Fashion Image Editing
Fashion image editing involves modifying model images with specific target garments. We examine various approaches to fashion image editing based on latent diffusion, generative adversarial networks, and transformers.
- Introduction
- Multimodal Garment Designer (MGD)
- Text-Conditioned Image Editing with Guided GAN Inversion (FICE)
- Multi-Garment Virtual Try-On (M&M VTO)
- Conclusion
- References
Introduction
Computer vision has played an increasingly large role in fashion-related problems such as the recommendation of similar clothing items, the recognition of garments, and the virtual try-on of outfits. There have been several efforts to expand on virtual try-on and employ computer vision-based editing of fashion images, which involves generating realistic fashion designs on images of models using a variety of inputs such as text prompts and sketches. Fashion image editing with computer vision can help a fashion designer efficiently visualize clothing items on any number of people without requiring their physical presence. Here, we examine three different approaches to fashion image editing:
- Multimodal Garment Designer (MGD), a latent diffusion-based solution that takes a model image, its pose map, a textual description of a garment, and a sketch of the garment as the inputs and produces an image of the model wearing the target garment as the output.
- Fashion Image CLIP Editing (FICE), a generative adversarial network-based solution that takes a model image and a textual description of a garment as the inputs and produces an image of the model wearing the target garment as the output.
- Multi-Garment Virtual Try-On and Editing (M&M VTO), a diffusion- and transformer-based solution that takes a model image, multiple garment images, and a textual description as the inputs and produces an image of the model wearing the target garments as the output.
Multimodal Garment Designer (MGD)
Many existing works explore the conditioning of diffusion models on various modalities, like text descriptions and sketches, to allow for more control over image generation. Multimodal Garment Designer (MGD), in particular, focuses on the fashion domain and is a human-centric architecture that builds on latent diffusion models. It is conditioned on multiple modalities: textual sentences, human pose maps, and garment sketches.
Given an input image \(I \in \mathbb{R}^{H \times W \times 3}\), MGD’s goal is to generate a new image \(I\)’ of the same dimensions that retains the input model’s information, while replacing the existent garment with a target garment.
Stable Diffusion Model
MGD builds off of the Stable Diffusion Model, which is a latent diffusion model that involves an encoder \(E\) to convert the image \(I\) into a latent space of dimension \(\frac{H}{8} \times \frac{W}{8} \times 4\), and a decoder \(D\) that converts back into the image space. It uses a CLIP-based text encoder \(T_E\), which takes input \(Y\), and a text-time-conditional U-Net denoising model \(\epsilon_{\theta}\). The denoising network \(\epsilon_{\theta}\) minimizes the loss:
\[L = \mathbb{E}_{\epsilon(1), Y, \epsilon \sim 𝒩(0,1), t} \left[ \left\| \epsilon - \epsilon_0(\gamma, \psi) \right\|\ _2^2 \right]\]where \(t\) is the time step, \(\gamma\) is the spatial input to the denoising network, \(\psi = \begin{bmatrix} t; T_E(Y) \end{bmatrix}\), and \(\epsilon \sim 𝒩(0, 1)\) is the Gaussian noise added to the encoded image.
The Stable Diffusion Model is a state-of-the-art text-to-image model widely known for its ability to generate high-quality, realistic images from textual descriptions. MGD broadens its scope to focus on human-centric fashion image editing, maintaining the body information of the input model while also incorporating an input sketch.
Conditioning Constraints
Instead of employing a standard text-to-image model, we also need to perform inpainting to replace the input model’s garment using the multimodal inputs. The denoising network input is concatenated with an encoded mask image and binary inpainting mask. Because the encoder and decoder are fully convolutional, the model can preserve spatial information in the latent space; thus, we can add constraints to the generation process, in addition to the textual information.
First, we can condition on the pose map \(P\), which represents various body keypoints, to preserve the input model’s pose information. MGD proposes to improve the garment inpainting by utilizing the pose map in addition to the segmentation mask. Specifically, it adds 18 additional channels to the first convolution layer of the denoising layer (one for each keypoint).
