Final Report - Hand Gesture Recognition
Hand gesture recognition aims to identify hand gestures in the context of space and time. It is a subset of computer vision whose goal is to learn and classify hand gestures.
- Overview
- Current Methods of Object Detection
- Google Media Pipe
- Gesture Classification with CNNs
- Comparing SSD and Multiple CNN Classification
- Experiments with Media Pipe
- Our Own Model
- Future Applications / Research?
- Conclusion
- References
Overview
What is Hand Gesture Recognition
From the dictionary:
Gesture (noun): a movement of part of the body, especially a hand or the head, to express an idea or meaning.
Hand gesture recognition or gesture recognition in general has many applications. It can be used for communication such as ASL translation, interfacing with electronic devices, and even computer animation.
Objectives
To begin understanding hand gestures we must have data to look at. Data sources often come from cameras, 3D camera systems, and motion tracking setups. This gives us visual information about what is in the scene and the context around it.
The goal of hand gesture recognition is to take the input data, detect the presence of a hand, and then extract the meaning (or lack thereof) behind the movement. Outputs from a model like this could be classifications of gesture types, bounding boxes, skeleton wire frames, or just text outputs.
Current Methods of Object Detection
Early Models of Hand Gesture Recognition
Currently, the most common methods of human pose detection do not use computer vision. Rather, it uses a method referred to as Passive Optical Motion Capture, which involves people (or animals) wearing suits with reflective markers on them that cameras can easily track.

This is convenient for animations, game development, and movies since it provides accurate 3-dimensional points that can be easily analyzed later. However, many other use cases are appearing where reflective markers are not practical, such as in sports analysis, virtual reality development, wildlife research, or sign language translations, just to name a few. Pose Detection with deep learning offers a non-invasive method for real-time body tracking.
Hand gesture tracking is really a subset of human pose detection, which is a subset of object or feature detection. In fact, each hand gesture may be treated as their own separate ‘object’ for the computer to recognize. As a result, hand trackers tend to use similar technologies and concepts as human pose detectors and general object detectors - just with some extra specializations.
The earliest object detectors use a structure called an R-CNN, or a region-based convolutional neural network. Although these work for processing recorded videos, they take too long to run to be practical for real-time video processing. This led to developments on the neural network and the advent of the Fast R-CNN and Faster R-CNN which are approximately 9.6 times and 210 times faster than R-CNN, respectively. More recently, another neural network model named YOLO emerged, which runs faster than Faster R-CNN at the cost of accuracy.
Architecture of YOLO
YOLO, an acronym for “You Only Look Once” is a single-pass neural network (e.g., each image is processed only once) used for object detection.
Figure 1
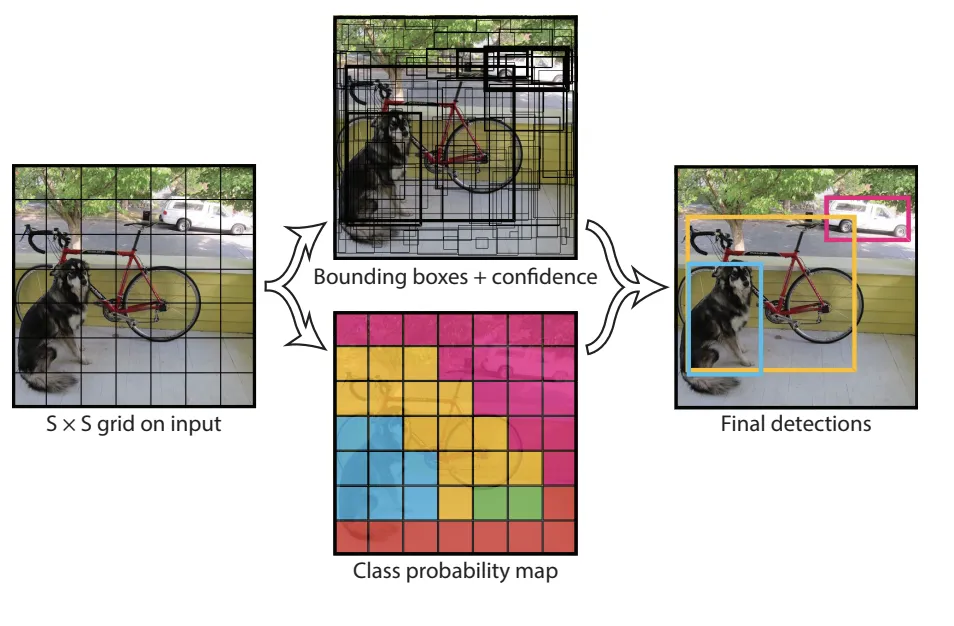
It accomplishes this task by essentially merging the region proposal network and the general object classification neural network, making it faster than Faster R-CNN.
