Instance Segmentation Paper Synthesis: Evolution and New Frontiers
Instance segmentation is a fundamental task in computer vision that detects and separates individual object instances on a pixel level. There have been several recent developments in computer vision that have led to improvements in instance segmentation performance and new applications of instance segmentation. We will discuss and analyze Segment Anything Model, Mask2Former, and Relation3D for image and point cloud instance segmentation in this paper report.
- Introduction
- Segment Anything Model
- All in One: Mask2Former
- New Frontiers in Instance Segmentation: Relation3D
- Conclusion
- References
Introduction
Instance segmentation is a core computer vision task that separates each individual object in an image at the pixel level. In a sense, this computer vision task combines the problems of object detection, where the model identifies all the objects in an image, and semantic segmentation, where the model detects the pixels that belong to each object. Due to instance segmentation outlining every distinct object in an image, it is useful for a model to gain a deeper visual understanding of a complex scene. This makes it particularly essential for applications like self-driving cars, medical imaging, and robotics.
Early research in instance segmentation adopted the approach of a two-stage detector by using defined object detection and semantic segmentation methods. This approach is primarily known through Mask R-CNN, which uses baseline object detection frameworks with an additional component for pixel level mask prediction. Specifically, Mask R-CNN uses Faster R-CNN as the object detector model, which includes a Region Proposal Network, RoI Align, and CNN layers in its structure. Mask R-CNN then adds a mask head branch that generates a mask for each object instance in parallel to the classification and bounding box regression heads. However, Mask R-CNN is slow, limiting its real-time use on complex or large objects. This motivated the development of one-stage instance segmentation methods, such as SOLO (Segmenting Objects by Locations), to focus on improving the slower speed of two-stage methods. One-stage methods, like SOLO, use a more direct approach of outputting instance masks and class probabilities in a single pass. This one-pass method eliminates the process of grouping, anchor boxes, and convolutions that were present in Mask R-CNN.
Recent advances in deep learning have substantially influenced the landscape of instance segmentation. Significant examples of this are through transformer based architectures and large scale pretraining. Due to this, the realm of instance segmentation has been advancing year by year. In this paper, we synthesize three influential directions in instance segmentation research. These paper topics cover Segment Anything, which is a “promptable” image segmentation model, Mask2Former, which provides a universal, non-specialized architecture for image segmentation, and instance segmentation methods for point clouds, which extend visual data understanding to a 3D level.
Segment Anything Model
Historical Context and Motivation
The development of the Segment Anything Model (SAM) by Meta can be traced back to the company’s origins in 2004, when it was still known as Facebook. As a social media platform, Facebook rapidly evolved into one of the world’s largest repositories of visual data. This rapidly motivated early investment in computer vision, through applications such as automated photo tagging and content moderation, and later through more advanced machine learning systems. By the mid-2010s, the establishment of Facebook AI Research (FAIR) marked a shift toward foundational AI research, with FAIR becoming a leading contributor to advances in self-supervised learning, computer vision, and large-scale deep learning. After Facebook’s rebrand to Meta in 2021, the company’s long-term vision expanded toward spatial computing, AR/VR systems in the form of Meta glasses, increasing the demand for models capable of robustly understanding objects, scenes, and their interactions in the physical world. Soon, Meta introduced the Segment Anything Model (SAM) as a new model for image segmentation.
SAM Architecture
SAM uses an encoder-decoder framework with separation between image encoding, prompt encoding, and mask decoding, enabling efficient reuse of image features across multiple segmentation queries. Essentially, SAM is a Vision Transformer (ViT) image encoder, which processes an input image \(I \in \mathbb{R}^{H \times W \times 3}\) into a dense latent representation \(E_I \in \mathbb{R}^{N \times D}\), where \(N\) is the number of image tokens and \(D\) the embedding dimension. With multi-head self-attention, the ViT captures long-range spatial dependencies, and allows SAM to model global context beyond local receptive fields from convolutional networks. SAM is pretrained on a large corpus of image–mask pairs and leverages masked autoencoding and self-supervised learning objectives to learn robust visual representations [1]. This allows for SAM to achieve strong generalization for many different objects and stronger reliability, from its trained inputs. User interaction is added via a prompt encoder, which embeds sparse and dense prompts into the same latent space as the image embeddings. Sparse prompts with small pieces of information, including background and foreground points, are encoded using positional embeddings and lightweight MLPs, while dense prompts, like low-resolution masks of objects, are embedded using convolutional layers. These influence the segmentation process while leaving the image encoder unchanged.
