Diffusion Models for Image Editing: A Study of SDEdit, Prompt-to-Prompt, and InstructPix2Pix
Image editing stands at the heart of computer vision applications and enables object attribute modifications, style changes, or transformations in general appearance while retaining much of the structural information about an image. Classic deep learning methods, in particular the GAN-based approach, suffer from this balancing act. They either introduce artifacts, distort salient features, or fail to preserve the original content when performing edits. Recently, diffusion models have emerged as a powerful alternative. Instead of generating an image with a single forward pass, diffusion models progressively remove noise according to a series of denoising steps. This iterative structure makes them particularly suitable for editing: partial noise levels can preserve the content, cross-attention layers control which regions change, and textual instructions guide the model to make targeted changes. For this reason, diffusion-based editing methods are among the most flexible and reliable tools in modern image manipulation. In this report, I investigate three diffusion-based image editing methods-SDEdit, Prompt-to-Prompt, and InstructPix2Pix-each representing a different stage in the evolution of editing techniques. SDEdit showcases how diffusion is able to maintain structure during edits, Prompt-to-Prompt introduces fine-grained control through prompt manipulation, and InstructPix2Pix allows for natural-language-driven edits without large model retraining. All together, these works highlight the versatility of diffusion models and illustrate how iterative denoising can support a wide range of editing tasks.
- 1. Background
- 2.SDEdit
- Prompt-to-Prompt
- Technical Details
- InstructPix2Pix
- Comparison Across Methods
- Summary Table
- Discussion
- Challenges and Limitations
- Future Directions
- Conclusion
- References
1. Background
Diffusion models are generative models that create images by learning to reverse a gradual noising process. During training, an image is repeatedly corrupted through the addition of Gaussian noise until it is almost indistinguishable from pure noise. Then the model is trained to do the opposite: starting from the noise, denoising it step by step to recover the distribution of original images. Although this idea is conceptually simple, the iterative nature of the denoising process makes diffusion models considerably more stable and controllable than earlier approaches to generative image synthesis.
1.1 Forward and Reverse Processes
The forward process progressively adds noise to an image over some predefined number of steps. Eventually, this results in a sample that bears no resemblance to the original content, but the noising schedule is carefully designed so the corruption is predictable. The reverse process, which the model learns, takes a noisy image and removes noise one step at a time. Each such denoising step is handled by a neural network, usually a U-Net, that predicts the noise added at that stage. The model can generate new images or modify existing ones by chaining these predictions together.
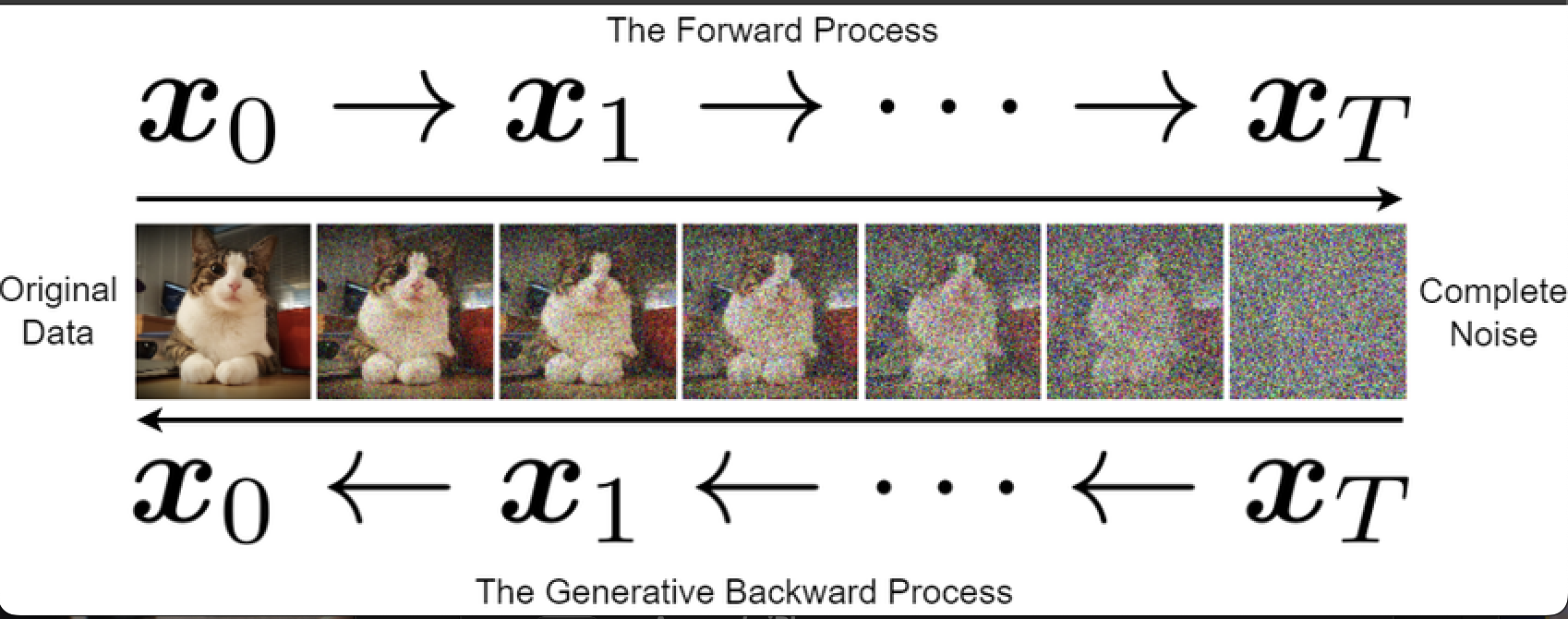
