Dynamic Hand Gesture Classification
In this report, we review three deep learning models in the domain of static and dynamic hand gesture classification.
- Overview
- Recurrent 3D Convolutional Neural Networks
- Mediapipe and Convolutional Neural Networks
- Three-Stream Hybrid Model
- Comparison
- Conclusion
- References
Overview
Hand gestures are a form of non-verbal communication that conveys information and emotion through the motion of hands. This has significant applications in human-computer interfaces; hand gesture recognition systems can implement touchless systems, sign language translation, or assist the impaired. One of the challenges in hand gesture recognition is the processing of a dynamic hand gesture (DHG). Unlike static hand gestures, which convey information through the basic pose of the hand, DHGs communicate information through both spatial and temporal dimensions of the hand pose. Thus, any system that processes DHGs must contain the context of recently seen movements to formulate a hand gesture classification, disregard any invalid or unrecognized hand gestures over a data stream, and achieve computational performance such that classification can be performed in a real-time setting.
In recent years, deep learning techniques have achieved human-like accuracy in DHG classification. These techniques have all taken both spatial and temporal information into account, but vary widely in methodology. This report will highlight three different deep learning architectures that classify dynamic hand gestures. The first model builds upon previous Recurrent Neural Networks to create a Recurrent 3D Convolutional Neural Network to encode both spatial and temporal states for the classification of DHGs. The second model uses Google’s Mediapipe to extract landmarks of the user’s hand to create a more accurate classification. The third model is a hybrid deep learning model that obtains high-level features with ImageNet, ResNet50v2, and Mediapipe to increase dynamic hand recognition accuracy.
Recurrent 3D Convolutional Neural Networks
Overview
The common data pipeline to perform DHG recognition with 3D CNNs is to create two frame queues, one for detection and the other for classification, where the classification queue extends farther back in time. A lightweight detection 3D CNN would be used to detect if a hand gesture has been performed in its frame queue; if so, then the heavier 3D CNN model would perform classification within its queue to categorize the gesture that was being performed. Researchers at NVIDIA proposed an implementation that breaks away from this architecture and jointly detects and classifies a DHG, since the previous methodology’s accuracy would be upper-bounded by the lightweight detector. A recurrent 3D convolutional neural network is proposed, capturing both short-term temporal data through the CNN, while also encoding long-term temporal data through the hidden state of the recurrent network.
Architecture
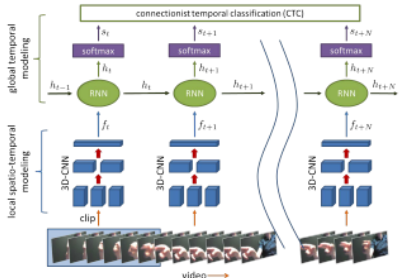
Figure 1: R3DCNN. A 3D-CNN encoder transforms a subset of the data stream as inputs for each time step of the RNN [1].
Researchers proposed a combination of the two widely known temporal modelling architectures: the recurrent neural network (RNN) and the 3D convolutional neural network (3D-CNN). This architecture is designed to jointly detect and classify DHGs as well as provide rapid feedback for real-time video streams.
A video stream can be divided into 8-frame sections called a “clip”; each clip can be considered as the initial input for each timestep. Through a 3D-CNN encoder, spatio-temporal filters can transform each clip into a local feature representation to be passed into each timestep input of the RNN. As shown above in (1), the RNN takes a feature representation f_t, and with the previous hidden state h_(t-1), which implicitly captures historical information of the previous inputs in the sequence, h_t. This current hidden state can be transformed into softmax probabilities to classify the clip as one of the DHG classes, or the “no gesture” class.
Training
Instead of utilizing the negative log-likelihood (NLL) loss function to measure how well a model’s predicted probabilities aligned with a one-gesture training sample classification, the connectionist temporal classification (CTC) loss function was proposed. CTC was opted for due to its flexibility in assigning predictions to a sequence of segmented on-line input streams and its ability to assign a “no gesture” output to a segment. In CTC, the path π is a mapping of the input sequence X to a sequence of class labels y, where repeated class labels and “no gesture” labels are omitted. The temporal aspect of classification is ignored with this loss function; if two paths π_1 and π_2 have the same sequence of classifications, the time these classifications occurred within their respective input streams does not matter; they are considered equivalent. p(y|X), the probability of observing a particular sequence y given an input sequence X, is the sum of all possible paths mapping to sequence X. Thus, the calculation for CYC loss is -ln(p(y|X)). Now, the network can train by computing the probability of observing a particular gesture at a timestep in an input sequence, instead of classifying entire video streams in a coarse-grained manner.
