Unsupervised Domain Adaptation for Semantic Segmentation
Data annotation is widely considered a major bottleneck in semantic segmentation. It leads to domain gaps between labeled source data and unlabeled target data and stresses the need for unsupervised domain adaptation (UDA) methods. This post covers DAFormer, a recent transformer-based UDA method which significantly improved state-of-the-art performance, as well as two more recent performance-improving approaches to UDA (HRDA and MIC).
Introduction
Semantic segmentation is the computer vision task of assigning a class label to every pixel in an image in the pursuit of understanding the image’s content with pixel-level precision. Due to its impact in popular research fields such as autonomous vehicles and medical imaging, it has been a prominent area of study within deep learning. The introduction of CNNs a decade ago allowed major breakthroughs in semantic segmentation, and in recent years, after revolutionizing natural language processing, Transformers have quickly adapted to many computer vision tasks such as this one. However, Transformers were not quick to supplant CNNs in Unsupervised Domain Adaptation (UDA) approaches to semantic segmentation. It was only three years ago when such an attempt was systematically made. We will explore this novel architecture (DAFormer) and its influence on UDA performance of semantic segmentation, as well as state-of-the-art upgrades (HRDA and MIC).
Unsupervised Domain Adaptation (UDA)
UDA is a learning paradigm that addresses the challenge of domain shift, a phenomenon where a model overfits on a labeled source domain and performs poorly on a different, unlabeled, target domain. In the context of semantic segmentation, the motivation for UDA arises because in many settings, pixel-level annotations for a target dataset can be expensive to obtain or even unavailable. UDA is necessary to transfer knowledge from the source dataset, which is much cheaper to label, to the target dataset. Common domain gaps include lighting, textures, resolution, and small objects. UDA methods primarily focus on learning domain-invariate representations that capture semantic similarities in both domains, enabling models to generalize well to novel conditions and environments. Ultimately, progression in this field reduces the need for expensive, manual annotations of the target domain.
DAFormer
Architecture
Previous UDA methods mostly used CNN network architectures, which were beginning to become outdated. Researchers hypothesized that the dynamic self-attention mechanism in Transformers would improve robustness and produce more adaptive models. In particular, the design of Mix Transformers (MiT) was tailored for semantic segmentation, and was chosen for DAFormer. MiT uses smaller image patches than Vision Transformers (ViT) to capture finer details. The self-attention blocks use sequence reduction to compensate the increased feature resolution. Additionally, MiT has an encoder-decoder architecture. The encoder produces multi-level feature maps defined as
\[F_i \in \mathbb{R}^{\frac{H}{2^{i+1}} \times \frac{W}{2^{i+1}} \times C_i}, \hspace{1mm} i \in \{1,2,3,4\}\]The decoder, in addition to exploiting local information from bottleneck features like a typical decoder, also uses context across features from different encoder levels. The earlier features provide insightful low-level understandings for semantic segmentation at a high resolution. First, each feature map \( F_i \) is aligned to the same number of channels and to the same size of \( F_1 \), and then they are stacked together. The context-aware feature fusion then fuses the respective outputs from applying multiple parallel 3 x 3 depthwise separable convolutions with varying dilation rates on the stack.
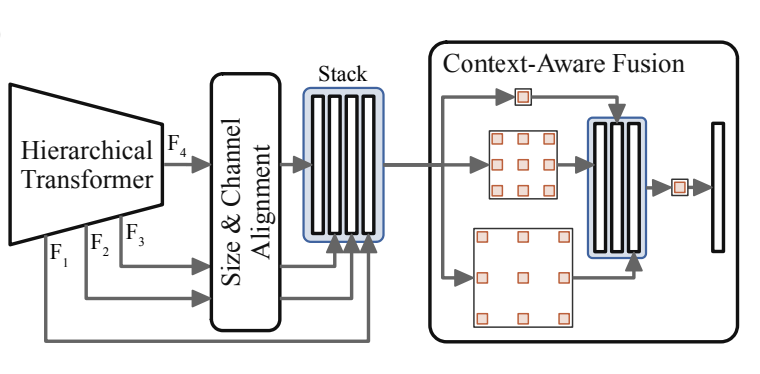
Fig 1. DAFormer architecture: encoder with a feature pyramid, context-aware fusion decoder [1].
