Survey on Foundation Models for Embodied Decision Making
Foundation models are reshaping embodied AI – from robots that manipulate the physical world to agents that navigate virtual environments. These models leverage vast datasets and high-capacity architectures to learn generalizable policies for perception, reasoning, and action across diverse tasks and domains. This survey reviews recent advances in vision-language-action (VLA) models for embodied decision making, covering their architectures, training pipelines, datasets, benchmarks, reasoning abilities, and current limitations, with an emphasis on cross-domain generalization and strategies for grounding abstract knowledge in embodied action.
- Introduction
- Foundation Models for Robotic Manipulation
- Foundation Models for Visual Navigation
- Dual-System Models for Humanoid Robots
- LLM-Based Reasoning and Memory in Embodied Agents
- Current Challenges
- References
Introduction
AI agents are increasingly expected to perceive, reason, and act within complex environments – whether in the physical world (robotics) or digital worlds (web and software UIs). Foundation models for embodied decision making aim to fulfill this vision by training large-scale models on diverse, multi-task data so that a single model can generalize to new tasks and situations. This follows the success of foundation models in NLP and vision, but applying them to embodied settings introduces unique challenges. Embodied tasks demand understanding of 3D spatial relationships, real-time sequential decision making, multimodal perception (vision, language, proprioception), and long-horizon planning under environment dynamics. Collecting large-scale interactive data is harder than scraping text, and evaluating generalization requires comprehensive benchmarks beyond single-task success rates.
Early efforts in embodied AI often trained specialized models per task or robot, yielding narrow expertise. For example, in robotics, it was common to train a separate policy for each manipulation skill or each navigation environment. This paradigm is now shifting: generalist agents are emerging that absorb diverse experience (across many tasks, objects, and domains) and perform a wide range of behaviors via one model. The promise is that such models exhibit positive transfer: experience on one task or embodiment can help performance on others. Indeed, recent work shows that scaling up data and model size can produce cross-task and cross-embodiment generalization not seen in smaller, siloed models. For instance, a model trained on a broad mixture of robot datasets achieved significantly higher success on each individual domain than experts trained solely on that domain.
This survey reviews key advances in foundation models for embodied decision making. We first discuss vision-language-action models for robotic manipulation, which leverage large demonstration datasets to learn general robotic skills. Next, we cover foundation models for visual navigation, enabling agents to reach goals across varied environments. We then explore specialized architectures for complex embodiments, such as humanoid robots requiring both high-level reasoning and low-level motor control. We examine efforts to integrate LLMs for planning and memory in 3D environments, bridging text-based reasoning with embodied action. Additionally, we survey progress in embodied web agents, which act within web browsers or GUI interfaces using foundation models. Throughout, we highlight the implementation details – model architectures, training pipelines, datasets, and benchmarks – and discuss the current limitations (e.g. sim-to-real gaps, long-term reasoning, safety) and open challenges. Finally, we outline promising directions for future research to realize more general, trustworthy, and capable embodied agents.
Here is a conceptual overview of the major works I will discuss in this survey:
| Paper | Primary Focus | Model Architecture | Key Innovation |
|---|---|---|---|
| RT-1 | Robotic Manipulation | Transformer | Large-scale, real-world robotic data training |
| RT-2 | Robotic Manipulation | Vision-Language-Action | Integration of web-scale knowledge |
| OpenVLA | Robotic Manipulation | LLaMA-based VLA | Open-source, accessible VLA model |
| Open X-Embodiment | Robotic Manipulation | Transformer | Large, diverse, and standardized dataset |
| ViNT | Visual Navigation | Transformer | Foundation model for general-purpose navigation |
| 3D-LLM | 3D Reasoning | LLM with 3D awareness | Injection of 3D information into LLMs |
| 3DLLM-Mem | 3D Reasoning | LLM with 3D & memory | Long-term spatial-temporal memory |
| GR00T N1 | Humanoid Robots | Transformer | Foundation model for generalist humanoid motion |
| Embodied Agent Interface | Benchmarking | N/A | Realistic and challenging benchmark for embodied agents |
| Embodied Web Agents | Conceptual Framework | N/A | Vision for integrated physical-digital AI agents |
Foundation Models for Robotic Manipulation

Overview of the RTX work. (Figure comes from RTX paper.)
One of the breakthroughs in embodied AI has been the development of large-scale robotic manipulation models that can perform many different tasks on real robots. A prominent example is Google’s Robotics Transformer (RT) series. RT-1 was a pioneering effort demonstrating that a transformer-based policy can learn hundreds of skills from a massive dataset of robot demonstrations. RT-1 takes in a sequence of images (captured from the robot’s camera over a short horizon) plus a textual task instruction, and outputs a sequence of discretized motor actions for the robot. Internally, RT-1 uses a pretrained CNN (EfficientNet) to encode vision, conditioned on language via FiLM layers, then a Token Learner module to reduce visual tokens, and finally a Transformer decoder that produces action tokens. The action space spans 7-DoF arm motions (x, y, z, roll, pitch, yaw, gripper) plus 3-DoF base motions and a discrete mode switch (to swap between base/arm control or stop). By discretizing continuous motor commands into tokens, the problem is cast into a language modeling format, enabling the use of standard transformers. RT-1 was trained on 130k real-world robot episodes (collected over 17 months with a fleet of 13 robots), covering 700+ tasks such as picking, placing, opening containers, wiping surfaces, etc.. Impressively, a single RT-1 model learned this entire multi-task repertoire, exhibiting strong generalization to novel instructions, objects, and environments. For example, RT-1 can robustly pick and place objects in cluttered scenes it had never seen during training, and execute long-horizon instructions by chaining low-level actions until the task is complete. It achieved much better success rates than prior imitation learning approaches when tested on new combinations of distractor objects and backgrounds. RT-1’s success demonstrated that open-ended, task-agnostic training at scale is a viable path toward generalist robot control.
Building on this, Google introduced RT-2, which pushes the idea of foundation models in robotics even further by directly leveraging knowledge from web-scale vision-language pretraining. The key insight of RT-2 is to incorporate a pretrained vision-language model (VLM) into the robot policy, rather than training purely on robot data from scratch. In RT-2, the robot’s perception and language understanding capabilities come from a large VLM (in fact, RT-2 used PaLM-E 12B or PaLI-X 55B as backbones), and the model is co-fine-tuned on both internet-scale image-text data (e.g. image captioning, VQA) and the robot demonstration data. To make this feasible, robot actions are represented as text: each action (the same 7+3 DoF motion as RT-1) is encoded as a string of numbers, which the model treats just like another language output. Thus, RT-2 is a “vision-language-action” (VLA) model that extends a VLM to output robot commands in the same token stream as natural language. This elegant unification allowed RT-2 to inherit a wealth of semantic knowledge and reasoning ability from web pretraining. Indeed, RT-2 demonstrated emergent capabilities far beyond the robotics data it was fine-tuned on. For example, users could ask RT-2 to “pick up the extinct animal” and, without that exact phrase ever appearing in the robot data, the model would correctly select a toy dinosaur – relying on its world knowledge that dinosaurs are extinct. It could interpret high-level modifiers like “pick up the smallest object” by leveraging visual reasoning, and even perform multi-step semantic reasoning when augmented with chain-of-thought prompting. On quantitative evaluations, RT-2 achieved a ~3× improvement in success on novel object manipulation tasks compared to RT-1, and about 2× higher generalization on broad tests of new instructions and scenes. These gains highlight the power of transferring Internet-scale knowledge into robot control. In essence, RT-2 showed that a single model can serve dual roles: both as a capable vision-language model and as an effective robotic policy.