Results
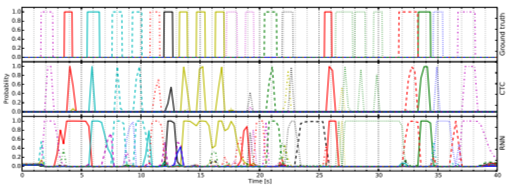
Figure 2: comparison of gesture recognition performance between ground-truth, the R3DCNN trained on CTC, and the R3DCNN trained on negative log-likelihood [1].
R3DCNN trained with CTC performs well regarding early detection in online operation, according to (2). R3DCNN + CTC performs with significantly fewer false positive classifications. Additionally, if the same gesture is performed repeatedly in a sequential fashion, R3DCNN + CTC outputs a classification for each instance of the gesture, while R3DCNN + NLL “merges” each instance into a single long-running classification. Additionally, this data indicates that dynamic gestures can be classified with R3DCNN + CTC within 70% of its completion, satisfying the real-time and “negative lag” requirements that the R3DCNN set out to achieve. R3DCNN + CTC achieves a 0.91 AUC score, compared to R3DCNN + NLL with a 0.69 AUC score, due to the former classifying less false positives.
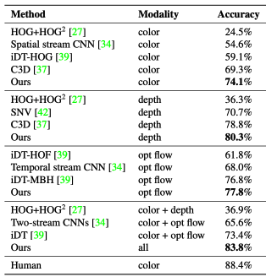
Figure 3: label-wise classification accuracy between different architectures and modalities [1].
R3DCNN + CTC’s classification accuracy was state-of-the-art for the time. R3DCNN performs far better than 2D CNNs (which don’t account for temporal context), and its high accuracy throughout different modalities (74.1% for color modality, 80.3% for depth modality, 77.8% for optical flow, and 83.8% for modality fusion) indicates that encoding global temporal modeling with an RNN as well as traditional short-term temporal modeling with a 3D-CNN significantly improves DHG classification.
Conclusion
R3DCNN combines a 3D-CNN encoder and an RNN to store local and global temporal features, respectively. By training with the connectionist temporal classification loss function, R3DCNN can perform on-line DHG recognition, classifying a hand gesture potentially before the gesture has been completed, while separating repeated hand gestures into different classification instances.
Mediapipe and Convolutional Neural Networks
Overview
This paper documents the development of a real-time ASL recognition system. This is accomplished using a combination of computer vision techniques with more typical ML ideas. With the use of the Mediapipe framework to track hands and extract features, accompanying a CNN to classify said gestures, they were able to achieve 99.95% accuracy. With such incredible accuracy in real-time situations, the authors argue that such systems could soon be implemented to help those with hearing impairments.
Architecture
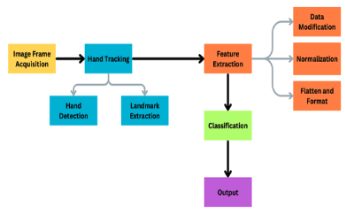
Figure 4: High-level overview of system’s architecture [2].
Researchers used Google’s Mediapipe for hand tracking. Mediapipe offers robust and efficient hand pose estimation. It tracks a total of 21 landmarks from each hand in frame. Based on these landmarks, the model can estimate what pose is being presented as well as understand if the information being processed is logical.
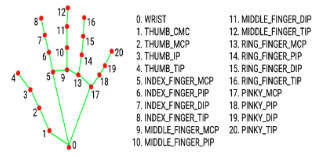
Figure 5: Landmarks from Mediapipes tracking [2].
In order to properly extract features in an invariant fashion, normalization techniques were implemented. Firstly, they calculated the offset of each landmark relative to the hand’s center allowing for spatial information to be preserved. This information was then scaled and normalized allowing for consistent data for different hand sizes, distances from camera, etc. Finally, this data was then flattened into a 1D array and then properly formatted for classification.
Results
Training the model on ~166,000 samples, corresponding to roughly 4,500 photos per class and splitting training and testing sets 80% and 20% respectively, researchers achieved a perfect 100% accuracy on their testing set.

Figure 6: Examples of the model’s output [2].
