Human Pose Estimation
In this paper, I will be discussing the fundamentals and workings of deep learning for human pose estimation. I believe that there has been a lot of research and breakthroughs, especially recently, on technology that relates to this, and I hope that this deep dive will bring some clarity and new information to how it works!
- Introduction
- Why Does Human Pose Estimation Work Now?
- Problem Formulation of Human Pose Estimation
- Transformer-Based Pose Models
- 3D Human Pose Estimation
- Implementation Example with MMPose
- Applications of Human Pose Estimation
- Related Work
- Conclusion
- Reference
Introduction
Human pose estimation is the computational task of detecting and localizing predefined keypoints, such as joints or landmarks, on one or more objects in images or videos. These keypoints are typically represented as 2D or 3D coordinates (e.g., [x, y] or [x, y, visibility]), often accompanied by confidence scores indicating the model’s certainty for each point. By capturing the spatial arrangement of the body parts, pose estimation enables fine-grained applications such as motion analysis, gesture recognition, animation, biomechanics, surveillance, and human-computer interaction.
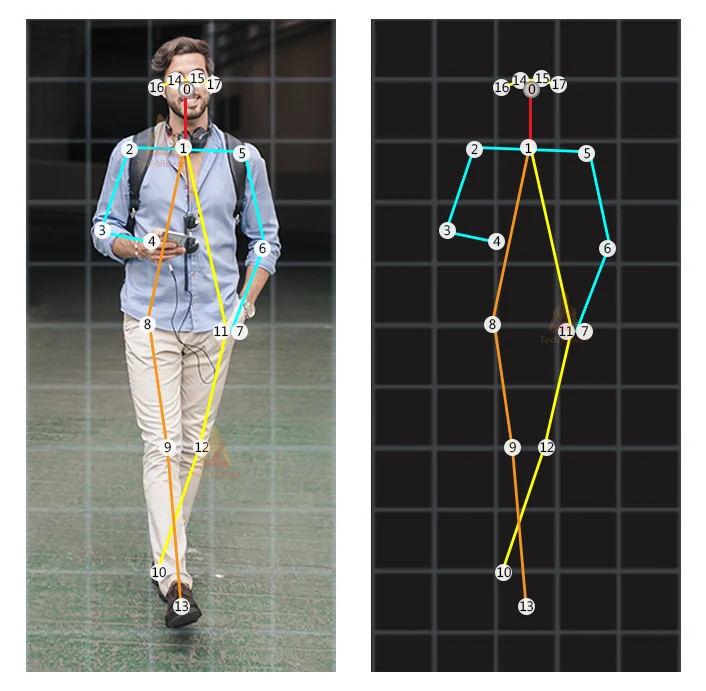
Fig 1. Graphical Skeleton. (Image source: https://www.mdpi.com/2071-1050/15/18/13363)
The field of pose estimation has grown in the past few years, driven by advances in deep learning, the availability of large annotated datasets, and the development of flexible, production toolkits. Out of all of these, MMPose stands out as an open-source and extensible framework build on PyTorch that supports a wide array of tasks. Some of these tasks include 2D multi-person human pose estimation, hand keypoint detection, face landmarks, full-body pose estimation including body, hands, face, and feet, animal pose estimations, and so much more.
The advantages of MMPose is its comprehensive “model zoo” that includes both accuracy-oriented and real-time lightweight architectures, pertained weights on strandard datasets, and configurable pipelines for dataset loading, data augmentations, and evaluation. This versatility makes MMPose suitable for both academic research and real-world production systems, whether the task is single-person pose detection, multi-person tracking, or whole-body landmark detection.
