NeRF Exploration
The focus of project is to explore various approaches to generating 3-D scenes with Neural Radiance Fields. we utilize NeRF and NeRF variants to model Royce Hall and generate and generate novel viewpoints using prior images.
- Team 23
- Demo
- Introduction to Neural Radiance Fields (NeRF)
- Conclusions
- Reference
- Code Repos and Pages
Team 23
Group Members: Felix Zhang
Demo
github link (credit to nerfmm authors for implementation: here
3D Scene Generation (involving Generative Neural Radiance Fields)
There has been a recent surge in using exploring image generation centered in three dimensions due to the adoption of virtual, augmented, and mixed reality devices, as well as the possibility of using scenes to power downstream task datasets for agents. Volume-based representations have been at the forefront of innovation, with recent techniques like Neural Radiance Fields (NeRFs) Mildenhall et al. being a hot topic due to its ability to synthesize high fidelity lifelike renders.
Introduction to Neural Radiance Fields (NeRF)
Neural Radiance Fields are a recent development introduced by Mildenhall et al. for 3d image synthesis by optimizing a volumetric function with a multi-layer perceptron network. They achieve impressive results compared to traditional generative techniques.
NeRF works by estimating the density and 3-D RGB data from the position x (x,y,z) and viewpoint d (theta, phi). It uses a simple MLP to do this estimation.
\[(\theta,\phi), (x,y,z) -> (r,g,b), (\sigma)\]
class Nerf(nn.Module):
def __init__(self, pos_in_dims, dir_in_dims, D):
self.pos_in_dims = pos_in_dims
self.dir_in_dims = dir_in_dims
self.layers0 = nn.Sequential(
nn.Linear(pos_in_dims, D), nn.ReLU(),
nn.Linear(D, D), nn.ReLU(),
nn.Linear(D, D), nn.ReLU(),
nn.Linear(D, D), nn.ReLU(),
)
self.skip = nn.Linear(D + pos_in_dims, D)
self.layers1 = nn.Sequential(
nn.Linear(D, D), nn.ReLU(),
nn.Linear(D, D), nn.ReLU(),
nn.Linear(D, D), nn.ReLU(),
nn.Linear(D, D), nn.ReLU(),
)
self.fc_density = nn.Linear(D, 1)
self.fc_feature = nn.Linear(D, D)