YOLO first passes the input image through a CNN for feature extraction, followed by multiple fully connected layers which predict class probabilities and bounding boxes. The image is then divided into a grid of squares, where each square, or grid cell, is associated with a set of class probabilities and bounding boxes (See Figure 1). Bad bounding box selections are then filtered out using a process referred to as non-maximum suppression (discussed later), then finally predicted bounding boxes with their class predictions are returned.
The image processing pipeline YOLO uses is massively efficient compared to its predecessors Faster R-CNN and Fast R-CNN. However, its main drawback is that it is not as accurate, especially with small objects like hands. Because of the step where the image is divided into a grid, the smallest object that can be classified by YOLO is the size of one grid cell. As a result, although YOLO is great for classifying larger objects very quickly, it is not particularly efficient or accurate for hand gesture recognition, since the number of grid cells would have to be increased. Despite this, YOLO is an important stepping stone to more specialized models designed for hand gesture recognition.
Google Media Pipe
Google’s MediaPipe framework provides a straightforward pipeline for developers to build machine learning applications for free. Their models are open source, and designed for a wide range of computer vision tasks. While they offer frameworks for tasks like object detection, image segmentation, and image classification; in the interest of our report, we will focus mainly on the “Hand Gesture Recognition” graph.
The hand gesture recognition model works in multiple steps. First, it detects the presence of hands using a single shot detector (SSD) model to generate bounding boxes. Next, it feeds the cropped image into a CNN regression model to predict hand landmarks. Lastly, from the hand landmarks, the model predicts the final gesture using two fully connected neural networks.
SSD with RetinaNet Influence
Single Shot Detectors (SSDs) is a single pass algorithm for generating bounding boxes, much like YOLO. However, at the price of a couple extra convolutions per image is a great increase in accuracy, especially with varying scales for how big the bounding box should be.
Like YOLO, it splits the image into regions, and has a certain set of default sized bounding boxes (known as anchors) that it applies to each region. But, unlike YOLO, instead of having plenty of differently sized anchors, SSDs have comparatively few - this is because SSDs don’t just have one convolution step, but multiple, and thus can make predictions for bounding boxes at each “scale”. This allows SSDs to make more accurate predictions for objects that have varied sizes, and much better at predicting large objects (due to the large amount of information after multiple convolutions).
But, predicting hands is a difficult task. There’s a reason that AI and artists alike are famously bad at generating/drawing hands, and that’s because there’s so many different poses and possibilities for hands to be in. So, the Mediapipe architecture made a couple changes to the standard SSD to adjust it to be able to detect hands with over 95% accuracy!
First off, it’s not actually a hand detector, it actually only detects palms! Palms can actually be modeled using only square bounding boxes, which reduces the number of anchors by a factor of 3∼5. Additionally, as “…palms are smaller objects, the non-maximum suppression algorithm works well even for two-hand self-occlusion cases, like handshakes.”
One of the large changes they made was to add a feature-pyramid network as well as implementing Focal Loss, inspired by the work of Retina-Net.
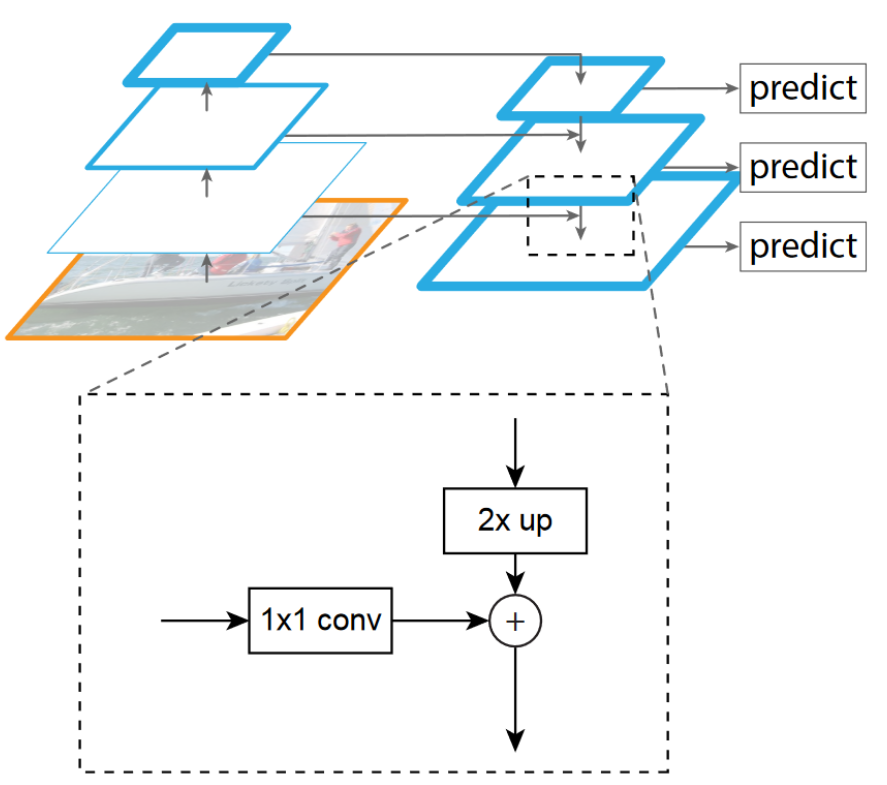
To explain the feature pyramid, let’s revisit the SSD. The features that exist in the most zoomed in scope (i.e. after all convolutions take place) are very strong. Compare that to the raw image with no convolutions on it - it is very difficult to extract meaningful features from it. What if we wanted the layers at all scopes to be feature rich? Here’s what we’ll try. First, run all the convolutions, seen in the image as going up in the diagram. Next, predict anchors on the top box. Then, upscale the top feature layer and simply add it to the second layer image from the top. Now, this image has all the information from features below it and above it, so predicting anchors on this new image actually increases accuracy. Continuing this process all the way down the feature pyramid leads to increased accuracy of predictions of bounding boxes.