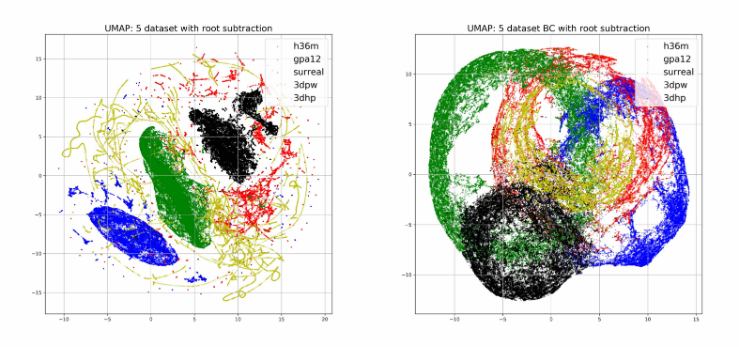
Fig 2. UMAP of datasets with root subtraction. (Image source: https://wangzheallen.github.io/cross-dataset-generalization)
Accompanying the implementation is a curated collection of seminal and research papers, datasets, benchmark tasks, and open-source implementations that cover 2D and 3D pose estimation, human mesh construction, pose-based action recognition, and video pose tracking. These sources provide researchers and engineers with a structured overview of the theoretical foundations, methodological advances, and practical tools in the domain. In combiningthe implementation toolkit with a comprehensive research source, one obtains both the useful means to build pose-estimation systems and the theoretical grounding to understand trade-offs. In this paper, we leverage the idea that we adopt the MMPose framwork for our pose estimation tasks, while consulting the literature summarized by several resources to choose appropraite architectures, training strategies, and evaluation protocols. The goal is to demonstrate accurate pose detection in both 2D and 3D, under diverse conditions, and to assess how well modern models generalize beyond standard benchmark datasets.
Why Does Human Pose Estimation Work Now?
Although pose estimation has been studied for decades, its recent success can largely be attributed to three converging facts. These factors are data, computation, and model design. Modern pose estimation models rely on large-scale annotated datasets such as COCO, MPII, Human3.6M, and 3DPW, which provide diverse human poses across different viewpoints, environments, and levels of occlusion. Without these datasets, learning representations of human articulation would not be possible.

Fig 3. Examples of 3D pose estimation for Human3.6M. (Image source: ResearchGate)
Just as important is the availability of powerful computational resources. Training deep neural networks for pose estimation involves optimizing millions of parameters and processing high-resolution feature maps. GPUs and specialized accelerators make it possible to train models efficiently and deploy them in real-time systems.
Finally, deep learning architectures are designed to learning spatial dependencies between joints. Unlike traditional hand-crafted approaches, deep models can automatically learn hierarchical representations that encode both local joint appearance and global body structure. This allows pose estimation systems to scale effectively as data size increases, improving performance rather than saturating.
Problem Formulation of Human Pose Estimation
At its core, human pose estimation can be formulated as a structured prediction problem. Given an input Image \(I\), the goal is to predict a set of keypoints:
\[\mathbf{P} = \{(x_i, y_i, c_i)\}_{i=1}^{K} ])\]where \(K\) is the number of keypoints, \((x_i, y_i)\) denotes the spatial location of the \(i\) -th joint, and \(c_i\) represents either a confidence score or a visibility flag.
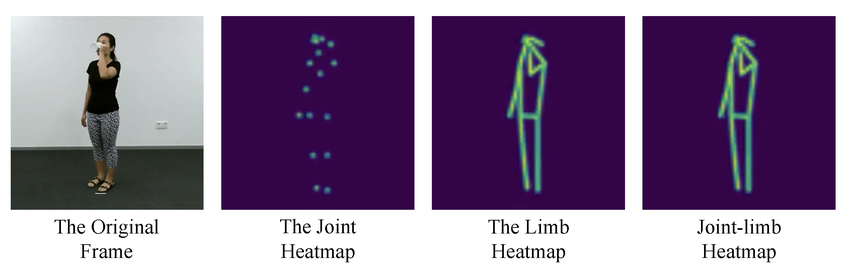
Fig 4. Examples of generated joint heatmap, limb heatmap, and joint–limb heatmap. (Image source: ResearchGate)
{kind=link}
Most modern approaches model pose estimation as a heatmap regression problem. For each joint \(i\), the network predicts a heat map (shown below), where each pixel value represents the probability of that joint appearing at that location. The final keypoint location is obtained by:
\[(x_i, y_i) = \arg\max_{(x, y)} H_i(x, y), \quad H_i \in \mathbb{R}^{H \times W}\]This formulation is particularly effective because it preserves spatial uncertainty and allows the network to express ambiguity when joints are occluded or visually similar.
Single-Person and Multi-Person Pose Estimation
Single-person pose estimation assumes the presence of one dominant subject in the image. The model focuses entirely on accurately localizing all keypoints of that individual, often after a preprocessing step that crops the person from the background. This setup allows for high precision and is commonly used in controlled environments such as motion capturing or sports analysis.