Self-Training for UDA
Due to the lack of labels for images in the target domain, naively training a neural network with categorical cross-entropy loss on the source domain causes the network to generalize poorly on the target domain. Self-training has been the most effective strategy for addressing this domain gap.
Self-training uses a teacher network \( h_{\phi} \) to generate pseudo-labels for target domain data. The pseudo-labels are defined as
\[p_T^{(i,j,c)} = [c = \mathrm{argmax}_{c^\prime} h_\phi(x_T^{(i)})^{(j,c^\prime)} ]\]where \( [\cdot]\) denotes the Iverson bracket.
Additionally, the pseudo-labels are weighted with a confidence estimate defined as
\[q_T^{(i)} = \frac{\sum_{j=1}^{H \times W} [\max_{c^\prime} h_\phi(x_T^{(i)})^{(j,c^\prime)} > \tau]} {H \cdot W}\]where \( \tau \) is a threshold of the maximum softmax probability.
These two quantities are used to build a new loss function for the network \( g_\theta \) that can train on the target domain:
\[\mathscr{L}_T^{(i)} = - \sum^{H \times W}_{j=1} \sum^C_{c=1} q_T^{(i)} p_T^{(i,j,c)} \log g_\theta(x_T^{(i)})^{(j,c)}\]The teacher network is implemented as an Exponential Moving Average (EMA) teacher, which means the weights of the teacher network (\( \phi \)) are updated based on the weights of the student network (\( \theta \)) after each training step t as follows:
\[\phi_{t+1} \leftarrow \alpha \phi_t + (1-\alpha)\theta_t\]Additional Training Strategies
Rare Class Sampling (RCS)
It was observed that rarer classes in the source domain performed inconsistently over different runs. The order in which the data was sampled decided when the classes were learned, and classes that were learned later were more likely to perform worse. To prevent the model from being overly biased towards common classes in later training iterations, rare class sampling samples images with rare classes from the source domain more often so that these classes may be learned better and earlier.
Thing-Class ImageNet Feature Distance (FD)
DAFormer is pretrained on the ImageNet-1K classification dataset, which provides information on high-level semantic classes (bus vs. train) that often pose a challenge to UDA. It was observed that such classes were segmentable by DAFormer early on during training, but were forgotten after a few hundred training steps. The learned synthetic source data features began to override the ImageNet features. To preserve these generic features, the model is regularized with the feature distance between bottleneck features of the segmentation model and the bottleneck features of the ImageNet model, but for only thing-classes (well-defined objects) which comprised most of the ImageNet data.
Learning Rate Warmup
Warming up the learning rate has commonly been applied to models to improve network generalization by stabilizing initial training. For UDA purposes, a learning rate warmup would prevent distortion of important ImageNet features early on in training. Up to iteration \( t_{warm} \), the learning rate at iteration t is defined as
\[\eta_t = \eta_{base} \cdot t/t_{warm}\]
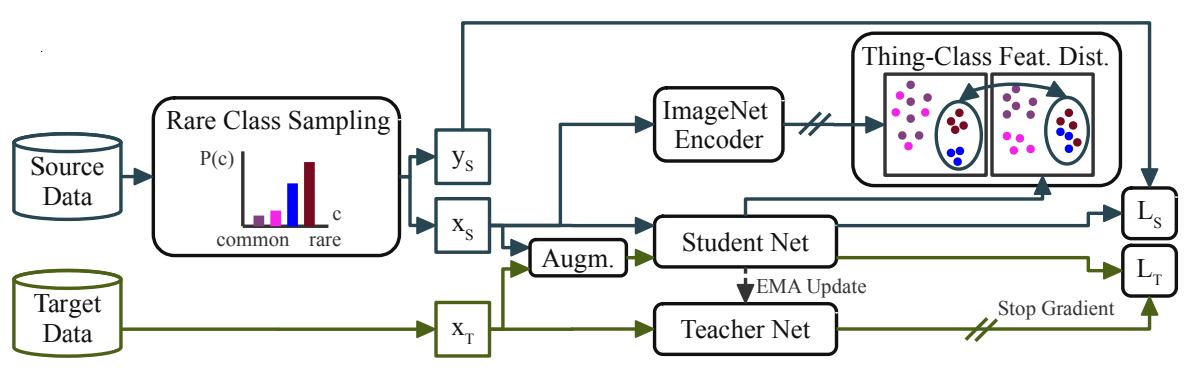
Fig 2. DAFormer UDA framework: self-training with EMA teacher network, rare class sampling of source data, thing-class feature distance regularization using ImageNet encoder [1].