Researchers also live-tested their model, showing correct classification on live video streams demonstrating incredible capabilities for its application.
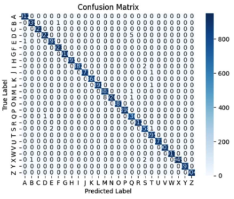
Figure 7: Confusion Matrix relating to output of testing [2].
As shown by (7), they were able to achieve incredible accuracy only having just a few misclassifications over hundreds of thousands of attempts.
Conclusion
The researchers believe that the future for such a model is to increase the amount of hand gestures the model classifies as well as perform classification on dynamic hand gestures since this model does not preserve temporal context. Such classification is a large jump and possibly requires other deep learning architectures and approaches. However, even as is it is claimed that this models and others like it have an incredible ability to improve quality of life for those with hearing impairments and or their loved ones.
Three-Stream Hybrid Model
Overview
This advanced deep learning model combines “RGB pixel values”, as well as skeleton-based features to recognize hand gestures dynamically. The main goal of this deep learning model is to get a high level of features that will increase the hand recognition’s performance accuracy. The model performs this by obtaining the vision-based image and video-based hand gesture recognition. As usual, data is inputted through a preprocessing and augmentation pipeline to ensure uniformity and generalizability in their training samples. In their feature extraction stage, they utilized ImageNet and ResNet modules, pre-trained models in the first two streams of their architecture. Additionally, the 3rd stream extracts hand pose key points using Mediapipe and enhances them with stacked LSTM for hierarchical feature creation.
The model takes hand gesture videos to grasp what hand gesture is occurring and then segments the video to spotlight the gesture itself, subtracting it from superfluous background elements, such as useless background elements and clutter. To combat real-world variability, their model introduced controlled changes through augmentation. The following working flow of their methodology is shown below:
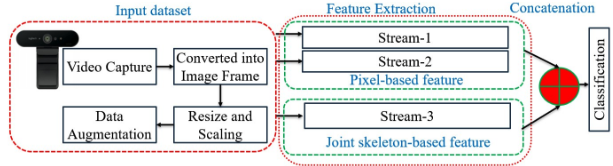
Figure 8: Architecture of the Three-Stream Hybrid Model [3].
Dataset
The researchers’ dataset consists of 10 different dynamic hand gesture movements: “left”, “right”, “up”, “down”, “bye”, “hi”, “close”, “open”, “thumbs down”, and “thumbs up”. They gathered these data through a Logitech BRIO Ultra HD Pro 4 webcam, as well as sourcing performances of dynamic hand gestures from 17 individuals. In addition, each participant completed each activity 5 times to create each video. Their video resolution was 1080x1920 with 30 FPS. There were 1500 images per 10 tasks per person and 150 images per gesture collected, for a total of 25500 original dataset images.

Figure 9: Input images of Dynamic Hand Recognitions [3].
Preprocess and Augmentation
Data preprocessing starts with a uniform resolution of 128x128 pixels and a normalization range of 0-1 for pixel intensity. This is the typical preprocess in deep learning techniques to ensure the data is clean for a deep learning model. In addition, they employed 3 augmentation methods: brightness, horizontal flip, and rotation of 10 degrees, respectively.
As mentioned before, the researchers used Mediapipe, a ML algorithm to estimate the hand joints. Its initial job is to recognize the existence of a hand within the camera image, and then proceed to calculate the 3D coordinates of the hand joints. As a result, they obtained roughly 258 positions per image and 33 points for pose estimations. Note that each point has 4 characteristics: X, Y, Z, and Visibility, thus the total # of hand pose estimation points is 132. Lastly, they calculated that the left and right hands landmarks have 21 points. It has the properties X, Y, Z, thus the total # of landmark positions for the left and right hands is 63. An example of the landmark position detection of the input image is shown below:

Figure 10: Example of landmark information of the input image [3].
Training
In each of the streams, they use a hybrid module that combines both LSTM and GRU, allowing the model to get long-term dependencies with LSTM, while benefiting computational efficiency with GRU. In the first stream, ImageNet anchors this one. ImageNet enhanced the model’s robustness. Then, the features are then split into 2 branches: 1st branch combines LSTM and GRU’s capabilities which handles both long and short term dependencies, while the 2nd branch employs a Gather operation that aggregates features.
