Survey on Foundation Models for Robotics
Foundation models (FMs) have demonstrated remarkable capabilities in the field of natural language processing (NLP) and computer vision (CV). Their success stems from pre-training on massive, diverse datasets using self-supervised learning, leading to the ability to generalize across diverse tasks and also enables efficient finetuning to the downstream tasks. This paradigm shift, largely driven by advancements in large language models and vision transformers, holds great potential for the field of robotics. While conventional robotic systems often rely on task-specific models requiring extensive, domain-specific data and expert engineering, foundation models provide the opportunity to design robots with greater autonomy, adaptability, and generalized intelligence. In this study, we aim to provide a comprehensive survey of foundation models in robotics. This includes the main challenges of foundation models for robotics and most of their main use cases.
- Introduction
- Challenges
- Conventional Foundation Models for Robotics
- Robotics Foundation Models
- Conclusion
- References
Introduction
Foundation models (FMs) have demonstrated remarkable capabilities and revolutionized the field of natural language processing (NLP) and computer vision (CV). These models are obtained through pre-training on massive, diverse datasets using self-supervised learning. They possess multiple desirable properties such as the ability to generalize across diverse tasks and the ability to be efficiently adapted to the downstream tasks. This paradigm shift from individual specialist models to a single powerful generalist model holds great potential to various fields of application, including robotics. The main driving force behind this is the advancements of large language models and vision transformers, which provide the opportunity to design robots with greater autonomy, adaptability, and generalized intelligence. However, even though the use of foundation models certainly has strong potential for robotics, there are still some main challenges to be addressed for them to have a practical impact for real world usages. This mainly lies in the inherent difference of the nature of robotics and the other common machine learning fields like natural language processing (NLP) and computer vision (CV). Unlike natural language processing (NLP) and computer vision (CV) which can be obtained virtually throughout the internet, the collection of robotic data requires physical interaction with the real world. The interaction with the real world not only makes data collection more difficult, but also raises security concerns. The diversity in the number of robotic tasks also makes task specification challenging. This study aims to provide a comprehensive survey of foundation models in robotics. We will systematically cover the challenges of foundation models for robotics and analyze the existing approaches. We will discuss the various use cases of foundation models, including perception, localization, and task planning.
Challenges
In this section, we summarize the main challenges of foundation models for robotics. This includes data scarcity, task specification, and safety.
Data Scarcity
The success of the foundation model lies in the broad and diverse data source for training. This should be no exception when it comes to robotics. However, acquiring large-scale and high-quality real-world robotic data remains a significant challenge. Since it takes time for the robot to interact with the real world, the collection of such time is not only time-consuming but also expensive [1]. There are also safety concerns for both the robot and the surrounding environments [2]. While simulation offers a controlled environment for the efficient generation of synthetic data [3] [4] [5], the challenge remains whether and how they could cover the full diversity of the real world.

Isaac gym for the simulation of robotics environments.
Task Specification
Given the diversity in the large number of possible robotic tasks, having a precise task specification is challenging. The need to resolve ambiguities under limited demonstrations and the robot’s limited cognitive ability raises questions about what is the best way for task specifications. Existing approaches commonly specific the tasks through language prompts [6] [7], images [8], or reward signals for reinforcement learning [9].
Safety
Safety is critical for both the robot and the environment during its real-world interaction. The uncertainty that naturally lies in the environment and the ambiguity in task specification makes safety particularly challenging. One approach to enhance the safety for robotics is uncertainty quantification [10]. Even though the advance in foundation models for self-reasoning (reasoning about the model itself) to quantify uncertainty provides a huge potential, a designed robotical framework that can provide accurate self-estimation on its own actions still remains as an open challenge. Additionally, there are approaches that aim for provable safety in robotics. These theoretical grounded methods include control barrier functions [11] and reachability analysis [12], which are well-known and standard techniques for ensuring safety under bounded levels of noise.
Conventional Foundation Models for Robotics
In this section, we describe the main uses of foundation models for robotics. These can be roughly classified as three main categories. The use of foundation models for perception, localization, and task planning.
Perception
The most straightforward use of foundation models for robotic perception will be the use of visual language models for object recognition and environment understanding.
