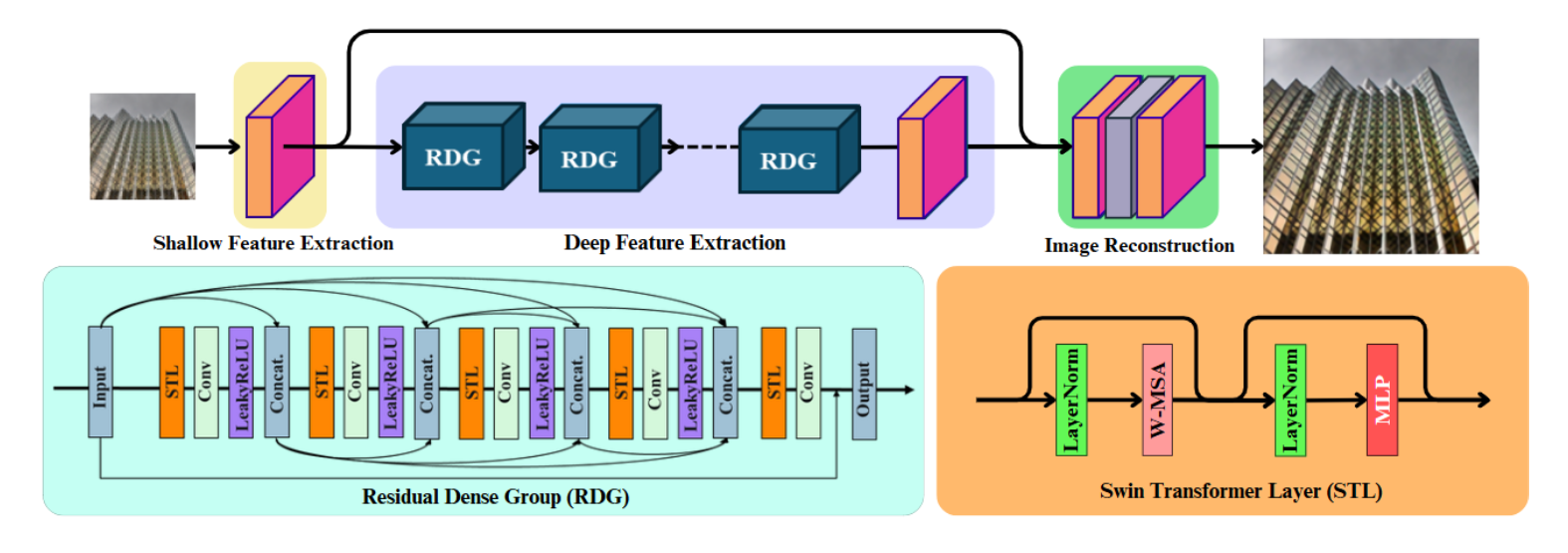
Figure 5: Feature Map Amplitudes of Swin-transformer-based SISR Models [2].
Method
Deep-residual-connected Transformer (DRCT) addresses the information loss problem by proposing Swin-Dense-Residual-Connected Block (SDRCB), which incorporates Swin Transformer Layers and transition layers into each Residual Dense Group (RDG). This not only solves the information loss problem but also results in a denser model structure with fewer parameters, achieving state-of-the-art performance with high efficiency.
Dense-Residual-Connected Architecture
DRCT addresses the bottleneck by introducing dense-residual connections within residual groups. This innovation ensures a smoother information flow and prevents the abrupt loss of spatial details. By integrating these connections into a Swin-Transformer-based architecture, DRCT stabilizes deep feature propagation while retaining high-frequency spatial details.
Key Innovations
- Swin-Dense-Residual-Connected Block (SDRCB):
- Combines dense connections and Swin Transformer layers.
- Enhances receptive fields while maintaining stability in forward propagation.
- Progressive Training Strategy:
- Employs pretraining on large datasets like ImageNet.
- Fine-tunes the model using specific loss functions (L1 and L2) for refined results.
Model Details
Figure 6: The Overall Model Architecture of DRCT and the Structure of Residual Dense Group [2].
The DRCT pipeline is straightforward yet powerful:
- Shallow Feature Extraction: Captures initial spatial details via a simple convolutional layer.
-
Deep Feature Extraction: Leverages SDRCBs within Residual Dense Groups (RDGs) to fuse multi-level spatial information and enhance receptive fields.
- Image Reconstruction: Merges shallow and deep features to produce high-resolution outputs.