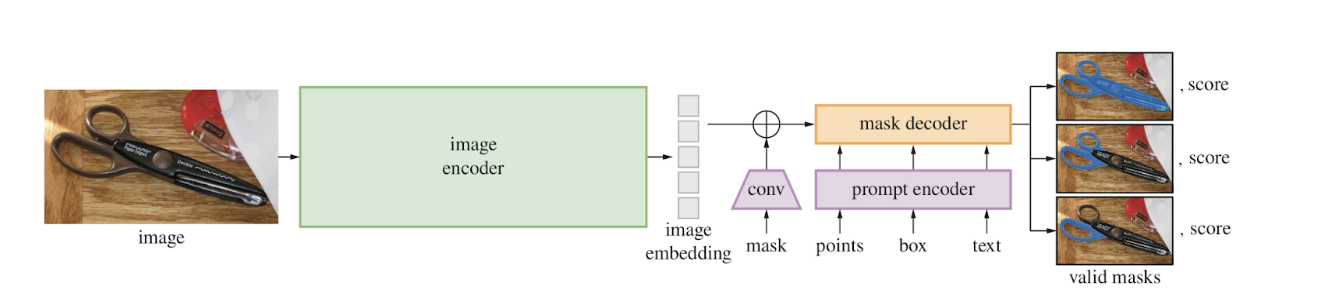 Fig 1. SAM Overview [1]
Fig 1. SAM Overview [1]
The mask decoder is implemented as a lightweight transformer that performs cross-attention between the prompt embeddings and image embeddings. Given query tokens derived from the prompts, the decoder looks at relevant spatial regions in \(E_I\) and predicts a set of candidate segmentation masks along with corresponding confidence scores. To handle ambiguity, SAM also outputs multiple mask hypotheses per prompt and ranks them using a predicted mask quality score, usually modeled as an estimated Intersection-over-Union (IoU). Formally, mask prediction can be expressed as:
\(M = \text{Decoder}(E_I, E_P)\)
where \(E_P\) is the encoded prompts and \(M\) represents the predicted binary masks. By separating image encoding from prompt-based decoding, SAM stays computationally efficient while handling a wide range of segmentation tasks.
Despite its strong generalization capabilities, SAM primarily models segmentation as an appearance-driven, prompt-conditioned task. Interactions between multiple instances are handled implicitly through attention over image tokens, without needing to enforce explicit relational or structural constraints. This limitation can result in overlapping or redundant masks in complex scenes, motivating subsequent extensions.
