Survey on Vision-Language-Action Models for the Digital World
Vision-Language-Action (VLA) models are emerging as generalist agents that can see, read, and act within graphical user interfaces. These models bridge computer vision, natural language, and reinforcement learning to enable AI systems to perceive screen content and execute UI actions. This survey reviews the latest developments in VLA models for digital environments, from early text-based approaches to today’s fully vision-driven agents with advanced reasoning, and discusses their benchmarks, innovations, results, and open challenges.
- Introduction
- Prior Works
- Problem Formulation
- Proposed Methods and Evaluation
- Experiments and Results
- Discussion
- Conclusion
- Links
- References
Introduction
Modern AI assistants are expanding beyond chat and code generation into the realm of digital action, performing tasks on computers and mobile devices by operating graphical user interfaces (GUIs). The goal is to create Vision-Language-Action (VLA) models (also known as GUI agents or computer-use agents) that can interpret natural language instructions, visually perceive the screen like a human, and execute actions (clicks, typing, scrolling) to accomplish tasks on apps and websites[17, 25]. These agents promise to automate routine digital tasks, enhance accessibility, and serve as “copilots” for knowledge work.
Early efforts in this domain relied on structured data like HTML DOMs or accessibility trees to locate interface elements. While effective in constrained settings (e.g., web form automation via DOM), these text-based approaches faced limitations: they require platform-specific access, often miss visual context (images, layout), and break easily if the UI changes[2, 7]. Moreover, treating GUI control as a purely text (or API) problem ignores how humans naturally use interfaces by looking at the screen and reacting visually. This has led to a paradigm shift: from reading underlying code to seeing pixels on the screen. Recent VLA models embrace a “pure vision” embodiment, taking screenshots as input and learning to act from what they see[6].
Concurrently, advances in multimodal large language models (MLLMs) have fueled VLA progress. Vision-augmented LLMs like GPT-4V, PaLM-E, and others demonstrated that language models can be taught to reason about images and even plan actions. This inspired researchers to integrate screen vision with action policy learning, creating unified models that understand UI screenshots and output action commands. By leveraging large-scale pretraining and fine-tuning on human demonstrations, these systems began to generalize across websites, apps, and devices [1]. Today, VLA agents can handle diverse tasks from filling web forms and navigating settings menus to editing documents and operating complex software, all through a single model interface that sees and acts on the GUI.
This survey provides a comprehensive overview of the state of the art in Vision-Language-Action models for the digital world. We start by formulating the problem and describing common benchmarks. We then discuss key model architectures and learning approaches including vision-centric grounding models, large multimodal action models, and reinforcement learning fine-tuning for reasoning. We highlight representative systems (e.g., CogAgent[1], ShowUI[3], UI-TARS[25], OS-Atlas[8], Aguvis[15], Omini-Parser[13], GUI-R1[10] and others) and their innovations. Next, we summarize experimental results on standard benchmarks (like Mind2Web[18], ScreenSpot[6], AITW[17], etc.) and analyze current performance. Finally, we discuss challenges (such as generalization, data efficiency, and reasoning) and suggest directions for future work toward more generalist embodied agents in the digital domain.
Prior Works
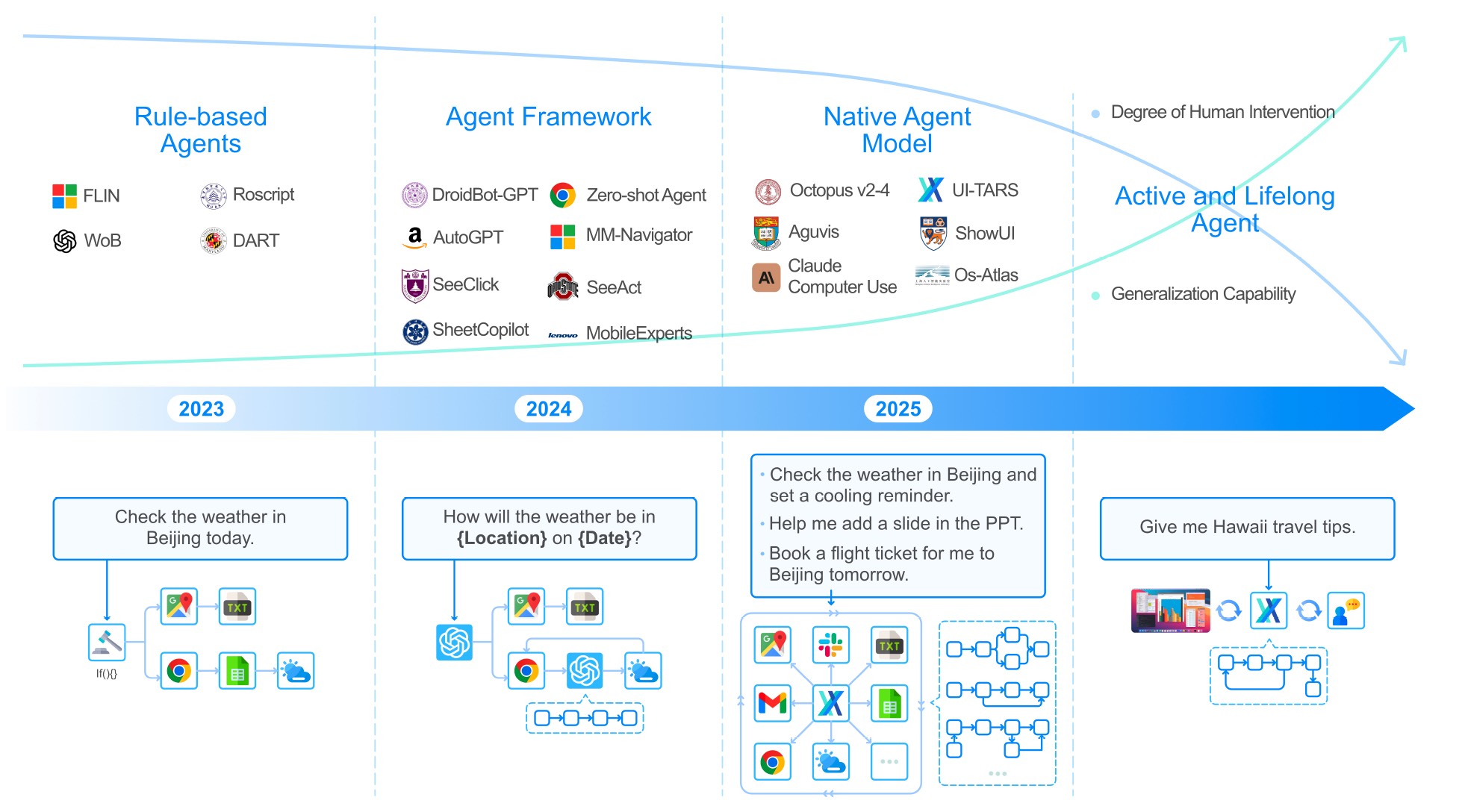
Early GUI automation agents largely relied on rule-based or template-based methods. For instance, scripting tools and robotics process automation (RPA) systems could follow predefined sequences of clicks/keystrokes but lacked flexibility. Academic efforts like MiniWoB provided a web environment to train agents on simple web tasks (e.g., form-filling) via reinforcement learning. These agents treated the web page as a DOM tree and learned policies to manipulate it, but they struggled with generalization beyond the toy environment. Similarly, mobile UI automation datasets in the early stage often assumed access to UI element structures (view hierarchies) or used computer-vision templates to locate buttons, which didn’t scale well across apps.
