From Paris to Seychelles - Deep Learning Techniques for Global Image Geolocation
Image geolocation—the task of predicting geographic coordinates from visual content alone—has evolved significantly with advances in deep learning. This survey examines four landmark approaches that have shaped the field. We begin with PlaNet (2016), which pioneered the geocell classification framework using CNNs and adaptive spatial partitioning based on photo density. We then explore TransLocator (2022), which leverages Vision Transformers and semantic segmentation maps to capture global context and improve robustness across varying conditions. Next, we analyze PIGEON (2023), which introduces semantic geocells respecting administrative boundaries, Haversine smoothing loss to penalize geographically distant predictions less harshly, and CLIP-based pre-training to achieve human-competitive performance on GeoGuessr. Finally, we examine ETHAN (2024), a prompting framework that applies chain-of-thought reasoning to large vision-language models, enabling interpretable geographic deduction without task-specific training. Through this progression, we trace the architectural evolution from convolutional networks to transformers to foundation models, highlighting key innovations in spatial partitioning strategies, loss function design, and the integration of semantic reasoning for worldwide image localization.
- Introduction
- PlaNet: The Classification Approach (2016)
- TransLocator: A New Architecture (2022)
- PIGEON: The Semantic Shift (2023)
- ETHAN (2024)
- Conclusion
- References
Introduction
Image geolocation is the task of predicting the geographic coordinates (latitude and longitude) of a given image. While humans rely on specific landmarks or cultural context, training a machine to recognize any location on Earth is a massive classification and regression challenge.
Early approaches relied on matching images to databases of landmarks, but these failed in “in the wild” scenarios where no distinct landmark is visible (e.g., a random road in rural Norway). Deep learning has since shifted this paradigm by learning global feature distributions and characteristics around the world.
In this survey, we explore how architectures have evolved from Convolutional Neural Networks (CNNs) to Transformers and CLIP-based models, specifically focusing on how they handle the partitioning of the Earth and the loss functions used to train them.
PlaNet: The Classification Approach (2016)
The pioneering paper Photo Geolocation with Convolutional Neural Networks [1], known as PlaNet, framed geolocation not as a regression problem (predicting raw coordinates), but as a classification problem.
The Concept of Geocells
To treat the world as a classification target, PlaNet subdivides the Earth into discrete regions called Geocells.
However, a uniform grid doesn’t work well because photo distribution is not uniform since there are millions of photos of Paris, but very few of the middle of the ocean for example. PlaNet thus introduces adaptive partitioning:
- Start with an S2 geometry grid.
- Recursively subdivide cells that contain too many photos.
- Stop when a cell reaches a target photo count.
This results in a map where dense urban areas have tiny, precise cells, while oceans and deserts have massive cells.
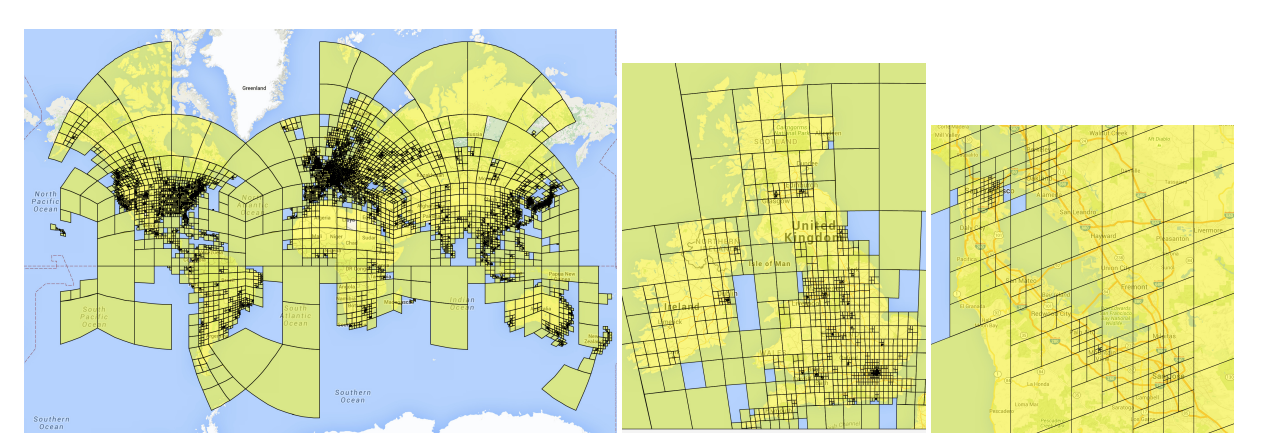
Fig 1. Adaptive partitioning of the world into Geocells based on photo density [1].
