Street-view Semantic Segmentation
[Project Track: Project 8] In this project, we delve into the topic of developing model to apply semantic segmentations on fine-grained urban structures based on pretrained SegFormer model. We explore 3 approaches to enhance the model performance, and analyze their result. You can find the code here
- Introduction
- Dataset
- Model: SegFormer
- Evaluation Metrics
- Baseline Methods
- Our Approach
- Result and Analysis
- Conclusion
- Reference
Introduction
Understanding street-level scenes through segmentation is crucial to autonomous driving, urban mapping, and robot perception. And it is especially important when it comes to segment fine-grained urban structures because a lot of what makes a street safe, legal, and navigable lives in small, easily missed details. So, this naturally leads to the question we want to investigate in this project: How to improve the semantic segmentation performance on those fine-grained urban structures?
Dataset
Cityscapes is a large-scale, widely used dataset for understanding complex urban environments, featuring diverse street scenes from many cities with high-quality pixel-level annotations for tasks like semantic segmentation and instance segmentation. It contains 30 classes and many of them are considered to be fine-grained urban structures, thus this dataset is a perfect choice for this project.
We remapped all categories in cityscapes to a consistent six-class scheme - fence, car, vegetation, pole, traffic sign, and traffic light. All of the classes are fine-grained urban structures. We define an additional implicit background class which are default to ignore by setting their pixel values to zero.
Dataset Split
We partition the Cityscapes dataset into three subsets from training, validation, and testing. Then, we sample 2000 images to form our training set, 250 images to form our validation set, and another 250 images to form our test set.
Model: SegFormer
In this project, we build everything upon the SegFormer model. SegFormer is a transformer-based semantic segmentation model designed to be simple and accurate. It contains two main parts: encoder and decoder.
The encoder is MiT (Mix Transformer), a hierarchical Transformer that produces 4 multi-scale feature maps. It uses overlapped patch embeddings and an efficient attention design [1].
The decoder is a lightweight All-MLP decoder. It linearly projects each of the 4 feature maps to the same channel size, upsamples them to the same resolution, concatenates and fuses them with an MLP, then outputs per-pixel class scores [1].
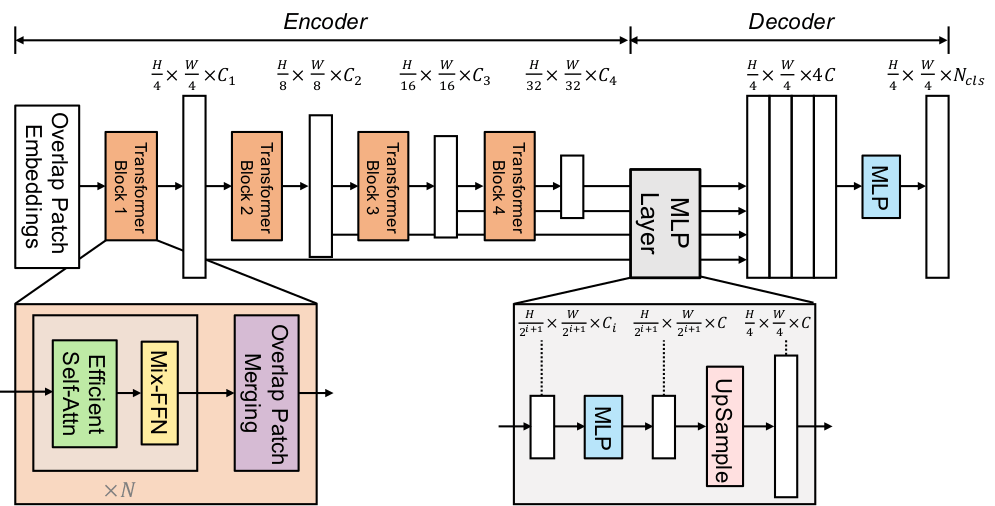 Fig 1. SegFormer Architecture, consists of a hierarchical Transformer encoder to extract coarse and fine features and a lightweight All-MLP decoder to fuse these multi-level features and predict the segmentation mask [1].
Fig 1. SegFormer Architecture, consists of a hierarchical Transformer encoder to extract coarse and fine features and a lightweight All-MLP decoder to fuse these multi-level features and predict the segmentation mask [1].
Evaluation Metrics
We evaluate the performance of models using both per-class intersection over union (IoU) and mean intersection over union (mIoU). IoU measures the overlap between the predicted region and the ground truth bounding box. The equation of calculating IoU is given as follows:
\[\mathrm{IoU}(A,B)=\frac{|A\cap B|}{|A\cup B|}\]Where:
- \(A \cap B\) is the area (or volume) of the overlap between A and B
- \(A \cup B\) is the area (or volume) covered by A or B (their union)
Given C classes, the mean IoU (mIoU) is the average IoU across classes:
\[\mathrm{mIoU} = \frac{1}{C}\sum_{c=1}^{C} \mathrm{IoU}_c\]The higher the IoU and mIoU value is, the better is the model performance.
