Audio-Visual Sentiment Analysis
Our group explored the cutting-edge field of Audio-Visual Sentiment Analysis (AVSA), and how multimodal data (comprising of visual, audio, and textual inputs) can be combined to better understand human emotion.
Introduction
The rise of multimedia platforms such as YouTube, TikTok, and Instagram has transformed the way emotions are expressed and perceived online. These platforms feature a huge amount of audio and visual cues that convey sentiment more effectively than simply text. Traditional sentiment analysis methods are effective for written text but struggle tremendously to interpret the complexity of human emotions from speech tones, facial expressions, and gestures. Audio-Visual Sentiment Analysis (AVSA) uses both visual and auditory cues to capture the nuanced expressions of human sentiment in the context of videos.
Sentiment analysis in videos is much harder than in plain text because of the complexity of audiovisual content. After all, facial expressions, body language, tone of voice, and verbal content all contribute to the overall emotional message. Common unimodal approaches can’t capture these interactions, forcing us to use multimodal solutions. A perfect example of this is that of a sarcastic comment - it may appear positive when analyzed textually but conveys a negative sentiment when combined with an exasperated tone and a disapproving facial expression.
Objectives
- To analyze the effectiveness of multimodal sentiment analysis in improving emotion prediction accuracy.
- To evaluate state-of-the-art attention mechanisms for modeling cross-modal dependencies.
- To explore the potential applications and challenges of deploying these techniques in real-world scenarios.
Key Components
Audio-visual sentiment analysis combines three modalities: visual, audio, and text. Each modality contributes unique insights into emotional states, and their integration allows us to conduct a holistic analysis of human emotion.
1. Visual Analysis
Visual features such as facial expressions, gestures, and body language play an important role in conveying emotions. Key analysis techniques include:
- Facial Landmark Detection: This technique identifies key points such as eyes, nose, and mouth to track expressions dynamically.
- Convolutional Neural Networks (CNNs): This technique finds deep hierarchical features from video frames for emotion classification.
For example, a smile detected in visual data often correlates with positive sentiment, but subtle variations in facial tension may indicate sarcasm or discomfort (such as a polite smile you give to someone when they simply won’t stop talking).
2. Audio Analysis
Audio signals reveal emotions through speech tone, pitch, and intensity. Key analysis techniques include:
- Mel-frequency Cepstral Coefficients (MFCCs): This technique represents audio signals in a frequency domain.
- Speech Prosody Analysis: This technique finds rhythm, stress, and intonation patterns.
Example: An elevated pitch combined with a rapid speech rate may indicate excitement, while a flat tone suggests apathy.
3. Textual Analysis
While not as important as audio-visual data, text input provides crucial context for our audio and visual features. Natural Language Processing (NLP) models analyze text for:
- Sentiment Classification: This technique determines polarity (positive, negative, neutral).
- Contextual Understanding: This technique recognizes idiomatic expressions, sarcasm, or contextual cues (unlike my mom, who doesn’t understand my sarcasm lol).
For example, the phrase “I’m fine” may appear neutral in isolation but acquires a negative connotation when paired with a frustrated tone and averted gaze.
Methodologies
Gaussian Adaptive Attention Mechanism (GAAM)
Summary
The Gaussian Adaptive Attention Mechanism (GAAM) is one of our favorite mechanisms that addresses the challenges in modeling non-stationary data. It incorporates learnable Gaussian parameters for dynamic feature recalibration to enhance explainability and robustness. This lets GAAM excel in multi-modal tasks such as emotion recognition and text classification, our goal for this project.
Key Contributions
- GAAM introduces a learnable Gaussian-based attention mechanism where the mean and variance are dynamically adjusted. This significantly improves the model’s ability to capture contextually significant features across our three modalities of text, audio, and vision.
- GAAM integrates an Importance Factor (IF), improving the explainability of attention outputs by quantifying the significance of different features.
