A Comparison of Recent Deepfake Video Detection Methods
The rapid recent improvments of generative AI models has created an era of hyper-realistic generated images and videos. This has rendered traditional, artifact-based detection methods obsolete. As synthetic media becomes multimodal and increasingly realistic, new methods are needed to identify generated videos from real media. This report examines three new methodologies designed to counter these advanced threats: Next-Frame Feature Prediction, which leverages temporal anomalies to identify manipulation; FPN-Transformers, which utilizes feature pyramids for precise temporal localization; and RL-Based Adaptive Data Augmentation, which employs reinforcement learning to improve model generalization against unseen forgery techniques.
- Introduction
- Method 1 - Next-Frame Feature Prediction
- Method 2 - FPN Transformer
- Method 3 - Reinforcement Learning-Based Adaptive Data Augmentation
- Conclusion
- References
Introduction
Background
Deepfakes are media that have been digitally manipulated to alter a face, body, or voice in existing content to have a subject appear as someone else, many times done maliciously to damage someone’s reputation or image. Generative models for visual data have been a mainstream tool since around 2021. However, past AI generated/augmented images and videos have been easy to spot through irregular pixel patterns, poor feature coherence, or temporal flickering.
As generative models have improved through innovations in architecture and compute, these easily identified markers are disappearing. Recent models such as OpenAI’s Sora 2 or Google’s Nano Banana Pro are able to create increasingly realistic, multimodal (containing both audio and video), and fine-grained media that are sometimes impossible to distinguish from real sources. While almost all hosted models have safeguards to stop misuse, open-source models that are run locally such as Flux.1 (image generation) or ControlNet (image alterations) often lack restrictions allowing users to generate harmful images or videos.
Recently there has been a rise of high-fidelity synthetic content on social media and news. Now researchers are forced to look beyond simple visual artifacts. In this post, we aim to detail some recent developments of deepfake detection methodologies designed to counter these sophisticated image and video alteration tools.
Past Detection Methods and Limitations
While early deepfake detection methods relied on identifying obvious visual artifacts within single frames or detecting clear mismatches between audio and video, these techniques are increasingly insufficient against modern generative models. Contemporary deepfakes have advanced to the point where image quality is photorealistic and the alignment between audio and visual components is often seamless, rendering artifact-based detection obsolete. One large issue with detection methods is generalization; while methods perform well on the specific forgeries they were trained on, accuracy drops sharply when faced with unseen manipulation techniques or different data distributions. Second, many detection frameworks operate in a unimodal setting, analyzing audio or video in isolation, limiting their ability to capture subtle cross-modal inconsistencies.
Modern forgeries often manipulate only specific segments of a video, yet standard approaches typically focus on clip-level classification and fail to localize these forged segments. Consequently, there is a need for generalized frameworks that can not only detect sophisticated, multimodal deepfakes but also adapt to evolving generation methods. The following report explores three novel approaches that address these challenges through temporal feature prediction, transformer-based localization, and reinforcement learning-based adaptive augmentation.
Method 1 - Next-Frame Feature Prediction
Approach
The proposed method from this paper modifies the detection problem into a next-frame feature prediction problem over the input data. The model is divided into four components: Feature Encoding, Masked-Prediction Based Feature Extraction, Intra/Cross-Modal Feature Mixing, and a Prediction head for classification and regression. Combined, these components allow the model to learn a temporal representation of the real source videos to then identify the subtle irregularities found within the deepfakes. The key distinguishing feature between this approach and those of the past, is the objective to learn temporal predictability rather than artifact detection.
The model operates as a robust, single-stage, multimodal framework with real videos as inputs and predicted future representations as outputs. The pipeline starts with feature encoding, which processes the raw audio and raw video separately to produce rich embeddings through the use of an encoder model. It is important to note that these encoders are temporally aligned, ensuring consistency in our prediction model.