HRDA
UDA methods require images from multiple domains, additional networks, and more loss functions to train, so due to GPU memory constraints, most previous works, including DAFormer, only use low resolution (LR) inputs. Consequently, excluding high-/multi-resolution (HR) inputs hinders a model’s ability to recognize smaller objects and produce fine segmentation borders. Context-aware high-resolution domain-adaptive semantic segmentation (HRDA) addresses this issue by introducing a large LR context crop and a small HR detail crop. The context crop exploits the benefits of LR by learning long-range context relations while the detail crop focuses on HR to recognize small objects and produce fine segmentation details. HRDA is a training approach that can be adapted to various UDA methods such as DAFormer.
Context Crop
Beginning with an HR image \(x_{HR} \in \mathbb{R}^{H \times W \times 3}\), it is cropped such that
\[x_{c, HR} = x_{HR} = [b_{c,1} : b_{c,2}, b_{c,3} : b_{c,4}]\]where \( b_c \) is a bounding box that is randomly sampled from a discrete uniform distribution bounded by the size of the image, or more specifically
\[b_{c,1} \sim \mathscr{U}\{0, (H - sh_c) / k\} \cdot k, \hspace{3mm} b_{c,2} = b_{c,1} + sh_c\] \[b_{c,3} \sim \mathscr{U}\{0, (W - sw_c) / k\} \cdot k, \hspace{3mm} b_{c,4} = b_{c,3} + sw_c\]\( k \) is defined as \( k = o \cdot s \) where \(o\) is the output stride of the segmentation network while \( s \) is the factor used to bilinear downsample \(x_{c, HR}\) to obtain the context crop \(x_c \in \mathbb{R}^{h_c \times w_c \times 3}\).
\[x_c = \zeta(x_{c, HR}, 1/s)\]The intuition behind the choice of \(k\) is to ensure exact alignment later on in the network because the coordinates of the bounding box \(b_c\) are defined to be divisible by \(k\).
Detail Crop
The context crop is then used to generate the detail crop \(x_d \in \mathbb{R}^{h_d \times w_d \times 3}\). It has a similar definition, but without downsampling:
\[x_d = x_{c, HR} = [b_{d,1} : b_{d,2}, b_{d,3} : b_{d,4}]\] \[b_{d,1} \sim \mathscr{U}\{0, (sh_c - h_d) / k\} \cdot k, \hspace{3mm} b_{d,2} = b_{d,1} + sh_d\] \[b_{d,3} \sim \mathscr{U}\{0, (sw_c - w_d) / k\} \cdot k, \hspace{3mm} b_{d,4} = b_{d,3} + sw_d\]To balance resources between both crops and have equal tradeoffs between context-aware and detailed predictions, the researchers set \(h_c = h_d\) and \(w_c = w_d\). By using a downscale factor of \(s=2\), the context crop essentially comprises 4 times more content than the detail crop.
Multi-Resolution Fusion
As mentioned earlier, the HR detail crop and LR context crop have different strengths and address the other’s weaknesses. To maximize the performances of both, their predictions are fused using a learned scale attention which essentially weighs the trustworthiness of their predictions.
Following the architecture of DAFormer, HRDA uses a feature encoder \(f^E \) and a semantic decoder \(f^S\), which are shared for HR and LR inputs. Hence we have the context semantic segmentation
\[\widehat{y}_c = f^S(f^E(x_c)) \in \mathbb{R}^{\frac{h_c}{o} \times \frac{w_c}{o} \times C}\]and the detail semantic segmentation
\[\widehat{y}_d = f^S(f^E(x_d)) \in \mathbb{R}^{\frac{h_d}{o} \times \frac{w_d}{o} \times C}\]To predict the scale attention \(a_c\), the researchers selected a lightweight SegFormer MLP decoder as the scale attention decoder \(f^A\), such that
\[a_c = \sigma(f^A(f^E(x_c))) \in [0,1]^{\frac{h_c}{o} \times \frac{w_c}{o} \times C}\]The attention is predicted on the context crop, and the sigmoid is used since the scaled attention represents a ratio of focus, where a value closer to 1 means on a focus on the HR detail crop and a value closer to 0 means a focus on the LR context crop. Since the detail crop exists within the context crop, only \( a_c \) values within the bounds of the detail crop are kept, and denoted as \( a_c’ \).