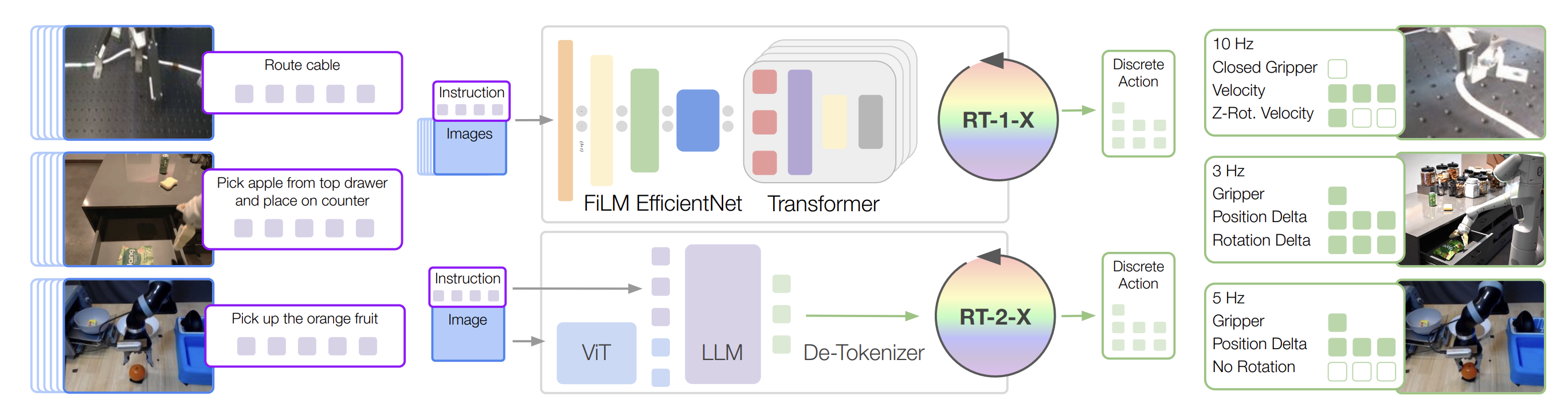
Model of the RTX work. (Figure comes from RTX paper.)
While RT-1 and RT-2 were groundbreaking, they were initially developed on proprietary data and not released, which spurred a community effort to create open counterparts. One major outcome is the Open X-Embodiment project – a collaboration of dozens of robotics labs to aggregate their datasets into the largest open robotic learning dataset to date. Open X-Embodiment (often shortened to OpenX) contains over 1 million real-world robot trajectories collected from 60+ datasets across 22 different robot embodiments. These range from single-arm manipulators (like WidowX or UR5) to bimanual humanoids and even quadrupeds, encompassing a wide variety of tasks and environments. Using this treasure trove, researchers trained open analogues of RT models: RT-1-X (an RT-1 architecture on the OpenX data) and RT-2-X (an RT-2 style VLA model on OpenX). The results demonstrate strong cross-embodiment generalization. For instance, RT-1-X, when evaluated on specific lab tasks, outperformed models trained on each lab’s data in isolation by ~50%. It learned broad skills that transfer to new settings. RT-2-X, a huge 55B parameter VLA model, achieved striking emergent abilities: it showed 3× higher success on complex, language-intensive tasks than the original closed RT-2 model. Qualitatively, RT-2-X can follow subtle linguistic variations (e.g. “move apple near the cloth” versus “move apple on the cloth”) and adjust its low-level behavior accordingly – indicating a refined understanding of spatial prepositions and their effect on action. These open models (RT-1-X, RT-2-X) provide a foundation that others can build upon without needing proprietary data.
Another notable open model is OpenVLA, a 7-billion-parameter vision-language-action model introduced by an academic–industry team. OpenVLA’s claim to fame is being fully open-source (code and model checkpoints released) while delivering state-of-the-art performance on multi-task robot control. It was pretrained on 970k trajectories from the OpenX dataset, covering a vast range of manipulation tasks and robot types. Architecturally, OpenVLA uses a fused dual-visual encoder (combining a SigLIP and DINOv2 backbone to extract image patches) whose outputs are projected into a Llama-2 7B language model. Like RT-2, it outputs actions as token sequences that are decoded into continuous joint commands. Despite its moderate size, OpenVLA achieved surprisingly strong results: zero-shot, it can control multiple robot platforms (such as a WidowX arm and a mobile manipulation robot) without retraining. On standardized tests, it outperformed prior generalist policies including RT-1-X and a model called “Octo” on these multi-robot tasks. In fact, OpenVLA even outperformed RT-2-X (55B) on many evaluations, despite RT-2-X’s much larger size, showcasing the efficiency of a well-designed 7B model trained on diverse data. For example, in tests of generalization to unseen object colors, positions, and novel instructions, OpenVLA exhibited more robust behavior (e.g. approaching the correct object among distractors, adjusting gripper orientation properly, and even recovering from failed grasps) compared to other baselines. OpenVLA also focuses on adaptability: the authors demonstrated that it can be quickly fine-tuned to new robot hardware or refined for specific tasks using parameter-efficient methods like LoRA, without needing to retrain the whole model. This is crucial for practical deployment, as it means an existing foundation model can be specialized to a new robot with relatively little data. Overall, the emergence of open models like RT-X and OpenVLA means that the community now has access to powerful pre-trained “brains” for robots, analogous to how NLP has GPT-style models. These can serve as starting points for research and applications, accelerating progress in generalist robotic agents.
Benchmarks and evaluation metrics for these robotic foundation models typically measure success on multi-step manipulation tasks and fine-grained action accuracy. For example, Google’s RT models were evaluated on hundreds of real-world trial runs to see if the instructed task was completed, as well as on “emergent” tasks not in the training data (like semantic object selection). The OpenX team introduced evaluations across different university labs, where a single model must perform each lab’s tasks (e.g. toy cleanup at Berkeley, kitchen tasks at Stanford) – a stringent test of cross-embodiment generalization. Success rates were measured both in-domain and on unseen setups (“in-the-wild”). These foundation models show a clear trend of closing the gap with human-level performance on constrained tasks, but still falter on long-horizon or compositional tasks. For instance, RT-2-X could understand spatial commands better than RT-2, yet complex sequences involving tool use or multi-object interactions remain challenging. Overall success rates often hover in the 50–80% range for moderately complex tasks, indicating there is room to improve reliability and consistency.
Current limitations in this area include data biases and real-world robustness. Because models like RT-1/2 learned from scripted or teleoperated demonstrations, they may struggle if confronted with scenarios outside the distribution of that data (e.g. truly novel objects or extreme lighting conditions). They also largely operate open-loop or with short-horizon feedback (RT-1 closes the loop at 3 Hz, which can miss fine error corrections). Handling extended decision horizons (like a 50-step assembly task) may require integrating higher-level planning (we discuss attempts at this later). Safety and failure modes are also concerns – a policy might grab the wrong object or apply excessive force if it misinterprets the goal, since it lacks explicit common-sense constraints. Efforts like policy reward fine-tuning (RLFH) and human-in-the-loop correction are being explored to address these failure modes. Despite these challenges, the progress on multi-task robotic foundation models in the past two years has been remarkable. We now turn to a different embodied domain: visual navigation, where the objective is for an agent to move through 3D environments towards goals.