SAM2: Memory-Augmented Video Segmentation
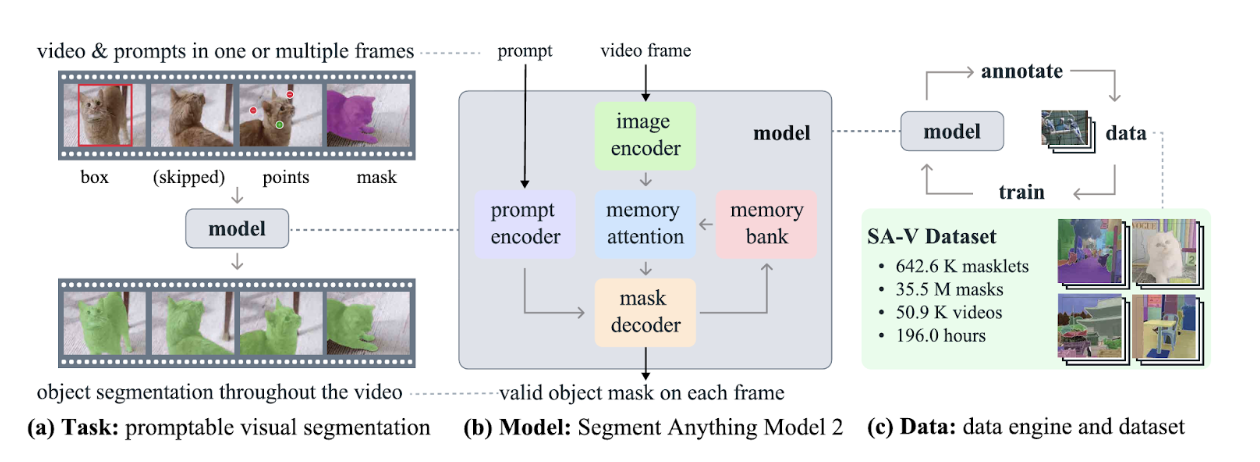 Fig 2. SAM 2 Overview [2]
Fig 2. SAM 2 Overview [2]
To address temporal consistency, SAM2 expands the original architecture to video and sequential data by introducing a memory-augmented segmentation framework. This stores and recalls features from previous time stamps to allow the model to maintain context and ensure consistent object segmentation across sequences. While keeping the same image encoder, prompt encoder, and mask decoder, SAM2 adds a temporal memory bank that stores embeddings, predicted masks, and object identity information from previous frames [2]. While inferring frames, the decoder simultaneously focuses on the current frame’s image embeddings and relevant memory entries, enabling information to propagate across time. For a frame at time tt, mask prediction can be written as: \(M_t=\text{Decoder}(E_{I_t},E_{P_t},M_{t−1})\) where \(M_{t−1}\) denotes stored memory from prior frames. This design enhances resilience to occlusion, motion, and changes in appearance, all while preserving amortized efficiency. However, SAM2’s relational reasoning is primarily temporal and does not explicitly model spatial relationships between multiple instances within a single frame.
SAM3: Structured Relational Reasoning via PCS and PVS
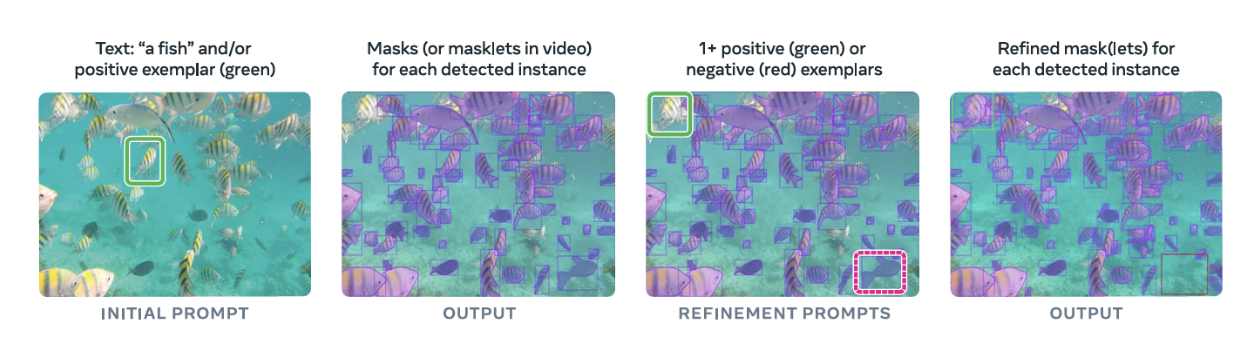 Fig 3. Illustration of supported initial and optional interactive refinement prompts in the PCS task [3]
Fig 3. Illustration of supported initial and optional interactive refinement prompts in the PCS task [3]
Building on this foundation, SAM3 further strengthens intra-frame relational modeling and expands the Segment Anything framework through two complementary tasks: Promptable Consistent Segmentation (PCS) and Promptable Video Segmentation (PVS). In PCS, SAM3 jointly refines multiple candidate masks using cross-mask attention, allowing the model to reason explicitly about overlap, redundancy, and spatial consistency between instances [3]. This structured decoding process reduces fragmented or conflicting predictions, particularly in crowded scenes or under ambiguous prompts. PVS extends this relational reasoning into the temporal domain. While SAM2 introduces memory for video segmentation, SAM3 combines temporal memory attention with intra-frame cross-mask interactions, enabling more stable and identity-preserving segmentation across frames. This unified treatment improves robustness to occlusions and object interactions while maintaining spatial coherence within each frame. Together, the progress from SAM to SAM2 and SAM3 reflects a shift from independent, appearance-driven segmentation toward increasingly structured and relation-aware modeling. Although SAM3 significantly improves spatial and temporal reasoning in 2D image and video domains, its relational understanding remains largely implicit and attention-based, lacking explicit geometric or physical priors. This limitation motivates further exploration of architectures that encode explicit relational structure, particularly in domains such as 3D instance segmentation, where spatial relationships and object geometry are fundamental to scene understanding.
