Facial-Action-Detection
- Introduction
- Overview of Facial Action Detection Techniques
- EAC-Net (CNN approach to Facial Action Unit detection)
- JAA-Net
- ResNet-50
- Experiments
- References
Introduction
Background Introduction
Application value of facial action detection in natural human-computer interaction, emotional analysis, and other fields.
Facial Action Detection is an important aspect in improving human and technology interactions. The ability to recognize and analyze facial expressions is essential for sentiment analysis and other fields that require understanding a user’s emotions. Facial action detection technology allows for more interactions by recognizing and responding to facial emotions.This effectively reduces the communication gap between individuals and machines.
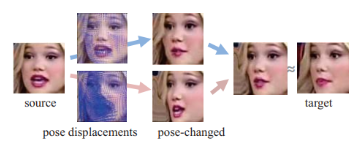
Fig 1. Illustration of Facial Pose Detection and Transformation
Visualizing the process helps when we talk about the usefulness of facial activity recognition in applications. A practical example of the change that facial action detection technology provides is shown in Figure 1. The technique starts with a source image and uses unique pose displacements that are applied to generate a target image with a changed posture. This procedure illustrates how capable these systems are in detecting, predicting, and modifying facial expressions, bringing up new possibilities for complex interactions between humans and machines. In applications that include sentiment analysis to current time responsive models in virtual worlds, the accuracy and flexibility shown here are essential.
Research Objective
Compare the effectiveness and possible applications of various facial motion detection methods with the aim of comparing their performance and application potential.
The main objective of this project is to evaluate and contrast different facial motion detection techniques in order to get further insight into their potential. We will dive into further detail about the obstacles of every approach in this project. Important factors including processing speed, accuracy of detection, and potential losses will also be evaluated. The technique may be applied to many different fields, mainly aim to aid in sentiment analysis. For example, Healthcare, the automated analysis of human emotions allows for early and accurate diagnosis of depression, anxiety, and other mental illnesses, or new forms of entertainment (like games, movies) that will adapt to your emotions. Others like educational technologies that can detect students’ emotional responses and personalize their learning experiences, improving engagement. Together, these applications show how AU Detection is not just a technical feat but a bridge to more empathetic and responsive technology. With this research, we are hoping for insight into the importance of facial action detection techniques, as well as their advantages and disadvantages, and provide a deeper understanding of the significance that each approach performs in certain applications.
Project Structure
Summarize the contents of the report, including discussion and comparative analysis of the three approaches.
In this project, we will be focused on the implementation and evaluation of three different facial motion detection methods: basic CNN model, Joint Attention Aware Network, and Method Based on ResNet50. First, we will cover the discussion of different approaches. The Basic CNN Model is the first model to be analyzed, along with its technical details, application cases, advantages and limitations. The Joint Attention Aware Network (JAA-Net) is then being analyzed in detail, similar to the process for CNN mode, emphasizing on its usefulness and layout in facial action detections and the utilization of attention procedures. After that, we will look at the ResNet50-Based Models, which focus on its architecture and how to enhance model performance by introducing graph attention mechanisms. Next, we will be looking at the comparison analysis, and how well each approach performs in terms of accuracy, speed in real time, and losses. Lastly, we will talk about the practical application of facial action detection. Our experimental design, result analysis, problems and possible solutions will also be discussed.
Overview of Facial Action Detection Techniques
Basic Principles
Brief introduction of the key concepts of facial action units and detection.
Facial Action Units (FAUs) are the basic concepts used to analyze and interpret a variety of emotions and facial movements. It also serves as the basis for comprehending human face expressions. The expression of emotions depends on the movement of a particular group of facial muscles, which corresponds to each FAU.
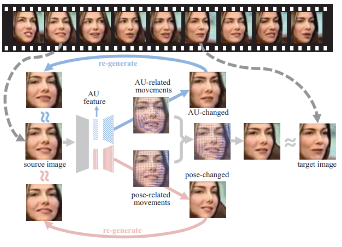
Fig 2. Facial Action Detection
A structured flowchart can help us see and comprehend the complex process of facial action recognition as we dive deeper into the details (see Figure 2). The flow chart illustrates how the source picture is transformed, with a focus on action unit (AU) detection and position adjustments, to create a target image that includes the detected face motions. Complex algorithms that analyze facial features and recognize patterns and changes related to various expressions are required to detect these action units. In fields like emotion identification, for example, this technique is essential because precisely localizing these units might improve our comprehension of human interactions and emotions. As technology develops, techniques for identifying these action units get more complex, utilizing sophisticated computer models to boost the precision and dependability of real-time analysis.
Technological Development
Overview of the evolution from early algorithms to current deep learning methods.
When we look at facial action detection technology from the very beginning until now, we can see that this technology has evolved significantly over time, moving from simple algorithms to complex deep learning techniques. At first, Paul Ekman and Wallace V. Friesen developed FACS in the 1970s even before computers, which only looked at facial muscle actions and descriptions. Then with the rise of computer vision, researchers began to explore its application in AU detection. First, the technique advanced with the development of machine learning methods such as Support Vector Machines (SVM). Then, the learning algorithms experienced a revolution with the development of CNNs. Its deep layers allowed for the direct learning of complicated facial expressions from large amounts of data. Then, JAA-Net provides a new approach that improves the model’s response to complicated emotions by integrating attention mechanisms. It focuses on relevant facial areas. Finally, ResNet50 improves the accuracy of facial motion detection by integrating Deep Residual Learning, which enables deeper network training without decreasing from gradient descent. All these techniques help the evolution of facial detection from a very simple algorithm to now with more complex, deep learning methods.
