Panoptic Segmentation – From Foundational Tasks to Modern Advances
In this post, I will discuss recent advancements in image segmentation, including panoptic segmentation.
Background
Segmentation and its Applications
Segmentation is a broad category of computer vision tasks. At its core, it involves breaking up an image into meaningful parts or “segments” so that further analysis can be done. For instance, we might want to segment an image so that we can then assign labels to each of the parts, or draw precise boundaries around them to keep track of the exact location of an object in the scene. The real-world applications of image segmentation are vast:
- Autonomous vehicles need to be able to identify the presence of obstacles and recognize lane markings, signs, and traffic signals. In addition to identifying these things, an autonomous vehicle must also be able to distinguish between different types of objects – another car on the road should be treated differently from a pedestrian.
- In medical imaging, image segmentation allows medical professionals to identify and outline tumors, organ tissue, etc.
- In robotics, it’s important for an agent to be able to identify objects in it’s surroundings so that it can interact with them appropriately.
“Things” versus “Stuff”
To understand image segmentation, let us first take a step back and look at computer vision tasks more broadly. Computer vision tasks can largely be broken down into the study of “things” and the study of “stuff”. A “thing” can be defined as an object with a specific shape and size. “Things” are countable objects such as people, animals, cars, etc. “Stuff”, on the other hand, can be defined as amorphous masses of material, such as the sky, water, grass, road, etc. Unlike things, stuff is uncountable.
Semantic Segmentation and Instance Segmentation
