Image Translation
An exploration of three different approaches of image-to-image translation.
Introduction
We explore the problem of translating images across domains. An example of this could be translating pictures of horses into pictures of zebras. Or a more practical use case could be translating a sketch of a horse into a realistic rendering of a horse. Oftentimes this image translation process is thought of as changing the appearance or style of an image, while preserving its underlying structure.
Popular methods of image translation include those based on training Generative Adversarial Networks (GANs) and modifying already existing diffusion models. We discuss CycleGAN as a GAN-based method, and FreeControl and Ctrl-X as diffusion-based methods.
CycleGAN
A CycleGAN[1] model is a model trained to translate between two specific domains of images. The training data is composed of a set of images from each of the domains. An advantage of this method versus prior methods is that these training images need not be paired, the model learns to translate images between domains without an explicit ground truth images defined.
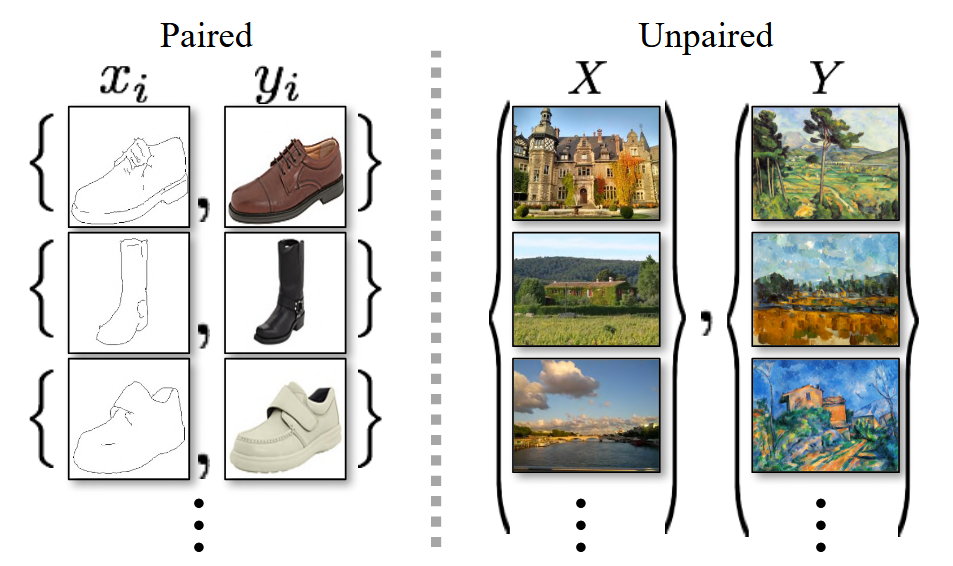
Fig 1. An example of paired vs. unpaired data [1].
This is accomplished by training two GANs, one for each direction of translation:
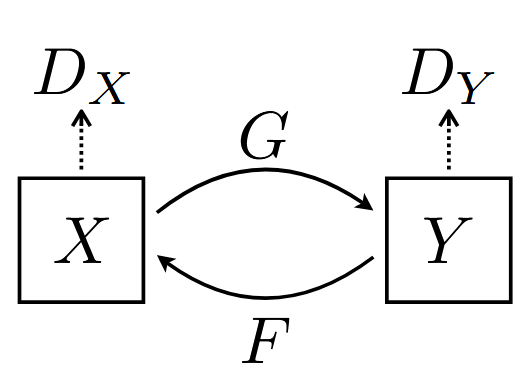
Fig 2. CycleGAN architecture [1].
One might think that if we only want to perform image translation in one direction, than one GAN should be enough. However, consider the following hypothetical:
Imagine we want to translate between two domains of numbers, domain \(X\) is defined as the set of integers from 0 to 9 and domain \(Y\) is defined as the set of multiples of 10 from 0 to 90. Clearly, there is an easy way to translate items of \(X\) to items of \(Y\), just multiply by 10. Indeed, this is one possible optimal mapping that a generator could learn, for which the discriminator wouldn’t be able to distinguish between “fake” outputs of the generator from “true” members from \(Y\). One could imagine that the first digit of the numbers is analagous to the structure of the image while the number of digits is analagous to the appearance.