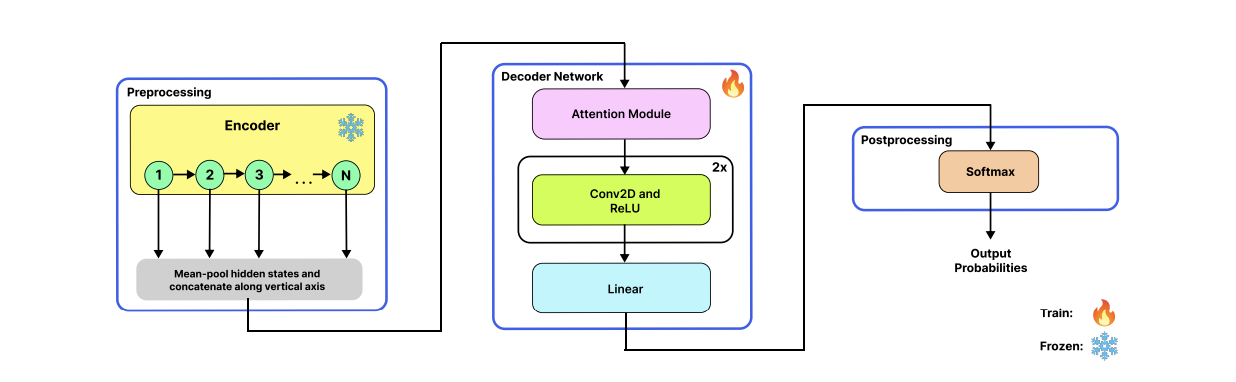
Technical Innovations
1. Utterance-Level Feature Extraction
Unimodal Encoding
Each statement \(u_i\) in the dialogue is processed to extract features for each modality:
- Audio features: \(x_i^a \in \mathbb{R}^{d_a}\)
- Visual features: \(x_i^v \in \mathbb{R}^{d_v}\)
- Text features: \(x_i^l \in \mathbb{R}^{d_l}\)
For text, a Transformer encoder generates semantic features: \(x_i^l = \text{Transformer}(u_i^l, W_l^\text{trans})\), where \(W_l^\text{trans}\) represents the trainable parameters of the Transformer model. For audio and visual features, a fully connected network (FCN) is used: \(x_i^a = \text{FCN}(u_i^a, W_a^\text{FCN}), \quad x_i^v = \text{FCN}(u_i^v, W_v^\text{FCN})\)
Where \(W_a^\text{FCN}\) and \(W_v^\text{FCN}\) are learnable parameters for each modality.
Speaker Embedding
The speaker’s identity is encoded to capture conversational dynamics: \(S_\text{emb} = \text{Embedding}(S, N_S)\), where \(N_S\) is the total number of speakers. Speaker embeddings are added to the unimodal features to enhance context: \(X^\tau = \eta S_\text{emb} + X^\tau, \quad \tau \in \{a, v, l\}\)
Where \(\eta \in [0,1]\) controls the contribution of speaker information.
2. Relational Temporal Graph Convolutional Network (RT-GCN)
Multimodal Graph Construction
The conversation is modeled as a graph \(G(V, R, E)\), where:
- Nodes (V): Represent the audio, visual, and textual features for each utterance (\(V = 3N\)).
- Edges (E): Capture relationships between nodes, divided into:
- Multimodal Relations (\(R_\text{multi}\)): Intra-utterance connections between modalities.
- Temporal Relations (\(R_\text{temp}\)): Inter-utterance connections between past and future utterances within a specified window \([P, F]\).
For example, multimodal relationships (\(R_\text{multi}\)) are defined as: \(R_\text{multi} = \{(u_i^a, u_i^v), (u_i^v, u_i^l), (u_i^l, u_i^a)\}.\)
Temporal relationships (\(R_\text{temp}\)) capture connections across time: \(R_\text{temp} = \{(u_j^\tau \rightarrow u_i^\tau) | i-P < j < i+F\},\) where \(P\) and \(F\) are the past and future windows, respectively.
Graph Learning
Using Relational Graph Convolution Networks (RGCN), each node aggregates information from its neighbors: \(g_i^\tau = \sum_{r \in R} \sum_{j \in N_r(i)} \frac{1}{|N_r(i)|} W_r x_i^\tau + W_o x_i^\tau,\) where:
- \(N_r(i)\): Neighbors of node \(i\) for relation \(r\),
- \(W_r, W_o\): Learnable weight matrices,
- \(x_i^\tau\): Feature vector for node \(i\) and modality \(\tau\).
