FaceNet
Our project is about FaceNet, how it works, and its use cases. We had a lot of fun playing around with it and learning about it. We hope you do too!
- FaceNet: Revolutionizing Facial Recognition with Deep Learning
- Background: The Evolution of Facial Recognition in Deep Learning
- What is FaceNet?
- How FaceNet Works
- Advantages of FaceNet
- Applications and Use Cases of FaceNet
- Playing Around With FaceNet
- FaceNetCompare Inputs and Outputs
FaceNet: Revolutionizing Facial Recognition with Deep Learning
Facial recognition has become an important application of deep learning, playing a pivotal role in everyday technology seen all around the world. From unlocking smartphones to improving law enforcement practices, facial recognition has redefined how we interact with technological systems and the information space. FaceNet, a facial recognition system developed by Florian Schroff, Dmitry Kalenichenko and James Philbina from Google, is one of the most influential models for facial recognition today. In this article, we’ll explore the history of facial recognition, how FaceNet works, the underlying algorithms and technologies that power it, and its wide range of use cases.
Background: The Evolution of Facial Recognition in Deep Learning
Facial recognition has been a challenge for computer vision researchers for a long time. Early facial recognition technologies relied on rule-based techniques or used simple mathematical methods to analyze faces. These methods worked to a certain extent but struggled with variability in lighting, pose, and facial expressions, and could only perform in constrained settings.

Fig 1. Art example of facial recognition [1].
1. Early Approaches: Eigenfaces and Fisherfaces
In the 1990s, principal component analysis or PCA, was at the forefront of facial recognition. PCA would reduce the dimensionality of colored facial images, making it easier to compute facial recognition algorithms. The use of PCA led to the development of Eigenfaces, an algorithm that represented faces as a weighted sum of principal components or eigenvectors, which were learned from a dataset of face images. While Eigenfaces could recognize faces based on these components, it still had limitations, especially when faces were seen in different conditions such as lighting. To address some of these issues, Linear Discriminant Analysis (LDA) was introduced, resulting in the Fisherfaces method. Fisherfaces would instead find a projection of face images that maximized the difference between different faces in a dataset. However, even with Fisherfaces, recognition performance decreased as the variation in face images increased. A more robust model was desperately needed to tackle this issue.
2. The Rise of Deep Learning
Deep learning in the 2000s brought about a significant breakthrough in facial recognition technology. Neural networks, particularly Convolutional Neural Networks (CNNs), began to replace traditional methods by automatically learning feature representations directly from raw pixel data. In 2012, a pivotal moment in computer vision came with the introduction of AlexNet, a deep CNN that dramatically improved performance in the ImageNet competition. This was one of the first demos of how powerful deep learning was for visual tasks, including facial recognition. Around the same time, researchers began applying deep learning to face-related tasks, leading to the development of the DeepFace model by Facebook in 2014. DeepFace, which used deep CNNs to map faces into a Euclidean space, improved face recognition accuracy. However, it still required facial images to be in similar poses and lighting, which limited its flexibility and use.
3. FaceNet: A Paradigm Shift in Facial Recognition
While DeepFace made substantial progress, FaceNet represented a breakthrough by allowing facial images to exist in varying conditions and also introducing a new approach to face representation, embedding learning. Unlike previous methods that relied on classification, FaceNet focuses on learning embeddings, which are low-dimensional vector representations of faces. These embedding vectors capture the unique features of a face, allowing FaceNet to compare faces based on their Euclidean distance, making it highly effective in both facial verification and facial recognition.
What is FaceNet?
FaceNet is a deep learning model that learns to map face images to an embedding space, where the face of each individual is represented as a unique vector. The key idea behind FaceNet is that this embedding captures the essential characteristics of a face, such that:
-
Images of the same face are close together in this space.
-
Images of different faces are farther apart.
Essentially, FaceNet allows computers to understand and compare faces in a way that mimics human perception, making it possible to identify, verify, and cluster faces with very high accuracy. In addition, since FaceNet is very intricate and complex, it required a lot of effort to train it. The researchers at Google spent 2.5 years total in just labeling the training images of about 200 million faces with Amazon Mechanical Turk. While Google didn’t explicitly state how long it took to train FaceNet, it can be estimated that training the model took about a few weeks on their known GPU infrastructure. Now, let’s go deeper into how FaceNet works!