For the 2nd stream, the researchers used a ResNet50v2 architecture to account for residual connections and address the vanishing gradient problem. Similarly to the first stream, it is also split into 2 branches: 1st branch integrates two GRU modules, a dropout layer for model generalization, and a dense layer that amplifies model intricacy. The 2nd branch mirrors the first stream’s strategy to ensure consistency in fortifying the robust, sequential data.
For the 3rd stream, the researchers deployed Mediapipe for hand pose extraction. The stream then utilized a sequence consisting of 3 LSTM modules and 2 GRU modules because it encapsulates the sequential data and ensures an exhaustive representation of the gestures in question.
Finally, the model concatenated all of the streams’ features to produce the final features that will be fed into the dense classification layer. By combining all model outputs, the hybrid model emerges as an efficient, robust, and intricate feature extraction. Note that the researchers partitioned their dataset with 60% to training, 20% to validation, and 20% to testing, respectively, and the experiments were conducted in a lab environment using a GeForce GTX 1660 Ti GPU, CPU, and 16 GB RAM, and then evaluated the dataset for the 10-class classification task.
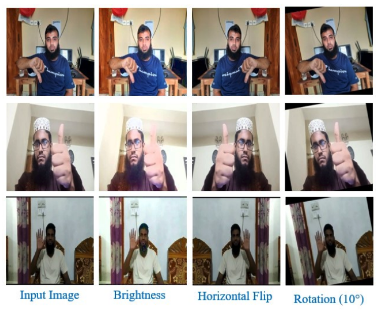
Figure 11: The augmentation process of the input images [3].
Results
Listed in the table below are the several evaluation metrics that they used to evaluate the hybrid model:

Figure 12: Evaluation metrics of the processed system [3].
The gestures for right, left, up, down, bye, and thumbs down have high performance, while gesture left has a precision of 97.78% with recall of 100%. The rest of the performances are shown below:
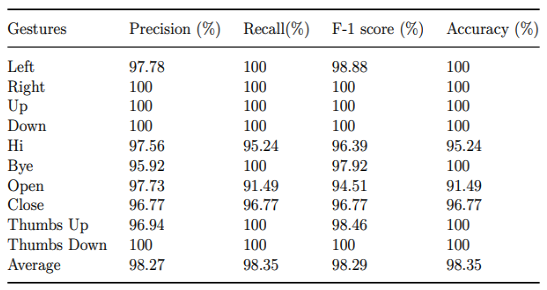
Figure 13: Label-wise classification results using proposed hybrid model [3].
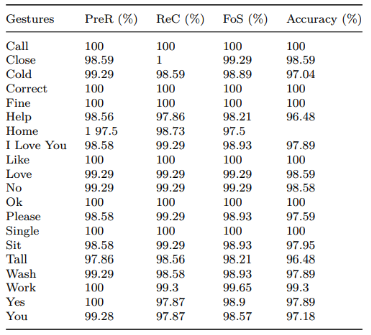
Figure 14: Classification accuracy of proposed hybrid model on benchmark dataset [3].
As a result, these accuracy levels exceeding 97% showcase the robustness of the hybrid model. But, it is essential to highlight gestures like “cold”, “help”, “tall”, and “you”, which all scored slightly lower.
Conclusion
This model capitalized the strengths of various architectures and fine-tuned specifically for hand gesture recognition, dynamically. The model also outperformed the CNN Feature Fusion which has a reported accuracy of 97.28%. It is safe to say that this model has a bright future ahead of us.
Comparison
This section will go over a detailed comparison of all the 3 models that have been covered thus far.
R3DCNN is a combination of recurrent neural networks and 3D convolutional neural networks that divides an input stream into “clips” and sequentially processes each clip and outputs a softmax prediction on the type of DHG classified, including no gesture. Training with the connectionist temporal classification loss function, R3DCNN can perform on-line video stream classification with zero-to-negative lag to classify a DHG with 83.8% accuracy when fusing color, depth, and optical flow modalities.
The Mediapipe model consists of some data preprocessing that is then fed into a CNN to classify extracted features and gestures. The live feed is interpreted by Google’s media pipeline extracting key landmarks and their positions relative to the hand’s center to keep positional information. The CNN then classifies this information extremely accurately giving a final classification and bounding box. The bounding box is simply given from Mediapipe’s feature extraction and the class is obviously given by the output of the CNN. However, the model does not include a temporal aspect to it, making it struggle to classify dynamic gestures. However, it achieves >99% on static gestures.