MGD also utilizes a garment sketch \(S\) to capture spatial characteristics that text descriptions may not fully be able to describe. Similar to the pose map, additional channels are added for the garment sketches. The final input to the denoising network is:
\[\gamma = \begin{bmatrix} z_t ; m ; E(I_M) ; p ; s \end{bmatrix}, \quad [p; s] \in \mathbb{R}^{H/8 \times W/8 \times (18+1)}\]where \(z_t\) is the convolutional input, \(m\) is the binary inpainting mask, \(E(I_M)\) is the encoded masked image, and \(p\) and \(s\) are resized versions of \(P\) and \(S\) to match the latent dimensions.
Training
Classifier-free guidance is used during the training process, meaning the denoising network is trained to work both with a condition and without any condition. This process aims to slowly move the unconditional model toward the conditional model by modifying its predicted noise. Since MGD uses multiple conditions, it computes the direction using joint probability of all conditions. We also use unconditional training, where we replace one or more of the conditions with a null value according to a set probability. This improves model versatility, as it must learn to produce results when certain conditions are taken away.
Datasets
To obtain data to train and test the model, two popular fashion datasets, Dress Code and VITON-HD, were extended with text descriptions and garment sketches. Half of the text was manually annotated, while the rest was automated using a CLIP model that assigned nouns to each garment. A pre-trained edge detection network called PiDiNet was used to generate garment sketches.
Evaluation and Metrics
Many different metrics can be used to assess the performance of MGD. Fréchet Inception Distance (FID) and Kernel Inception Distance (KID) measure the differences between real and generated images, and thus help represent the realism and quality of images. The CLIP Score (CLIP-S) captures the adherence of the image to the textual input. MGD also uses novel metrics: pose distance (PD), which compares the human pose of the original image to the generated one, and sketch distance (SD) which reflects how closely the generated image adheres to the sketch constraint.
Comparison of Methods
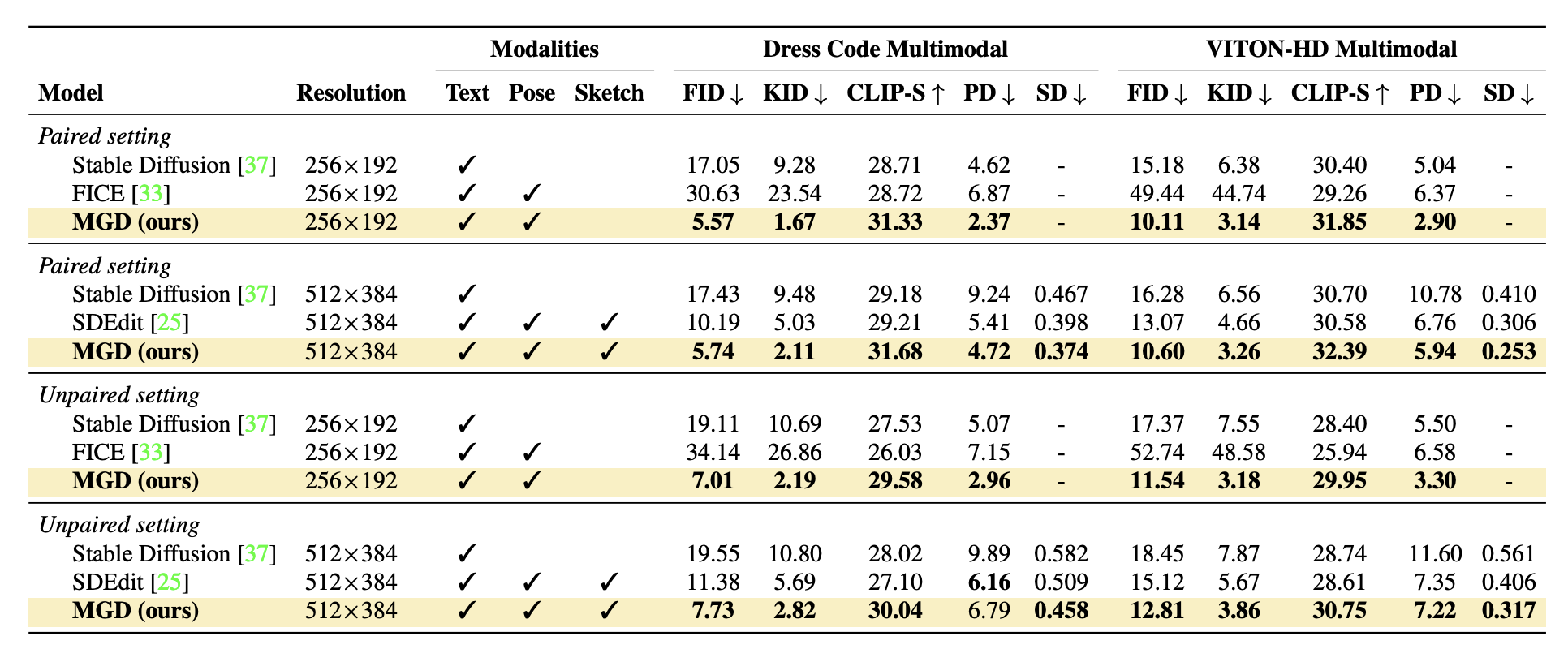
Fig 1. Comparison of results on the Dress Code Multimodal and VITON-HD Multimodal datasets [1].