Foundation Models for Visual Navigation
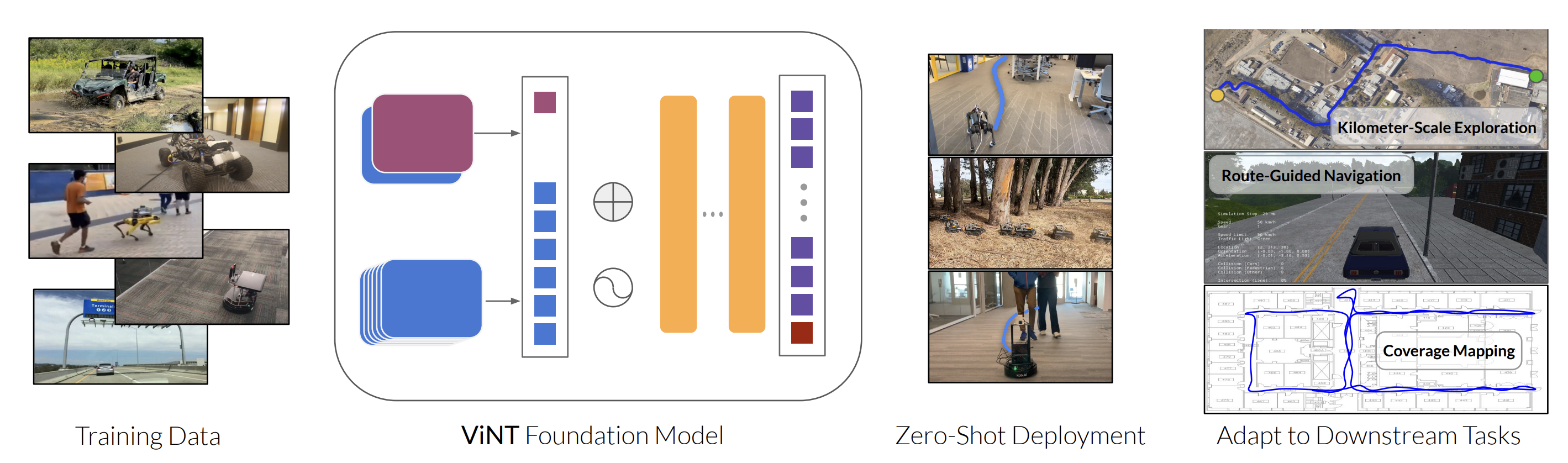
Overview of the ViNT work. (Figure comes from ViNT paper.)
Navigating through unseen environments is a core competency for embodied agents, and researchers have begun applying the foundation model paradigm here as well. A representative work is ViNT (Visual Navigation Transformer), a foundation model for goal-directed navigation introduced by Shah et al.. ViNT was trained with a general goal-reaching objective on a amalgamation of existing navigation datasets, totaling hundreds of hours of robot experience across different platforms (e.g. indoor mobile robots in houses, outdoor robots, etc.). Rather than learning a policy for one specific navigation task, ViNT learns a universal navigation policy that can be quickly adapted to many navigation-style tasks. The architecture consists of an EfficientNet-based visual encoder and a Transformer that processes the agent’s observations and a “goal specification”. Importantly, ViNT’s design is embodiment-agnostic – it outputs a normalized action command (e.g. a velocity vector or direction) that can be interpreted by different robots. This is achieved by training on data from various embodiments and finding a common representation of movement. Additionally, ViNT predicts a form of progress metric (temporal distance to goal) to help with planning.
On standard benchmarks, ViNT demonstrated positive transfer: it outperformed specialist navigation models trained on individual datasets, by leveraging commonalities across tasks. For example, a ViNT model trained on both indoor room navigation and outdoor path following did better on each than models that only saw one domain, showing the benefit of shared representations of navigational affordances. ViNT can take different forms of goals – an image of a target location, coordinates, or even a textual instruction – by swapping out the goal encoder (akin to prompt-tuning the model for new modalities). Shah et al. demonstrated that by replacing ViNT’s image-goal module with an encoder for GPS waypoints or language commands, the same policy can follow those new goal types. This modular flexibility is a hallmark of foundation models: once you have a strong core policy, you can interface it with various inputs/outputs to solve related problems.
A striking capability of ViNT is its competence in long-horizon navigation when augmented with a deliberative planner. In their experiments, the authors tackled a 1.5 km navigation task in a previously unseen city environment. ViNT alone would not plan that far, so they employed a hierarchical approach: a topological graph planner proposed intermediate subgoals, and ViNT was used to execute each segment. To generate exploratory subgoals in unknown territory, they used a diffusion model (named NoMaD) that produces candidate images of plausible nearby landmarks. ViNT evaluates which proposed subgoal is reachable and relevant (using its learned navigation heuristic h), and those subgoals are added to the plan. This combination allowed efficient exploration – the agent, guided by ViNT, naturally tended to follow sensible paths (e.g. staying on corridors or roads) even without explicit maps. Qualitatively, ViNT exhibited emergent behaviors like preferring to go through doors or down hallways rather than random wandering, presumably because it learned those patterns as efficient exploration strategies. It could also handle dynamic obstacles: for instance, navigating through a crowd of moving pedestrians by deftly avoiding collisions. Notably, all this was learned via self-supervised training on past navigation trajectories, without explicit programming of those behaviors.
To adapt ViNT to new downstream tasks, one can fine-tune part of the model with small amounts of data. The authors showed that ViNT fine-tuned on a new task (like following high-level route instructions) achieved 80% success with <1 hour of new data, whereas training from scratch would need 5× more data to reach similar performance. This indicates that ViNT learned generally useful navigation priors that speed up learning new behaviors – a key advantage of foundation models.
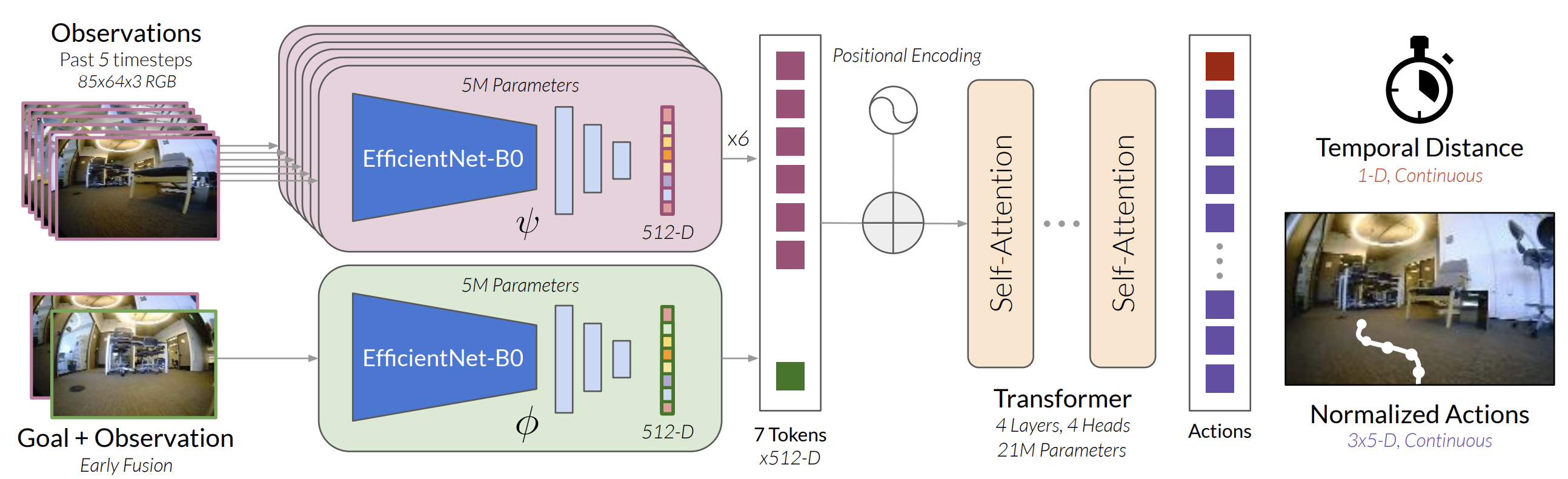
OModel of the ViNT work. (Figure comes from ViNT paper.)
Benchmarks for navigation foundation models include standard ones like Habitat or Gibson (simulated 3D environments for point-goal navigation), as well as real-world tests. The ViNT paper introduced a benchmark for long-term memory navigation (NoMaD and ViKiNG) to test exploration, and measured success at reaching distant goals, path efficiency, etc.. Another important task is Embodied QA (EQA), where an agent must navigate to gather information to answer questions (e.g. “What color is the car in the garage?”). Foundation models with built-in exploration heuristics and the ability to integrate visual and textual cues are showing progress on such integrated tasks. Still, long-range navigation in novel environments remains difficult – many models struggle if the environment is significantly larger or more complex than the training distribution, due to compounding errors or getting lost. Memory (or lack thereof) is a major issue here, as pure transformers have fixed-length context.