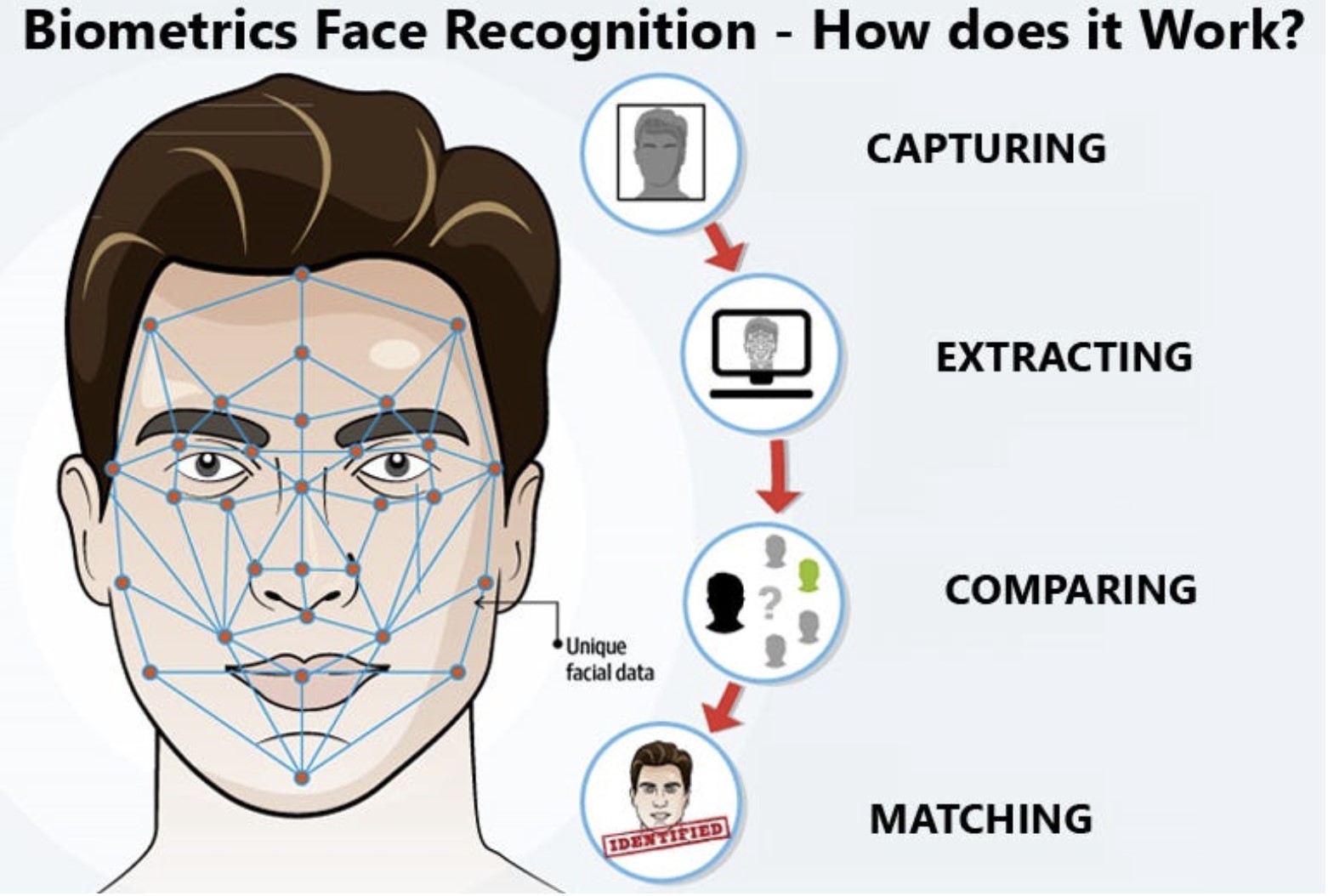
Fig 2. How computer vision works [2].