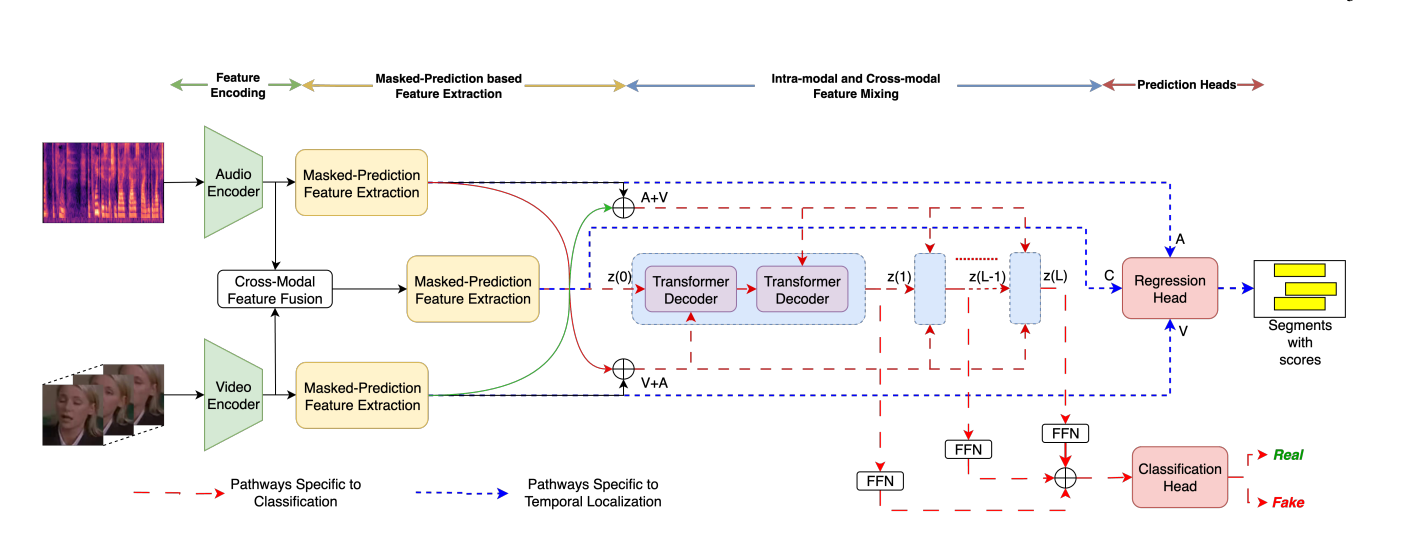
Fig 1. Next-Frame Feature Prediction for Multimodal Deepfake Detection and Temporal Localization [1].
The features generated by the encoders are then passed into a masked-prediction feature extraction module, where certain features are masked away so that the model can then be trained to reconstruct them. This occlusion mechanism is used in many computer vision contexts, because it forces the network to develop a deep knowledge of the temporal structure of the source videos. Further, this is all done in feature-space which emphasizes the necessity to differentiate based on semantics. At the same time these masks are being generated, there exists a cross-modal fusion module that allows the network to learn correlations between both the audio and visual modalities as well.
The masked, extracted features are then passed through a sequence of Transformer decoders which perform both intra-modal and cross-modal mixing. They operate over the latent representations across the time domain, which allows the model to learn long-term dependencies and allows information to propagate across timesteps. The last stage of the pipeline is the prediction head branch. There are two sources of inputs to these final classification modules. The outputs from each of the L decoder transformers are aggregated and fed to the classification head, which is a separate neural network that outputs a binary real or fake result for the input video. The regression head on the other hand processes the temporal embeddings and produces likelihood of deepfake manipulation on a frame-by-frame basis.
Thus, with this pipeline, we are able to achieve deepfake detection and temporal localization with a single-stage model. Further, this pipeline doesn’t rely on arbitrary heuristics that result in performance decreases like past deepfake detection approaches.