EAC-Net (CNN approach to Facial Action Unit detection)
Structure
The EAC-Net is a convolutional neural network (CNN) designed for Facial Action Unit (AU) detection, integrating enhancing and cropping features to focus on specific facial expressions. It is composed of three main components: a fine-tuned pre-trained VGG 19-layer network, enhancing layers (E-Net), and cropping layers (C-Net). This structure allows for detailed feature extraction and learning, tailored to the nuances of facial expressions and AU detection.
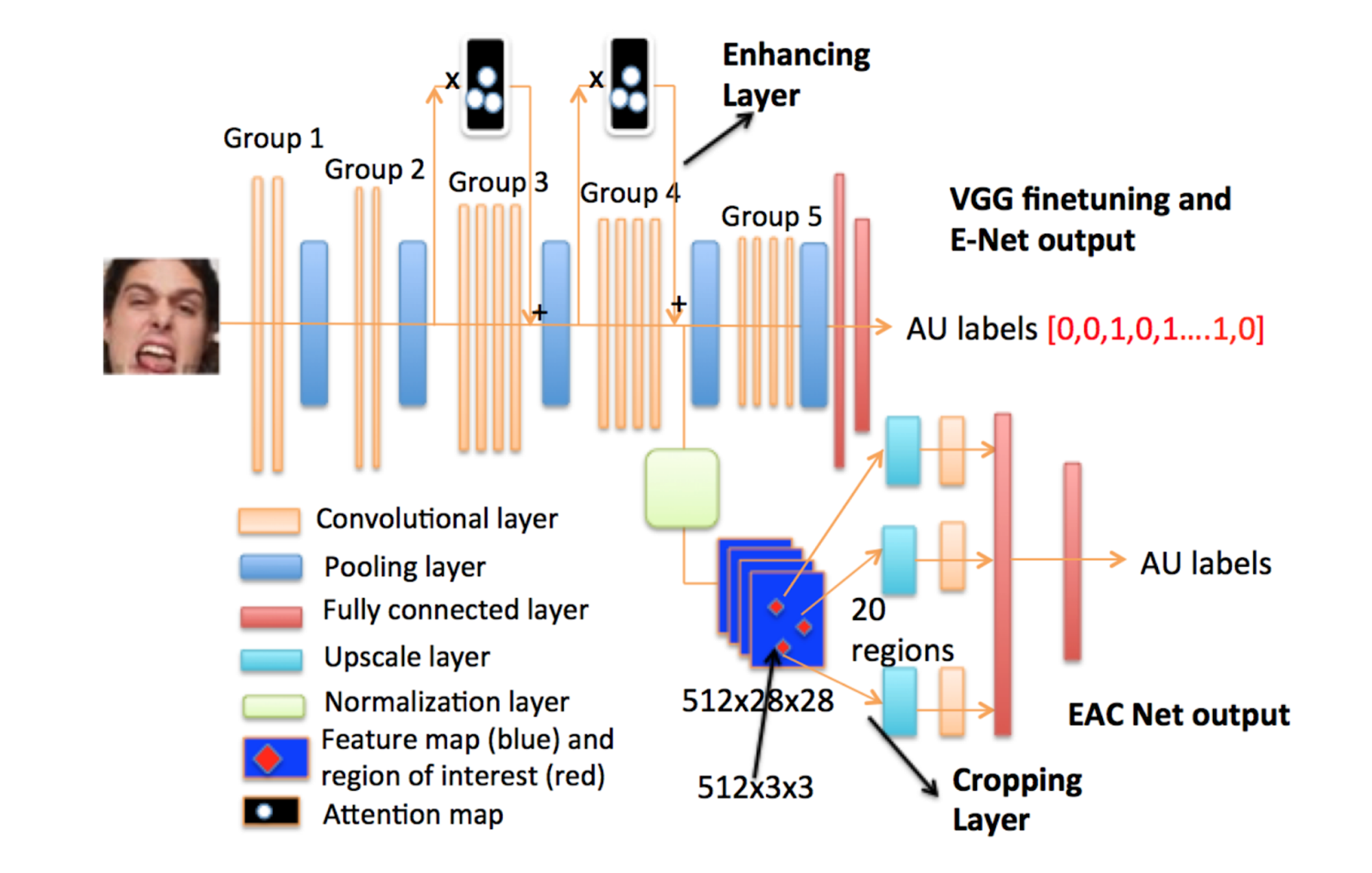
Fig 3. Architecture of EAC-Net [1].
Finetuning Network
The base of the EAC-Net utilizes a fine-tuned pre-trained VGG 19-layer network. The lower-level convolutional layers (groups 1 and 2) are retained with their original parameters for extracting basic visual features. In contrast, the parameters of the higher-level convolutional layers (groups 3 and 4) are fine-tuned specifically for AU detection. This approach ensures the network has a solid foundation in understanding the input images at both basic and complex levels.
E-Net
The enhancing layers, or E-Net, are added atop the high-level convolutional layers of the VGG network. These layers employ an attention map based on facial landmark features to enhance the learning process, focusing specifically on areas of interest related to AUs. The goal of the E-Net is to extract features with more valuable information for AU detection, drawing a parallel to the structure of Residual Net but with a focus on generating enhanced features.