Baseline Methods
We fully fine-tuned a SegFormer-B0 segmentation model from a Cityscapes-fine-tuned checkpoint, with a newly initialized 7-class (six fine-grained urban structure classes + background) segmentation head, and we are going to use this fully-finetuned SegFormer-B0 as our baseline model. The reason is that due to limited computational resources, SegFormer-B0 is the most suitable starting point, the original head and label set don’t match our remapped classes, and a fine-tuned baseline gives a strong, task-aligned reference so any gains can be attributed to our methods rather than simply training the model on the target data. The training setup is shown in the code below:
model_base = SegformerForSemanticSegmentation.from_pretrained(
"nvidia/segformer-b0-finetuned-cityscapes-512-1024",
num_labels=7,
ignore_mismatched_sizes=True
)
training_args = TrainingArguments(
output_dir="./segformer-thin-structures-v2",
learning_rate=6e-5,
num_train_epochs=15,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
save_total_limit=1,
eval_strategy="epoch",
save_strategy="epoch",
logging_steps=25,
remove_unused_columns=False,
dataloader_num_workers=8,
fp16=torch.cuda.is_available(),
gradient_accumulation_steps=1,
report_to="none",
)
trainer = Trainer(
model=model_base,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
)
trainer.train()
trainer.save_model("./segformer-thin-structures-v2-final")
All methods we explored in the project will use same set of training_args as shown above for better comparison.
The performance of the baseline model is shown in below:
| Class | Fine-tune |
|---|---|
| fence | 0.3438 |
| car | 0.8964 |
| vegetation | 0.8968 |
| pole | 0.3119 |
| traffic sign | 0.5653 |
| traffic light | 0.4583 |
| mIoU | 0.5788 |
Our Approach
Approach 1 - BASNet Hybrid Loss
In our first approach we implement a boundary-aware supervision strategy designed to improve the geometric precision of the baseline model without altering its underlying architecture. While standard semantic segmentation relies on pixel-wise classification, a “Boundary-Aware” mechanism redefines the optimization objective to prioritize structural fidelity. Inspired by Boundary-Aware Segmentation Network (BASNet), we achieve the boundary-aware supervision by adopting the hybrid loss, which is proposed in the BASNet, that combines three distinct supervisory signals to train the SegFormer. The three types of losses are described below:
-
Structural Similarity (SSIM): Unlike pixel-wise losses that treat neighbors as independent, SSIM evaluates the structural information within a local sliding window. By using Gaussian-weighted convolutions (
\[\ell_{ssim} = 1 - \frac{(2\mu_x \mu_y + C_1)(2\sigma_{xy} + C_2)}{(\mu_x^2 + \mu_y^2 + C_1)(\sigma_x^2 + \sigma_y^2 + C_2)}\]F.conv2d), it penalizes predictions where the local variance—representing texture and edges—does not match the ground truth. This effectively forces the model to sharpen boundaries around objects. It has the following mathematical form:where \(\mu_x\), \(\mu_y\) are the mean for x and y, and \(\sigma_x\), \(\sigma_y\) are the standard deviations for x and y, \(\sigma_{xy}\) is their covariance, \(C_1 = 0.01^2\) and \(C_2 = 0.03^2\) are used to avoid dividing by zero [2].
-
Multi-Class IoU Loss: This component optimizes the Jaccard Index directly. It aggregates softmax probabilities across the entire image to calculate the intersection and union for each class. This creates a global gradient that rewards the correct extent and shape of the predicted region, preventing the model from generating fragmented or “shattered” masks. It has the following mathematical form (for multi-class case):
\[\ell_{iou} = 1 - \frac{1}{C} \sum_{c=1}^{C} \frac{\sum_{r,w} S_c(r,w) G_c(r,w) + \epsilon}{\sum_{r,w} S_c(r,w) + \sum_{r,w} G_c(r,w) - \sum_{r,w} S_c(r,w) G_c(r,w) + \epsilon}\]where \(G_c(r,w)\) is the one-hot ground truth label of the pixel (r,w) and \(S_c(r,w)\) is the predicted probability for class c at pixel (r,w) [2].
-
Cross-Entropy (CE): We retain the standard Cross-Entropy loss to anchor the pixel-level class fidelity, ensuring the semantic categorization remains accurate while SSIM and IoU refine the geometry.
