UCLA Human Pose Estimation + Trajectory Prediction for AVs
This report explores the topic of Human Pose Estimation - specifically its history, approaches, and application to the realm of Autonomous Driving. We talk in depth about some of the overarching approaches that are taken when tackling HPE and then we go in depth on some exciting developments in the space. We also connect our research to work done in Trajectory Prediction, also with a focus on autonomous driving.
- Introduction
- Deep Pose
- Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving
- Trajectory Prediction
- Limitations, Possible Improvements
- Discussion
- References
Introduction
Human Pose Estimation (HPE) is a computer vision task that aims to locate body joints, such as the head, knees, wrists, etc in an image or video frame. The goal is to connect these joints to form a skeleton shape. Building on top of HPE is trajectory prediction where the idea is to identify an object and its pose, and then from there understand the surroundings estimating the direction and trajectory of the object. Building on top of trajectory prediction is Autonomous Driving which allows vehicles to navigate and operate without human intervention. This report highlights key approaches that evolved HPE into Autonomous Driving.
Deep Pose
Intro
Deep Pose was one of the first applications of deep learning to the field of Human Pose Estimation in 2013. It used an architecture that was heavily influenced by the work of Krizhevsky et al. in their ImageNet Classification with Deep Convolutional Neural Networks, and also used a novel approach of applying a cascade of learned models to refine its estimates.
Method
The Deep Pose model took as input images of people paired with a ground truth pose vector that specified the locations of joints of the joints of the person’s body. The joint coordinates were normalized with respect to a bounding box that enclose either the entire body or part of it. The model was trained on this data and used the L2 distance between the predicted and true joint coordinates as its minimization objective.
Model

Fig 1. The multi-staged approach that iteratively refines the initial prediction by utilizing the same network on cropped sections of the original image to provide higher resolution.
Deep Pose is a Convolutional Neural Network that contains 7 layers that hold learnable parameters, separated by ReLU nonlinearities, Local Response Normalization, and Pooling:
Convolution (55 × 55 × 96) − Local Response Normalization − Pooling − Convolution (27 × 27 × 256) − Local Response Normalization − Pooling − Convolution (13 × 13 × 384) − Convolution (13 × 13 × 384) − Convolution (13 × 13 × 256) − Pooling − Fully Connected (4096) − Fully Connected (4096)
The first two Convolutions have a filter size of 11 × 11 and 5 × 5, while the rest have a filter size of 3 × 3. In total the model contains around 40M parameters.
Training
The training process of Deep Pose starts with data augmentation of the input images to get a more robust training set. It implements crops, translations, flips, and so on in order to achieve this. It uses the L2 distance between the normalized predicted pose and the normalized coordinates of the ground truth pose vector and uses a mini-batch size of 128 and a learning rate of 0.0005.
The first stage involves inputting the entire image into the model which has an input dimension of (220 × 220). Because of this compression, the network is only able to output a rough estimate of the joint positions, so the creators of Deep Pose decided to follow the initial estimation with a series of networks that worked to refine the initial prediction. These following stages use the same network architecture but take in a higher resolution portion of the image that contains the joint that the network is seeking to evaluate. Each subsequent stage predicts a displacement of the predicted joint coordinate to the ground truth joint location, therefore iteratively refining its prediction.

Fig 2. The progression of the predictions of joint positions across multiple stages. With each stage, the joint approaches the ground truth position.
Results
Deep Pose achieved impressive results compared to previous approaches to the problem of Human Pose Estimation. It was evaluated in comparison to other models on the metrics of Percentage of Correct Joints which measures the detection rate of limbs, and was proven to be very notably effective at detecting elbow and wrist positions. The cascade of pose regressors proved to be an effective method, and Deep Pose proved that it was possible to learn the necessary information to detect human joints from data rather than hand craft feature representations and detectors for these parts. This model was what set the stage for the future of deep learning applications of Human Pose Estimation.
Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving
Intro
10 years after the introduction of Deep Pose, the space of Human Pose Estimation has advanced, and in the process, it has begun to find applications in areas of technology including Autonomous Driving. Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving was released in 2023, and it presented one such application.
Human Pose Estimation in the context of Autonomous Driving is different from the problem that Deep Pose attempted to address in a few ways. First, vehicles operate in 3 dimensional space, so it is important for HPE models to be able to provide 3D information about the human position. Additionally, many autonomous vehicles are equipped with other sensors like LiDAR, which provide an additional source of information to make predictions off of. Finally, the data that exists in this space is sparse. Images of outdoor scenarios are harder to train with and even annotate with ground truth labels. Currently available LiDAR data also tends to lack 3D keypoint labels, which makes designing a supervised learning process with the available data challenging.
Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving proposes a novel method of fusing the information extracted from RGB images and LiDAR point clouds to obtain a 3D Human Pose Estimation in a weakly supervised training process that leverages existing 2D HPE models.
Method
There are two approaches specified in this paper: Supervised and Weakly Supervised.
In the supervised approach, the 3D ground truth labels are available. The Supervised Model consists of a Point Cloud Regression model and a Keypoint Lifting model. The LiDAR information is fed into the Point Cloud model and the image is used as the input to the Keypoint Lifting network. The results of these two networks are fused and used to provide a prediction that is compared to the ground truth label for training.
In the weakly supervised approach, keypoint labels of the LiDAR point cloud are not provided, which makes this the more interesting approach for the application of Autonomous Driving because of the issues described above. In this approach, the 2D keypoint information that is inferred from the image input is combined with the point cloud information to produce “pseudo-labels” that are used in the place of the ground truth labels in training.
The pseudo labels are created by projecting the point cloud from the LiDAR data onto the 2D image and taking the weighted sum of the points that are closest to the joint in question. The weight of each point in the point cloud is defined as the exponential of the negative squared distance between each LiDAR point and the average point among the set of LiDAR points near the kth joint. This effectively prioritizes points that are closer to the centroid of the point cluster in creating the pseudo label.
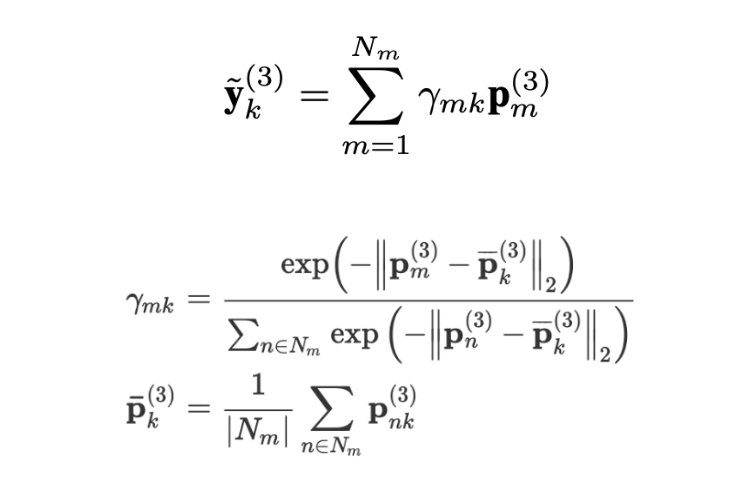
Figure 3.Relevant equations to the pseudo-label generation process.
Model
Both the Supervised and Weakly Supervised approaches leveraged existing and proven architectures in order to achieve their end result. They used the work of Martinez et al. in A simple yet effective baseline for 3d human pose estimation to design their keypoint lifting model which consisted of dense layers with dropout, RELU-activation, and residual connections. They also used PointNet, a model by Qi et al. to perform the regression on the LiDAR point cloud. The outputs of these models were combined and the prediction was made based on how the two model’s outputs were weighted.