How FaceNet Works
At the heart of FaceNet’s capabilities lies its deep learning architecture, which primarily consists of a CNN. Here’s a breakdown of the key components that make FaceNet so effective:
1. Convolutional Neural Network (CNN)
CNNs are the backbone of FaceNet. They are designed to automatically extract features from raw pixel data by applying convolution operations. In the case of FaceNet, these networks learn to identify key facial features, such as eyes, nose, and mouth. Then, it converts these features into a fixed-size vector representation. Before images are put through the CNN, they are preprocessed. Each image is then resized to 160x160 pixels and then normalized. This ensures all pixel values are between -1 and 1. Lastly, data augmentation is applied to the images before training. This includes creating copies of images with random deviations, such as cropping, flipping, rotating, or inverting the colors. This ensures the CNN is more robust, precise, and accurate. After the images are preprocessed, they are inputted into the CNN. The CNN in FaceNet has 9 total layers, 6 of which are convolutional layers, and 3 of which are fully connected linear layers. The first convolutional layer uses a 7x7 filter, which is later reduced to 3x3 filters on the rest of the convolutional layers. In addition, each convolutional layer has max pooling, with the first 2 convolutional layers having normalization. All of this computation is very taxing as it totals to 140 million parameters stored in memory and 1.6 billion FLOPS of computation. Through these layers, CNNs progressively learn complex patterns in the facial images, eventually outputting a vector (embedding) that succinctly represents the face in a 128-dimensional space.
2. The Triplet Loss Function
The most innovative aspect of FaceNet’s architecture that sets it apart from other models is the use of the triplet loss function in training the model. Unlike traditional classification loss functions, triplet loss focuses on learning the relative distances between images. The triplet in the triplet loss function consists of:
-
Anchor: A reference face.
-
Positive: A face of the same person as the anchor.
-
Negative: A face of a different person.