Additionally, using focal loss instead of normal Cross-Entropy loss was incredibly helpful in increasing accuracy. Focal Loss is, in the words of the paper a “dynamically scaled cross entropy loss, where the scaling factor decays to zero as confidence in the correct class increases…”. This change along with the feature-encoder increased their accuracy ~9.5% alone.
Non-Maximum Suppression
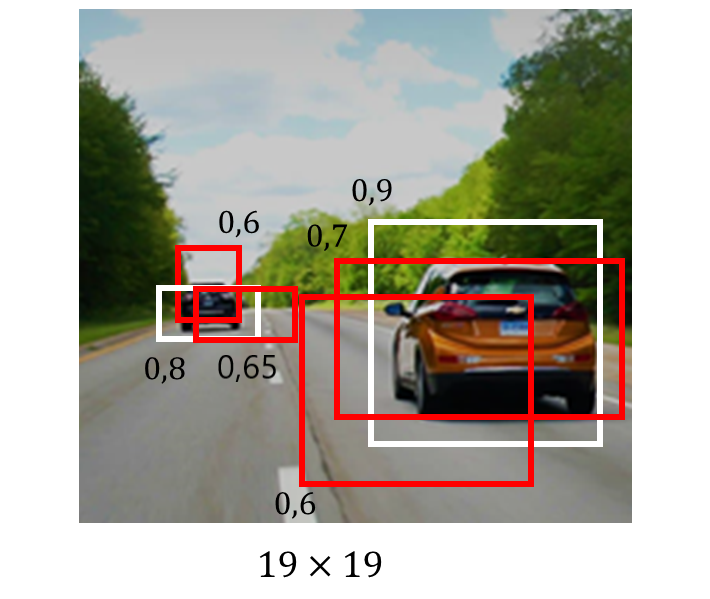 Now that we have all these predicted bounding boxes, how do we get rid of the ones that overlap? The algorithm works as follows: First, sort the bounding boxes from highest confidence to lowest. Pick the first one (i.e. the highest confidence bounding box) and eliminate all bounding boxes that overlap with it (usually using IoU) over a certain threshold value. Then, repeat with the next boxes until you’re left with high probability, low-overlapping boxes
Now that we have all these predicted bounding boxes, how do we get rid of the ones that overlap? The algorithm works as follows: First, sort the bounding boxes from highest confidence to lowest. Pick the first one (i.e. the highest confidence bounding box) and eliminate all bounding boxes that overlap with it (usually using IoU) over a certain threshold value. Then, repeat with the next boxes until you’re left with high probability, low-overlapping boxes
We now have hands in a bounding box. How do we get hand landmarks?
With a Regression Model! There just needs to be a lot of data to train on to make sure that the model is accurate. So, that’s just what MediaPipe’s authors did - annotate a lot of pictures. A LOT. They manually annotated around 30 thousand hands, but to cover even more possibilities of orientations, genders, and skin colors they simulated images of hands using the GHUM dataset of 3d human models. Interestingly, the mean regression error (normalized by palm size) of using both simulated and real data is actually smaller (good!) than the loss using either dataset individually.
After finding hand landmarks, 2 fully connected neural networks utilize the hand landmark data to figure out what gesture is being made; where the first normalizes the hand landmarks within the image, and the second is a classification model.
Gesture Classification with CNNs
Another method of gesture recognition involves just using CNNs, to address the challenge of having indefinite start and end of gestures in live videos. In a model developed by Köpüklü et al. and the Institute for Human-Machine Communication, located in Munich Germany, as well as the Dependability Research Lab backed by Intel Labs Europe, a lightweight convolutional neural network for gesture detection and a deep neural network for classification are used in parallel to identify gestures in real time.