All in One: Mask2Former
As instance segmentation research has progressed from object-proposal based approaches such as Mask R-CNN to prompt driven systems like Segment Anything, a complementary research direction has focused on designing universal frameworks capable of solving semantic, instance, and panoptic segmentation within a single model. Meta’s Masked Attention Mask Transformer, or Mask2Former, represents a significant advancement in this direction [4]. It introduces a unified meta architecture that achieves state of the art performance across all major two dimensional segmentation tasks using a single, task agnostic formulation. Figure 4 illustrates the differences between semantic, instance, and panoptic segmentation tasks, highlighting the motivation and performance for a unified segmentation framework.
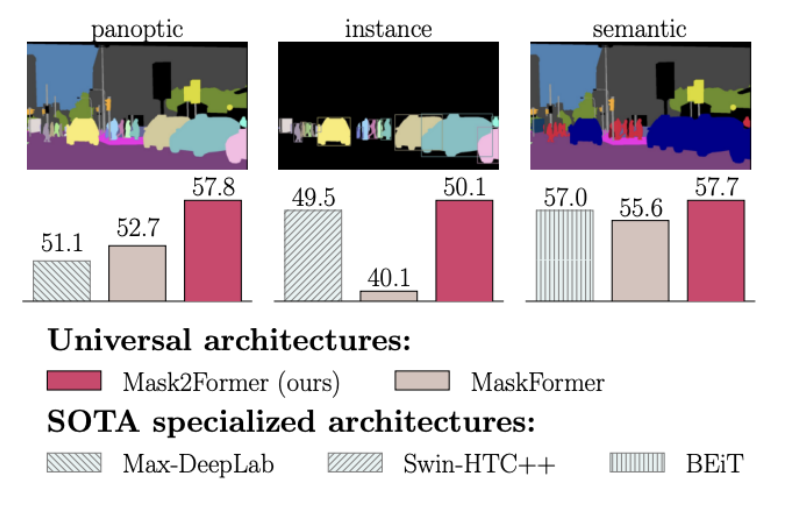 Fig 4: Comparison of semantic, instance, and panoptic segmentation tasks, motivating a unified segmentation formulation [4].
Fig 4: Comparison of semantic, instance, and panoptic segmentation tasks, motivating a unified segmentation formulation [4].