MGD was tested for paired and unpaired settings; in the paired settings, the conditions refer to the garment the model is wearing, while in the unpaired settings, the target garment differs from the worn one. The results on the Dress Code Multimodal and VITON-HD Multimodal datasets outperform competitors in both realism and adherence to the inputs (text, pose map, garment sketch). It produces much lower FID and KID scores compared to other models, slightly higher CLIP scores, and lower PD and SD scores due to the pose map and garment sketch conditioning. Stable Diffusion produces realistic results but fails to preserve the model’s pose information because such data is not included in the inputs to the model.
Text-Conditioned Image Editing with Guided GAN Inversion (FICE)
Fashion Image CLIP Editing (FICE) also relies on text descriptions, as opposed to the traditional method of overlaying clothing images onto a target person, to enable broader creativity through natural language. FICE builds on the standard GAN inversion framework and the pre-trained CLIP model using semantic, pose-related, and image-level constraints.
Given a fashion image \(I \in \mathbb{R}^{3 \times n \times n}\) and some corresponding text description about the image \(t\), FICE synthesizes an output image \(I_f \in \mathbb{R}^{3 \times n \times n}\) that adheres as closely as possible to the semantics described in \(t\).
Generative Adversarial Network (GAN) Inversion
A Generative Adversarial Network (GAN) is a machine learning model that uses a generator and discriminator to generate data. GAN inversion projects a target image into the GAN’s image generation space. FICE uses constrained GAN inversion over the latent space of pre-trained a StyleGAN model. This model eliminates artifacts and stabilizes the training process to incorporate the semantics conveyed by the input text description into the generated image.
FICE tailors its GAN inversion to fashion images by enforcing constraints like pose preservation, semantic alignment, and image stitching.
FICE Methodology
Given an input image, FICE initializes a latent code using the GAN inversion encoder. Dense-pose and segmentation maps are then computed for body structure and regions of interest. The initial latent code is iteratively optimized to align the synthesized image with the text. This creates latent code:
\[w^* = arg_wmin \{L(I,G(w),t)\}\]where \(w^*\) is the optimized latent code, \(L\) is the loss, \(I\) is the original image, \(G(w)\) is the GAN generator output, and \(t\) is the text description.
Finally, the optimized GAN image \(I_g^*\) is combined with the original image \(I\) via stitching to ensure identity preservation and generate output image \(I_f\).