Now let us discuss two visual recognition tasks that represent different fundamental approaches to image segmentation – Semantic Segmentation and Instance Segmentation. This will set the stage for our discussion of Panoptic Segmentation, and more recent advances in image segmentation at large.
Semantic Segmentation
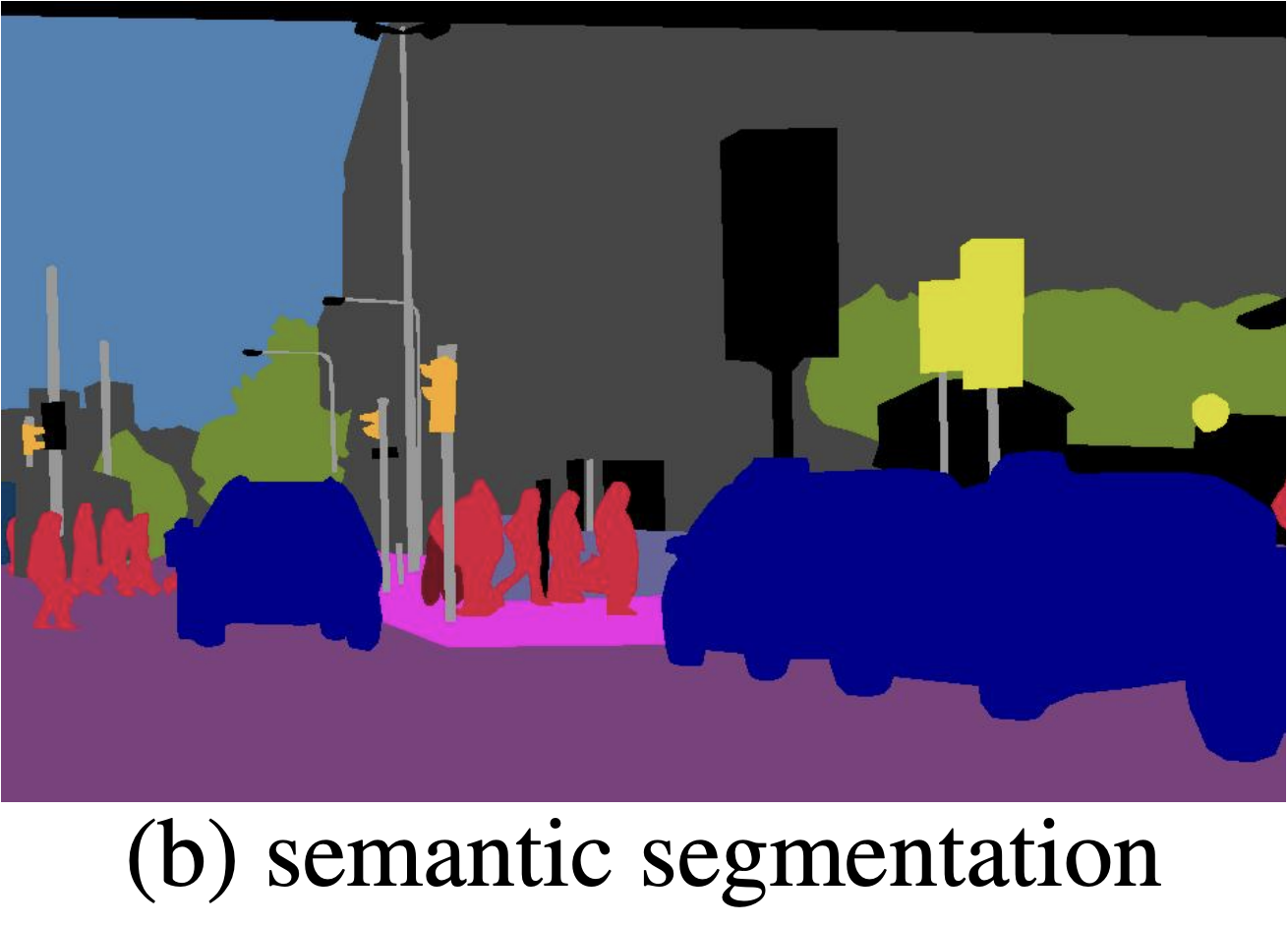
Semantic segmentation is a visual recognition task that falls under the study of “stuff”. In semantic segmentation, we aim to cluster parts of an image together that belong to the same class. Given an input image, we attempt to assign a class label to each pixel (such as car, person, sky, etc.). We do not distinguish between different instances of an object. Notice how in the image, all of the cars are treated as a single amorphous mass.
Instance Segmentation
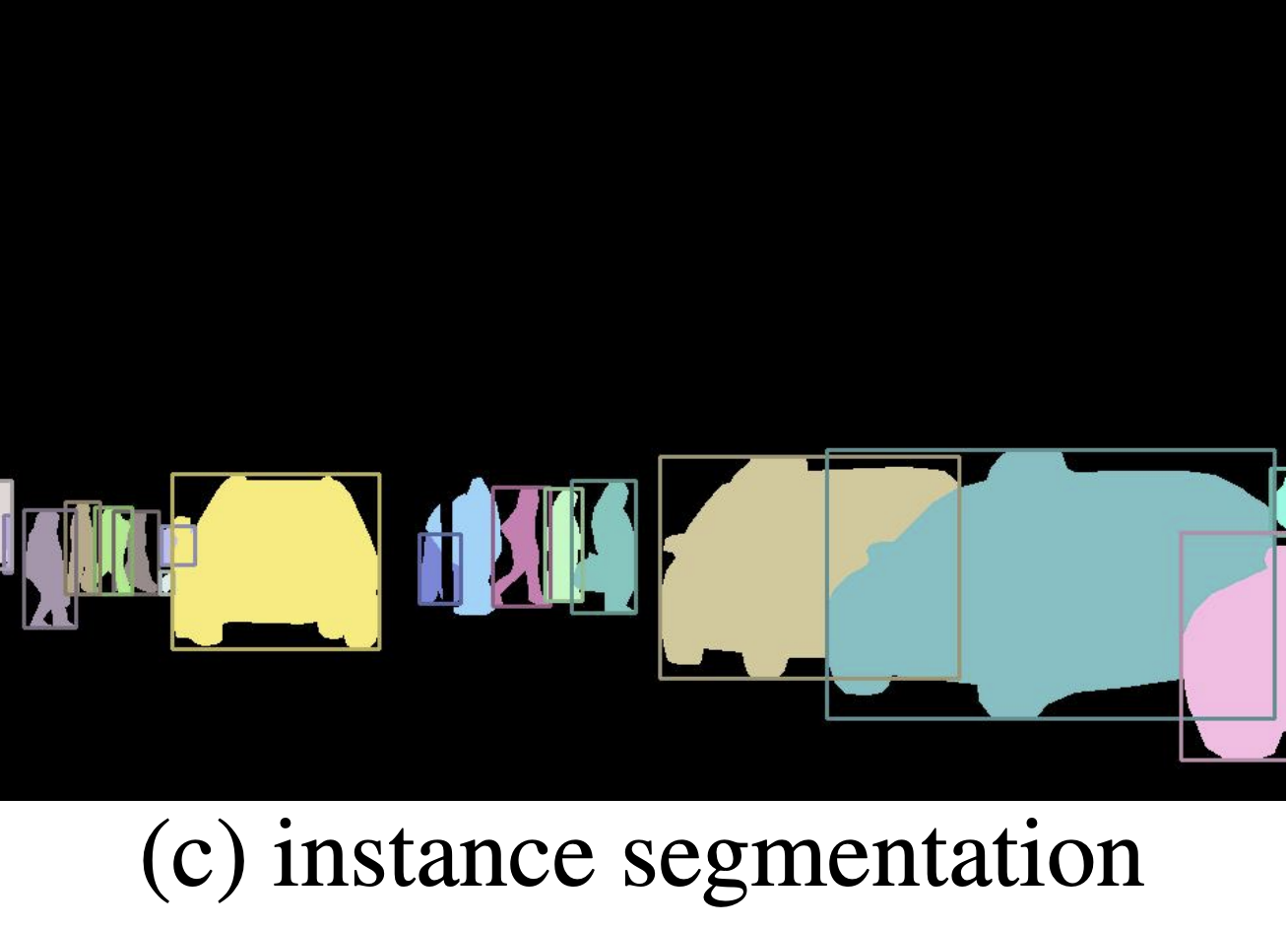
Instance segmentation, on the other hand, is a visual recognition task that falls under the study of “things”. In instance segmentation, we aim to detect individual instances of objects in a scene and apply a pair of class and instance labels. For example, given an input image, we might want to determine the exact region that corresponds to a particular car. If two cars are present in an image, then we want to recognize them as distinct objects and assign different instance labels (even though they both have the class label “car”). Unlike semantic segmentation, we focus on detecting “things” as opposed to labeling “stuff”.
Panoptic Segmentation
What is Panoptic Segmentation?
While advances in instance segmentation and semantic segmentation were significant and highly applicable, Kirillov et. al. (2019) recognized a growing rift between the study of “things” and the study of “stuff”, and the methodologies/techniques used in each. Panoptic segmentation, introduced by Kirillov et. al. (2019), seeks to unify the typically disparate tasks of semantic segmentation and instance segmentation into a single unified task. For example, in an image of a street, panoptic segmentation might label the road as ‘stuff’ while distinguishing individual cars and pedestrians as ‘things.’ This provides both high-level scene context and granular object identification