Current limitations in navigation models include dealing with dynamic changes (moving people or obstacles can confuse policies that never saw them in static training data) and sample efficiency in fine-tuning. Also, safety and interpretability are concerns – a navigation agent might take an unsafe route or get stuck without explaining why. Some recent works integrate semantic mapping or language explanations to improve transparency (e.g. having the agent describe its plan: “I will go down the hallway and turn left at the kitchen…”). Nonetheless, ViNT and related models mark an important step: they show that a single pretrained model can serve as a general navigator across many settings, analogous to how NLP models serve across tasks. Future work is likely to combine such visuomotor policies with higher-level reasoning (for example, asking an LLM for directions if the map is complex) – we will discuss such hybrids later.
Dual-System Models for Humanoid Robots
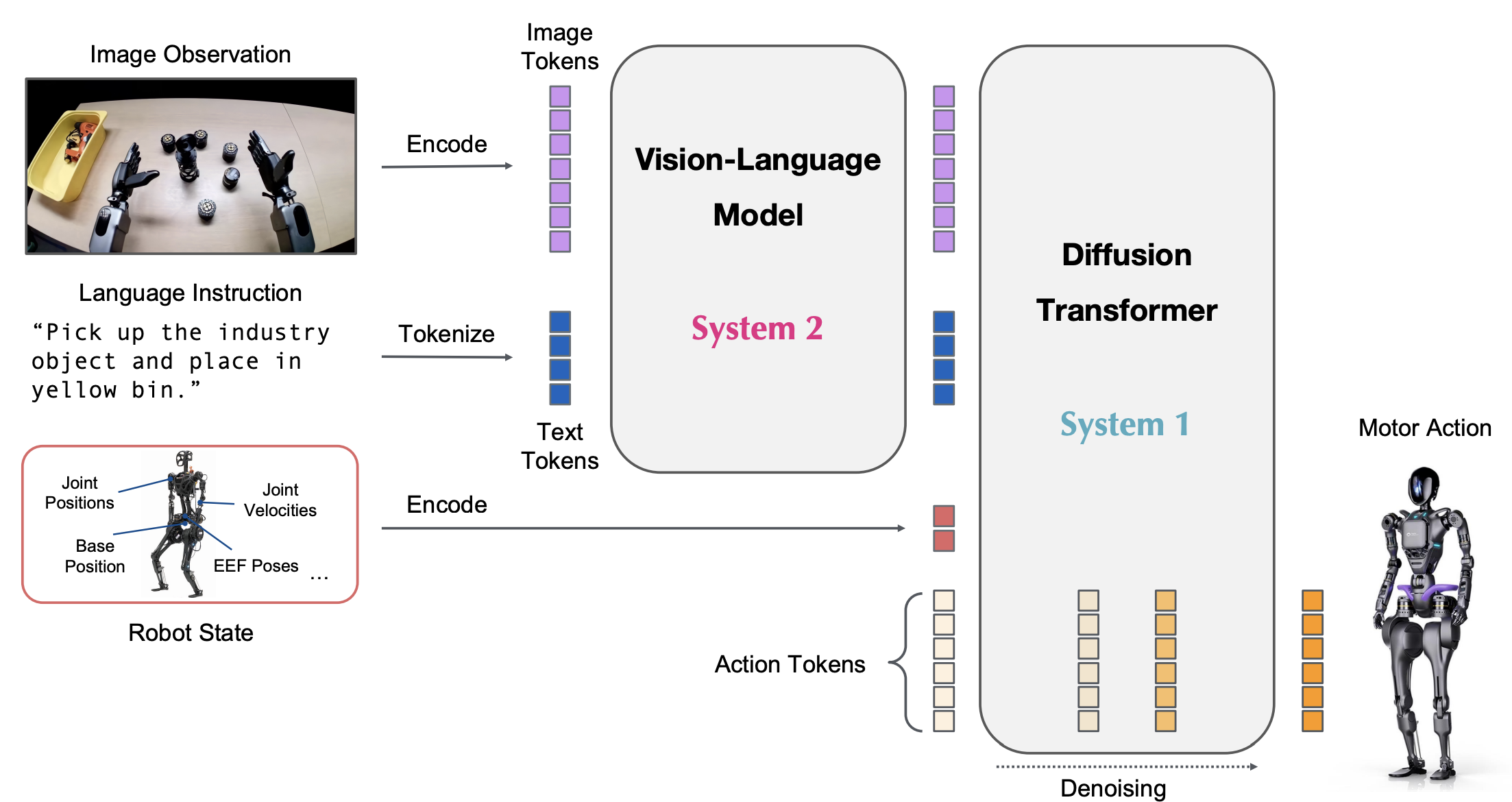
Overview of the GR00T-N1 work. (Figure comes from GR00T-N1 paper.)
Embodied intelligence in humanoid robots presents a special challenge: these robots have high degrees of freedom (multiple arms, legs, grasping mechanisms) and operate in human environments, so they require both fine-motor control and abstract reasoning. A recent milestone in this domain is NVIDIA’s Isaac GR00T N1, touted as “the world’s first open foundation model for generalist humanoid robots”. GR00T N1 (often just called GROOT) is a vision-language-action model with a dual-system architecture, explicitly inspired by cognitive theories of System 1 and System 2 thinking. In GROOT’s design, System 2 is a vision-language module that perceives the environment (through cameras) and interprets language instructions or high-level goals. System 2 effectively plans what needs to be done in a more deliberative manner, reasoning over the visual input and task context (e.g. “I need to pick up the bottle from the table and place it on the shelf”). Then, System 1 is a diffusion transformer policy that takes the plan or intermediate goal from System 2 and generates continuous low-level motor commands in real time. This split allows the model to handle both fast reflexive actions and slow, planned decisions by coupling two subsystems. Importantly, they are trained jointly end-to-end, meaning the System1–System2 interface is learned rather than hardcoded. The low-level controller (System 1) was trained heavily on synthetic data: NVIDIA leveraged Omniverse (their simulation platform) to generate a massive dataset of human demonstrations and robot trajectories for tasks like grasping, dual-arm manipulation, object handover, etc.. By supplementing real robot data with simulation, they achieved coverage of many behaviors that would be difficult to manually collect in the real world. The high-level module (System 2) is akin to a multimodal transformer that fuses camera input and language; it likely benefits from vision-language pretraining similar to VLMs, though specifics are under NDA.
GROOT N1 was evaluated both in simulation benchmarks and on a real humanoid. In simulation, it outperformed state-of-the-art imitation learning baselines on standard benchmarks across multiple robot embodiments. This suggests the dual-system approach gave it an edge in learning efficient policies. For example, on a suite of manipulation tasks requiring long sequences (e.g. pick up object A, hand it to the other hand, then place it in container B), GROOT succeeded more often and with smoother motions than prior RL or IL policies (which often failed to coordinate bimanual actions). The real proof-of-concept was deploying GROOT on the Fourier GR-1 humanoid robot, a human-sized bimanual robot. With only minimal fine-tuning using a small amount of real data, GROOT N1 was able to perform language-conditioned manipulation on the physical robot. For instance, given an instruction “pick up the box with both hands and place it on the shelf,” the robot’s cameras feed into GROOT’s vision module, the language is parsed by GROOT, and the model then controls both arms to execute the task. It achieved a high success rate on tasks like two-arm pick and place, object transfer between hands, etc., reportedly with far less real training data than would normally be required. NVIDIA also emphasized that GROOT N1 is fully open and customizable – developers can download the 2-billion-parameter model (there is a version on HuggingFace) and post-train it on their own robot or specific use case. This is significant because companies like 1X (which makes the NEO humanoid) have used GROOT as a starting point and then fine-tuned it on their robot, accelerating development. In a live demo, 1X’s robot (with a policy built on GROOT) autonomously tidied a room – picking up toys and organizing items – which was cited as evidence that the model can handle multistep domestic tasks with minimal additional training.