For fusion purposes, the detail crop must be aligned with the context crop by padding it with zeros, and the result is denoted as \( y_d’ \).Then the fused multi-scale prediction is constructed as follows:
\[\widehat{y}_{c, F} = \zeta((1-a_c') \odot \widehat{y}_c,s) + \zeta(a_c',s) \odot \widehat{y}_d'\]With the ground truth \(y_{c, HR}^S\) / \( y_d^S\) for the source domain, the encoder, segmentation head, and attention head are trained with the loss function
\[\mathscr{L}^S_{HRDA} = (1-\lambda_d) \mathscr{L}_{ce} (\widehat{y}_{c,F}^S, y_{c,HR}^S, 1) + \lambda_d \mathscr{L}_{ce}(\widehat{y}_d^S, y_d^S, 1)\]The detail loss weight \( \lambda_d\) is a hyperparameter that is chosen empirically as 0.1. An additional cross-entropy loss is included for direct supervision of the detail crop in order to learn more robust features of HR inputs independent of the scaled attention.
Likewise, the target loss function is defined as
\[\mathscr{L}^T_{HRDA} = (1-\lambda_d) \mathscr{L}_{ce} (\widehat{y}_{c,F}^T, p_{c,HR}^T, q_{c, F}^T) + \lambda_d \mathscr{L}_{ce}(\widehat{y}_d^T, p_d^T, q_d^T)\]where \(p \) and \(q \) respectively signify pseudo-labels and their confidence estimates as described previously in the self-training process of DAFormer. Here, \(p_{c,HR}^T\) are pseudo-labels generated using a similar multi-resolution fusion process, in which scale attention decides which resolution to trust more for each prediction. Specifically, the teacher network makes an LR prediction on \(x_c\) and a HR prediction on \(x_{c, HR}\). Since the HR prediction is on the non-downsampled context crop, a sliding window approach is used over the entire context crop to generate overlapping predictions, which are then averaged. The fused prediction, using the full scale attention \( a_c \) instead of the masked scale attention is hence
\[\widehat{y}_{c, F}^T = \zeta((1-a_c^T) \odot \widehat{y}_c^T,s) + \zeta(a_c^T,s) \odot \widehat{y}_{c, HR}^T\]This fused prediction is the output of the teacher network, and through the self-training method outlined in DAFormer, we can obtain the pseudo-labels necessary for the student network to learn the target loss.
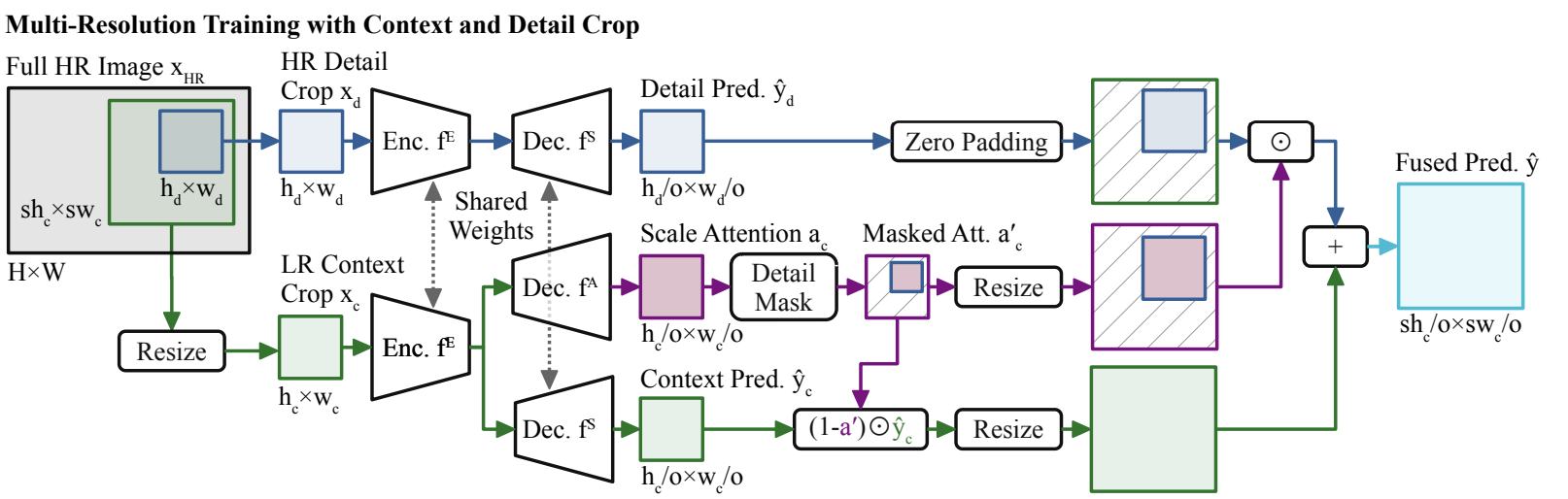
Fig 3. HRDA network: HR image converted to detail and context crops to produce fused prediction using scale attention [2].