Architecture and Sequence Learning
PlaNet utilizes an Inception V3 architecture to classify images into one of these 26,263 geocells.
A key innovation in PlaNet was the use of LSTMs (Long Short-Term Memory) networks. Geolocation often happens in the context of a photo album. Knowing that the previous photo was taken at the Eiffel Tower heavily implies the current photo of a generic croissant is likely in Paris.
The model then outputs a probability distribution
\[P(c_i | I)\]over all geocells using the features extracted by the CNN backbone.
TransLocator: A New Architecture (2022)
The next major advancement in tackling geolocation as a classification problem is introduced in the paper Where in the World is this Image? Transformer-based Geo-localization in the Wild. The paper proposes TransLocator, a fundamentally different model architecture to PlaNet that makes use of transformers and semantic segmentation maps [2].
Transformers + Segmentaion
The TransLocator uses a vision transformer (ViT) as the backbone of the model, and contains two parallel ViT branches. One branch’s input is the RGB image, and the other’s is a semantic segmentation map of the image, obtained from HRNet pretrained on ADE20K.
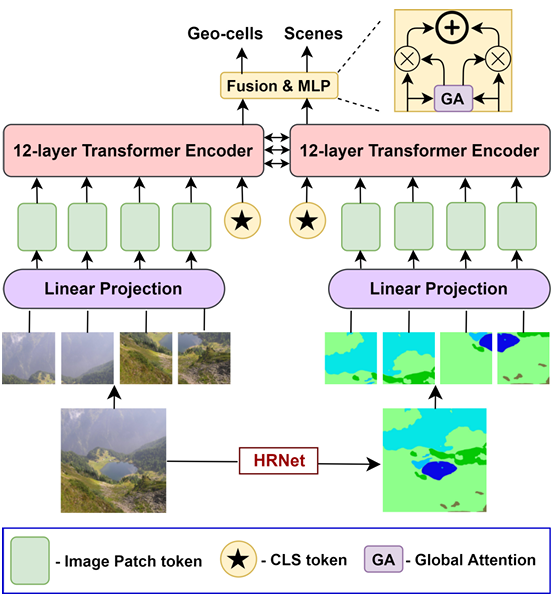
Fig 2. Overview of the proposed model TransLocator [2].
Both the RGB image and segmentation map are first divided into 16x16 pixel patches and passed into a trainable linear layer to create a sequence of tokens with added positional embeddings and a CLS token. Then, the token sequences are passed into two parallel 12-layer transformer encoders which interact with each other through Multimodal Feature Fusion (MFF). In MFF, after each layer, the CLS tokens from each branch are summed together before being passed back into the patch tokens of subsequent layers. After passing through all 12-layers, the representations from each branch are combined together using an attentive fusion mechanism called global attention. The final representation is then fed into 4 parallel classifier heads, where 3 of them predict the image’s location at 3 different resolutions (coarse, middle, fine) and 1 of them predicts the image’s scene category (e.g. indoor, urban, rural). Cross-entropy loss is used for each head, and the model is trained end to end with a weighted sum of losses from each of the four heads as follows:
\[\mathcal{L}_{total}=(1-\alpha-\beta)\mathcal{L}_{geo}^{coarse}+\alpha\mathcal{L}_{geo}^{middle}+\beta\mathcal{L}_{geo}^{fine}+\gamma\mathcal{L}_{scene}\]This approach of adding complementary tasks (coarse and middle resolution prediction, scene prediction) to the main task (fine resolution prediction) has been known to improve the results of the main task [2].