The dual-system strategy in GROOT highlights an embodiment strategy where the “brain” of the agent is factorized: one part reasons in a high-dimensional semantic space (vision+language), and another part handles precise control in joint space. This has advantages for humanoids where planning and control are very intertwined. It also allows injecting prior knowledge at different levels – e.g. System2 can be pretrained on vision-language data (like image captioning datasets) to imbue it with object recognition and semantic reasoning, while System1 can be trained on physics simulation data for motor skills. Such specialization can make training more sample-efficient than end-to-end black box training. However, a challenge is ensuring the two systems remain aligned; if System 2’s plan is misinterpreted by System 1, the execution could go awry. Tight coupling during training (joint loss) and large-scale data of paired perception-action is used to mitigate this.
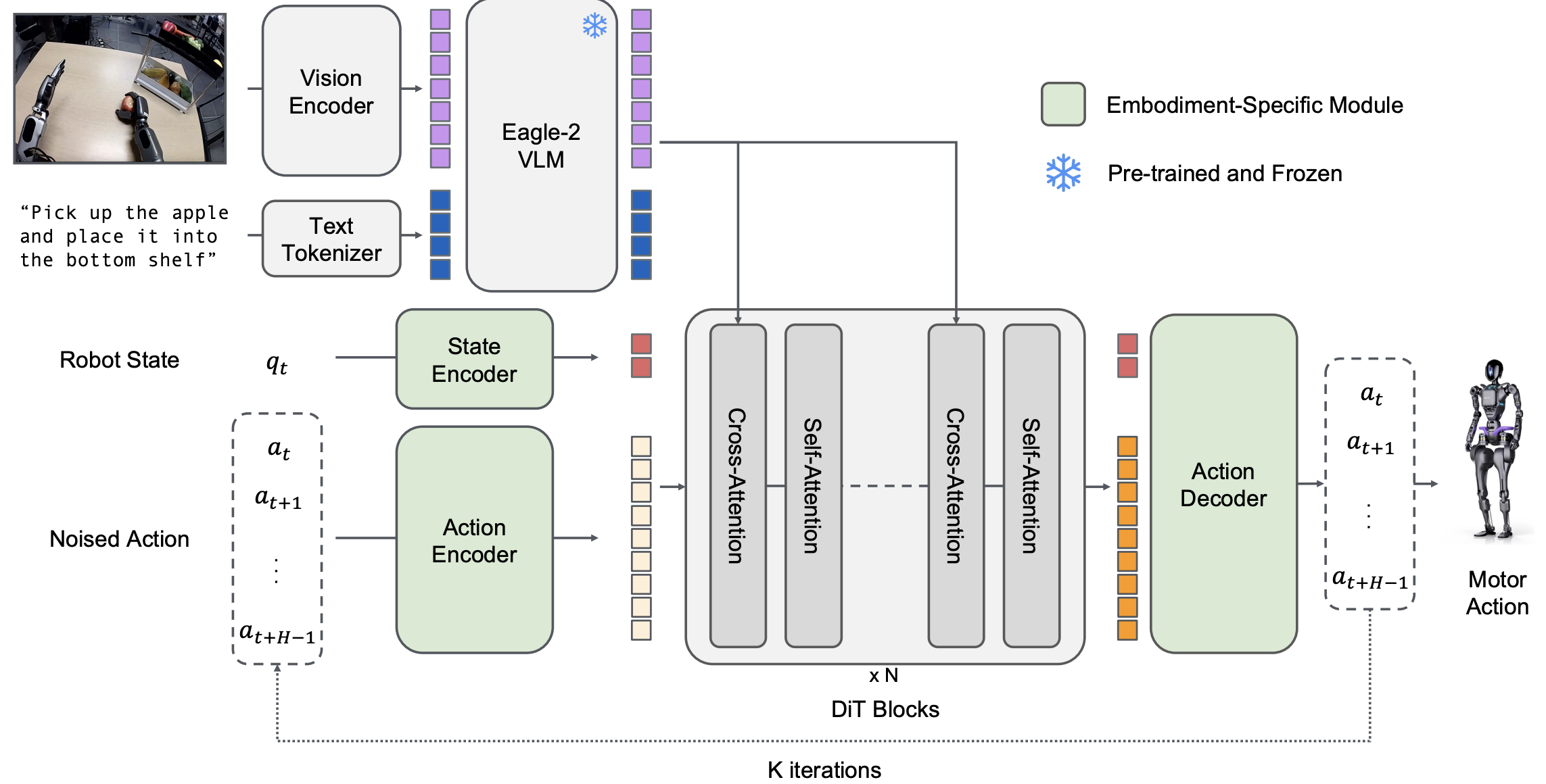
Model of the GR00T-N1 work. (Figure comes from GR00T-N1 paper.)
Benchmarks for humanoid skills are still emerging. NVIDIA reported results on a proprietary simulation benchmark, but generally we look to tasks like the Adroit hand manipulation or the DARPA Robotics Challenge tasks (locomotion + manipulation) for inspiration. Metrics often involve success rates of complex sequences and the fluidity/naturalness of motion (since a humanoid should ideally move in a human-like way for safety and acceptance). Human evaluators may also judge outcomes (does the robot clean the room correctly, etc.). GROOT N1’s introduction is very recent (2025), so its full impact will be seen as others adopt it.
Limitations of current humanoid foundation models include the sim-to-real gap – even with lots of synthetic data, subtle differences in reality (friction, delays, unmodeled dynamics) can cause failures. Fine-tuning on real data is essential, and how much is needed is an open question. Moreover, humanoids operate in unstructured environments where safety is paramount; foundation models have a tendency to occasionally produce out-of-distribution actions, which on a heavy robot could be dangerous. Therefore, researchers stress the need for safety controllers or guardrails (e.g. monitoring forces, emergency stop conditions) around these policies. Another limitation is multi-step long-term reasoning: GROOT can execute multi-step tasks it was trained on, but if asked to do something truly novel that requires improvisation, it might fail or do something unpredictable. Integrating explicit symbolic reasoning or on-the-fly planning (perhaps by having System2 internally simulate or prompt itself, like chain-of-thought) could enhance this, but it’s not yet standard. Despite these challenges, GROOT N1 showcases a promising pathway to general-purpose humanoid helpers, combining the strengths of high-level LLM-style reasoning with low-level control proficiency in one learning framework.
LLM-Based Reasoning and Memory in Embodied Agents
Overview of the 3D-LLM-Mem work. (Figure comes from 3D-LLM-Mem paper.)
A notable trend is the integration of large language models (LLMs) for planning, reasoning, and memory within embodied agents. While the previously discussed models (RT, ViNT, GROOT) do incorporate language and vision, they are primarily trained end-to-end on behavioral cloning or reinforcement objectives. In contrast, some works explicitly use LLMs as a cognitive component that reasons about the environment and decides on actions in a more interpretable way. Two important concepts here are 3D-LLMs – language models grounded in 3D environments – and architectures that equip agents with explicit memory of past interactions.
One line of research asks: Can we inject 3D understanding into an LLM such that it can handle spatial tasks through language? An example is 3D-LLM (Injecting the 3D World into LLMs) by Hong et al.. This work created a family of models that take 3D scene data as input (point clouds or multi-view images) and produce language outputs to accomplish tasks like describing the scene, answering questions about it, or even generating plans for interaction. They curated over 300k 3D-language pairs across tasks including 3D captioning (describe a scene), dense captioning (describe all objects in a scene), 3D question answering, and even instructing navigation or manipulation in the scene. The 3D input is processed via a 3D feature extractor: essentially, they render the point cloud from multiple views and use 2D vision models to extract features, which are then fused. A pretrained VLM (vision-language model) is used as the backbone, with special prompting mechanisms to encourage it to capture spatial information (they introduce a 3D localization module within the model). The result is a model that, for example, can look at a 3D scan of a room and answer, “How many chairs are around the table and what is on the table?” by examining the geometry and contents in the 3D space – something 2D models struggle with. On a benchmark called ScanQA (questions on 3D indoor scans), 3D-LLM improved scores significantly (e.g. +9 BLEU-1 over prior SOTA), showing it better understands spatial language grounding. Moreover, it demonstrated capabilities beyond those of traditional VLMs: e.g. task decomposition (breaking down an instruction into sub-tasks in a Minecraft-like 3D environment) and 3D-assisted dialog (conversing about a scene with awareness of 3D context). This indicates that grounding language in 3D perception helps the model reason about affordances and physical relations (e.g. knowing that an object is behind another, or that you need to open a drawer before grabbing something inside). While 3D-LLM is not an acting agent per se (it doesn’t directly output a robot command, except in some navigation experiments), it provides a bridge: an LLM that “understands” a 3D world can be used to plan high-level steps for an embodied agent.