C-Net
The cropping layers, known as C-Net, focus on precise facial regions by cropping sub-features from ten selected interest areas of the feature map. These areas then undergo further processing with upscale layers and convolutional layers to deepen the learning on each facial region. C-Net ensures the network pays attention only to relevant regions for AU detection, enabling deeper contextual understanding.
Loss Function
The loss function for EAC-Net is designed to handle the multi-label binary classification problem inherent in AU detection, where multiple AUs may be present simultaneously. It employs cross-entropy to measure loss, adjusted with constants to prevent excessively large values and stabilize training.
\[\text{Loss} = -\Sigma \left( l \cdot \log\left( \frac{p}{1.05} + 0.5 \right) + (1 - l) \cdot \log\left( \frac{1.05 - p}{1.05} \right) \right)\]\(l\) represents the label (1 for the presence of an AU and 0 for its absence), and \(p\) denotes the predicted probability for the AU’s presence. The constants 1.05 and 0.5 are used to adjust the loss function to prevent the loss values from becoming excessively large, thus stabilizing the training process.
Attention Map
The attention map is a critical component of the E-Net, designed to give more attention to individual AU areas of interest. It is generated based on the distance to the AU center, employing the Manhattan distance formula to calculate the weight of each pixel. This approach ensures that the enhancing layers focus more precisely on the areas of the face most relevant to AU detection, improving the accuracy and effectiveness of the EAC-Net.

Fig 4. Attention Map of EAC-Net [1].
Formula for calculating weight of each pixel: \(w = 1 - 0.095 \cdot d_m\)
\(d_m\) is the Manhattan distance to the AU center[1]
JAA-Net
JAA-Net, Joint learning and Adaptive Attention Network, presents an approach to facial analysis by integrating the tasks of facial action unit (AU) detection and face alignment. Through hierarchical and multi-scale region learning, adaptive attention mechanisms, and a novel local AU detection loss function, JAA-Net achieves state-of-the-art performance on benchmark datasets. By jointly optimizing these tasks, JAA-Net sets a new standard for accurate and robust facial expression analysis, offering a unified solution for real-world computer vision applications.
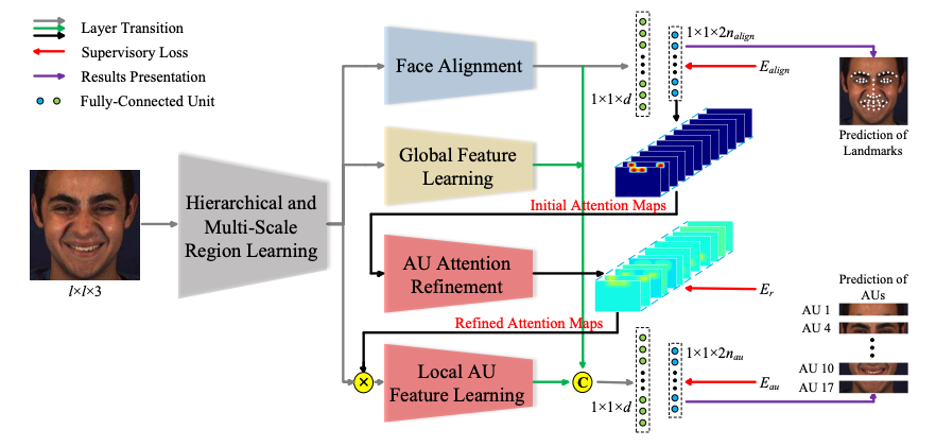
Fig 5. Architecture of JAA-Net [3].
Structure
JAA-Net is composed of several interconnected modules:
Hierarchical and Multi-Scale Region Learning
This module serves as the foundation of JAA-Net, extracting multi-scale features from local regions of varying sizes. It consists of plain convolutional layers and hierarchical partitioned convolutional layers, facilitating the extraction of hierarchical and multi-scale features essential for AU detection and face alignment.
Face Alignment Module
This component estimates facial landmarks, which are utilized to predefine the initial attention map for each AU. It comprises successive blocks for feature extraction, followed by max-pooling layers, ultimately generating a face alignment feature containing global facial shape and local landmark information. The loss supervises the face alignment module, ensuring accurate estimation of facial landmarks essential for subsequent stages of AU detection and alignment. The formula of the loss for this part is shown below:
\[E_{\text{align}} = \frac{1}{2d_0^2} \sum_{j=1}^{n\_{\text{align}}} \left( (y_{2j-1} - \hat{y}_{2j-1})^2 + (y_{2j} - \hat{y}_{2j})^2 \right)\]where:
- \(y_{2j-1}\) and \(y_{2j}\) denote the ground-truth x-coordinate and y-coordinate of the j-th facial landmark.
- \(\hat{y}_{2j-1}\) and \(\hat{y}_{2j}\) are the corresponding predicted results.
- \(d_0\) is the ground-truth inter-ocular distance for normalization.
Global Feature Learning
This module captures overall facial structure and texture information, providing crucial contextual information for AU detection. Its output, combined with the face alignment feature, contributes to the final AU detection process.
Adaptive Attention Learning
The core of AU detection in JAA-Net, this module refines the attention map of each AU adaptively to capture local AU features at different locations. It employs multiple branches, each refining the attention map for a specific AU under the supervision of local AU detection loss.