Unified Segmentation Architecture
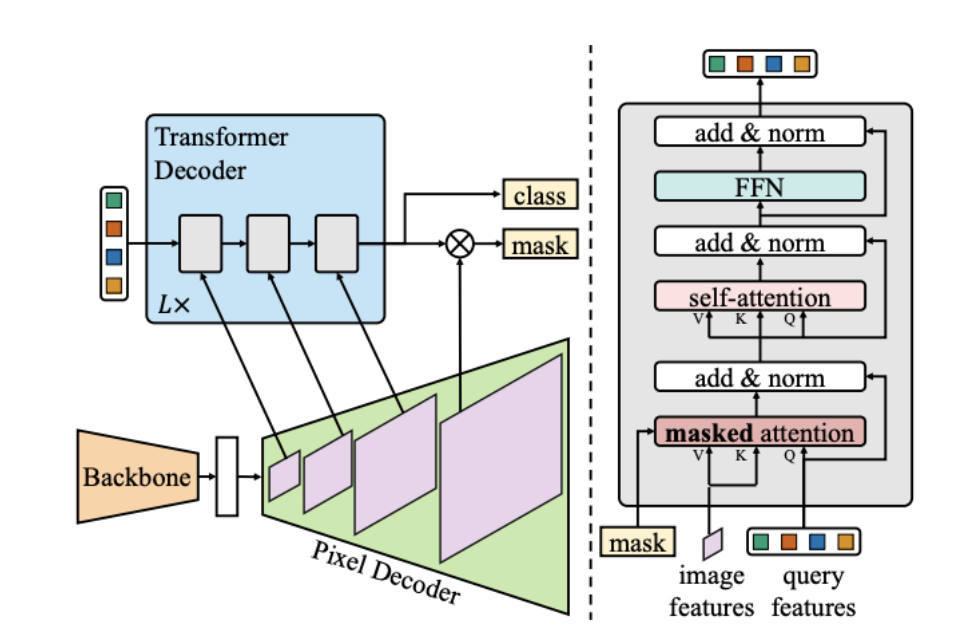 Fig 5: Overview of the Mask2Former meta architecture, consisting of a backbone, pixel decoder, and transformer decoder with masked attention [4].
Fig 5: Overview of the Mask2Former meta architecture, consisting of a backbone, pixel decoder, and transformer decoder with masked attention [4].
As shown in Figure 5, Mask2Former consists of a backbone network, pixel decoder, and a transformer decoder operating on a fixed set of learned queries. Mask2Former formulates segmentation as a direct set prediction problem, inspired by detection transformers but adapted for dense pixel-level output [4]. Instead of relying on task specific heads or heuristics, the model predicts a fixed size set of segmentation masks and corresponding class labels. These predictions can be interpreted uniformly for semantic, instance, or panoptic segmentation. The overall meta architecture is composed of three primary components. a. The backbone network extracts hierarchical and multi scale feature representations from the input image. Both convolutional and transformer based backbones can be used, with Swin Transformer being a common choice due to its strong multi-scale representations. b. The pixel decoder aggregates features from multiple backbone stages into a unified high resolution pixel embedding. This step preserves fine spatial details while efficiently combining contextual information across scales, which is critical for accurate mask prediction. c. The transformer decoder operates on a fixed set of learned query embeddings. Each query represents a potential segmentation region and is iteratively refined through attention mechanisms to predict both a segmentation mask and an associated class label. This design allows the same set of queries to support all segmentation tasks without requiring architectural changes.
Masked Attention Mechanism
The primary contribution of Mask2Former is the introduction of masked attention within the transformer decoder [4]. In standard transformer based segmentation models, cross-attention is computed globally over all pixel features. This global attention can introduce irrelevant background information and reduce localization accuracy, particularly for small objects or complex shapes. Figure 6 contrasts standard global cross attention with the masked attention mechanism used in Mask2Former.
 Fig 6: Comparison between global cross attention (on top) and masked attention (on bottom), where attention is restricted to predicted foreground regions [4].
Fig 6: Comparison between global cross attention (on top) and masked attention (on bottom), where attention is restricted to predicted foreground regions [4].