Comparison to PlaNet
The backbone of the PlaNet model, as mentioned earlier, utilizes the Inception V3, a CNN based architecture with fixed receptor field sizes. The authors argue that in the TransLocator, the self attention mechanism in the ViT layers gives TransLocator the ability to aggregate information from the entire image, allowing it to learn small but essential visual cues often missed by CNNs. PlaNet also trains on geo-tagged RGB images alone, while TransLocator’s additional semantic approach allows it to be more robust to extreme differences in appearance not necessarily caused by location (e.g. weather or time of day). These theoretical improvements are backed up by the clear outperformance of PlaNet by TransLocator across every dataset and distance scale [2].
| Dataset | Method | Street (1 km) | City (25 km) | Region (200 km) | Country (750 km) | Continent (2500 km) |
|---|---|---|---|---|---|---|
| Im2GPS | PlaNet | 8.4% | 24.5% | 37.6% | 53.6% | 71.3% |
| Im2GPS | TransLocator | 19.9% | 48.1% | 64.6% | 75.6% | 86.7% |
| Im2GPS3k | PlaNet | 8.5% | 24.8% | 34.3% | 48.4% | 64.6% |
| Im2GPS3k | TransLocator | 11.8% | 31.1% | 46.7% | 58.9% | 80.1% |
| YFCC4k | PlaNet | 5.6% | 14.3% | 22.2% | 36.4% | 55.8% |
| YFCC4k | TransLocator | 8.4% | 18.6% | 27.0% | 41.1% | 60.4% |
| YFCC26k | PlaNet | 4.4% | 11.0% | 16.9% | 28.5% | 47.7% |
| YFCC26k | TransLocator | 7.2% | 17.8% | 28.0% | 41.3% | 60.6% |
Table 1. Geolocational accuracy of PlaNet vs TransLocator compared to several datasets and distance scales [2].
Persisting Limitations
Upon analyzing the errors made by TransLocator, the authors found that the model could not properly locate images without enough geo-locating clues. For example, images of just a cherry blossom tree were not accurately located by TransLocator, as there are many major locations around the world where cherry blossom trees reside. Likewise, images without sufficient background clues, such as plain beaches or desserts, cannot be consistently accurately predicted [2].

Fig 3. Some examples of incorrectly geo-located images [2].
PIGEON: The Semantic Shift (2023)
The next leap forward comes from PIGEON (Pre-trained Image GEO-localization Network) [3]. This model was designed to compete against top human GeoGuessr players. Geoguessr is a popular browser game designed around humans guessing where you are in the world based on an image or 3D explorable space travelable via Google Streetview.
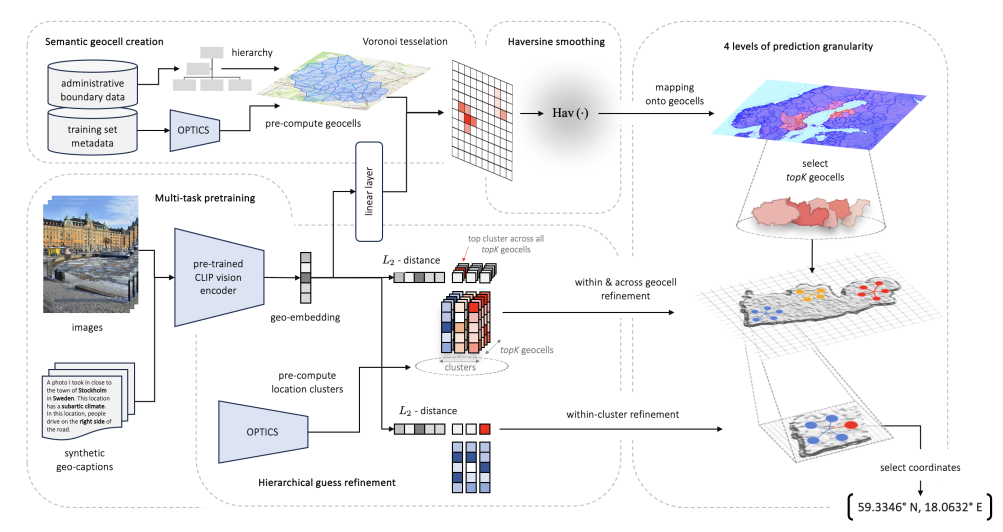
Fig 4. Prediction pipeline and main contributions of PIGEON.