The model is trained to minimize the distance between the anchor and the positive image while maximizing the distance between the anchor and the negative image, which is calculated in the embedding space. The specific distance function being used is Euclidean distance. This process ensures that faces from the same person should be close together and faces from different people should be pushed farther apart. Mathematically, this can be expressed as: \(L_{\text{triplet}} = \max \left( d(a, p) - d(a, n) + \alpha, 0 \right)\) Where:
-
d(a,p) is the distance between the anchor and positive example.
-
d(a,n) is the distance between the anchor and negative example.
-
α is the margin that ensures the distance between the positive and negative faces is sufficiently large. If the positive images are closer to the anchor than the negative images, then the loss should theoretically be 0, as the difference calculated will be negative. In the opposite instance where the negative image is closer to the anchor than the positive image, there will be a loss to describe the performance of the model. As you can see, this specific loss function is responsible for making FaceNet very successful in the facial recognition space.
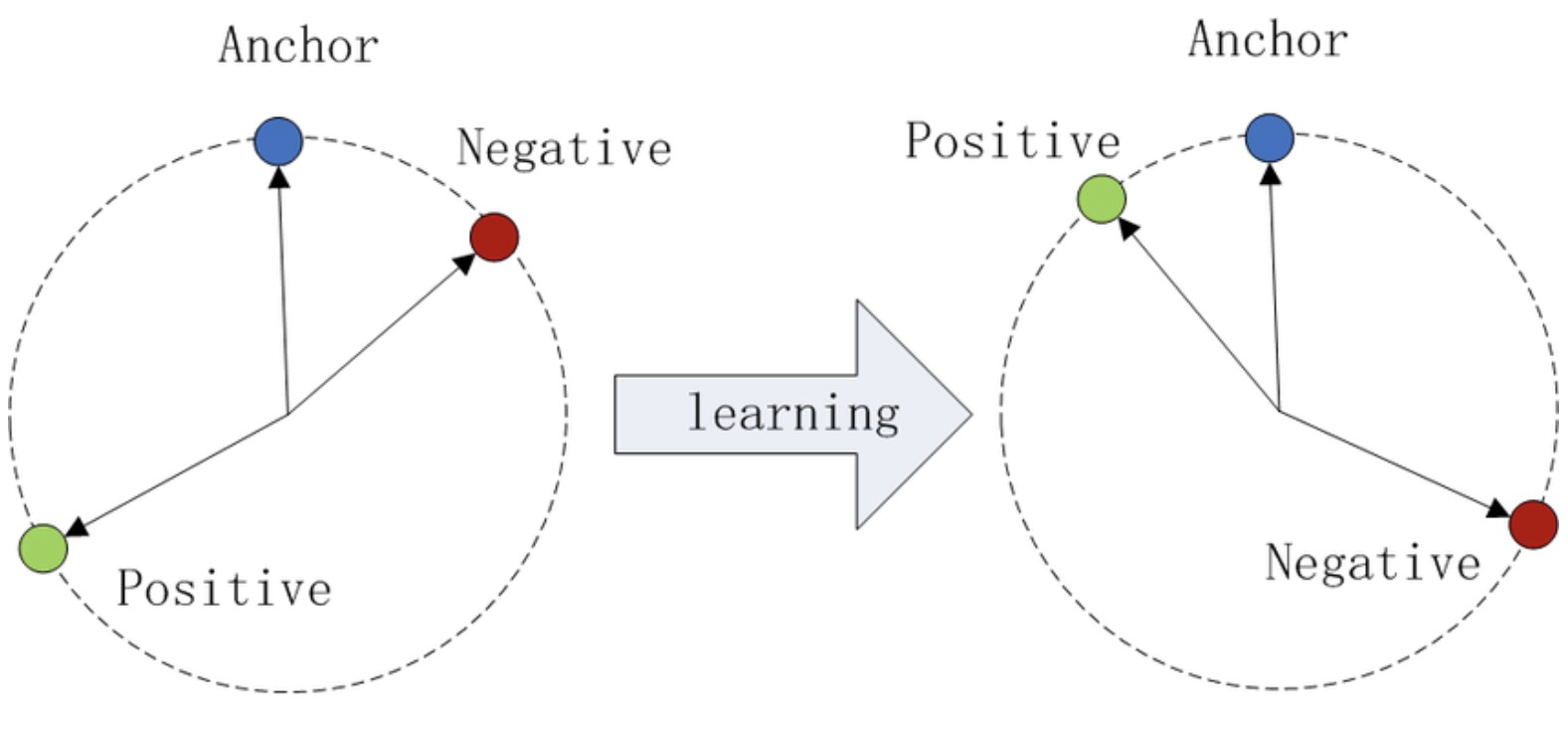
Fig 3. Triplet loss function [3].
3. Embedding Generation
After training, FaceNet generates embeddings for an inputted face picture. This is the one dimensional output after passing the output from the convolutional layers through a fully connected linear layer. These embeddings are compact vectors that represent a person’s face and are fixed in size, making them easy to be stored, retrieved, and compared. Additionally, it has many different details of the face stored through the vector, such as the eyes, nose, and mouth of a face. One huge benefit is that FaceNet works regardless of pose, lighting, or age, allowing the system to recognize faces even in challenging conditions.
4. Face Recognition and Verification
With the embeddings generated, FaceNet can now perform two primary tasks:
-
Face Recognition: When given a new face, FaceNet compares its embedding to a database of known faces. The model then finds the closest matching face and identifies the individual.
-
Face Verification: Given two face embeddings, FaceNet can determine whether they belong to the same person by calculating the distance between them. If the distance is below a certain threshold, the faces are considered a match. This ability to compare face embeddings quickly is what makes FaceNet ideal for real-time applications.
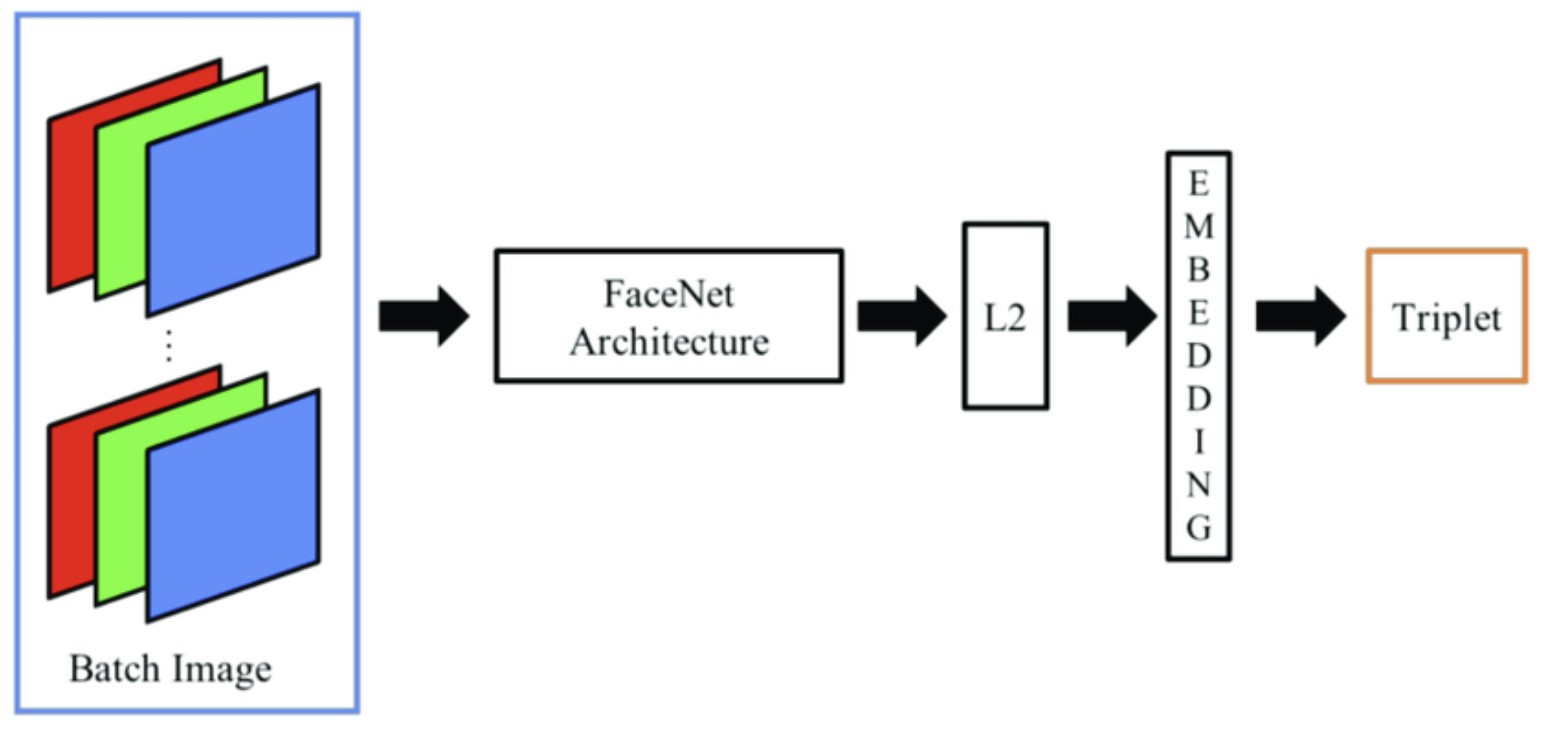
Fig 4 FaceNet End-to-End Architechture [4].
Advantages of FaceNet
