Team49 Linguistic binding in diffusion models
This project explores the improvement of text-to-image diffusion models, focusing on the problem of language binding in stable diffusion models. Text-to-image generation usually suffers from attribute misbinding, omissions, and semantic leakage, which can lead to inaccurate visual representations between textual prompts and generated images. Based on the SynGen method, our team proposes a new loss function by introducing an extra entropy term. During the denoising process, this entropy term aims to refine the attention graph to make the relationship between modifiers and their corresponding entities more accurate. This method achieves an improvement in the correspondence of attributes in the generated image compared to the Syngen method.
Introduction
After introducing the basic diffusion model and its role in text-to-image generation, we now turn our focus to the stable diffusion model[1]. Stable Diffusion (SD) is currently one of the most influential generative models, which utilizes the Latent Diffusion Model (LDM), which significantly reduces the computational complexity while maintaining high-quality image generation performance by relocating the diffusion process from the pixel space to the latent space. This Latent Diffusion Model (LDM) avoids the high computational cost common to pixel-level diffusion models by extracting the latent features of the image with the help of a pre-trained Variable Auto-Encoder (VAE) and executing the diffusion process in the latent space. Here, the training objective of Stable Diffusion is:
\[L_{\text{LDM}} = \mathbb{E}_{z, \epsilon \sim \mathcal{N}(0, 1), t} \left[ \| \epsilon - \epsilon_\theta(z_t, t, c) \|^2 \right]\]where z_t denotes the latent representation of the image at time-step t, and c is the conditioning information (e.g., text embeddings).
In addition, Stable Diffusion introduces a cross-attention mechanism that aligns the text-encoded embeddings (derived from a CLIP text encoder) with the latent features in the generation process, enabling it to perform well in text-to-image generation tasks.
While this approach enables effective text-to-image generation, the text encoder’s limited grasp of syntactic structure often leads to incorrect associations between the nouns and their modifiers known as the “linguistic binding.” This problem caused the stable diffusion to semantic confusion such as attribute misassignment, semantic leakage, and entity neglect.
We can now begin to look specifically at the inaccurate binding of modifiers to entities that often occurs when Stable Diffusion processes complex text prompts. For example, for the cue ‘a pink sunflower and a yellow flamingo’, the generated result can incorrectly produce a yellow sunflower and a pink flamingo. This semantic binding inaccuracy is called Attribute Misbinding.