The Task Format
In panoptic segmentation, each pixel \(i\) in an image to a pair (\(l_i\), \(z_i\)), where \(l_i\) represents the semantic class of the pixel, and \(z_i\) represents the instance id this pixel belongs to. The set of all possible semantic labels can be partitioned into a set of “stuff” labels and a set of “thing” labels. When a pixel’s semantic label is a “stuff” label, the pixel’s instance id becomes irrelevant. Otherwise, two pixels j, k belong to the same instance if and only if (\(l_j\), \(z_j\)) = (\(l_k\), \(z_k\)).
The panoptic segmentation task format is a generalization of the semantic segmentation task format. It’’s also important to note that the panoptic segmentation task format differs from the instance segmentation task format in the sense that a single pixel will not have more than one semantic label and instance label. No overlaps are possible between segments.
The Panoptic Quality Metric
In the panoptic segmentation paper, Kirillov et. al. (2019) [1] also introduces the Panoptic Segmentation Metric, a unified metric for measuring performance on the panoptic segmentation task. It’s novel in the sense that previously, semantic segmentation and instance segmentation were measured separately using independent metrics.
A predicted segment is said to match a ground truth segment only if its IoU (intersection over union) is greater than 0.5. This criterion, when coupled with the non-overlapping property of the task format, actually guarantees that there can be at most one predicted segment matched to each ground truth segment. The proof can be found in the paper. This is significant because it makes the segment matching and computing the panoptic quality metric simple, efficient, and deterministic.