Training Objective
To jointly optimize deepfake classification and temporal localization, the model uses a combination of learning objectives. The classification loss is defined as:
\[\mathcal{L}_{cls} = \mathcal{L}_{\text{BCE}} + \frac{ \mathcal{L}^{a}_{\text{contrast}} + \mathcal{L}^{v}_{\text{contrast}} + \mathcal{L}^{av}_{\text{contrast}} }{3}\]where (\mathcal{L}_{\text{BCE}}) denotes the binary cross-entropy loss used for real/fake classification. The contrastive losses are computed over the audio, visual, and audio–visual feature spaces to encourage strong separation between real and fake videos.
The localization loss is defined as:
\[\mathcal{L}_{reg} = \mathcal{L}^{U}_{cls} + \lambda^{U}_{reg}\mathcal{L}^{U}_{reg} + \lambda^{U}_{rec}\mathcal{L}^{U}_{rec} + \lambda^{U}_{scls}\mathcal{L}^{U}_{scls} + \frac{ \mathcal{L}^{a}_{\text{contrast}} + \mathcal{L}^{v}_{\text{contrast}} + \mathcal{L}^{av}_{\text{contrast}} }{3}\]where \((\mathcal{L}^{U}_{cls})\) and \((\mathcal{L}^{U}_{reg})\) are adopted from the UMMAFormer head, while \((\mathcal{L}^{U}_{rec})\) and \((\mathcal{L}^{U}_{scls})\) correspond to the reconstruction loss and video-level focal loss, respectively.
Conducted Experiments
The authors evaluated the deepfake detection using multiple datasets and benchmarks, including FakeAVCeleb, KoDF, and LavDF. After each experiment, the models were evaluated using two performance metrics, accuracy and AUC which is the area under the ROC curve.
For the video detection, the proposed model was compared against a set of visual-only and audio-visual baselines.
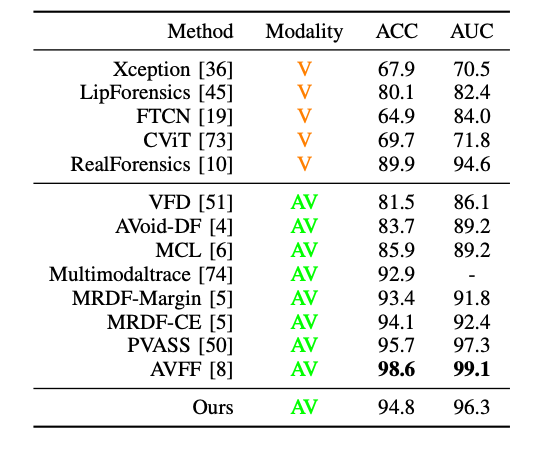
Fig 2. Next-Frame Feature Prediction for Multimodal Deepfake Detection and Temporal Localization [1].
We can observe from the results that there is a lot of variance in the performance of the visual-only methods, however we achieve much stronger and consistent results with both modalities combined. Therefore temporal predictability is quite possible without the usage of pretraining with real data.
The authors further evaluated the robustness of the approach through cross-dataset experiments. An example of this was training the model on FakeAVCeleb and then evaluating on another dataset like KoDF. In this experiment, the model managed to produce a very strong ACC and AUC, vastly outperforming all baseline comparisons.
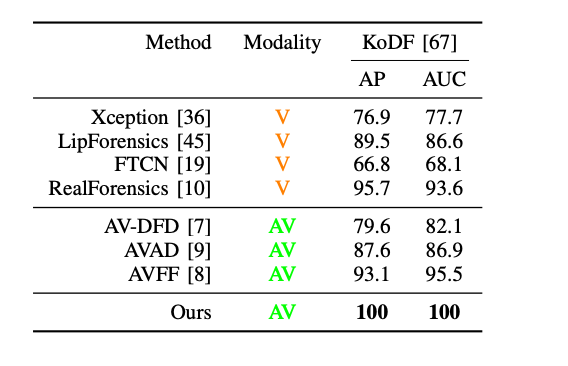
Fig 3. Next-Frame Feature Prediction for Multimodal Deepfake Detection and Temporal Localization [1].