For environment understanding, NLMap [13] provides an open-vocabulary and queryable scene representations. This serves as a framework to gather and integrate contextual information to the robot. With NLMap, robots are now capable of seeing and querying the available objects before their action planning. During the robots exploration of the environment, a map is being built. The region of interest for the exploration is then encoded by the visual language model and being added to the map. ConceptFusion [14] provides multimodal maps, allowing the robots to query different modalities such as image, audio, and text. The authors of ConceptFusion had shown that it is applicable to real-world applications such as autonomous driving.
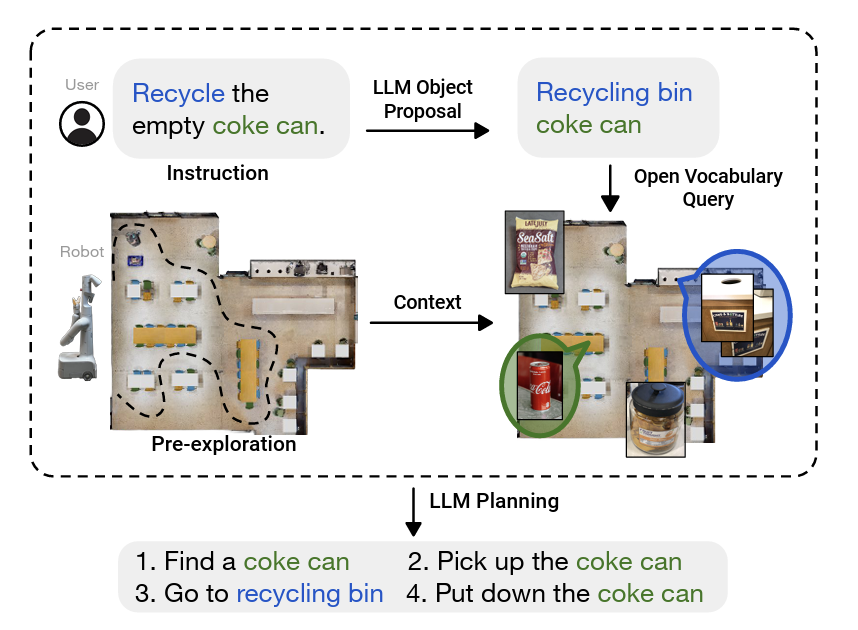
The open-vocabulary framework NLMap provides for queryable scene representations.
Localization
The task of localization is to determine the position of the robot. LEXIS [15] and FM-Loc [16] both attempt to use CLIP [17] features for indoor localization. They both use the CLIP model to encode reference objects, by mapping the view of the robots to the reference objects, they are able to achieve indoor localization. Specifically, FM-Loc [16] utilizes CLIP and GPT3 features for reference object matching, while LEXIS [15] additionally introduces a dynamic topological graph for real-time reference object matching.
Task Planning
Task planning involves dividing complex tasks into smaller, actionable steps. For the use of foundational models to achieve this, the initial attempts rely on plaintext for planning [6]. The later approaches like ProgPrompt [18] and GenSim [19] formalize the process of planning through code. Common coding structures like for-loop and function calls provide convenient ways to express high-level plans. Additionally, the form of code also helps address ambiguity and provides higher modularity and portability.
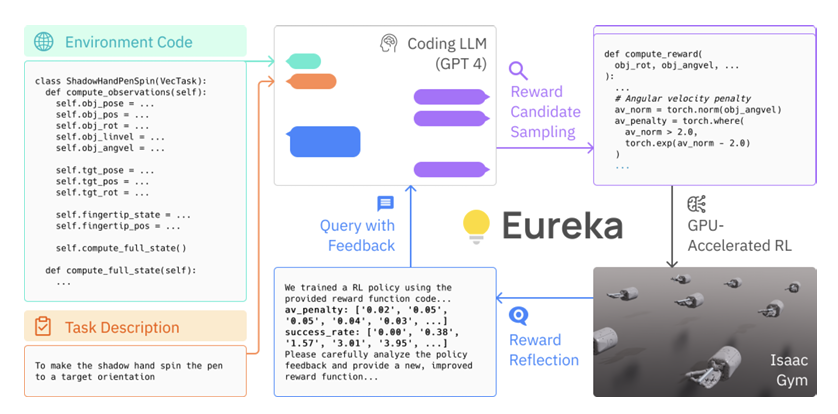
The eureka framework utilizes code structures for high-level robotic plannings.