Gesture Detection
Like how 2D CNNs are used for identifying objects in images, 3D CNNs can be used for identifying objects in videos. The goal of the detector is simply to output whether or not there is a gesture in the current frame. As such, its two classes are gesture and no gesture. Although this detection is not at all complex compared to classification, it must run fast enough to evaluate all the frames in real time. Not only that, but it must also be particularly robust - because the classifier CNN runs considerably slower, the detector cannot afford to have false positives.
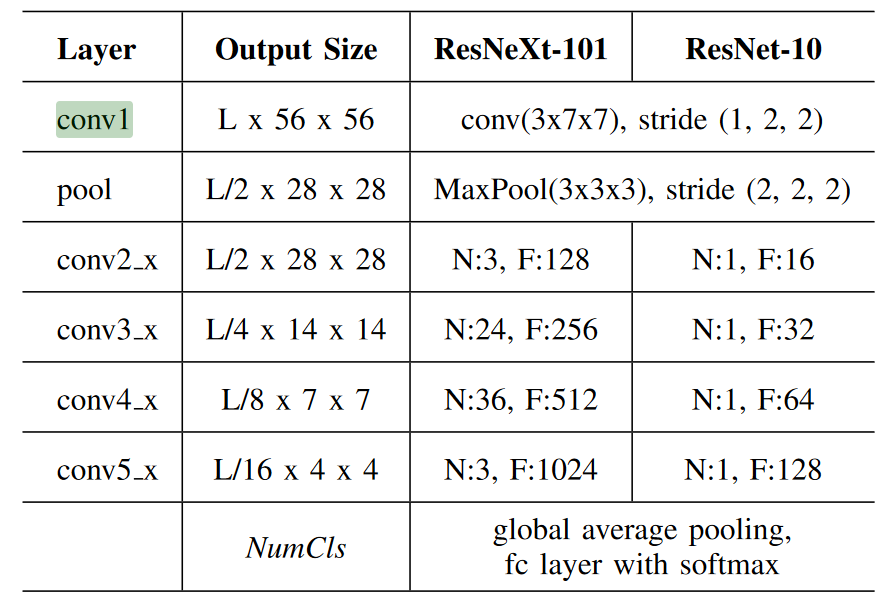
This classifier uses a ResNet-10 architecture and is trained using cross-entropy loss as it has a low likelihood of false positives, and the class weights for no gesture and gesture classes are 1 and 3, respectively.
If the detector detects a gesture on a given frame, it sends the frame to the classifier to identify which gesture it is. If there is no gesture in the frame, it simply moves to the next frame.
Gesture Classification
Unlike the detector, the classifier does not have to run every frame, and can therefore run slower. The classifier was implemented using a ResNeXt-101 architecture with the following finetuning parameters, and with stochastic gradient descent, damping factor 0.9, momentum 0.9, 0.001 weight decay, and 0.01 starting learning rate, which divides by 10 at the tenth and twenty-fifth epochs.
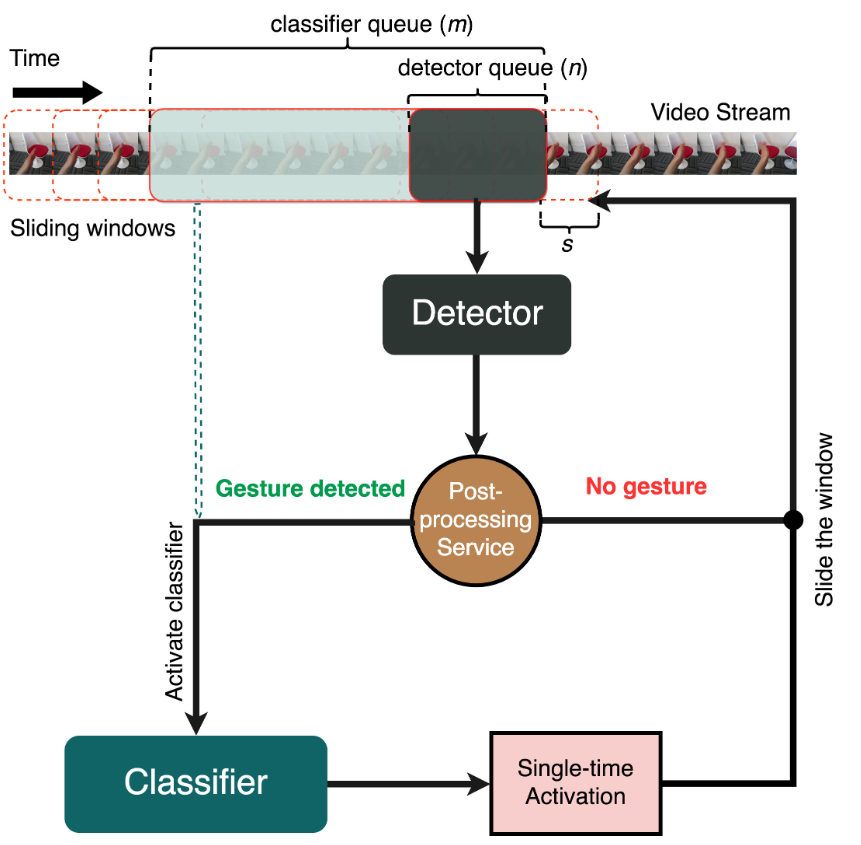
Post-processing
Due to the nature of recording videos, there are some points where the hands would be outside of the camera frame while performing gestures. In this case, previous predictions would be used. Softmax probabilities of previous detector predictions are inserted into a queue, and values are filtered to inform a detector decision. The queue size used in the model was 4, to achieve the best results.