However, notice that different permutations of the outputs are also valid. Instead of mapping \((0, 1, 2, 3, 4, 5, 6, 7, 8, 9) \rightarrow (0, 10, 20, 30, 40, 50, 60, 70, 80, 90)\), the generator could learn the equally valid mapping \((0, 1, 2, 3, 4, 5, 6, 7, 8, 9) \rightarrow (0, 10, 70, 90, 80, 20, 40, 30, 50, 60)\). But this new mapping fails to preserve the “structure” of the numbers. In the worst case, the generator could learn a constant mapping, but we would obviously like to produce more than a single image.
CycleGAN remedies this by learning two GANs during training, one for each direction. They then introduce a cycle consistency loss term to the overall loss function, similar to the reconstruction loss of autoencoders, encouraging the model to learn mappings in both directions such that images are reconstructed when fed through the generators in a series. This obviously prevents the learning of constant mappings, and in practice also discourages permuting.
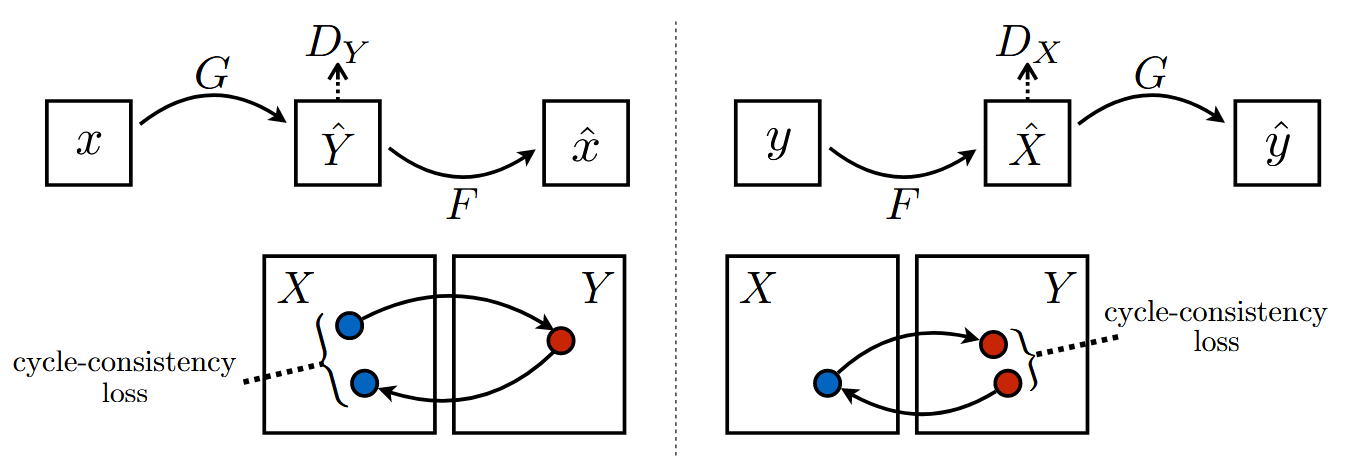
Fig 3. Cycle consistency loss [1].
The overall loss function is \(L(G, F, D_X, D_Y) = L_{GAN}(G, D_Y, X, Y) + L_{GAN}(F, D_X, Y, X) + \lambda L_{cyc}(G, F)\) where \(L_{GAN}\) is the usual GAN loss, \(L_{cyc}\) is cycle reconstruction loss, \(G, F\) are generators, \(D_X, D_Y\) are discriminators, and \(\lambda\) is a hyperparameter used for controlling the relative importance of the GAN loss vs. cycle consistency loss.

Fig 4. Example results from CycleGAN [1].
FreeControl
Text to image diffusion models such as Stable Diffusion have recently become popular. With them, a user inputs a text prompt, and the diffusion model generates a image through iterative denoising of gaussian noise conditioned on the input text. One problem that comes with this is that while the user can pretty easily control the appearance of the image, it is harder to precisely control a desired structure. As such, image translation in the sense of transferring structure in diffusion models is an active area of research.
FreeControl[2] is one guidance-based training-free method of accomplishing this task. It is built on top of the following insights:
- Many diffusion models are build with U-Nets that utilize self- and cross-attention
- Self-attention models interactions between different spacial regions of an image
- Cross-attention models interactions between regions of an image and the conditioning text prompt
- The noise predicted by the diffusion model used in the iterative denoising process can be modifed through guidance, where the predicted noise is modifed with another function conditioned on additional information.