-
Accuracy: FaceNet has demonstrated exceptional performance on several standard benchmarks, outperforming earlier facial recognition methods like Eigenfaces and Fisherfaces.
-
Scalability: With its compact embeddings, FaceNet is ideal for large-scale applications, such as government databases or social media platforms.
-
Real-time Performance: FaceNet can process facial recognition requests in real time.
Applications and Use Cases of FaceNet
FaceNet’s robust performance and flexibility have led to its adoption across various industries. Let’s look at some of the key use cases where FaceNet is making a significant impact.
1. Security and Access Control
One of the most common applications of FaceNet is in security systems for access control. Many modern smartphones and laptops now utilize FaceNet-based systems to authenticate users by recognizing their faces, such as the iPhone. Similarly, FaceNet can be employed in secure facilities to allow or deny access based on facial recognition.
2. Surveillance and Law Enforcement
In surveillance systems, FaceNet is used to identify and track individuals in real-time. Law enforcement agencies are using FaceNet-powered systems more and more to match suspects’ faces to databases of known individuals. This technology has already proven valuable in criminal investigations.
3. Face Clustering for Photo Management
FaceNet is also widely used for photo organization and tagging within photos. It’s applied by platforms like Google Photos to automatically recognize and group images of the same person together. This makes it easier for users to organize and search through a large number of photos, such as looking for pictures of only one friend in a huge photo library.
4. Emotion and Sentiment Analysis
While FaceNet is primarily designed for recognition, it can also be adapted to perform emotion detection by analyzing facial expressions. This has applications in customer feedback analysis, improving human-computer interaction, and even in psychological research to assess emotional responses.
5. Healthcare and Patient Identification
FaceNet offers healthcare institutions a reliable and secure way to identify patients. This can reduce the risks of medical errors caused by mistaken identities, ensuring that patient records are matched with the correct individual. Moreover, facial recognition systems can speed up patient check-ins and facilitate smoother interactions in hospitals and clinics.