Results
Below is a graph of raw and weighted classification scores.
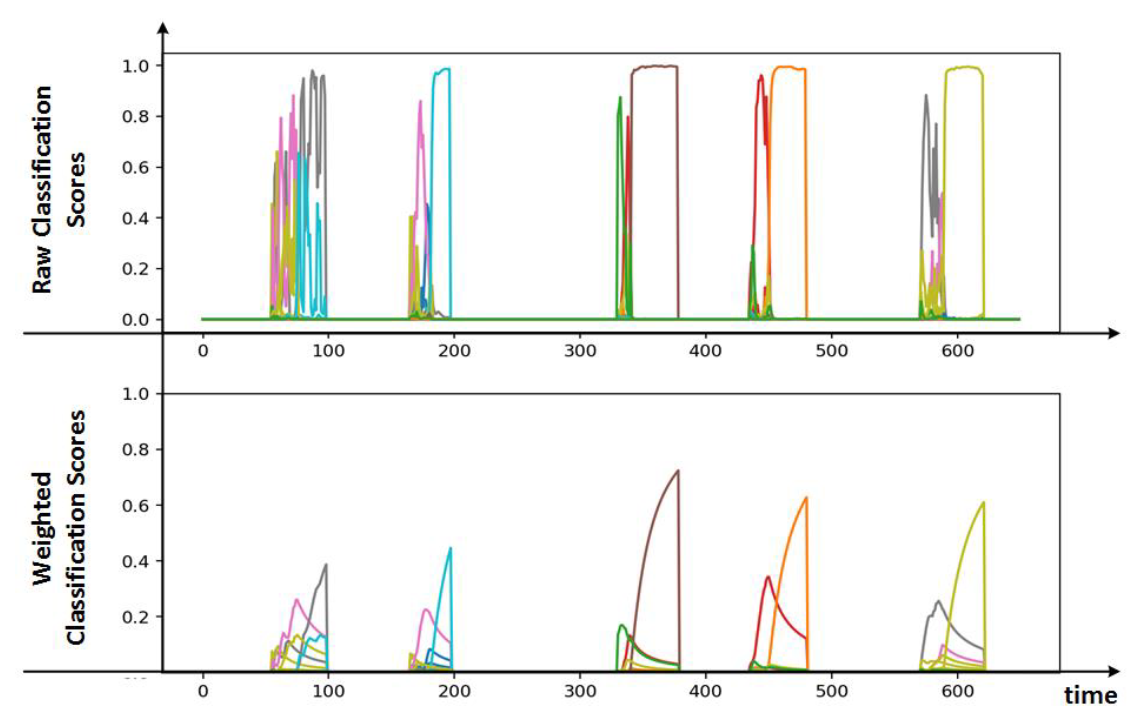
The beginning of each classification contains a considerable amount of noise, but the classifier grows more confident as time progresses. The noise was removed in the weighted classification scores by using a smaller weight for the beginning of the gesture compared to the end.
Comparing SSD and Multiple CNN Classification
While both MediaPipe’s model and the CNN model by Köpüklü et al. can classify gestures with real-time videos with high accuracy, there are some differences in the approaches. MediaPipe’s model is a little less recent, and is made to be open source and adjustable for developers. Many of the decisions in regards to the model revolve around making it as robust and accurate as possible to allow for adjusting the model for experimentation and live video. This led to the main design decision of having a hand detector that outputted hand landmark data into another model that standardized and classified the gestures. In comparison, the first CNN in Köpüklü’s model outputs a simple bounding box where the hand is, and the second does all the heavy lifting to decipher the gesture. Going more in depth, the CNN model by Köpüklü is far more recent, and is primarily meant to score highly on gesture benchmarks, which includes a temporal aspect. By adding temporal elements, it increases the complexity of the model significantly, and thus led to a lot of adjustments for this model including the much deeper CNN, the early detection model, and a new distance metric to more accurately calculate loss for the model. Both are great models, but for slightly different use cases.