Masked attention addresses this limitation by restricting each query to attend only to the spatial regions corresponding to its predicted mask from the previous decoding stage. Formally, Mask2Former implements masked attention by modulating the standard cross-attention operation with a spatial mask derived from the previous decoder layer [4]. The masked cross-attention update at the layer \(l\) is defined as
\[X_l = \text{softmax}(M_{l-1} + Q_l K_l^\top) V_l + X_{l-1}\] \[M_{l-1}(x, y) = \begin{cases} 0, & \text{if } \hat{M}_{l-1}(x, y) = 1 \\ -\infty, & \text{otherwise} \end{cases}\]Here, \(Q_l\), \(K_l\), and \(V_l\) denote the query, key, and value projections at decoder layer \(l\), and \(X_{l-1}\) represents the residual connection from the previous layer. The mask \(M_{l-1}\) is constructed from the predicted segmentation mask of the previous decoding stage and is added directly to the attention logits. Spatial locations outside the predicted foreground region are assigned a value of \(-\infty\), effectively suppressing their contribution after the softmax operation. As a result, each query attends only to features within its predicted object region. By constraining attention in this way, the model achieves two important benefits. First, masked attention encourages localized feature extraction. Each query focuses on features within its predicted foreground region, enabling the model to learn more discriminative and object specific representations. This results in faster convergence and improved segmentation accuracy. Next, masked attention improves computational efficiency by avoiding unnecessary attention computations over background regions. This reduction in redundant computation leads to more efficient training and inference compared to fully global attention. Mask2Former further incorporates several complementary design choices that contribute to its strong performance. These include the use of multi scale features in a round robin manner across decoder layers and a point based sampling strategy for mask loss computation [4]. The latter significantly reduces GPU memory usage during training while maintaining segmentation accuracy.
Performance and Significance
By combining masked attention with a unified set prediction formulation, Mask2Former becomes the first segmentation model to consistently outperform specialized task specific architectures across semantic, instance, and panoptic segmentation benchmarks. Its success demonstrates that a unified, query based approach can exceed the performance of fragmented pipelines designed for individual tasks. As a result, Mask2Former has established an influential framework for subsequent transformer based segmentation research and has reinforced the viability of universal segmentation architectures.
New Frontiers in Instance Segmentation: Relation3D