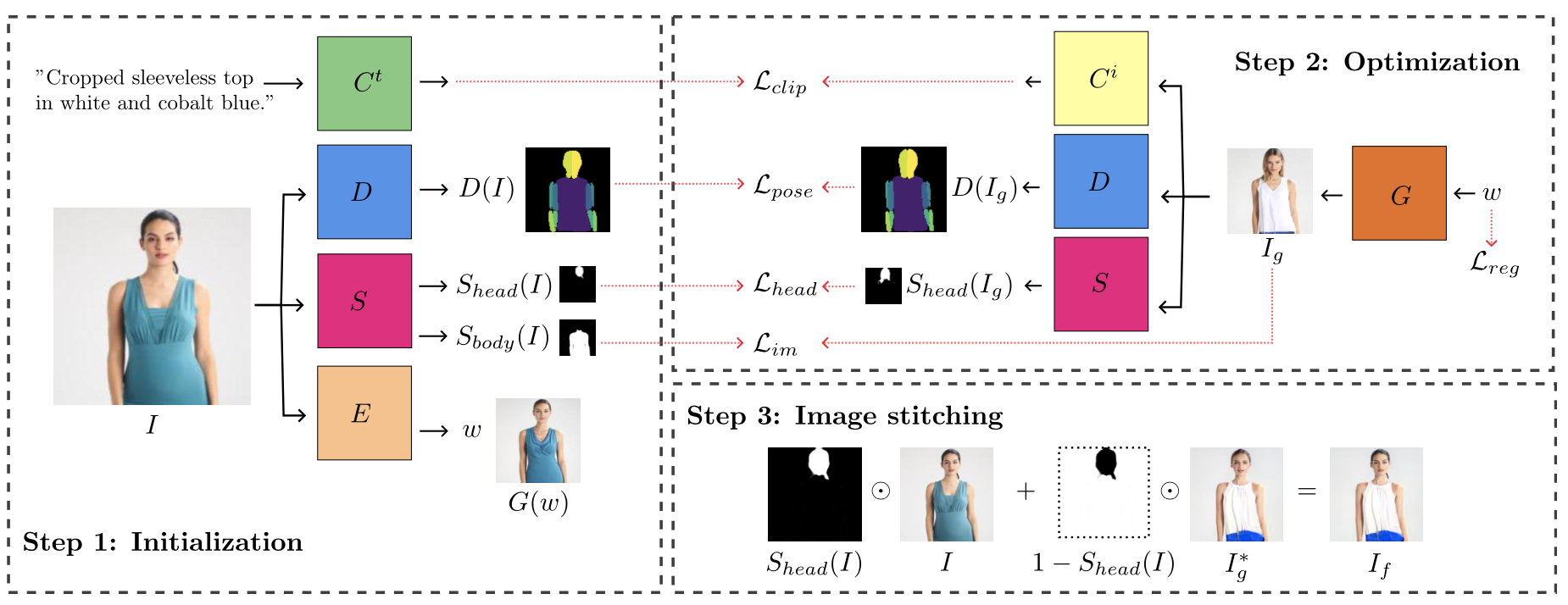
Fig 2. FICE Editing Model: Overview with optimizations enforcing semantic content, pose preservation, image consistency, and latent code regularization. [2].
Datasets
FICE used VITON, a fashion dataset with training and test sets, to train the StyleGAN generator and encoder and evaluate performance. DeepFashion, another dataset, trains the segmentation model. The segmentation masks are divided into body, face and hair, and background; the masks are then padded and downscaled to the ideal resolution. Fashion-Gen, a dataset with image and text descriptions, provided a source of clothing descriptions necessary for testing.
Evaluation and Metrics
FICE can edit clothing styles while preserving poses and generating realistic textures without 3D models. It excels at preserving image identity and avoiding entanglement issues. Removing any loss terms—pose preservation, image composition, or latent-code regularization—negatively impacts key metrics and is, therefore, important for high-quality results.

Fig 3. Results generated by FICE with various text input [2].
However, a disadvantage of the FICE model is the inherited constraints of CLIP. FICE is limited to 76 tokens and thus has a maximum length of text descriptions from the byte-pair encoding technique. FICE’s gradient optimization also creates slower processing speeds. Fine tuning CLIP on larger datasets can mitigate some of these problems and reduce semantic issues.
Comparison of Methods
FICE and MGD had identical modalities as MGD retrained all the main components of FICE on newly collected datasets. However, MGD far outperformed FICE in terms of realism and coherency. FICE can produce images consistent with text conditioning, though the images are less realistic than models like MGD.