Experiments with Media Pipe
We were able to demo MediaPipe’s gesture recognition model through their web interface. Their default model comes pre-trained with 7 different gestures that can be run with 1 or 2 hands in the frame at a time. Also available as adjustable parameters are hand detection confidence, hand presence confidence, and tracking confidence. Input is live streamed from a laptop webcam and then inference is run on either a CPU device or a GPU device if one is available.
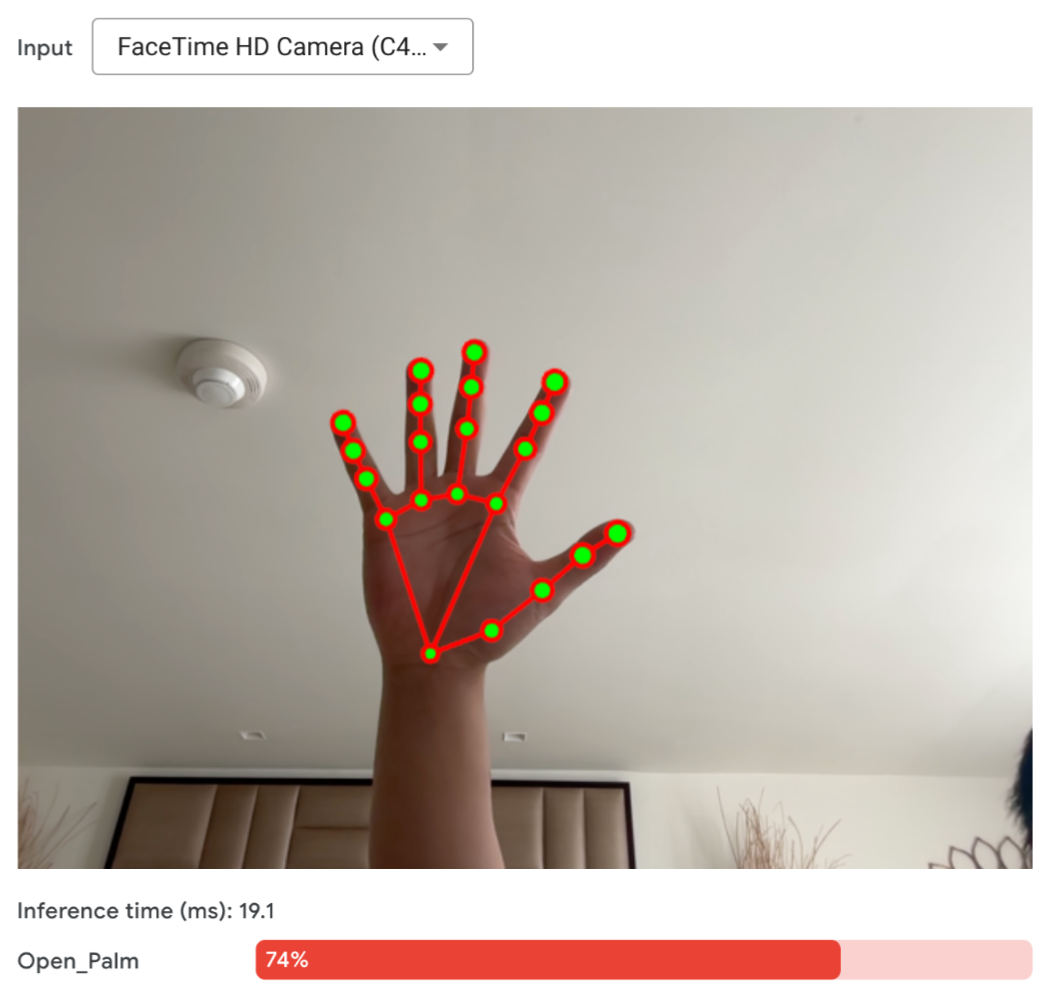
Trying the “Open_Palm” gesture Outputs of the model are a wireframe skeleton of my hand with the red color representing the right hand and the green color representing the left hand. Another output metric is the interference time which rounding up to 20ms per frame results in about 50 frames per second. This is more than enough for real-time applications of gesture recognition.
Gesture class outputs like the one shown above could be used to interface with computers by executing a shortcut or performing an action. Another way to use the output of MediaPipe is to take the coordinate array that represents the wireframe and manually do distance calculations on the joints to extract gestures.

The joints and what they represent Each of these coordinates comes with an x, y, and z component so it is very easy to do manual inference just based on the joint positions.
Aside from having an online web demo, their code is publicly available as a colab notebook.