MIC
In DAFormer, UDA is addressed using the standard self-training method, in which a teacher network generates pseudo-labels for an unlabeled target domain. However, due to the lack of ground truth labels in the target domain, self-supervised losses are too weak to properly exploit the learning of context relations on the target domain. Consequently, many classes with a similar visual appearance on the target domain are often confused with one another. Masked Image Consistency (MIC), which aims to facilitate learning of context relations on the target domain, is a plug-and-play module that can be applied to existing UDA methods.
MIC randomly masks out patches of the target image as follows:
\[M_{mb+1:(m+1)b, nb+1:(n+1)b} = [v > r], \hspace{4mm} v \sim \mathscr{U}(0,1)\]with \([\cdot]\) denoting the Iverson bracket, \( b \) as the patch size, \( r \) as the mask ratio, and \(m, n\) as the patch indices.
With this mask, the masked target image is constructed as
\[x^M = M \odot x^T\]where \(x^T\) are images from the target domain.
Hence, the prediction of the semantic segmentation network \(f_\theta\) on the masked target image is
\[\widehat{y}^{M} = f_\theta(x^M)\]The masking process eliminates most local information, making the prediction more difficult and forces the network to use the remaining context clues to segment the masked image. The network is then trained on an additional MIC loss defined as
\[\mathscr{L}^M = q^T\mathscr{L}_{ce}(\widehat{y}^M, p^T)\]where \(p^T\) and \(q^T\) are the pseudo-labels and their confidence estimates as described previously in the self-training method for DAFormer.
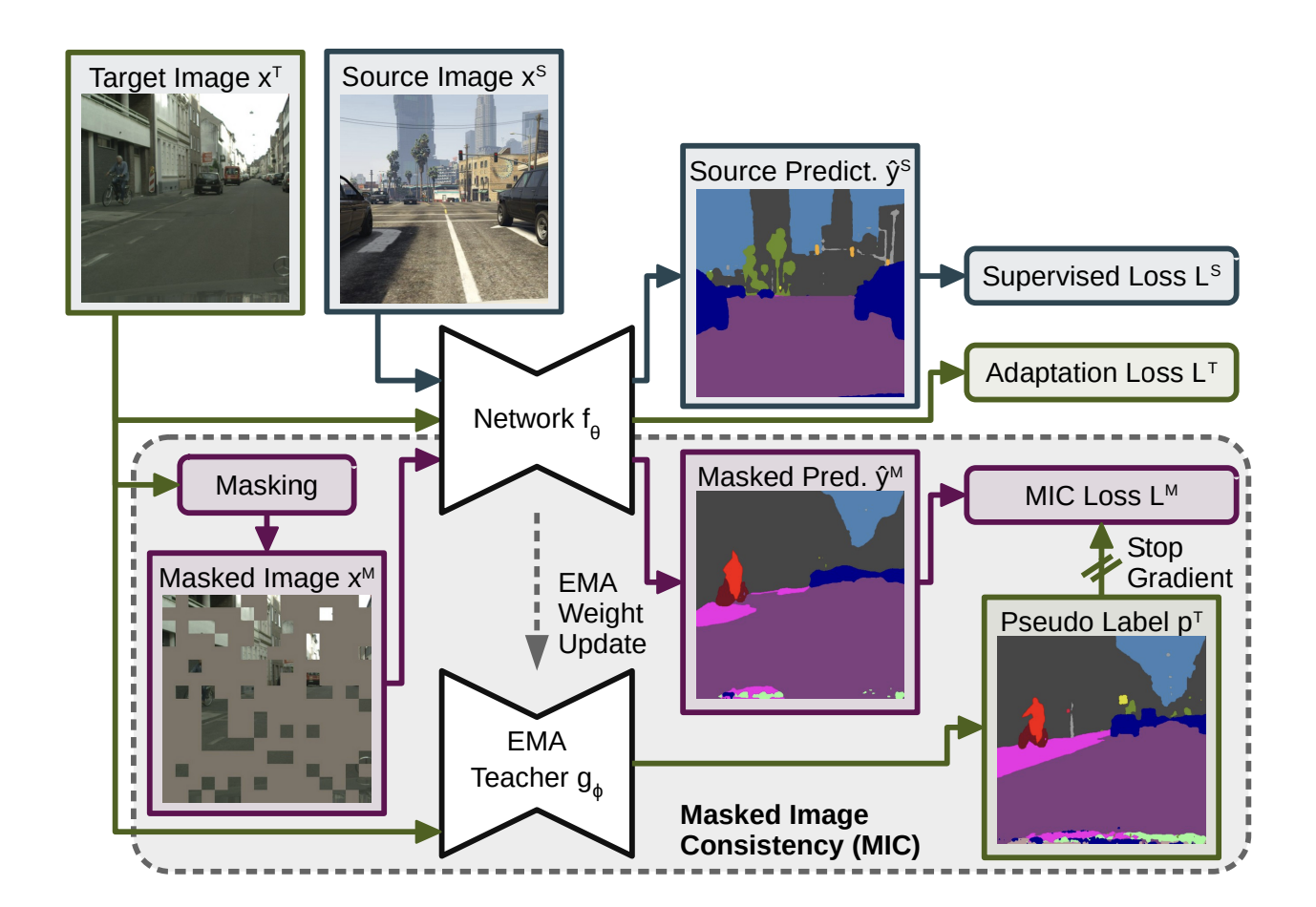
Fig 4. MIC UDA framework: network receives masked input images to learn MIC loss [3].
Evaluation
DAFormer is trained on the Cityscapes street scene dataset for the target domain, and on GTA and Synthia datasets for the source domain. It significantly outperforms previous methods, achieving 68.3 mIOU on GTA \(\rightarrow\) Cityscapes and 60.9 mIOU on Synthia \(\rightarrow\) Cityscapes, a 10.8 mIOU and 5.4 mIOU improvement in state-of-the-art performance, respectively.
