Visual Question Answering
Visual Question Answering (VQA) combines computer vision and natural language processing to enable AI systems to answer questions about images. This project explores and compares models like LSTM-CNN, SAN, and CLIP, evaluating their performance on datasets such as VQA v2, CLEVR, GQA, and DAQUAR. Using accuracy metrics and attention map visualizations, we uncover how these models process visual and textual data, highlighting their strengths and identifying areas for improvement.
- Introduction
- Early Fusion: LSTM-CNN
- Attention Mechanisms: SAN
- Recent Advancements: Zero-Shot and Few-Shot Learning with CLIP
- Other Models in VQA
- Conclusion and Future Perspectives
- Running VQA Model
- References
Introduction
Visual Question Answering (VQA) is a challenging task at the intersection of computer vision and natural language processing, where models are required to answer questions based on the content of images, requiring a multimodal interpretation of image and text data. This paper explores the evolution of VQA models, starting from earlier architectures like LSTM-CNN and Stacked Attention Networks (SAN), which focus on integrating visual and textual data. We also discuss more recent advancements in VQA, such as CLIP, which leverages large-scale pretraining of image-text pairs for zero-shot learning. CLIP’s ability to generalize across tasks without task-specific fine-tuning represents a significant leap in VQA research, as it improves on older models’ limitations. Additionally, we briefly cover other notable models, like HieCoAtten, which introduces hierarchical co-attention mechanisms, and the contributions of these approaches to the field. By evaluating their performance on popular VQA datasets, such as VQA v2, CLEVR, GQA, and DAQUAR, we assess the progress made and identify areas for future research in the ever-evolving VQA landscape.
Early Fusion: LSTM-CNN
Overview
Early fusion models in Visual Question Answering (VQA) aim to combine visual and textual features in a straightforward manner, typically by encoding each modality separately and merging them into a unified representation. The LSTM-CNN model, proposed in the VQA-v1 paper by Antol et al. (2015) [1] and expanded upon by Milnowski et al. (2015) [3], exemplifies this approach by utilizing convolutional neural networks (CNNs) to extract visual features and long short-term memory networks (LSTMs) to process questions. Despite its simplicity, the model laid the groundwork for later advancements by showcasing how effective multi-modal fusion could be achieved for answering questions about images.
Architecture and Process
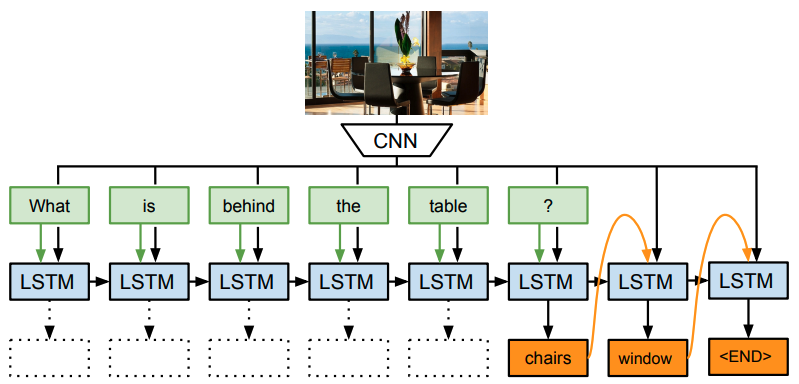
Fig 1. Basic process for the LSTM-CNN [3].
The LSTM-CNN model operates in two stages: visual feature extraction and textual question encoding, followed by fusion and prediction. The process is as follows:
-
Image Feature Extraction (CNN): The model begins by passing the image through a pre-trained CNN, such as ResNet or VGG, which extracts high-level visual features. These features represent various aspects of the image, including objects, textures, and their spatial relationships. The output of this step is a fixed-length feature vector representing the entire image.
-
Question Encoding (LSTM): The question is tokenized into a sequence of words and embedded into a dense vector space using an embedding layer. These word embeddings are then processed by an LSTM, which captures the sequential dependencies of the question and encodes it into a fixed-length vector. This vector encapsulates the semantic meaning of the question.
-
Fusion of Image and Question Features: Once both the visual and textual features have been extracted, they are concatenated into a single vector. This combined representation merges the information from both modalities, enabling the model to use the visual context in conjunction with the question’s meaning for reasoning.