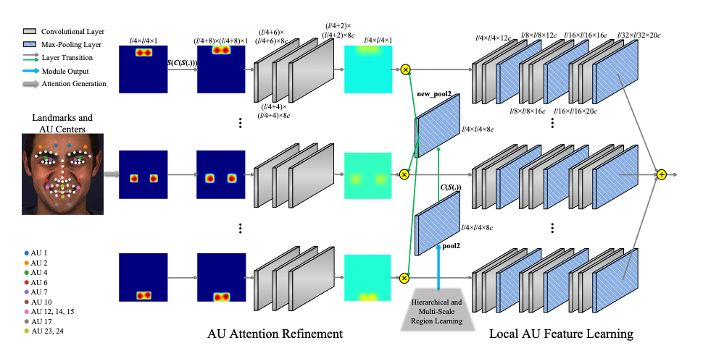
Fig 6. Architecture of JAA-Net Adaptive Attention Learning Module [3].
The loss essentially measures the sigmoid cross entropy between the refined attention maps and the initial attention maps, formula as shown below:
\[E_r = -\sum_{i=1}^{n_{au}} \sum_{k=1}^{n_{am}} \left[ v_{ik} \log \hat{v}_{ik} + (1 - v_{ik}) \log (1 - \hat{v}_{ik}) \right]\]where:
- \(\hat{v}_{ik}\) is the refined attention weight of the k-th point for the i-th AU.
- \(n_{am} = \frac{l}{4} \times \frac{l}{4}\) is the number of points in each attention map.
Facial AU Detection
In the final stage of JAA-Net, assembled local AU features are combined with the face alignment feature and the global feature. This amalgamation is then fed into a network comprising two fully-connected layers with dimensions of \(d\) and \(2n_{\text{au}}\), respectively. Subsequently, a softmax layer is employed to predict the probability of occurrence for each AU. This approach effectively addresses data imbalance issues commonly encountered in AU detection tasks, ensuring robust and accurate predictions across all AU classes. The formula of softmax loss is shown below:
\[E_{\text{softmax}} = -\frac{1}{n_{au}} \sum_{i=1}^{n_{au}} w_i \left[ p_i \log \hat{p}_i + (1 - p_i) \log (1 - \hat{p}_i) \right]\]where:
- \(p_i\) denotes the ground-truth probability of occurrence for the i-th AU, which is 1 if occurrence and 0 otherwise.
- \(\hat{p}_i\) denotes the corresponding predicted probability of occurrence.
In some cases, some AUs appear rarely in training samples, for which the softmax loss often makes the network prediction strongly biased towards absence. To overcome this limitation, a weighted multi-label Dice coefficient loss is introduced:
\[E_{\text{dice}} = \frac{1}{n_{au}} \sum_{i=1}^{n_{au}} w_i \left( 1 - \frac{2p_i\hat{p}_i + \varepsilon}{p_i^2 + \hat{p}_i^2 + \varepsilon} \right)\]where \(\varepsilon\) is the smooth term.
Loss Function
JAA-Net introduces a novel local AU detection loss, enhancing the refinement of attention maps to extract more precise local features. This loss function is more effective than traditional methods, as it directly supervises attention map refinement and removes constraints on attention map differences, facilitating adaptive learning of attention.
\[E = E_{au} + \lambda_1 E_{align} + \lambda_2 E_r\]where \(E_{au}\) and \(E_{align}\) denote the losses of AU detection and face alignment, respectively, \(E_r\) measures the difference before and after the attention refinement, which is a constraint to maintain the consistency, and \(\lambda_1\) and \(\lambda_2\) are trade-off parameters.
Advantage
JAA-Net offers several advantages:
- Significantly outperforms state-of-the-art AU detection methods on challenging benchmarks, including BP4D, DISFA, GFT, and BP4D+.
- Adaptsively captures irregular regions of each AU, enhancing the accuracy of AU detection.
- Achieves competitive performance for face alignment, ensuring accurate localization of facial landmarks.
- Works well under partial occlusions and non-frontal poses, demonstrating robustness in real-world scenarios.[3]
ResNet-50
ResNet-50 has been utilized for the task of AU detection. Researchers from Shenzhen University had done a study presenting an approach utilizing ResNet-50 to encode AU activation status and associations into node features. The model learns multi-dimensional edge features to capture complex relationship cues between AUs, considering the facial display’s influence on AU relationships. The approach achieves state-of-the-art results, with an average F1 score of 64.7 on the BP4D dataset and 63.1 on the DISFA dataset.
Structure
The model involves a two main modules:
- AUs Relationship-aware Node Feature Learning (ANFL): This module learns a representation for each AU from the input full face representation. It encodes not only the AU’s activation status but also its association with other AUs1. The module consists of a AU-specific Feature Generator (AFG): that generates a representation for each AU and a facial Graph Generator (FGG) that designs an optimal graph for each facial display, enforcing the AFG to encode task-specific associations among AUs into their representations.