Multi-Garment Virtual Try-On (M&M VTO)
The M&M VTO (multi garment virtual try on and editing) model leverages a UNet Diffusion Transformer to take an image of a person along with multiple garments to output a visualization of how the garments would look on the person. In addition, the model supports conditioning of the output, allowing users to make slight adjustments of the output image – for example, users can pass prompts such as “rolling up the sleeves” or “tuck in the shirt” to edit the output. Typically, virtual try on models, like the models outlined above, consider the target outfit as one garment. This model separates garments by top and bottom garments, formulating the problem to be to impose two different garments on a human. This allows for more mixing, matching, and editing of layouts. Further, the model attempts to solve problems in VTO (Virtual Try On) of preserving small, yet important, details of garments, and preserving the identity of the human image input without leaking the original garments to the final result. Previous methods use diffusion based models to solve the former problem, using noising to prevent leaking of original garments, however, these solutions are often memory heavy and also can remove important human identity information. The model attempts to additionally solve these problems through its architecture and training methods.
Methodology
The model first uses a single stage diffusion model to synthesize the 1024x512 image inputs, opting to not perform extra super resolution (SR) stages as is common in many state of the art image generation models. Super resolution stages involve the model producing low resolution images first, and then using super resolution models to upscale the image. However, the authors found that the base low resolution model resulted in excess downsampling on the input image, losing important information and garment details in the process. Instead, they designed a progressive training strategy where the model first produces low resolution images, and then the same model progressively works to produce higher resolution images throughout training. This allows the model to leverage what it has learned about the data at lower resolutions and add to it as it attempts to produce higher resolution images.
The model then tries to solve the problem of human identity loss and clothing leakage through finetuning the person features only, rather than finetuning the entire model during post processing. To do this, the authors designed the UNet Diffusion Transformer to isolate the encoding of person features from the denoising process using the “stop gradient”.
Finally, the authors created text based labels representing various garment layout attributes, like rolled sleeves, tucked in shirt, open jacket. To extract these attributes, the authors decided to formulate the problem as an image captioning task – they finetuned a PaLI-3 model using 1.5k labeled images to caption the image based on its attributes.
In sum, a forward process takes the input image and adds noise. A UNet model then encodes the noised image, encodes the top garment, bottom garment, and person’s key features in the DiT transformer. It then decodes the output to remove noise and produce the denoised image.
Data
The model uses training pairs, consisting of a person image and a garment image. The garment image can either be an image of a garment on a flat surface or a garment on a person. Then, garment embeddings for the upper, lower, and full garments are computed and matched/mapped to the garments in the person image. Any embedding that was not matched is set to 0.
Further, the person image and garment image are extracted for their 2D pose keypoints, and a layout input (text prompt) represents the desired attributes of the garment. Additionally, a clothing agnostic RGB image is generated, to provide a neutral template of the person. These inputs are known as “ctyron”.
The model is trained on a “garment paired” dataset of 17 million samples, where each sample consists of two images of the same garment in two different poses/body shapes. Additionally, it is trained on a “layflat paired” dataset of 1.8 million samples, where each sample consists of an image with a garment laid out on a flat surface and an image of a person wearing the garment.
Architecture
The UDiT network can be described as the following, where t is the diffusion timestep, zt is the noisy image corrupted from ground truth x0, and ^x0 is the predicted clean image at timestep t.
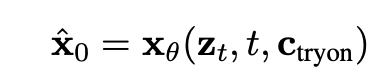
Fig 4. Description of the UDiT network [3].
