Text to Image Generation
- Introduction
- Diffusion Models
- Application of Latent diffusion
- Societal impact
- Other than Diffusion?
- Reference
Introduction
Stable Diffusion is a state-of-the-art image synthesis method, however its applications extend far beyond just image synthesis. In this article, we will develop a working understanding of Stable Diffusion, discuss a more realistic approach to Latent Diffusion, and then apply some of its applications such as vanilla image generation, image inpainting, and finally fine-tuning approaches.
 [1]
[1]
Diffusion Models
How do they work?
By treating images as progressively noised data, we can train models to learn how to denoise, or “diffuse” noise on an image. This idea serves as the backbone for diffusion models. Moreover, the diffusion model’s iterative nature allows for the ability to guide the generation via some textual input, or anything else a user might want to use. That being said, diffusion models come with crucial shortcomings, specifically, the fact that their operations must occur in the pixel space, which can be computationally massive.
Diffusion to Latent Diffusion
A particularly effective solution to this problem, proposed by Rombach et al. is to instead introduce some “latent space” to do our calculations in. This latent space is essentially a computationally simplified representation of our image, keeping only the most important details. We can do this by introducing autoencoders to learn these latent representations. Put simply, given an autoencoder E and an input x, z = E(x). Then, from there, our decoder attempts to recreate the image as close to the original as possible. This encoder essentially downsample the image by a factor of W/w = H/h. The autoencoders can be trained through both perceptual loss and a patch-based adversarial objective. Diffusion models can be thought of as equally weighted denoising autoencoders, e_theta(x_t,t), where t ranges from 1 to T. This can be summarized in the equation below
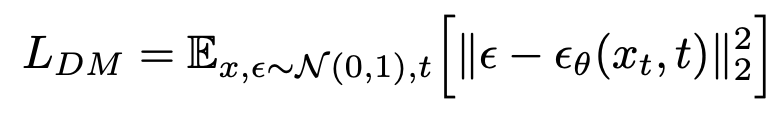
Now, here’s where the crucial difference between LDMs and DMs comes in. Rather than use the actual x_t, we replace it with our encoder representation, z_t. Now, we can train as usual but instead, focus on the important details learned by the autoencoders and greatly reduce the complexity at the same time. The change is reflected in the modified loss objective below
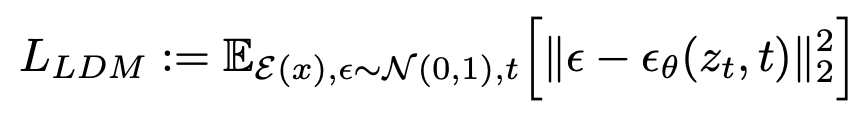
Moreover, due to the image-specific inductive bias granted in this model, we can build the U-net backbone entirely from convolutional layers. This is also highlighted in the equation, with e_theta now representing the convolutional U-net, rather than the denoising autoencoders in standard diffusion models.
Cross-attention for conditional image generation
By augmenting the previously mentioned U-net with a cross-attention mechanism, we can improve the conditional nature of our model. We can introduce a domain-specific encoder, tau_theta, that learns to project our conditional input into some intermediate representation, which can then be mapped into our U-net via a classic cross-attention layer.