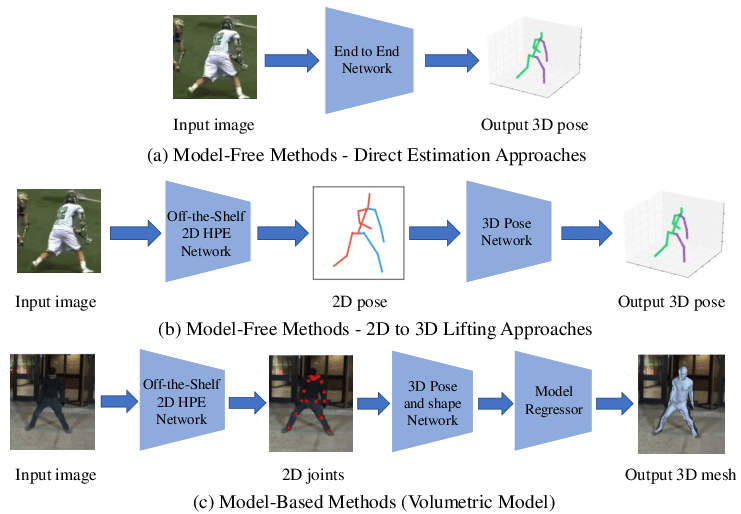
Fig 5. Single-person 3D HPE frameworks. [5].
Multi-person pose estimation, on the other hand, introduces the challenge of associating detected keypoints with the correct individuals. Top-down approaches first detect bounding boxes for each person and then apply a single-person pose estimator to each crop. Bottom-up approaches detect all keypoints in the image simultaneously and then group them into individual skeletons.

Fig 6. Results of CMU-Pose (a–c) and SE-ResNet-OKHM-CMU-Pose (Ours) (d–f). The joint points in the red circle were not recognized by CMU-Pose. (Image source: ResearchGate)
Building on the challenges inherent in multi-person pose estimation recent research has explored architectural improvements to enhance robustness in crowded and complex scenes. Figure 18 illustrates a qualitative comparison of multi-person 2D pose estimation results from the research project Improved Multi-Person 2D Human Pose Estimation Using Attention Mechanisms and Hard Example Mining. The first row presents results produced by the baseline CMU Pose network, while the second row shows outputs from the proposed SE-ResNet-OKHM-CMU-Pose model.
In the first set of images, the CMU Pose network detects only 17 joint keypoints for the two individuals on the right, whereas the SE-ResNet-OKHM-CMU-Pose model successfully identifies all 18 joints. The missing joints, highlighted by red circles, demonstrate the baseline model’s difficulty in localizing harder or partially occluded joints. Similarly, in the second image set, only the proposed model correctly detects all 18 joints for the third person in the scene, while the baseline fails to fully recover the pose. In the third set of images, the left ankle of the first individual is accurately detected only by the SE-ResNet-OKHM-CMU-Pose network, further emphasizing its improved sensitivity to challenging and flexible joints.
These qualitative results demonstrate that incorporating attention mechanisms and online hard keypoint mining significantly improves joint localization accuracy, particularly in crowded scenes with overlapping bodies or visually ambiguous joints. By explicitly focusing on difficult examples during training, the proposed method addresses common failure cases present in the COCO dataset. Overall, these findings validate the effectiveness of the approach in improving multi-person pose estimation performance under complex real-world conditions.
Deep Learning Models for Pose Estimation
Human pose estimation aims to infer the spatial configuration of human body parts from visual input such as images or videos. Depending on the target representation, pose estimation can be formulated as either a 2D or 3D prediction problem. In 2D pose estimation, the task is to localize body joints on the image plane, while 3D pose estimation further recovers depth information to reconstruct the full skeletal structure in three-dimensional space. As a result, human pose estimation has become a dominant and foundational research topic within the computer vision community.
Accurate pose estimation plays a critical role in a wide range of applications. For example, sports activity recognition relies on precise skeletal joint localization to analyze movement patterns, evaluate performance, and prevent injuries. Similarly, pose estimation enables downstream tasks such as action recognition, gesture classification, and posture assessment, although these tasks are conceptually distinct. While action recognition focuses on identifying motion patterns over time, pose estimation provides the structural representation required to support such high-level reasoning. As pose estimation models improve, they increasingly serve as a backbone for action understanding systems, suggesting that future advances in pose estimation may significantly enhance action recognition performance.