3. Pairwise Cross-Modal Feature Interaction (P-CM)
Cross-Modal Attention
The P-CM module uses attention mechanisms to model unaligned sequences between modalities (e.g., audio, text, video). For two modalities (e.g., audio \(a\) and text \(l\)), features are computed as:
- Queries (Q): \(Q_a = X_a W_Q^a\),
- Keys (K): \(K_l = X_l W_K^l\),
- Values (V): \(V_l = X_l W_V^l\).
Cross-modal attention is computed as: \(CM_{l \rightarrow a} = \sigma\left(\frac{Q_a K_l^T}{\sqrt{d_k}}\right) V_l,\) where:
- \(\sigma\): Softmax function,
- \(W_Q, W_K, W_V\): Learnable parameter matrices,
- \(d_k\): Scaling factor.
Sequential Cross-Modal Layers
Cross-modal transformers are applied over \(D\) layers:
- At each layer \(i\), the representation for \(l \rightarrow a\) is updated as:
\(Z_{l \to a}[i] = CM_{l \to a}[i](\text{LN}(Z_{l \to a}[i-1])) + \text{LN}(Z_{l \to a}[i-1]),\)
where:
- \(Z_{l \to a}[i]\): Representation at layer \(i\),
- LN: Layer normalization.
This process is repeated for all modality pairs to obtain global cross-modal features: \(Z^\text{final} = [Z_{a \to l}, Z_{v \to l}, Z_{a \to v}].\)
4. Multimodal Emotion Classification
Fusion and Prediction
Local (RT-GCN) and global (P-CM) context representations are concatenated: \(H = \text{Fusion}([G, Z]) = [\{o_i^\tau\}, \{Z_{a \leftrightarrow l}, Z_{v \leftrightarrow l}, Z_{a \leftrightarrow v}\}],\) where \(H\) is the final fused representation.
The final emotion label for each utterance is predicted using a fully connected neural network (FCN): \(v_i = \text{ReLU}(\Phi_o h_i + b_o),\) \(p_i = \text{softmax}(\Phi_1 v_i + b_1),\) \(\hat{y}_i = \arg\max(p_i).\)
Here, \(\Phi_o, \Phi_1\) are learnable parameters, and \(\hat{y}_i\) is the predicted emotion label.
Conversation Understanding with Relational Temporal Graph Neural Network (CORECT)
Summary
The CORECT model is a new neural network framework designed for multimodal emotion recognition in conversations (ERC), very similar to the sentiment analysis we are interested in. It combines relational temporal graph convolution networks with cross-modal interactions to improve emotional understanding across different conversations.