-
Prediction Layer: The fused vector is passed through a fully connected layer (typically a dense layer), which produces the final output—either a class label (for multiple-choice questions) or a probability distribution over possible answers. This layer performs the task of generating the answer based on the combined understanding of the image and question.
This approach highlights a simple but effective method of fusing image and textual information early in the processing pipeline. However, it lacks the ability to focus on specific parts of the image in response to a question, which is a limitation that later attention-based models would address.
Code Implementation
Below is a general implementation of the model based on the architecture and approach described in the paper.
The original paper uses a pretrained GoogleNet CNN, and this implementation keeps that same CNN architecture. The LSTM layer is retained as in the paper, with the image features extracted using GoogleNet and the question features processed by the LSTM. These features are then fused for the final prediction. The code has been modernized using current libraries and methods, but the approach remains consistent with the original model.
import torch
import torch.nn as nn
import torchvision.models as models
import torch.nn.functional as F
# 1. Image Feature Extraction (CNN) using GoogleNet
class CNN_Extractor(nn.Module):
def __init__(self):
super(CNN_Extractor, self).__init__()
# Using pretrained GoogleNet model from ImageNet, removing final fully connected layer
self.googlenet = models.googlenet(pretrained=True)
self.googlenet.fc = nn.Linear(self.googlenet.fc.in_features, 256)
def forward(self, x):
# Extract image features through the modified GoogleNet model
features = self.googlenet(x)
return features
# 2. Question Encoding (LSTM) - Single Layer LSTM
class Question_Encoder(nn.Module):
def __init__(self, vocab_size, embed_dim=256, hidden_dim=256):
super(Question_Encoder, self).__init__()
# Embedding layer and LSTM for question encoding
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True, num_layers=1)
def forward(self, x):
# Convert word indices to embeddings and pass through LSTM
x = self.embedding(x)
_, (hidden, _) = self.lstm(x)
return hidden[-1]
# 3. Fusion of Image and Question Features
class Feature_Fusion(nn.Module):
def __init__(self, image_dim=256, question_dim=256, fusion_dim=512):
super(Feature_Fusion, self).__init__()
# Fully connected layer to combine image and question features
self.fc = nn.Linear(image_dim + question_dim, fusion_dim)
def forward(self, image_features, question_features):
# Concatenate and fuse image and question features
combined = torch.cat((image_features, question_features), dim=1)
return self.fc(combined)
# 4. Prediction Layer
class Prediction_Layer(nn.Module):
def __init__(self, input_dim=512, output_dim=10):
super(Prediction_Layer, self).__init__()
# Fully connected layer for final prediction
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, x):
# Output predictions using softmax
return F.softmax(self.fc(x), dim=1)
# Complete LSTM-CNN Model
class LSTM_CNN_Model(nn.Module):
def __init__(self, vocab_size, output_dim=10):
super(LSTM_CNN_Model, self).__init__()
# Initialize submodules: CNN feature extractor, LSTM question encoder, feature fusion, and prediction layer
self.cnn_extractor = CNN_Extractor()
self.question_encoder = Question_Encoder(vocab_size)
self.feature_fusion = Feature_Fusion()
self.prediction_layer = Prediction_Layer(input_dim=512, output_dim=output_dim)
def forward(self, image, question):
# Extract image and question features, fuse them, and predict the final output
image_features = self.cnn_extractor(image)
question_features = self.question_encoder(question)
fused_features = self.feature_fusion(image_features, question_features)
return self.prediction_layer(fused_features)
Results
The performance of the LSTM-CNN model was evaluated using the DAQUAR dataset. The model was tested on both the full dataset and a reduced version with 25 images and 297 QA pairs. The evaluation was done using standard metrics: accuracy and WUPS scores at thresholds of 0.9 and 0.0.
Explanation of WUPS Scores
WUPS (Word Overlap with Partial Matching Score) is a metric used to evaluate the semantic similarity between the predicted and ground truth answers. It is particularly useful in VQA tasks where the output may not exactly match the ground truth answer but may still be semantically close.
- WUPS@0.9: This score measures how closely the predicted answer matches the ground truth, with a high threshold (0.9) for word overlap. A higher score means the predicted answer is more likely to be semantically identical or nearly identical to the ground truth answer.
- WUPS@0.0: This score is less stringent, allowing for partial matches in the answers. A score of 0.0 means there is no threshold for word overlap, and even partially matching answers can achieve higher scores.