A notable shift occurred as large language models rose to prominence. Researchers began using LLMs (like GPT-4) with prompt-based planning for GUI tasks. For example, having an LLM parse a web page’s HTML and decide actions, as seen in early web agents. However, without fine-tuning on GUI data, these approaches had limited success. They also relied on textual representations, inheriting the limitations mentioned earlier (fragility to layout changes, incomplete info, etc.).
Then, the community recognized that a more human-like approach that seeing the rendered interface was needed. This gave rise to vision-based GUI agents. The first wave of such models still often separated the problem into modules: a visual parser to extract screen elements and an LLM planner to choose actions [6, 13]. While this incorporated visual cues, the pipeline was complex and error-prone[7].
The latest works, in contrast, moves toward end-to-end trainable models that directly map screenshots and instructions to actions. Pioneering work like SeeClick emphasized GUI grounding, the ability to locate UI elements from textual descriptions, as the key challenge for vision-based agents. SeeClick introduced the idea of pretraining a model on synthetic GUI grounding data, then fine-tuning it on actual task demonstrations. SeeClick utilized some benchmarks like Mind2Web[18], which is a benchmark of over 2,000 web tasks paired with crowd-sourced action sequences. Mind2Web underscored the need for agents that can handle open-ended web tasks and provided a platform to evaluate generalist web agents.
Another strand of prior work came from the robotics domain. Vision-language-action models had been explored for physical robots (e.g., say an instruction and have a robot manipulate objects). Techniques like RT-2 showed that web-scale vision-language pretraining could help robots act in the real world. Insights from those efforts such as the importance of grounding language in vision and the use of reward fine-tuning have cross-pollinated into GUI agents. For example, the concept of reinforcement fine-tuning (RFT) with verifiable reward signals (popular in robotics and reasoning tasks) was applied to GUI agents in works like UI-R1, InfiUI-R1 and GUI-R1. These works demonstrated that training an agent to maximize task-specific rewards (like successful clicks, correct type prediction, and correct output format) can greatly improve its planning abilities even with limited data.
In summary, the field has evolved from template-based and text-based UI agents to vision-based and learning-based agents. Early attempts established the problem and provided simulation benchmarks. The introduction of multimodal LLMs and large-scale datasets enabled more general solutions, culminating in the current focus on end-to-end vision-language models that see the GUI and decide actions directly. Below, we formalize this problem setting and then delve into the methods that are driving progress in this exciting area.
Evolution of GUI Agents.(Figure comes from UI-TARS)
Problem Formulation
A Vision-Language-Action (VLA) GUI agent operates in a partially observable Markov decision process where the state is the GUI screen image, the actions are UI operations, and the goal is to fulfill a high-level task specified in natural language. Formally, at each time step t the agent receives: (1) an instruction I (e.g., “Book a flight from NYC to LA on the travel app”), and (2) the current screenshot S_t of the device or app window. Based on its policy π, the agent outputs an action a_t, which can be a discrete UI action such as “CLICK(x,y)” at screen coordinates (for mouse/tap), “TYPE(‘text’)” into a field, “SCROLL(direction)”, etc. The environment (the operating system or app) executes this action, resulting in a new screen S_{t+1}. This continues until the task is done or a step limit is reached. The agent may also maintain a history of past observations and actions (especially for long multi-step tasks).
A fundamental challenge in this formulation is GUI grounding: how to interpret instructions in terms of screen content. The agent must map references like “the Settings icon” or “the Next button” to specific pixels or regions on S_t. Unlike static vision tasks (e.g., captioning an image), here the agent must not only understand the screen but also locate interactive elements that fulfill a described function. This is complicated by varying layouts, themes, or unlabeled icons. Another challenge is the action space, while conceptually simple (click, type, etc.), the agent often must predict continuous coordinates for clicks. Small errors in coordinates can mean hitting the wrong UI element. Some recent solutions aim to avoid explicit coordinate regression by treating grounding as an attention or selection problem[27].
Task complexity is also an issue. Benchmarks range from single-step commands (“Click OK”) to lengthy workflows (like registering an account on a website, involving navigation across pages). To succeed on the latter, agents need a degree of planning and memory, they must understand intermediate steps and adjust if something unexpected occurs (e.g., a pop-up appears). High-level tasks can often be decomposed into subgoals, which some frameworks explicitly model by prompting the agent to generate “thoughts” or reasoning traces before each action. This is analogous to chain-of-thought prompting, but now grounded in interactive state. For example, an agent might internally reason: “Previous step failed and maybe the button was disabled, I should scroll first” before trying the next action.