Build upon the original hybrid loss proposed in the BASNet, we combine the three types of losses in a weighted way, so we can have more flexibility.
\[\ell_{hybrid} = \lambda_{ce} \cdot \ell_{ce} + \lambda_{ssim} \cdot \ell_{ssim} + \lambda_{iou} \cdot \ell_{iou}\]By defining this new loss function we shifted from a purely semantic focus to a hybrid focus, and more focus is expected to be shifted to fine-grained things in the image because such loss is architecturally biased toward boundaries and those fine-grained urban structures have small interiors relative to their boundary. The hybrid loss implementation is shown below:
class SSIM(nn.Module):
def __init__(self, window_size=11, size_average=True, return_loss=True):
super().__init__()
self.window_size = window_size
self.size_average = size_average
self.return_loss = return_loss
self.channel = 1
self.register_buffer('window', self._create_window(window_size, self.channel))
def _gaussian(self, window_size, sigma):
coords = torch.arange(window_size, dtype=torch.float32) - window_size // 2
gauss = torch.exp(-coords**2 / (2 * sigma**2))
return gauss / gauss.sum()
def _create_window(self, window_size, channel):
_1D_window = self._gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).unsqueeze(0).unsqueeze(0)
return _2D_window.expand(channel, 1, window_size, window_size).contiguous()
def forward(self, img1, img2):
_, channel, _, _ = img1.size()
# Recreate window if channel count changed
if channel != self.channel:
self.channel = channel
self.window = self._create_window(self.window_size, channel).to(img1.device, img1.dtype)
pad = self.window_size // 2
# Apply reflection padding to avoid artificial edges
img1_padded = F.pad(img1, (pad, pad, pad, pad), mode='reflect')
img2_padded = F.pad(img2, (pad, pad, pad, pad), mode='reflect')
# Compute means
mu1 = F.conv2d(img1_padded, self.window, padding=0, groups=channel)
mu2 = F.conv2d(img2_padded, self.window, padding=0, groups=channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1 * mu2
# Compute variances and covariance
sigma1_sq = F.conv2d(img1_padded * img1_padded, self.window, padding=0, groups=channel) - mu1_sq
sigma2_sq = F.conv2d(img2_padded * img2_padded, self.window, padding=0, groups=channel) - mu2_sq
sigma12 = F.conv2d(img1_padded * img2_padded, self.window, padding=0, groups=channel) - mu1_mu2
# Clamp for numerical stability
sigma1_sq = torch.clamp(sigma1_sq, min=0)
sigma2_sq = torch.clamp(sigma2_sq, min=0)
# Stability constants
C1 = 0.01 ** 2
C2 = 0.03 ** 2
ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / \
((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2))
if self.size_average:
ssim_val = ssim_map.mean()
else:
ssim_val = ssim_map.mean(dim=[1, 2, 3])
return 1 - ssim_val if self.return_loss else ssim_val
class MultiClassIoULoss(nn.Module):
def __init__(self, num_classes=7, smooth=1e-6):
super().__init__()
self.num_classes = num_classes
self.smooth = smooth
def forward(self, pred_softmax, target_onehot):
intersection = (pred_softmax * target_onehot).sum(dim=(2, 3))
union = pred_softmax.sum(dim=(2, 3)) + target_onehot.sum(dim=(2, 3)) - intersection
iou = (intersection + self.smooth) / (union + self.smooth)
#1 - mIoU as loss
return 1 - iou.mean()
class HybridLoss(nn.Module):
def __init__(self, num_classes=7, ce_weight=1.0, ssim_weight=1.0, iou_weight=1.0):
super().__init__()
self.num_classes = num_classes
self.ce_weight = ce_weight
self.ssim_weight = ssim_weight
self.iou_weight = iou_weight
self.ce_loss = nn.CrossEntropyLoss(ignore_index=255)
self.ssim_module = SSIM(window_size=11, size_average=True)
self.iou_loss = MultiClassIoULoss(num_classes=num_classes)
def forward(self, logits, labels):
# Upsample logits to match label size
if logits.shape[-2:] != labels.shape[-2:]:
logits = F.interpolate(logits, size=labels.shape[-2:],
mode='bilinear', align_corners=False)
#Cross-Entropy Loss
ce_out = self.ce_loss(logits, labels)
pred_softmax = F.softmax(logits, dim=1)
#one-hot encoding for valid pixels
valid_mask = (labels != 255)
labels_for_onehot = labels.clone()
labels_for_onehot[~valid_mask] = 0
target_onehot = F.one_hot(labels_for_onehot, num_classes=self.num_classes)
target_onehot = target_onehot.permute(0, 3, 1, 2).float()
# Mask out invalid pixels
valid_mask_expanded = valid_mask.unsqueeze(1).float()
target_onehot = target_onehot * valid_mask_expanded
pred_softmax_masked = pred_softmax * valid_mask_expanded
#SSIM Loss (boundary-aware component)
#ssim_out = 1 - self.ssim_module(pred_softmax_masked, target_onehot)
ssim_out = self.ssim_module(pred_softmax_masked, target_onehot)
#IoU Loss
iou_out = self.iou_loss(pred_softmax_masked, target_onehot)
# Combine losses
total_loss = (self.ce_weight * ce_out +
self.ssim_weight * ssim_out +
self.iou_weight * iou_out)
return total_loss, {
'ce_loss': ce_out.item(),
'ssim_loss': ssim_out.item(),
'iou_loss': iou_out.item()
}