Training
The Supervised Method followed a classic supervised learning structure. First, the data was prepared by cleaning and normalizing it to parameters that were shown to work well. Because of the need for accurate 3D keypoint labels in the supervised approach, much of the test set had to be removed.
The LiDAR data was fed through the Point Network, and the image was given to the off the shelf model which identified and lifted the key points into 3D space. These two results were combined and trained using the distance between the predicted joint positions and the ground truth labels.
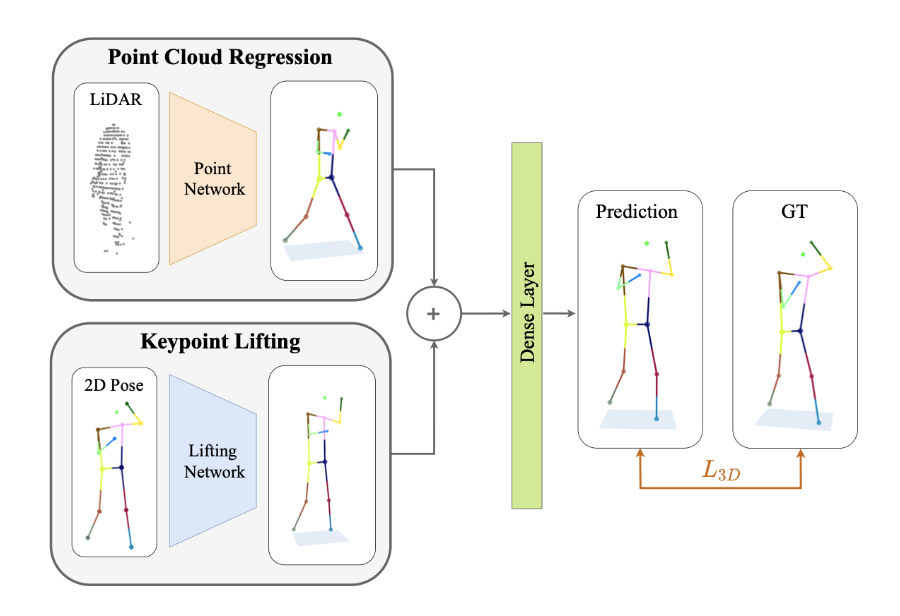
Figure 4. Supervised Approach.
The more interesting case was of the Weakly Supervised method. Because this method does not require the 3D ground truth labels, it is able to use much more of the available data as long as the LiDAR point cloud is accurate and robust enough. In this model, the images are fed into an off the shelf 2D HPE model which predicts the 2D keypoint positions of the photographed person. This 2D estimation is fed into the lifting network and combined with the result of the point network like in the supervised method. However, the 2D keypoints are also overlaid with the point cloud and the pseudo labels are generated as described previously. These pseudo labels are used in place of the ground truth labels, and the model can be trained to minimize the distance between the predicted outputs and these labels. In the training process, an Adam optimizer was used alongside exponential learning rate decay, and the lifting and the point cloud branch were trained in parallel.
