Tunable GANs
Today, generative adversarial networks (GANs) make up most state-of-the-art deepfake portrait generators. However, most of these deep learning networks generate completely random images; the user has little to no control over the output, and it is difficult to determine how the images are produced. This gap limits the utility of modern deepfake technology for potential users like special effects teams. We will therefore investigate how to make GAN-based deepfake generators tunable and understandable so that users can edit different aspects of generated images in real time. We then examine some of the applications of tunable GANs.
Introduction
Fig 1. Deepfake images generated by StyleGAN2 [4], a widely popular deepfake generator.
Today, GAN-based deep learning models like StyleGAN and StyleGAN2 are able to generate hyperrealistic images of fake people as shown above. Despite this success, customizing qualities of output images like pose, lighting, and expression is an open question. One of the major challenges in this field is the lack of sufficient training data especially if utilizing 3D face models as training input or if requiring labeled data. The proposed solutions all seek to address this issue by attempting to decrease the reliance on labeled or hard-to-obtain data and moving towards self-supervised or unsupervised learning techniques instead. In this article, we will examine StyleRig, DiscoFaceGAN, and SeFa and then discuss an application of tunable GANs.
A demo of our work in the applications of tunable GANs can be found here.
Our video can be found here.
StyleRig
Motivation
There have historically been several ways to represent the data encoding a face in deep learning models. The first was to create a 3D rig of a face with different controllable parameters like identity, expression, or lighting. However, this approach is severely limited by a lack of training data, as it is necessary to perform a 3D scan of faces to obtain a single data sample, which is incredibly expensive as compared to other data collection techniques. This technique is able to provide a high degree of control over the output as desired, but because of the limited training data, output images are often not very realistic.
The other approach is to use a GAN to learn various parameters from 2D training images, which has shown great results in terms of generating realistic images but provides the user with no control over the output. As a result, StyleRig proposes a hybrid, self-supervised solution which provides the controllability of 3D rigs and the hyperrealism of GAN models.
Architecture
StyleRig involves several different networks. First, a differentiable face reconstruction network (DFR) takes in a latent vector \(\textbf{v}\) and produces facial parameters \(\textbf{p} = (\mathbf{\alpha}, \mathbf{\beta}, \mathbf{\delta}, \mathbf{\gamma}, \mathbf{R}, \mathbf{t})\) where \(\mathbf{\alpha}\in\mathbb{R}^{80}\) represents facial shape, \(\mathbf{\beta}\in\mathbb{R}^{80}\) represents skin reflectance, \(\mathbf{\delta}\in\mathbb{R}^{64}\) represents facial expression, \(\mathbf{\gamma}\in\mathbb{R}^{27}\) represents scene illumination, \(\mathbf{R}\in SO(3)\) represents head rotation, and \(\mathbf{t}\in\mathbb{R}^3\). This network is trained using self-supervised loss in tandem with a differentiable render layer which takes in \(\textbf{p}\), converts it into a 3D mesh, and generates a rendering \(\mathcal{R}(\textbf{p})\).
Similarly, the RigNet encoder and decoder are trained in a self-supervised manner. The total loss is therefore \(\mathcal{L}_{total} = \mathcal{L}_{rec} + \mathcal{L}_{edit}+ \mathcal{L}_{consist}\) where given latent code \(\textbf{w}\), reconstruction loss is \(\mathcal{L}_{rec}=||RigNet(\textbf{w}, \mathcal{F}(\textbf{w})) - \textbf{w}||_2^2\) and editing and consistency loss are computed using a cycle-consistent rerendering loss.