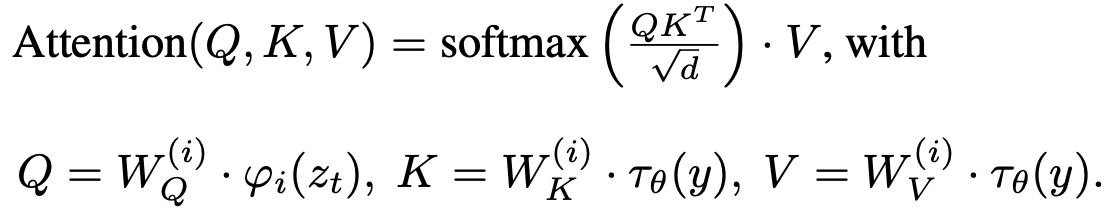
Note here phi is a simplified representation of our U-net. Then, we can augment the previous loss objective to include this, giving us
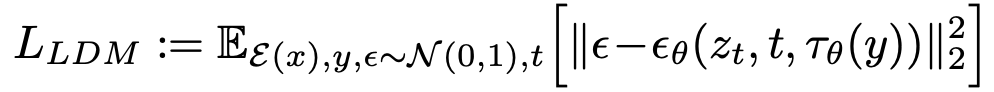
Finally, we provide an image displaying the LDM architecture explicitly
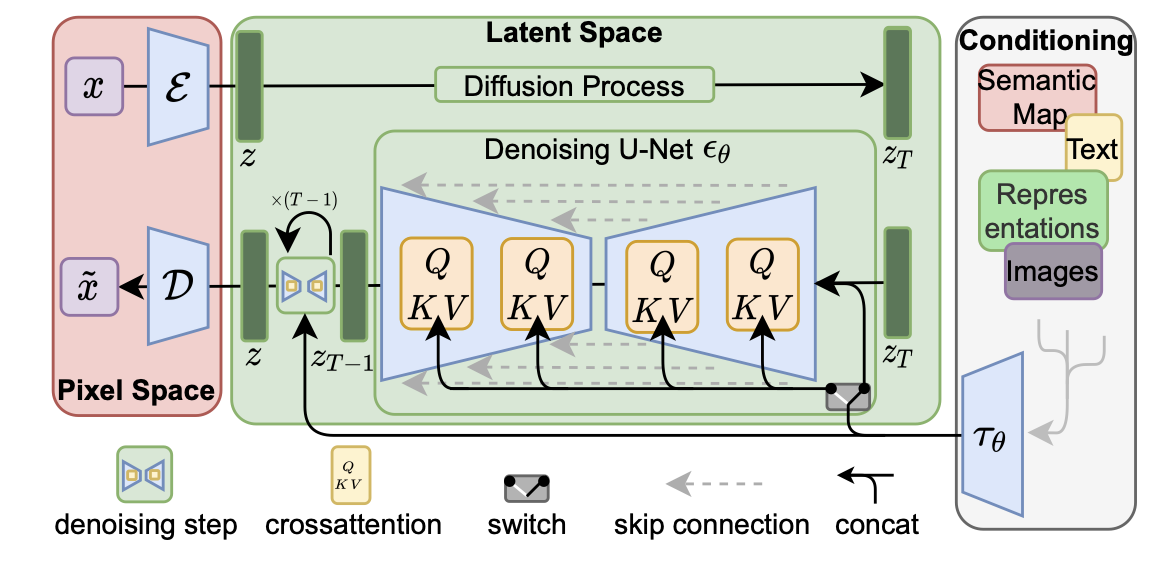 [1]
[1]
Generalizing Latent Diffusion Models
Due to the use of cross-attention in Latent Diffusion Models, the ability to generalize these models is instantly available. For example, by supplying these LDMs with appropriately labeled semantic segmentation maps, we can introduce the ability to generalize these models to a multitude of tasks, such as the discussed image synthesis, or even image inpainting and super-resolution.
 [1]
[1]
Codebase setup
Thanks to the Rombach et al paper mentioned previously, it is easy to reproduce these models and experiment locally. To do so, the majority of the setup can be done simply by following the instructions on the following GitHub link associated with the paper: https://github.com/CompVis/latent-diffusion/tree/main/configs
After cloning into this GitHub, the associated conda environment can be activated by conda env create -f environment.yaml conda activate ldm
Application of Latent diffusion
Latent diffusion for image generation
To begin experimentation, we downloaded the necessary pre trained weights and began running the necessary commands to generate images. We provide some sample images we produced:
Note by altering the –num_samples command line argument, we were able to generate different amounts of outputs
 [1]
[1]
A virus monster is playing guitar, oil on canvas.
The model also has some understanding of what real people look like!
 [1]
[1]
Lebron James holding a cat, oil painting.
Latent diffusion for image inpainting
Inpainting is a classic and quintessential computer vision task that essentially involves taking a region of an image, and removing or replacing the region with something different. Doing this with Latent diffusion is fairly intuitive. By providing the trained latent diffusion model with a mask over the area where the inpainting is desired, latent diffusion can simply diffuse on the masked region.
 [1]
[1]
Moreover, by utilizing the cross attention previously mentioned, the noise can be diffused conditionally via some other data type, such as a textual prompt. LDMs are able to achieve state-of-the-art results on image inpainting, even with significantly less parameters!
 [1]
[1]
Latent diffusion for image superresolution
LDMs have proven to be effective in performing the task of super-resolution via conditioning on low-resolution images. LDMs show a strong sense of depicting fine textures as compared to SR3, a GAN-based model performing the same task. It however falls short when capturing fine structures in an image, resulting in a lower IS score but a higher FID score. Lastly, amongst human participants, when shown a low resolution image and given the choice between LDM and SR3, more participants selected the LDM model, proving that LDM is capable of developing more pleasing high-res images to the human eye.