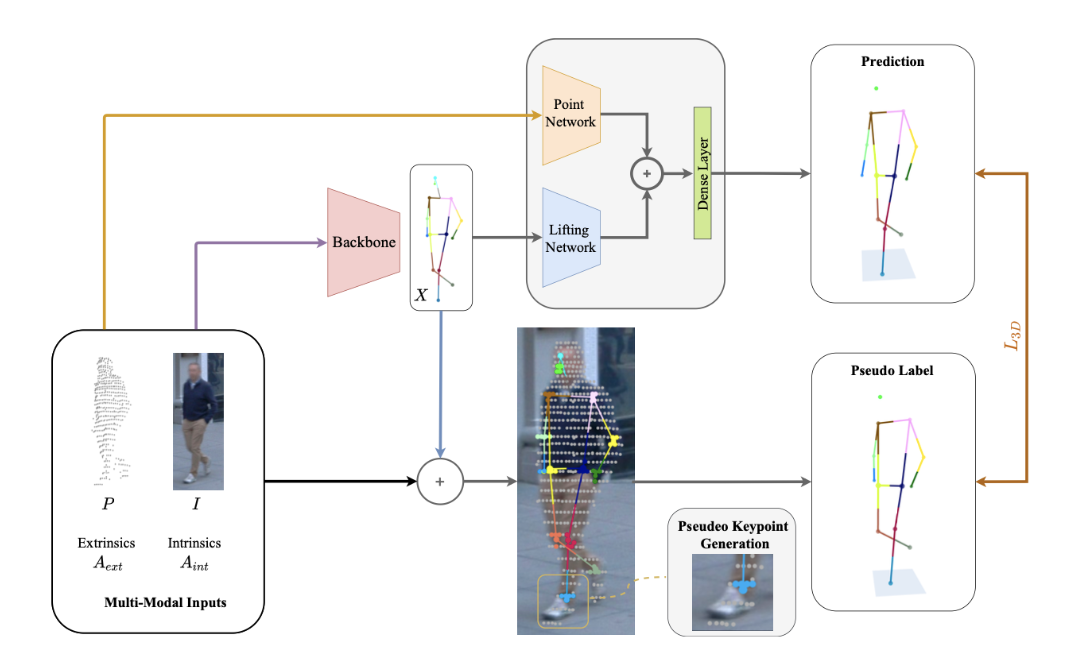
Figure 5. Weakly Supervised Approach.
Results
The results of this method of fusing LiDAR and image data are impressive and optimistic. The keypoint lifting network on its own showed issues determining orientation and size, while the point network alone struggled identifying joints that were held close to the body. Combining the information from these two sources and using the methods described above resulted in generally improved predictions. The weakly supervised approach of producing pseudo labels from this combination of sources was also validated and proven to be effective. Generating these labels enabled the model to be trained on data that may have had poor or no 3D keypoint labels, resulting in a more well rounded model. This fusion model performed around 31% better than the keypoint network and 24% better than the point network, and the pseudo label generation strategy outperformed other methods by 2.78 centimeters (∼ 23%) on the test dataset.

Figure 6. Qualitative Result Comparisons between the different networks.
Trajectory Prediction
Trajectory Prediction is a step past Human Pose Estimation. The idea behind it is to be able to first recognize a human and their current pose (HPE) and then from there understand the surroundings and estimate the direction and trajectory of the Human, Vehicle, Animal, etc.
Trajectory prediction plays a crucial role in Autonomous Driving because it increases the safety and efficiency of autonomous vehicles. Autonomous vehicles supplemented with trajectory prediction are better able to understand the interactivity of its environment, enhancing safety. Self-Aware Trajectory Prediction for Safe Autonomous Driving by Wenbo Shao, Jun Li, and Hong Wang introduced a self-aware trajectory prediction framework aimed at enhancing the safety and reliability of Autonomous Driving systems in 2023.
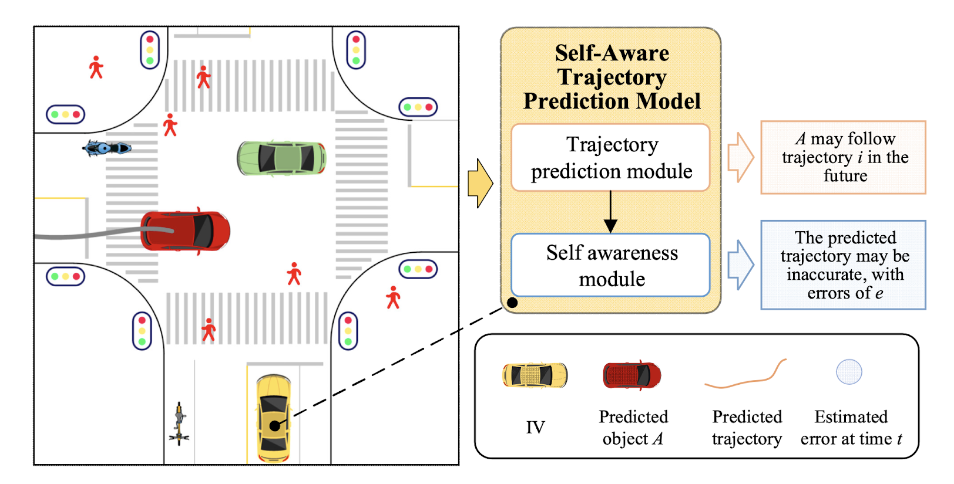
Figure 7. Self-awareness and trajectory prediction in context of autonomous vehicles. Endowing the trajectory prediction model with self-awareness.