Finally, evaluating VLA agents requires measuring success on tasks. Common metrics include: success rate (did the agent achieve the goal?), or step-wise accuracy (percent of correct actions). Datasets often provide a set of tasks with initial states and goal conditions. For instance, the Android in the Wild[17] dataset has 715k recorded episodes on Android phones; an agent is successful if it reproduces the human-demonstrated sequence on a test scenario. Similarly, the Mind2Web[18] benchmark defines success by whether the final webpage state meets the task request (e.g., an item added to cart). Some benchmarks provide a soft score (like an information retrieval reward on web tasks) when a perfect match is hard to define.
To promote the discussion, the list below summarizes a few prominent benchmarks/environments.
- MiniWoB (2017) – 100+ synthetic web tasks in a browser sandbox (e.g., fill form, click button); early RL benchmark, mostly text-based.
- WebArena (2023) – A realistic web environment with multi-page tasks (like comparing products across tabs). Agents perceive rendered pages; WebArena and its extension VisualWebArena test multimodal understanding (text + images on pages).
- AndroidControl (2024) – A dataset of 15k Android app task demos covering 833 apps. Each task has a high-level instruction and step-by-step low-level instructions, enabling evaluation of both levels. “AndroidControl-High” and “-Low” refer to whether the high-level task description is given or broken into low-level steps.
- GUI-Act & OmniAct (2024) – Datasets for web and desktop GUI tasks. GUI-Act-Web provides web task trajectories; OmniAct includes web and desktop and emphasizes cross-application generalization. These are often used for evaluating zero-shot generalization.
- ScreenSpot & ScreenSpot-Pro – Benchmarks focused on GUI grounding accuracy. In ScreenSpot, the agent must highlight the correct UI element given an instruction (covering mobile, web, desktop). ScreenSpot-Pro extends this to high-resolution “professional” UIs. Accuracy here reflects how often the agent’s selected region matches the ground truth target.
- OS-World (2024) – A full operating system environment with 369 tasks across real desktop apps, web, and OS file operations. Agents run in a virtual machine, making it a very comprehensive, open-ended test of general computer use.
- VideoGUI (2024) – A benchmark from instructional videos for complex software like Photoshop. It provides multi-step tasks derived from video tutorials, including high-level goals, intermediate subgoals, and fine-grained click/drag actions. This evaluates an agent’s ability to plan and execute sequences in professional GUI applications.
- GUI-Odyssey (2024) – A dataset of 7,735 cross-app mobile navigation tasks involving switching between apps (e.g., share an image from Gallery to WhatsApp). It tests how well agents handle multi-app workflows and maintain state across app boundaries.
These benchmarks provide a rich testbed. Agents are often first trained on large multimodal agentic datasets and then evaluated zero-shot or fine-tuned on these benchmarks. In the next section, we explore the approaches and models that have been developed to tackle this problem setting.
Proposed Methods and Evaluation
Vision-Centric Grounding and Perception Models
A central focus of recent work is improving visual grounding, enabling agents to reliably pick out the correct UI element given an instruction. One line of research treats this as a visual grounding task: feed in the screenshot and a query, and output a bounding box (or mask) for the target element. The aforementioned SeeClick was a seminal example: it introduced ScreenSpot as a grounding benchmark and showed that pretraining on millions of synthetic GUI element annotations significantly boosts grounding accuracy. SeeClick’s model used a ViT-based vision encoder and was fine-tuned with a coordinate prediction head, outputting the (x,y) location to click. After grounding-pretraining, SeeClick achieved double-digit improvements on downstream tasks, affirming that better grounding yields better overall task success.
Subsequent models pushed this idea further. UGround built the largest GUI grounding dataset to date: over 1.3 million synthetic screenshots with more than 7 million referring expressions for clickable elements. They leveraged the Common Crawl to extract diverse web pages, segmented full-page screenshots, and generated referring texts for each clickable element (e.g., using HTML attributes). By training a vision-language model (based on LLaVA architecture) on this, UGround achieved state-of-the-art grounding on multiple benchmarks, purely via vision, no HTML needed. Notably, agents augmented with UGround’s visual grounding were shown to outperform those using HTML/A11y tree inputs, despite the latter having structured information. This demonstrated that a high-capacity multimodal model can “see and click” as effectively as reading underlying code. It is a milestone toward human-like GUI interaction.
While SeeClick and UGround still output explicit coordinates, GUI-Actor proposes a coordinate-free grounding mechanism. GUI-Actor observes that predicting exact pixel coordinates is unnecessarily rigid and can be error-prone due to slight misalignments. Instead, it introduces an attention-based action head: the model has a dedicated
Another notable perception advancement came from UI-TARS team in the form of multi-granularity screen understanding. In training their agent, they curated several types of auxiliary data: (1) element-wise descriptions (captions for individual buttons/icons), (2) dense image captions for entire UI screens describing layout, (3) state-change descriptions (before/after screenshots to describe what changed), (4) visual Q&A about the UI, and (5) “set-of-mark” annotations linking text tokens to UI regions. These correspond to the “five perception layers” described in the UI-TARS 1.5 release. Incorporating this rich supervision made the model far better at recognizing GUI elements and their roles. For instance, UI-TARS can produce detailed captions of a settings window or identify which menu item is highlighted. This yields stronger downstream performance, especially on tasks requiring reading GUI text or dealing with dense layouts. CogAgent[] took a similar approach by evaluating their 18B model CogAgent on standard vision-language benchmarks (like VQA, DocVQA, ChartQA) to ensure it learned to read on-screen text and icons. Indeed, CogAgent achieved state-of-the-art on several text-rich VQA tasks and outperformed HTML-based baselines on Mind2Web and AITW tasks, highlighting the power of superior visual understanding.
In summary, cutting-edge VLA models devote significant effort to the vision and grounding subsystem. By pretraining on massive GUI datasets (Mind2Web, AITW, ScreenSpot, etc.) and innovating in output representation (coordinate-free attention maps, multi-task perception training), they equip the agent with “eyes” that can locate what the instruction refers to. This is a foundational capability upon which higher-level planning is built. We now turn to those higher-level policy models and how they incorporate these perception modules.
