Scale Up VLM for Embodied Scene Understanding
[Project Track: Self-Propose-Topic] Spatial reasoning and object-centric perception are central to deploying Vision–Language Models (VLMs) in embodied systems, where agents must interpret fine-grained scene structure to support action and interaction. However, current VLMs continue to struggle with fine-grained visual reasoning, particularly in the object-centric tasks that demand visual understanding that requires dense visual perception. We introduced VLIMA, a guided fine-tuning framework that enhances VLMs by incorporating auxiliary visual supervision from external self-supervised vision encoders. Specifically, VLIMA adds an auxiliary alignment loss that encourages intermediate VLM representations to match features from encoders such as DINOv2, which exhibit emergent object-centricity and strong spatial correspondence. By transferring these spatially precise and object-aware inductive biases into the VLM representation space, VLIMA improves object-centric embodied scene understanding without calling external tools or modifying the VLM’s core architecture.
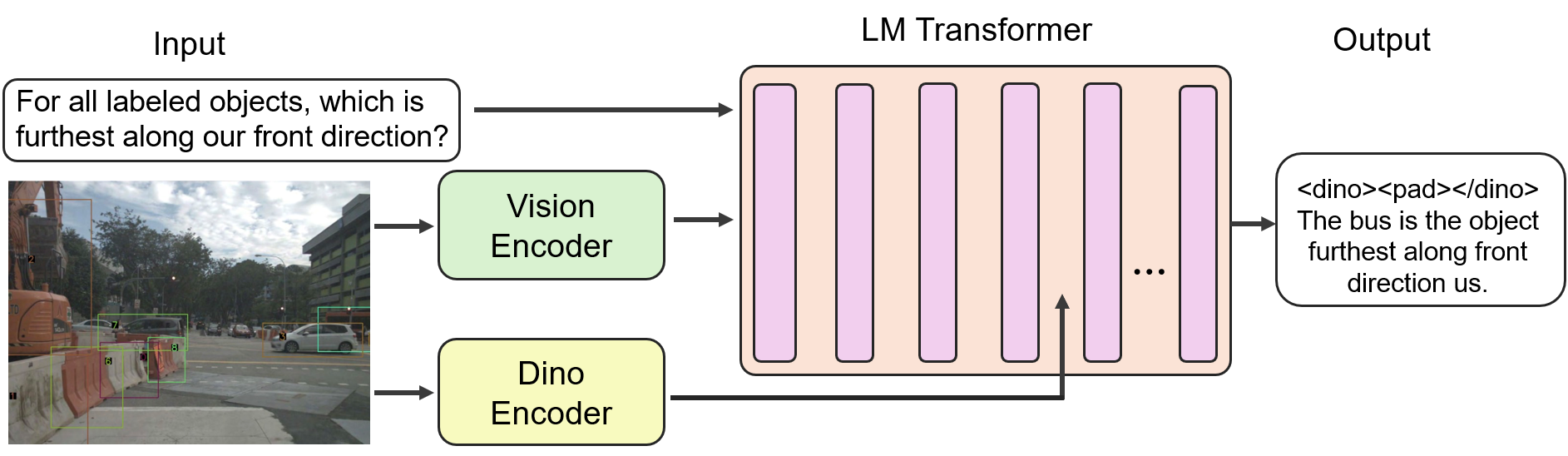
Fig 1. VLIMA introduced a guided fine-tuning method that enhances VLMs by incorporating visual supervision from external DINO encoders and aligned DINO features with model’s intermediate features.
Introduction
Vision–language models (VLMs) combine a vision encoder with a large language model to interpret images and generate natural-language responses, enabling unified perception-and-reasoning for tasks such as visual question answering, captioning, and embodied decision making. Despite rapid progress and strong benchmark results, many recent failures on vision-centric evaluations point to an integration gap: rich visual evidence exists in the model’s latent representations, but it is not consistently accessed or utilized when the model must express answers through the language interface [1]. We introduced VLIMA, a guided fine-tuning framework that enhances VLMs by incorporating auxiliary visual supervision from external self-supervised vision encoders. Specifically, VLIMA adds an auxiliary alignment loss that encourages intermediate VLM representations to match features from encoders such as DINOv2, which exhibit emergent object-centricity and strong spatial correspondence. We evaluate VLIMA on MetaVQA, BLINK, MMVP, and MMStar, where it consistently outperforms the baseline. Further ablations show that applying alignment within transformer intermediate states yields larger gains than adding it only to the output step.