The paper introduces a self-awareness module that evaluates the performance of the trajectory prediction in real time. This module enables the system to identify and react to potential failures in trajectory prediction making it useful for preventing accidents and safe navigation. The framework includes a two-stage training process that optimizes the self-awareness module consisting of a Graph Convolutional Model and a Trajectory Prediction model. This separation of concerns ensures that the introduction of the self-awareness module does not degrade the original trajectory prediction performance. Extensive experiments demonstrate the proposed method’s effectiveness in terms of self-awareness, memory usage, and real-time performance, making it a promising approach for safe Autonomous Driving. The module’s ability to self-diagnose and address prediction inaccuracies in real-time position it as an important development for improving safety and reliability.
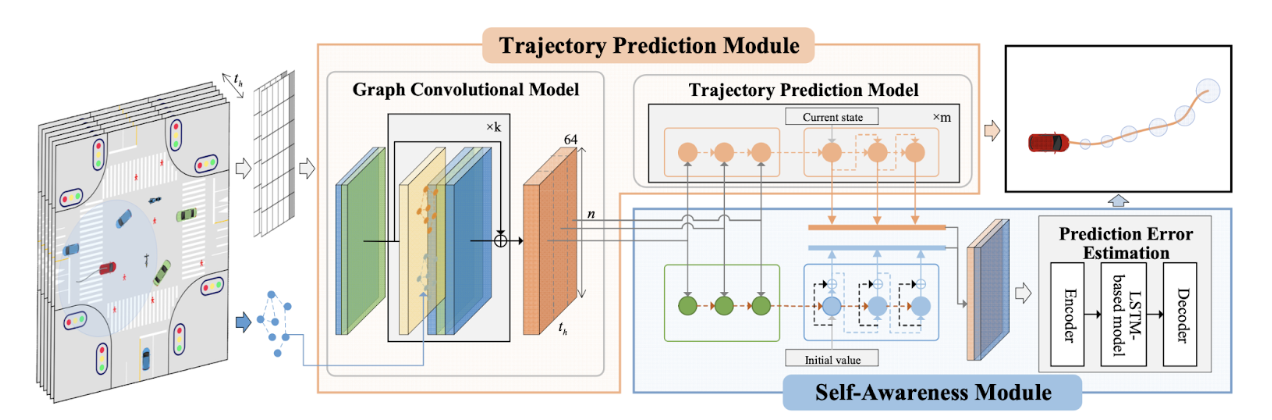
Figure 8. Proposed method in Self-Aware Trajectory Prediction for Safe Autonomous Driving.
Limitations, Possible Improvements
Although there have been some successful applications of HPE for autonomous vehicles as highlighted in Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving and Self-Aware Trajectory Prediction for Safe Autonomous Driving, there are still limitations to the proposed approaches.
In Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving, Bauer and the group faced several limitations inherent to the challenges of 3D HPE in outdoor scenarios. First, accurate annotations of 3D poses in outdoor, uncontrolled environments was time-consuming and costly, making it difficult to obtain high-quality ground truth data for training and evaluation. The researchers also had to deal with the unpredictability of human poses/movement in real-world settings, as well as the potential occlusions and varied lighting conditions that could affect sensor readings.