We’ve seen how instance segmentation has advanced in 2D, but we can apply similar principles to conduct instance segmentation in a 3D space as well, specifically in the more unordered, and sparse input of 3D point clouds. This kind of segmentation task has massive implications for rapidly growing technologies, including robotic spatial understanding and autonomous driving. To solve this problem, transformer-based methods have primarily been the focus due to the ubiquity of their pipelines and generally high performance. However, they primarily use mask attention to model external relationships between features, ignoring internal relationships i.e the connections between scene features and the spatial relationships between the queries. Other 2D segmentation methods have explored relation modeling and underscored its importance, but relation priors in 3D instance segmentation have been largely unexplored in research until now.
Relation3D is a new architecture proposed in a titular CVPR 2025 paper that aims to better represent the missing links between these features and improve spatial understanding in transformer-based 3D point cloud instance segmentation.
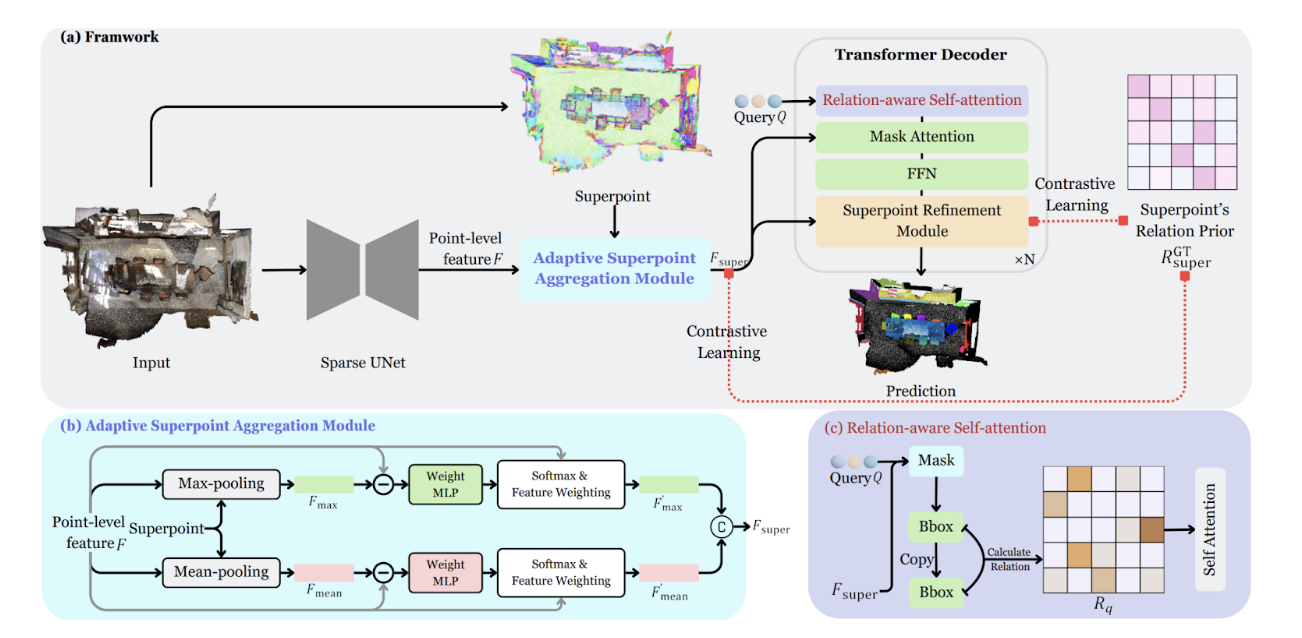 Fig 7. The overall framework of Relation3D, along with the proposed adaptive Superpoint Aggregation Module and Relation-aware self-attention mechanism [5].
Fig 7. The overall framework of Relation3D, along with the proposed adaptive Superpoint Aggregation Module and Relation-aware self-attention mechanism [5].
Better Scene Features (ASAM & CLSR)
First, we reevaluate traditional aggregation methods of point clouds into “superpoints,” which usually use simple pooling that ends up blurring out important details or mistakenly incorporating noise into the reduced point cloud space. The new proposed Adaptive Superpoint Aggregation Module (ASAM) in Relation3D calculates adaptive weights for each point within a group, comparing with the pooled max and mean to learn weights that emphasize edges and corners [5].
Then a Contrastive Learning-guided Superpoint Refinement (CLSR) module is employed to act as a dual path loop for superpoint features and query features to interact with each other and update their information, improving superpoint features’ consistency within object instances and the differences between features of different instances. This process is guided using a contrastive loss function:
\[L_{cont} = BCE\left(\frac{\mathcal{S}+1}{2}, R_{super}^{GT}\right)\]where \(\mathcal{S}\) is a similarity matrix of superpoint features and \(R_{super}^{GT}\) is ground truth relation matrix from instance annotations.
 Fig 8. Visualization of weights in the adaptive superpoint aggregation module [5].
Fig 8. Visualization of weights in the adaptive superpoint aggregation module [5].
Improved Query Interactions with Relation-Aware Self-Attention (RSA)
Typical self-attention mechanisms rely on position embeddings that often lack concrete spatial meaning. The proposed RSA injects explicit geometric priors into the attention mechanism to accelerate convergence and improve accuracy [5].
- Geometric Priors: The model calculates the bounding box for each query’s predicted mask (center \(x,y,z\) and scale \(l,w,h\))20.
- Relative Relationships: It computes explicit relationships between two queries \(i\) and \(j\). For example, the positional relationship is defined as:
Similar log-ratios are calculated for geometric scales (length, width, height)
- Attention Mechanism: These relationships form an embedding \(R_q\) that is injected directly into the self-attention calculation:
This allows the model to learn and attend to physical proximity and geometric similarity, in addition to just semantic similarity.