Fig 1. Overview of the diffusion process. Left: forward noising, where Gaussian noise is incrementally added to the image over $T$ steps. Right: reverse denoising, which the model learns to perform step by step to reconstruct an image sample. This formulation underlies all subsequent diffusion-based editing techniques.
Why Diffusion Models Support Image Editing
This is particularly effective for editing, since diffusion models allow fine control over how much of the original image to retain. By adjusting the amount of noise injected before running the reverse process, the model can either keep most of the structure intact-when the noise is low-or make more dramatic changes-when the noise is high. Further, many diffusion models make use of attention mechanisms, which naturally yield “handles” useful for directing edits. For instance, cross-attention maps link parts of a text prompt to specific regions of an image, allowing updates to be localized or constrained. Combining this preservation of structure with flexible conditioning allows diffusion models to perform a broad range of editing tasks.
Image Editing Task Categories
Editing images itself encompasses many types of transformations. Some edits aim to alter attributes-for example, color, lighting, or style-of an image, while the structure of the scene remains unchanged. Others include more semantic changes such as adding or removing objects or changing textures. More advanced methods support natural-language guidance where a user can describe the target edit in plain text. Diffusion-based methods have seen very successful applications across all these categories and often result in edits that preserve much more detail and coherence compared to earlier methods.
Technical Perspective on Diffusion Models
Most models based on diffusion define the forward noising process as a sequence of Gaussian transitions:
\[q(x_t \mid x_{t-1}) = \mathcal{N}\left(x_t; \sqrt{1-\beta_t}\, x_{t-1},\, \beta_t I \right),\]Here, \(\alpha_t = 1 - \beta_t\) and \(\bar{\alpha}_t = \prod_{s=1}^t \alpha_s\) denote the cumulative noise scheduling terms used in DDPMs.
\(\beta_t\) controls the amount of noise added at each step. The model then learns the reverse process \(p_\theta(x_{t-1} \mid x_t)\), ussually parameterized by a U-Net that predicts the noise component \(\epsilon_\theta(x_t, t)\). During either generation or editing, the model iteratively ``denoises’’ a sample \(x_T\) (pure noise) or a partially noised input image $x_t$ to reconstruct a coherent output.
This underlying formulation is common to the various editing methods discussed in later sections; each technique conditions or modifies this denoising process differently to achieve its specific editing behavior.
Reverse Update Rule
In diffusion models, each denoising step is implemented using a parameterized approximation of the reverse transition \(p_\theta(x_{t-1} \mid x_t)\). A commonly used update, derived from the DDPM formulation, is:
\[x_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}} \epsilon_\theta(x_t, t) \right) + \sigma_t z,\]where \(z \sim \mathcal{N}(0, I)\) and \(\sigma_t\) controls the stochasticity of the reverse step. This equation formalizes how the model progressively removes noise, allowing it to reconstruct an image from either pure noise or a partially noised input.