Convolutional neural networks form the backbone of most pose estimation systems. CNNs exploit local spatial correlations in images and progressively build higher-level features through stacked convolutional layers. Early layers capture low-level patterns such as edges, while deeper layers encode semantic concepts like limbs and body parts.
A typical pose estimation network predicts a stack of heatmaps using a fully convolutional architecture:
\[\hat{\mathbf{H}}_k = f_\theta(\mathbf{I})\]where \(f_\theta\) is a CNN parameterized by \(theta\). The loss function is usually defined as the mean squared error between predicted and ground-truth heatmaps:
\[\text{L} = \frac{1}{K} \sum_{i=1}^{K} \left\| H_i - \hat{H}_i \right\|_2^2\]Beyond research settings, human pose estimation has become indispensable in real-time systems across multiple domains. In healthcare, pose estimation supports rehabilitation monitoring, fall detection, and posture grading systems that assess whether patients perform movements correctly. In human–machine interaction, pose-based interfaces allow users to control systems using body movements rather than traditional input devices. Additional applications include surveillance, animation, virtual reality, and intelligent monitoring systems. These use cases demand models that are not only accurate but also robust, efficient, and capable of operating in unconstrained environments.
Fig 7. Intelligent monitoring system. (Image source: Semantic Scholar)
To overcome the spatial resolution limitations of traditional CNNs, later architectures introduced multi-scale feature fusion and high-resolution representations. Models such as HRNet maintain high-resolution feature maps throughout the network and continuously exchange information across resolutions. This design significantly improves joint localization accuracy, especially for fine-grained body parts like wrists and ankles.
Transformer-Based Pose Models
More recently, transformer-based architectures have been introduced to human pose estimation. Unlike CNNs, transformers rely on self-attention mechanisms to capture long-range dependencies and global context. This capability is particularly beneficial in scenarios involving occlusion, crowded scenes, or unusual body configurations. Transformer-based pose models, such as ViTPose, treat pose estimation as a sequence modeling problem.

Fig 8. Examples of Berkeley's HMR 2.0 system, which uses Transformers to more effectively and simply extract pose information that can be superimposed onto a CGI-based SMPL human template. [8].
Transformers introduce self-attention mechanisms that allow each joint representation to attend to all others. This is particularly useful for modeling long-range dependencies, such as symmetric limbs or full-body constraints. Instead of relying solely on local convolutions, transformers explicitly reason about global body structure.
Self-attention is written as:
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^\top}{\sqrt{d}}\right) V\]where \(Q\), \(K\), and \(V\), are query, key, and value matrices derived from feature embeddings. By inforporating attention, pose models can better handle occlusions and complex interactions between joints.
3D Human Pose Estimation
3D pose estimation extends the 2D formulation by predicting depth information for each joint and predicting the image-plan coordinates (x,y) of each joing, as well as estimating the depth \(z\), thereby reconstructing the full three-dimensinoal structure of the human body. The task is inherently ill-posed because multiple 3D poses can project to the same 2D configuration. Many approaches therefore, rely on multi-view supervision, temporal constraints, or learned priors over human anatomy.
Fig 9. A baseline model for 3D human pose estimation by Martinez et al. (Image source: Springer)
A common formulation predicts 3D joints (\(x_i\), \(y_i\), \(z_i\)) from 2D detections:
\[P_\text{3D} = g_\phi(P_\text{2D})\]where \(g_\phi\) is a regression network. The loss is typically defined as the mean per-joint position error (MPJPE):
\[\text{MPJPE} = \frac{1}{K} \sum_{i=1}^{K} \| \hat{p}^i - p^i \|_2\]Implementation Example with MMPose
Below is a simplified example of running inference using a pretrained MMPose model:
from mmpose.apis import init_pose_model, inference_top_down_pose_model
from mmdet.apis import init_detector
detector = init_detector(det_config, det_checkpoint)
pose_model = init_pose_model(pose_config, pose_checkpoint)
person_results = inference_detector(detector, image)
pose_results, _ = inference_top_down_pose_model(
pose_model,
image,
person_results
)
This pipeline demonstrates how detection and pose estimation are decoupled in a top-down framework, enabling flexible experimentation and modular design.