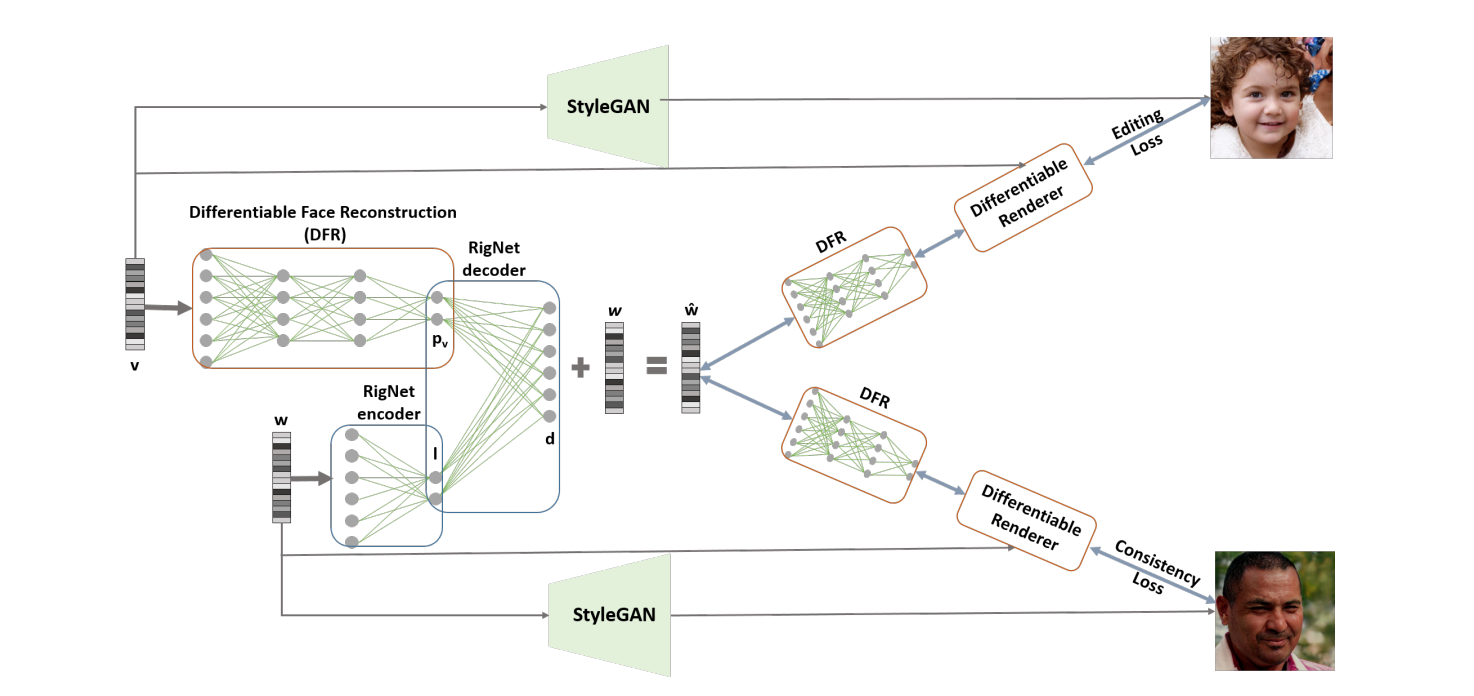
Fig 2. Architecture of StyleRig[1].
Results
StyleRig is therefore able to perform style mixing where features in one image are transferred to another, interactive rig control in which users can change parameters like pose in real-time, generate images conditioned on a particular parameter, and control various parameters simultaneously.
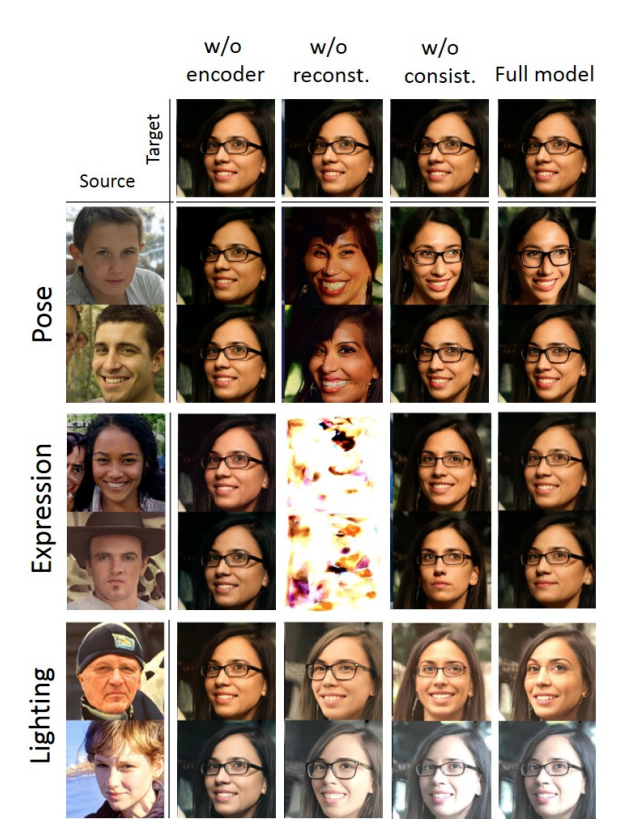
Fig 3. StyleRig results when changing pose, expression, and lighting[1].