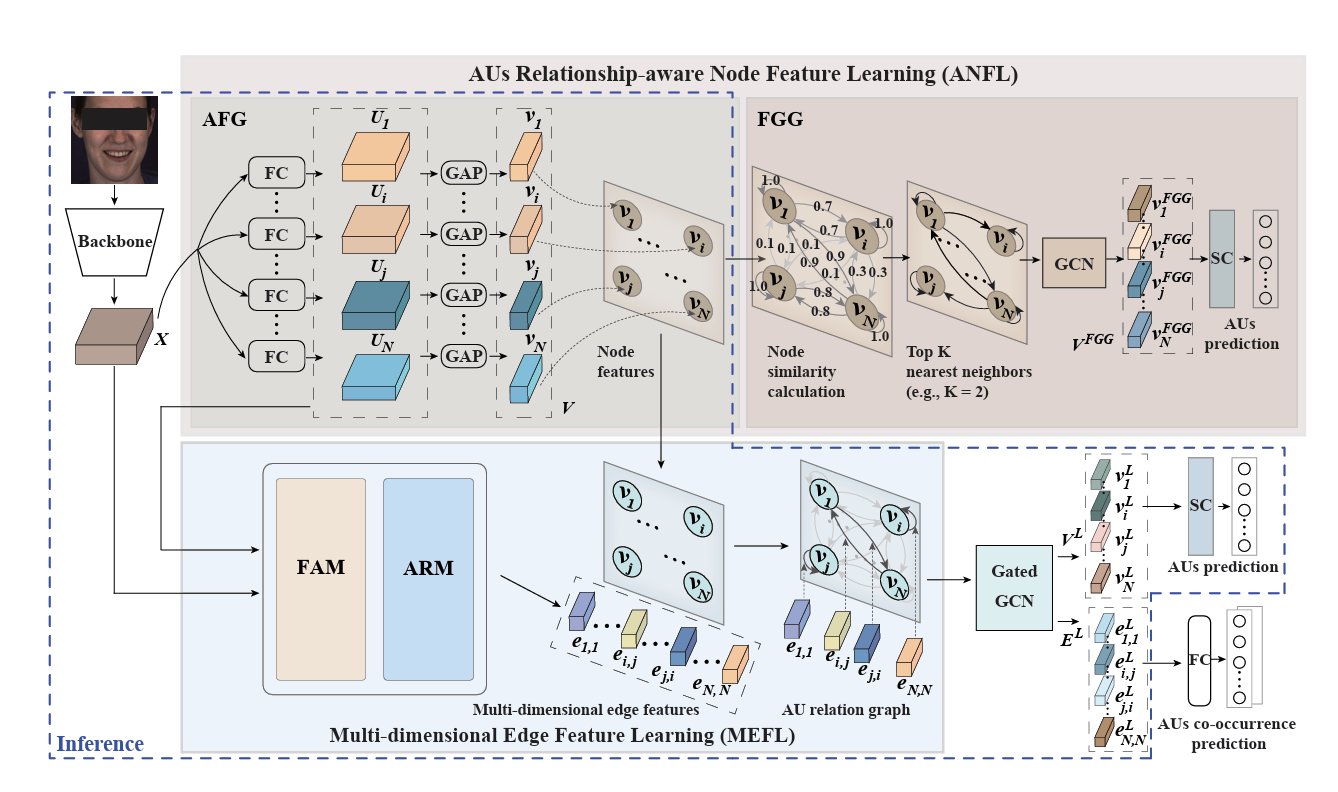
Fig 7. Structure of ANFL [2].
- Multi-dimensional Edge Feature Learning (MEFL): This module learns multiple task-specific relationship cues as the edge representation for each pair of AUs2. It considers both connected and un-connected node pairs defined in the ANFL module. The module also has two main components:Facial display-specific AU representation modelling (FAM) which locates activation cues of each AU from the full face representation, and AU relationship modelling (ARM) which extracts features related to both AUs’ activation, producing multi-dimensional edge features.
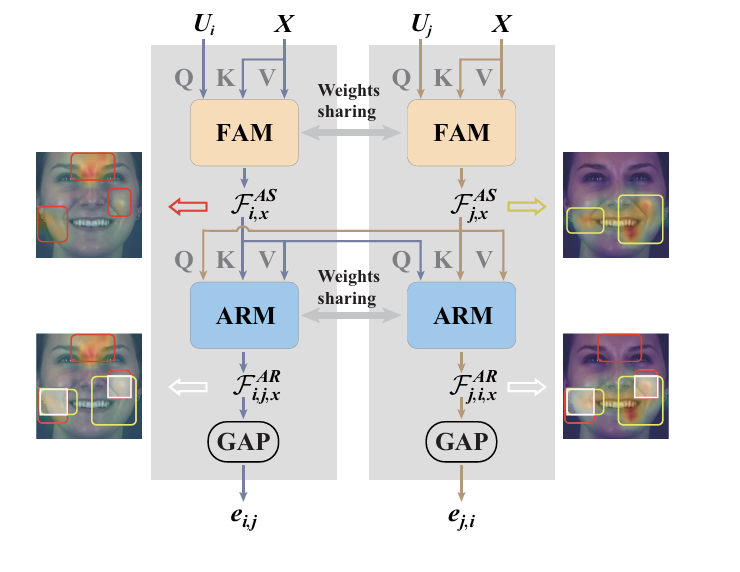
Fig 8. Structure of MEFL [2].
ResNet-50 is used as one of the backbones for the model. It provides the initial full face representation, which is then processed by the ANFL module to generate node features. These features are further utilized by the MEFL module to learn the multi-dimensional edge features, enhancing the AU recognition performance. The model achieves state-of-the-art results on two widely used datasets for AU recognition.