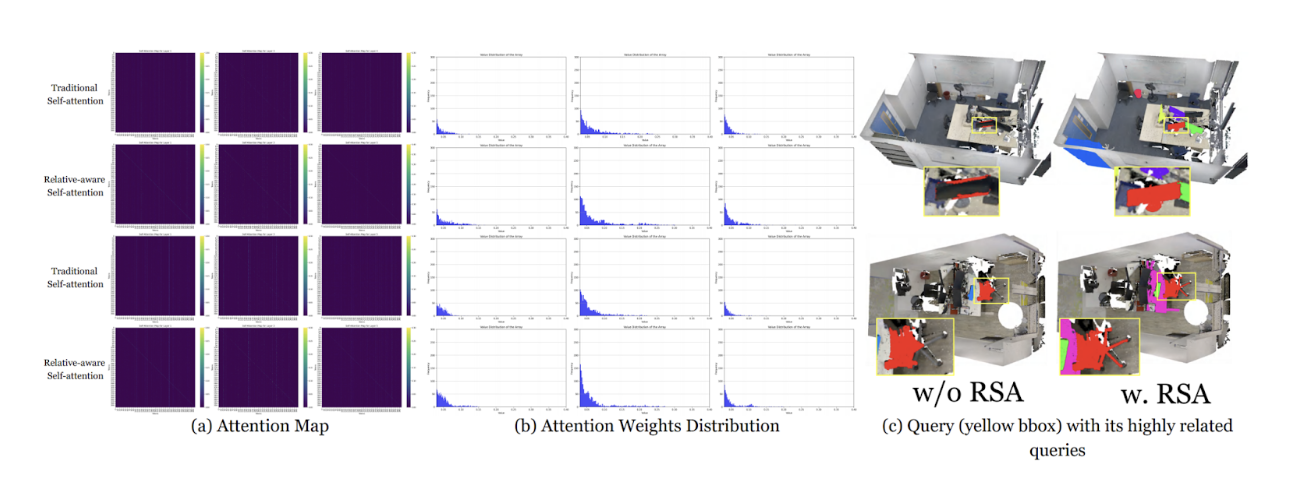 Fig 9. Attention maps for traditional self-attention vs. relation-aware self-attention, attention weight distributions for traditional self-attention vs. relation-aware self-attention, and effect of RSA on instance segmentation from bbox queries [5].
Fig 9. Attention maps for traditional self-attention vs. relation-aware self-attention, attention weight distributions for traditional self-attention vs. relation-aware self-attention, and effect of RSA on instance segmentation from bbox queries [5].
Relation3D is noted as achieving better performance on standard benchmarks like ScanNetV2, ScanNet++, and S3DIS than previous transformer-based approaches, demonstrating the efficacy of relation-aware approaches to instance segmentation in the 3D space [5].
Conclusion
Through this paper, we have thoroughly examined three developments in instance segmentation research. Segment Anything demonstrates using large scale pretraining and prompt based interaction for better generalization performance on new tasks. However, SAM faces a limitation in its relational understanding between multiple instances being largely implicit. Relation 3D is a newly proposed architecture that brings instance segmentation to the unordered and sparse point cloud data domain. Here, Relation3D incorporates explicit geometric priors with relation-aware self-attention to encourage strong spatial understanding in 3D point cloud data. Mask2Former is a universal architecture that combines semantic, instance, and panoptic segmentation capabilities within a single model. It importantly adds a masked attention mechanism that helps improve computational efficiency and improves localization. The topics discussed in this paper report provide examples of a push toward methods that are more generalizable, universal, and applicable within instance segmentation problems.
References
[1] A. Kirillov et al., “Segment Anything,” Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023.
[2] Meta AI, “SAM2: Segment Anything in Video,” arXiv preprint, 2024.
[3] Meta AI, “SAM3: Promptable Consistent and Video Segmentation,” arXiv preprint, 2024.
[4] Cheng, B., Misra, I., Schwing, A. G., Kirillov, A., & Girdhar, R. (2021). Masked-attention Mask Transformer for Universal Image Segmentation. arXiv. https://arxiv.org/abs/2112.01527
[5] Lu, J., & Deng, J. (2025). Relation3D: Enhancing Relation Modeling for Point Cloud Instance Segmentation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).