However, because the DFR network only predicts a set parameters like pose, expression, and lighting, editing with StyleRig is limited to only these features. Users are therefore not able to change all latent parameters of a picture like hairstyle, which limits the utility of StyleRig. Furthermore, there is no guarantee that the parameters produced by the DFR network are disentangled from other features like background. Therefore, editing pose may not preserve these other latent features; for example, it may be impossible to edit pose without changing the background as well.
DiscoFaceGAN
Motivation
DiscoFaceGAN was created by Microsoft researchers and addresses several of the problems that StyleRig and other recent works do not resolve. First, DiscoFaceGAN investigates disentangling the latent parameters of the image so that one parameter can be changed without affecting the others. Second, DiscoFaceGAN accounts for a random noise parameter so that other latent parameters can be accounted for and disentangled from the main parameters that DiscoFaceGAN focuses on. Third, StyleRig relies on rerendering 3D priors in a cyclic fashion, while DiscoFaceGAN only uses them in the training stage. Relying less on 3D priors allows for producing a wider variety of images, since available data for 3D face rigs is constrained to a small identity subspace.
Architecture
DiscoFaceGAN considers five latent variables: identity, expression, illumination, pose, and random noise (which incorporates other properties such as background). During training, we train four different VAE models for \(\alpha, \beta, \gamma\), and \(\theta\) which correspond to identity, expression, illumination, and pose, respectively. We sample 5 Gaussian distributions for each of these parameters and use a 3D model to obtain the variables for all training images. We then discard the encoders in the VAEs to translate Gaussian \(z\)-vectors to our latent parameters. Finally, we produce two images: one by the generator in the GAN and another by a pretrained 3D face reconstruction model and train the GAN by minimizing the loss between the 3D rendered face and generated face.
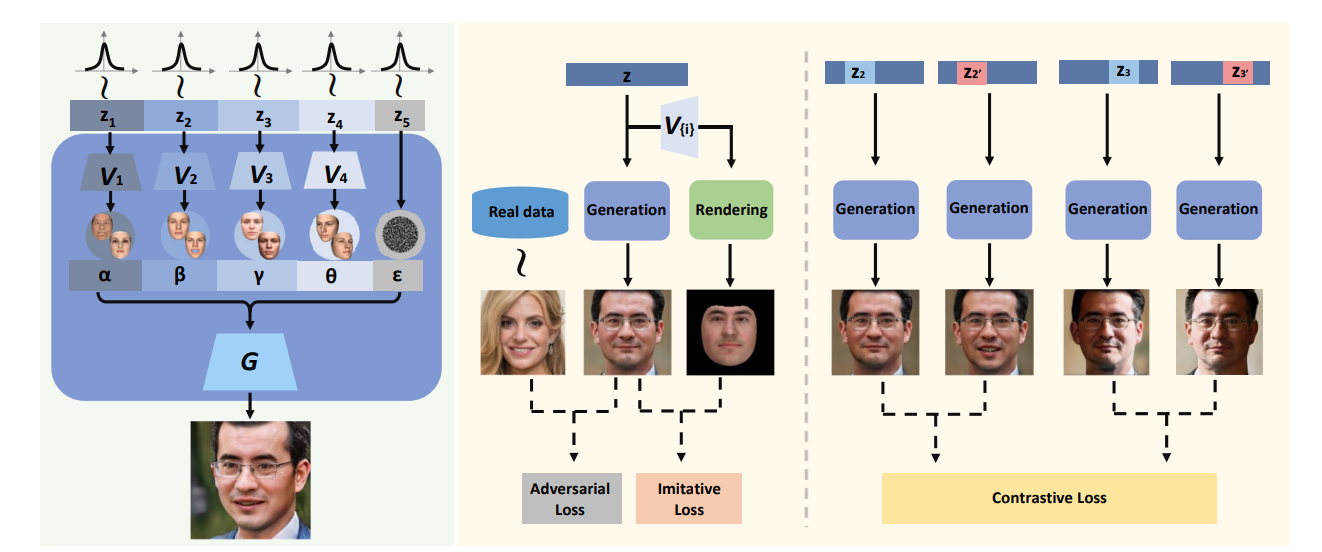
Fig 4. DiscoFaceGAN architecture and training scheme[2].