Semantic Geocells
PIGEON refines the geocell concept. While PlaNet split cells based purely on photo density, PIGEON incorporates administrative boundaries.
- PlaNet: Splits a cell if it has too many photos, regardless of borders.
- PIGEON: Tries to respect country/region borders. This creates “Semantic Geocells,” preventing the model from confusing two neighboring countries that might look similar but have different road markings or signage.
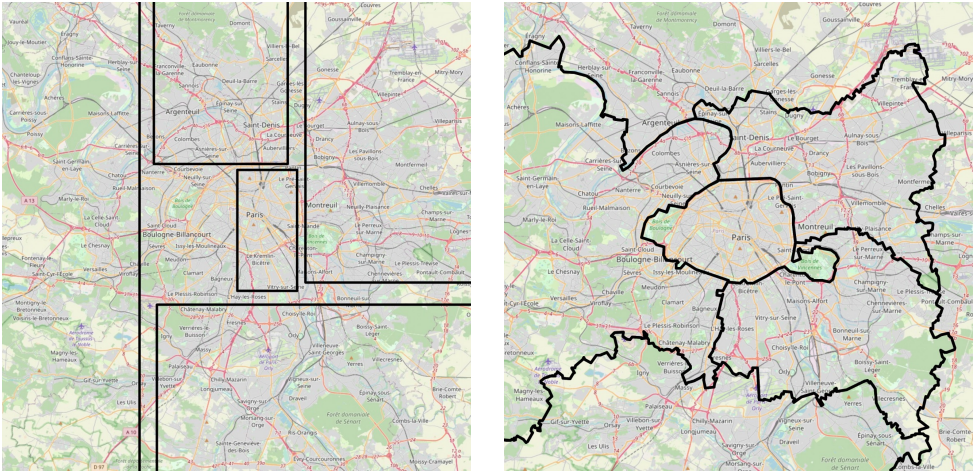
Fig 5. a) Old Naive geocells b) Pigeon’s semantic geocells [3].
Haversine Smoothing Loss
A major limitation of PlaNet’s classification approach is that it penalizes “near misses” just as harshly as “far misses.” If the model guesses a cell 1km away from the correct one, standard One-Hot encoding treats it the same as guessing a cell on a different continent.
To fix this, PIGEON replaces standard labels with Haversine Smoothing. Instead of the correct cell being a 1 and all others 0, neighboring cells get a partial label based on their physical distance to the image.
First, they define the Haversine Distance between two points \(\mathbf{p}_1\) and \(\mathbf{p}_2\) on Earth:
\[\text{Hav}(\mathbf{p}_1, \mathbf{p}_2) = 2r \arcsin \left( \sqrt{\sin^2 \left( \frac{\phi_2 - \phi_1}{2} \right) + \cos(\phi_1) \cos(\phi_2) \sin^2 \left( \frac{\lambda_2 - \lambda_1}{2} \right)} \right)\]They then generate a “smoothed” label \(y_{n,i}\) for every geocell \(i\) relative to the true image location \(\mathbf{x}_n\). Cells closer to the true location receive a higher value:
\[y_{n,i} = \exp \left( - \frac{\text{Hav}(\mathbf{g}_i, \mathbf{x}_n) - \text{Hav}(\mathbf{g}_n, \mathbf{x}_n)}{\tau} \right)\]Finally, the Loss Function \(\mathcal{L}_n\) minimizes the difference between the predicted probability \(p_{n,i}\) and this smoothed distance label:
\[\mathcal{L}_n = - \sum_{g_i \in G} \log(p_{n,i}) \cdot y_{n,i}\]This ensures that the gradient penalty is lower if the model predicts a location that is geographically close to the target, effectively teaching the model a continuous topology of the Earth.