# STEP 1: Import the necessary modules.
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
# STEP 2: Create a GestureRecognizer object.
base_options = python.BaseOptions(model_asset_path='gesture_recognizer.task')
options = vision.GestureRecognizerOptions(base_options=base_options)
recognizer = vision.GestureRecognizer.create_from_options(options)
images = []
results = []
for image_file_name in IMAGE_FILENAMES:
# STEP 3: Load the input image.
image = mp.Image.create_from_file(image_file_name)
# STEP 4: Recognize gestures in the input image.
recognition_result = recognizer.recognize(image)
# STEP 5: Process the result. In this case, visualize it.
images.append(image)
top_gesture = recognition_result.gestures[0][0]
hand_landmarks = recognition_result.hand_landmarks
results.append((top_gesture, hand_landmarks))
display_batch_of_images_with_gestures_and_hand_landmarks(images, results)
MediaPipe makes it very easy to get a basic model up and running with very few lines of code as shown in the above code snippet. Plus with such a low latency, MediaPipe enables us to build a real-time application using their model.
Our Own Model
We took advantage of MediaPipe’s coordinate array output to construct our own model. We collected data by recording videos of various individuals performing 3 specific gestures and ran them through MediaPipe’s hand landmark model to get our array outputs. This would become the dataset for our pytorch-based model.
To be specific, the three specific gestures we tested with are a closed fist ✊, an open hand ✋, and a pinch 👌, and the model can be found here.
Since our model does not need to do any image processing, we stuck with just four linear layers. The input is the array of coordinates MediaPipe provided (size 63). The first fully connected layer takes in the 63 inputs and outputs 32, the second takes 32 and outputs 16, the third takes 16 and outputs 8, and the final layer takes in 8 and outputs 3, which is the number of classes. Each fully connected layer is initialized with the Xavier Initialization and is followed by a Leaky ReLU activation function, except for the output layer. We also used a batch size of 64 and a learning rate of 0.01. With this setup, we were able to achieve a 79.97% accuracy and a loss of 0.8038 in identifying the three gestures.
Despite the model generally working, running multiple epochs lowers the average validation loss, but does not change accuracy. The reason for this is likely due to overfitting since we have limited data to use with the model.
Future Applications / Research?
Recent improvements to the quality of CNN-based gesture recognizers have come from improvements to machine learning models, new training techniques, and integrations with new sensors to improve the quality of data fed to models. These improvements are unlocking new potential applications for gestures, and newly popularized forms of consumer electronics are also poised to take advantage of these improvements.
New Models and Training Techniques
Prior to 2018, the state of the art in hand gesture recognition used a depth map, a 2D vector of 3D information, to do predictions. Using the data layout directly in the modeling was most common, and researchers had obtained 12% error on a dataset of static hand pose images from NYU. V2V-PoseNet, a new network model built by South Korean researchers (Moon et. al.), used neural networks to predict the mapping from the 2D vector of depths into a 3D network of volumetric densities. This allowed the researchers to use a 3D convolutional structure in their network, improving accuracy to only 8.42% error.
In 2020, a new team (Rastgoo, et. al.) extended this research, combining 3D CNNs with the lower-memory projected 3D representation of tri-planes to improve their accuracy. Using a fully-connected model on the concatenated combination of the various spatial 2D CNN predictions produced by the planar views, their error on the NYU hand pose dataset was reduced to 4.64%.
Building on this work, researchers earlier this year (Shanmugam, et. al.) have worked to improve the training process for dynamic hand gesture recognition. A new genetic optimizer, the Hybrid Arithmetic Hunger Games (HAHG), is used to improve their training process for a deep CNN similar to those used formerly, and improved the recognition of dynamic gestures to be on par with static pose recognition in 2020 for small datasets. In the DHG-14 dataset (which contains 14 distinct dynamic hand gestures), their model achieved 2.80% error, and in the larger DHG-28 dataset, they obtained 3.87% error. However, work on much larger datasets is still underway, with 7.22% error obtained by their model on the 71-gesture FHPA dataset. Work into recognizing the thousands of gestures used in sign language is ongoing and represents the most difficult current goal for gesture recognition algorithms.
We can expect to see similar types of improvements to existing models in the near future. Applying existing structures like voxels to the problem of gesture recognition could yield future successes: combining the real time single-frame successes of MediaPipe with existing highly-parallelizable sequence-parsing techniques like attention could yield effective new real time dynamic gesture classifiers. Further, the improvements within the hand gesture field like HAHG may soon find uses in other fields of machine learning, like natural language processing and generative modeling.
New Sensor Integrations
Although classifiers like MediaPipe are currently extremely accessible due to their minimal hardware requirements (both from a computational perspective and in terms of only needing a webcam), their accuracy and ability to perform in new environments is limited. Depth cameras that give both color and distance information were used in all of the papers referenced in the previous section. New research (Birkeland, et. al.) investigates the use of thermal cameras to further improve models’ ability to discern hands from backgrounds, adapt to lighting conditions, and maintain accuracy over the wider diversity of hands that could be presented.