Unified Multimodal Action Models (Foundation Models for GUI Agents)
Another thread of research aims to develop large foundation models that can handle the entire pipeline of perceiving and acting, much like a human user. These models are trained on diverse multi-step task demonstrations across many applications, seeking generalization through scale (in model size and data). They often integrate visual encoders with transformer decoders that output actions in a textual format (e.g., “ [200, 350]”). Several recent systems exemplify this approach:
• Magma – Magma is a multimodal foundation model trained on an unprecedented variety of data: not only web/mobile GUI demonstrations, but also images, videos, and even robotic manipulation records. The idea is to endow a single model with both verbal intelligence (vision-language understanding) and spatial-temporal intelligence (planning and acting in environments). Magma introduced two novel annotations during pretraining: Set-of-Mark (SoM), which labels actionable visual objects in images (e.g., marking clickable GUI widgets), and Trace-of-Mark (ToM), which labels the trajectory of object motions in videos (e.g., a hand moving a slider). By learning from SoM and ToM, Magma can effectively ground actions in static images and understand dynamic sequences for planning. Impressively, Magma achieves state-of-the-art on both UI navigation and robot manipulation tasks, it is a testament to the power of scaling across domains. It suggests a future where one foundation model controls both software and physical devices.
• UI-TARS – UI-TARS represents one of the most comprehensive efforts, targeting “native” GUI agents that rely only on pixels and work across platforms. The team scaled model sizes up to 72B parameters and used about 50B tokens of multimodal training data to train UI-TARS-7B and 72B. Their training data was a mix of public GUI datasets (like AITW, AITZ[], Mind2Web, AndroidControl, etc.) plus in-house collected traces. Unique aspects include the unified action space design (same action format for Windows, Android, Web, etc.) and the use of augmented “System-2” reasoning where the model generates explicit intermediate reasoning (“thoughts”) before actions. They also employed a Reflection mechanism: after initial training, they let the agent run and collected instances where it made mistakes, then annotated corrective actions and fine-tuned on those (a form of iterative self-improvement). The result was a model that surpasses GPT-4V and Anthropic’s Claude on several benchmarks, especially in long, dynamic tasks. For example, on the complex OSWorld benchmark, UI-TARS-72B achieved new SOTA success rates in both 15-step and 50-step task settings. Notably, UI-TARS can handle tasks like configuring OS settings or multi-step form filling with very high reliability, due to its strong visual perception and large-scale learned knowledge of common UIs. It is also open-sourced, providing a foundation many others are now building upon (lighter variants like “UI-TARS 1.5 (7B)” have been released to the community).
• CogAgent - CogAgent was one of the first 10B+ scale VLA models, with 18B parameters. It introduced a dual-encoder architecture: a high-resolution image encoder for fine UI text/icons and a low-resolution one for broader layout, enabling it to ingest full 1080p screenshots without losing tiny details. CogAgent was trained on a blend of general VQA data and GUI tasks. It demonstrated that a single model can excel at both standard vision-language tasks and GUI control, e.g., it topped multiple VQA benchmarks and simultaneously outperformed baseline methods that use HTML on GUI navigation benchmarks. This was an important proof-of-concept that one multimodal model can serve dual roles: understanding content (for answering questions or describing charts) and taking actions (for interactive tasks).
• Fuyu-8B – Fuyu-8B is a relatively small (8B) but efficient multimodal model released by Adept, known for their ACT-1 agent. Fuyu’s contribution was showing that simplicity in architecture can suffice for strong performance in GUI tasks. It uses a vanilla decoder-only transformer (no fancy fusion modules), yet can handle arbitrary image resolutions and perform fine-grained localization on screen images. Designed from scratch for digital actions, Fuyu is fast, processing large screenshots in ~100ms. Adept’s results showed Fuyu-8B can answer UI-related questions and even control certain interfaces after finetuning, despite its relatively modest scale. It underscores that optimized data and training can sometimes beat raw parameter count for this domain.
In evaluating these foundation models, researchers often fine-tune or test them on standard benchmarks and look at a variety of metrics. A common evaluation is success rate on multi-step tasks (e.g., how many tasks in Mind2Web or AndroidControl the agent completes correctly). Another is the accuracy of each action step (type accuracy, grounding accuracy, etc.), which helps pinpoint whether errors come from perception or from decision-making. Large models like UI-TARS have been shown to drastically improve both. For instance, UI-TARS-7B achieved ~75% grounding accuracy on ScreenSpot-Pro, far above previous ~50% by smaller models. On Mind2Web tasks, generalist agents still lag human performance, but the gap is closing as models incorporate more reasoning.
An interesting trend is emerging: cross-domain training (like Magma’s inclusion of robotics and games) can improve robustness. The recent study[“From Multimodal LLMs to Generalist Embodied Agents (GEA)”] found that a model trained on a mix of GUI, web, game, and robotic tasks generalized better to unseen scenarios than those trained on a single domain. It seems exposing the model to varied embodiments forces it to learn more abstract reasoning and aligns modalities better. For instance, an action like “click OK button” shares structure with “pick up cube” in robotics, both involve identifying an object and executing a motor command. A multimodal foundation model can capture this common structure.
Overall, unified multimodal models represent the “brains” of GUI agents. Large neural networks that ingest everything (pixels, text instructions, history) and output the next action. Their development is quickly advancing, with increasing scale and increasingly clever training regimes. But pure supervision has limits; this is where reinforcement learning techniques come in, as described next, to further hone these models’ decision-making and long-horizon planning.
Reinforcement Fine-Tuning and Reasoning Enhancement
While supervised learning on large datasets produces capable agents, researchers have found that a further boost can be obtained via reinforcement learning fine-tuning (RL or RFT), essentially allowing the model to learn from trial and error with feedback, or to optimize for long-term rewards. Two notable frameworks in this vein are UI-R1 and GUI-R1, both inspired by the DeepSeek-R1 paradigm.