Related Work
Current approaches in vision–language models (VLMs), such as Qwen2.5-VL [5], emphasize fine-grained visual perception and agentic interaction, achieving improved visual recognition, spatial grounding, document understanding, and long-video comprehension.
Recent work has begun to question whether strong performance in vision language models (VLMs) truly reflects effective utilization of visual representations. [1] argue that many VLM failures on vision-centric benchmarks reflect an integration gap rather than weak visual features. They compare standard VQA prompting with direct probing of the underlying vision encoder on tasks from CV-Bench, BLINK, and MOCHI, and find that accuracy often drops to near-chance when answers must be produced through language, despite the visual representations being sufficient.
Fig 2. The demo figure for REPA architecture.
REPA [4] introduces a representation alignment regularizer for diffusion transformers that explicitly aligns noisy intermediate hidden states with clean features from a pretrained vision encoder, thereby encouraging models to preserve semantically meaningful visual structure throughout generation and improving downstream reasoning fidelity.
Method
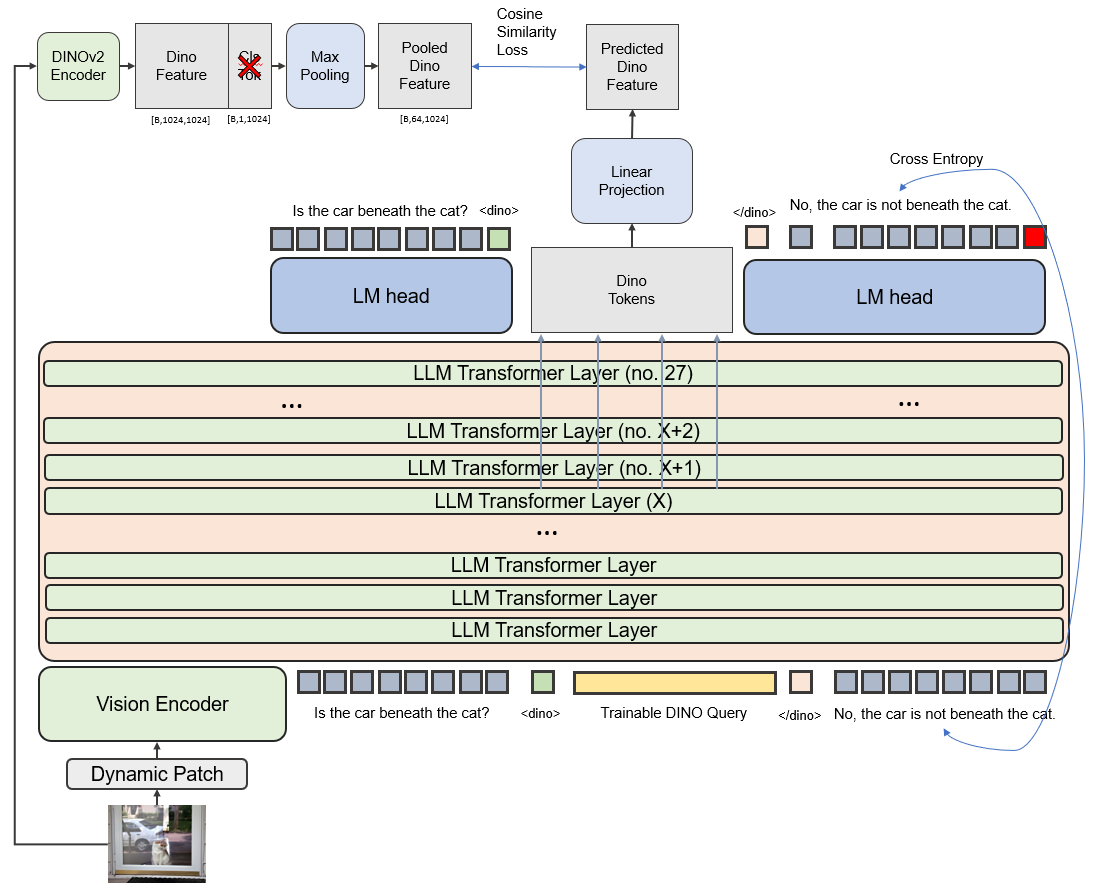
Fig 3. The Training Pipeline of VLIMA. VLIMA augments a vision–language model with a trainable continuous token block inserted after a special <dino> token as a marker. During training, the hidden states of this block are projected and aligned with frozen DINOv2 features via a reconstruction dino loss, while the model is jointly optimized with the standard language modeling objective. At inference time, the model emits <dino> to trigger the insertion of the learned token block as DINO feature reasoning, after which generation resumes at </dino> to produce the final answer.