WUPS scores provide a more nuanced view of model performance compared to accuracy, as they consider semantic similarity and partial matches, which are important in natural language processing tasks.
Quantitative Results
Full DAQUAR Dataset
- Multiple Words:
- Accuracy: 17.49%
- WUPS@0.9: 23.28%
- WUPS@0.0: 57.76%
- Single Word:
- Accuracy: 19.43%
- WUPS@0.9: 25.28%
- WUPS@0.0: 59.13%
These results suggest that while the model handles both multiple-word and single-word queries, its performance is limited by the complexity and variation in the dataset. The WUPS scores at both thresholds indicate the model’s ability to produce answers with varying degrees of semantic similarity, though it struggles to provide precise answers (e.g., at WUPS@0.9).
Reduced DAQUAR Dataset (25 images, 297 QA pairs)
- Multiple Words:
- Accuracy: 29.27%
- WUPS@0.9: 36.50%
- WUPS@0.0: 66.33%
- Single Word:
- Accuracy: 34.68%
- WUPS@0.9: 40.76%
- WUPS@0.0: 67.95%
The model shows improved performance across all metrics when tested on the reduced dataset. The increased accuracy and WUPS scores indicate that the LSTM-CNN model performs better with less complexity and fewer variations in the data, with notable improvements in both single-word and multiple-word queries.
Comparison with Language-Only Model
For comparison, a language-only model (that doesn’t use any visual features) was evaluated on the same datasets:
- Full DAQUAR dataset:
- Accuracy: 17.06%
- WUPS@0.9: 21.75%
- WUPS@0.0: 53.24%
- Reduced DAQUAR dataset:
- Accuracy: 32.32%
- WUPS@0.9: 35.80%
- WUPS@0.0: 63.02%
The language-only model showed lower performance than the LSTM-CNN model, especially with complex, visual-based queries. However, it performed reasonably well in terms of accuracy on the reduced dataset, though it struggled more with precise, context-aware answers as reflected by the WUPS scores.
Qualitative Results
Qualitative analysis of the model’s output revealed that the LSTM-CNN model is effective in generating answers aligned with the visual context in the images. The model shows good spatial reasoning when handling questions related to object counting or identifying attributes. However, it struggles with queries involving spatial relations, achieving only around 21 WUPS at 0.9, a challenging aspect that accounts for a significant portion of the DAQUAR dataset.
The model performs well on questions involving clearly defined objects and their attributes, such as identifying locations or colors. However, tasks that require understanding the spatial relationships between objects are more challenging. These types of queries, which involve questions like relative positions or sizes, often result in lower accuracy due to the difficulty in interpreting complex spatial interactions from the visual input. Additionally, questions about small objects, negations, and shapes tend to have reduced performance, likely due to limited training data for these scenarios. Despite these challenges, focusing on simpler or less ambiguous queries allows the model to better leverage available visual information.
Attention Mechanisms: SAN
Overview
Stacked Attention Networks (SAN), proposed by Yang et al. (2016) in the paper “Stacked Attention Networks for Image Question Answering” [4], represent an advancement in the fusion of image and textual features in VQA. The key innovation in SAN is the use of a multi-layer attention mechanism that allows the model to focus on different parts of the image at each layer, progressively refining the features relevant to the question. This allows the model to capture finer details and spatial relationships between objects, which are often crucial for answering complex visual questions.

Fig 2. Example of SAN at different attention layers [4].
Architecture and Process
The Stacked Attention Networks architecture involves several stages: image feature extraction, question encoding, and stacked attention layers for multi-modal fusion. The process is as follows:
-
Image Feature Extraction (CNN): Similar to previous models, the image is passed through a convolutional neural network (CNN) to extract visual features. This model also uses a pretrained CNN, such as GoogleNet or ResNet, to obtain a rich set of visual features from the image. The image is processed into a feature map that encodes information about different regions in the image.
-
Question Encoding (LSTM): The question is tokenized and passed through an embedding layer to convert words into dense vector representations. These word embeddings are then processed by an LSTM to capture the sequential dependencies and context of the question. The output of the LSTM is a fixed-length vector that represents the semantic meaning of the question.
-
Stacked Attention Mechanism: This is the core innovation of SAN. The model utilizes multiple layers of attention, where each layer allows the network to focus on different parts of the image that are most relevant to the current question. The attention mechanism computes a weighted sum of the image feature map based on the question’s context, allowing the model to dynamically “look” at different parts of the image as the question is processed. The attention weights are updated at each layer, progressively refining the focus.