To adopt this new loss function, we implement a new ‘BATrainer’ based on the original Trainer provided by the HuggingFace
The implementation is shown below
class BATrainer(Trainer):
def __init__(self, *args, ce_weight=1.0, ssim_weight=1.0, iou_weight=1.0, **kwargs):
super().__init__(*args, **kwargs)
self.hybrid_loss = HybridLoss(
num_classes=7,
ce_weight=ce_weight,
ssim_weight=ssim_weight,
iou_weight=iou_weight
)
def compute_loss(self, model, inputs, return_outputs=False, **kwargs):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.logits
loss, loss_components = self.hybrid_loss(logits, labels)
return (loss, outputs) if return_outputs else loss
Then, we initialize another pretrained SegFormer-B0 model, and use the same training_arg as the one we used for our baseline model training and test the per-class IoU and the mIoU across all classes
model_bas = SegformerForSemanticSegmentation.from_pretrained(
"nvidia/segformer-b0-finetuned-cityscapes-512-1024",
num_labels=7,
ignore_mismatched_sizes=True
)
training_args = TrainingArguments(
output_dir="./segformer-thin-structures-ba",
learning_rate=6e-5,
num_train_epochs=15,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
save_total_limit=1,
eval_strategy="epoch",
save_strategy="epoch",
logging_steps=25,
remove_unused_columns=False,
dataloader_num_workers=8,
fp16=torch.cuda.is_available(),
gradient_accumulation_steps=1,
report_to="none",
)
trainer = BATrainer(
model=model_bas,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
ce_weight=1,
ssim_weight=0.4,
iou_weight=0.5,
)
trainer.train()
trainer.save_model("./segformer-thin-structures-ba-final")
Approach 2 - BASNet Hybrid Loss + Copy-Paste Augmentation
Building upon the structural precision achieved by our Boundary-Aware (BA) approach, we further introduce a Copy-Paste Augmentation strategy that fundamentally alters the training data distribution. While the BA method refines how the model learns, this augmentation strategy refines what the model sees during training.
The motivation for this copy-paste augmentation is that: While the Boundary-Aware (BA) method successfully mitigates over-smoothing by sharpening object edges, it remains constrained by the inherent class imbalance present in the original dataset. In typical street-view scenes, safety-critical objects such as traffic poles, distant lights, and road signs constitute only a small fraction of total pixels relative to dominant classes including road, sky, and building surfaces. Consequently, even a boundary-focused model may struggle to detect these objects due to their limited representation in the training data. To directly address this “long-tail” distribution problem without incurring the cost of manual data collection, we employ Copy-Paste augmentation. By synthetically transplanting instances of rare classes onto diverse background contexts, we encourage the model to decouple objects from their typical environmental associations and recognize them based on intrinsic visual features rather than contextual priors. This augmentation strategy primarily targets recall: whereas the BA method improves the quality of detected object boundaries, Copy-Paste augmentation improves the likelihood of successful detection by exposing the model to a high frequency of rare, spatially sparse structures throughout training. [3]
The core mechanism relies on an object-level augmentation technique that synthesizes new training samples dynamically. For each target image, the system randomly selects a source image from the dataset and identifies specific object classes within it. The identified objects are extracted and optionally transformed through geometric operations that introduce additional variance. These extracted objects are then composited onto the target image using binary masking, and the corresponding segmentation masks are updated simultaneously to reflect the newly transplanted objects. By combining extracted objects with realistic textures in a single image, this process creates training samples with increased object density and complexity. Importantly, the model is trained on these augmented samples using the same Hybrid Boundary-Aware loss function (SSIM + IoU + CE) described previously. This integrated approach ensures that the model not only encounters rare objects more frequently but also learns their precise boundaries with high fidelity. [3]
Then, we initialize another pretrained SegFormer-B0 model model_bas_aug, and use the same training_arg as the one we used for our baseline model training and test the per-class IoU and the mIoU across all classes
The copy-paste augmentation implementation is demonstrated in the code below:
class CopyPasteAugmentation:
def __init__(self, dataset, paste_prob=0.5):
self.dataset = dataset
self.paste_prob = paste_prob
def __call__(self, image, label):
if random.random() > self.paste_prob:
return image, label
# Get random source image
source_idx = random.randint(0, len(self.dataset) - 1)