With the HRDA modification to the DAFormer approach, the resulting model achieves 73.8 mIOU on GTA \(\rightarrow\) Cityscapes and 65.8 mIOU on Synthia \(\rightarrow\) Cityscapes, a 5.5 mIOU and 4.9 mIOU improvement from before, respectively.
With both the HRDA and MIC additions to the DAFormer approach, the resulting model achieves 75.9 mIOU on GTA \(\rightarrow\)Cityscapes and 67.3 mIOU on Synthia \(\rightarrow\) Cityscapes, a 2.1 mIOU and 1.5 mIOU improvement from before, respectively.
Additionally, more tests were conducted on different domain transfer pairs. The tests above are synthetic-to-real adaptations, and the researchers also studied clear-to-adverse weather (Cityscapes \(\rightarrow\) DarkZurich) and day-to-nighttime adaptations (Cityscapes \(\rightarrow\) ACDC). Similarly, DAFormer with HRDA and MIC was the best-performing approach, raising state-of-the-art performance by 4.3 mIOU on Cityscapes \(\rightarrow\) DarkZurich and 2.4 mIOU on Cityscapes \(\rightarrow\) ACDC.
Conclusion
DAFormer shows that Transformer-based architectures, when combined with effective self-training and stabilization methods, significantly advances UDA for semantic segmentation. HRDA navigates around the GPU memory bottleneck for UDA methods and allows use of HR inputs for capturing fine details, while MIC strengthens contextual learning on unlabeled target images. Together, these methods achieve state-of-the-art results across multiple domain shifts, and further reinforce UDA as a solution towards costly annotations as well as a means of making semantic segmentation models more robust and adaptable to real-world environments.
References
[1] Hoyer, Lukas et al. “DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation.” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021): 9914-9925.
[2] Hoyer, Lukas et al. “HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation.” ArXiv abs/2204.13132 (2022): n. pag.
[3] Hoyer, Lukas et al. “MIC: Masked Image Consistency for Context-Enhanced Domain Adaptation.” 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022): 11721-11732.