In order to achieve disentanglement in the latent space, DiscoFaceGAN uses expression-invariant contrastive learning (based on 3D priors) and illumination-invariant contrastive learning (by minimizing the difference between the 3D face structures). Constrastive learning works by sampling pairs of latent vectors \(z\) and \(z'\) which differ only at \(z_k\). We then examine the corresponding face images \(x\) and \(x'\) and penalize the difference at any \(z_i\) where \(i\neq k\).
Results
Like StyleRig, DiscoFaceGAN is able to mix styles and edit images. Some sample results from the original paper are shown below. The latent parameters are highly disentangled, as changing one factor does not affect the others as much as StyleRig.

Fig 5. Faces generated by DiscoFaceGAN with varying identity, expression, pose, and illumination[2].
Like StyleRig, DiscoFaceGAN still faces several limiations. It is unable to change highly specific parameters like details of expressions, eye gaze, or hair placement. Furthermore, because it also relies on 3D priors, it is still limited by the small domain of 3D models.
SeFa
Motivation
StyleRig and DiscoFaceGAN both rely on 3D priors of faces and only allow tuning of a closed set of latent parameters. An effective tuning system, however, should be able to tune an arbitrary set of parameters that range from coarse (pose and illumination) to fine (hair placement or detailed expression), since users have a diverse set of use cases. Furthermore, an ideal tuning system would not have to rely on having 3D priors for each parameter in order to have better generalizability, as there is limited 3D training data. Thus, SeFa was developed as an unsupervised generator which allows for tunability for an arbitrary number of features.
Method
SeFa involves calculating the closed form of a semantic factorization problem. Traditional GAN models project the latent space to intermediate spaces and eventually to the final image; let the first transformation be
\[G_1(\mathbf{z}) = \mathbf{Az} + \mathbf{b} = y.\]Then we can perturb the latent vector and thereby edit the intermediate space to produce
\[\mathbf{y}' = G_1(\mathbf{z}+\alpha\mathbf{A}\mathbf{n}).\]Because we are acting upon the transformation from the latent space to the first intermediate space, this manipulation holds for any input image and is therefore independent of training data. \(\mathbf{A}\) therefore represents an important transformation, and by decomposing \(\mathbf{A}\), we can uncover latent parameters that have a large effect on the image.
SeFa therefore computes the \(k\) most important directions \(\mathbf{n}_1, \mathbf{n}_2,..., \mathbf{n}_k\) by finding the \(k\) best solutions to the following equation:
\[\mathbf{n}=argmax_{\mathbf{n}^T\mathbf{n}=1}||\mathbf{An}||^2_2.\]This is solvable by obtaining the eigenvectors of \(\mathbf{A}^T\mathbf{A}\) that correspond to the \(k\) largest eigenvalues. SeFa then applies this approach to pretrained GANs like StyleGAN2 to edit the \(k\) most important latent parameters. Furthermore, this approach can be generalized to any layer within a GAN.
Results
Because SeFa can be applied at different layers of a GAN, it can capture different levels of latent parameters from coarse to fine as shown in figure 6 below. For example, StyleGAN’s lower layers correspond to coarser parameters like pose and illumination, whereas the top layers correspond to finer parameters like line thickness. SeFa is therefore a significant improvement in tunability as compared to StyleRig and DiscoFaceGAN. Furthermore, SeFa can be extended to other kinds of images rather than portraits.

Fig 6. Images produced by tuning parameters at different levels of StyleGAN and StyleGAN2 using the SeFa approach[3].