Overview
Despite strong semantic alignment, existing VLMs exhibit key limitations when deployed for embodied scene understanding. These questions require spatially grounded and object-centric representations, yet end-to-end image–text training often underemphasizes token-level structure and dense correspondence. In contrast, self-supervised ViT encoders such as DINO series are known to produce features with emergent object-centric organization and semantics-aligned spatial structure at the token level. Motivated by representation alignment ideas in generative modeling (e.g., REPA), we introduce VLIMA, which adds an auxiliary alignment loss to guide intermediate VLM features toward a frozen DINO encoder, injecting the spatial/grounding perception which needed for embodied VQA into VLMs.
VLMs follows the standard next-token prediction paradigm. Let a VLM consist of a visual encoder \(\mathcal{V}\) and a language model \(\mathcal{T}\) with hidden size \(d_T\). For a given image-text pair \((x_{\text{img}}, x_{\text{txt}})\), the VLM encodes \(x_{\text{img}}\) into a sequence of visual tokens, which are then passed to \(\mathcal{T}\) along with text tokens. The VLM estimates the probability of generating a sequence \(Y =(y_1, y_2, ..., y_n)\) as:
\[Y = \mathcal{T}(\mathcal{V}(x_{\text{img}}), x_{\text{txt}})\]As shown in Fig 3, VLIMA learns to produce a <dino> token that triggers insertion of a fixed-length trainable token block whose hidden states features are supervised to match projected DINOv2 features, after which generation resumes at </dino> to produce the final answer. Specifically,
-
During training, VLIMA adds an additional trainable “continuous-token” padding block and supervises the VLM to align the block’s intermediate hidden states (after a lightweight projection) with frozen DINOv2 features, while jointly learning to generate the correct
<dino>…</dino>span and the final textual answer. -
At inference time, once the model outputs
<dino>, we replace the following with the learned “continuous-token” padding block. The aligned feature tokens will automatically decode inside hidden states until</dino>, and then continue normal text generation for answering the question.
Cross-Modal Representation Alignment
VLIMA extract features \(f_{\mathcal{E}} \in \mathbb{R}^{M \times d_E}\) from the external DINOv2 Encoder \(\mathcal{E}\), which produces dense patch-level outputs for the same image. DINOv2 produced \(1025\) tokens with \(1024\) feature tokens corresponding to \(16 \times 16\) patches and a [CLS] token. This might be too much for the model to produced. Thus we downsampled it through a \(4 \times 4\) max pooling to produced DINO feature \(f_{\mathcal{E}_{proj}} \in \mathbb{R}^{N_q \times d_E}\) with \(N_q = 8 \times 8 = 64\):
\[f_{\mathcal{E}_{pool}} = \text{MaxPool}_{4 \times 4}(f_{\mathcal{E}}) \in \mathbb{R}^{T \times d_E}\]We define the trainable padding \(t_{\text{padding}} \in \mathbb{R}^{N_q \times d_T}\) with the hidden features \(f^{(4)}_{\text{padding}} \in \mathbb{R}^{N_q \times d_T}\) after 4 layers of transformer blocks in \(\mathcal{T}\). As the hidden size of language model \(d_T \neq d_E\), we introduce a projection head \(P : \mathbb{R}^{d_T} \rightarrow \mathbb{R}^{d_E}\) to map trainable padding’s hidden features into the DINO feature space:
\[f_{\text{padding}_{proj}} = P(f^{(4)}_{\text{padding}}) \in \mathbb{R}^{T \times d_E}\]The resulting projected representation is compared to the pooled feature. We define this target as the feature alignment loss as:
\[\mathcal{L}_{\text{DINO}} = \mathcal{L}_{\text{sim}} + \mathcal{L}_{\mathrm{mdms}}\] \[\mathcal{L}_{\text{sim}} = \operatorname{ReLU}\bigl(1 - \frac{f_{\mathcal{E}_{pool}} \cdot f_{\text{padding}_{proj}}}{||f_{\mathcal{E}_{pool}}|| \times ||f_{\text{padding}_{proj}}||})\] \[\mathcal{L}_{\mathrm{mdms}}= \frac{1}{N^2} \sum_{i,j} \operatorname{ReLU} \left( \left| \frac{f_{\mathcal{E}_{pool}}^{(i)} \cdot f_{\mathcal{E}_{pool}}^{(j)}}{\|f_{\mathcal{E}_{pool}}^{(i)}\| \, \|f_{\mathcal{E}_{pool}}^{(j)}\|} - \frac{f_{\text{padding}_{proj}}^{(i)} \cdot f_{\text{padding}_{proj}}^{(j)}}{\|f_{\text{padding}_{proj}}^{(i)}\| \, \|f_{\text{padding}_{proj}}^{(j)}\|} \right| \right)\]Specifically, \(\mathcal{L}_{\text{sim}}\) optimized the cosine similarity of the alignment feature with the actual feature at each spatial location. Penalizing only poorly aligned regions via a ReLU. \(\mathcal{L}_{\mathrm{mdms}}\) encourages global structural consistency. Preserving relational geometry across spatial locations while ignoring minor discrepancies through a margin. This alignment mechanism regularizes the VLM to internalize semantically meaningful patterns from the external encoder, much help the VLM “speak to learn” the features and representations of image. We jointly optimize the standard autoregressive language modeling loss \(\mathcal{L}_{\text{LM}}\) and the proposed alignment loss:
\[\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{LM}} + \lambda \cdot \mathcal{L}_{\text{DINO}}\]where \(\lambda\) is a tunable hyperparameter that governs the influence of the external alignment signal during fine-tuning.
This objective allows VLIMA to preserve the original task while injecting powerful external visual priors, improving spatial/grounding capability for embodied VQA for VLMs.
Implementation Detail (Code)
We choose to use Qwen2.5-VL-Instruct as our base model and trained the model with InternVL-SFT data. In this section, we will introduced the detail code implementation of our method.
Model Designs
Trainable Padding is simply defined as a new empty parameters, it will be attached inside Qwen2.5VL model.
self.trainable_dino_padding = nn.Parameter(torch.randn((1, self.alignment_token_size, 3584)), requires_grad=True)
The decode projection is simply defined as a linear projection, we used a module list for future convenient with multiple encoders.
self.encoder_projection_decoder.append(nn.Linear(3584, encoder_shape_i[0], bias=True))
The DINO feature loss is defined as an external function:
def cosine_loss(self, x, y, mu=0): # L_sim
return (F.relu((1 - F.cosine_similarity(x, y) - mu))).mean()
def reconstruction_loss(self, x, y, mu=0): # L_mdms
# Normalize the input tensors
x = F.normalize(x, dim=1)
y = F.normalize(y, dim=1)
x_sim = torch.einsum('bci,bcj->bij', x, x)
y_sim = torch.einsum('bci,bcj->bij', y, y)
diff = torch.abs(x_sim - y_sim)
# Compute the cosine similarity loss
return (F.relu(diff - mu)).mean()
Training Design
In order to correctly match and take out the features aligned with trainable padding, we externally defined a new token <dino_pad> for dino paddings, this will not fed into tokenizer but directly replaced with the trainable padding before text embedding.