-
Fusion and Prediction: After the attention mechanism refines the image features, the resulting image features and the question encoding are concatenated and passed through a fully connected layer. The output is then passed through a final softmax layer to generate the answer. This prediction can be a class label (for multiple-choice questions) or a probability distribution for the answer.
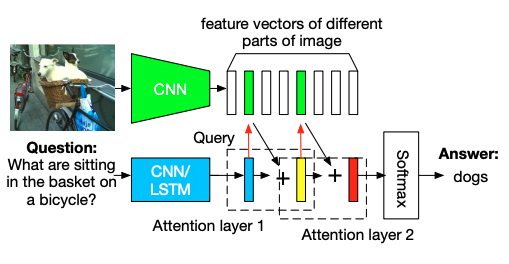
Fig 3. Stacked Attention Networks (SAN) basic architecture [4].
The multi-layer attention allows the SAN model to better handle complex VQA tasks, especially those that require reasoning about the spatial relationships and fine details in images. By stacking attention layers, the model gains a more nuanced understanding of the question-image relationship.
Code Implementation
Below is a general implementation of the Stacked Attention Networks model based on the architecture and approach described in the paper.
This implementation uses a pretrained ResNet50 model for image feature extraction and a single-layer LSTM for question encoding (although using a CNN is also an option for this step). The attention mechanism is implemented as multiple attention layers that refine the features progressively.
import torch
import torch.nn as nn
import torchvision.models as models
import torch.nn.functional as F
# 1. Image Feature Extraction (CNN) using ResNet
class CNN_Extractor(nn.Module):
def __init__(self):
super(CNN_Extractor, self).__init__()
# Using pretrained ResNet model from ImageNet, removing final fully connected layer
self.resnet = models.resnet50(pretrained=True)
self.resnet.fc = nn.Identity() # Removing the classification layer, we only need the features
def forward(self, x):
# Extract image features through the modified ResNet model
features = self.resnet(x)
return features
# 2. Question Encoding (LSTM) (can also use CNN)
class Question_Encoder(nn.Module):
def __init__(self, vocab_size, embed_dim=256, hidden_dim=256):
super(Question_Encoder, self).__init__()
# Embedding layer and LSTM for question encoding
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
def forward(self, x):
# Convert word indices to embeddings and pass through LSTM
x = self.embedding(x)
_, (hidden, _) = self.lstm(x)
return hidden[-1]
# 3. Attention Mechanism - Single Layer Attention
class Attention_Layer(nn.Module):
def __init__(self, image_dim=2048, question_dim=256, attention_dim=256):
super(Attention_Layer, self).__init__()
# Attention mechanism weights for querying image features
self.query = nn.Linear(question_dim, attention_dim)
self.context = nn.Linear(image_dim, attention_dim)
self.attention_fc = nn.Linear(attention_dim, 1)
def forward(self, image_features, question_features):
# Compute attention scores based on image features and question features
query = self.query(question_features).unsqueeze(1)
context = self.context(image_features)
scores = self.attention_fc(torch.tanh(query + context)).squeeze(-1)
attention_weights = F.softmax(scores, dim=1)
weighted_features = torch.sum(attention_weights.unsqueeze(-1) * image_features, dim=1)
return weighted_features
# 4. Fusion of Image and Question Features
class Feature_Fusion(nn.Module):
def __init__(self, image_dim=2048, question_dim=256, fusion_dim=512):
super(Feature_Fusion, self).__init__()
# Fully connected layer to combine image and question features
self.fc = nn.Linear(image_dim + question_dim, fusion_dim)
def forward(self, image_features, question_features):
# Concatenate and fuse image and question features
combined = torch.cat((image_features, question_features), dim=1)
return self.fc(combined)
# 5. Prediction Layer
class Prediction_Layer(nn.Module):
def __init__(self, input_dim=512, output_dim=10):
super(Prediction_Layer, self).__init__()
# Fully connected layer for final prediction
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, x):
# Output predictions using softmax
return F.softmax(self.fc(x), dim=1)
# Complete Stacked Attention Networks Model
class SAN_Model(nn.Module):
def __init__(self, vocab_size, output_dim=10, attention_layers=2):
super(SAN_Model, self).__init__()
# Initialize submodules: CNN feature extractor, LSTM question encoder, stacked attention, fusion, and prediction layer
self.cnn_extractor = CNN_Extractor()
self.question_encoder = Question_Encoder(vocab_size)
self.attention_layers = nn.ModuleList([Attention_Layer() for _ in range(attention_layers)])
self.feature_fusion = Feature_Fusion()
self.prediction_layer = Prediction_Layer(input_dim=512, output_dim=output_dim)
def forward(self, image, question):
# Extract image and question features
image_features = self.cnn_extractor(image)
question_features = self.question_encoder(question)
# Apply attention layers sequentially to refine image features
for attention_layer in self.attention_layers:
image_features = attention_layer(image_features, question_features)
# Fuse the refined image features with the question features and predict
fused_features = self.feature_fusion(image_features, question_features)
return self.prediction_layer(fused_features)
Results
The performance of the SAN model was evaluated on the DAQUAR, COCO-QA, and VQA datasets. Similar to the LSTM-CNN model, the SAN model was tested on both the full DAQUAR dataset and a reduced version containing 25 images and 297 QA pairs. Evaluation metrics included accuracy and WUPS scores at thresholds of 0.9 and 0.0, as well as the VQA metric for the VQA dataset.