Limitations
While we do observe strong performance in the benchmarks, there are some clear limitations that should be considered. The model relies on temporal alignment between the audio and visual modalities, which may not be possible in real-world scenarios. Further, the sequential nature of next-frame prediction adds a significant amount of computational overhead, which will reduce the scalability of this approach.
Method 2 - FPN Transformer
Approach
The authors propose a multi-modal deepfake detection and localization framework based on a Feature Pyramid Network combined with a Transformer architecture (FPN-Transformer).
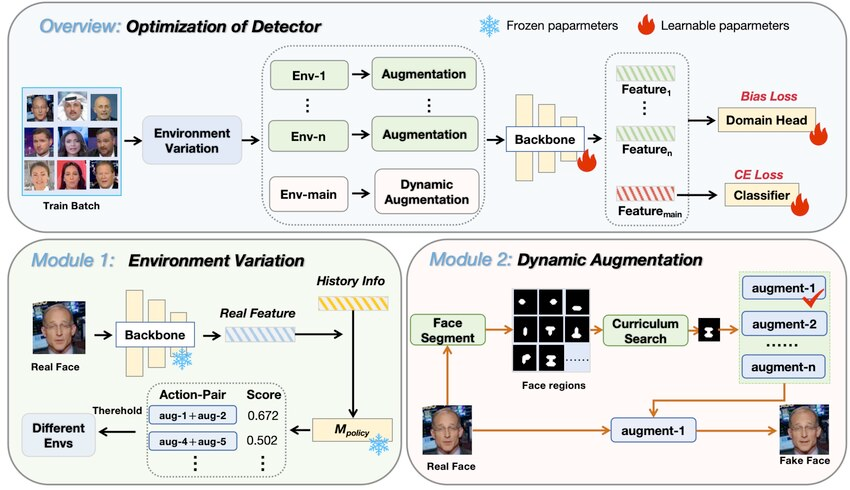
Fig 4. Multimodal Deepfake Detection and Localization with FPN-Transformer [2].
The first step in the pipeline converts audio and video inputs into unified temporal feature sequences using frozen, pretrained self-supervised models: WavLM-Large for audio and CLIP ViT-B/16 for video. These models are kept frozen to prevent overfitting and improve the generalization of the extracted features. Next, the features are processed through masked differential 1D convolutions to capture local temporal variations. Such variations are often indicative of manipulation, as deepfake artifacts commonly manifest as abrupt temporal changes, inconsistent transitions, or subtle discontinuities. The resulting features are then passed into the core backbone, which consists of stacked R-TLM Transformer blocks with localized attention and strided convolutions. This design constructs a multi-scale temporal feature pyramid, enabling the model to detect forged segments of varying temporal lengths. Finally, a dual-branch prediction head is applied to the pyramid features. One branch performs timestamp-level forgery classification, while the other regresses the start and end offsets of manipulated segments. Separate audio and video models are trained using the same architecture, and their outputs are combined at inference time.
Training Objective
The training objective jointly optimizes detection accuracy and temporal localization precision through a multi-task loss function:
\[\mathcal{L}_{\text{total}} = \frac{1}{T^+} \sum_{t=1}^{T} \left[ \lambda \mathcal{L}_{\text{cls}}(t) + \mathbf{1}(t \in \Omega^+)\mathcal{L}_{\text{reg}}(t) \right]\]Classification Loss
For forgery classification at each time step, the model uses focal loss to address the severe class imbalance between real and fake segments and to emphasize harder examples:
\[\mathcal{L}_{\text{cls}} = - \frac{1}{T^+} \sum_{t=1}^{T} \mathbf{1}(t \in \Omega^+) \left[ \log(p_t) + \gamma (1 - p_t)^{\alpha} \right]\]Regression Loss
For localization, a DIoU (Distance-IoU) based regression loss is applied to predicted start and end boundaries of forged segments, encouraging tight temporal alignment with ground truth:
\[\mathcal{L}_{\text{reg}} = \frac{1}{T^+} \sum_{t \in \Omega^+} \left( 1 - \text{DIoU}(\hat{s}_t, \hat{e}_t; s_t^*, e_t^*) \right)\]These two losses are combined with a weighting factor to balance classification confidence and boundary accuracy, enabling the model to learn both whether a segment is fake and precisely when the manipulation occurs.