# find dino paddings
mask = input_ids == self.config.encoder_token_id
mask_unsqueezed = mask.unsqueeze(-1)
mask_expanded = mask_unsqueezed.expand_as(inputs_embeds)
dino_mask = mask_expanded.to(inputs_embeds.device)
# replaced with trainable features
inputs_embeds = inputs_embeds.masked_scatter(dino_mask, replaced_trainable_dino_padding.to(inputs_embeds.device))
We will also use this to extract dino features from LM output
all_hidden_features = outputs.hidden_states[self.token_align_layer][..., :-1, :] # shifted hidden state
dino_token_mask = (input_ids == self.config.encoder_token_id)[0][1:] # one digit move from input to output
hidden_features = all_hidden_features[..., dino_token_mask, :] # [B , 64 , 3584]
Generation Design
Since special tokens are added to the output part of the model, an optimized generation pipeline is also designed to make sure the model is able to output <dino begin> token then we could attach the trainable padding on to the model. We attached the quick psudocode here for reference how to implement the generation pipeline.
def generate(
... # generate params
):
dino_begin_token = 151665 # DINO_BEGIN_TOKEN
dino_end_token = 151666
dino_pad_token = 151667
dino_feature = []
... # initializing KV cache, attention records, output tokens...
while generated.size(1) < max_length:
... # single step of model
model_token_output = torch.argmax(logits, dim=-1, keepdim=True)
if dino_begin_token in model_token_output: # hit DINO token, next output will be 64 len dino feature
... # update cache position
# prepare for one more time of generation with trainable paddings
model_inputs = self.prepare_inputs_for_generation(generated, past_key_values=past_key_values, cache_position=cache_position, **generate_kwargs)
dino_internal_prediction_quick = self(**model_inputs, return_dict=True)
# the first 64 logits this time is meaningless, thus only keeping the last one
logits = dino_internal_prediction_quick.logits[:, -1, :] # [bsz, vocab_size]
model_token_output = torch.argmax(logits, dim=-1, keepdim=True)
# the features are on the first 64 output, extract it if needed
dino_feature.append(dino_internal_prediction_quick.hidden_states[2][:, :-1, :])
outputs = dino_internal_prediction_quick
... # update output, cache and early stop
return generated
Experiment
Experiment Setup
