Semantic Segmentation of Coral Reefs: Evaluating SegFormer, DeepLab, and SAM3
[Project Track: Project 1] Deep learning has become a standard tool for dense prediction in environmental monitoring. Inthis project, we focus on semantic segmentation of coral reef imagery using the CoralScapes dataset. Starting from a pretrained SegFormer-B5 model, we design a coral-specific training pipeline that combines tiling, augmentations, and a CE+Dice loss. This yields a modest but consistent improvement in mIoU and qualitative boundary sharpness over the original checkpoint. We also run exploratory experiments with DeepLabv3 and SAM3, and discuss practical limitations due to the absence of coral-specific pretraining and limited compute.
- Main Content
- Results
- Models and Experiments
- Model Comparison
- Conclusion
- Limitations and Future Work
- References
Main Content
Coral reefs are under increasing stress from climate change and local human impacts, and high-resolution monitoring is essential for tracking reef health over time. Manual annotation of underwater imagery is slow and requires expert knowledge, which motivates the use of semantic segmentation models to automate benthic mapping.
In this project, we focus on semantic scene understanding in coral reefs using the CoralScapes dataset.
Dataset.
We use the CoralScapes dataset, a general-purpose coral reef semantic segmentation benchmark
with 2,075 images, 39 benthic classes, and 174,077 segmentation masks (≈ 3.36B annotated
pixels). The dataset is split spatially by reef site for fair generalization testing:
- 1,517 train images (27 sites)
- 166 validation images (3 sites)
- 392 test images (5 sites)
The imagery spans diverse real reef conditions (e.g., shallow reefs <15m, varying camera-to- seabed distance and turbidity, different times/lighting conditions), making it a challenging, realistic segmentation setting.
Results
Full Results (Qualitative)
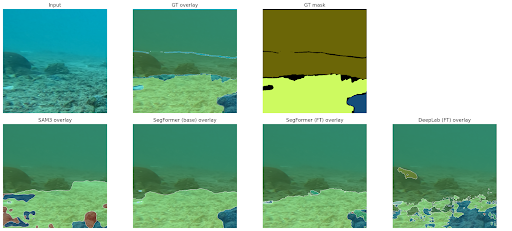
SegFormer-B5 Overlay (Video): https://drive.google.com/file/d/119cAD7lq9Zfyn4leEki5gl8dGJ9USxdg/view?ts=693df8e8
Full Results (Quantitative)
| Model | Data | Split | Pixel Acc | mIoU |
|---|---|---|---|---|
| SegFormer Base | FULL | Val | 0.9372 | 0.7660 |
| SegFormer Base | FULL | Test | 0.8277 | 0.5668 |
| SegFormer Base | TILED | Val | 0.9244 | 0.7230 |
| SegFormer Base | TILED | Test | 0.8122 | 0.5615 |
| SegFormer FT | FULL | Val | 0.8680 | 0.5906 |
| SegFormer FT | FULL | Test | 0.7837 | 0.4788 |
| SegFormer FT | TILED | Val | 0.8532 | 0.5821 |
| SegFormer FT | TILED | Test | 0.7676 | 0.4767 |
| DeepLab FT | FULL | Val | 0.7219 | 0.3591 |
| DeepLab FT | FULL | Test | 0.7783 | 0.4548 |
| DeepLab FT | TILED | Val | 0.7050 | 0.3333 |
| DeepLab FT | TILED | Test | 0.7533 | 0.4260 |
| SAM3 FT | FULL | Val | 0.5981 | 0.1428 |
| SAM3 FT | FULL | Test | 0.6199 | 0.1833 |
| SAM3 FT | TILED | Val | 0.6526 | 0.1919 |
| SAM3 FT | TILED | Test | 0.6906 | 0.2352 |
Models and Experiments
SegFormer-B5 (Released CoralScapes Checkpoint)
Motivation.
SegFormer is a transformer-based semantic segmentation architecture that performs strongly on
dense prediction tasks. Because a CoralScapes-tuned SegFormer-B5 checkpoint is publicly
available, it serves as a high-quality reference baseline for our experiments.