Fig 1. Here we showed the results of the stable diffusion, where it sometimes didn’t generate correctly. [2].
To address problems like these, SynGen[2] proposes 3 novel methods such as: (1) Syntactic Parsing of the Prompt, (2) Extraction of Cross-Attention Maps, (3) Language-Driven Cross-Attention Losses, and (4) Generating process interventions.
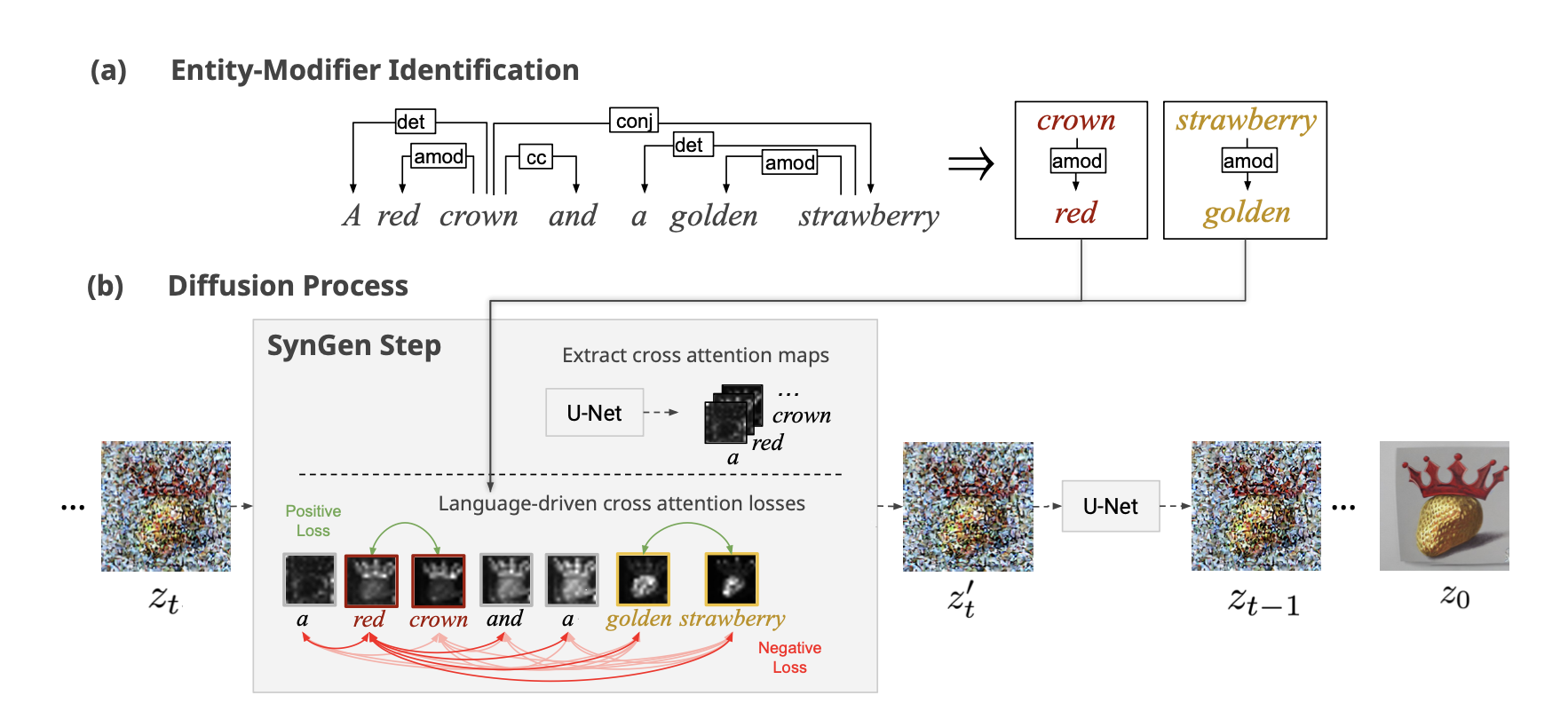
Fig 2. Flow chart of SynGen [2].
Methodology
First, they use a dependency grammar parser named spaCy to extract grammatical relations between noun entities and their modifiers from textual cues. For example, the pairs of modifier relations (“red”, “crown”) and (“golden”, “strawberry”) are extracted from the sentence ‘a red crown and a golden strawberry’. The modifier-noun relations are then explicitly described by syntactic tags (e.g. amod, nmod) and used as semantic binding constraints in the generation process, guiding the model to associate the correct attributes with the correct entities.
Second, SynGen operates on the cross-attention maps produced during the diffusion process. Each timestep of the diffusion denoising (conducted by the U-Net architecture) involves cross-attention layers that map tokens in the prompt to spatial latent features. The attention weights from these layers form a 2D score matrix for each token, indicating how strongly each token attends to different spatial regions of the latent representation.
To obtain a distribution over spatial patches per token, SynGen normalizes the raw attention weights row-wise, transforming them into probability distributions over patches. In other words, for each token, the normalized attention map indicates how the model’s generation process “assigns” visual concepts to particular latent regions.
Third, using the language structured found in the first step. SynGen introduces two types of cross-attention losses to optimize the distribution of attention for modifiers and related nouns to guide the latent updates, respectively.
- Positive loss : Encourage overlapping cross-attention maps of modifiers with their associated nouns with the formula.
- Negative loss: Suppressing Cross-attention Map Overlap Between Modifiers and Irrelevant Words
Finally, the final loss combines the two loss terms: \(L = L_{\text{pos}} + L_{\text{neg}}\)
Fourth, finally, SynGen adjusts the cross-attention graph by updating latent variables in gradients during the first 25 steps of the diffusion process, thus ensuring that the semantic bindings in the generated images conform to the syntactic structure.