In our experiments, we followed CoVT’s design [2], Qwen2.5-VL-7B [5] is selected as the main baseline, we uses LoRA [7] tuning method, while the rank and Alpha of LoRA is both 32. The learning rate of LoRA and projection layers are set as 1e-4. We trained the model for 8000 steps on InternVL-SFT [6] dataset and set the Global (Total) Batch size to 16. The experiments are carried out on one A100 (about 30 hours) or four A6000 GPUs (about 10 hours).
Main Result
Demo
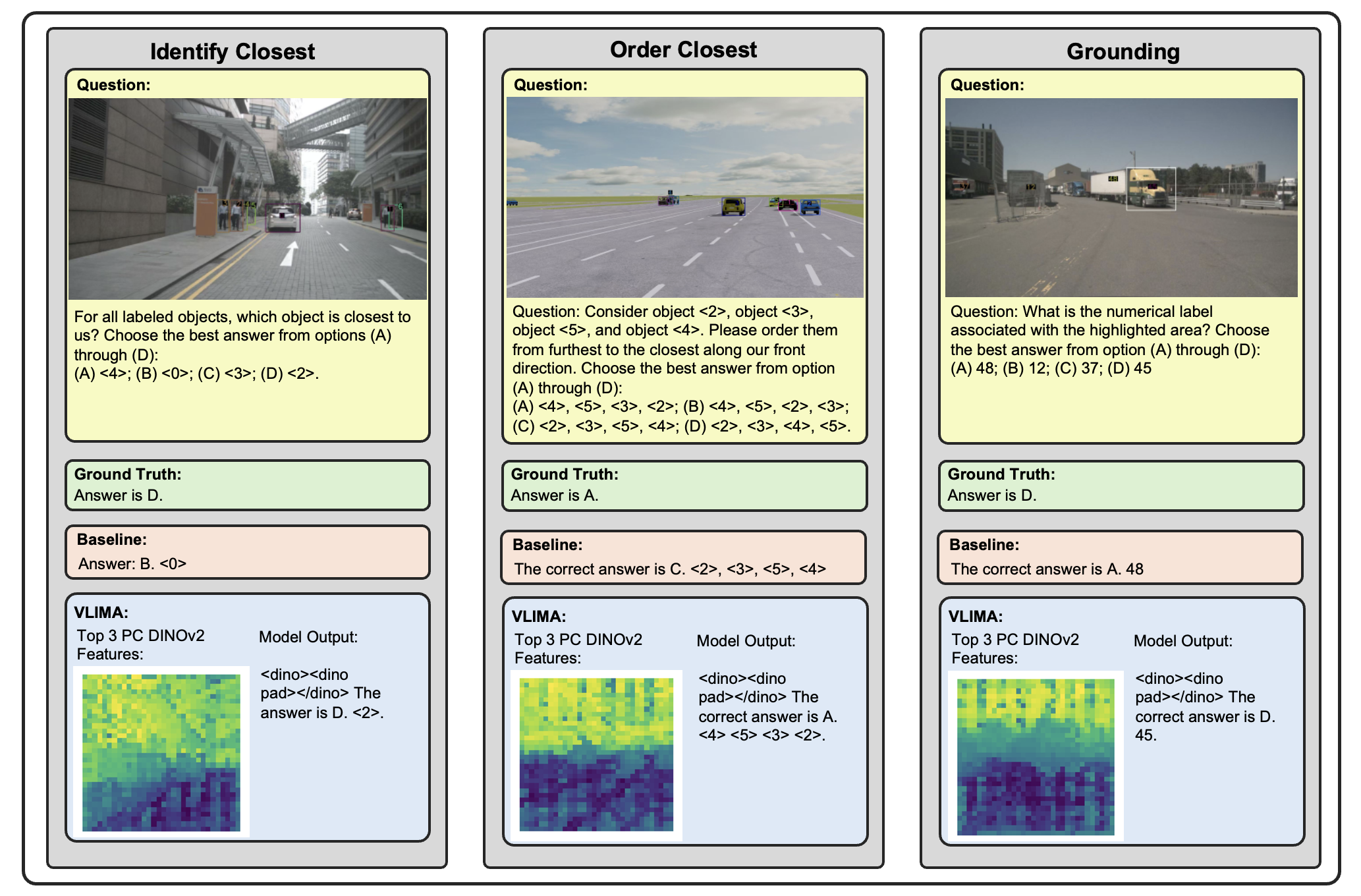
Fig 3. Qualitative Demo results on MetaVQA [3]. VLIMA consistently outperforms the baseline on spatial and grounding questions by decoding aligned DINOv2 features through the <dino> token span, enabling object-centric and spatially grounded reasoning.
MetaVQA
| MetaVQA | Overall | Real | Sim |
|---|---|---|---|
| ChatGPT-4o | 0.628 | 0.655 | 0.602 |
| Baseline (Qwen2.5VL-7B) | 0.617 | 0.631 | 0.604 |
| Ours (VLIMA) | 0.629 | 0.647 | 0.610 |
Table 1. On the MetaVQA benchmark, our method improve over the baseline. Notably, the largest gains are observed on the “identify all non-ego agents” subset, where our approach attains an average accuracy of 0.649 compared to the baseline’s 0.630, indicating stronger holistic object recognition and more complete scene understanding.
Additional Benchmark
| Task | Average | BLINK [8] | MMVP [9] | MMStar [10] |
|---|---|---|---|---|
| Baseline (Qwen2.5VL-7B) | 0.5828 | 0.5576 | 0.5667 | 0.6240 |
| Ours (VLIMA) | 0.5969 | 0.5671 | 0.5933 | 0.6303 |
Table 2. Our VLIMA method’s performance on other vision centric benchmarks. VLIMA shows a consistent improvements across all tested vision centric benchmarks.
Ablation Studies
To isolate the contribution of DINO feature alignment, we conducted ablation comparing with pure training without feature alignment and last token prediction (alignment with the last layer).
| Task | Average | BLINK | MMVP | MMStar |
|---|---|---|---|---|
| Baseline (Qwen2.5VL-7B) | 0.5828 | 0.5576 | 0.5667 | 0.6240 |
| Ours (VLIMA) | 0.5969 | 0.5671 | 0.5933 | 0.6303 |
| Pure Training | 0.5672 | 0.5476 | 0.5467 | 0.6072 |
| Token Prediction | 0.5727 | 0.5260 | 0.5733 | 0.6188 |
Table 3. VLIIMA Ablation Study. Pure Training applies additional training without DINO-based feature alignment and yields no consistent improvement over the baseline. Token Prediction aligns DINO features only at the final layer, demonstrating limited gains. In contrast, VLIMA’s intermediate feature alignment consistently improves performance across BLINK, MMVP, and MMStar, highlighting the importance of guiding internal representations rather than relying on token-level supervision alone.