Applications of Human Pose Estimation
Human pose estimation enables a wide range of applications beyond academic benchmarks. In healthcare, pose estimation supports rehabilitation monitoring and gait analysis. In sports, it enables fine-grained motion analysis for performance optimization. In entertainment and AR/VR, pose estimation allows realistic avatar animation and immersive interaction.
Three-dimensional human pose estimation extends the traditional 2D pose estimation problem by predicting the spatial coordinates of body joints in three-dimensional space rather than only their image-plane locations. While 2D pose estimation outputs pixel coordinates of joints projected onto the camera sensor, 3D pose estimation seeks to recover depth information, enabling a more faithful representation of human body geometry and motion. This added dimensionality is crucial for applications that require accurate modeling of posture, joint angles, and movement dynamics, such as biomechanics analysis, robotics, animation, and clinical assessment. However, 3D human pose estimation is inherently an ill-posed problem. A fundamental challenge arises from the fact that multiple distinct 3D body configurations can produce identical 2D projections when viewed from a single camera. As a result, depth information cannot be uniquely inferred from monocular images alone without additional assumptions or constraints. This ambiguity is further exacerbated by factors such as self-occlusion, variations in body shape, loose clothing, and complex camera viewpoints.
To address these challenges, many approaches incorporate additional sources of information to constrain the solution space. Multi-view methods leverage synchronized images from multiple cameras to triangulate joint positions in 3D space, significantly reducing depth ambiguity and improving accuracy. While effective, these approaches often require careful calibration and controlled setups, limiting their scalability in real-world environments. Temporal models exploit motion continuity across video frames, enforcing smoothness and physical plausibility in predicted poses by assuming that human motion evolves gradually over time. Learned priors over human anatomy and kinematics further constrain predictions by embedding structural knowledge, such as limb length consistency and joint angle limits, into the model.
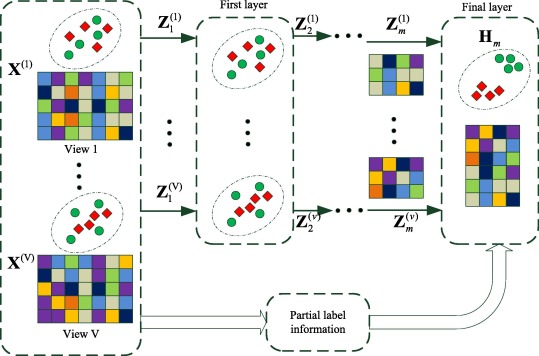
Fig 10. The framework of deep multi-view concept learning method (DMCL). [10].
Recent deep learning approaches have shown remarkable success by learning implicit 3D pose priors from large annotated datasets. These models can infer plausible 3D poses even from single images by exploiting statistical regularities in human motion and body structure. Nevertheless, despite substantial progress, 3D pose estimation remains an active area of research due to persistent challenges in generalization, robustness to occlusion, and performance in unconstrained, in-the-wild settings.
The emergence of human pose estimation algorithms represents a paradigm shift in the quantitative analysis of human movement. Powered by advances in computer vision and deep learning, modern pose estimation methods enable automatic tracking of human body joints from simple video recordings captured using widely available, low-cost devices such as smartphones, tablets, and laptop cameras. This accessibility has dramatically lowered the barriers to motion analysis, making pose-based measurement feasible in everyday environments rather than restricted laboratory settings. One of the most promising application areas is human health and performance. In clinical contexts, pose estimation allows clinicians to conduct quantitative motor assessments remotely, potentially within a patient’s home, without the need for expensive motion capture systems or wearable sensors. Similarly, researchers without access to specialized laboratory equipment can analyze movement kinematics using consumer-grade video data, while coaches and trainers can evaluate athletic performance directly on the field. These capabilities offer significant advantages in terms of cost, scalability, and ecological validity.
Related Work
Human pose estimation has evolved considerably over the last decade, largely driven by advances in deep learning architectures. In this section, we compare some of the most influential models and frameworks, including SRCNN and ViTPose, highlighting their design and limitations.