The DiT blocks process the lower resolution feature maps for attention operations to learn, and the person image encodings are introduced in this stage. Below is a diagram of the architecture:
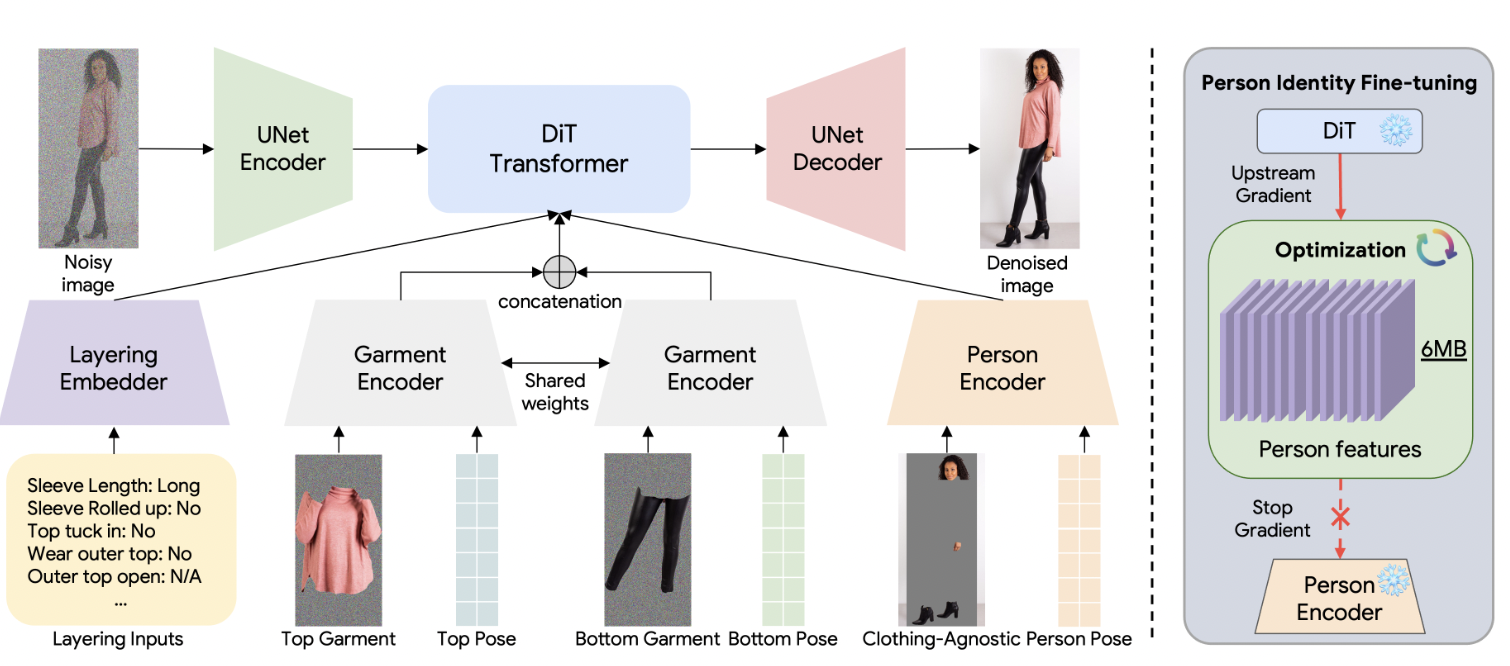
Fig 5. Diagram of model architecture [3].
Evaluation and Metrics
The model was compared with TryOnDiffusion and GP-VTON model on two test sets. M&M VTO outperformed these models in FID (frechet inception distance) and KID (Kernel Inception Distance). In a user study where 16 non-experts evaluated the results, experts preferred M&M VTO 78% of the time over TryOnDiffusion and 55% of the time over both GP-VTON and TryOnDiffusion.
Conclusion
MGD, FICE, and M&M VTO approach fashion image editing in three different ways, each achieving impressive results.
MGD uses a latent diffusion-based model with multimodal inputs (pose maps, textual descriptions, and sketches) to visualize garments on model images. The approach involves inpainting with pose and sketch conditioning, and the model is trained with classifier-free guidance. MGD outperforms competitors in realism and adherence to inputs.
FICE uses a GAN inversion-based model with CLIP for text-conditioned image editing. FICE preserves pose and image characteristics using semantic and image-level constraints. It produces realistic images but is less consistent than MGD, and is also limited by CLIP’s short maximum token length.
Finally, M&M VTO is a diffusion transformer that uses garment images and text prompts for high-resolution virtual try-ons. It allows for mixing and matching of multiple garments on models and preserves person identity by solely fine-tuning person features during post-processing. M&M VTO outperforms competitors in realism and user preferences.
Fashion designers may choose to use any of these models depending on their workflow and preferences. Computer vision is truly beginning to shape the future of fashion design!
References
[1] Baldrati, Alberto, et al. “Multimodal Garment Designer: Human-Centric Latent Diffusion Models for Fashion Image Editing.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[2] Pernuš, Martin, et al. “FICE: Text-Conditioned Fashion Image Editing With Guided GAN Inversion.” ArXiv abs/2301.02110 2023, http://arxiv.org/abs/2304.02051.
[3] Zhu, Luyang, et al. “M&M VTO: Multi-Garment Virtual Try-on and Editing.” ArXiv.org, 2024, arxiv.org/abs/2406.04542.