source_example = self.dataset[source_idx]
source_image = source_example['image'].convert('RGB')
source_label = np.array(source_example['semantic_segmentation'])
if len(source_label.shape) == 3:
source_label = source_label[:, :, 0]
source_label = remap_labels(source_label)
# Resize source to match main image
source_image = source_image.resize(image.size, Image.BILINEAR)
source_label = np.array(Image.fromarray(source_label.astype(np.uint8)).resize(
image.size, Image.NEAREST))
# Random horizontal flip
if random.random() > 0.5:
source_image = source_image.transpose(Image.FLIP_LEFT_RIGHT)
source_label = np.fliplr(source_label).copy()
# Select random subset of classes to paste
available_classes = [c for c in range(1, 7) if c in source_label]
if not available_classes:
return image, label
num_to_paste = random.randint(1, len(available_classes))
classes_to_paste = random.sample(available_classes, num_to_paste)
# Create mask and blend: I1 * alpha + I2 * (1 − alpha)
alpha = np.isin(source_label, classes_to_paste).astype(np.float32)
alpha_3d = alpha[:, :, np.newaxis]
image_np = np.array(image).astype(np.float32)
source_np = np.array(source_image).astype(np.float32)
new_image_np = source_np * alpha_3d + image_np * (1 - alpha_3d)
new_image = Image.fromarray(new_image_np.astype(np.uint8))
# Update labels
new_label = np.where(alpha > 0, source_label, label)
return new_image, new_label
class CopyPasteDataset(torch.utils.data.Dataset):
def __init__(self, hf_dataset, processor, copy_paste_aug=None, target_size=(1024, 512)):
self.hf_dataset = hf_dataset
self.processor = processor
self.copy_paste_aug = copy_paste_aug
self.target_size = target_size
def __len__(self):
return len(self.hf_dataset)
def __getitem__(self, idx):
example = self.hf_dataset[idx]
image = example['image'].convert('RGB')
label = example['semantic_segmentation']
image = image.resize(self.target_size, Image.BILINEAR)
label = label.resize(self.target_size, Image.NEAREST)
label = np.array(label)
if len(label.shape) == 3:
label = label[:, :, 0]
label = remap_labels(label)
if self.copy_paste_aug is not None:
image, label = self.copy_paste_aug(image, label)
inputs = self.processor(images=image, return_tensors="pt")
inputs = {k: v.squeeze(0) for k, v in inputs.items()}
inputs['labels'] = torch.tensor(label, dtype=torch.long)
return inputs
Generally, this is the training flow: Boundary-aware SegFormer-B0 + copy-paste augmented train split → BA loss training → save segformer-thin-structures-ba_aug-final.
model_bas_aug = SegformerForSemanticSegmentation.from_pretrained(
"nvidia/segformer-b0-finetuned-cityscapes-512-1024",
num_labels=7,
ignore_mismatched_sizes=True
)
training_args = TrainingArguments(
output_dir="./segformer-thin-structures-ba_aug",
learning_rate=6e-5,
num_train_epochs=15,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
save_total_limit=1,
eval_strategy="epoch",
save_strategy="epoch",
logging_steps=25,
remove_unused_columns=False,
dataloader_num_workers=8,
fp16=torch.cuda.is_available(),
gradient_accumulation_steps=1,
report_to="none",
)
trainer = BATrainer(
model=model_bas_aug,
args=training_args,
train_dataset=train_dataset_aug,
eval_dataset=val_dataset,
ce_weight=1,
ssim_weight=0.4,
iou_weight=0.5,
)
trainer.train()
trainer.save_model("./segformer-thin-structures-ba_aug-final")
Approach 3 - SSIM + Lovasz Softmax Loss + Copy-Paste Augmentation
In our third approach, we replace the soft IoU loss from the BASNet hybrid loss with the Lovász-Softmax loss, while retaining SSIM loss and copy-paste augmentation. The motivation is to explore whether Lovász-Softmax, which directly optimizes for the IoU metric through a convex surrogate, can provide better supervision than the standard soft IoU loss.
Unlike soft IoU loss which computes a differentiable approximation of IoU, Lovász-Softmax loss leverages the Lovász extension to create a convex surrogate that directly optimizes the Jaccard index [4]. The key mechanism involves sorting pixels by their prediction error magnitude and applying class-specific gradient weighting derived from the Lovász extension. Critically, the loss uses per-class averaging, where each class contributes equally to the total loss regardless of its pixel count:
\[\ell_{lovasz} = \frac{1}{C} \sum_{c=1}^{C} \Delta_{J_c}(m(c))\]where \(\Delta J\) is the Lovasz extension of the IoU loss for class \(c\), and \(m(c)\) represents the vector of errors for that class
In addition to using Lovasz loss, we introduce explicit class weighting in the cross-entropy loss to further address class imbalance. We assign higher weights to underrepresented fine-grained structures:
The detailed implementaion of this approach is shown below:
class SSIM(nn.Module):
def __init__(self, window_size=11, size_average=True, return_loss=True):
super().__init__()
self.window_size = window_size
self.size_average = size_average