Conducted Experiments
The proposed framework is evaluated on the IJCAI’25 DDL-AV benchmark, a large-scale dataset containing diverse audio and video deepfake generation methods. The experiments assess both detection and localization performance using AUC for classification and Average Precision (AP) and Average Recall (AR) at multiple temporal IoU thresholds for localization.
The best-performing configuration achieves a final score of 0.7535, demonstrating strong performance across both tasks. Ablation studies show that WavLM and CLIP provide more robust feature representations than alternative encoders, and that excessive training leads to reduced generalization on unseen forgery methods. Qualitative visualizations further confirm that the model can accurately identify and align forged temporal segments in both audio and video.
Limitations
Despite its effectiveness, the proposed approach has several limitations. Audio and video modalities are processed independently and combined only at the decision level, meaning the model does not explicitly learn fine-grained cross-modal interactions through joint attention. The reliance on large pretrained encoders and Transformer-based architectures introduces significant computational cost, limiting real-time applicability. The model’s performance is also sensitive to training duration, with overtraining harming generalization to unseen attacks. Finally, the framework focuses exclusively on temporal localization and does not address spatial localization of visual forgeries, such as identifying specific manipulated facial regions.
Method 3 - Reinforcement Learning-Based Adaptive Data Augmentation
Traditional data augmentation strategies are static and often fail to address the diverse and evolving nature of deepfakes. CRDA tackles this by using reinforcement learning, a way to make training data more useful for deepfake detection. Instead of applying the same changes to every video, a learning agent chooses which augmentations (like color changes or distortions) will help the model improve. It gets feedback based on how well the detector performs, and over time learns to create data that teaches the model to focus on real, generalizable signs of deepfakes rather than specific artifacts.
Previous work like CDFA used data augmentation and a dynamic forgery search to improve deepfake detectors by selecting augmentations based on validation performance. However, this approach is limited because it overfits to the validation set and doesn’t generalize well.
CRDA overcomes these limitations by using a carefully designed reward system to guide the learning agent. The reward encourages the model to first learn basic features, then gradually handle more challenging examples, and finally explore diverse augmentations. It combines multiple components:
Fig 5. Improving Deepfake Detection with Reinforcement Learning-Based Adaptive Data Augmentation [3].
-
Training Stability: \((\lambda_1 \mathbb{E}[1 - C_{tr}])\) \(\mathbb{E}[1 - C_{tr}] = \frac{1}{N} \sum_{i=1}^{N} \left(1 - \left| f_\theta(x_i) - y_i \right|\right)\)
Promotes confident predictions while avoiding overfitting. -
Validation Improvement: (\(\Delta AUC_{val} = AUC_{val}(t) - AUC_{val}(t-1)\))
Rewards gains on a validation set containing complex augmented fakes to drive generalization. -
Adversarial Deception: Selects augmentations that challenge the detector, expanding its knowledge boundary through a minimax-like strategy.
Multi-Environment Causal Invariance Learning
CRDA enhances deepfake detection by training the detector across multiple environments to learn causally stable features rather than overfitting. Causal inference is a key AI methodology that determines if and how one variable directly affects another and quantifies such effects. Features are divided into causal features (\(X_v\)) and spurious features (\(X_s\)), and the goal is to focus on \(X_v\) across diverse environments.