Related Work
Diffusion models have rapidly expanded beyond unconditional generation into applications such as inpainting, super-resolution, text-guided synthesis, and video generation. Early work on image editing studied methods based on GAN inversion and optimization, but diffusion-based methods have proved more stable and controllable. For broader context on diffusion models and score-based generative modeling, see Weng (2021) and Song (2021), who provide thorough overviews of the mathematical foundations and emerging variants.
2.SDEdit
SDEdit, short for “Stochastic Differential Editing,” is one of the first works to demonstrate how diffusion models can be applied to controlled image editing rather than unconditional generation. The intuition behind SDEdit is simple: instead of starting the reverse diffusion process from pure noise, the model initializes a partially noised version of the original image. In this manner, the model can modify certain features of the image while retaining most of the underlying structure.
Approach Overview
SDEdit takes an input image, adding a controlled amount of noise according to a given timestep, t. When it is small, only a little noise is added, and the model retains most of the original content. The larger t is, the more the input to the model is like random noise. It therefore gives more freedom in changing the image. After this noising step, the method simply runs the standard reverse diffusion process in order to produce the edited image. This design enables SDEdit to generate conditioned edits based, for example, on a user-provided target, another image, or a prompt, yet it keeps the core structure of the original input intact: edges, shapes, overall composition. Since the model is not asked to rebuild the whole image from noise, it is less likely to introduce structural distortions or unexpected artifacts.
Figure~\ref{fig:sdedit_process} shows the forward corruption and reverse denoising trajectory used in SDEdit. Starting from a lightly noised version of the input image, the method applies reverse diffusion steps that gradually reintroduce fine-grained details while preserving the high-level structure. This visualizes why SDEdit excels at structure-preserving edits.
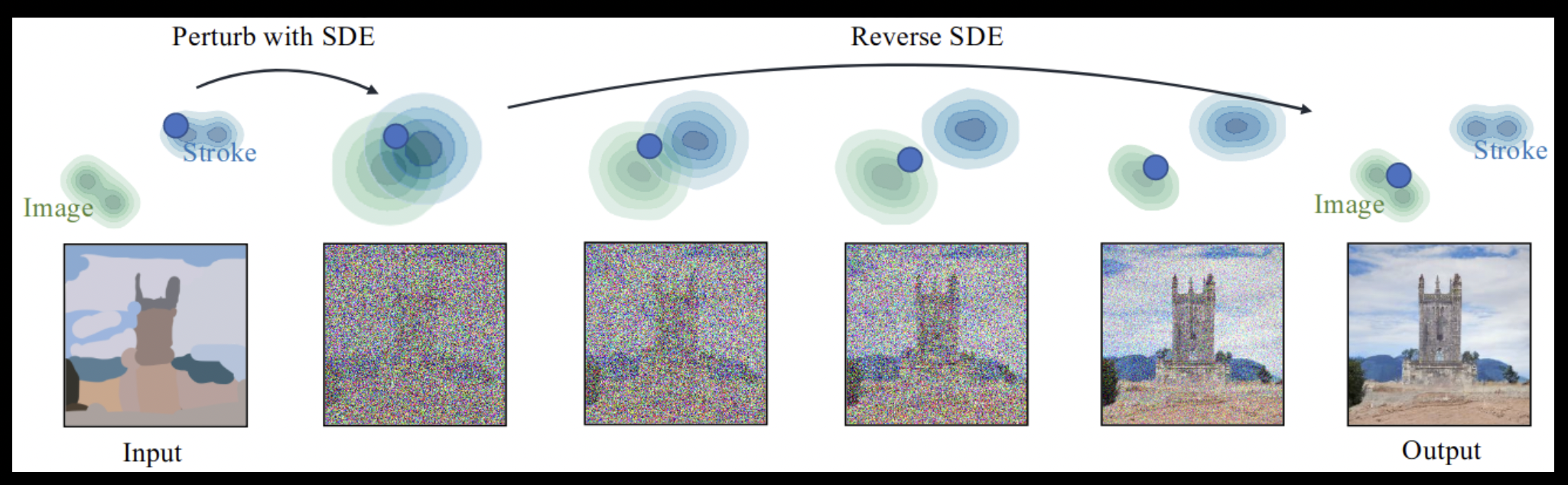
Fig. X. Illustration of SDEdit’s editing procedure. The input image is first perturbed with a controlled amount of noise and then refined through the reverse diffusion (SDE) process. The overall structure of the original image is largely preserved while stylistic or semantic changes are introduced. Reprinted from Meng et al. (2021).