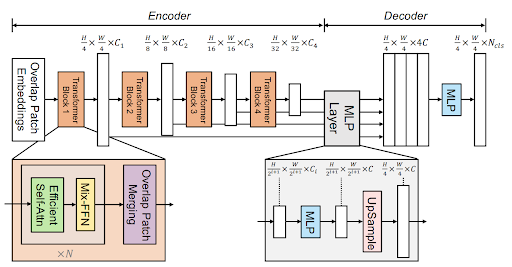
Architecture.
SegFormer uses a hierarchical Mix Transformer (MiT-B5) encoder that produces multi-scale
feature maps, and a lightweight decoder that fuses these features into dense per-pixel logits.
Results.
The released SegFormer-B5 checkpoint is the strongest model in our study across most splits,
achieving:
- FULL: Val mIoU 0.7660, Test mIoU 0.5668
- TILED: Val mIoU 0.7230, Test mIoU 0.5615
SegFormer Fine-Tuning (Our Short-Budget Adaptation)
Motivation.
We fine-tune SegFormer using a coral-specific pipeline (tiling, strong augmentations, and a
CE+Dice loss) to test whether a stronger training setup can improve robustness despite limited
compute.
Training Pipeline.
- Train on tiles to increase sample count and reduce memory cost per step
- Use strong augmentations (Flip, Rotate, RGBShift, RandomFog, GaussianBlur)
- Optimize with Cross-Entropy + Dice to balance pixel accuracy and region overlap under class imbalance
Results. Under our constrained training schedule, our fine-tuned SegFormer model underperforms the released SegFormer-B5 checkpoint:
- FULL: Val mIoU 0.5906, Test mIoU 0.4788
- TILED: Val mIoU 0.5821, Test mIoU 0.4767
Interpretation.
SegFormer-B5 is large and typically benefits from long schedules; short fine-tuning can fail to
match a strong dataset-tuned checkpoint. Given more time and compute, we would expect
performance to improve with longer schedules and better-tuned optimization (LR schedule,
weight decay, freezing strategy, etc.).
DeepLabV3+ Fine-Tuning (ResNet-50)
Motivation.
DeepLabV3+ is a widely used CNN-based segmentation baseline. We include it as a comparison
point against transformer segmentation, particularly since coral imagery contains fine textures
and complex boundaries.
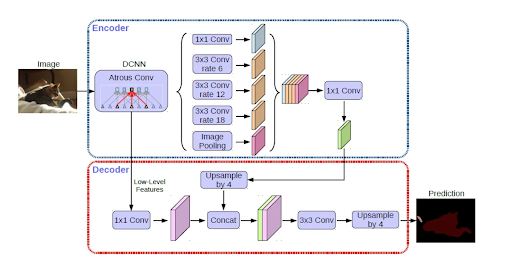
Architecture (brief).
DeepLabV3+ combines a CNN backbone with atrous/dilated convolutions (ASPP) for multi-scale
context, followed by a decoder for boundary refinement.
Results. With limited training time, DeepLabV3+ performs below SegFormer:
- FULL: Val mIoU 0.3591, Test mIoU 0.4548
- TILED: Val mIoU 0.3333, Test mIoU 0.4260
Interpretation.
The DeepLab result is similar to our SegFormer result as we could optimize and get better results with more time/compute. CNN models can require careful tuning of LR schedules and longer training to be competitive on fine-grained multi-class segmentation.
SAM3 Fine-Tuning (Foundation Model)
Motivation.
SAM3 is a recent foundation model designed for promptable segmentation and tracking. We
explore whether its large-scale pretraining can transfer to coral reef semantic segmentation with
minimal adaptation.