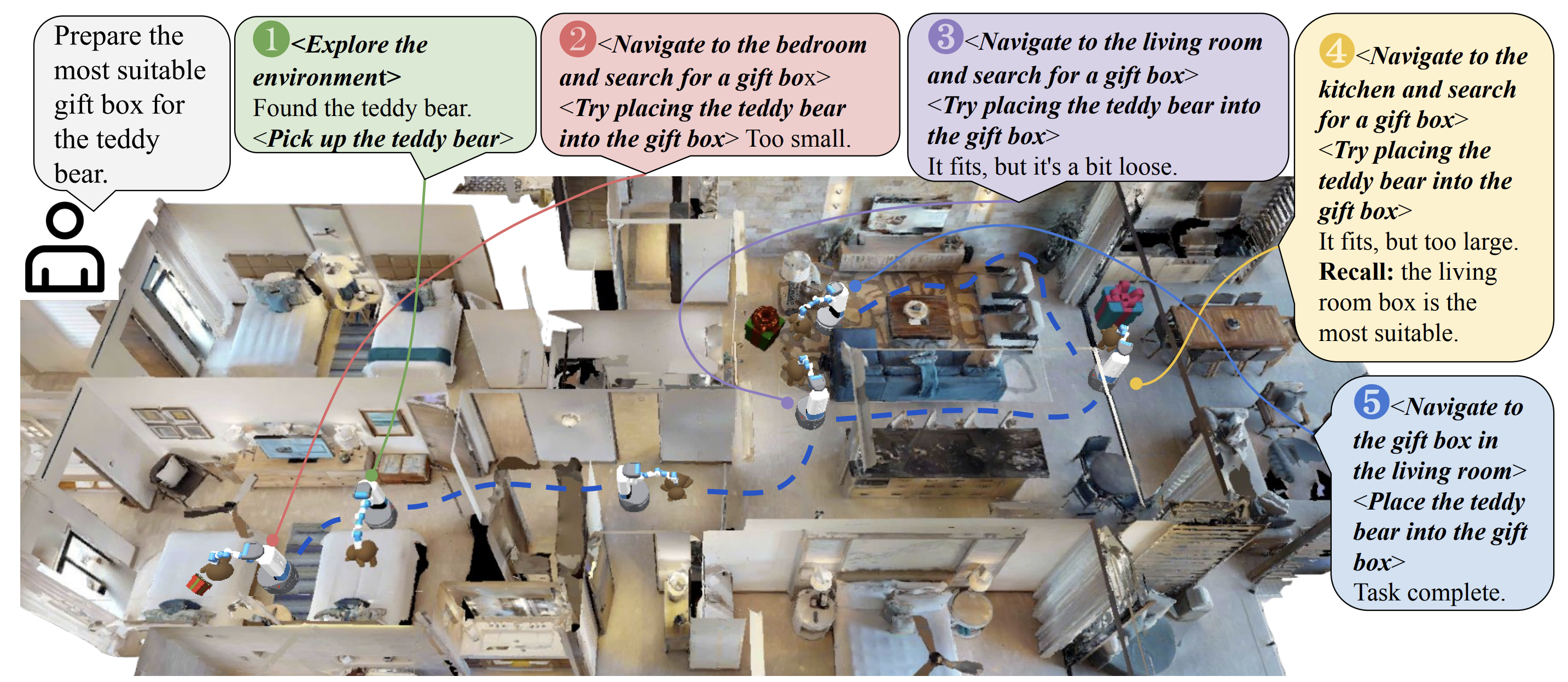
Extending this idea, researchers have asked how an LLM-based agent can maintain long-term memory of a 3D environment as it explores. Consider an agent that goes through a multi-room house – it needs to remember where it saw certain objects, which doors were open, etc., especially for tasks like “find all the mugs in the house” which requires recalling past observations. A recent work addressing this is 3DLLM-Mem: Long-Term Spatial-Temporal Memory for Embodied 3D LLMs by Zhen et al. (2025). They identify that current 3D-LLM or VLA agents have limited context and struggle to handle tasks that span multiple rooms or extended time. To benchmark this, they created 3DMem-Bench, a suite of embodied tasks in Habitat requiring agents to navigate multi-room scenes and remember information (like locations of objects) to answer questions or accomplish goals. For example, an agent might be tasked to “Find the largest gift box that can fit a teddy bear and bring it to the living room” – it must explore all rooms, note various gift boxes and their sizes, and recall which was largest and where it was. In such tasks, naive agents either forget earlier observations or run out of context window if they try to stuff everything into a prompt.
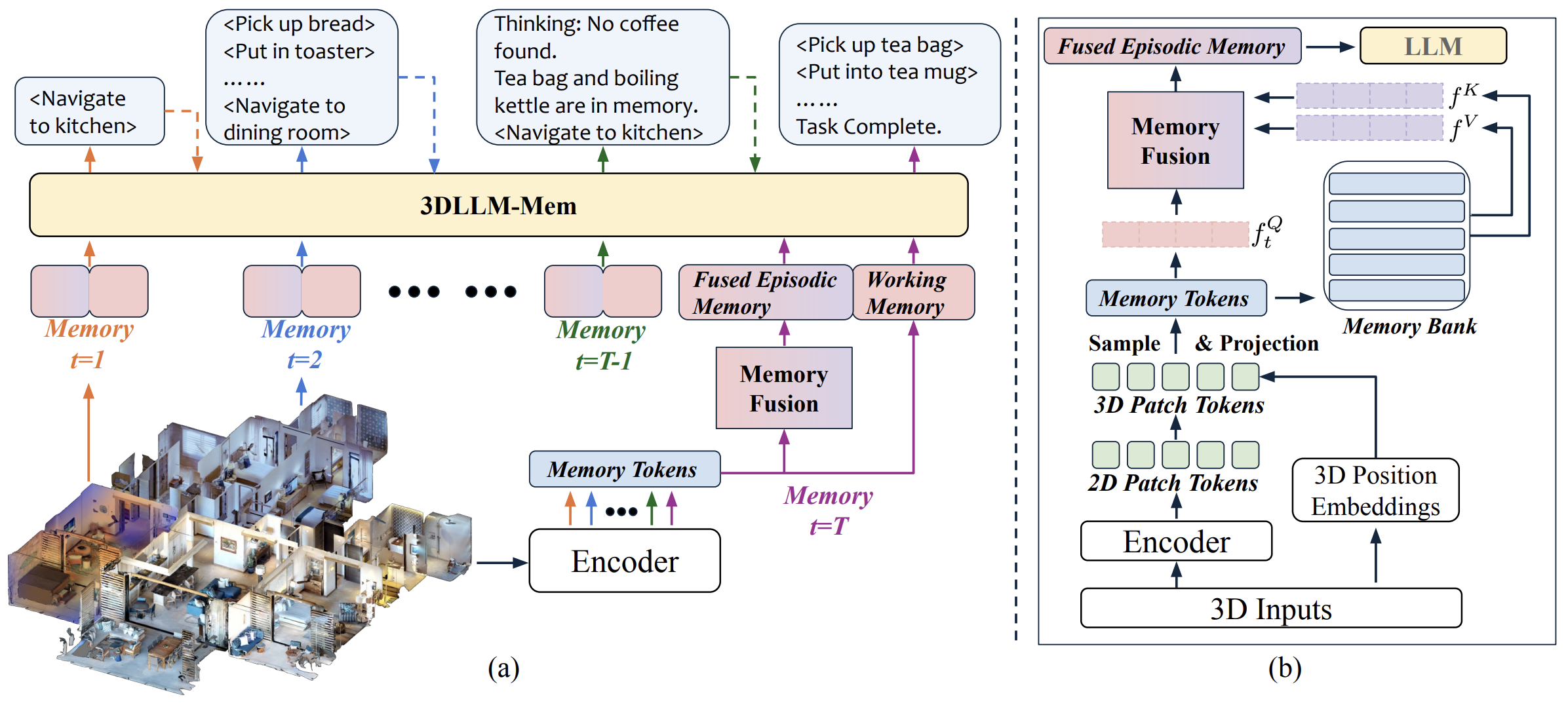
Model of the 3D-LLM-Mem work. (Figure comes from 3D-LLM-Mem paper.)