SRCNN (Super-Resolution Convolutional Neural Network)
Single-image super-resolution (SR) is a classical and well-studied problem in computer vision that aims to recover a high-resolution image from a single low-resolution input. This task is fundamentally ill-posed, as multiple high-resolution images can correspond to the same low-resolution observation. In other words, SR is an underdetermined inverse problem, where the solution space is large and non-unique. To mitigate this ambiguity, most super-resolution approaches constrain the solution space by imposing strong prior information learned from data.
SRCNN introduced a key conceptual shift by showing that this traditional pipeline can be interpreted as a deep convolutional neural network, enabling end-to-end learning of the super-resolution mapping. Rather than explicitly learning dictionaries or manifolds for patch representation, SRCNN implicitly captures these priors through hidden convolutional layers. Patch extraction, non-linear mapping, and reconstruction are all reformulated as convolution operations, allowing the entire process to be optimized jointly using backpropagation.
Although SRCNN was originally designed for image super-resolution, its underlying convolutional architecture has inspired early approaches to pose estimation through feature extraction and heatmap regression. SRCNN consists of three layers of convolution:
\[F_1(Y) = \max\left(0, W_1 * Y + B_1\right)\] \[F_2(Y) = \max\left(0, W_2 * F_1(Y) + B_2\right)\] \[F(Y) = W_3 * F_2(Y) + B_3\]Where \(Y\) is the input image, \(*\) denotes convolution, \(W_i\) and \(B_i\) are the weights and biases of the \(i\)-th layer, and max (0,⋅) represents the ReLU activation. SRCNN’s simplicity allows fast training and easy integration into pipelines where low-resolution keypoint heatmaps are upscaled to higher resolution for finer localization.
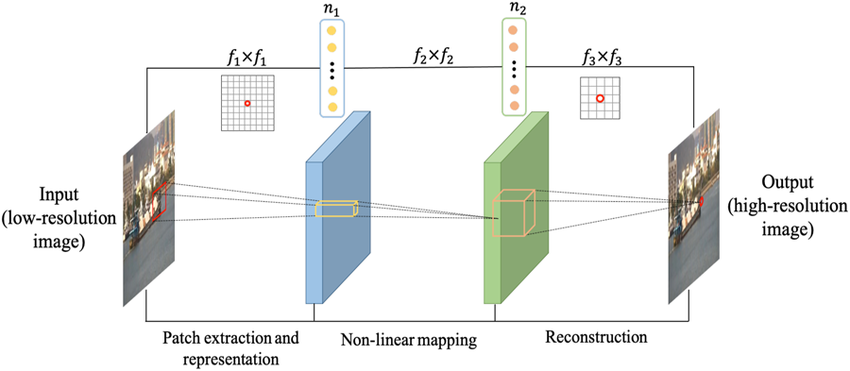
Fig 11. Architecture of SRCNN. [11].
While SRCNN was originally designed for image super-resolution, its principles have influenced pose estimation pipelines—particularly in heatmap-based keypoint localization. In pose estimation, models often predict low-resolution heatmaps for each joint, which must then be upsampled to higher resolutions for precise localization. SRCNN-like architectures can be used to refine or super-resolve these heatmaps, improving joint accuracy without substantially increasing computational cost. In this context, SRCNN-style models serve as post-processing or refinement modules, learning a mapping from coarse joint confidence maps to sharper, more spatially precise outputs. The ill-posed nature of heatmap super-resolution mirrors that of image SR, as multiple high-resolution joint configurations can correspond to the same low-resolution heatmap.
Implementation of SRCNN
import torch
import torch.nn as nn
import torch.nn.functional as F
class SRCNN(nn.Module):
def __init__(self):
super(SRCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)
self.conv2 = nn.Conv2d(64, 32, kernel_size=5, padding=2)
self.conv3 = nn.Conv2d(32, 3, kernel_size=5, padding=2)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = self.conv3(x)
return x
While SRCNN provides a foundation for feature extraction, it suffers in hgih complexity scenes due to its shallow structure and limited capacity to capture long range dependencies.
ViTPose (Vision Transformer for Pose Estimation)
ViTPose is a transformer-based approach to human pose estimation that leverages the global modeling capabilities of Vision Transformers (ViTs) to address limitations inherent in convolutional neural networks. Unlike CNN-based methods, which rely on local receptive fields and hierarchical feature aggregation, ViTPose models long-range spatial dependencies directly through self-attention. This property is particularly advantageous for pose estimation in crowded or complex scenes, where joints may be spatially distant, heavily occluded, or visually ambiguous.