UI-R1 focuses on low-level action prediction for mobile GUIs using rule-based rewards. The authors constructed a small but very challenging set of 136 mobile tasks that require the agent to predict a sequence of 5 action types (tap, swipe, etc.) to accomplish each. They then designed a unified reward function that gives positive feedback when the correct action type or correct target area is chosen. Using Grouped Policy Optimization (GRPO), they fine-tuned a 3B Qwen-VL model on these tasks. The results were striking: the RL-trained UI-R1-3B model gained +15% action type accuracy and +10.3% grounding accuracy on the AndroidControl benchmark compared to its supervised baseline. Moreover, with only ~0.2% of the data that larger models used (it trained on 136 tasks vs tens of thousands), UI-R1-3B nearly matched the performance of a much bigger 7B model that had been SFT-trained on 76k examples. This data efficiency highlights how giving the model a clever reward signal and letting it practice can compensate for limited data. Essentially, RL fine-tuning taught the model to “think a few steps ahead” and handle ambiguous situations better than supervised training alone.
GUI-R1 extended the idea to high-level task completion. Instead of just predicting one action at a time, GUI-R1 has the model produce a chain-of-thought alongside actions. For each high-level instruction, the model generates a rationale and series of low-level steps, which are then executed and verified with rewards (e.g., did the click succeed, did the text input match?). The key insight was using verifiable reward signals for each step: correctness of action type, correctness of click position, and correctness of any text input. By optimizing these with policy gradients, GUI-R1 significantly improved success rates on complex multi-step tasks. For example, on a suite of tasks across web, desktop, and mobile, GUI-R1 boosted average success from ~56% to ~80% (at 3B scale) relative to a comparable supervised agent. It also notably outperformed an existing agent (UI-TARS) by ~10 points at the same 3B model size, indicating the RFT approach yielded a more effective problem-solving strategy. The ablation showed that even a little bit of supervised fine-tune data can actually hurt if not combined with RL, as it might bias the model to narrow patterns. GUI-R1’s ability to outperform larger models with much smaller scale training suggests that smart training (RFT) beats brute-force training in certain scenarios.
Other groups are exploring related ideas. InfiGUI-R1 aims to convert reactive GUI agents into “deliberative reasoners” by integrating infinite-length chain-of-thought with RL. They incorporate a self-reflection after each action, similar to UI-TARS’s iterative improvement but done on-the-fly during task execution. Early reports indicate this helps in out-of-domain tasks, though detailed results are pending publication. There is also interest in self-supervised RL: e.g., training an agent to explore interfaces without a specific task (just to discover possible actions and state transitions). A recent example is Explorer[], which focuses on autonomously mapping out an application’s UI by detecting interactable elements and performing random but informed exploration. While not an end-task model, such exploration data can bootstrap an agent’s knowledge of what actions do (e.g., clicking a gear icon opens settings) without manual labels. This could greatly expand training data via unsupervised means.
Beyond raw task success, RL-trained agents also demonstrate more robust reasoning. For instance, UI-R1’s thought-length ablation showed that forcing the model to think in longer sequences of steps improved performance up to a point, after which too long thoughts had diminishing returns. This suggests an optimal granularity for internal reasoning. Meanwhile, models like Aguvis explicitly incorporate an “inner monologue” during planning. Aguvis trains the agent in two stages: first on GUI grounding (perception), then on planning with a structured reasoning annotation (essentially chain-of-thought describing why an action is taken). Their agent is among the first to be fully vision-based and also fully autonomous (no reliance on external models), and it achieved state-of-the-art on both offline and online benchmarks when it debuted. The inner monologue approach and results like “InfiGUIAgent” align with a broader trend: merging decision-time planning with policy learning. In other words, the agent learns not just to map state→action, but state→(think)→action, with the thinking itself optimized by rewards. This is a powerful idea as tasks become more complex.
In summary, reinforcement learning and advanced training tricks are increasingly integral to VLA models. They are the “finishing school” that turns a capable vision-language model into an expert problem-solver that can handle long horizons, recover from errors, and make efficient use of limited data. As tasks move toward open-world settings (arbitrary apps, dynamic web content), such robustness will be essential.
Experiments and Results
The rapid progress in VLA models is reflected in their performance on benchmarks. Here we synthesize key results reported across recent studies, highlighting how far we’ve come and where gaps remain.
On GUI grounding tasks, we’ve seen accuracy leap from roughly 20-30% in early stage to over 40% recently for top models (on challenging benchmarks like ScreenSpot-Pro). For example, SeeClick’s baseline achieved ~24% on ScreenSpot. Then, UGround-7B pushed grounding Acc to ~35%. And recently, GUI-Actor’s coordinate-free approach hit 44.6% (with Qwen2.5-VL backbone) on ScreenSpot-Pro, surpassing even the massive UI-TARS-72B’s ~38%. These numbers signify that visual grounding is becoming a solved component for many cases, errors still occur in extremely crowded or novel UIs, but on common app screens, agents can usually pinpoint the described element. The introduction of grounding verifiers and multi-candidate proposals (GUI-Actor, Aguvis) further closes the gap by handling ambiguity (e.g., multiple “OK” buttons).
For single-turn, single-step tasks, the best models are already nearing human-level. AITW reports human demo success as 100% by definition; models like OS-Atlas-7B achieved ~90% subtask success on AITW sequences. On Mind2Web, which has more open-ended web tasks, the original baselines were below 50% success. An LLM-based agent with filtering got ~60% on seen domains. WebAgent (OpenAI’s GPT-4 with tools) reportedly got closer to 70-75% on the easier tasks, though direct comparison is tricky. The current best generalist (e.g., a fine-tuned UI-TARS) operates in the 70-80% range on Mind2Web’s evaluation (some tasks like form filling nearly solved, others like multi-site navigation still challenging). The limiting factor on the web is often not vision, but reasoning and understanding complex instructions or when to switch strategies.