SynGen was evaluated on multiple benchmark datasets (ABC-6K, DVMP, and Attend-and-Excite datasets), and its performance was validated through human evaluations. The experimental results show that SynGen improves the property binding accuracy benchmark when compared to the other existing methods, such as (1)Stable Diffusion, (2) Attend-and-Excite, and (3) Structured Diffusion significantly, which has proven their success in reducing property misalignment (Improper Binding) and entity Neglect (Entity Neglect).
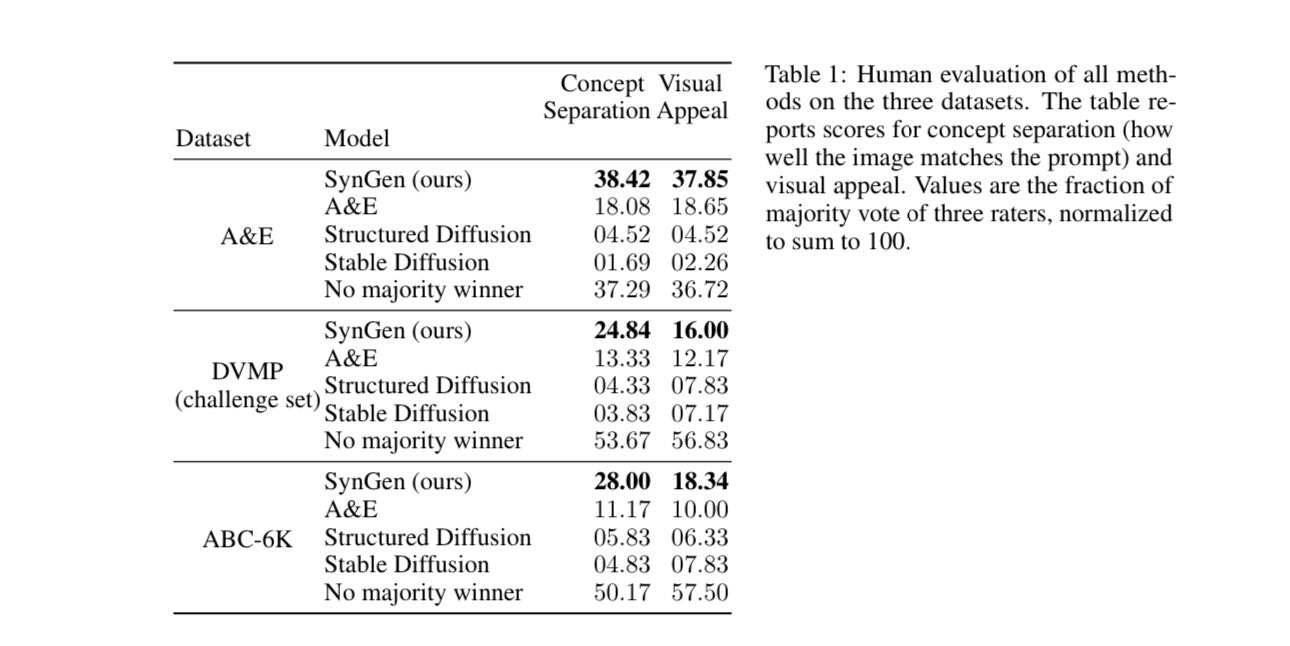
Fig 3. Linguistic Binding in Diffusion Models human evalutaion result, when comparing multiple datasets. [2].
Additionally, here are some visual comparisons:

Fig 4. SynGen, visual results. [2].

Fig 5. SynGen, visual results. [2].
Related Existing Literature
Atted and Excite[3]
Attend-and-Excite (A&E) is a recently proposed inference-time technique that aims to address a specific semantic failure mode in text-to-image diffusion models known as catastrophic neglect. This failure occurs when a model fails to generate one or more of the subjects mentioned in a prompt. To overcome this, A&E intervenes during the generation process, modifying the latent representation to ensure each subject token is attended to by at least one patch in the image.