Robotics Foundation Models
With the increased amount of robotic data sets, the class of foundation models that are native to robotics becomes more viable. Different from text and visual foundational models, which are trained on NLP and CV tasks, robotics foundation models are trained on native robotic data. The robotics foundation models are capable of taking sensory input like image, audio, and video and directly output actions that could be taken by the robot. The most prominent example includes the RT series [1], RoboCat [20], and MOO [21].
Imitation learning
There is a long history of applying imitation learning to the field of robotics. Initially, the goal is to imitate a single specific task. Then there are works like [22] [23] which aim to use imitation learning to master multiple tasks through one-shot imitation learning. In order to specify the task to be learned, there are different approaches such as through text prompts [24], goal images [25], or task vectors [26]. Recently, the main focus of this research direction is to further scale up these models. Both RoboCat [20] and RT [1] train a single model from a variety of datasource originating from multiple robots.
Reinforcement learning
The use of reinforcement learning becomes a possibility as the number of robotic datasets grows. Offline Q-learning methods like QT-OPT [27] is an early attempt to learn policy from robotics data. Recently, with the success of transformers, Q-Transformer [28] combines Q-learning with transformers, showing great potential in various robotic tasks.
Conclusion
In this study, we survey the use of foundational models for robotics. We systematically cover the challenges of foundation models for robotics and analyze the existing approaches. We will discuss the various use cases of foundation models, including perception, localization, and task planning.
References
[1] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022.
[2] Peide Huang, Xilun Zhang, Ziang Cao, Shiqi Liu, Mengdi Xu, Wenhao Ding, Jonathan Francis, Bingqing Chen, and Ding Zhao. What went wrong? closing the sim-to-real gap via differentiable causal discovery. In 7th Annual Conference on Robot Learning, 2023. 5, 17
[3] Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. Isaac gym: High performance gpu-based physics simulation for robot learning, 2021.
[4] Mayank Mittal, Calvin Yu, Qinxi Yu, Jingzhou Liu, Nikita Rudin, David Hoeller, Jia Lin Yuan, Pooria Poorsarvi Tehrani, Ritvik Singh, Yunrong Guo, Hammad Mazhar, Ajay Mandlekar, Buck Babich, Gavriel State, Marco Hutter, and Animesh Garg. Orbit: A unified simulation framework for interactive robot learning environments, 2023.
[5] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019.
[6] Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
[7] Peiqi Liu, Yaswanth Orru, Chris Paxton, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Ok-robot: What really matters in integrating open-knowledge models for robotics. arXiv preprint arXiv:2401.12202, 2024
[8] Yuchen Cui, Scott Niekum, Abhinav Gupta, Vikash Kumar, and Aravind Rajeswaran. Can foundation models perform zero-shot task specification for robot manipulation? In Learning for Dynamics and Control Conference, pages 893–905. PMLR, 2022.
[9] Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models. In 2nd Workshop on Language and Robot Learning: Language as Grounding, 2023.
[10] Jakob Gawlikowski, Cedrique Rovile Njieutcheu Tassi, Mohsin Ali, Jongseok Lee, Matthias Humt, Jianxiang Feng, Anna Kruspe, Rudolph Triebel, Peter Jung, Ribana Roscher, et al. A survey of uncertainty in deep neural networks. Artificial Intelligence Review, 56(Suppl 1):1513–1589, 2023
[11] Aaron D Ames, Samuel Coogan, Magnus Egerstedt, Gennaro Notomista, Koushil Sreenath, and Paulo Tabuada. Control barrier functions: Theory and applications. In 2019 18th European control conference (ECC), pages 3420–3431. IEEE, 2019.
[12] Bingqing Chen, Jonathan Francis, Jean Oh, Eric Nyberg, and Sylvia L Herbert. Safe autonomous racing via approximate reachability on ego-vision. arXiv preprint arXiv:2110.07699, 2021.
[13] Boyuan Chen, Fei Xia, Brian Ichter, Kanishka Rao, Keerthana Gopalakrishnan, Michael S. Ryoo, Austin Stone, and Daniel Kappler. Open-vocabulary queryable scene representations for real world planning. In arXiv:2209.09874, 2022.
[14] Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, Mohd Omama, Tao Chen, Shuang Li, Ganesh Iyer, Soroush Saryazd, Nikhil Keetha, Ayush Tewari, Joshua B. Tenenbaum, Celso Miguel de Melo, Madhava Krishna, Liam Paull, Florian Shkurti, and Antonio Torralba. Conceptfusion: Open-set multimodal 3d mapping. In arXiv:2302.07241, 2023.