Losses
Two types of losses are used in this model, Weighted Asymmetric Loss and Categorical Cross-Entropy Loss. The former is designed to alleviate data imbalance issues by assigning unique weights to each subtask (each AU’s recognition) based on the AU’s occurrence rate in the training set. The latter is employed to supervise the training process by leveraging the AUs co-occurrence patterns. It is used in conjunction with the multi-dimensional edge features generated from the last GatedGCN layer to predict the co-occurrence pattern of AUs. The formulation of losses are show below:
\[L_E = -\frac{1}{|E|} \sum_{i=1}^{|E|} \sum_{j=1}^{N_E} y_{i,j}^e \log\left(\frac{e^{p_{i,j}^e}}{\sum_k e^{p_{i,k}^e}}\right)\]where:
- \(E\) denotes the number of edges in the facial graph.
- \(N_E\) is the number of co-occurrence patterns.
- \(p_{i,j}\) is the co-occurrence prediction output from the shared fully connected layer.
where:
- \(p_i\) is the prediction (occurrence probability) for the \(i^{th}\) AU.
- \(y_i\) is the ground truth for the \(i^{th}\) AU.
- \(w_i\) is the weight of the \(i^{th}\) AU.
The total loss is calculated as the sum of \(L_{WA}\) and \(L_E\).
Performance
The reported results are shown below:
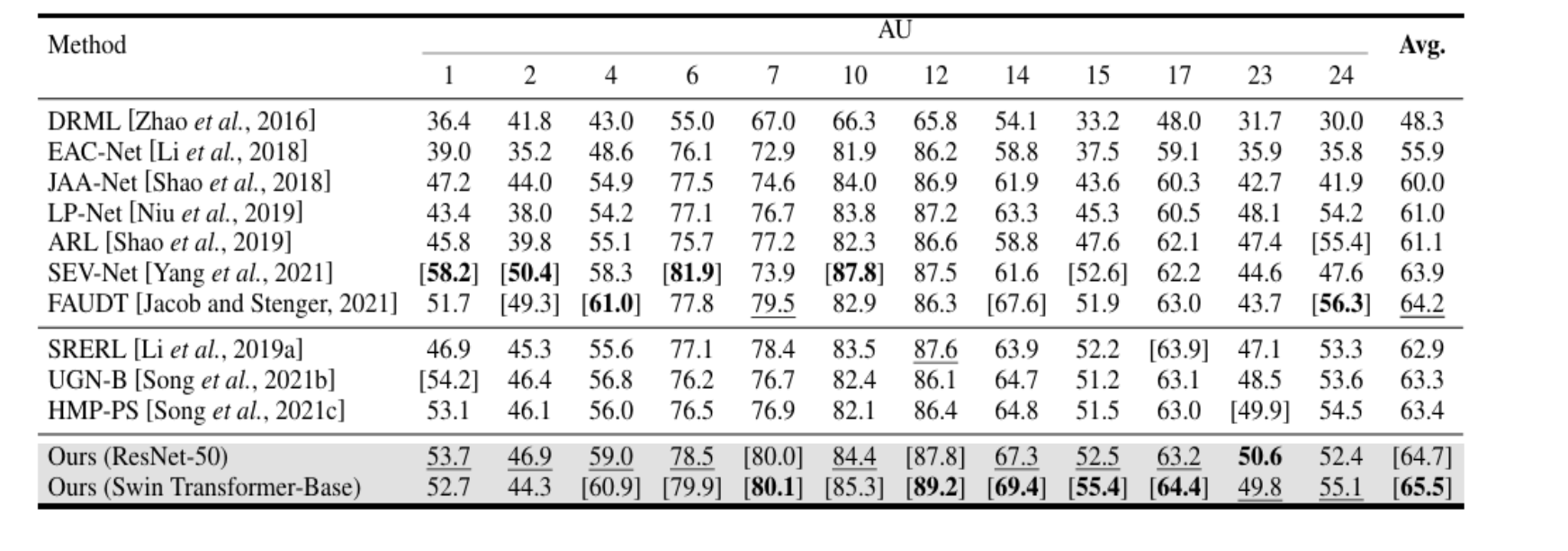
Table 1. ResNet-50 results [2].
The model outperforms both JAA-Net and ResNet-50, which is not surprising since ResNet is only utilized as a backbone structure and the model is new with more sophisticated structure.[2]
Experiments
We attempted to train a model using JAA-Net that is public on BP4D dataset. With limited resources, we had to scale down the dataset, but we were successful to train JAA-Net and obtained its performance metrics. The code, trained models (12 in total, with each being a snapshot after a epoch), and attention heatmaps can be found in this repository: GitHub Repository
Dataset
We were able to obtain a subset of BP4D dataset.BP4D-Spontaneous dataset is a database of videos of facial expressions in a group of young adults. The participants in the video clips are around 18-29 years of age from various ethnicity backgrounds. The expressions they displayed in these videos are induced from natural stimulus. Facial features are tracked in both 2D and 3D domains. The entire dataset is about 2.6TB in size. We utilized the metadata associated with AU activation and facial landmark information included with the dataset. [4] The sub-dataset we use contains 125884 images sampled from frames of videos, and ground truth labels of the presence of 12 AU labels and facial landmarks. The dataset we obtained was missing AU activation labels and facial landmark information for some pictures, causing a mismatch between images and labels. This issue was discovered during training when the model displayed low loss but low accuracy during testing with new images. Because of lack of knowledge to properly label these images, we determined to exclude them from the dataset. The final dataset used contained 83924 images for training and 45809 images for testing. Training was done locally on a laptop with a RTX 3070Ti as it requires a large amount of memory and time, and it was not realistic to do on a Google Cloud VM with the few credits that were available. Because of limited resources, training set was kept small compared to the test set.