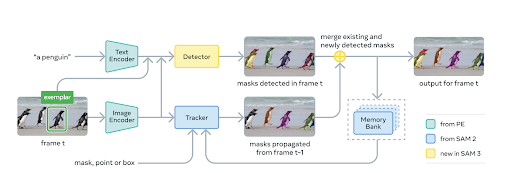
Adaptation for Semantic Segmentation. SAM3 is originally built for prompt-driven instance segmentation. To repurpose it for dense multi-class segmentation, we:
- Use SAM3 as an image feature backbone
- Attach a lightweight per-pixel semantic head
- Train in a prompt-free dense prediction mode with the same CE+Dice objective
Results. SAM3 performs poorly in this prompt-free, dense multi-class setup:
- FULL: Val mIoU 0.1428, Test mIoU 0.1833
- TILED: Val mIoU 0.1919, Test mIoU 0.2352
Interpretation.
There are two main reasons for poor performance:
- SAM3 is optimized for prompted instance masks (“segment the object I indicate”), not specific multi class dense semantic labeling.
- SAM3 is extremely large, so our fine-tuning budget was necessarily short. Under short training, the model is unlikely to adapt fully to the coral-specific label space and underwater domain shift.
Takeaway.
In our constrained setting, a dataset-tuned semantic segmentation model (SegFormer)
transfers far better than a large promptable foundation model adapted with a small semantic
head.
Model Comparison
Transformed-based segmentation models demonstrate the strongest performance on the CoralScapes dataset, while operating under limited compute and training time. SegFormer consistently outperformed both the CNN and foundation model approaches, likely because it captures global context without losing fine spatial detail. This matters for benthic segmentation, where visually similar classes must be separated despite varying lightings and reef structure.
DeepLabV3 focuses on more local texture through convolutional features. While this performs well for many image segmentation tasks, it may be less effective at separating fine-grained benthic classes without longer training or careful tuning. This suggests that CNN-based models may need additional optimization or task-specific pretraining to perform well on underwater images.
SAM3 performs poorly in this project, likely because it was pre-trained for prompt-based instance segmentation rather than semantic segmentation. While it can produce spatially coherent masks, it has difficulty assigning the correct class labels to fine-grained coral categories, especially with limited fine tuning. This suggests that large foundation models do not translate well to semantic segmentation tasks without task-specific adaptations.
Conclusion
In this project, we evaluated multiple modern segmentation architectures on the CoralScapes dataset while operating under limited compute. Our results show that models explicitly designed and fine-tuned for semantic segmentation, particularly transformer-based architectures like SegFormer, perform best on fine-grained coral reef images compared to CNN or adapted foundation models with a semantic head. However, performance of models may be vastly different without the time and compute limitations we faced.
Limitations and Future Work
A key limitation of this study is compute and time. Large models such as SegFormer-B5 and SAM3 typically require long training schedules, careful hyperparameter tuning, and (in SAM3’s case) potentially prompt-aware training strategies to reach their full potential. Our experiments instead reflect a realistic small-budget regime, so results for the fine-tuned models (SegFormer FT, DeepLab FT, SAM3 FT) should be interpreted as lower bounds on what these approaches could achieve.
Future work includes:
- Longer fine-tuning schedules with tuned learning rates/warmup/weight decat
- Layer-freezing or gradual unfreezing to reduce catastrophic forgetting
- Coral-domain pretraining or underwater-specific augmentation strategies
- SAM3 experiments that incorporate prompts or prompt-like conditioning instead of forcing a prompt-free dense prediction mode
Colab notebook with project code: https://colab.research.google.com/drive/1-XIG4hYo7OcubjfQI2XydadW4JpQBowh?usp=sharing
References
Carion, N., et al. (2025). SAM 3: Segment anything with concepts. arXiv preprint arXiv:2511.16719.
Chen, L.-C., et al. (2017). DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(4), 834–848.
Sauder, J., et al. (2025). The CoralScapes dataset: Semantic scene understanding in coral reefs. arXiv preprint arXiv:2503.20000.
Xie, E., et al. (2021). SegFormer: Simple and efficient design for semantic segmentation with transformers. Advances in Neural Information Processing Systems, 34, 12077–12090.