Key Contributions
- CORECT introduces the Relational Temporal Graph Convolutional Network (RT-GCN) for modeling temporal dependencies and the Pairwise Cross-Modal Feature Interaction (P-CM) for global multimodal context.
- By explicitly leveraging temporal and multimodal relationships, CORECT achieves state-of-the-art results in ERC tasks.
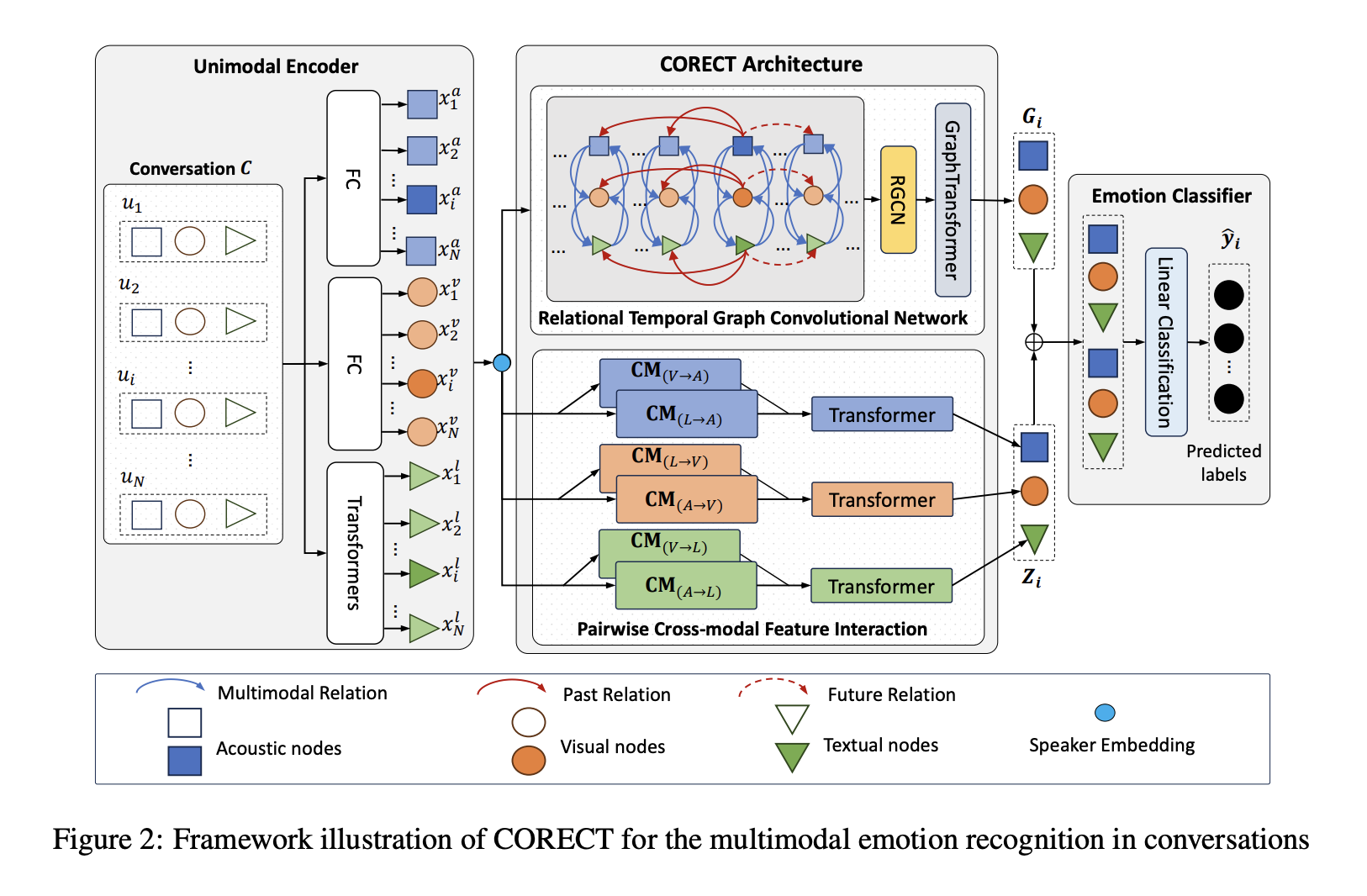
Technical Innovations
1. Relational Graph Convolutional Network (RGCN)
Our objective is to capture the interactions between different nodes (utterances) and modalities (audio, video, text) in a multimodal graph. For each relation \(r\) (e.g., between audio and text or between past and future utterances), the node representation is updated based on its neighbors: \(g_i^\tau = \sum_{r \in R} \sum_{j \in N_r(i)} \frac{1}{|N_r(i)|} W_r \cdot x_j^\tau + W_0 \cdot x_i^\tau\)
- \(N_r(i)\): Neighbors of node \(i\) for relation \(r\).
- \(W_r\): Weight matrix for the relation \(r\).
- \(x_i^\tau\): Feature vector for node \(i\) and modality \(\tau\) (audio, video, text).
The first term aggregates information from neighboring nodes (\(j\)), weighted by \(W_r\). The second term adds a self-projected representation for the node using \(W_0\). The intuition behind this is that the equation ensures that each node’s features are updated by considering not just its own information, but also that of neighboring nodes with respect to their relationships (e.g., temporal or cross-modal links).
2. Graph Transformer for Feature Enrichment
We use a transformer to capture local (neighbor-specific) and global (entire graph) patterns in the graph. After the RGCN updates, each node’s features are further refined using a Graph Transformer. The new representation is given by: \(o_i^\tau = W_1 g_i^\tau + \sum_{j \in N(i)} \alpha_{i,j}^\tau W_2 g_j^\tau\) \(\alpha_{i,j}^\tau = \text{softmax} \left( \frac{(W_3 g_i^\tau)^T (W_4 g_j^\tau)}{\sqrt{d}} \right)\)
- \(W_1, W_2\): Weight matrices for self and neighbor contributions, respectively.