Methods And Results
Some minor modifications to the code base was required to work with our specific dataset, but nothing with JAA-Net’s structure were changed. During the preprocessing step, similarity transformation is conducted on each image, cropping every image around the face.
def align_face_49pts(img, img_land, box_enlarge, img_size):
leftEye0 = (img_land[2 * 19] + img_land[2 * 20] + img_land[2 * 21] + img_land[2 * 22] + img_land[2 * 23] +
img_land[2 * 24]) / 6.0
leftEye1 = (img_land[2 * 19 + 1] + img_land[2 * 20 + 1] + img_land[2 * 21 + 1] + img_land[2 * 22 + 1] +
img_land[2 * 23 + 1] + img_land[2 * 24 + 1]) / 6.0
rightEye0 = (img_land[2 * 25] + img_land[2 * 26] + img_land[2 * 27] + img_land[2 * 28] + img_land[2 * 29] +
img_land[2 * 30]) / 6.0
rightEye1 = (img_land[2 * 25 + 1] + img_land[2 * 26 + 1] + img_land[2 * 27 + 1] + img_land[2 * 28 + 1] +
img_land[2 * 29 + 1] + img_land[2 * 30 + 1]) / 6.0
deltaX = (rightEye0 - leftEye0)
deltaY = (rightEye1 - leftEye1)
l = math.sqrt(deltaX * deltaX + deltaY * deltaY)
sinVal = deltaY / l
cosVal = deltaX / l
mat1 = np.mat([[cosVal, sinVal, 0], [-sinVal, cosVal, 0], [0, 0, 1]])
mat2 = np.mat([[leftEye0, leftEye1, 1], [rightEye0, rightEye1, 1], [img_land[2 * 13], img_land[2 * 13 + 1], 1],
[img_land[2 * 31], img_land[2 * 31 + 1], 1], [img_land[2 * 37], img_land[2 * 37 + 1], 1]])
mat2 = (mat1 * mat2.T).T
cx = float((max(mat2[:, 0]) + min(mat2[:, 0]))) * 0.5
cy = float((max(mat2[:, 1]) + min(mat2[:, 1]))) * 0.5
if (float(max(mat2[:, 0]) - min(mat2[:, 0])) > float(max(mat2[:, 1]) - min(mat2[:, 1]))):
halfSize = 0.5 * box_enlarge * float((max(mat2[:, 0]) - min(mat2[:, 0])))
else:
halfSize = 0.5 * box_enlarge * float((max(mat2[:, 1]) - min(mat2[:, 1])))
scale = (img_size - 1) / 2.0 / halfSize
mat3 = np.mat([[scale, 0, scale * (halfSize - cx)], [0, scale, scale * (halfSize - cy)], [0, 0, 1]])
mat = mat3 * mat1
aligned_img = cv2.warpAffine(img, mat[0:2, :], (img_size, img_size), cv2.INTER_LINEAR, borderValue=(128, 128, 128))
land_3d = np.ones((int(len(img_land)/2), 3))
land_3d[:, 0:2] = np.reshape(np.array(img_land), (int(len(img_land)/2), 2))
mat_land_3d = np.mat(land_3d)
new_land = np.array((mat * mat_land_3d.T).T)
new_land = np.reshape(new_land[:, 0:2], len(img_land))
return aligned_img, new_land
Then interocular distances of each sample and weight loss of each AU for the training set is calculated.
# interocular distances
import numpy as np
list_path_prefix = '../data/list/'
input_land = np.loadtxt(list_path_prefix+'BP4D_att2_land.txt')
biocular = np.zeros(input_land.shape[0])
l_ocular_x = np.mean(input_land[:,np.arange(2*20-2,2*25,2)],1)
l_ocular_y = np.mean(input_land[:,np.arange(2*20-1,2*25,2)],1)
r_ocular_x = np.mean(input_land[:,np.arange(2*26-2,2*31,2)],1)
r_ocular_y = np.mean(input_land[:,np.arange(2*26-1,2*31,2)],1)
biocular = (l_ocular_x - r_ocular_x) ** 2 + (l_ocular_y - r_ocular_y) ** 2
np.savetxt(list_path_prefix+'BP4D_att2_biocular.txt', biocular, fmt='%f', delimiter='\t')
# weight loss for each AU
import numpy as np
list_path_prefix = '../data/list/'
imgs_AUoccur = np.loadtxt(list_path_prefix + 'BP4D_att2_AUoccur.txt')
AUoccur_rate = np.zeros((1, imgs_AUoccur.shape[1]))
for i in range(imgs_AUoccur.shape[1]):
AUoccur_rate[0, i] = sum(imgs_AUoccur[:,i]>0) / float(imgs_AUoccur.shape[0])
AU_weight = 1.0 / (AUoccur_rate+1)
AU_weight = AU_weight / AU_weight.sum() * AU_weight.shape[1]
np.savetxt(list_path_prefix+'BP4D_att2_weight.txt', AU_weight, fmt='%f', delimiter='\t')
The model was trained on the training set (processed image) for 12 epochs with learning rate originally set at 0.00007 for first that 0.000096 and decays down to 0.000024. Training took more than 50 hours, which underscores a significant drawback of this model: it requires a lot of resources and time to train. This is an older model using CNN and attention mechanisms, and they can be difficult to train.