6. Retail and Marketing
In retail environments, FaceNet can be used to improve customer experiences by recognizing returning customers. This can help businesses tailor advertisements, product recommendations, or even discount offers based on the customer’s preferences.
Playing Around With FaceNet
We ran the FaceNet codebase, and implemented some of our own ideas to enhance the use of it. We did facial comparison, where we took images of two different celebrities and compared them using the model. The model automatically detects the face and draws a bounding box for it. What we did to make this process easier for a user, was that we changed the color of the bounding box to represent the percent match between them. 0% - 50% match would be red, while a 50% - 100% match would be between yellow and green.
from facenet_pytorch import MTCNN, InceptionResnetV1
import torch
from PIL import Image
import numpy as np
import cv2
# FaceNet class to compare two images
class FaceNetCompare:
"""
initialize FaceNet class object with image paths of the two images and preferred output path (default is output_comparison.jpg)
"""
def __init__(self, image_path_1, image_path_2, output_img_path='output_comparison.jpg'):
self.image_path_1 = image_path_1
self.image_path_2 = image_path_2
self.mtcnn = MTCNN(image_size=160, margin=0, min_face_size=20)
self.resnet = InceptionResnetV1(pretrained='vggface2').eval()
self.target_size = (800, 600)
self.output_path = output_img_path
"""
Resize the image to the target size so that the model can process it better
Input: image
"""
def resize_image(self, image):
return cv2.resize(image, (self.target_size[0], self.target_size[1]))
"""
Draw a rectangle around the face inside the image and label the similarity percentage underneath the face
Input: image_path, similarity=None
"""
def draw_around_face_and_label(self, image_path, similarity=None):
img = cv2.imread(image_path)
img = self.resize_image(img)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
boxes, _ = self.mtcnn.detect(Image.fromarray(img_rgb))
if boxes is not None:
for box in boxes:
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
# Extra implementation: color changes based on similarity
# Calculate color based on similarity
if similarity is not None:
if similarity >= 50:
# 50-100%: Yellow to Green
red = int(255 * (1 - (similarity - 50) / 50.0))
blue = 0
green = 255
else:
# 0-50%: Red to Yellow
red = 255
blue = 0
green = int(255 * (similarity / 50.0))
color = (blue, green, red)
else:
color = (0, 0, 255) # Default to red in case of any weird errors
# Draw rectangle around face
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)
# Show the similarity right underneath the box
if similarity is not None:
label = f"Similarity: {similarity:.2f}%"
text_pos_x = x1
text_pos_y = y2 + 25
cv2.putText(img, label, (text_pos_x, text_pos_y),
cv2.FONT_HERSHEY_DUPLEX, 0.8,
color, 2)
return img
"""
Detect the similarity between the two faces in the images
Input: image_path1, image_path2
"""
def detect_similarity(self, image_path1, image_path2):
img1 = Image.open(image_path1)
img2 = Image.open(image_path2)
img1_cropped = self.mtcnn(img1)
img2_cropped = self.mtcnn(img2)
# Create the embeddings for the images and calculate the similarity using cosine similarity
if img1_cropped is not None and img2_cropped is not None:
img1_embedding = self.resnet(img1_cropped.unsqueeze(0))
img2_embedding = self.resnet(img2_cropped.unsqueeze(0))
similarity = torch.nn.functional.cosine_similarity(img1_embedding, img2_embedding)
return similarity.item() * 100
return 0
"""
Process the images, draw the rectangles, and label the images
This is the main function to call to do the whole process
"""
def process_images(self):
similarity = self.detect_similarity(self.image_path_1, self.image_path_2)
img1_processed = self.draw_around_face_and_label(self.image_path_1, max(0, similarity))
img2_processed = self.draw_around_face_and_label(self.image_path_2, max(0, similarity))
combined_img = np.hstack((img1_processed, img2_processed))
cv2.imwrite(self.output_path, combined_img)
return max(0, similarity) # Return 0 if similarity is negative
# First example uses Chirstopher Nolan with different angles of his face
face_net_1 = FaceNetCompare('celebrity-1.jpg', 'celebrity-2.jpg', 'output_1.jpg')
# Second example uses Leonardo DiCaprio when he was young and old
face_net_2 = FaceNetCompare('celebrity-3.jpg', 'celebrity-4.jpg', 'output_2.jpg')
# Third example uses Christopher Nolan and Leonardo DiCaprio when he was a child to ensure 0 similarity condition
face_net_3 = FaceNetCompare('celebrity-1.jpg', 'celebrity-3.jpg', 'output_3.jpg')
# Process the images and get results
similarity_1 = face_net_1.process_images()
similarity_2 = face_net_2.process_images()
difference_1 = face_net_3.process_images()
print(f"Face Similarity: {similarity_1:.2f}%")
print(f"Face Similarity: {similarity_2:.2f}%")
print(f"Face Similarity: {difference_1:.2f}%")
FaceNetCompare Inputs and Outputs

Fig 5. Christopher Nolan 1 (celebrity-1.jpg) [5].