- \(N(i)\): Neighbors of node \(i\).
- \(\alpha_{i,j}^\tau\): Attention coefficient, calculated as: \(\alpha_{i,j}^\tau = \text{softmax} \left( \frac{(W_3 g_i^\tau)^T (W_4 g_j^\tau)}{\sqrt{d}} \right)\)
This attention mechanism assigns importance to neighbors (\(j\)) based on their relationship with the current node (\(i\)).
Final Node Representations: Once the Graph Transformer processes all nodes, the final graph embeddings for each modality (\(a, v, l\)) are obtained as: \(G^\tau = \{o_1^\tau, o_2^\tau, \ldots, o_N^\tau\}, \quad \tau \in \{a, v, l\}\)
- \(G^\tau\): Set of updated node representations for modality \(\tau\) (audio, video, or text).
Video Sentiment Analysis with Bimodal Multi-Head Attention (BIMHA)
BIMHA is a sophisticated framework designed for modeling complex emotional dynamics in videos by using hierarchical bimodal attention. This approach is very strong at integrating visual, auditory, and text data for robust sentiment analysis, our goal.
Key Contributions
BIMHA uses hierarchical attention to model relationships between textual, visual, and auditory modalities for video-based sentiment analysis. It assigns unique weights to pairwise modality interactions (e.g., text-audio, audio-visual), which helps capture nuanced emotional cues.
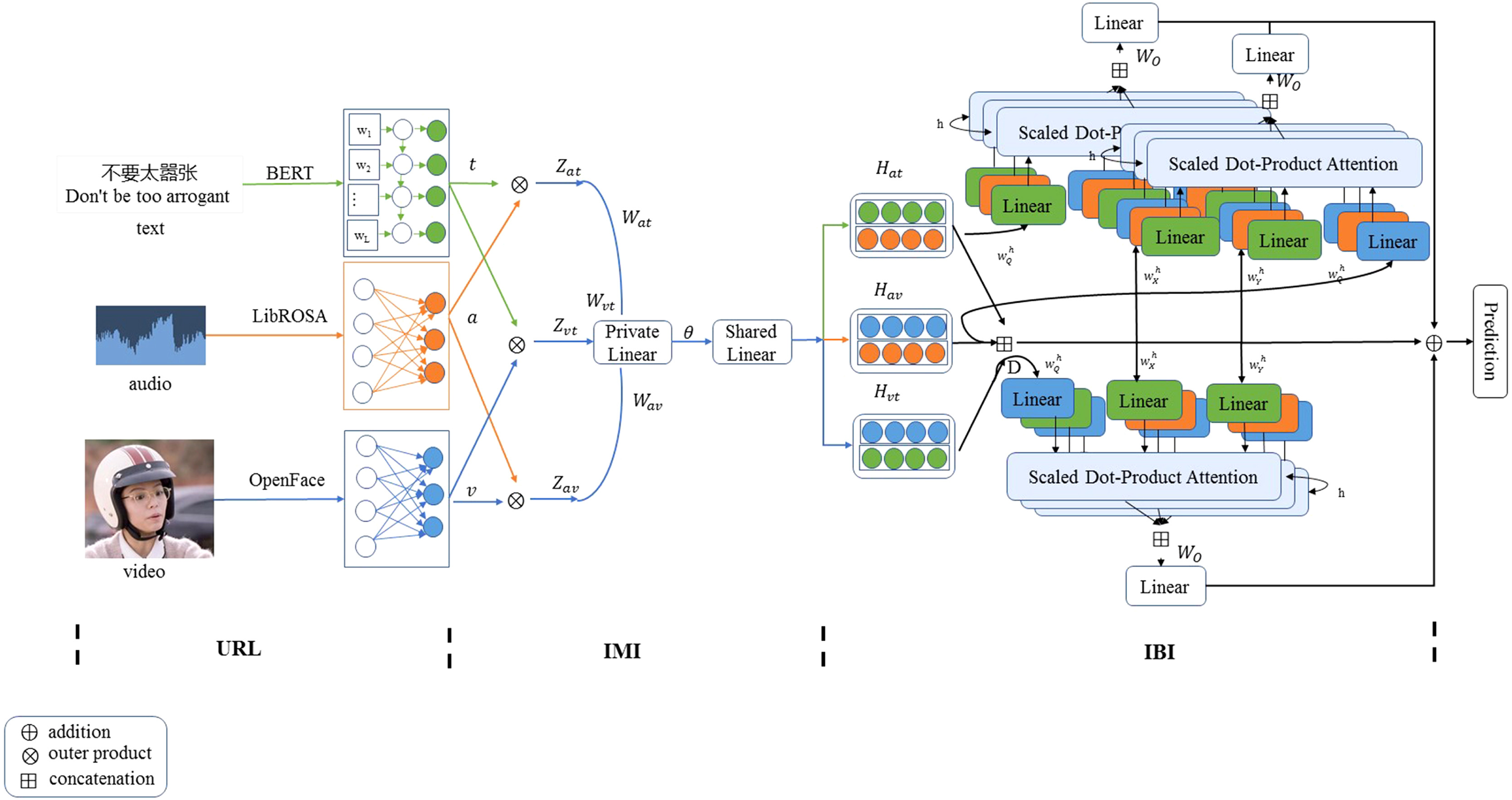
Technical Innovations
1. Inter-Modal Interaction Information (Tensor Fusion)
Unimodal Features
The input representation for each dataset sample is made up of three distinct feature sets, where N is the number of samples in the dataset:
- \(Z_t = \{t_1, t_2, \ldots, t_N\}\) for text features
- \(Z_a = \{a_1, a_2, \ldots, a_N\}\) for audio features
- \(Z_v = \{v_1, v_2, \ldots, v_N\}\) for video features
Tensor Fusion
Tensor fusion combines features from different modalities using outer products:
- Audio-Visual Fusion (AV): \(Z_{av} = Z_a \otimes Z_v, \quad Z_{av} \in \mathbb{R}^{d_{av}}\)
- Audio-Text Fusion (AT): \(Z_{at} = Z_a \otimes Z_t, \quad Z_{at} \in \mathbb{R}^{d_{at}}\)
- Video-Text Fusion (VT): \(Z_{vt} = Z_v \otimes Z_t, \quad Z_{vt} \in \mathbb{R}^{d_{vt}}\)
Linear Transformation