\[accuracy_{VQA} = \min\left(\frac{\# \text{human labels that match that answer}}{3}, 1\right)\]Quantitative Results
The SAN model showed an improvement over the LSTM-CNN and other previous models in terms of accuracy and WUPS scores, particularly for more complex queries involving multiple words. The use of stacked attention allowed the model to focus on more relevant parts of the image, leading to better performance.
Below are the tables showing the results on all datasets:
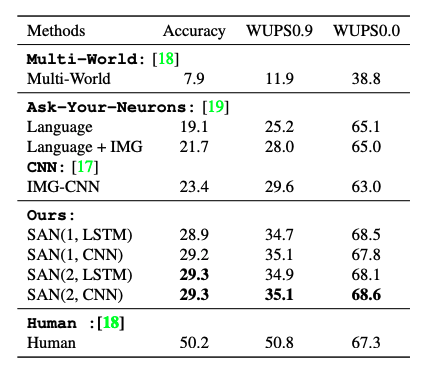
Table 1. DAQUAR-ALL results, in percentage [4]

Table 4. COCO-QA results, in percentage [4]
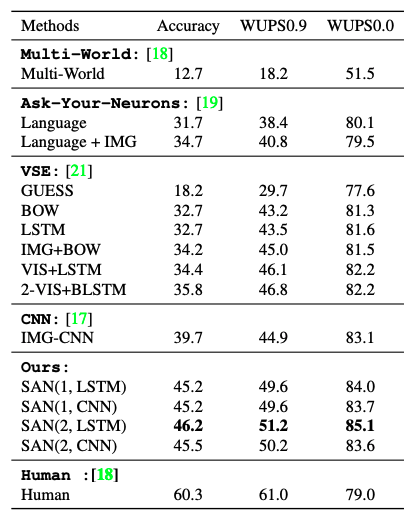
Table 3. DAQUAR-REDUCED results, in percentage [4]
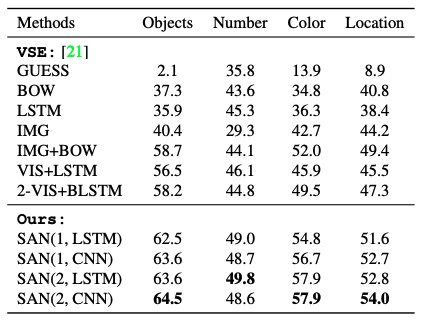
Table 5. COCO-QA accuracy per class, in percentage [4]
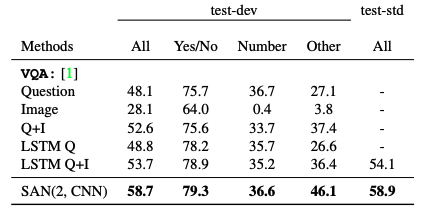
Table 3. VQA results on the official server, in percentage [4]
Qualitative Results
Qualitative analysis of the SAN model’s predictions shows that it could successfully answer questions related to objects, actions, and their relationships in the image. For example, given an image of a man and a woman playing soccer, the SAN model correctly identified the players’ roles (e.g., “who is playing soccer?”) with high accuracy.