 [1]
[1]
Societal impact
Benefits
Since generative image models were first introduced, their potential impacts on society have been excruciatingly questioned. They pose a multitude of privacy threats, and in the eyes of many steal work from artists. Even in the limited scope of this paper, we showed the powerful capabilities of latent diffusion to provide renderings of real individuals, and as we’ve seen over the past few years, these models only increase in their ability to generate images.
That being said, latent diffusion models allow a key difference between diffusion models: they don’t require absurd compute time to run. This allows for a few social benefits of LDMs over other generative models. First, this model can be run and utilized by a normal person, as we were able to do with image generation, as compared to traditional Diffusion Models which really only are available to powerful companies. Second, this vastly reduces the carbon footprint of the training of these models, another key benefit. So, while generative models have many common pitfalls, LDMs allow for at least a few positive societal benefits.
Potential Challenge and Solution
Large-scale text-to-image diffusion models trained on diverse datasets frequently incorporate copyrighted material, necessitating strategies for concept removal without extensive retraining. We present a method based on modifying image distributions to achieve concept ablation, thereby addressing copyright concerns without compromising model performance.
 [4]
[4]
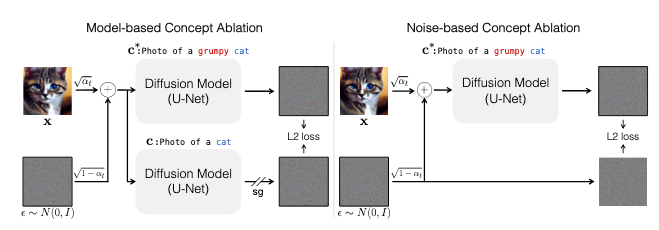 [4]
[4]
We update model weights to modify the generated image distribution on the target concept, e.g., Grumpy Cat, to match an anchor distribution, e.g., Cat. We propose two variants. Left: The anchor distribution is generated by the model itself, conditioned on the anchor concept. Right: The anchor distribution is defined by the modified pairs of <target prompt, anchor image>. An input image x is generated with anchor concept c. Adding randomly sampled noise epsilon results in noisy image xt at time-step t. Target prompt c∗ is produced by appropriately modifying c. In experiments, we find the model-based variant to be more effective.
Other than Diffusion?
Autoregressive models
The Parti model employs the autoregressive approach that treats the task as a sequence-to-sequence problem. By adopting Transformer-based image tokenization, Parti scales an encoder-decoder Transformer model to a 20B parameter, delivering high-fidelity, photorealistic images from textual descriptions.
Parti’s simplicity in design belies its sophisticated output, achieving state-of-the-art FID scores on MS-COCO and demonstrating robust generalization across detailed narratives. The model introduces the PartiPrompts benchmark to evaluate the generative capabilities of text-to-image models further.
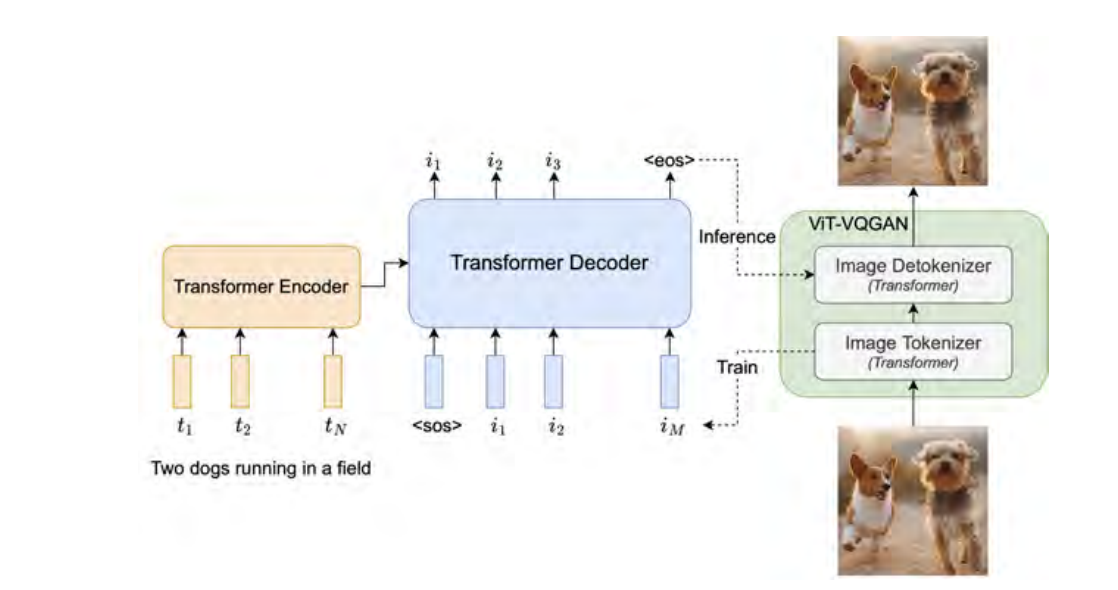 [5]
[5]
Comparison
Diffusion models, such as Stable Diffusion variants like Dreamlike Photoreal 2.0 and Dreamlike Diffusion 1.0, exhibit greater efficiency compared to autoregressive models when controlling for parameter count. Autoregressive models generally require a larger model size to achieve comparable performance to diffusion models across most metrics. Additionally, autoregressive models like DALL-E 2 show promising performance in reasoning tasks.