Another limitation was related to the use of LiDAR and camera data for pose estimation. Making inferences on 3D poses from the sparse and sometimes noisy data LiDAR’s produced posed significant challenges. The paper attempts to solve this by proposing a novel method that fuses data from these two sensor types but the reliance on accurate LiDAR-to-image projections for training the model introduces another potential source of error, especially if the sensor calibrations are not precise. Furthermore, the paper also highlights the difficulty of projecting LiDAR points onto 2D images accurately, which is a crucial step in their weakly supervised learning approach.
In Autonomous Driving and Self-Aware Trajectory Prediction for Safe Autonomous Driving, Shao and his group also ran into limitations with their approach. First, their module’s ability to generalize well across diverse driving conditions, especially those not well-represented in the training data, could cause issues to arise. The module was also dependent on the accuracy of error labels.
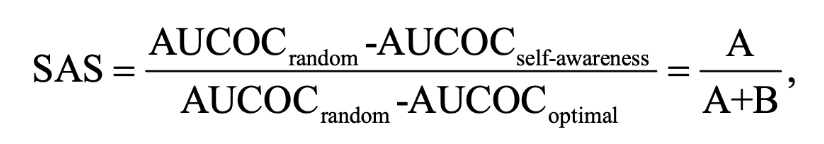
Figure 9. Self-awareness score used to compare different self-awareness modules separately and adjust error labels.
The paper also acknowledged that real-time performance with computation constraints and its innovative two-stage training process, could introduce problems in scenarios where the trajectory prediction model is updated or retrained with new data.
Common limitations in the field of HPE include adaptability to 3D space, accurate annotations / training data, and handling of noisy data. Although these papers address some of these issues, more problems arise highlighting the challenges of extending 3D HPE methods to the autonomous vehicles context. The interconnected fields of HPE, Trajectory Projection, and autonomous vehicles is still growing. Possible improvements to address the limitations previously mentioned include using generative models / approaches that treat trajectory prediction as conditional sampling which may offer advances in handling the diversity and uncertainty of driving scenarios. Diffusion-Based Environment-Aware Trajectory Prediction by Theodor Westny, Björn Olofsson and Erik Frisk introduced a diffusion-based model for predicting the future trajectories of traffic participants. They essentially use a multi-agent trajectory prediction model that conditions predictions on inter-agent interactions and map-based information, integrating differential motion constraints to produce physically feasible predictions.
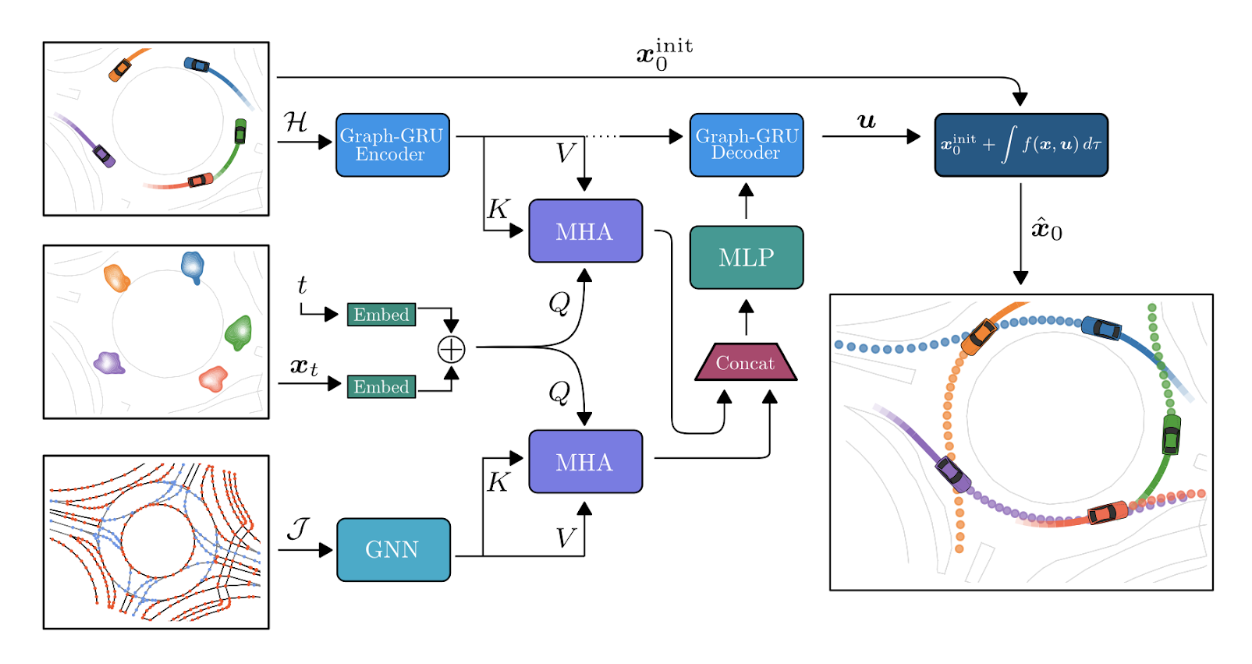