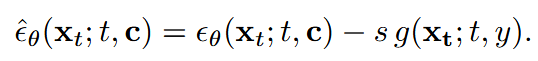
Fig 5. How guidance works [2].
Guidance is accomplished by augmenting the model with an energy function that conditions diffusion on auxiliary information (\(y\)). In the case of FreeControl, the noise components predicted by the model are conditioned on structure and appearance information.
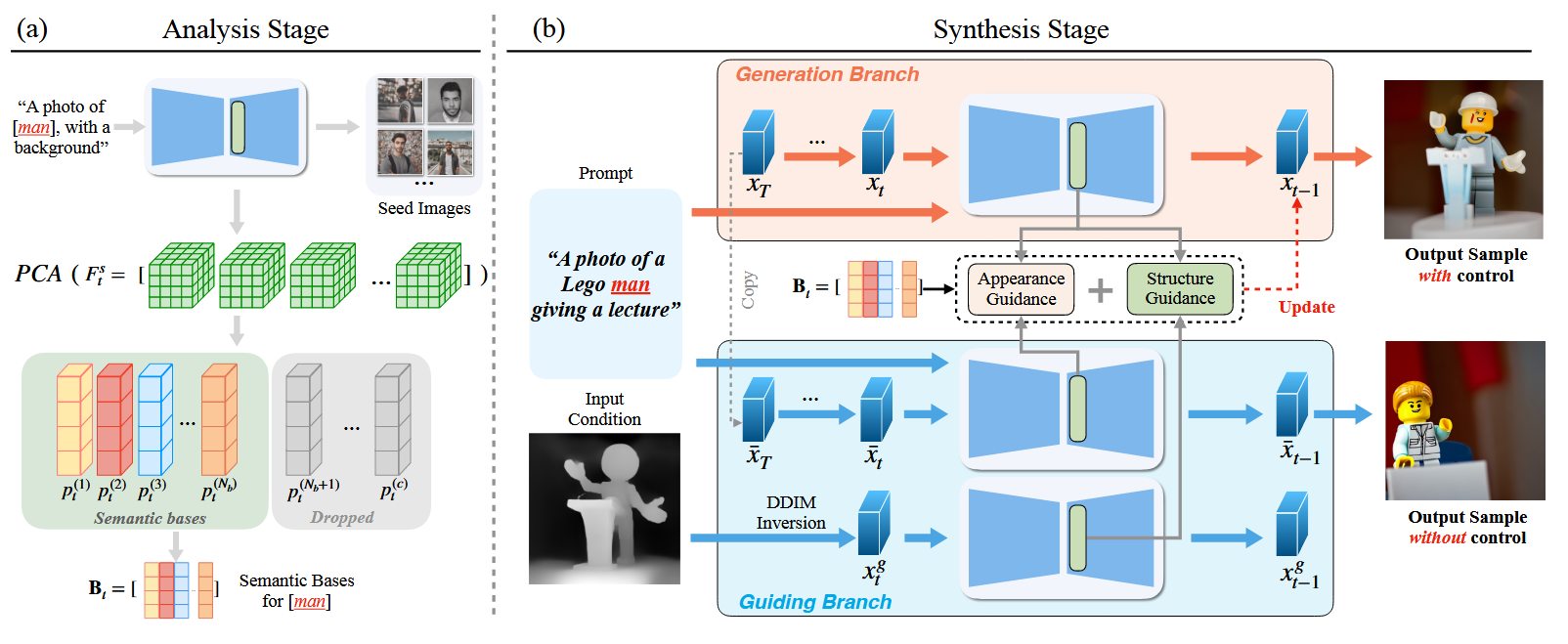
Fig 6. Overview of FreeControl [2].
There are two stages to FreeControl during inference. During the analysis stage, a generic prompt is used to generate seed images, which are then run through forward diffusion to extract the feature maps at each time step. PCA is used to extract the most important components of the features, which form semantic bases to be used later. The example provided in the FreeControl paper is that if we wanted to control the structure for the prompt “A photo of a Lego man giving a lecture”, we would generate seed images with the prompt “A photo of a man, with a background”. This results in a diverse set of images of men, for which their feature maps can be analysed.