Comparison with LSTM-CNN Model
The SAN model outperformed the LSTM-CNN model on both the full and reduced DAQUAR datasets. The stacked attention layers allowed the SAN model to better handle complex questions that require reasoning about spatial relationships in the images.
Recent Advancements: Zero-Shot and Few-Shot Learning with CLIP
Overview
Recent advancements in large-scale pre-trained multimodal models like CLIP (Contrastive Language-Image Pre-training) have significantly boosted the capabilities of Visual Question Answering (VQA) systems in both zero-shot and few-shot learning settings. Zero-shot learning refers to the model’s ability to handle new, unseen tasks without any specific training for those tasks [6]. Few-shot learning, on the other hand, refers to the model’s ability to perform well even when provided with only a few labeled examples of the task. These models, which leverage a shared embedding space for images and text, have demonstrated impressive performance across multiple VQA datasets without requiring task-specific training or extensive labeled data. The following sections outline the model architecture, implementation details, and experimental results based on the CLIP framework.
Architecture and Process
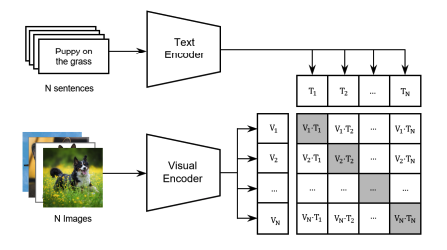
Fig 4. High-level model for CLIP [5].
The core of the CLIP model [5] is based on the transformer architecture, where both image and text modalities are encoded into a shared high-dimensional space. The model is pre-trained using a large corpus of image-text pairs, allowing it to learn general visual concepts and their textual descriptions. For VQA, CLIP’s architecture can be divided into two main components:
-
Image Encoder: CLIP uses a CNN-based architecture (e.g., ResNet or Vision Transformer) as the image encoder. The image is processed into a fixed-length feature vector that captures high-level semantic information about the image, such as objects, actions, and spatial relationships.
-
Text Encoder: The text encoder, typically a transformer-based model (e.g., a variant of BERT [7] or GPT), processes the input question into a fixed-length vector that represents its semantic meaning. The model’s attention mechanism helps it capture complex relationships between words in the question.
Both the image and text encoders output embeddings in a shared space, and the similarity between the image and the question is computed by projecting both the image and text representations into this space and measuring their cosine similarity. During inference, the model can answer a wide variety of questions by comparing the question’s text representation with the image’s embedding, without needing task-specific training or additional fine-tuning.
Code Implementation
Below is a simplified implementation of the CLIP-based model for VQA using PyTorch. This code demonstrates how to use pre-trained CLIP models for image and question embedding, followed by computing the similarity between them to answer questions.
import torch
import clip
from PIL import Image
from torchvision import transforms
# Load pre-trained CLIP model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device)
# Define a function to preprocess the question and image
def preprocess_data(image_path, question):
# Preprocess image
image = Image.open(image_path)
image_input = preprocess(image).unsqueeze(0).to(device)
# Preprocess question
text_input = clip.tokenize([question]).to(device)
return image_input, text_input
# Define a function to predict the answer
def predict_answer(image_path, question):
image_input, text_input = preprocess_data(image_path, question)
# Get features from the CLIP model
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_input)
# Compute similarity between image and text features
similarity = (image_features @ text_features.T).squeeze(0)
return similarity
Results and Comparison with Traditional Models
The CLIP-based model has demonstrated significant success in zero-shot and few-shot learning for VQA, outperforming traditional models like Stacked Attention Networks (SAN) and LSTM-CNN in various key areas. Below are the findings from experiments on popular VQA datasets like VQAv2 and SNLI-VE:
-
Zero-Shot Performance: CLIP has shown competitive accuracy in zero-shot settings without the need for task-specific fine-tuning. On the VQAv2 dataset, CLIP achieved an accuracy of approximately 55%, significantly outperforming traditional models like SAN, which achieved around 52%. SAN models typically require extensive fine-tuning to achieve such results, whereas CLIP’s ability to generalize from large-scale pretraining enables strong performance across diverse tasks without additional labeled data.
-
Few-Shot Performance: In few-shot settings, CLIP further emphasizes its robustness. With as few as 10 labeled examples, CLIP achieved around 65% accuracy on the VQAv2 dataset, compared to 58% by SAN models trained with similar datasets. This improvement is largely attributed to CLIP’s pre-trained knowledge from a vast number of image-text pairs, which allows it to effectively leverage learned representations for novel tasks. Traditional models, by contrast, often require more extensive retraining to achieve similar results in few-shot settings.