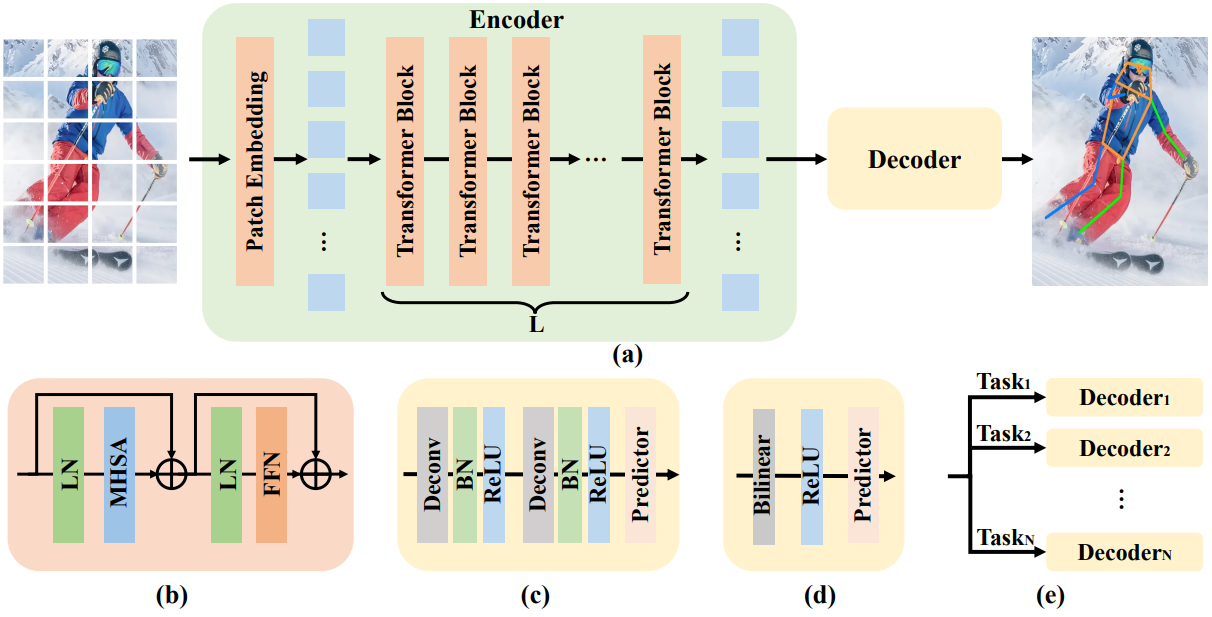
Fig 12. Architecture of the ViTPose model. It consists of a Transformer encoder and two different kinds of decoders. [12].
In ViTPose, the input image is first divided into fixed-size patches that are linearly embedded and processed by a transformer encoder. Through multi-head self-attention, the model captures global contextual relationships among different body parts, enabling more coherent reasoning about human structure and inter-joint constraints. This global awareness allows ViTPose to better disambiguate challenging poses, such as overlapping limbs or interactions between multiple individuals, which are common failure cases for purely convolutional architectures.
The input image is split into patches, embedded, and passed through a series of self-attention layers:
\[Z_0 = X_p + E_{\text{pos}}\] \[Z_l' = \text{MSA}(\text{LN}(Z_{l-1})) + Z_{l-1}\] \[Z_l = \text{MLP}(\text{LN}(Z_l')) + Z_l'\]Where \(X_p\) is the patch embedding, \(E_{\text{pos}}\) is positional encoding, MSA is multi-head self-attention, and LN is layer normalization. ViTPose produces heatmaps for keypoints using transformer output, enabling it to capture spatial and contextual dependencies across the whole image, even in crowded scenes.