3DLLM-Mem addresses this by implementing a dual-memory system inspired by human working vs. long-term memory. The agent has a limited-capacity working memory that holds the current observation (e.g. the immediate scene view, recent sensor readings) and an episodic memory store that can accumulate embeddings of past important observations. When the LLM (which is controlling the agent’s decisions) needs to reason, it uses the current observation as a query to retrieve relevant bits of the episodic memory (using attention mechanisms). A memory fusion module then selectively integrates those past features with the current input to produce a combined context for the LLM. In essence, the agent builds a 3D cognitive map over time – storing spatial features of visited areas and objects – and queries it as needed. This architecture allowed the model to maintain coherence over very long trajectories (visiting ~18 rooms) and not forget critical details. On 3DMem-Bench, 3DLLM-Mem achieved state-of-the-art results, outperforming the best baseline by 16.5% in success rate on the hardest tasks. Notably, while other methods’ performance collapsed to around 5% success on the most challenging “in-the-wild” scenarios (new house layouts with tricky goals), 3DLLM-Mem still managed about 28% success – a huge improvement. This shows much stronger generalization and scalability in long-horizon reasoning. A concrete example from their results: previous models might enter 10 rooms and then incorrectly recall where an item was seen, leading to failure. The memory-enhanced model correctly remembered that “the red box was in the second bedroom” even after exploring the whole house, and planned its return path to that room, thus succeeding in the task. Figure 1 of their paper illustrates the agent progressively building a memory (with snapshots of each room and found objects) and using it to decide where to go next.
These approaches (3D-LLM and 3DLLM-Mem) reflect a broader theme: combining the symbolic-like reasoning of LLMs with the embodied knowledge of 3D environments. Rather than treating the policy as a black-box neural network, they let an LLM think through actions (often by producing intermediate text, like “I should go to the kitchen next because I haven’t checked there for a mug”). Indeed, many experimental systems use techniques like chain-of-thought prompting for decision-making in embodied tasks. For example, one can prompt an LLM with a formatted memory of events (e.g. “Room1 had a mug on the table. Room2 had no mugs. Goal: find a mug.”) and have it reason (“I found a mug in Room1, so I should bring that.”) to output a high-level plan. This can then be executed by a low-level controller.
A related development is the Embodied Agent Interface (EAI), a standardized framework to evaluate LLM-based modules on embodied tasks. EAI defines four “ability modules” for an embodied agent using an LLM: Goal Interpretation, Subgoal Decomposition, Action Sequencing, and Transition Modeling. Essentially, it breaks the problem down: (1) interpret the high-level instruction in terms of environment entities (ground the language to objects/states), (2) decompose the task into a sequence of intermediate state goals, (3) generate a sequence of low-level actions to achieve each state transition, and (4) execute those actions with a model of how the environment changes. By evaluating each module separately (with fine-grained metrics like correctness of goal parsing, logical consistency of plans, hallucination rate, etc.), EAI can pinpoint where an LLM might be failing in an embodied reasoning loop. For example, an LLM might be great at breaking a task into steps but poor at predicting the outcome of an action (transition model), leading to errors. This framework was used to benchmark several LLMs on tasks in a household simulator (like ALFRED environment) and revealed interesting weaknesses – e.g., some LLMs hallucinate non-existent objects (affordance errors) or make logically impossible plans (planning errors). By identifying these, researchers can then target improvements, such as incorporating physical commonsense knowledge into the model or adding verification steps. EAI doesn’t introduce a new model per se, but it’s a valuable tool to measure reasoning capabilities of embodied foundation models and thus drive progress.
In summary, LLM-based embodied agents attempt to bring the strengths of language models (flexible reasoning, memory via text, abstract knowledge) into contact with the grounded experience of embodied AI. We see early evidence that this yields more interpretable and generalizable behaviors – e.g., an agent that can explain its plan and remember what it did hours ago, which pure end-to-end policies typically cannot. However, combining these paradigms is challenging: LLMs are prone to hallucination and are not natively designed for continuous control. The work on 3DLLM-Mem shows that augmenting them with proper perception modules and memory structures can mitigate some of these issues, enabling them to operate over long durations without losing track. Still, performance is far from perfect; an average success of 32% on hard tasks means substantial failure rates remain. Solving this will likely require further advancements in neural-symbolic methods, better training of LLMs on procedural knowledge, and tighter integration between the “mind” (LLM planner) and “body” (control policy) of agents – an active area of research.
Current Challenges
Despite the rapid progress, foundation models for embodied decision making are still in their infancy compared to their NLP counterparts. We conclude by highlighting key challenges and limitations and discussing promising future directions:
-
Generalization vs. Specialization: Embodied foundation models must strike a balance between broad generalization and specialist accuracy. A model like RT-2 or OpenVLA is trained on many tasks, but when faced with highly specialized or safety-critical tasks (e.g. surgery robotics, or an unusual website UI), they may underperform a specialized system. Future models may incorporate meta-learning or few-shot learning abilities to quickly adapt to new tasks or domains with minimal data. Few-shot adaptation has shown promise (e.g. ViNT adapting to novel goal modalities), and extending this across embodiments is an open research area.
-
Data and Simulation: High-quality data is the fuel for these models. Physical data collection is expensive and slow. Simulation and synthetic data generation will continue to play a vital role. Projects like Open X-Embodiment pooled many datasets, but there are still gaps (for instance, limited data on deformable object manipulation or crowd navigation). Advances in simulation (like NVIDIA’s Omniverse and the Newton physics engine co-developed with DeepMind and Disney) will help create more realistic training scenarios. However, sim-to-real transfer remains challenging – future work may focus on better domain randomization and real-to-sim calibration to ensure policies transfer smoothly to real hardware without regression.
-
Long-Horizon Reasoning and Memory: As seen with 3DMem-Bench and EAI, current models struggle with long tasks that require remembering past events or planning many steps ahead. Incorporating explicit memory modules (as 3DLLM-Mem did) and hierarchical planning (as in ViNT’s diffusion-based planner) are promising approaches. We expect more work on hierarchical agents where a high-level policy (possibly an LLM) sets subgoals and a low-level policy executes them, with feedback loops in between. Additionally, lifelong learning – agents updating their knowledge as they operate – could allow an embodied agent to avoid repeating mistakes or to handle environment changes over time.
-
Multimodal Integration and Embodiment Variability: Embodied agents may benefit from additional modalities beyond vision and text. Audio perception (e.g. a robot hearing a timer go off, or an assistant hearing a user’s verbal request) is one avenue. Tactile feedback for robots, or reading on-screen documents for web agents (combining visual and textual inputs), are others. Furthermore, models that can cover multiple embodiments (as OpenX attempts) need architectures flexible enough to represent, say, both a drone’s flying actions and a hand’s grasping actions. Techniques like dynamic action tokens or multiple “heads” for different embodiment types might be expanded.