A&E’s key idea is to define a loss function that encourages each subject’s cross-attention map to have a sufficiently large maximum activation. Formally, for each subject token, A&E computes the maximum value of its spatial attention map and constructs a loss that penalizes low maxima. By iteratively adjusting the latent variable to minimize this loss, the model pay more attention to neglected tokens. Through this, A&E implicitly improves attribute binding since attributes and subjects are encoded together in the text embeddings.
In contrast, SynGen takes this concept further by parsing the syntactic structure of the prompt. It introduces specific attention-based loss functions designed not only to combat neglect but also to ensure proper binding of attributes to their respective entities.
A-Star[4]
Similarily, A-STAR is a test-time optimization method designed to improve semantic fidelity, the meaning of each words, in text-to-image diffusion models. Existing models, such as Stable Diffusion, often fail to accurately depict all concepts described in a prompt, frequently omitting certain subjects or misaligning attributes. Through a detailed analysis of cross-attention maps, A-STAR identifies two key issues. First, multiple concepts often overlap spatially in the attention maps, causing confusion and forcing the model to focus on only one. Second, even when all concepts are initially detected in early denoising steps, the model fails to retain this knowledge through to the final stages of generation, resulting in lost or neglected elements in the final image.
To address these problems, A-STAR introduces two new loss terms applied during inference time. The attention segregation loss reduces spatial overlap between attention maps of different concepts, ensuring that each subject is assigned distinct, non-overlapping regions in the latent representation. The attention retention loss preserves crucial information about each concept across all denoising steps, preventing knowledge decay. Together, these loss functions steer the diffusion process so that every concept remains visually and semantically distinct.
Evaluations show that A-STAR significantly outperforms baselines and prior approaches, including Attend-and-Excite. By applying these losses at test time without retraining the base model, A-STAR can generates images that better match the full semantic content of the input prompt most of the time.
StructureDiffusion[5]
Additionally, a new method named StructureDiffusion, paper tackle the challenge of accurate compositional image synthesis and attribute binding. While large-scale diffusion models like Stable Diffusion can generate high-quality images, they often struggle when prompts involve multiple objects and their associated attributes, leading to misaligned colors, attributes, or even missing entities. To address these, this paper propose Training-Free Structured Diffusion Guidance, a method that integrates linguistic structures from parsed sentences into the diffusion process itself, thereby improving the compositional fidelity of generated images without requiring additional training data.
Their approach leverages off-the-shelf language parsers to extract structured representations (e.g., constituency trees, scene graphs) from the input text. By aligning these linguistic components with the cross-attention maps in the diffusion model, the system isolates and preserves attribute-object pairs. Crucially, this structured guidance does not necessitate re-training the diffusion model. Instead, it manipulates existing cross-attention layers, reshaping how textual tokens influence spatial image features. As a result, the model’s outputs exhibit more accurate attribute binding, better handling complex prompts.
While the authors do not introduce a new loss function specific to their structured guidance approach, their method operates on top of the standard diffusion training objective already established in Stable Diffusion. Their key innovation is that by integrating structured textual insights directly into the inference process, the model’s compositional understanding is enhanced, improving text-image alignment and maintaining overall image quality.
Implementation
We decided to implement SynGen by downloading and running their code from Github. We run the syngen_notebook.ipynb, which contains their code and methodology, locally on our laptop using the GPU 4060 after all the necessary installation using Anaconda. From the code, we see that they include methods like calculate_positive_loss, calculate_negative_loss, and _calculate_losses to calculate their positive, negative, and final loss in code:
def calculate_positive_loss(attention_maps, modifier, noun):
# Get attention maps for the modifier and noun
modifier_attention = attention_maps[modifier]
noun_attention = attention_maps[noun]
# Compute overlap using dot product (or cosine similarity)
overlap = torch.sum(modifier_attention * noun_attention)
# Loss is the negative overlap (to maximize alignment)
loss = -overlap
return loss
def calculate_negative_loss(attention_maps, modifier, noun, subtree_indices, attn_map_idx_to_wp):
# Get attention maps for the modifier
modifier_attention = attention_maps[modifier]
# Sum the attention maps of all unrelated nouns
unrelated_nouns = [idx for idx in attn_map_idx_to_wp if idx not in subtree_indices]
unrelated_attention = sum(attention_maps[idx] for idx in unrelated_nouns)
# Compute overlap using dot product (or cosine similarity)
overlap = torch.sum(modifier_attention * unrelated_attention)
# Loss is the overlap (to minimize it)
loss = overlap
return loss
def _calculate_losses(self, attention_maps, all_subtree_pairs, subtree_indices, attn_map_idx_to_wp):
positive_loss_list = []
negative_loss_list = []
for (noun, modifier) in all_subtree_pairs:
positive_loss_list.append(
calculate_positive_loss(attention_maps, modifier, noun)
)
negative_loss_list.append(
calculate_negative_loss(attention_maps, modifier, noun, subtree_indices, attn_map_idx_to_wp)
)
return sum(positive_loss_list), sum(negative_loss_list)
Additionally, to make sure that we actually implemented the SynGen code, we run multiple different prompts that are not discussed in their paper. Below, we showed our results with these different prompt. Below, we shared our results.

Fig 6. Linguistic Binding in Diffusion Models: Enhancing Attribute Correspondence through Attention Map Alignment [2].
Our Own Ideas
To further enhance the semantic alignment between modifiers and their corresponding nouns, from SynGen, we introduce an additional Shannon entropy[6] term into our loss function. The intuition behind incorporating the idea of entropy in two aspects. First, for syntactically related words—such as a modifier-noun pair—we want their attention maps to be similar and more concentrated, thereby reducing semantic ambiguity. Second, when considering pairs of related words and unrelated words, we wish to enforce dissimilarity in their attention maps, effectively encouraging more diffuse, less focused attention distributions for the unrelated terms.
The entropy (H(A)) of an attention map (A) is defined as:
\[H(A) = -\sum_{i=1}^{n} A_i \log A_i,\]where ( A_i ) represents the normalized attention probability for the ( i )-th element in the attention distribution ( A ), and (n) is the total number of elements in the distribution.
Here, we define the new positive loss term as:
\[L_{\text{pos}}(A, S) = \sum_{i=1}^k \sum_{(m,n) \in P(S_i)} \bigl(\text{dist}(A_m, A_n) + \lambda_{\text{entropy}}\bigl(H(A_m) + H(A_n)\bigr)\bigr),\]The negative loss, which applies to unrelated sets which defined as:
\[L_{\text{neg}} = -\sum_{i=1}^k \frac{1}{|U(S_i)|} \sum_{(m,n) \in P(S_i)} \sum_{u \in U(S_i)} \frac{1}{2}\bigl(\text{dist}(A_m, A_u) + \text{dist}(A_u, A_n) - \gamma_{\text{entropy}}H(A_u)\bigr).\]Combining both terms yields the final loss:
\[L = L_{\text{pos}} + L_{\text{neg}}.\]Below, we present images demonstrating the improved results achieved using this enhanced loss function when using the same seed, when comparing against the original.

Reference
[1] Rombach, Blattmann, et al. “High-Resolution Image Synthesis with Latent Diffusion Models” Computer Vision and Pattern Recognition. 2021
[2] Rassin, Hirsch, et al. “Linguistic Binding in Diffusion Models: Enhancing Attribute Correspondence through Attention Map Alignment” Advances in Neural Information Processing Systems. 2023
[3] Chefer, Alaluf, et al. “Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models” Computer Vision and Pattern Recognition. 2023.
[4] Agarwal, Karanam, et al. “A-STAR: Test-time Attention Segregation and Retention for Text-to-image Synthesis” Computer Vision and Pattern Recognition. 2023.
[5] Feng, He, et al. “Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis” Computer Vision and Pattern Recognition. 2023.
[6] Shannon Entropy: https://www.sciencedirect.com/topics/engineering/shannon-entropy