self.rgb_layers = nn.Sequential(nn.Linear(D + dir_in_dims, D//2), nn.ReLU())
self.fc_rgb = nn.Linear(D//2, 3)
self.fc_density.bias.data = torch.tensor([0.1]).float()
self.fc_rgb.bias.data = torch.tensor([0.02, 0.02, 0.02]).float()
Generating the image and Loss
In order to generate an image, NeRF first takes a single image and splits it up per pixel. Each pixel has a corresponding angle and viewpoint, and points are sampled along the path of the ray given by the angle and viewpoint. They are weighted accordingly to the distance on the ray. Note that the camera intrinsics and extrinsics are assumed to be known in the NeRF paper. We will touch upon later on. The points are then accumulated and summed to create the pixel using the accumulated transmittance with the rendering equation below.
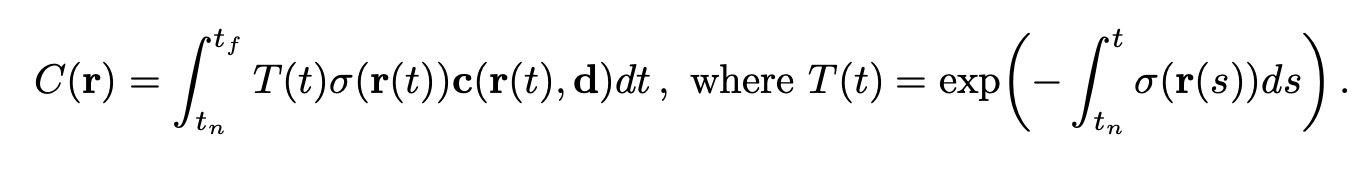
In order to sample the points, the NeRF paper has two different networks, a coarse network that does an initial sample, and a fine network that samples based on a probability distribution created from the coarse network’s results. This ensures that the model spends more time sampling points in more detailed areas rather than empty space. Due to GPU constraints, we only use the coarse network to generate results.
One key factor that the authors discovered were able to dramatically increase render quality was embed the position into a vector of sin/cos functions. This allowed the network to encode much higher frequencies, and greatly increases the detail.
Each pixel is compared to the ground truth pixel via a simple reconstruction loss. This whole process is differentiable, so we are able to optimize our MLP to internally represent our 3-D scene.
The following figure demonstrates the NeRF process.
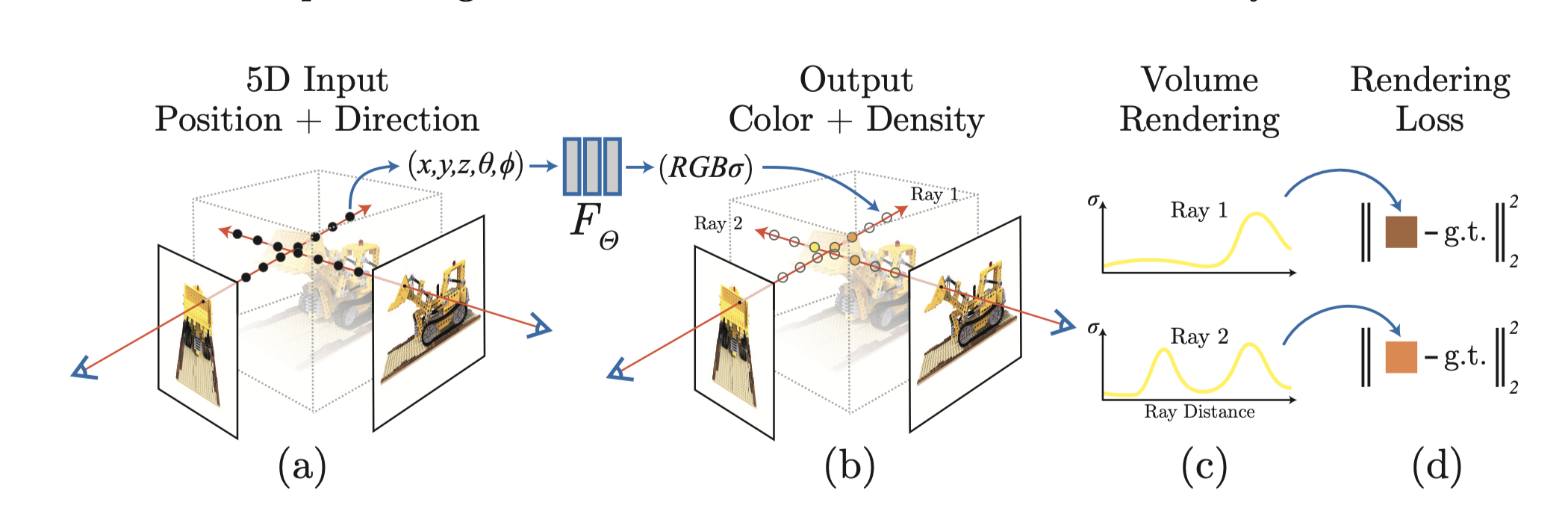
We can see that NeRF is able to successfully render realistic new viewpoints.
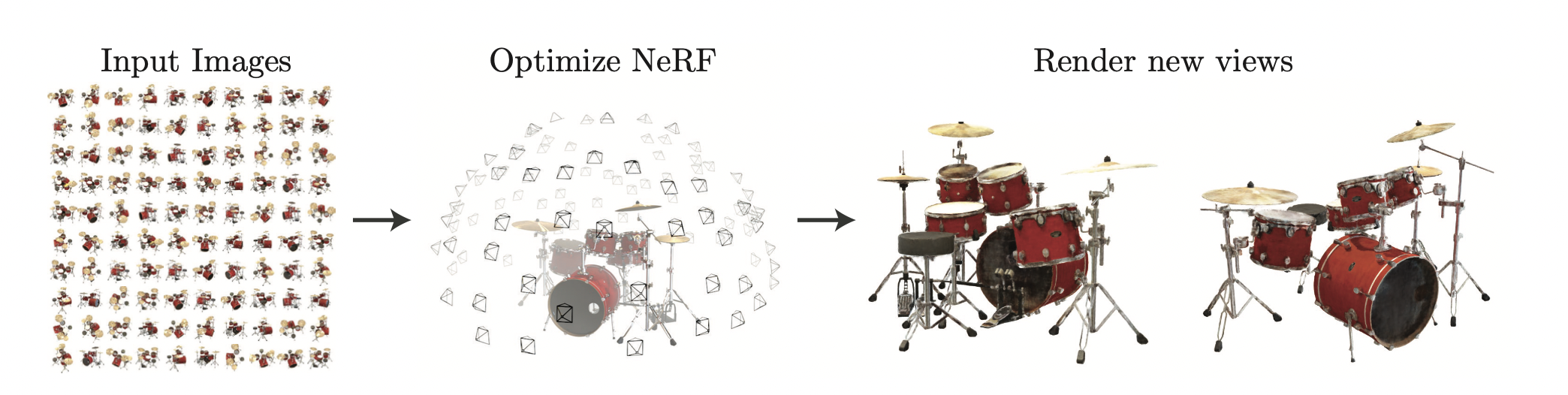
We specifically utilize the open source PyTorch implementation of NeRF located at [NeRF-Torch]. We have attached the NeRF model below, and use various helper functions as implemented to render the rays and reconstruction of the 2-D image from the 3-D volume.