CLIP Pre-training & Retrieval
PIGEON utilizes CLIP (Contrastive Language-Image Pre-training) from OpenAI as its backbone. CLIP is trained on 400 million image-text pairs, so it already possesses a deep understanding of visual concepts, even before it is fine-tuned for location. It also introduces intra-cell retrieval to refine the exact location by looking up similar images within the predicted geocell.
Results
After several other finetuning features discussed in the paper but not here, PIGEON achieved landmark results and near pefect accuracy on country and continent classification:
| Ablation Configuration [Distance (% @ km)] | Street (1 km) | City (25 km) | Region (200 km) | Country (750 km) | Continent (2,500 km) |
|---|---|---|---|---|---|
PIGEON (Full Model) |
5.36 |
40.36 |
78.28 | 94.52 | 98.56 |
| Freezing Last CLIP Layer | 4.84 | 39.86 | 78.98 |
94.76 | 98.48 |
| Hierarchical Refinement | 1.32 | 34.96 | 78.48 | 94.82 |
98.48 |
| Contrastive Pretraining | 1.24 | 34.54 | 76.36 | 93.36 | 97.94 |
| Semantic Geocells | 1.18 | 33.22 | 75.42 | 93.42 | 98.16 |
| Multi-task Prediction | 1.10 | 32.74 | 75.14 | 93.00 | 97.98 |
| Fine-tuning Last Layer | 1.10 | 32.50 | 75.32 | 92.92 | 98.00 |
| Four-image Panorama | 0.92 | 24.18 | 59.04 | 82.84 | 92.76 |
| Haversine Smoothing | 1.28 | 24.08 | 55.38 | 80.20 | 92.00 |
Table 2. PIGEON Model results on a holdout dataset of 5,000 Street View locations [3].
While some may call the above results unimpressive, they then compare PIGEON’s results to ranked players on GeoGuessr to more fairly contextualize results:

Fig 6. PIGEON Model Comparison to Ranked GeoGuessr players. Champion Division being top 0.01% of all players.
ETHAN (2024)
ETHAN introduces a framework that leverages existing large vision language models(LVLMs). While PlaNet and PIGEON achieved impressive results, they operate as pattern matching systems, relying on visual features tied to geocells. ETHAN, instead, attempts to mimic human geoguessing strategies by analyzing visual and contextual cues such as architectural, natural, and cultural elements. It replicates this reasoning process through chain-of-thinking prompting built on top of existing VLMs.
Vision-Language Models:
ETHAN is a prompting framework that relies on existing VLM models. They test their prompting framework on top of GPT-4o and LLaVA. These models have the architecture of Vision Encoder + projection + generative language model, combining context from image and text tokens. Ethan leverages this pre-existing knowledge without additional training
Chain-Of-Thought Geolocation
The core innovation lies in the use of chain-of-thought(CoT) prompting that guide VLMs through structured geolocation reasoning. ETHAN produces intermediate reasoning steps that mirror human geographic deduction.
A typical reasoning hierarchy looks like the following:
- Visual clue extraction: architecture, vegetation, road signs, infrastructure
- Geographic constraint Reasoning: apply world knowledge to narrow possibilities
- Progressive Refinement: Continent->Country->Region->Coordinates
- Uncertainty Quantification: Express confidence and alternate hypotheses
GPS Module Prompting Strategy:
ETHAN introduces the GPS (Geolocation Prompting Strategy) module, which structures how queries are presented to VLMs. Since VLMs are general-purpose models not specifically trained for geolocation, careful prompt design is crucial for strong geographic reasoning.
A typical prompt looks like:
You are the leading expert in geolocation research. You have been presented with an image, and your task is to determine its precise geolocation, specifically identifying the country it was taken in. To accomplish this, examine the image for broad geographic indicators such as architectural styles, natural landscapes, language on signs, and culturally distinctive elements to suggest a particular country. Narrow down the location by identifying regional characteristics like specific flora and fauna, types of vehicles, and road signs that can indicate a particular region or subdivision within the country. Focus on highly specific details within the image, such as unique landmarks, street names, or business names, to pinpoint an exact location. For instance, if the place is address, with coordinates lat, lon, explain how these elements led you to this conclusion by analyzing visual clues, cross-referencing data with known geographic information, and validating your findings with additional sources
The GPS module can be enhanced with few-shot examples, providing 2-3 sample images with reasoning chains to prime the VLM’s logical patterns and calibrate confidence levels.