import torch
import torch.nn as nn
class PatchEmbed(nn.Module):
def __init__(self, img_size=256, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # (B, embed_dim, H/patch, W/patch)
x = x.flatten(2).transpose(1, 2) # (B, num_patches, embed_dim)
return x
Example of patch embedding layer:
import torch
import torch.nn as nn
class PatchEmbed(nn.Module):
def __init__(self, img_size=256, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) ** 2
self.proj = nn.Conv2d(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x):
# x: (B, C, H, W)
x = self.proj(x) # (B, embed_dim, H/P, W/P)
x = x.flatten(2).transpose(1, 2) # (B, N, embed_dim)
return x
Self-attention allows every patch to attend to every other patch:
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_dim=768, num_heads=12):
super().__init__()
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.scale = self.head_dim ** -0.5
self.qkv = nn.Linear(embed_dim, embed_dim * 3)
self.proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(
B, N, 3, self.num_heads, self.head_dim
).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
out = (attn @ v).transpose(1, 2).reshape(B, N, C)
out = self.proj(out)
return out
In modern pose estimation pipelines, ViTPose is often integrated with convolutional components to combine the strengths of both paradigms. Convolutional backbones are frequently used for early-stage feature extraction due to their efficiency and inductive bias toward local spatial patterns, while transformer modules are employed at later stages to perform global reasoning and joint refinement. This hybrid design enables accurate, fine-grained keypoint localization while retaining the transformer’s ability to model long-range dependencies and holistic body structure. Overall, ViTPose represents a shift toward attention-based modeling in human pose estimation, demonstrating that transformers can serve as powerful alternatives—or complements—to convolutional networks. Its success highlights the importance of global context in understanding human body configurations and has influenced a growing number of transformer-based and hybrid architectures in both 2D and 3D pose estimation research.
Conclusion
Human pose estimation has emerged as a fundamental problem in modern computer vision, driven by deep learning, large datasets, and powerful toolkits such as MMPose. Through structured representations of the human body, pose estimation enables machines to reason about motion, posture, and interaction at a fine-grained level. As models continue to evolve toward 3D, whole-body, and real-time systems, pose estimation will remain a critical component of intelligent visual understanding.
Reference
Please make sure to cite properly in your work, for example:
[1] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. You only look once: Unified, real-time object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Dong, C., Loy, C. C., He, K., & Tang, X. Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(2), 295–307, 2016. (Architecture figure source: ResearchGate) https://www.researchgate.net/publication/378907335/figure/fig1/AS:11431281252590961@1718783506447/Architecture-of-SRCNN-SRCNN-consists-of-feature-block-extraction-and-representation.png
[3] Dong, C., Loy, C. C., He, K., & Tang, X. Learning a deep convolutional network for image super-resolution. arXiv preprint arXiv:1501.00092, 2015. https://arxiv.org/pdf/1501.00092v3
[4] Cao, Z., Hidalgo, G., Simon, T., Wei, S. E., & Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using part affinity fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(1), 172–186, 2021. (Heatmap visualization example) https://www.researchgate.net/figure/The-examples-of-generated-joint-heatmap-limb-heatmap-and-joint-limb-heatmap_fig3_368320282
[5] Toshev, A., & Szegedy, C. DeepPose: Human pose estimation via deep neural networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
[6] Sun, Y., Wang, W., Tang, X., & Liu, X. Human pose estimation in the wild: A survey. Neurocomputing, 2021. https://www.sciencedirect.com/science/article/pii/S0925231221004768
[7] Kocabas, M., Athanasiou, N., & Black, M. J. HMR 2.0: Advances in human mesh recovery. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. (Example visualization) https://blog.metaphysic.ai/wp-content/uploads/2023/06/hmr2-examples-1024x397.jpg
[8] Ashfaq, N., et al. Intelligent monitoring systems using human pose estimation. Sensors, 2022. (Figure source) https://www.researchgate.net/profile/Niaz-Ashfaq/publication/366703501/figure/fig3/AS:11431281111105083@1672881081850/ntelligent-monitoring-system.ppm
[9] Kim, J., et al. Vision-based human activity recognition: A comprehensive review. Sustainability, 15(18), 13363, 2023. https://www.mdpi.com/2071-1050/15/18/13363
[10] Mathis, A., et al. DeepLabCut: Markerless pose estimation of user-defined body parts with deep learning. Nature Neuroscience, 21(9), 1281–1289, 2018. (Application and clinical context) https://pmc.ncbi.nlm.nih.gov/articles/PMC8588262/
[11] Xu, Y., Zhang, J., & Zhang, Y. Vision Transformer-based pose estimation. arXiv preprint, 2022. (ViTPose architecture visualization) https://debuggercafe.com/wp-content/uploads/2025/02/vitpose-architecture.png