[15] Christina Kassab, Matias Mattamala, Lintong Zhang, and Maurice Fallon. Language-extended indoor slam (lexis): A versatile system for real-time visual scene understanding. arXiv preprint arXiv:2309.15065, 2023.
[16] ReihanehMirjalili, Michael Krawez, and WolframBurgard. Fm-loc: Using foundation models for improved vision-based localization. arXiv:2304.07058, 2023.
[17] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, 2021.
[18] Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. ProgPrompt: Generating situated robot task plans using large language models, 2022.
[19] Lirui Wang, Yiyang Ling, Zhecheng Yuan, Mohit Shridhar, Chen Bao, Yuzhe Qin, Bailin Wang, Huazhe Xu, and Xiaolong Wang. Gensim: Generating robotic simulation tasks via large language models. In CoRL, 2023.
[20] Konstantinos Bousmalis, Giulia Vezzani, Dushyant Rao, Coline Devin, Alex X. Lee, Maria Bauza, Todor Davchev, Yuxiang Zhou, Agrim Gupta, Akhil Raju, Antoine Laurens, Claudio Fantacci, Valentin Dalibard, Martina Zambelli, Murilo Martins, Rugile Pevceviciute, Michiel Blokzijl, Misha Denil, Nathan Batchelor, Thomas Lampe, Emilio Parisotto, Konrad ˙ Zo lna, Scott Reed, Sergio G´ omez Colmenarejo, Jon Scholz, Abbas Abdolmaleki, Oliver Groth, Jean-Baptiste Regli, Oleg Sushkov, Tom Roth¨ orl, Jos´ e Enrique Chen, Yusuf Aytar, Dave Barker, Joy Ortiz, Martin Riedmiller, Jost Tobias Springenberg, Raia Hadsell, Francesco Nori, and Nicolas Heess. Robocat: A self-improving foundation agent for robotic manipulation, 2023.
[21] Austin Stone, Ted Xiao, Yao Lu, Keerthana Gopalakrishnan, Kuang-Huei Lee, Quan Vuong, Paul Wohlhart, Brianna Zitkovich, Fei Xia, Chelsea Finn, et al. Open-world object manipulation using pre-trained vision-language models. arXiv preprint arXiv:2303.00905, 2023.
[22] Yan Duan, Marcin Andrychowicz, Bradly Stadie, OpenAI Jonathan Ho, Jonas Schneider, Ilya Sutskever, Pieter Abbeel, and Wojciech Zaremba. One-shot imitation learning. Advances in neural information processing systems, 30, 2017.
[23] Chelsea Finn, Tianhe Yu, Tianhao Zhang, Pieter Abbeel, and Sergey Levine. One-shot visual imitation learning via meta-learning. In Conference on robot learning, pages 357–368. PMLR, 2017.
[24] Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning. In 5th Annual Conference on Robot Learning, 2021.
[25] Tianhe Yu, Chelsea Finn, Annie Xie, Sudeep Dasari, Tianhao Zhang, Pieter Abbeel, and Sergey Levine. One-shot imitation from observing humans via domain-adaptive meta-learning. arXiv preprint arXiv:1802.01557, 2018.
[26] Rouhollah Rahmatizadeh, Pooya Abolghasemi, Ladislau Boloni, and Sergey Levine. Vision-based multi-task manipulation for inexpensive robots using end-to-end learning from demonstration. In 2018 IEEE international conference on robotics and automation (ICRA), pages 3758–3765. IEEE, 2018.
[27] Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, and Sergey Levine. Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation. In CoRL, 2018.
[28] Yevgen Chebotar, Quan Vuong, Alex Irpan, Karol Hausman, Fei Xia, Yao Lu, Aviral Kumar, Tianhe Yu, Alexander Herzog, Karl Pertsch, Keerthana Gopalakrishnan, Julian Ibarz, Ofir Nachum, Sumedh Sontakke, Grecia Salazar, Huong T Tran, Jodilyn Peralta, Clayton Tan, DeekshaManjunath, JaspiarSinght, BriannaZitkovich, TomasJackson, KanishkaRao, ChelseaFinn, andSergeyLevine. Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions. In CoRL, 2023.