Fig 6. Christopher Nolan 2 (celebrity-2.jpg) [6].

Fig 7. Leonardo DiCaprio 1 Young (celebrity-3.jpg) [7].

Fig 8. Leonardo DiCaprio 2 Old (celebrity-4.jpg) [8].

Fig 9. Christopher Nolan similarities (high accuracy) [9].

Fig 10. Leonardo DiCaprio similarities (medium accuracy) [10].

Fig 11. The similarity between Leonardo DiCaprio and Christopher Nolan (low accuracy) [11].
Conclusion
In conclusion, FaceNet is an extremely influential and widely used facial recognition system that’s relevant even today. Its innovative approach of using the triplet loss function as well as embeddings has led to a great advancement in the facial recognition field. It has also spread widely throughout society, being used in fields such as security, medicine, and even parking!
Reference
[1] Faresse, Marc. “What Is Facial Recognition and How Does It Work?” EN - Dormakaba Blog, 4 Sept. 2020, blog.dormakaba.com/what-is-facial-recognition-and-how-does-it-work/.
[2] “Biometric Face Recognition System: Benefits, Uses, & How Does It Work? - Starlink India.” StarLink India -, 7 Nov. 2023, www.starlinkindia.com/blog/biometrics-face-recognition/.
[3] “Triplet Loss.” Wikipedia, Wikimedia Foundation, 11 Dec. 2024, en.wikipedia.org/wiki/Triplet_loss.
[4] Block Diagram of FaceNet Architecture. Download Scientific Diagram, www.researchgate.net/figure/Block-diagram-of-FaceNet-architecture_fig3_345983861. Accessed 14 Dec. 2024.
[5] Bahr, Lindsey. “Christopher Nolan on ‘interstellar’s’ Cosmic Success 10 Years Later.” Yahoo!, Yahoo!, 10 Dec. 2024, www.yahoo.com/entertainment/christopher-nolan-interstellar-cosmic-success-154800290.html.
[6] “Christopher Nolan Net Worth: Is He the Richest Director?” MARCA, Marca, 29 July 2023, www.marca.com/en/lifestyle/celebrity-net-worth/2023/07/29/64c535a446163f034e8b45a9.html.
[7] Seth, Radhika. “27 Throwback Photos of a Fresh-Faced Young Leonardo DiCaprio.” Vogue, Vogue, 11 Nov. 2024, www.vogue.com/slideshow/27-throwback-photos-of-leonardo-dicaprio.
[8] Dunn, Billie Schwab. “Leonardo DiCaprio Breaks His Own Dating ‘Rule.’” Newsweek, Newsweek, 10 June 2024, www.newsweek.com/leonardo-dicaprio-breaks-dating-rule-1909560.
[9] Image Output of our FaceNetCompare class comparing [5] and [6]
[10] Image Output of our FaceNetCompare class comparing [7] and [8]
[11] Image Output of our FaceNetCompare class comparing [5] and [7]
F. Schroff, D. Kalenichenko and J. Philbin, “FaceNet: A unified embedding for face recognition and clustering,” 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 2015, pp. 815-823, doi: 10.1109/CVPR.2015.7298682.
I. William, D. R. Ignatius Moses Setiadi, E. H. Rachmawanto, H. A. Santoso and C. A. Sari, “Face Recognition using FaceNet (Survey, Performance Test, and Comparison),” 2019 Fourth International Conference on Informatics and Computing (ICIC), Semarang, Indonesia, 2019, pp. 1-6, doi: 10.1109/ICIC47613.2019.8985786.
L. Li, X. Mu, S. Li and H. Peng, “A Review of Face Recognition Technology,” in IEEE Access, vol. 8, pp. 139110-139120, 2020, doi: 10.1109/ACCESS.2020.3011028.