Fig 7. Visualization of the correspondence between principle components and original images [2].
During the synthesis stage, two branches of model inference are formed, a generation branch and a guiding branch. The generation branch is the branch where the final image is generated, starting from the original prompt, and guided with information derived from the guiding branch. The guiding branch takes a guiding image that encodes the target structure, and derives the features for each time step. At each relevant time step in the denoising process, both the features from the generation branch and the features from the guiding branch are projected to the semantic bases derived from the analysis stage. The semantic coordinates are then effectively compared to each other in the energy function used for guidance.
In practice, the authors found that using just this caused a loss of appearance details, so they also employ appearance guidance, with appearance represented as a spatial mean of diffusion features, weighted by the semantic components previously derived from projection of the features to the semantic bases.
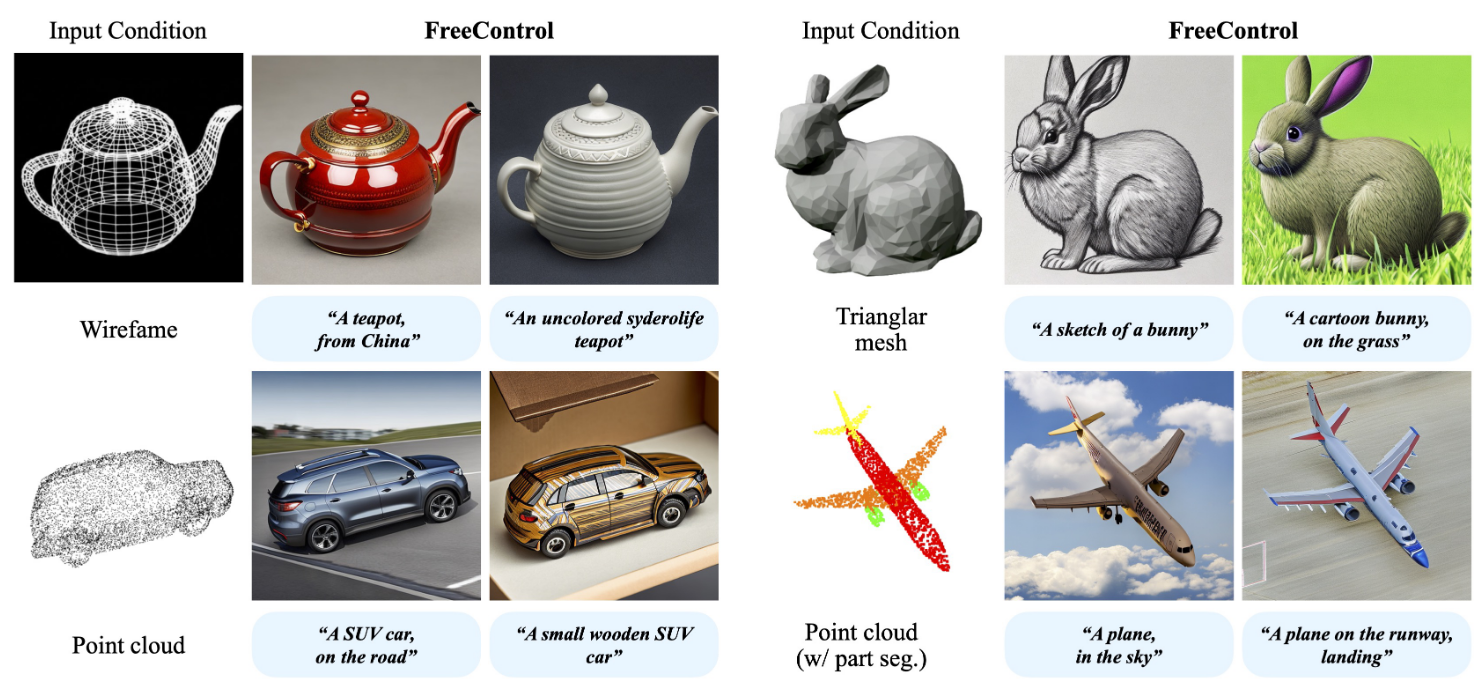
Fig 8. Example results of FreeControl [2].