Applications
SDEdit is effective for a wide range of editing tasks, but particularly for those that benefit from maintaining the overall layout of the input image. Some typical applications are: - Style transfer: the process where an image changes its artistic style, yet still retains its shapes intact. - Change of color or texture due to differential light and material. - Light structural edits: minor shape edits, fine details added. Since the only difference from the standard diffusion pipeline is the choice of the noise level, SDEdit can be implemented without retraining the model. This made it widely accessible and easy to use when diffusion models first became popular.
Figure~\ref{fig:sdedit_examples} illustrates several representative SDEdit outputs for a variety of editing tasks, including stroke-based painting, stroke-based editing, and image composition. These examples illustrate how SDEdit can preserve scene layout while making significant visual changes guided by sparse user input. This ability to maintain structure distinguishes SDEdit from earlier GAN-based editing techniques.

Fig. X. Examples of SDEdit editing tasks, including stroke painting, stroke-based editing, and image compositing. SDEdit preserves the underlying image structure while enabling stylistic and semantic changes. Reprinted from Meng et al. (2021).
Technical Details
The model SDEdit uses the same U-Net architecture as standard DDPMs but modifies the starting point of the reverse process. Instead of sampling$x_T \sim \mathcal{N}(0, I)$, it constructs a partially noised version of the input image:
\[x_t = \sqrt{\alpha_t}\, x_0 + \sqrt{1-\alpha_t}\, \epsilon,\]where \(\epsilon\) is Gaussian noise. The choice of the timestep \(t\) renormalizes how much structure from \(x_0\) to preserve. The subsequent denoising steps from $t \rightarrow 0$ follow the same update rules from DDPMs; thus, making SDEdit easy to integrate into existing diffusion pipelines without additional training. This underlying formulation is shared across the various editing methods discussed in later sections; each technique conditions or modulates this denoising process in a different way to achieve its specific editing behavior.
Strengths and Limitations
The key advantage of SDEdit consists in its structure preservation. Anchoring the reverse process to a noised version of the original image, many failure modes of GAN-based editing are avoided: shapes do not collapse, and no non-realistic details are invented. Yet, SDEdit has its own limitations. The only form of control being the noise level, it is difficult for the user to specify which part of the image is to change, and how. Edits tend to be broad, sometimes semantic precision is lacking. Later approaches like Prompt-to-Prompt and InstructPix2Pix address these shortcomings by introducing more explicit conditioning mechanisms.
Practical Insight
Practically, SDEdit preserves high-frequency details better than GAN-inversion methods because the denoising U-Net propagates multi-scale features in a consistent manner. The choice of timestep $t$ effectively controls the ``editing radius’’ in pixel space: smaller values restrict edits to fine appearance changes, while larger values allow broader semantic variation.
In practice, the choice of time-step $t$ is a tricky choice to make: too low and the edits are barely visible, too high and the final result loses structural fidelity.
Prompt-to-Prompt
P2P indeed opens an interesting new direction for diffusion-based image editing, anchored around text-driven control. Whereas diffusion models usually control the degree of image change based on noise levels, Prompt-to-Prompt uses modifications to the text prompt itself as a guide for edits. They utilize the fact that diffusion models are heavily dependent on cross-attention layers, binding words in the prompt to spatial regions in the result image. By manipulating these attention maps, Prompt-to-Prompt manages to offer a much more targeted, semantically meaningful way to edit images.
Introduction to Approaches
Prompt-to-Prompt works by running the diffusion model twice, once for the original and once for the modified prompt. The key novelty here is how cross-attention maps are handled in this process. Rather than allowing the second prompt to fully determine the image, P2P selectively replaces or combines these attention maps from the original prompt with the new one. This allows it to maintain the layout and structure of the initial image, while still encoding semantic changes described in the edited prompt.
For example, to change “a red car” to “a blue car”, one needs only local changes. Prompt-to-Prompt implements this by aligning the attention for “car” but allowing the attention maps for “red” and “blue” to differ. This means that in practice, the model updates parts of the image which correspond to the changed words and leaves everything else unchanged.
Types of Edits
Since it is an attentional shift, Prompt-to-Prompt allows several kinds of fine-grained editing: - Editing of attributes: color, material, and minor visual properties. - Object replacement: this allows substituting one object for another in a way that the surrounding scene is preserved. - Changes in style or texture are applied so that the overall structure remains intact. - Selective modification: edits are triggered by only certain words in the prompt. These capabilities enable Prompt-to-Prompt to make edits that are far more precise compared to the ones from SDEdit, particularly when the preferred change is related to a specific concept or region.
Technical Details
Prompt-to-Prompt utilizes the cross-attention layers in the U-Net. At each step of denoising, the model computes attention maps that relate text tokens to spatial regions in the latent representation. Let \(A_{\text{orig}}\) and \(A_{\text{edit}}\) refer to the cross-attention maps extrated from the original and edited prompts respectively. Prompt-to-Prompt either freezes or blends these maps using
\[A_t = \lambda A_{\text{orig},t} + (1-\lambda) A_{\text{edit},t},\]where \(\lambda\) assists in the control of structure preservation. This approach freezes the attention for certain words, by which it preserves geometric layout while semantic attributes are allowed to change.
Prompt-to-Prompt relies heavily on controlling the cross-attention layers inside the U-Net. Figure~\ref{fig:p2p_attention} shows how the pixel-level queries interact with token keys and values to form attention maps, and how these can be modified to preserve or change parts of the image. The word swap, prompt refinement, and attention re-weighting editing strategies correspond directly to replacing or mixing these attention maps across timesteps.
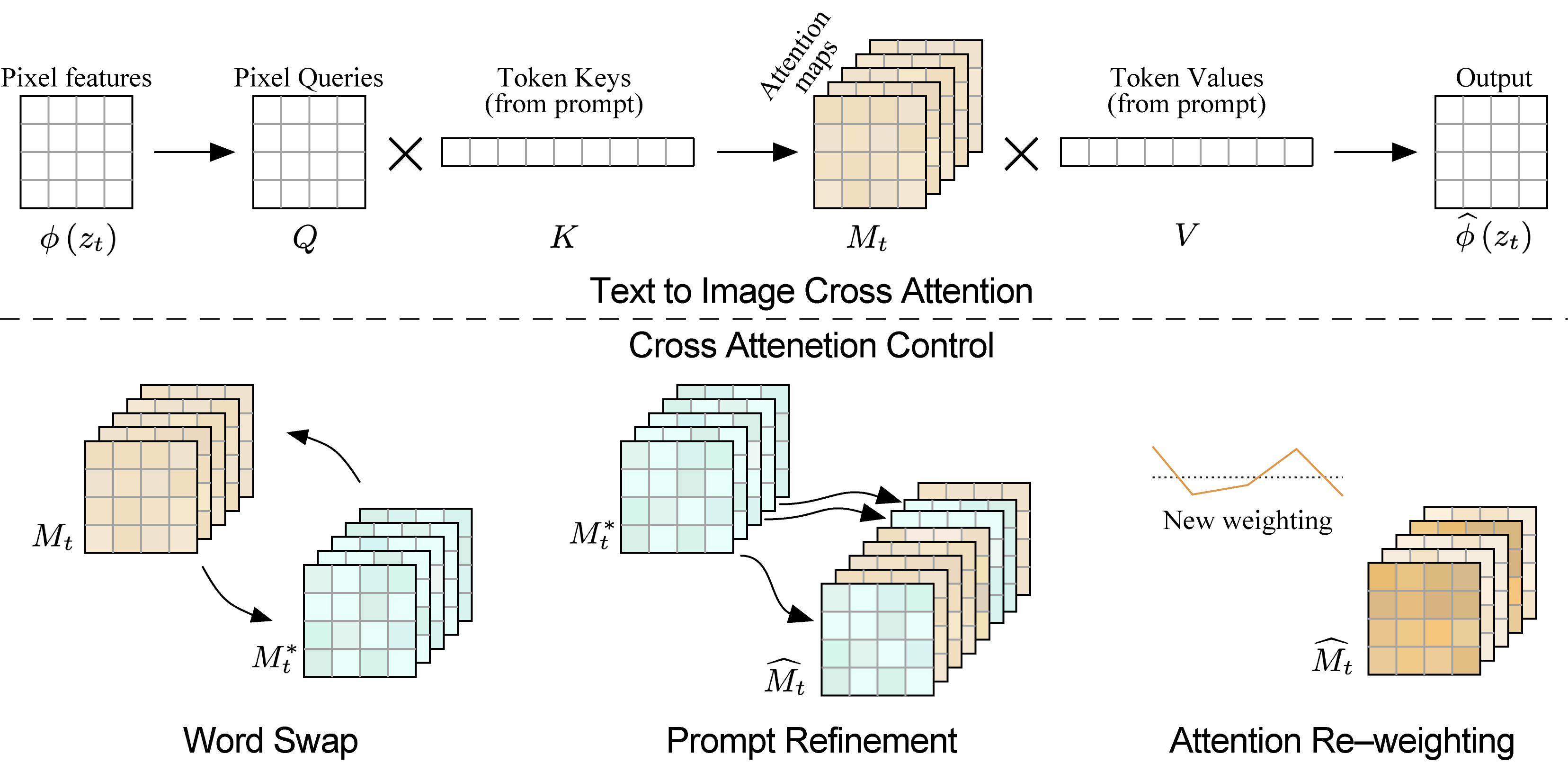
Fig. X. Visualizing text-to-image cross-attention in Prompt-to-Prompt.
Top: pixel-level queries interact with prompt tokens to form cross-attention maps.
Bottom: three attention manipulation strategies for editing—word substitution, prompt refinement, and attention re-weighting.
Reprinted from Hertz et al. (2022).
Practical Insight.
One subtle detail is that freezing attention maps across denoising steps implicitly constrains the latent geometry. This explains why Prompt-to-Prompt is remarkably good at preserving global structure even when the textual prompt introduces significant semantic changes.
Above all, for most codebases, applying Prompt-to-Prompt controls requires attention maps from different U-Net blocks to be aligned across timesteps. The most straightforward solution is to cache the attention tensors during the first pass and reuse them in the second.
Edits which require large geometric changes remain hard; attention manipulation cannot fully alter the latent spatial layout.
Strengths and Limitations
The key strength of Prompt-to-Prompt is the level of semantic control that it offers. Because edits are directly tied to changes in a text prompt, users can edit images with modifications that more closely align with their meaning. This makes Prompt-to-Prompt particularly useful in scenarios where the overall layout needs to remain fixed but certain elements need to be adjusted. Prompt-to-Prompt has its limitations, though: it relies on cross-attention maps for structure, which are generally not intuitive and sometimes difficult to manipulate. In general, this makes edits that are impossible to predict, especially if the prompt expresses an abstract or complex scenery. Furthermore, this approach is worse in situations where structural changes are quite significant to the edit one wants to make, since the whole idea of the approach is designed to maintain the original image’s spatial arrangement intact. Later methods extend this concept in various ways, including InstructPix2Pix, which allows for more flexible and instruction-based editing.
InstructPix2Pix
InstructPix2Pix extends diffusion-based editing to allow users to edit an image by using natural language instructions such as “make the sky darker” or “turn this house into a cabin.” Unlike SDEdit, which relies on noise levels, and Prompt-to-Prompt, which manipulates attention maps tied to prompt changes, InstructPix2Pix directly learns how to map an input image and an instruction into a corresponding edited output. This formulation makes the method more flexible and better suited for a wide range of real-world editing tasks.
Overview of Methods
The key idea of InstructPix2Pix consists in training a diffusion model on pairs of images and written instructions. To collect this data at scale, the authors leverage a large language model to generate synthetic editing instructions and pair them with images transformed by Stable Diffusion. Trained on such pairs, the model learns not just what the final edited image should look like but also how the instruction should guide the transformation.
During inference, the model takes as input an original image and a text instruction. These inputs drive the diffusion process through conditioning mechanisms inspired by those used in text-to-image models. It changes regions of the image concerning the instruction while keeping other aspects of its content intact. This setup allows for a wide range of edits, ranging from subtle adjustments to larger changes in both appearance and structure.
Capabilities and Types of Edits
The instructions can describe almost anything. Therefore, Pix2Pix allows for a wide range of edits. Common examples include the following: - Edit attributes including Color, Brightness, and style. - Object-level editing is the transformation, addition, or deletion of elements in the image. - Semantic transformations, for instance, changing a “cat” into a “fox.” - High-level aesthetic directives, such as “this photo should appear like a watercolor painting. One of the strengths of InstructPix2Pix is that it can interpret relatively loose or open-ended instructions. While Prompt-to-Prompt requires carefully controlled prompt wording, InstructPix2Pix can respond to more natural, flexible phrasing.
Technical Details
InstructPix2Pix is trained with synthetic triplets \((x, y, c)\), where $x$ is the original image, \(y\) is an edited version created by Stable Diffusion, and $c$ is a natural-language instruction generated by a language model. The model is conditioned jointly on the image and the instruction using classifier-free guidance:
\[\hat{\epsilon}_\theta(x_t, t, c) = \epsilon_\theta(x_t, t, \emptyset) + w \big(\epsilon_\theta(x_t, t, c) - \epsilon_\theta(x_t, t, \emptyset)\big),\]where \(w\) is a scalar that controls the strength of instruction-driven editing. The above formulation allows the model to edit regions relevant to the instruction, while anchoring other areas to the input image.
Practical Insight.
Because the training triplets are synthetically generated, the model often inherits biases from the output distribution of Stable Diffusion. This affects the types of structural edits the model performs reliably, especially for images or instructions that deviate from the synthetic training domain.
Long or vague natural language instructions often result in varied, or overly broad, edits.
Strengths and Limitations
The biggest advantage of InstructPix2Pix is its versatility: by training on explicit instruction-image pairs, it learns to make a wide variety of edits using simple, human-language input. This makes the method more intuitive and accessible compared to earlier approaches. It also supports structural changes more effectively than Prompt-to-Prompt, since the model can reinterpret the scene rather than restricting edits to specific attention regions. However, there are also some limitations to the method. The quality of the edit relies on the synthetic instruction–image pairs the model is trained on, which can introduce biases and reduce reliability for unusual instructions. Very fine-grained control may be difficult for some instructions that are ambiguous or require the model to preserve delicate details. These challenges notwithstanding, InstructPix2Pix represents a significant step toward more general-purpose diffusion-based image editing.
Comparison Across Methods
SDEdit, Prompt-to-Prompt, and InstructPix2Pix each take very different approaches toward the goal of image editing, reflecting the broader evolution of diffusion-based editing techniques. While all three methods leverage the same underlying denoising process, they differ significantly in how edits are guided, what kinds of transformations they support, and how much structure they preserve.
Primary Limitations of Each Method
| Method | Key Limitation |
|---|---|
| SDEdit | Limited semantic specificity; editing is controlled primarily via the noise level, making fine-grained or localized edits difficult. |
| Prompt-to-Prompt | Hard to support large structural edits because freezing attention maps constrains changes to the original spatial layout. |
| InstructPix2Pix | Quality depends heavily on the diversity and bias of synthetic instruction–image training pairs. |
Table: Primary limitations of each diffusion-based image editing method.
Summary Table
Following is a high-level comparison of the three methods.
Comparison of Diffusion-Based Image Editing Methods
| Method | Primary Control Mechanism | Structure Preservation | Edits Supported | Semantic Control | Retraining Required? |
|---|---|---|---|---|---|
| SDEdit | Noise level (timestep) | High | Style changes, color/texture edits, small structural edits | Low | No |
| Prompt-to-Prompt | Cross-attention manipulation | Medium–High | Attribute edits, object replacement, selective prompt-based edits | Medium–High | No |
| InstructPix2Pix | Natural-language instructions + supervised training | Medium | Attribute edits, object-level edits, structural and stylistic transformations | High | Yes |
Table: High-level comparison of diffusion-based image editing methods.
Discussion
SDEdit has the strongest structure preservation because the reverse diffusion process is anchored to a lightly perturbed version of the input image. This makes it well-suited for edits that require maintaining composition, such as style transfer or subtle adjustments in lighting. However, its reliance on noise levels alone means the user has limited control over which aspects of the image change, and the edits can sometimes be overly broad.
Prompt-to-Prompt improves on this by introducing a more explicit form of guidance through cross-attention manipulation. Since attention maps directly link words in the text prompt with spatial regions in the image, changes in the prompt can result in specific and localized edits. This leads to finer semantic granularity compared to SDEdit; however, the method works best when the desired changes align naturally with modifications in the text prompt. Large structural changes remain difficult since the approach is set up to preserve most of the scene layout.
InstructPix2Pix is the most flexible of the three methods. The model trains on instruction–image pairs and learns how natural-language commands align with actual image transformations. This allows for edits that involve object shape modifications or changes in the overall scene. Of course, this means it requires supervision in the form of training data, which can limit the reliability with which less common and ambiguously phrased instructions are edited. Additionally, because this method reinterprets the scene in a more aggressive manner, structure may not be preserved quite as well as SDEdit or Prompt-to-Prompt for very subtle or highly controlled edits. Taken together, these techniques represent a trajectory from low-level control-noise-based-to higher semantic level mechanisms: attention-based and instruction-driven. This has substantially widened the variety of editing tasks that diffusion models can engage in.
Challenges and Limitations
Although diffusion-based methods have significantly enhanced the quality and flexibility of image editing, there are still a number of important challenges. One significant concern is that of computational cost: Diffusion models have to run many steps of denoising, which can make editing slow, especially for high-resolution images. Recent work has begun to explore the use of model distillation and consistency models for accelerating inference, but these are active areas of research.
Another challenge lies in control and predictability. Although there are more explicit forms of guidance-for example, Prompt-to-Prompt or InstructPix2Pix-the relation between prompts, instructions, and edits that actually occur is not always transparent. Small changes in phrasing or emphasis may generate unexpected results, and attention-based control is not always aligned with the way users naturally think about editing tasks.
Similarly, fine-grained or very precise changes pose a problem for the diffusion-based editing approaches. SDEdit does not have semantic specificity, Prompt-to-Prompt relies on attention structures which may not be clean in correspondence to objects or regions, and InstructPix2Pix may misunderstand some instructions that are ambiguous. Besides, certain biases originating from the datasets used for generating the training pairs can be passed to instruction-driven models, reducing their reliability for cases out of common patterns.
It remains challenging to strike the right balance between structure preservation and allowing changes: strongly structure-preserving methods, like SDEdit, do not support larger transformations, while more flexible models, like InstructPix2Pix, sometimes change details that users intended to keep. In other words, developing models that can interpret user intent reliably while maintaining controlled editing behavior remains an open problem.
Future Directions
Despite all the progress, there are still many open problems in diffusion-based editing. Among them, arguably the biggest is that these models are slow: dozens of steps of denoising might be required to edit a single image, so that’s an obvious target for speedup. Recent work on fewer-step diffusion or model distillation has some promise, but it’s early days yet.
Another challenge is control. Even with attention maps or instruction-based models, it’s not always clear how to tell the model exactly what to change and what to leave alone. More interactive forms of input—like masks, sketches, or adjustments in specific regions—might make the editing process feel more predictable.
Researchers are also pushing diffusion editing beyond 2D images. Editing videos or 3D scenes brings in new challenges, such as the coherence of details over time or geometry handling; however, lately, there has been considerable progress in these areas.
Finally, as instructions are increasingly free-form, diffusion models will need to understand language even better. Combining diffusion with stronger language models seems a natural direction-especially for edits in which users describe something less specific or more conceptual.
Conclusion
Bringing all three together demonstrates how diffusion models approach image editing in quite different ways: SDEdit keeps most of the original image by adding only a small amount of noise, Prompt-to-Prompt uses changes in the text prompt to guide more specific edits, and InstructPix2Pix lets users describe edits in plain language. All three rely on the same diffusion process, but each solves slightly different problems.
What stood out is that none of these methods are perfect, with some preserving structure better, others offering more control, and some being more flexible with instructions. But taken together, they show how fast the growth in diffusion-based editing has been and how many directions it can still go. And as these models get faster and easier to control, they will most probably become even more common in image editing tools.
References
-
Chenlin Meng, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon.
“SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations.”
arXiv preprint arXiv:2108.01073, 2021. -
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or.
“Prompt-to-Prompt Image Editing with Cross Attention Control.”
arXiv preprint arXiv:2208.01626, 2022. -
Tim Brooks, Aleksander Holynski, and Alexei A. Efros.
“InstructPix2Pix: Learning to Follow Image Editing Instructions.”
arXiv preprint arXiv:2211.09800, 2023.