The three-stream hybrid model that consists of ImageNet, ResNet50v2, and Multipipe architectures works by taking all of the streams’ features and producing the final features that will be fed into the dense classification layer. To backtrack, in the first stream, ImageNet anchors this. ImageNet enhanced the model’s robustness, as well as LSTM and GRU’s capabilities to handle both short and long-term dependencies. For the 2nd stream, they used ResNet50v2 to account for the vanishing gradient problem, as well as residual connectivity. So then it is the stream’s strategy to ensure consistency in making sure that the sequential data is robust. Lastly, the 3rd stream uses the Mediapipe to handle pose extraction and also uses 3 LSTM and 2 GRU modules to ensure an exhaustive representation of the gestures. Lastly, the results of this model is great, achieving 97% accuracy in most gestures, however, it has slightly less accuracy on gestures like “cold”, “tall”, and “help”.
Each different deep learning technique has different strengths and weaknesses in their respective domains. R3DCNN performs very well in speed and instance segmentation. The model can classify a dynamic hand gesture within 70% of its completion in on-line testing and can correctly identify repeated instances of a hand gesture. However, due to the nature of hidden states within RNNs not being able to encode a sufficient amount of global history and RNNs being prone to vanishing gradients, the model only has an 83.8% test accuracy when fusing all color, depth, and optical flow modalities. Thus, use the R3DCNN model if the user requires zero-to-negative lag during dynamic hand gesture classification.
The Mediapipe model performs significantly well as it estimates the hand pose itself instead of the general shape of the hand like other deep learning models. The model is invariant to scaling and different hand sizes, allowing for significant generalization potential. This is evident in the >99% test accuracy when classifying static hand gestures. However, since the Mediapipe does not have a temporal aspect to its pipeline, it treats each frame as a separate input; it is unable to store context or local history to generalize to dynamic hand gestures. Thus, use the Mediapipe model if the user is solely interested in static hand gesture classification.
The three-stream hybrid model passes a video stream input the ImageNet, ResNet50v2, and Multipipe models to produce a final classification. This ensures the hybrid model’s robustness, leading to a 97% test accuracy in dynamic hand gesture classification. However, its hybrid nature is computationally expensive to run, requiring significant hardware capabilities for the user to address. Thus, use the three-stream model if the user is concerned with near-perfect dynamic hand gesture classification and has the computational resources to utilize this model.
Conclusion
The exploration of dynamic hand gesture recognition systems demonstrates how the advancements in deep learning and computer vision have significantly improved the accuracy and efficiency of gesture recognition. Thus, 3 models were examined carefully, each of them having unique strengths and weaknesses.
The first model, R3DCNN, combines with a 3D-CNN encoder and an RNN. It captures both local and global temporal features for online gesture recognition. By utilizing the CTC loss, it achieves high performance in dynamic settings, classifying gestures, and 83% accuracy when fusing modalities such as color, depth, and optical flow. Lastly, its ability to process gestures in real-time with minimal lag marks it as a cutting-edge solution for dynamic recognition tasks.
The second model, Mediapipe-CNN, does great in gesture recognition such as leveraging Google’s Mediapipe framework to achieve a 99% accuracy in real-time ASL classification. However, its lack of temporal modeling limits its effectiveness in dynamic gesture recognition, so there would need to be more development in this area.
The last model, a 3-stream that combines ImageNet, ResNet50v2, and Mediapipe architectures. This advanced deep learning model captures diverse data representations across RGB, skeleton-based features, and key pose points. By integrating GRU and LSTM modules, it excels in handling both short and long-term dependencies, achieving over 97% accuracy in most gestures. Its robustness and versatility show the potential multi-stream architectures in complex gesture recognition tasks, despite slight challenges in some gesture recognitions such as “cold”, “help”, and “you”.
Overall, these systems collectively demonstrate how combining temporal, spatial, and hybrid approaches can enhance DHG recognition. Thus, future research and development could involve refining these great models to further increase classification and recognition accuracies, as well as reduce computational costs. These advances have the potential to revolutionize human-computer interaction through ASL, offering tools for accessibility usage to several people in need.
References
[1] Molchanov, Pavlo, et al.: “Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[2] Kumar, Rupesh, et al.: “Mediapipe and CNNs for Real-Time ASL Gesture Recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2023.
[3] Rahim, Md Abur, et al.: “An Advanced Deep Learning Based Three-Stream Hybrid Model for Dynamic Hand Gesture Recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2024.