Ctrl-X
Ctrl-X[3] is a newer method published in 2024 that is also training-free and augments diffusion models, but does so more efficiently than FreeControl by being guidance-free. It accomplishes this by directly modifying diffusion features, instead of guiding the noise predictions.
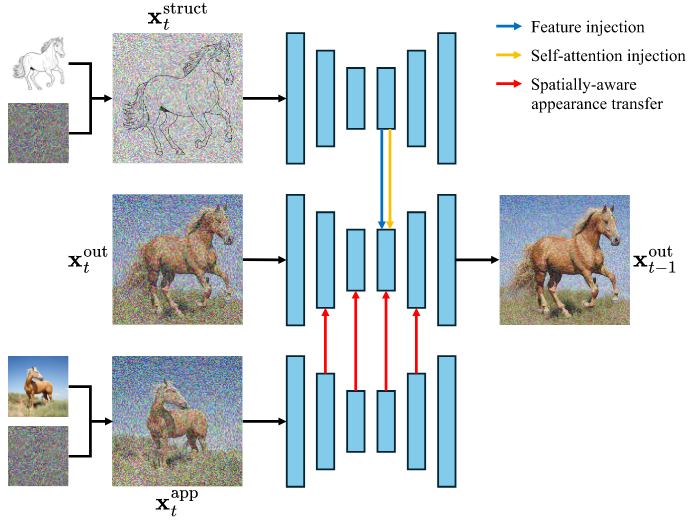
Fig 9. An overview of Ctrl-X [3].
An output branch exists that generates the output image through the standard iterative denoising process from gaussian noise. During this, structure and appearance information is injected from two other branches.
Structural information is derived from taking an input image that encodes the desired structure information, and deriving its diffusion features for each time step through forward pass. For each desired time step, the diffusion features and attentions of the output branch’s self-attention block are replaced with those from the structure branch.
![]()
Fig 10. Modifying appearance statistics using an attention map derived from cross-attention of output and appearance diffusion features [3].
Appearance transfer is achieved by performing what is basically cross-attention. At each desired time step, diffusion features from the appearance and output branches are normalized to remove appearance information. An attention map is then calculated, and then applied to the normalized output branch features, from which the original model’s self-attention proceeds as normal. Essentially what this process does is utilize the structural correspondences between the appearance and output features to decide which appearance components to amplify.

Fig 11. Example results of Ctrl-X [3].
Conclusion
There are two main methods of accompishing image-to-image translation.
GAN-based methods such as CycleGAN train generators on unpaired training data to translate images between different domains. Training two generators, one for each direction of translation, allows consideration of how well images can be reconstructed from translating to a domain and back, qualitatively improving model performance.
From here, other architectures can be proposed, such as StarGAN[4], which generalizes the cycle idea to training a single model to handle translation between greater than two domains.
Augmenting a pre-existing diffusion model allows style transfer to be accomplished without a training phase, although diffusion model-based methods that incorporate training do exist. FreeControl accomplishes zero-shot style transfer by using guidance to condition the denoising of the model, using auxiliary structure information from a provided guiding image. Ctrl-X accomplishes more efficient zero-shot structure and appearance transfer by directly modifying output diffusion features based on structure and appearance image diffusion features.
Reference
[1] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks,” Aug. 24, 2020, arXiv: arXiv:1703.10593. Accessed: Nov. 07, 2024. [Online]. Available: http://arxiv.org/abs/1703.10593
[2] S. Mo et al., “FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition,” Dec. 12, 2023, arXiv: arXiv:2312.07536. Accessed: Nov. 07, 2024. [Online]. Available: http://arxiv.org/abs/2312.07536
[3] K. H. Lin, S. Mo, B. Klingher, F. Mu, and B. Zhou, “Ctrl-X: Controlling Structure and Appearance for Text-To-Image Generation Without Guidance,” Jun. 11, 2024, arXiv: arXiv:2406.07540. doi: 10.48550/arXiv.2406.07540.
[4] Y. Choi, Y. Uh, J. Yoo, and J.-W. Ha, “StarGAN v2: Diverse Image Synthesis for Multiple Domains,” Apr. 26, 2020, arXiv: arXiv:1912.01865. Accessed: Nov. 08, 2024. [Online]. Available: http://arxiv.org/abs/1912.01865