On multi-step workflows, we see clear improvements thanks to larger models and RL. AndroidControl’s high-level tasks (which may involve ~5-10 steps) were a big challenge. After scaling to more data, their in-domain success reached ~50-60% but OOD remained ~25%. UI-TARS-72B, however, with reflection and huge scale, achieved 85%+ success on in-domain Android tasks and ~73% on out-of-domain tasks indicating that given enough knowledge and reasoning ability, the agent can even handle new apps or updated OS versions fairly well. On OS-World (which strings multiple apps together), the absolute scores are lower. UI-TARS-72B reportedly scored ~55-60% on 50-step tasks in OS-World, whereas GPT-4V was around 45-50%. A gap remains, but it’s closing. OS-Atlas achieved SOTA on a variety of benchmarks by training on 13M multi-platform steps, hitting ~70% average success across web, desktop, mobile tasks (zero-shot). This suggests that massive multitask training (13 million is huge) can yield a strong general policy, though OS-Atlas is not as readily available to verify externally.
One notable outcome of experiments is that vision-only agents now consistently outperform those using privileged information. Earlier, an HTML-based agent might have had an edge in web tasks. But models like CogAgent and UGround changed this line of research. For instance, CogAgent (vision-only) beat an HTML-reading GPT-4 on Mind2Web tasks by a significant margin. UGround’s pure pixel approach outperformed prior state-of-the-art that used accessibility trees on a GUI grounding benchmark. And in fully interactive evaluations, OS-Atlas (vision) surpassed a baseline that had oracle DOM info, demonstrating the vision models’ representation has become rich enough. This is a key result: it validates the “human-like” embodiment as not just more general, but actually more effective when paired with large model learning. It means future systems need not rely on platform-specific hooks; they can truly rely on the screen as the universal interface.
Nonetheless, failure modes are still observed. Common error cases reported include: the agent clicking the wrong instance of a repeated element (e.g., two “Reply” buttons on a page); timing issues such as clicking too early before an element loads (some papers introduced wait actions or used vision to detect loading spinners to handle this); and misunderstanding ambiguous instructions (like “refresh”, which could mean clicking a refresh icon or pressing F5, etc.). Models sometimes also hallucinate actions, a well-known example is an agent trying to scroll on a page that isn’t scrollable or typing text that wasn’t asked for, akin to how LLMs hallucinate facts. These issues are targets for ongoing research, often addressed by adding more feedback signals or guardrails. For example, some agents incorporate a verification step after executing each action, allowing them to detect if something went wrong (no state change, error message) and then adjust their plan. Others, like Reflection agents (UI-TARS, InfiGUI), will explicitly check the goal after each subtask and, if not met, try alternative strategies. This kind of resilience is still not perfect and is an area where humans still have a sizeable edge.
In terms of evaluation protocols, there is a push towards more “live” evaluations. Instead of static recorded episodes, researchers use environments where the agent must actually execute actions in real software. Mind2Web’s online variant (Mind2Web-Live) tests an agent on real websites loaded in a browser. Similarly, AndroidWorld provides a dynamic Android emulator to test agents on new apps or tasks not in training. These live tests are considered the gold standard since they reveal if an agent can cope with unpredictability (pop-ups, network delays, etc.). Aguvis, for instance, touts its state-of-the-art performance on a real-world online benchmark, which suggests its vision and reasoning model didn’t just memorize training patterns but can adapt on the fly. As more of these results emerge, we’ll get a clearer picture of how close we are to reliable real-world deployment.
To conclude the Experiments section, the trajectory is clearly upward. What started with sub-50% success on simple tasks has moved into 80%+ on complex ones in just a couple of years. Vision-language-action models, especially when combined with strategic training (large-scale multi-task learning and reinforcement fine-tuning), are rapidly approaching human-level proficiency in many digital domains. Yet, certain hard problems like open-web generalization and error recovery still keep performance below 100%. These form the basis for discussion in the next section on limitations and opportunities.
Discussion
The progress in VLA models brings both optimism and new questions. Here we discuss some overarching themes, current limitations, and implications for the broader AI field.
Generality vs. Specialization. One tension is between building a single generalist agent versus specialized agents for specific domains (web, mobile, etc.). The trend so far favors generality, models like UI-TARS, OS-Atlas, Magma show one architecture can span multiple platforms. Cross-domain training often even improves performance through shared learning. However, the highest results on certain benchmarks sometimes come from tailoring. For example, GUI-Actor specialized in the grounding aspect and achieved breakthrough accuracy, and UI-R1 focused on mobile actions with custom rewards for big gains there. A likely direction is a modular generalist: a big common model with pluggable specialized components (much like GUI-Actor’s action head could be a module). This way, an agent could, say, swap in a high-precision grounding module when pixel-perfect clicking is needed, or a code-execution module if the task involves scripting. Designing architectures that allow such flexible modules without losing end-to-end coherence will be valuable.
Data and Simulation. Despite the large datasets, there is still a data bottleneck for interactive behavior. It is infeasible to collect human demonstrations for every possible task in every app. Thus, techniques like simulation and self-play are vital. Some works generate synthetic tasks (e.g., UGround’s synthetic web data, or TongUI’s use of web tutorials as proxy demonstrations). TongUI is noteworthy, by crawling multimodal tutorials (YouTube videos, how-to articles) and converting them into trajectories, they created a dataset (GUI-Net) of 143k trajectories across 200+ applications without explicit manual labeling. The agent fine-tuned on GUI-Net (TongUI agent) showed ~10% improvement on benchmarks over baselines, proving the usefulness of these “found” demonstrations. Going forward, leveraging online resources (documentation, Q&A forums, recorded user sessions) might cover the long tail of tasks. Additionally, training agents to learn by exploring (like Explorer and some self-supervised approaches) could yield unlimited interaction data. For instance, an agent could roam through an OS, trying random actions and learning state transitions, which later informs goal-directed behavior. This echoes how humans learn UIs, we click around and see what happens.
