Controlling Images with Diffusion Models
Image Diffusion models generate novel images by starting from pure noise and gradually denoising. This process is inherently random and much work has been put in to controlling the generation of image diffusion models. We will discuss three papers that introduced innovative methods to control the generation process beyond standard text-guided generation: InstructPix2Pix, DreamBooth and ControlNet.
Introduction
Text-guided generation models, such as Stable Diffusion, can produce novel images conditioned on text but lack the ability to edit existing images. InstructPix2Pix addresses this limitation by enabling Stable Diffusion to edit images guided by human instructions. However, if the goal is to preserve the presence of an object while placing it in novel contexts, DreamBooth provides a solution by allowing you to provide reference images of the object and generate images where the object appears in various contexts guided by text. ControlNet is similar in the sense that it also accepts a reference, but it is primarily designed for novel generation. ControlNet takes a reference image as control and uses it to guide the generation alongside text.
InstructPix2Pix
InstructPix2Pix proposed a method for editing images through human instruction. The method involves creating a synthetic dataset using a fine-tuned GPT-3 and Stable-Diffusion consisting of a edit instruction, original image, and edited image. Despite being trained entirely on synthetic data, their model generalizes well to real images and human instruction.
Dataset Generation
The dataset was generated using a fine-tuned GPT-3 model, which was trained to take an input caption and output an edit instruction along with a corresponding edited caption. These captions were then used to generate images with Stable Diffusion. To ensure that the generated images were spatially and structurally similar—so that the concept of “editing” remained meaningful—the authors used prompt-to-prompt [1] to create the samples. The resulting dataset for the instruction-following Diffusion Model consisted of the instructions generated by GPT-3 and the paired images.

Fig 1. Pix2Pix dataset creation pipeline [1].
Training Pix2Pix
Using the generated dataset, a Stable Diffusion checkpoint is fine-tuned to minimize the mean squared error between the latent noise and the predicted noise at each time step, conditioned on the latent representation of the original unedited image, \(E(c_I)\), and the edit instruction, \(c_T\).
\[L = \mathbb{E}_{\mathcal{E}(x), \mathcal{E}(c_I), c_T, \epsilon \sim \mathcal{N}(0, 1), t} \left[ \left\| \epsilon - \epsilon_\theta\left(z_t, t, \mathcal{E}(c_I), c_T\right) \right\|_2^2 \right]\]Classifier-free Guidance
Standard Classifier-free Guidance in Stable Diffusion is a technique to give the ability to control how strongly the model adheres to the text conditioning in the generation process. In InstructPix2Pix, Classifier-free Guidance is modified to give the ability to control the strength of the conditioning of both \(c_I\) and \(c_T\).
\[L = \mathbb{E}{\mathcal{E}(x), \mathcal{E}(c_I), c_T, \epsilon \sim \mathcal{N}(0, 1), t} \left[ \left| \epsilon - \epsilon\theta\left(z_t, t, \mathcal{E}(c_I), c_T\right) \right|_2^2 \right]\]The strength of \(s_I\) denotes how strongly the model should adhere to the image conditioning, \(c_I\), relative to unconditioned generation, while the strength of $s_T$ indicates how strongly the model should adhere to the text conditioning, \(c_T\), relative to image-conditioned generation. According to the authors, this formulation of Classifier-Free Guidance is one of many possible formulations. This specific formulation worked well in practice.

Fig 2. Classifier free guidance with varying `s` as guidance weights [2].
Dreambooth
DreamBooth is a method for training text-to-image diffusion models that enables subject-driven generation in varied contexts with high fidelity. The method involves fine-tuning a model to learn a binding between the subject and a unique token assigned to it with only 3 to 5 input examples of the subject.
Fine Tuning
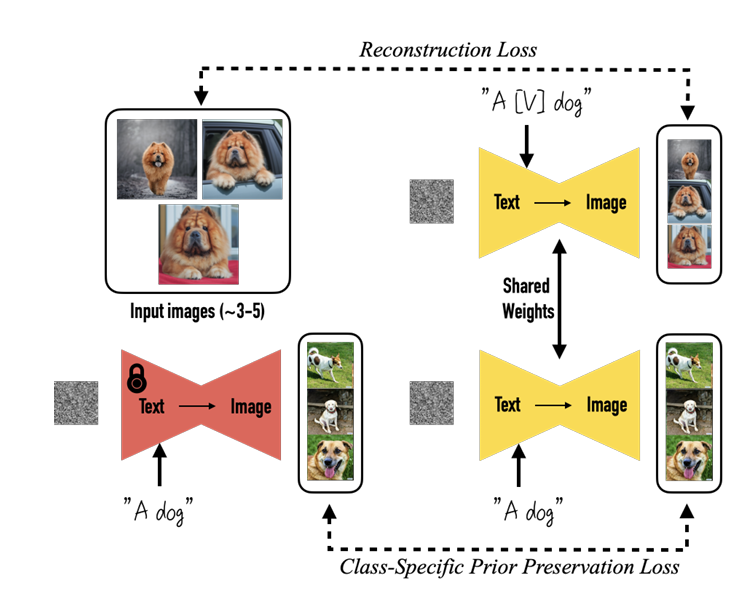
Fig 3. fine-tuning pipeline
The fine-tuning involves preserving a locked copy of the original model and feeding it a class-based prompt (e.g., “A dog”) without the unique identifier. The same prompt is sent to an unlocked copy of the model, and a prior-preservation loss is calculated based on the difference between these two outputs. The unlocked copy shares the same weights as the model being trained, which is optimized to reconstruct the original input images.
\[\mathbb{E}{\mathbf{x}, \mathbf{c}, \boldsymbol{\epsilon}, \boldsymbol{\epsilon}', t} \left[ w_t \left| \hat{\mathbf{x}}\theta (\alpha_t \mathbf{x} + \sigma_t \boldsymbol{\epsilon}, \mathbf{c}) - \mathbf{x} \right|2^2 + \lambda w{t'} \left| \hat{\mathbf{x}}\theta (\alpha{t'} \mathbf{x}{\text{pr}} + \sigma{t'} \boldsymbol{\epsilon}', \mathbf{c}{\text{pr}}) - \mathbf{x}{\text{pr}} \right|_2^2 \right]\]The prior-preservation loss is necessary because, without it, the model begins associating the subject of the class with the class itself and overfits to the subject images.

Fig 4. Impact of prior-perserving loss[2].
ControlNet
ControlNet is a neural network architecture designed to enhance large pretrained text-to-image diffusion models through spatial conditioning. Formally, let \(x\) be an input feature map from the pretrained model and \(c\) be a task-specific conditioning input (e.g., edge map, depth, or pose), ControlNet introduces a trainable neural block \(F(x, c; heta)\), where \(heta\) represents learnable parameters, while preserving the pretrained model’s weights through a frozen parallel path. The two branches are fused via zero-initialized convolutional layers \(Z(x; heta_z)\), ensuring no interference at initialization:
This formulation allows task-specific adaptations while retaining the pretrained model’s robust feature extraction capabilities.
Neural Architecture
ControlNet builds upon the foundational U-Net architecture, widely used in diffusion models like Stable Diffusion, by incorporating trainable copies of the encoder blocks. These added blocks handle conditioning inputs such as edge maps or pose skeletons, while the original encoder preserves the pre-trained model’s ability to extract robust features.
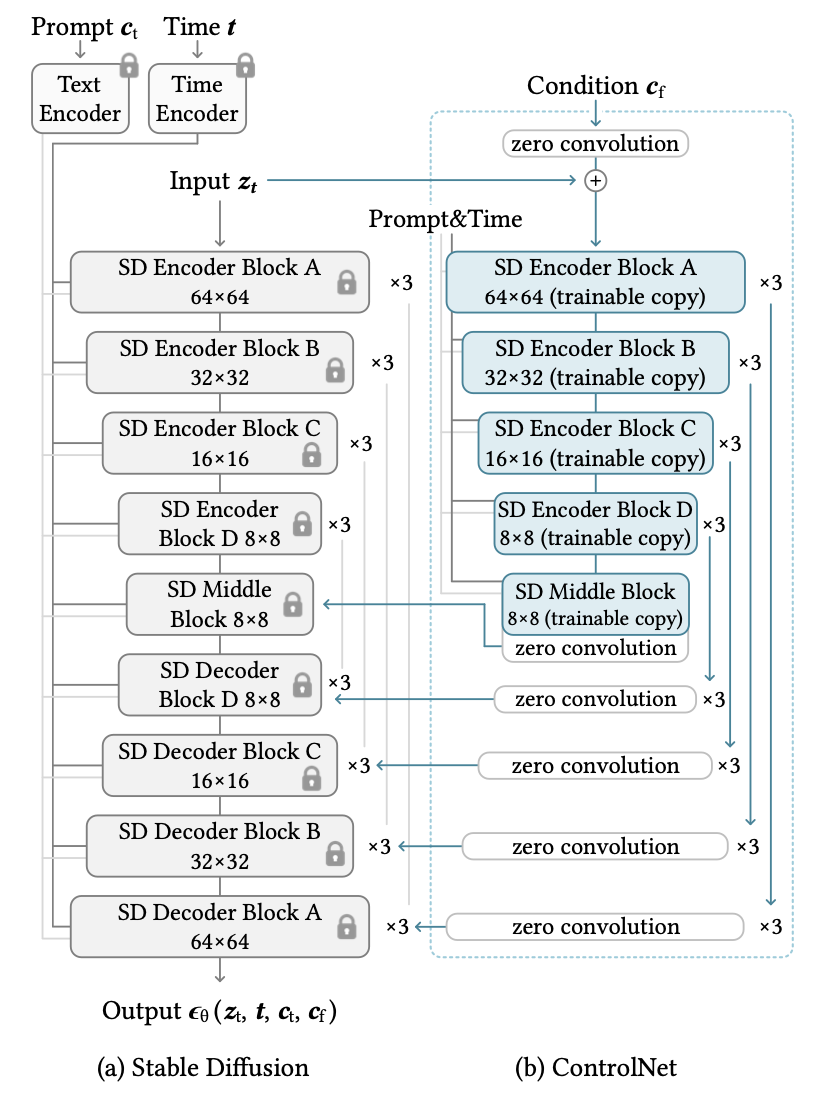
Fig 5. ControlNet Architecture [3].
However, what sets ControlNet apart is its design innovations:
-
Stacking Controls: ControlNet supports combining multiple conditioning inputs, such as an edge map and a pose skeleton, to produce highly controlled and detailed outputs.
-
1x1 Kernels: Using 1x1 kernels in Zero Convolution layers ensures efficient channel transformations without altering spatial features, maintaining the integrity of the input.
-
Custom Conditioning: ControlNet offers the flexibility to tailor task-specific conditioning setups, whether it’s for depth-to-image translation or sketch-based generation.
To ensure stability during training, ControlNet integrates Zero Convolution layers, which initialize all weights to zero.
A common question about Zero Convolutions is: If the weight of a convolutional layer is zero, won’t the gradient also be zero, preventing the network from learning anything?
This is a misconception. Consider a simple linear equation:
\[y = wx + b\]Here, the gradients are computed as:
\[\frac{\partial y}{\partial w} = x, \quad \frac{\partial y}{\partial x} = w, \quad \frac{\partial y}{\partial b} = 1\]If \(w = 0\) and \(x \neq 0\), then:
\[\frac{\partial y}{\partial w} \neq 0, \quad \frac{\partial y}{\partial x} = 0, \quad \frac{\partial y}{\partial b} \neq 0\]This means that, as long as \(x \neq 0\), one gradient descent iteration will make \(w\) non-zero. Once \(w\) is updated, we have:
\[\frac{\partial y}{\partial x} \neq 0\]This ensures that Zero Convolutions will progressively become standard convolutional layers with non-zero weights, allowing the network to learn effectively while maintaining initial stability.

Fig 6. Zero Convolution's Stability [3].
Below is an implementation example that illustrates how these elements interact within ControlNet:
import torch
import torch.nn as nn
# Zero Convolution Layer: Ensures stability by initializing weights to zero.
class ZeroConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(ZeroConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
nn.init.zeros_(self.conv.weight) # Initialize weights to zero
nn.init.zeros_(self.conv.bias) # Initialize bias to zero
def forward(self, x):
return self.conv(x)
# Control Block: Handles both feature maps and conditioning inputs, integrating them via zero convolutions.
class ControlBlock(nn.Module):
def __init__(self, in_channels, condition_channels, out_channels):
super(ControlBlock, self).__init__()
self.encoder_layer = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.condition_layer = nn.Conv2d(condition_channels, out_channels, kernel_size=3, padding=1)
self.zero_conv = ZeroConv2d(out_channels, out_channels, kernel_size=1, stride=1, padding=0) # 1x1 kernel
def forward(self, x, conditioning):
# Encode features and conditioning inputs separately
encoded_features = self.encoder_layer(x)
conditioned_features = self.condition_layer(conditioning)
# Combine feature maps (Stacking Controls)
combined = encoded_features + conditioned_features
# Apply zero convolution for efficient channel transformations
return self.zero_conv(combined)
# ControlNet: Processes multiple conditioning inputs (e.g., edge maps, poses) through separate branches.
class ControlNet(nn.Module):
def __init__(self, in_channels, out_channels, num_controls):
super(ControlNet, self).__init__()
self.control_blocks = nn.ModuleList([ControlBlock(in_channels, in_channels, out_channels) for _ in range(num_controls)])
def forward(self, x, controls):
# Process each control input through its corresponding ControlBlock
for control, block in zip(controls, self.control_blocks):
x = x + block(x, control) # Stacking Controls across inputs
return x
This implementation is inspired by the official ControlNet GitHub repository.
Training ControlNet
Training ControlNet involves learning from paired input-output examples. The loss function used is: \(L = E_{z_0, t, c_t, c_f, \epsilon \sim N(0,1)} \left[\| \epsilon - \epsilon_\theta(z_t, t, c_t, c_f)\|^2_2 \right]\)
Where:
- \(z_t\): Noisy latent representation of the image at timestep ( t ).
- \(c_t\): Text prompt embedding that guides the diffusion process.
- \(c_f\): Conditioning input (e.g., depth maps, edge maps, pose skeletons).
- \(\epsilon\): Gaussian noise sampled from a normal distribution.
This function measures the difference between the predicted noise \(\epsilon_\theta\) and the actual noise \(\epsilon\), guiding the model to iteratively denoise and reconstruct the image during the reverse diffusion process.
Classifier-Free Guidance in ControlNet
ControlNet extends Classifier-Free Guidance to balance the influence of text prompts \(c_T\) and conditioning inputs \(c_I\), such as edge maps or depth. This ensures that generated images adhere to both spatial and semantic constraints, providing fine-grained control for diverse applications.
Conclusion
ControlNet, DreamBooth, and InstructPix2Pix each address specific limitations of text-guided image generation. InstructPix2Pix excels at image editing based on text prompts but struggles with precise spatial control, while DreamBooth specializes in fine-tuning models to generate personalized outputs but lacks flexibility for spatial conditioning. ControlNet combines the advantages of both, providing robust spatial control and the ability to adapt to diverse tasks, all while maintaining stability and efficiency. Our investigation demonstrates that with the appropriate dataset, ControlNet can achieve the functionality of both DreamBooth and InstructPix2Pix, making it a versatile and powerful solution for conditional image generation.
Reference
[1] Brooks, T., Holynski, A., & Efros, A. A. (2023). Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18392-18402).
[2] Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., & Aberman, K. (2022). DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. ArXiv. https://arxiv.org/abs/2208.12242
[3] Zhang, L., Rao, A., & Agrawala, M. (2023). Adding Conditional Control to Text-to-Image Diffusion Models. ArXiv. https://arxiv.org/abs/2302.05543
[4] Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., & Pritch, Y. (2022). Prompt-to-Prompt Image Editing with Cross Attention Control. ArXiv. https://arxiv.org/abs/2208.01626