self.return_loss = return_loss
self.channel = 1
self.register_buffer('window', self._create_window(window_size, self.channel))
def _gaussian(self, window_size, sigma):
coords = torch.arange(window_size, dtype=torch.float32) - window_size // 2
gauss = torch.exp(-coords**2 / (2 * sigma**2))
return gauss / gauss.sum()
def _create_window(self, window_size, channel):
_1D_window = self._gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).unsqueeze(0).unsqueeze(0)
return _2D_window.expand(channel, 1, window_size, window_size).contiguous()
def forward(self, img1, img2):
_, channel, _, _ = img1.size()
if channel != self.channel:
self.channel = channel
self.window = self._create_window(self.window_size, channel).to(img1.device, img1.dtype)
pad = self.window_size // 2
img1_padded = F.pad(img1, (pad, pad, pad, pad), mode='reflect')
img2_padded = F.pad(img2, (pad, pad, pad, pad), mode='reflect')
mu1 = F.conv2d(img1_padded, self.window, padding=0, groups=channel)
mu2 = F.conv2d(img2_padded, self.window, padding=0, groups=channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1 * mu2
sigma1_sq = F.conv2d(img1_padded * img1_padded, self.window, padding=0, groups=channel) - mu1_sq
sigma2_sq = F.conv2d(img2_padded * img2_padded, self.window, padding=0, groups=channel) - mu2_sq
sigma12 = F.conv2d(img1_padded * img2_padded, self.window, padding=0, groups=channel) - mu1_mu2
sigma1_sq = torch.clamp(sigma1_sq, min=0)
sigma2_sq = torch.clamp(sigma2_sq, min=0)
C1 = 0.01 ** 2
C2 = 0.03 ** 2
ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / \
((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2))
if self.size_average:
ssim_val = ssim_map.mean()
else:
ssim_val = ssim_map.mean(dim=[1, 2, 3])
return 1 - ssim_val if self.return_loss else ssim_val
class LovaszSoftmaxLoss(nn.Module):
def __init__(self, ignore_index=255, classes='present'):
super().__init__()
self.ignore_index = ignore_index
self.classes = classes
def lovasz_grad(self, gt_sorted):
p = len(gt_sorted)
gts = gt_sorted.sum()
intersection = gts - gt_sorted.float().cumsum(0)
union = gts + (1 - gt_sorted).float().cumsum(0)
jaccard = 1. - intersection / union
if p > 1:
jaccard[1:p] = jaccard[1:p] - jaccard[0:-1]
return jaccard
def lovasz_softmax_flat(self, probas, labels):
C = probas.shape[1]
losses = []
valid = labels != self.ignore_index
if valid.sum() == 0:
return torch.tensor(0.).to(probas.device)
probas = probas[valid]
labels = labels[valid]
for c in range(C):
fg = (labels == c).float()
if self.classes == 'present' and fg.sum() == 0:
continue
class_pred = probas[:, c]
errors = (Variable(fg) - class_pred).abs()
errors_sorted, perm = torch.sort(errors, 0, descending=True)
perm = perm.data
fg_sorted = fg[perm]
losses.append(torch.dot(errors_sorted, Variable(self.lovasz_grad(fg_sorted))))
return sum(losses) / C
def forward(self, logits, labels):
probas = F.softmax(logits, dim=1)
probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, probas.shape[1])
labels = labels.view(-1)
return self.lovasz_softmax_flat(probas, labels)
class UltimateHybridLoss(nn.Module):
def __init__(self, num_classes=7, ce_weight=1.1, ssim_weight=0.5, lovasz_weight=0.5):
super().__init__()
self.num_classes = num_classes
self.ce_weight = ce_weight
self.ssim_weight = ssim_weight
self.lovasz_weight = lovasz_weight
# High weights for Fence(1), Pole(4), Sign(5)
# 0:bg, 1:fence, 2:car, 3:veg, 4:pole, 5:sign, 6:light
class_weights = torch.tensor([1.0, 5.0, 1.0, 1.0, 5.0, 5.0, 2.0]).cuda()
self.ce_loss = nn.CrossEntropyLoss(ignore_index=255, weight=class_weights)
self.ssim_module = SSIM(window_size=11, size_average=True)
self.lovasz_loss = LovaszSoftmaxLoss(ignore_index=255)
def forward(self, logits, labels):
if logits.shape[-2:] != labels.shape[-2:]:
logits = F.interpolate(logits, size=labels.shape[-2:], mode='bilinear', align_corners=False)
ce_out = self.ce_loss(logits, labels)
# SSIM Setup
pred_softmax = F.softmax(logits, dim=1)
valid_mask = (labels != 255)
labels_masked = labels.clone()
labels_masked[~valid_mask] = 0
target_onehot = F.one_hot(labels_masked, num_classes=self.num_classes).permute(0, 3, 1, 2).float()
valid_mask_expanded = valid_mask.unsqueeze(1).float()
ssim_out = self.ssim_module(pred_softmax * valid_mask_expanded, target_onehot * valid_mask_expanded)
# Lovasz Setup
lovasz_out = self.lovasz_loss(logits, labels)
total_loss = (self.ce_weight * ce_out + self.ssim_weight * ssim_out + self.lovasz_weight * lovasz_out)
return total_loss
class UltimateTrainer(Trainer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.criterion = UltimateHybridLoss(num_classes=7)
def compute_loss(self, model, inputs, return_outputs=False, **kwargs):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.logits
loss = self.criterion(logits, labels)
return (loss, outputs) if return_outputs else loss
In addition to this new hybrid loss, we also applied the copy-paste augmentation from approach 2, with the same rationale provided.