Now let’s look at how the panoptic quality (PQ) metric is actually calculated. The PQ score is calculated independently for each semantic class and averaged over the classes to allow for stability in the case of class imbalances. While the PQ metric might look complicated at first glance, it’s actually highly intuitive. We are essentially just taking the average IoU of the correctly matched prediction and ground truth pairs, and then we also add a term to the denominator to penalize false positives and false negatives (since an increase in the denominator results in a lower PQ score). Furthermore, we can actually write the PQ score as the product of a segmentation quality (SQ) term and a recognition quality (RQ) term (as they are called in the paper). The SQ term is the average IoU over the true positive matchings of predicted segments to the ground truth segments, and the RQ term is just the F1 score, a common metric for predictive performance.
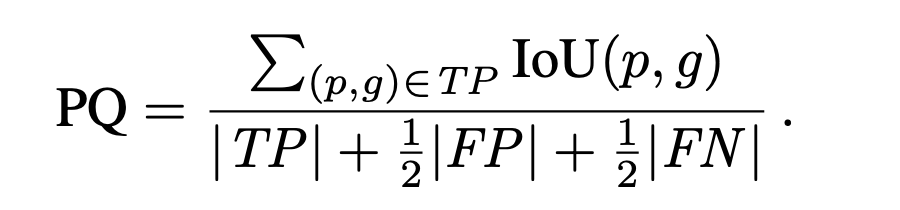
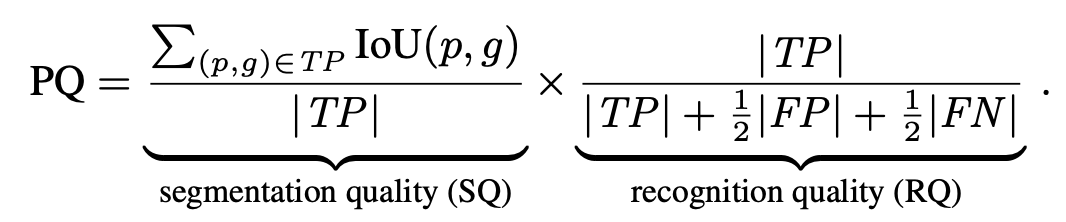
Thus, we see that the panoptic quality metric is highly interpretable, simple to compute, and parallels standard performance metrics in the field.
Mask2Former
Now that we know what panoptic segmentation is, and how it differs from previous segmentation approaches, let us dive into recent developments in panoptic segmentation. Specifically, we are going to look at the Mask2Former model. – a transformer-based architecture that attained SOTA performance in panoptic, instance, and semantic segmentation when it was created in 2022.
What is Mask2Former?
The Masked-attention Mask Transformer (Mask2Former) model is a universal image segmentation architecture introduced by Cheng et. al. (2022) [2][3]. It attained SOTA performance in panoptic, instance, and semantic segmentation at the time of its creation, outperforming task-specific architectures on each of these image segmentation tasks. The key innovation was the incorporation of masked attention, which “extracts localized features by constraining cross-attention within predicted mask regions”. Let us dive deeper into how Mask2Former works and why it’s such a powerful approach to segmentation.
Architecture Overview
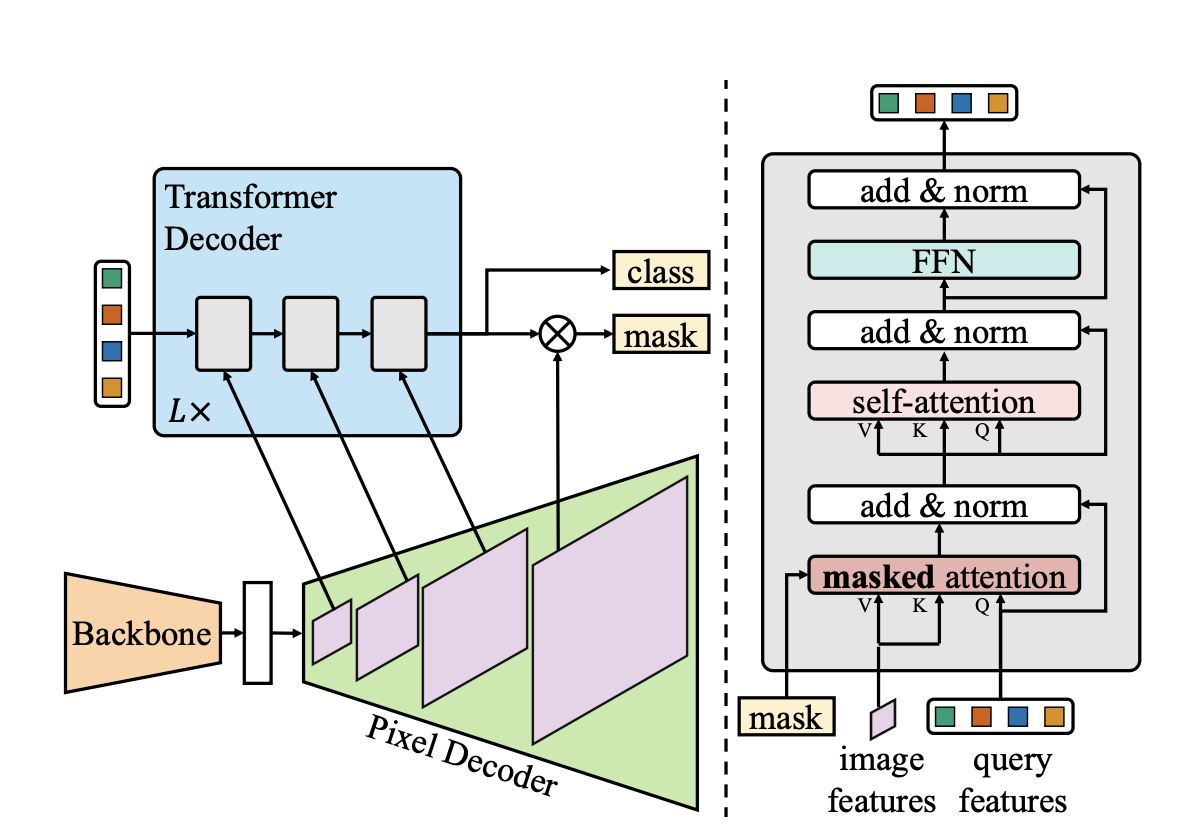
The Mask2Former architecture adopts the same meta-architecture as its predecessor (MaskFormer), consisting of a backbone, a pixel decoder, and a transformer decoder.
- Backbone Feature Extractor: First, Mask2Former uses a backbone architecture (typically either convo ution-based ResNet or transformer-based Swin-Transformer architectures) to extract low-resolution image features from an input.