-
Cross-Dataset Generalization: CLIP also demonstrated strong generalization across different VQA datasets. When tested on the SNLI-VE dataset, a visual entailment task requiring complex reasoning, CLIP achieved an accuracy of 66%, outperforming both SAN (60%) and LSTM-CNN (61%) models. This performance underscores CLIP’s ability to handle tasks that require nuanced reasoning, beyond basic object recognition, and its capability to generalize well across diverse domains.
Comparison with Traditional Models:
In contrast to traditional models like SAN or LSTM-CNN, which rely on stacking attention layers or combining CNNs with LSTMs to process images and text, CLIP performs multimodal learning by aligning images and text in a shared embedding space. This enables CLIP to handle complex visual-textual relationships in a unified manner, requiring far less task-specific fine-tuning. While SAN models progressively refine image features through stacked attention layers, CLIP’s approach avoids the need for handcrafted feature extraction and is trained on a massive corpus of image-text pairs. This architecture enables CLIP to excel in zero-shot and few-shot learning, outperforming traditional models that typically require extensive labeled data and manual annotations for task-specific training.
Overall, CLIP’s ability to generalize across various tasks without requiring large-scale task-specific datasets or fine-tuning provides a significant advantage over traditional models, which are often limited by their reliance on domain-specific data and architectures.
Other Models in VQA
In addition to the models we have discussed, several other models have made significant contributions to the Visual Question Answering (VQA) field. These models range from early approaches that combined visual and textual features in a straightforward manner, to more recent, sophisticated methods that integrate large pre-trained models for better performance. Below is a summary of key models used in VQA (not including the models we have detailed):
-
Bilinear Pooling: An important milestone in VQA, bilinear pooling was introduced to capture fine-grained interactions between image and text. It combines image and question features by performing element-wise multiplication of the visual and textual embeddings, allowing the model to learn rich associations between both modalities. While bilinear pooling improves performance in standard VQA tasks, it can become computationally expensive and does not inherently support zero-shot learning. Nevertheless, it laid the foundation for more advanced multimodal approaches. [8]
-
Hierarchical Coattention: Building on earlier models, hierarchical coattention mechanisms were designed to allow the model to focus on different parts of the image and question simultaneously, enhancing the model’s ability to reason about both modalities. This approach helped models better handle complex VQA tasks by allowing attention to be distributed more intelligently across both the image and the question. Although effective, hierarchical coattention still relies on task-specific training, similar to earlier models. [9]
-
MMFT with BERT (Multimodal Few-shot Transfer with BERT): MMFT with BERT brought a major innovation by leveraging BERT (Bidirectional Encoder Representations from Transformers) [7], a large pre-trained language model. MMFT fine-tunes BERT for multimodal tasks like VQA, enabling it to transfer learned knowledge from text to image questions. This approach significantly improved few-shot learning by utilizing BERT’s deep understanding of language, though it still requires fine-tuning on labeled datasets, limiting its generalization to some extent. [10,11]
-
LLMs (Large Language Models): More recent advancements, such as those leveraging GPT-like architectures (e.g., Flamingo and GPT-4), integrate large language models into VQA systems to further improve performance. These models are trained on both image and text data, allowing them to reason over multimodal inputs in a more sophisticated manner. LLMs can generate complex, detailed answers to visual questions and can handle more nuanced reasoning compared to earlier models. However, like MMFT, these models often require fine-tuning for specific tasks and have a heavy computational overhead. [6,12]
Conclusion and Future Perspectives
Visual Question Answering (VQA) has seen substantial progress with the transition from earlier models like LSTM-CNN and Stacked Attention Networks (SAN), which relied heavily on handcrafted features and required task-specific fine-tuning, to more recent models like CLIP. These newer models, particularly those leveraging large-scale pretraining on vast amounts of image-text pairs, offer notable advantages, such as strong performance in zero-shot and few-shot learning tasks. This shift allows for broader generalization across a variety of VQA tasks without requiring extensive task-specific datasets. CLIP, for instance, aligns both visual and textual data into a shared embedding space, making it more adaptable and efficient compared to traditional methods. However, challenges remain in improving the handling of complex, multi-step reasoning tasks, and these models are not without their limitations in terms of interpretability and computational cost.