Mathematically:
- Shallow features: \(F_0 = \text{Conv}(I_LR)\)
- Deep features: \(F_{DF} = \text{Conv}(RDG(F_0))\)
- Super-resolution image: \(I_{SR} = H_{\text{rec}}(F_0 + F_{DF})\)
- Swin-Dense-Residual-Connected Block: For the input feature maps $\mathbf{Z}$ within RDG, the SDRCB can be defined as \(\mathbf{Z}_j = H_{\text{trans}}(\text{STL}([\mathbf{Z},\ldots,\mathbf{Z}_{j-1}])), j = 1,2,3,4,5,\) \(\text{SDRCB}(\mathbf{Z}) = \alpha\cdot \mathbf{Z}_5 + \mathbf{Z},\) where $[\cdot]$ denotes the concatenation of multi-level feature maps produced by the previous layers. $H_{\text{trans}}(\cdot)$ refers to the convolution layer with an activation.
Results
Quantitative Performance
DRCT outperforms state-of-the-art methods across popular datasets (e.g., Set5, Set14, Urban100) with fewer parameters and computational demands. Its superior PSNR and SSIM scores underline its effectiveness.
Visual Quality
Compared to competing methods, DRCT restores finer textures and structures, especially in challenging scenarios. The model adeptly handles high-frequency details, avoiding the blurring artifacts common in other approaches.

Figure 7: DRCT Results on Several SISR Benchmark Datasets [2].
Conclusion
The field of single image super-resolution (SISR) has seen significant advancements through the development of novel deep learning approaches. This conclusion section synthesizes insights from three pivotal studies: SRCNN, USRNet, and DRCT. These methods showcase unique strengths, limitations, and potential applications within the SISR landscape.
Key Contributions and Advancements
SRCNN
SRCNN reformulated traditional sparse-coding-based methods into an efficient deep convolutional neural network, achieving state-of-the-art performance with a lightweight architecture. Its simplicity and robustness suggest broad applicability, including image deblurring and simultaneous SR + denoising tasks. However, despite incorporating multi-channel support for RGB, SRCNN’s color super-resolution has made no significant improvements. Additionally, SRCNN’s shallow depth is a double-edged sword: while it enables high computational efficiency, it also causes the model to struggle with images which have very intricate features and higher scaling factors.
USRNet
USRNet introduced a deep unfolding super-resolution network that integrates the advantages of both model-based and learning-based methods. By incorporating three interpretable modules—data, prior, and hyper-parameter modules—USRNet achieved flexibility and generalizability. Its performance on highly degraded images demonstrated the model’s adaptability, showcasing its ability to handle diverse SISR degradation scenarios effectively.
DRCT
The DRCT model addressed information bottlenecks in deeper networks, presenting a dense-residual-connected architecture within a Swin-transformer framework. By enhancing information flow and global receptive fields, DRCT achieved superior results compared to state-of-the-art methods. It also demonstrated computational efficiency, reducing memory requirements and FLOPs while maintaining high performance, as evidenced in the NTIRE 2024 Challenge results.
Comparison of Model Architectures
| Aspect | SRCNN | USRNet | DRCT |
|---|---|---|---|
| Architecture | Lightweight CNN | Deep unfolding network | Swin-transformer with dense connections |
| Key Strength | End-to-end simplicity and robustness | Flexibility and interpretability | Stable information flow and global context capture |
| Performance on RGB | Strong cross-channel correlation | Generalizable across degradation types | Superior performance with fewer parameters |
| Efficiency | Minimal pre/post-processing | Trainable parameter-free data module | Reduced computational burden |
| Limitations | Struggles with intricate features and high scaling factors | Dependence on degradation constraints | Information bottleneck in high-depth scenarios |
Future Direction
The comparison of SRCNN, USRNet, and DRCT highlights their unique strengths and trade-offs in achieving state-of-the-art SISR performance. SRCNN excels in simplicity and foundational performance; USRNet offers flexibility and generalizability; and DRCT combines efficiency with enhanced global information capture. Future advancements in SISR should focus on overcoming current model-specific challenges while integrating the best features of these architectures to push the boundaries of image super-resolution technology. Addressing these limitations through innovative architectures and optimization techniques will further enhance SISR performance, especially for real-world applications.
References
[1] Zhang, K., Van Gool, L., & Timofte, R. (2020). Deep Unfolding Network for Image Super-Resolution. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 3214–3223. [2] Hsu, C. C., Lee, C. M., & Chou, Y. S. (2024). DRCT: Saving Image Super-resolution away from Information Bottleneck. arXiv preprint arXiv:2404.00722. [3] Dong, C., Loy, C. C., He, K., Tang, X. (2016). Image Super Regolution Using Deep Convolutional Networks: IEE Transactions on Pattern Analysis and Machine Intelligence. v. 38. n. 2. pp. 295-307