- Pixel Decoder: Next, the pixel decoder (in Mask2Former, this is implemented as a feature pyramid network) takes the output of the backbone and gradually upsamples the low-resolution features to generate high-resolution per-pixel embeddings.
- Transformer Decoder: In the original MaskFormer architecture, they used a standard Transformer decoder to take the output of the backbone and N learnable positional embeddings, and compute N per-segment embeddings that encode global information about each of the predicted segments. For each of these N per-segment embeddings, we can then predict a class label, and we can query them against the per-pixel embeddings to generate N mask predictions.
- Masked-attention: Mask2Former largely adopts the same process, except it uses a Transformer decoder with masked attention instead of the standard cross-attention. At each layer of the decoder, we restrict our cross-attention to only the image features within the mask region predicted by the previous decoder layer. We don’t let each query attend to all of the image features and instead focus our attention on the masked regions. This allows for an iterative process where our masks become increasingly refined. The use of masked attention reduces computational cost while also improving accuracy, and is the key innovation in the Mask2Former architecture.
Results and Impact
Mask2Former set new benchmarks across multiple datasets. Notably, the Mask2Former with a Swin-L backbone attained a PQ score of 57.8 on the COCO panoptic val2017 dataset, setting a new standard for panoptic segmentation performance. But the implications here are even broader. Mask2Former demonstrated that a single universal model could generalize across all segmentation tasks. Mask2Former’s success as a unified segmentation model laid the foundation for more ambitious, task-agnostic approaches like Meta’s Segment Anything Model, which pushes generalization even further.
Segment Anything Model
Paradigm Shift: SAM isn’t a Panoptic Segmentation Model
The Segment Anything Model (SAM) was introduced by Kirillov et. al. (2023) [4], and represents a fundamental shift in image segmentation research. Unlike the Mask2Former model, SAM is actually not a panoptic segmentation model, nor is it an instance or semantic segmentation model. It was designed to be a foundation model in image segmentation. Given an input image and a user prompt (point, box, mask, and text), SAM will predict masks corresponding to the prompt.