Environments are constructed based on policy entropy, which measures the confidence of different augmentation strategies. Confidence divergence in strategies across environments forces the model to decouple correlations tied to specific tactics. This leads to:
- Dominant environment: Low-uncertainty samples with minimal entropy, representing clear, stable features.
- Adversarial environments: High-uncertainty samples partitioned by quantiles, challenging the detector to handle difficult or ambiguous cases
To learn invariant features, CRDA applies Invariant Risk Minimization (IRM) across environments. A bi-level optimization aligns environment-aware feature learning with augmentation policy adaptation, minimizing the detector’s loss while penalizing reliance on environment-specific cues. A model is then trained to minimize the prediction error across all environments while maintaining performance:
\[\min_{\theta} \sum_{m=1}^{M} w_m \mathbb{E}(x, y) \sim Q_m [\mathcal{L}(f_\theta(x), y)] + \Omega \|\nabla_{w}|_{w=\mathbf{1}} \mathcal{L}_m(w \circ f_\theta)\|^2\]Multi-Dimensional Curriculum Scheduling
CRDA’s reinforcement agent gradually guides the detector through increasingly difficult training data using multi-dimensional curriculum scheduling, which balances complexity, exploration, and regional focus.
- Data Course: Controls the proportion of augmented forged samples over time. Early in training, the model sees mostly simple forgeries; more complex augmented samples are gradually introduced using a sine-based scheduling function to ensure smooth learning.
- Exploration Course: Uses dynamic entropy regularization in the reinforcement learning agent to balance exploration and exploitation. Exploration starts low, peaks mid-training to encourage trying new augmentation strategies, and then decays to stabilize the policy.
- Region Course: Focuses on facial regions through a curriculum template. Initially, multiple facial organs (eyes, nose, mouth) are combined to create large forgery areas; over time, the model shifts to smaller, single-organ regions. This transition is controlled by an exponential decay function and Gaussian sampling to guide attention from coarse to fine features.
Loss Function
The overall loss function comprises two key components that optimizes both classification performance and feature invariance: \(L_{\text{total}} = L_{CE} + \gamma L_{\text{bias}}\).
Cross-Entropy Loss (LCE): Standard classification loss on augmented samples.
Bias Loss (Lbias): Regularization term from the invariant risk minimization framework to maintain feature invariance across different augmentation strategies. The hyperparameter γ balances discriminative learning with invariance.
Limitations
While this approach presents many benefits in generalizing deepfake detection techniques, it also is limited by a few factors. The first is computational cost, as the multi-environment framework and policy learning mechanism require multiple forward passes and environment-specific training, increasing training time significantly. In addition, there is also currently a lack of a quantitative method to guide the selection of base augmentation strategies.
Conclusion
As the power of generative models accelerates, the dynamic between generative models and detection has evolved into a race of models versus detection methods. The methodologies explored in this report of Next-Frame Feature Prediction, FPN Transformers, and Reinforcement Learning-Based Adaptive Data Augmentation, represent an evolution of detection models from identifying superficial visual artifacts to identifying deeper features such as temporal dependencies and minute invariances. By leveraging multimodal inputs and new methods, these frameworks address the issues of previous generation detectors. However, these models rely on heavy computational resources and complex architectures, highlightint a trade-off between detection accuracy and scalability/efficiency. Moving forward, the future of digital integrity will likely depend on refining these temporal and adaptive strategies to create lightweight, generalized solutions.
References
[1] Anshul, Ashutosh, et al. “Next-Frame Feature Prediction for Multimodal Deepfake Detection and Temporal Localization.” arXiv preprint arXiv:2511.10212. 2025.
[2] Zheng, Chende, et al. “Multi-modal Deepfake Detection and Localization with FPN-Transformer.” arXiv preprint arXiv:2511.08031. 2025.
[3] Zhou, Yuxuan, et al. “Improving Deepfake Detection with Reinforcement Learning-Based Adaptive Data Augmentation.” arXiv preprint arXiv:2511.07051. 2025.