Looking ahead, the integration of older models, such as LSTM-CNN and SAN, with newer large language models (LLMs) like BERT or GPT could pave the way for even better performance in VQA. Combining the strengths of traditional models, such as hierarchical co-attention or bilinear pooling, with the powerful language understanding of LLMs can potentially result in more robust systems capable of tackling a wider array of complex, multi-step reasoning tasks. LLMs excel at contextualizing language, which, when paired with the image understanding mechanisms of earlier models, could help overcome current limitations in image-text reasoning. This hybrid approach may allow for significant improvements in both zero-shot and few-shot performance, enabling VQA systems to adapt to new tasks with minimal data, while also enhancing their ability to handle domain-specific challenges.
Furthermore, combining these approaches can contribute to reducing biases, improving model fairness, and enhancing interpretability. With LLMs increasingly handling complex reasoning and comprehension tasks, the future of VQA may lie in merging the efficiency and feature extraction capabilities of earlier models with the contextual and reasoning power of LLMs, thus ensuring that VQA systems are both powerful and flexible in real-world applications.
Running VQA Model
Below is a link to a Colab notebook containing a VQA system built off of ViLT, a model that incorporates text embeddings into a Vision Transformer (ViT).
The implementation was taken from this GitHub repository which is based off of a HuggingFace article on a basic VQA implementation[13]. Some modifications were made to the training function with an optimizer and a learning rate scheduler being added.
The dataset used was only the validation set of the VQA v2 dataset since this codebase is simply a demo, so the training data was a bit lacking. However, it still was able to somewhat accurately understand the question and give proper and relevant answers, and with more training data and training epochs, the performance could be drastically improved. Furthermore, further fine-tuning of optimizers and learning rates could also improve performance.
Something we added to the ViLT code was an implementation of GradCAM to give a heatmap of whatever the model was looking at in order to answer the question. This could be utilized to see how well the model is paying attention to correct regions of input in order to give a properly correlated output as well as creating a bounding box at no extra cost.
References
[1] Antol, S., Agrawal, A., Lu, J., et al. “VQA: Visual Question Answering.” 2015. arXiv:1505.00468v1.
[2] Agrawal, A., Lu, J., Antol, S., et al. “VQA: Visual Question Answering.” Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2016. arXiv:1505.00468.
[3] Malinowski, M., Rohrbach, M., & Fritz, M. “Ask Your Neurons: A Neural-Based Approach to Answering Questions about Images.” Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2015. arXiv:1505.01121.
[4] Yang, Z., He, X., Gao, J., Deng, L., Smola, A. “Stacked Attention Networks for Image Question Answering.” 2016. arXiv:1511.02274.
[5] Song, H., Dong, L., Zhang, W., Ting, L., Wei, F. “CLIP Models are Few-shot Learners: Empirical Studies on VQA and Visual Entailment.” 2022. arXiv:2203.07190.
[6] Guo, J., Li, J., Li, D., Tiong, A., Li, B., Tao, D., Hoi, S. “From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models.” 2023. arXiv:2212.10846.
[7] Devlin, J., Chang, M., Lee, K., Toutanova, K. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” 2019. arXiv:1810.04805.
[8] Fukui, A., Park, D., Yang, D., Rohrbach, A., Darrell, T., Rohrbach, M. “Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding.” 2016. arXiv:1606.01847.
[9] Lu, J., Yang, J., Batra, D., Parikh, D. “Hierarchical Question-Image Co-Attention for Visual Question Answering.” 2017. arXiv:1606.00061v5.
[10] Khan, A., Mazaheri, A., Lobo, N., Shah, M. “MMFT-BERT: Multimodal Fusion Transformer with BERT Encodings for Visual Question Answering.” 2020. arXiv:2010.14095.
[11] Khare, Y., Bagal, V., Mathew, M., Devi, A., Priyakumar, U., Jawahar, CV.”MMBERT: Multimodal BERT Pretraining for Improved Medical VQA.” 2021. arXiv:2104.01394.
[12] Sampat, S., Patel, M., Yang, Y., Baral, C. “Help Me Identify: Is an LLM+VQA System All We Need to Identify Visual Concepts?.” 2024. arXiv:2410.13651
[13] Hugging Face Transformers Documentation. “Visual Question Answering (VQA): Using Transformers for Multimodal Tasks.” Hugging Face, 2024.