Currently, thermal and depth cameras cost on the order of $300 per unit. Lower-resolution thermal camera units are available for closer to $100, and research has shown these can provide benefits for gesture recognition, but the cost of adding these sensors far outweighs the benefit for most applications today, as webcams are significantly cheaper. However, this is likely to change, as higher-end devices take advantage of these new sensors and their production at scale becomes more economical and as more applications take advantage of this data.
Applications in VR/AR User Experience
With the recent releases of both the Meta Quest and Apple Vision Pro, virtual and augmented reality applications are becoming increasingly common, and research supporting them is increasingly profitable. Both products allow use of hand gestures for certain controls, like opening the main menu. However, many other features are still tied to physical controllers or to the headset itself. Improvements in accuracy with dynamic gesture recognition for large datasets will allow developers to integrate more gesture options. In some places this may eliminate the need for physical controllers and enhance the immersion of the experience; in others it may allow for new control modes that have not been used in the past. Many applications in this newly-expanding field are possible.

Gesture Generation
A common trend in machine learning fields is that once recognition tasks are solved, new research tends to focus on generation tasks. Tools for generating images and videos can create gestures as a byproduct of their training, but existing research has not focused on generating gestures specifically. This is something we can expect to happen soon, based on the lifecycle of gesture recognition as a machine learning task.
Applications for gesture generation are most clear in fields adjacent to sign language. Although generating improved hand gestures and sign language in videos where it is not the primary focus are side effects that we can expect to come from this future research, the truly interesting applications are in computer translation. Currently, no effective sign language translator programs exist. Google Translate, for example, does not even offer support for sign language, and historically Google Translate’s support for a language has not implied even that the translation technology in the supported language is good. Although a few purpose-dedicated sign language generation tools purport to exist, they act more as transliteration tools, and can only play back fixed gestures from small sets. This eliminates much of the inflection and nuance that represents the way sign language is actually used and that distinguishes similar phrases. A truly effective sign language translation tool remains a tool of the future, but with research into gesture generation on the horizon, this may soon become a reality.
Conclusion
Significant changes have occurred in the field of gesture recognition, especially hand gesture recognition, in the recent past. Early efforts at tracking the human body required purpose-built suits with markers, and following in the same vein, hand tracking efforts used purpose-built gloves. However, this requirement is expensive and invasive to many situations in which hand tracking is desired, and so machine learning algorithms began to be applied to the problem. R-CNN object locators, and the subsequent performance improvements made to that architecture, were applied to hands. Researchers found better results working to detect palms rather than hands, and by using a regression model to locate hand landmarks. Domain-specific datasets with labeled hand landmarks, as well as improvements to loss functions, optimizers, and architectures have pushed the latencies of gesture classifiers down to the tens of milliseconds and the accuracies of the classifiers to above 95%. High-quality camera-based gesture recognition is already in limited use for controlling high-end virtual reality headsets, and is likely to gain more widespread use in these existing applications as well as in new, not-yet-invented technologies.
References
Citations are in alphabetical order by the first author’s last name.
-
Bazarevsky et al . “On-Device, Real-Time Hand Tracking with MediaPipe” 2019. https://blog.research.google/2019/08/on-device-real-time-hand-tracking-with.html
-
Birkeland et al. “Video Based Hand Gesture Recognition Dataset Using Thermal Camera” 2024. https://doi.org/10.1016/j.dib.2024.110299
-
Köpüklü et al. “Real-time Hand Gesture Detection and Classification Using Convolutional Neural Networks.” 2019. https://doi.org/10.48550/arXiv.1901.10323
-
Lin et al. ”Feature Pyramid Networks for Object Detection” 2017. https://arxiv.org/abs/1612.03144
-
Lin et al. “Focal Loss for Dense Object Detection” 2018. https://arxiv.org/pdf/1708.02002v2.pdf
-
Moon et al. “V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map” 2018. https://doi.org/10.48550/arXiv.1711.07399
-
Rastgoo et al. “Hand Sign Language Recognition Using Multi-view Hand Skeleton” 2020. https://doi.org/10.1016/j.eswa.2020.113336
-
Shanmugam and Narayanan, “An Accurate Estimation of Hand Gestures Using Optimal Modified Convolutional Neural Network” 2024. https://doi.org/10.1016/j.eswa.2024.123351
Stand-alone images
-
Gandhi, Rohith. “R-CNN, Fast R-CNN, Faster R-CNN, YOLO - Object Detection Algorithms” 2018. https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
-
Hellerman, Jason. “How to Act in a Mo-Cap Suit” 2019. https://nofilmschool.com/how-to-act-in-mocap-suits
-
Matić, Vladimir. “CNN Non-Max Suppression algorithm” 2018. https://datahacker.rs/deep-learning-non-max-suppression/