Problem in Wonderland
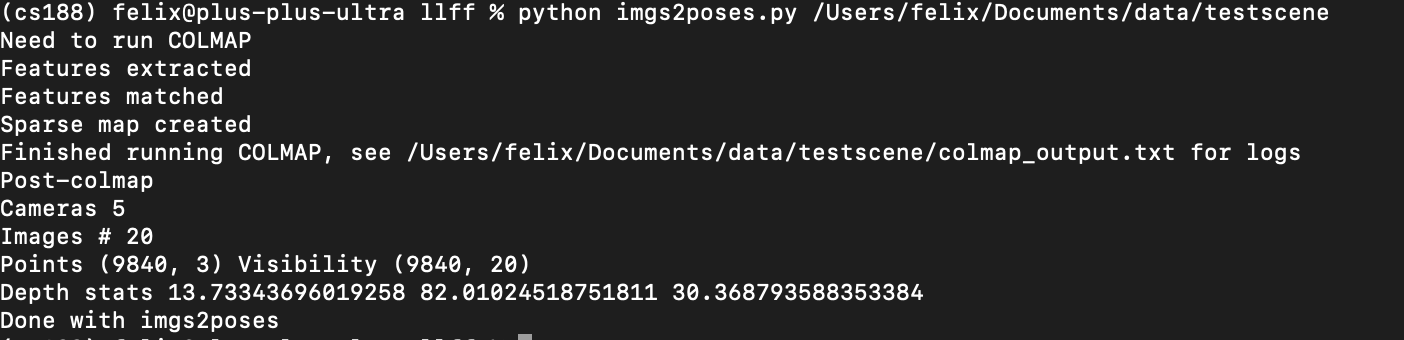
One main assumption in the NeRF model is that we know the camera intrinsics and extrinsics. The camera intrinsics are the focal length fxfy, and the camera extrinsics are the position x and viewpoint d. This however, is obviously broken in real life scenarios and our situation with pictures of Royce. To solve this, the authors of NeRF use Structure From Motion in order to estimate the camera parameters. When we tried to do this on our set of pictures, it ended up failing to converge.
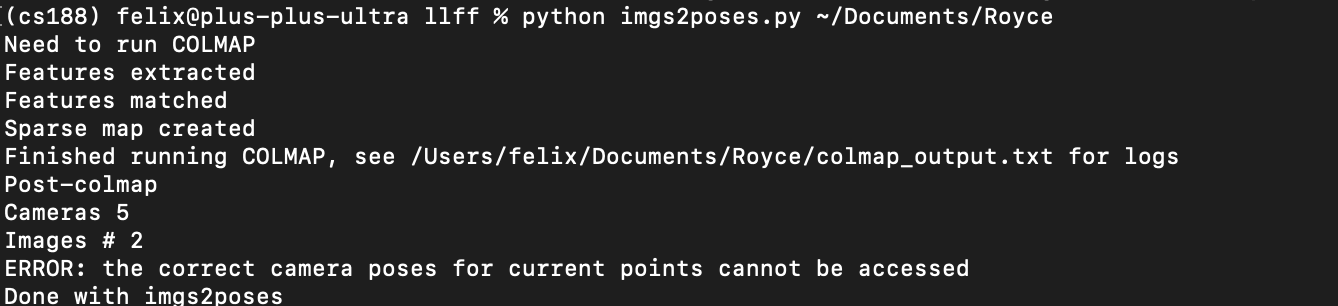
We verify the accuracy of our SOFM (colmap) package by checking on the test set.
Jointly Optimizing Camera Parameters (NeRF–)
NeRF– (Wang et al.) addresses this issue and demonstrates the combining of the inference of camera extrinsics and intrinsics with the MLP. They also show that the joint optimization is able to increase the capacity of the model.
NeRF– achieves this by considering the camera parameters as another part of the differentiable pipeline. It parameterizes the focal lengths below as a simple pinhole.
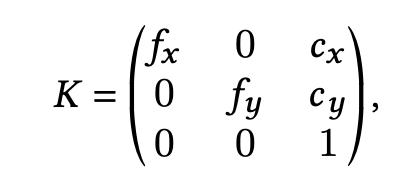
it also sets the rotation and translation (x,d) as a transformation matrix.
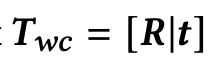
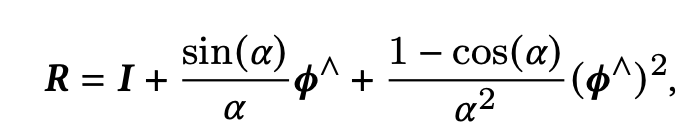
We proceed to use the NeRF– model (provided generously by the authors NeRF–). Because the intrinsics, position, and angle are jointly optimized, we don’t need run colmap to get structure from motion.
Following the general instruction from the github and cola, we explore tiny, normal, and big NeRF models varying the sizes of the stacked linear layers and adding shortcuts until performance has plateau’ed. The code is available below and Here.
We take pictures of Royce Hall at several vantage points and attempt to reconstruct a circle around similar to the original paper.
The output after 1000 epochs for each are below.
tiny:

normal:

big:

We observe that tiny seems to have the least amount of artifacts, but also doesn’t produce any detailing on the sides. As we increase the model sizing, we get more artifacts but more of the sides are preserved.
Note that the authors of NeRF– run a refinement model (keeping camera parameters but re-running NeRF). Due to GPU limitations, we don’t but note it could increase performance. We also only use a coarse model.
Database Cleaning
We note that the model itself has quite a bit of artifacts, and do an investigation of the database itself. Here are the pictures we use for the initial dataset.
Dataset:

We note one image with a severe occlusion, and try to train again without the occlusion.
New Dataset:

Clean Tiny NeRF–:

Clean Normal NeRF–:

Conclusions
We note that the results after reducing some features such as coarse-fine sampling and the refinement layer is not as high quality as hoped. We believe these limitations could be addressed with more GPU power and the features as well as more pictures around Royce itself.
We were hoping to look into NeRF-W Brualla et al, but could not due to GPU limitations. This model creates an embedding for each image, and is able to model transient parts of the image (such as the tree we removed). It also incorporates an appearance embedding which allows it to model different lighting settings such as sunrise and day.
NeRF++ also could be interesting, but since Royce is so large, we don’t need a second “sphere” of modeling for the background.
Another promising line of work is HashNeRF, which stores the pixels inside a progressively increasing hash-table for lookup, increasing run-time by a tremendous amount. For future extension, this is a good possible step forward while maintaing our GPU resources.
Reference
[1] Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, Angjoo Kanazawa. “Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image.” Proceedings of the ICCV conference on computer vision and pattern recognition. 2020.
[2] Michael Niemeyer, Andreas Geiger. “GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields” Proceedings of the CVPR conference. 2021.
[3] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng. “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis” Proceedings of ECCV conference 2020.
[4] Patrick Esser, Robin Rombach, Björn Ommer. “Taming Transformers For High-Resolution Image Synthesis” Proceedings of the CVPR conference. 2021.
[5] Sheng-Yu Wang, David Bau, Jun-Yun Zhu. “Sketch Your Own GANs” 2021.
[6] Yuanbo Xiangli, Linning Xu, Xingang Pan, Nanxuan Zhao, Anyi Rao, Christian Theobalt, Bo Dai, Dahua Lin. “CityNeRF: Building NeRF at City Scale” 2021.
[7] Stephan J. Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, Julien Valentin. “FastNeRF: High-Fidelity Neural Rendering at 200FPS” Proceedings of the ICCV conference 2021.
[8] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever. “DALL-E: Zero-Shot Text-to-Image Generation” 2021.
[9] Zirui Wang, Shangzhe Wu, Weidi Xie, Min Chen, Victor Adrian Prisacariu. “NeRF−−: Neural Radiance Fields Without Known Camera Parameters” 2021.
[10] Ricardo Martin Brualla, Noha Radwan, Mehdi S.M Sajjadi, Jonathan T. Barron, Alexey Dosovitskiy Daniel Duckworth. “NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections” 2021.
Code Repos and Pages
[1] NeRF
[2] Infinite Nature
[3] Giraffe
[4] NeRF-Torch
[5] NeRF–
[6] Exploration