SeFa still has several limitations. First, the top \(k\) parameters do not necessarily correspond to a human-understandable dimension such as pose. SeFa does not disentangle latent parameters, meaning that adjusting one of the top \(k\) parameters may vary a combination of human-understandable features. It is also weak in tuning parameters that do not cause a large variation, as it only takes the top \(k\). An example of entangled parameters provided by the paper is that age and eyeglasses correspond to the same latent direction according to SeFa because age and wearing of glasses are correlated. Supervised learning approaches are better able to make this kind of distinction since the labels provide more information on what latent parameters are distinct. However, it exceeds other unsupervised learning approaches, is far more simple than other approaches, and is much more generalizable, allowing users to edit complex attributes like hair style and placement of individual hairs.
Demos and Results
A demo created by the authors of SeFa is available here with Colab notebook here. The code for SeFa is also available here. Because all these details are already open source, it did not make sense to reproduce this work. As a result, we examine an application of tunable GANs.
Specifically, we can use tunable GANs like StyleGAN to see how they would processed for downstream tasks like image colorization.
Pix2PixGAN
The Pix2PixGAN is useful in many ways, but the GAN we trained in this project was soley in order to turn a black and white image of a face into to an RGB colored image.
The architecture of a Pix2PixGAN consists of a PatchGAN discriminator and U-net generator. The Unet generator was special at its time because it is composed of two paths, the contracting path and the expanding path. For the original paper, the authors made the contracting path of many blocks each composed of conv_layer1 -> conv_layer2 -> max_pooling -> dropout. After the contracting Path the authors made the expanding path of many blocks composed of conv_2d_transpose -> concatenate -> conv_layer1 -> conv_layer2.
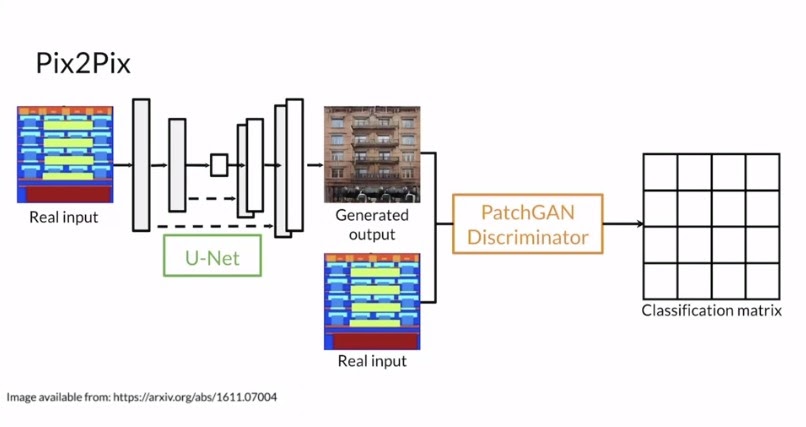
Fig 7. Architecture of Pix2PixGAN
This was used with a PatchGAN discriminator. The reason why the PatchGAN disciminator is effective is because it will convolve the image and try to classify each N by N pixel in an image as real or fake, and those results would then be averaged.
This results in a fairly good generator useful for an image to image translation task.
Results
While we used a Pix2PixGAN that was trained soley on hand drawn and colored images, we were able to obtain desirable results when we fed our styleGAN output into the Pix2PixGAN. This suggests that tunable GANS will produce an output that is not only indistinguishable to the human eye, but also to a GAN trained on human created images. attatched is a link to a demo that allows you to input an image of a face and get the corresponding results.

Fig . Sample of results from Pix2PixGAN
Reference
[1] Ayush Tewari, Mohamed Elgharib, Gaurav Bharaj, Florian Bernard, Hans-Peter Seidel, Patrick Perez, Michael Zollhofer, and Christian Theobalt, “StyleRig: Rigging StyleGAN for 3D Control over Portrait Images,” in CoRR, 2020.
[2] Yu Deng, Jiaolong Yang, Dong Chen, Fang Wen, and Xin Tong, “Disentangled and Controllable Face Image Generation via 3D Imitative-Constrastive Learning,” in IEEE Computer Vision and Pattern Recognition, 2020.
[3] Yujun Shen and Bolei Zhou, “Closed-Form Factorization of Latent Semantics in GANs,” in CVPR, 2021.
[4] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila, “Analyzing and improving the image quality of stylegan,” in CVPR, 2020.
[5] link to our code