-
Safety, Robustness, and Ethics: When deploying embodied agents, especially in the physical world, safety is paramount. Foundation models tend to be black boxes, making it hard to guarantee they won’t take an unsafe action if they encounter an unforeseen scenario. Future work likely needs to integrate constraint-aware planning or verifier modules (for instance, a module that checks a candidate action against safety rules before execution). There’s also the question of value alignment – ensuring the agent’s decisions align with human intents and ethical norms. This might involve incorporating reward modeling or human feedback (RLHF/RLFH) specifically targeting safety and compliance. In digital domains, issues of privacy (e.g. an agent browsing user data) and security (the agent should not execute harmful operations) need attention. Researchers are exploring explainable policies to increase trust, where an agent can explain why it took an action in human-understandable terms.
-
Benchmarking and Evaluation: As embodied foundation models become more capable, comprehensive benchmarks are needed to track progress. These benchmarks should test not only success rates but also adaptability (zero-shot tasks), robustness (noisy inputs, perturbations), and long-term reliability. We might see standardized test suites that include mixes of physical and digital tasks to evaluate truly general agents. Open-source platforms (similar to OpenAI Gym but for multi-modal embodied tasks) and challenge competitions can incentivize development of agents that excel across tasks and domains. Additionally, evaluation metrics need to capture not just success, but efficiency, safety, and human satisfaction.
In conclusion, foundation models are driving a convergence of techniques from machine learning, robotics, and cognitive systems toward the goal of generalist embodied agents. We have surveyed how models like RT-2 and GROOT integrate high-level knowledge with low-level control, how ViNT and OpenVLA achieve breadth across tasks, and how LLM-based components add reasoning and memory to embodied AI. The field is moving fast: what was science fiction a few years ago – say, telling a household robot in natural language to perform a complex chore – is now partially realized by combining these advances. Significant work remains to make these systems truly reliable, safe, and general. However, the momentum suggests that AI capable of seamless decision making across the physical and digital worlds is on the horizon. By continuing to refine these foundation models and addressing the open challenges, researchers are steadily unlocking an era where AI agents can understand our goals, learn from their experiences, and autonomously act to assist us in both real and virtual environments.
Future Work
Several promising avenues can drive the next generation of embodied foundation models:
-
Improved Generalization: Developing agents capable of quickly adapting to unseen situations (new objects, new websites, new tasks) via few-shot learning or meta-learning will be critical. This includes cross-modal generalization – e.g. leveraging knowledge learned in simulation to handle real-world variations seamlessly.
-
Continuous Learning: Enabling agents to learn continuously from their interactions (and mistakes) in the field, rather than being fixed after offline training. Techniques like reinforcement learning with human feedback, or self-supervised skill discovery (letting a robot play with its environment to discover new behaviors), could vastly expand an agent’s capabilities over time.
-
Enhanced Reasoning and Planning: Integrating more powerful reasoning modules, potentially via advanced LLMs, to handle long-horizon planning, causal reasoning, and abstract problem solving. This could involve hybrid systems where symbolic planners work alongside neural policies, or where agents can simulate outcomes (mental rehearsal) before acting.
-
Multimodal and Human-Agent Interaction: Extending embodiment to interact with humans and interpret more modalities. For example, an embodied agent might take spoken natural language instructions combined with gestures, or use haptic feedback to adjust its strategy. Developing mixed-initiative interaction, where the agent can ask clarification questions or get advice from humans when unsure, will improve practicality.
-
Safety and Ethics: Embedding safety constraints directly into model objectives, and creating rigorous testing protocols for failure modes. Future models may include certifiable action filters or employ verifiable control subroutines for critical tasks. Work on value alignment – ensuring agents act in accord with human values – is essential as these agents become more autonomous. This could include training with human demonstrations that reflect ethical choices, and using AI explainability tools to audit an agent’s decision rationale for bias or risks.
-
Benchmarking Ecosystem: Establishing standard benchmarks and simulation frameworks that cover a wide spectrum of embodied tasks will allow the community to measure progress. Open-source platforms (similar to OpenAI Gym but for multi-modal embodied tasks) and challenge competitions can incentivize development of agents that excel across tasks and domains. Additionally, evaluation metrics need to capture not just success, but efficiency, safety, and human satisfaction.
By pursuing these directions, we inch closer to AI agents that possess the general-purpose problem-solving skills of LLMs, grounded in the sensory-motor capabilities of robots and digital assistants. The convergence of these technologies holds the promise of truly versatile assistants – ones that can navigate both our physical surroundings and our digital lives, to augment our abilities and free us from routine decision making. The research surveyed here provides a strong foundation, and the coming years will undoubtedly bring even more exciting breakthroughs on this journey toward embodied intelligence.
References
-
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Ryan Julian, Dmitry Kalashnikov, Sergey Levine, Yao Lu, Igor Mordatch, Ofir Nachum, Kuang-Huei Lee, Karl Pertsch, Jornell Quiambao, Kanishka Rao, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Kevin Sayed, Clayton Tan, Vincent Vanhoucke, Quan Vuong, Fei Xia, Ted Xiao, Tianhe Yu. RT-1: Robotics Transformer for Real-World Control at Scale.
-
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof M. Choromanski, Danny Driess, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Ryan Julian, Dmitry Kalashnikov, Sergey Levine, Lisa Anne Hendricks, Henryk Michalewski, Karl Pertsch, Kanishka Rao, Krista Reymann, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Pierre Sermanet, Jaspiar Singh, Anikait Singh, Radu Soricut, Ted Xiao, Quan Vuong, Fei Xia, Sichun Xu, Tianhe Yu. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control.
-
Open X-Embodiment Collaboration (hundreds of contributing authors across 22 robot embodiments). Open X-Embodiment: Robotic Learning Datasets and RT-X Models.
-
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, Chelsea Finn. OpenVLA: An Open-Source Vision-Language-Action Model.
-
Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Stachowicz, Kevin Black, Noriaki Hirose, Sergey Levine. ViNT: A Foundation Model for Visual Navigation.
-
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi (Jim) Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang Tan, Guanzhi Wang, Zu Wang, Jing Wang, Qi Wang, Jiannan Xiang, Yuqi Xie, Yinzhen Xu, Zhenjia Xu, Seonghyeon Ye, Zhiding Yu, Ao Zhang, Hao Zhang, Yizhou Zhao, Ruijie Zheng, Yuke Zhu. GR00T N1: An Open Foundation Model for Generalist Humanoid Robots.
-
Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Yu Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Li Erran Li, Ruohan Zhang, Weiyu Liu, Percy Liang, Li Fei-Fei, Jiayuan Mao, Jiajun Wu. Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making.
-
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, Chuang Gan. 3D-LLM: Injecting the 3D World into Large Language Models.
-
Haoyu Zhen, Yining Hong, Wenbo Hu, Yanjun Wang, Leison Gao, Zibu Wei, Xingcheng Yao, Nanyun Peng, Yonatan Bitton, Idan Szpektor, Kai-Wei Chang. 3DLLM-Mem: Long-Term Spatial-Temporal Memory for Embodied 3D Large Language Models.
-
Hanyu Lai, Xiao Liu, Iat Long Iong, Shuntian Yao, Yuxuan Chen, Pengbo Shen, Hao Yu, Hanchen Zhang, Xiaohan Zhang, Yuxiao Dong, Jie Tang. AutoWebGLM: A Large Language Model-based Web Navigating Agent.
-
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, Yuquan Deng, Lars Liden, Jianfeng Gao. Magma: A Foundation Model for Multimodal AI Agents.
-
Fei Tang, Hang Zhang, Siqi Chen, Xingyu Wu, Yongliang Shen, Wenqi Zhang, Guiyang Hou, Zeqi Tan, Yuchen Yan, Kaitao Song, Jian Shao, Weiming Lu, Jun Xiao, Yueting Zhuang. A Survey on (M)LLM-Based GUI Agents.