Deriving Coordinates
To calculate coordinates form textual reasoning, ETHAN employs several strategies:
- Direct Coordinate Prediction: VLMs output coordinates for recognized landmarks
- Geocoding Integration: Convert place names (“Stockholm, Sweden”) to coordinates via APIs
- Hierarchical Averaging: Use region centroids when only broad areas are identified
- Multi-Hypothesis Handling: Process multiple candidates with associated probabilities
Results
| Method / Distance (% @ km) | Street (1 km) | City (25 km) | Region (200 km) | Country (750 km) | Continent (2,500 km) | Avg Dist (km) | Avg Score |
|---|---|---|---|---|---|---|---|
| StreetClip | 4.9 | 39.5 | 77.8 |
93.0 |
97.5 | 120.5 | 3500.0 |
| GeoClip | 3.6 | 38.4 | 75.2 | 92.4 | 97.2 | 135.2 | 3700.0 |
-GPT4o- |
|||||||
| Zero-shot | 5.5 | 40.8 | 71.0 | 85.0 | 93.0 | 160.3 | 3800.0 |
| Few-shot | 6.2 | 41.5 | 72.5 | 86.5 | 94.5 | 155.0 | 3900.0 |
| CoT | 6.0 | 42.0 | 73.0 | 87.0 | 95.0 | 150.7 | 4000.0 |
-LLaVA- |
|||||||
| Zero-shot | 7.0 | 43.2 | 74.0 | 88.0 | 96.0 | 140.7 | 4100.0 |
| Few-shot | 6.5 | 42.8 | 74.5 | 89.5 | 97.5 | 137.5 | 4200.0 |
| CoT | 7.2 | 44.5 | 76.0 | 90.0 | 98.0 | 135.2 | 4300.0 |
| GeoSpy | 25.5 | 53.7 | 74.1 | 89.4 | 98.3 | 110.3 | 4400.0 |
ETHAN |
27.0 |
55.0 |
75.5 | 91.2 | 99.0 |
105.0 |
4600.0 |
Table 3. Results of ETHAN Prompting framework with SOTA LVLMs on custom dataset[4].
ETHAN performs strongly, with high accuracy in country and continent classification, on par with Pigeon. As compared to previous strategies, ETHAN benefits from increased interpretability, zero-shot generalization, but has higher computational costs as VLM inference is slower. Additionally, it can suffer from hallucination risks where generative model recognizes non-existent models or applies incorrect assumptions.
Conclusion
The progression from PlaNet to ETHAN illustrates a fundamental shift in image geolocation architectures. Early CNN-based approaches like PlaNet established geocell classification as a viable framework, while TransLocator demonstrated the advantages of transformer architectures and multi-modal inputs through semantic segmentation.
Future work will likely focus on hybrid architectures that combine the computational efficiency of learned embeddings with the reasoning capabilities of VLMs. Possible research directions include developing loss functions that better capture hierarchical geographic relationships, improving geocell partitioning strategies that balance semantic coherence with training efficiency, and addressing the persistent challenge of performance degradation in underrepresented geographic regions where training data remains sparse.
References
[1] Weyand, Tobias, Ilya Kostrikov, and James Philbin. “Planet-photo geolocation with convolutional neural networks.” European Conference on Computer Vision. Springer, Cham, 2016.
[2] Pramanick, Shraman, et al. “Where in the World is this Image? Transformer-based Geo-localization in the Wild.” arXiv:2204.13861, 2022. https://doi.org/10.48550/arXiv.2204.13861
[3] Haas, Lukas, et al. “PIGEON: Predicting Image Geolocations.” arXiv preprint arXiv:2307.05845, 2023. https://doi.org/10.48550/arXiv.2307.05845 (Accepted at CVPR 2024.)
[4] Liu, Yi, et al. “Image-Based Geolocation Using Large Vision-Language Models.” arXiv:2408.09474, 2024. https://doi.org/10.48550/arXiv.2408.09474