To adapt fused features for downstream processing, a linear transformation is applied:
\[\bar{Z}_{av} = \text{ReLU}(W_{av} Z_{av} + b_{av})\]Similar transformations are applied for \(\bar{Z}_{at}\) and \(\bar{Z}_{vt}\).
Shared Representation
The transformed features are passed through a shared fully connected layer:
\[H_s = \text{FC}(\bar{Z}_s, \theta), \quad s \in \{av, at, vt\}\]2. Inter-Bimodal Interaction Information (BMHA)
Multi-Head Attention (our favorite!)
BMHA computes attention across pairwise features to capture relationships between modalities. The attention mechanism assigns higher weights to more significant pairwise interactions.
Attention Calculation
- Linear Projection of Input Features
- Attention Weights Calculation
- Bimodal Attention Output
The attention outputs across all heads are concatenated and linearly transformed:
\[\text{BMHA}(H_{av}, D, D) = [A_1^{av}; \dots; A_h^{av}] \cdot W_O\]3. Final Prediction
Using Residual Fusion, the outputs of BMHA are concatenated and added back to the original multimodal feature as a residual connection:
\[D_{\text{final}} = [A_{av}, A_{at}, A_{vt}] + D\]Lastly, the fused representation is passed through a three-layer DNN for the final sentiment prediction.
Applications
Understanding Emotional Arcs in Movies (MIT Media Lab)
The field of audio-visual sentiment analysis continues to evolve rapidly, leading to many exciting possibilities for understanding human emotions across various domains. Here, we’ll explore some additional aspects of this technology!
Using data from over 500 Hollywood films and 1500 Vimeo shorts, researchers at the MIT Media Lab created “emotional arcs” to map the ebb and flow of sentiment across a story. These arcs were generated by combining audio features (e.g., speech tone, background score) with visual valence cues (e.g., lighting, actor expressions). By clustering films into six optimal categories, they discovered emotional patterns tied to genres, such as “Adventure” and “Romantic Comedy,” and demonstrated that films with specific arc shapes garnered higher audience engagement and comments on Vimeo.