Architecture Overview
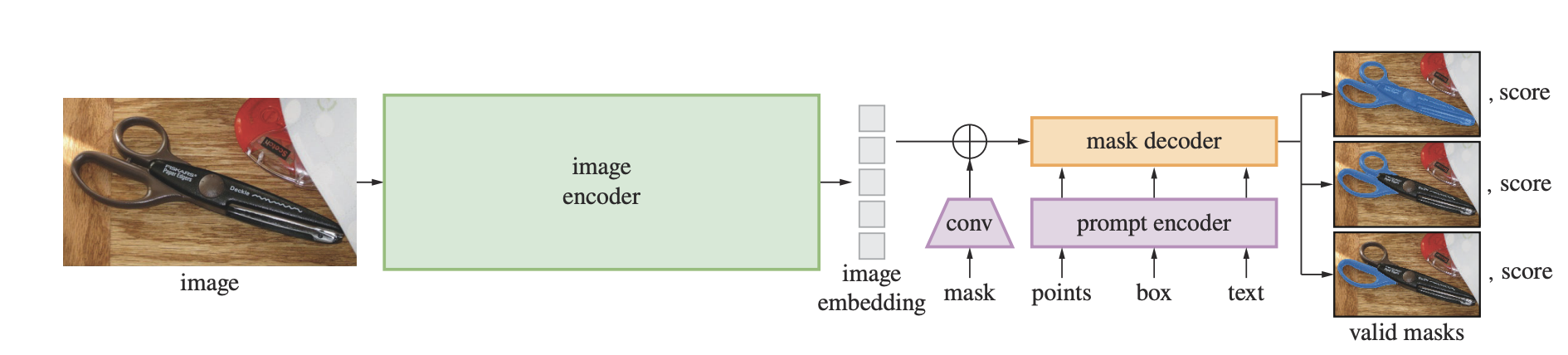
SAM is designed to generalize across datasets and downstream segmentation tasks, and thus efficiency is a key consideration in SAM’s architecture. The architecture consists of three core components:
- Image Encoder: First, a heavyweight Vision-Transformer (pre-trained using Masked Auto Encoding) is used to generate an embedding for an input image. Since the image encoder operates independently from the prompt encoder, the image encoder only needs to run once for a given image, allowing for greater efficiency.
- Prompt Encoder: A flexible prompt encoder is used to handle all of the different possible user inputs (points, boxes, text, and masks).
- Mask Decoder: The mask decoder block is quite similar to the transformer decoder used in MaskFormer and Mask2Former. Like Mask2Former, the mask decoder consists of a modified transformer decoder block. It uses prompt self-attention, and cross-attention is performed in two directions (image-to-prompt and prompt-to-image).
The Significance of SAM
While at first glance SAM might seem to be a model that performs quite a specific task (segmenting a single object given a prompt), upon closer inspection it becomes clear that this model is highly flexible and generalizable. For instance, look at how SAM was used to segment these images with high granularity and precision. In this instance, SAM yields a comprehensive scene segmentation akin to that of panoptic segmentation models (except without class labels). Another highly impactful result of the Segment Anything project was the SA-1B dataset. Using SAM, Meta was able to generate a dataset consisting of 1 billion masks across 11 million images. This dataset will be invaluable for future research in computer vision.

Conclusion
From foundational tasks like semantic and instance segmentation to unified models like Mask2Former and task-agnostic approaches like SAM, research in image segmentation has progressed greatly. Mask2Former proved that a single architecture could achieve state-of-the-art performance across segmentation tasks, while SAM marks a promising shift towards research in foundation segmentation models, pushing the boundaries of generalization by enabling flexible, prompt-driven image segmentation. These advancements, coupled with datasets like SA-1B, are helping us build more robust and scalable visual analysis systems, with a wide range of applications in autonomous systems, robotics, and beyond.
References
- [1] Kirillov et. al. “Panoptic Segmentation.” 2019.
- [2] Cheng et. al. “Per-Pixel Classification is Not All You Need for Semantic Segmentation.” 2021.
- [3] Cheng et. al. “Masked-attention Mask Transformer for Universal Image Segmentation”. 2022.
- [4] Kirillov et. al. “Segment Anything”. 2023.