The model was then tested on the test set, which yielded the following results:
| Epoch | F1 Score Mean | Accuracy Mean | Mean Error | Failure Rate |
|---|---|---|---|---|
| 1 | 0.521639 | 0.709132 | 0.046760 | 0.003956 |
| 2 | 0.527294 | 0.775433 | 0.044694 | 0.002002 |
| 3 | 0.534872 | 0.783711 | 0.040380 | 0.000715 |
| 4 | 0.534648 | 0.787174 | 0.040828 | 0.000763 |
| 5 | 0.541575 | 0.761680 | 0.040338 | 0.000643 |
| 6 | 0.556645 | 0.776259 | 0.040349 | 0.000667 |
| 7 | 0.555009 | 0.770363 | 0.040505 | 0.000620 |
| 8 | 0.553778 | 0.764504 | 0.040265 | 0.000596 |
| 9 | 0.551945 | 0.760742 | 0.039970 | 0.000572 |
| 10 | 0.549276 | 0.764444 | 0.040630 | 0.000596 |
| 11 | 0.550392 | 0.764053 | 0.040060 | 0.000596 |
| 12 | 0.552339 | 0.767260 | 0.039748 | 0.000620 |
Table 2. Results from JAA-Net
As can be seen from the table, JAA-Net is relatively reliable, with low failure rate. Overall, we see that F1 score shows a gradual increase, but the increase is not significant, signaling that learning rate can be tuned further to improve performance. Mean error also decreased, hovering around 0.04 range, indicating the consistency in model’s prediction errors. There are two interesting patterns that can be observed from these results:
- Accuracy fluctuation: The accuracy very quickly increases and reaches its peak at the 4th epoch and suddenly drops, then fluctuates around 76%. We theorizes that this fluctuation is caused by model maybe overfitting to the training data, which may be fixed through further optimization to the learning rate. Because we had to divide the dataset to reduce training time, it may have decreased diversity among images, with some images of some individuals from different ethnical backgrounds and with very different facial features excluded from the training set. This may cause the model to overfit on certain features.
- Difference between F1 score and accuracy: There is a large gap between F1 score and accuracy, indicating that the model performs well on majority class but struggles with minority class. This model is clearly biased towards predicting certain AUs more than others, which can be a result from the dataset being imbalanced and not necessarily a problem with the model itself. The results closely match the results reported by the researchers that created JAA-Net. Interestingly, our F1 score is higher than the reported 44%, which can indicate that maybe certain individuals in the dataset have tendencies to activate certain AUs which caused class imbalance in the dataset. Our accuracy is understandably lower than the reported 87%, which is understandable as our dataset is reduced and is not as diverse as the dataset they used to train the model.
Attention Heatmaps
Using the attention mechanism in the model, we generated heatmaps from some of the samples in the test dataset. Unfortunately, because JAA-Net requires facial landmark information to function properly, and we lack the technical knowledge to provide a labeled sample, we could only test the model on existing data in the BP4D dataset. The results show the model is clearly focusing on the correct regions of facial activation units.



 Fig 9. Attention Heatmaps Generated By JAA-Net for AU-02 and AU-07
Fig 9. Attention Heatmaps Generated By JAA-Net for AU-02 and AU-07
Future Improvements And General Discussion
As discussed before, the dataset was significantly reduced, and the partition of data can ideally be mixed better through shuffling of the images to include more varying faces at the cost of fewer examples for certain expressions for some individuals. Of course, ideally the training set should be much bigger than what we used for this experiment, and learning rate definitely requires some tuning, and the number of epochs can be cut down before overfitting occurs. We also would like to have taken our own pictures and tested model’s performance in a more realistic environment, with background noise in the pictures instead of a clean and controlled background that is in BP4D dataset.
Nonetheless, the results from JAA-Net is impressive, especially for an older model. The model was performing better than many other models at the time, proving that features learned during facial alignment can in fact provide non-negligible benefits for the task of detecting facial action units.
References
[1] Li, W., Abtahi, F., Zhu, Z., & Yin, L. (2017, May). Eac-net: A region-based deep enhancing and cropping approach for facial action unit detection. In 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017) (pp. 103-110). IEEE.
[2] Luo, C., Song, S., Xie, W., Shen, L., & Gunes, H. (2022, July). Learning Multi-dimensional Edge Feature-based AU Relation Graph for Facial Action Unit Recognition. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization.
[3] Shao, Z., Liu, Z., Cai, J., & Ma, L. (2020, September). Deep Adaptive Attention for Joint Facial Action Unit Detection and Face Alignment. In European Conference on Computer Vision (pp. 725-740). Springer.
[4] Yin, L., Wei, X., Sun, Y., Wang, J., & Rosato, M. J. (2006, April). A 3D Facial Expression Database For Facial Behavior Research. In 7th International Conference on Automatic Face and Gesture Recognition (pp. 211-216)1. IEEE.
[5] Li, Y., Zeng, J., Shan, S., & Chen, X. (2019). Self-supervised Representation Learning from Videos for Facial Action Unit Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).