Figure 10. Schematic illustration of the proposed model.
The model’s performance on two large-scale real-world datasets, highlights its effectiveness in managing multimodality and uncertainty in trajectory predictions. The paper also explores guided sampling based on inter-agent connectivity, showcasing how the model adapts to predict the behavior of less cooperative agents, enhancing its practical applicability in uncertain traffic conditions. The proposed model shows promising results when working with noisy and unpredictable data, having the ability to positively impact the field of autonomous vehicles and trajectory prediction.
Discussion
The fields of human pose estimation, trajectory prediction, and autonomous vehicles are all heavily intertwined and face similar challenges. Deep Pose was one of the first ground breaking HPE algorithms that influenced the field heavily, proving that models could learn to detect human joints from data rather than using hand craft feature representations. After the introduction of Deep Pose, HPE coupled with trajectory prediction found its way into Autonomous Driving proving their importance in creating safe and efficient autonomous vehicles.
However, in order to move forward into a future of driverless vehicles, challenges common to the fields of human pose estimation, trajectory prediction, and autonomous vehicles must be addressed. There has been heavy research to address things like adaptability to 3D space, accurate annotations / training data, and handling of noisy / unpredictable data. Proposed solutions are rooted in experimental architectures based on diffusion, graph convolutional models, weakly supervised labeling, and other novelties.
References
Bauer, Peter, et al. “Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving.” arXiv.Org, 27 July 2023, doi.org/10.48550/arXiv.2307.14889.
Luo, Z., Robin, M., & Vasishta, P. (2023). GSGFormer: Generative Social Graph Transformer for Multimodal Pedestrian Trajectory Prediction. arXiv preprint arXiv:2312.04479. Retrieved from https://arxiv.org/abs/2312.04479.
Toshev, Alexander, and Christian Szegedy. “DeepPose: Human Pose Estimation via Deep Neural Networks.” arXiv.Org, 20 Aug. 2014, doi.org/10.48550/arXiv.1312.4659.
T. Westny, B. Olofsson, and E. Frisk, “Diffusion-Based Environment-Aware Trajectory Prediction,” arXiv preprint arXiv:2403.11643, Mar. 2024.
W. Shao, J. Li, and H. Wang, “Self-Aware Trajectory Prediction for Safe Autonomous Driving,” IEEE Intelligent Vehicles Symposium 2023 (IV 2023), arXiv preprint arXiv:2305.09147, May 2023. Retrieved from: https://arxiv.org/abs/2305.09147.