For example:
- Evaluation Results: Emotional spikes correlated with narrative engagement, achieving a precision rate of 75.8%.
- Integration of Audio-Visual Features: Accuracy in sentiment alignment improved by 18% when combining movie embeddings with unimodal models.
This breakthrough highlights the potential for emotion-driven storytelling to captivate audiences and enhance movie-making processes. Check out the MIT Media Lab’s official research page here.
Mental Health and Real-Time Monitoring (Okaya Integration)
Okaya, a company specializing in wellness and emotional health through computer vision, has been heavily investing in multimodal sentiment analysis for years. We spoke directly with their CEO, who shared their ongoing efforts to use sentiment analysis for real-world applications, such as pre-flight wellness checks for airplane pilots. Their system analyzes video and audio data in real-time to assess stress, fatigue, and overall emotional well-being, ensuring pilots are mentally fit before boarding flights. This helps improve our flight safety!
Key features of Okaya’s system are below:
- Wellness Monitoring: Employs advanced computer vision to detect subtle changes in facial expressions, posture, and vocal tone.
- Data-Driven Diagnostics: Combines machine learning models like GAAM with proprietary algorithms to deliver accurate emotional insights.
- Real-World Integration: Their platform is already deployed in the aviation industry, focusing on critical safety applications.
Okaya’s leadership in this space highlights the importance of sentiment analysis in improving emotional health and ensuring public safety. Learn more about their work at Okaya’s official website.
Looking Ahead
Challenges
-
Data Complexity: Advanced models like CORECT and BIMHA require high-quality, annotated datasets that are often difficult to compile and maintain. Processing multimodal data demands significant computational resources and careful data preprocessing.
-
Alignment Issues: Synchronization between modalities such as text, audio, and video remains a technical hurdle. Ensuring that these modalities are properly aligned temporally is critical for accurate sentiment predictions.
-
Contextual Understanding: Interpreting emotions across diverse cultural and situational contexts remains challenging. Models may struggle to adapt to nuances in language, tone, and visual expressions that vary across demographics.
Future Directions
-
Algorithmic Optimization: Developing lightweight models and efficient attention mechanisms to reduce computational overhead without sacrificing performance. Techniques like pruning and quantization will continue to make models more accessible for real-time applications.
-
Diverse Applications: Extending multimodal sentiment analysis to domains such as education (e.g., assessing student engagement through lectures).
-
Ethical Considerations: Addressing privacy concerns, data security, and bias in emotion recognition systems. Developing frameworks for ethical AI use, including transparent data usage policies and fairness across demographic groups, is essential for long-term adoption.
Conclusion
Audio-visual sentiment analysis represents a significant advancement in understanding human emotions. By leveraging advanced attention mechanisms like BIMHA, BMAN, and GAAM, researchers will continue to unlock new possibilities across industries. As this field evolves, it promises to bridge the gap between technology and human emotional intelligence!
References
[1] Zhang, R., Xue, C., Qi, Q., Lin, L., Zhang, J., & Zhang, L. “Bimodal Fusion Network with Multi-Head Attention for Multimodal Sentiment Analysis.” Applied Sciences, 13(1915), 2023. https://doi.org/10.3390/app13031915.
[2] Ma, H., Wei, S., Yang, S., & Xu, J. “COnversation Understanding with Relational Temporal Graph Neural Network (CORECT).” ArXiv preprint, arXiv:2311.04507, 2023. https://doi.org/10.48550/arXiv.2311.04507.
[3] Wu, T., Peng, J., Zhang, W., & Zhang, Y. “Video Sentiment Analysis with Bimodal Information-Augmented Multi-Head Attention.” Knowledge-Based Systems, 235(2022), 107676. https://doi.org/10.1016/j.knosys.2021.107676.
[4] Reagan, A. J., Mitchell, L., Kiley, D., Danforth, C. M., & Dodds, P. S. “The Emotional Arcs of Stories Are Dominated by Six Basic Shapes.” IEEE International Conference on Data Mining (ICDM), 2017. https://alumni.media.mit.edu/~echu/assets/projects/emotional-arcs/11.2017.ICDM.pdf.