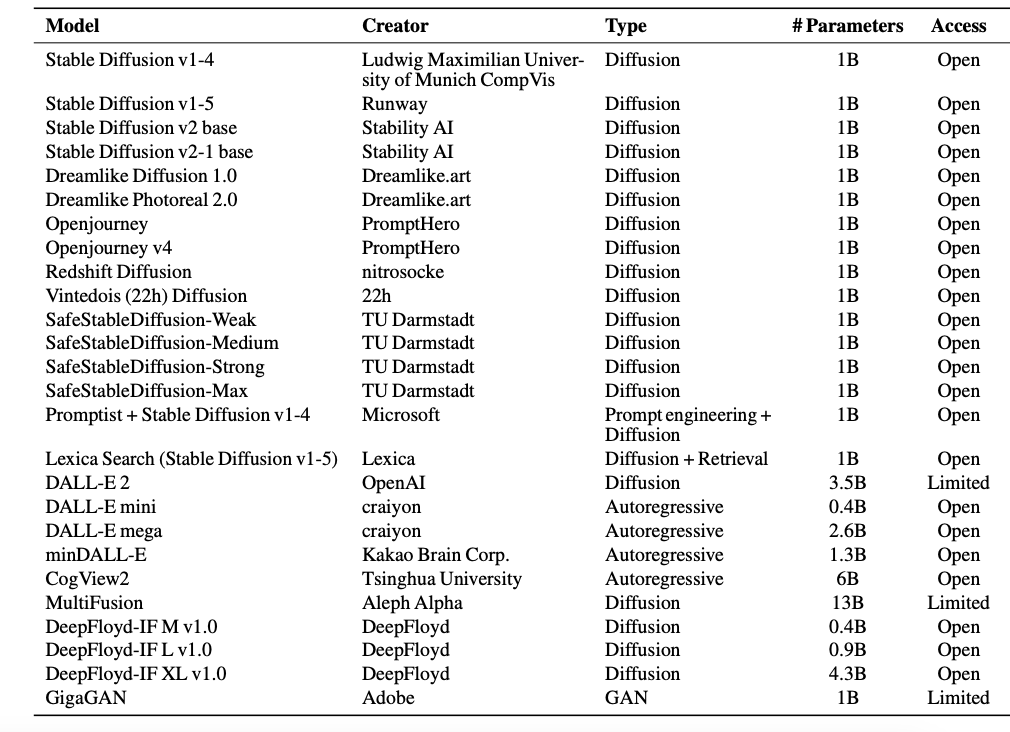 [6]
[6]
Reference
[1] Rombach, Robin, et al. “High-Resolution Image Synthesis with Latent Diffusion Models” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[2] Weng, Lillian. “What are Diffusion Models?” Lil’Log https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
[3] Xie, Shaoan, et al. “SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model” CVPR
[4] Kumari, Nupur, et al. “Ablating concepts in text-to-image diffusion models.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[5] Yu, Jiahui, et al. “Scaling autoregressive models for content-rich text-to-image generation.” arXiv preprint arXiv:2206.10789 2.3 (2022): 5.
[6] Lee, Tony, et al. “Holistic evaluation of text-to-image models.” Advances in Neural Information Processing Systems 36 (2024).