Reasoning and Alignment. VLA agents inherit the interpretability issues of LLMs, they are largely black boxes. However, their embodiment offers some advantages. We can log every action taken on the UI, and often we can tell exactly where it went wrong (e.g., clicked the wrong button). This opens the door to on-line feedback and correction. Some researchers are exploring integrating human feedback for GUI tasks, akin to ChatGPT’s RLHF but in the UI domain. Imagine a system observing an agent and providing reward/punishment or preference feedback on trajectories (“it completed the task but took too many steps” etc.). There’s initial work in preference modeling for action sequences, but it’s not yet widely applied. Another angle is using the agent’s own self-checks. Agents like InfiGUI-R1 and UI-TARS already generate internal thoughts, these could be surfaced to users or developers to debug behavior. If an agent can explain “I clicked that link because I thought it said ‘Next’”, and that was a mistake, one can adjust the perception module (the text said “Not now”, not Next). This could make these systems more transparent and easier to align with user intentions.
Safety and Robustness. When letting agents control computers, safety is a concern. We don’t want an AI autonomously deleting files or sending unintended emails. So far, most research agents operate in constrained sandboxes. But as they move to real-world use (e.g., an AI assistant that can drive your desktop apps), guardrails are needed. Some ideas include: limiting action permissions (only allow clicking within the app window, not the OS settings, unless explicitly permitted), having a confirmation mechanism for critical actions (“Are you sure you want to permanently delete?”), or using an external policy to veto obviously dangerous sequences (like typing certain commands). Ensuring the model itself understands concepts of safety (“don’t click Install on random software”) is an open challenge, it may require training on negative examples or adversarial scenarios. Robustness-wise, these agents can be brittle to even minor visual changes: e.g., if an app’s theme changes colors, will the detector still find the button? So far, models seem to generalize surprisingly well (due to high-level visual features), but extreme changes (dark mode vs light mode, or a complete UI redesign) could throw them off. Continued pretraining on diverse visual styles is one way to mitigate this; another is on-the-fly adaptation (few-shot learning from a handful of new screenshots to adjust the model).
Comparisons to Human Performance. In closed tasks, humans are still more reliable, especially in unstructured environments. But on repetitive, structured tasks (like form filling, data entry), current agents already approach human speed and accuracy. One interesting observation: agents don’t get bored or make accidental slips due to fatigue, but they do make systematic mistakes due to their training biases. For example, an agent might always click the first “Submit” button it sees, whereas a human would read context to pick the right one. In the user study, the OdysseyAgent (from GUI-Odyssey) was preferred by users for certain cross-app tasks because it was faster, but users noted it occasionally did odd things a human wouldn’t. The gap in natural judgment is closing, but closing the last bit will require more commonsense integration (maybe linking these agents with world knowledge LLMs).
Implications. If these vision-language-action agents reach maturity, they could revolutionize how we interact with computers. Instead of manually performing multi-step operations, one could simply tell their AI assistant what to do, and it will operate the software. This could democratize complex software usage (imagine telling an AI to “crop my face out of this photo and add it to slide 3”, and it does Photoshop and PowerPoint steps for you). It also raises the prospect of automated testing and tutoring, an AI could test software by exploring it like a user (some companies already use AI for UI testing, though not yet fully general). Moreover, such agents might serve as assistive technology, helping users with disabilities by acting as their “hands” on the computer following spoken instructions.
However, achieving this vision reliably will require addressing the challenges discussed and rigorous validation. The benchmarks are becoming more stringent (e.g., requiring zero-shot adaptation to new UIs). Also, collaboration between industry (with access to large-scale interaction data) and academia (developing novel methods) will likely accelerate progress. Notably, many projects (UI-TARS, OS-Atlas, GUI-Actor) have open-sourced their models or code, which will encourage reproducibility and extension by others.
In conclusion, the discussion highlights that VLA models are on a promising trajectory, but careful work remains to ensure they are robust, safe, and truly general. The next section outlines concrete future work directions that emerge from this analysis.
Conclusion
Vision-Language-Action models are poised to become a transformative technology. They encapsulate a long-standing vision: telling a computer what you want in plain language and it does it, by literally looking at the screen and using the software as you would. Achieving this reliably will take a bit more time and interdisciplinary effort, but the progress to date suggests that AI assistants capable of operating any software are on the horizon. This will usher in a new era of human-computer interaction, where automation is accessible to all through natural communication and visual context. The survey presented here serves as a snapshot of this rapidly moving field recently. We anticipate that in a year or two, many “futures” discussed will have become reality, and new horizons (like combining physical and digital actions seamlessly) will come into view.
Future Work
Several promising avenues can drive the next generation of Vision-Language-Action models: • Improved Generalization: Developing agents capable of quickly adapting to unseen interfaces through few-shot or meta-learning approaches will be critical for handling novel or dynamically changing apps and websites.
• Continuous and Lifelong Learning: Enabling agents to continuously learn from their own interactions and mistakes in real-time scenarios, potentially guided by user feedback or self-supervised exploration.
• Multi-Modal Extensions: Incorporating additional modalities like audio (notifications, screen readers), contextual documentation, or user-generated explanations to enhance robustness and contextual understanding.
• Human-Agent Collaboration: Exploring mixed-initiative interactions, where agents collaborate seamlessly with human users, seeking clarification or confirmation when uncertain, thus improving practical usability.
• Ethics, Safety, and Trust: Addressing the ethical implications and ensuring agents operate safely through transparent reasoning, uncertainty estimation, and explicit guardrails against unintended actions.
• Robust Evaluation and Benchmarking: Developing comprehensive benchmarks that test long-term reliability, adaptability to diverse interfaces, and robust real-world performance.
These directions can significantly enhance the practical deployment, reliability, and trustworthiness of future VLA models.
Links
- CogAgent (18B) – GitHub: THUDM/CogAgent, Paper  – Open-source 18B GUI VLM from Tsinghua (2023).
- UGround – Project Page, Paper  – OSU’s universal grounding model and data (2024).
- ShowUI (2B) – GitHub: showlab/ShowUI, Paper  – Vision-language-action model with UI-guided token pruning (CVPR 2025).
- TongUI & GUI-Net – Project Page, Paper  – Multimodal web tutorial crawling for cross-app agents (2025).