Conclusion
In this work, we introduced VLIMA, a framework for enhancing object-centric and spatial reasoning in vision–language models for embodied scene understanding. By inserting a trainable continuous-token block and aligning intermediate VLM representations with frozen DINOv2 features through an auxiliary alignment loss, VLIMA injects strong spatial and object-aware inductive biases without modifying the backbone architecture or relying on external tools at inference time.
Empirical results on MetaVQA and additional embodied benchmarks demonstrate that VLIMA consistently improves performance over strong baselines, with particularly notable gains on tasks requiring holistic object identification and spatial grounding. Ablation studies further confirm that the proposed feature-level alignment plays a critical role beyond standard fine-tuning or token-level supervision.
Overall, VLIMA shows that explicit representation alignment is a promising direction for closing the integration gap between visual perception and language reasoning in VLMs. We believe this approach offers a scalable and generalizable pathway for equipping future multimodal models with stronger embodied and spatial understanding and opens up avenues for integrating other self-supervised visual priors into large multimodal systems.
For future improvements, one limitation is that DINOv2 features are extracted at a fixed relative low resolution (\(224 \times 224\)), which can under-represent fine-grained details in large scenes and make the alignment less helpful for small or distant objects. A natural next step is to incorporate multi-scale and/or higher-resolution feature extraction so that the aligned continuous-token block can capture both global layout and small-object cues, improving robustness across diverse embodied viewpoints and scene scales.
Summary
- Codebase Usage:
- MetaVQA: https://github.com/metadriverse/MetaVQA.git
- Qwen2.5VL (the code base is updated): https://github.com/QwenLM/Qwen3-VL.git
- We impliment our idea on Qwen2.5VL
- VLMEvalKit: https://github.com/open-compass/VLMEvalKit.git
- We impliment the MetaVQA testing on VLMEvalKit
- Main Contributions
- Identified that current VLMs struggle with fine-grained, object-centric spatial reasoning required for embodied scene understanding, largely due to insufficient dense perceptual supervision.
- Proposed VLIMA, a guided fine-tuning framework that aligns intermediate VLM features with frozen DINOv2 representations via an auxiliary loss, injecting object-centric and spatial priors without changing the base architecture.
- Tested and proofed that VLIMA consistently improves performance on MetaVQA, BLINK, MMVP, and MMStar, and ablations show intermediate-state alignment outperforms output-only alignment.
Reference
[1] Fu, Stephanie, et al. “Hidden in plain sight: VLMs overlook their visual representations.” Proceedings of COLM and CVPR EVAL-FoMo 2 Workshop Best Paper Award. 2025.
[2] Qin, Yiming, Wei, Bomin el al. “Chain-of-Visual-Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens.” arXiv:2511.19418v2. 2025
[3] Wang, Weizhen, et al. “Embodied Scene Understanding for Vision Language Models via MetaVQA.” Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2025.
[4] Yu, Sihyun, et al. “Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think.” Proceedings of the International Conference on Learning Representations. 2025.
[5] Bai, Shuai, et al. “Qwen2.5-VL Technical Report.” arXiv:2502.13923. 2025.
[6] Chen, Zhe, et al. “Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling.” (InternVL2) arXiv:2412.05271. 2024
[7] Hu, Edward J., et al. “LoRA: Low-Rank Adaptation of Large Language Models.” Proceedings of the International Conference on Learning Representations (ICLR). 2022.
[8] Fu, Xingyu, et al. “BLINK: Multimodal Large Language Models Can See but Not Perceive.” Proceedings of the European Conference on Computer Vision (ECCV). 2024.
[9] Chen, Lin, et al. “Are We on the Right Way for Evaluating Large Vision-Language Models” Neural Information Processing Systems. 2024
[10] Tong, Shengbang, et al. “Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs.” Proceedings of the IEEE conference on Computer Vision and Pattern Recognition 2024.