model_hybrid = SegformerForSemanticSegmentation.from_pretrained(
"nvidia/segformer-b0-finetuned-cityscapes-512-1024",
num_labels=7,
ignore_mismatched_sizes=True
)
training_args = TrainingArguments(
output_dir="./segformer-thin-structures-hybrid",
learning_rate=6e-5,
num_train_epochs=15,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
save_total_limit=1,
eval_strategy="epoch",
save_strategy="epoch",
logging_steps=25,
remove_unused_columns=False,
dataloader_num_workers=8,
fp16=torch.cuda.is_available(),
gradient_accumulation_steps=1,
report_to="none",
)
trainer = UltimateTrainer(
model=model_hybrid,
args=training_args,
train_dataset=train_dataset_aug,
eval_dataset=val_dataset,
)
trainer.train()
trainer.save_model("./segformer-thin-structures-hybrid-final")
Result and Analysis
After all training and evaluations are done, we print the result, and compare it with the baseline model performance (The fully-finetuned SegFormer-B0 model). The results are shown below.
Approach 1 - BASNet Hybrid Loss:
| Class | Baseline | BAS | Improvement |
|---|---|---|---|
| fence | 0.3438 | 0.3960 | +0.0522 |
| car | 0.8964 | 0.8943 | -0.0021 |
| vegetation | 0.8968 | 0.8948 | -0.0020 |
| pole | 0.3119 | 0.3379 | +0.0259 |
| traffic sign | 0.5653 | 0.5819 | +0.0166 |
| traffic light | 0.4583 | 0.4730 | +0.0147 |
| mIoU | 0.5788 | 0.5963 | +0.0176 |
Approach 2 - BASNet Hybrid Loss + CopyPaste Augmentation:
| Class | Baseline | BAS + Aug | Improvement |
|---|---|---|---|
| fence | 0.3438 | 0.3880 | +0.0442 |
| car | 0.8964 | 0.8960 | -0.0005 |
| vegetation | 0.8968 | 0.8951 | -0.0017 |
| pole | 0.3119 | 0.3385 | +0.0266 |
| traffic sign | 0.5653 | 0.5894 | +0.0242 |
| traffic light | 0.4583 | 0.4775 | +0.0191 |
| mIoU | 0.5788 | 0.5974 | +0.0187 |
Approach 3 - SSIM Loss + Lovasz Loss + CopyPaste Augmentation:
| Class | Baseline | SLC | Improvement |
|---|---|---|---|
| fence | 0.3438 | 0.3786 | +0.0348 |
| car | 0.8964 | 0.8947 | -0.0017 |
| vegetation | 0.8968 | 0.8913 | -0.0055 |
| pole | 0.3119 | 0.3314 | +0.0195 |
| traffic sign | 0.5653 | 0.5787 | +0.0134 |
| traffic light | 0.4583 | 0.4724 | +0.0140 |
| mIoU | 0.5788 | 0.5912 | +0.0124 |
Compare to Baseline Model
By comparing the results of Approach 1, 2, and 3 to the baseline model, we can find that the per-class IoU scores on fence, pole, traffic sign, and traffic light get increased, and the overall mIoU scores also get increased in all three approaches (with a 1.76%, 1.87%, and 1.24% mIoU increase respectively, as you can see from the table). However, the model performance on both the car and vegetation classes degraded slightly. Before we start to analyze, there is something we need to know first: although still counted as fine-grained urban structures (from project description), car and vegetation classes generally have relatively larger sizes compared to the other 4 classes.
For the BASNet hybrid loss used in Approaches 1 and 2, SSIM loss is boundary-focused, providing stronger learning signals for objects that are mostly boundary, such as thin and small structures. IoU loss, on the other hand, is large-region focused, which actually helps large objects by emphasizing overall foreground confidence. However, SSIM’s boundary emphasis shifts overall model focus toward fine structures, and since model capacity is shared across all classes, this causes some degradation on some relatively large homogeneous regions. The original cross-entropy loss helps protect large objects by providing stable pixel-wise supervision across all pixels equally.
For the Lovász-based approach in Approach 3, SSIM remains boundary-focused as before. Lovász-Softmax loss differs from soft IoU in how gradients are computed. While soft IoU directly differentiates through the intersection-over-union ratio, Lovász uses a convex surrogate based on the Lovász extension, which sorts prediction errors by magnitude and applies class-specific gradient weights derived from the Jaccard index’s subgradients. Additionally, Approach 3 uses explicit class weighting in the cross-entropy loss (5× for fence, pole, and traffic sign), further amplifying supervision for fine-grained structures. These design choices explain why Approach 3 still improves over baseline on very small classes while showing similar trade-offs on relatively larger classes like car and vegetation.
The performance on larger objects did not degrade significantly because cross-entropy loss provides neutral, stable supervision for all pixels, and in the BASNet approaches specifically, IoU loss actually emphasizes large-region confidence which counterbalances SSIM’s boundary focus. Overall, we get better mIoU scores for all three approaches because we gain more on small and fine-grained classes than we lose on larger classes. Though all 6 classes are counted as fine-grained structures, the performance on “truly” small objects improved more than the performance on relatively larger objects worsened, which proves that the boundary-aware supervision strategy is valid for improving semantic segmentation on fine-grained urban structures.
Approach-to-Approach Comparison
When comparing the three approaches, Approach 2, which combines BASNet hybrid loss with copy-paste augmentation, generally achieves better performance than the other two approaches in both per-class IoU and mIoU, with a 0.11% mIoU improvement. The only exception is the fence class, where Approach 1 using BASNet hybrid loss alone performs better than Approach 2 with a 0.8% per-class IoU higher than Approach 2.
The reason fence degrades with copy-paste augmentation is that fence is fundamentally different from other classes. Fence has a mesh and grid structure with see-through patterns, and it has high context dependency. Copy-paste augmentation uses binary masks that treat fence as a solid blob, destroying its transparent mesh pattern, and places fence in random locations where fences never naturally appear, destroying spatial context. In contrast, other classes such as car, pole, traffic sign, and traffic light are self-contained objects whose identity comes from their internal appearance alone, making them more suitable for copy-paste augmentation. In general, Copy-paste Augmentation technique introduces helpful variability but also adds noise through unrealistic placements, hard binary edges, and context violations — these partially cancel out, leaving only small-to-modest net improvement.
It is also observed that Approach 3 did not work as well as we expected (with a 1.24 percentage point mIoU improvement, which is 0.52 points lower than Approach 1 and 0.63 points lower than Approach 2). We identify two potential reasons. First, soft IoU loss directly optimizes the intersection-over-union ratio through smooth gradients, providing stable global-shape supervision that complements SSIM’s boundary focus. Lovász-Softmax, while also optimizing IoU, uses a fundamentally different gradient mechanism based on sorting prediction errors by magnitude—this may interact less favorably with SSIM’s local window-based gradients. Second, the explicit class weighting (5× for fence/pole/sign) in cross-entropy may conflict with Lovász’s error-magnitude-based weighting scheme, potentially causing gradient instability rather than balanced learning.
In general, the Approach 2, combination of BASNet hybrid loss and copy-paste augmentation, helps improve model performance the most, achieving a 1.87% mIoU increase compared to the baseline model.
Visualization
In this part, we provide two example visualizations of the Approach 2 Model (which is the BASNet hybrid loss + copy-paste augmentation approach) and compare it with the baseline model (fully-finetuned SegFormer)
First visualization:
 Fig 2. Example Visualization 1 of Baseline Model.
Fig 2. Example Visualization 1 of Baseline Model.
 Fig 3. Example Visualization 1 of Approach 2 Model.
Fig 3. Example Visualization 1 of Approach 2 Model.
Second visualization:
 Fig 4. Example Visualization 2 of Baseline Model.
Fig 4. Example Visualization 2 of Baseline Model.
 Fig 5. Example Visualization 2 of Approach 2 Model.
Fig 5. Example Visualization 2 of Approach 2 Model.
From the example visualizations above we can see that the approach 2 is indeed improving the performance of the semantic segmentation task on fine-grained urban structures
Conclusion
In this project, we investigated methods to improve semantic segmentation performance on fine-grained urban structures using the SegFormer architecture. Starting from a fully fine-tuned SegFormer-B0 baseline, we explored three approaches that combined boundary-aware loss functions with data augmentation techniques.
Our experiments demonstrated that boundary-aware supervision—achieved through hybrid losses incorporating SSIM and IoU/Lovász components—consistently improves segmentation quality for small, thin urban structures such as poles, traffic signs, and traffic lights. All three approaches outperformed the baseline in terms of overall mIoU, with Approach 2 (BASNet Hybrid Loss + Copy-Paste Augmentation) achieving the best balance across most classes.
However, our results also revealed an inherent trade-off: the boundary-focused losses that benefit smaller objects can lead to slight performance degradation on relatively larger fine-grained urban structures like cars and vegetation due to gradient imbalance. This suggests that future work could explore class-aware loss weighting or adaptive loss scheduling to maintain performance across objects of varying scales.
We also observed that copy-paste augmentation, while generally beneficial for improving generalization, has limitations for context-dependent structures like fences. Objects with mesh-like patterns or strong spatial dependencies may require more sophisticated augmentation strategies that preserve their structural characteristics.
In summary, our findings confirm that shifting from purely pixel-wise supervision toward hybrid, boundary-aware objectives is a valid and effective strategy for improving segmentation of fine-grained urban structures—a capability critical for autonomous driving, urban mapping, and robotic perception systems. Future work could explore class-adaptive loss weighting, context-aware augmentation techniques, and scaling these methods to larger SegFormer variants to further improve performance across all object sizes.
Reference
[1] Xie, Enze, et al. “SegFormer: Simple and efficient design for semantic segmentation with transformers.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2021.
[2] Qin, Xuebin, et al. “BASNet: Boundary-aware salient object detection.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2019.
[3] Ghiasi, Golnaz, et al. “Simple Copy-Paste is a strong data augmentation method for instance segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2021.
[4] Berman, Maxim, et al. “The Lovasz-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.