- Magma (8B) – Project Page, Paper  – Microsoft’s multimodal foundation model for UI & robotics (CVPR 2025).
- SeeClick & ScreenSpot – Paper , Code – Introduced ScreenSpot benchmark and GUI grounding pre-training (2024).
- UI-TARS (72B) – GitHub: bytedance/UI-TARS, Paper  – ByteDance’s open-source native GUI agent model (2025).
- OS-Atlas – Paper , GitHub – Cross-OS foundation action model from OpenGVLab (2024).
- Aguvis – Project Page, Paper  – Salesforce’s vision-only GUI agent with inner monologue (ICML 2025).
- GUI-R1 – Paper  – High-level RFT framework for GUI agents with verifiable rewards (2025).
- UI-R1 – Paper  – Mobile GUI action model using rule-based RL (2025).
- InfiGUI-R1 – ArXiv  – (RealLM Labs 2025) Deliberative reasoning GUI agent, extending GUI-R1 with infinite thoughts.
- Adept Fuyu-8B – HF Model, Blog  – Open multimodal agent model from Adept AI (2023).
- GUI-Actor – Project Page, Paper  – Microsoft’s coordinate-free GUI grounding model (2025).
- Scaling UI Grounding (OSWorld-G & Jedi) – Paper , GitHub – OSWorld-G benchmark and Jedi 4M synthetic data for grounding (2025).
- GEA (Multimodal GEA) – Paper  – Study on adapting multimodal LLMs to embodied agents across domains (2024).
References
- Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxuan Zhang, Juanzi Li, Bin Xu, Yuxiao Dong, Ming Ding, Jie Tang. CogAgent: A Visual Language Model for GUI Agents.
- Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, Yu Su. Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents. 
- Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Weixian Lei, Lijuan Wang, Mike Zheng Shou. ShowUI: One Vision-Language-Action Model for GUI Visual Agent. 
- Bofei Zhang, Zirui Shang, Zhi Gao, Wang Zhang, Rui Xie, Xiaojian Ma, Tao Yuan, Xinxiao Wu, Song-Chun Zhu, Qing Li. TongUI: Building Generalized GUI Agents by Learning from Multimodal Web Tutorials. 
- Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, Yuquan Deng, Lars Liden, Jianfeng Gao. Magma: A Foundation Model for Multimodal AI Agents. 
- Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, Zhiyong Wu. SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents. 
- Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xiaojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen, Zhaojian Li, Haihua Yang, Haifeng Liu, Feng Lin, Tao Peng, Xin Liu, Guang Shi. UI-TARS: Pioneering Automated GUI Interaction with Native Agents. 
- Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, Yu Qiao. OS-ATLAS: A Foundation Action Model for Generalist GUI Agents. 
- Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, Caiming Xiong. Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction. 
- Run Luo, Lu Wang, Wanwei He, Xiaobo Xia. GUI-R1: A Generalist R1-Style Vision-Language Action Model For GUI Agents. 
- Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Guanjing Xiong, Hongsheng Li. UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning. 
- Yuhang Liu, Pengxiang Li, Congkai Xie, Xavier Hu, Xiaotian Han, Shengyu Zhang, Hongxia Yang, Fei Wu. InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners. 
- Yadong Lu, Jianwei Yang, Yelong Shen, Ahmed Awadallah. OmniParser: OmniParser for Pure Vision Based GUI Agent. 
- Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, Yu Su. SEEACT: GPT-4V(ision) is a Generalist Web Agent, if Grounded. 
- Tianbao Xie, Jiaqi Deng, Xiaochuan Li, Junlin Yang, Haoyuan Wu, Jixuan Chen, Wenjing Hu, Xinyuan Wang, Yuhui Xu, Zekun Wang, Yiheng Xu, Junli Wang, Doyen Sahoo, Tao Yu, Caiming Xiong. Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis. 
- Andrew Szot, Bogdan Mazoure, Omar Attia, Aleksei Timofeev, Harsh Agrawal, Devon Hjelm, Zhe Gan, Zsolt Kira, Alexander Toshev. From Multimodal LLMs to Generalist Embodied Agents: Methods and Lessons. 
- Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, Timothy Lillicrap. Android in the Wild: A Large-Scale Dataset for Android Device Control. 
- Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, Yu Su. Mind2Web: Towards a Generalist Agent for the Web. 
- Lucas-Andreï Thil, Mirela Popa, Gerasimos Spanakis. Navigating WebAI: Training Agents to Complete Web Tasks with Large Language Models and Reinforcement Learning. 
- Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, Graham Neubig. WebArena: A Realistic Web Environment for Building Autonomous Agents. 
- Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, Daniel Fried. VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. 
- Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, Tao Yu. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. 
- Kevin Qinghong Lin, Linjie Li, Difei Gao, Qinchen Wu, Mingyi Yan, Zhengyuan Yang, Lijuan Wang, Mike Zheng Shou. VideoGUI: A Benchmark for GUI Automation from Instructional Videos. 
- Quanfeng Lu, Wenqi Shao, Zitao Liu, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, Yu Qiao, Ping Luo. GUI Odyssey: A Comprehensive Dataset for Cross-App GUI Navigation on Mobile Devices. 
- Jiwen Zhang, Jihao Wu, Yihua Teng, Minghui Liao, Nuo Xu, Xiao Xiao, Zhongyu Wei, Duyu Tang. Android in the Zoo: Chain-of-Action-Thought for GUI Agents. 
- Vardaan Pahuja, Yadong Lu, Corby Rosset, Boyu Gou, Arindam Mitra, Spencer Whitehead, Yu Su, Ahmed Awadallah. Explorer: Scaling Exploration-driven Web Trajectory Synthesis for Multimodal Web Agents. 
- Qianhui Wu, Kanzhi Cheng, Rui Yang, Chaoyun Zhang, Jianwei Yang, Huiqiang Jiang, Jian Mu, Baolin Peng, Bo Qiao, Reuben Tan, Si Qin, Lars Liden, Qingwei Lin, Huan Zhang, Tong Zhang, Jianbing Zhang, Dongmei Zhang, Jianfeng Gao. GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents.