Using NeRF and Foundational Models to Create Distilled Feature Fields
Modern robotics applications require powerful visual systems to interact with the physical world. For example, consider a warehouse robot working at Amazon, tasked with grabbing a product from a bin filled with other products, using a mechanical arm, a camera, and the product description. Such a robot would need several capabilities: the semantic capabilities to identify the product in the bin from its description, and the spatial capabilities to successfully grab the product. Researchers have tackled this very problem by training Computer Vision models to both learn how to represent the 3D space captured by images of the scene, and learn how to represent the semantics of all objects present in the scene. Separately, these two approaches are achieved through Neural Radiance Fields (NeRF) and Image Features from Foundational Models, respectively; when combined, the new approach is called Distilled Feature Fields (DFFs). Here, we describe the inner workings of NeRF and Foundational Model Features, DFFs, and other approaches that have since been developed, along with their advantages and drawbacks.
- Neural Radiance Fields (NeRF)
- Foundational Model Image Features
- Distilled Feature Fields (DFFs)
- Applications of DFFs
- Additional Approaches
- Conclusion
Neural Radiance Fields (NeRF)
Neural Radiance Fields (Mildenhall et al.) were first developed in an unrelated field of Computer Vision. Researchers posed the following question: given a series of images of the same scene, from many different angles, can we synthesize an entirely new image of the scene from a new perspective that was never provided in the original set of images? When addressing this question, the authors arrived at a method they named Neural Radiance Fields. The core idea is to represent the 3D space of the scene as a set of points in a dense grid-like structure. Each point corresponds to a particular point in the 3D space of the scene, called a voxel, and contains two properties: its view-dependent color and its density. A voxel’s view-dependent color describes what color that point in space has when viewed from a particular angle. The dependence on view is quite crucial, as the same point in space can look very different depending on our viewing angle. The authors provide several examples to illustrate this point.
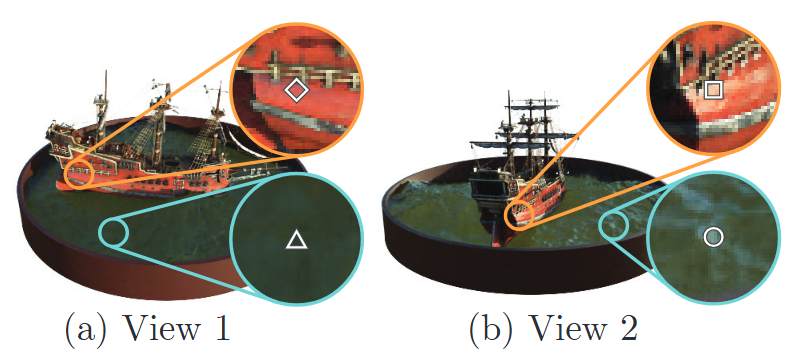
The water and the ship’s hull change colors between views as they reflect sunlight.
The density of a voxel is a little more complicated. Some voxels in the scene might be varying levels of transparent. In fact, most of the scene will be made up of empty space, which is fully transparent. Other parts of the scene might be slightly transparent, like a cloth held up against the sun, or very transparent, like a pane of glass. The level of opacity of each voxel is measured by its density — a high density means the voxel lets no light through, while a low density means the point is very transparent. In the spirit of showing off the cool capabilities of foundational models, here’s an example illustrating the varying degrees of opacity in everyday objects, generated by Gemini 2.5 Flash.

The glass, cloth, water, wood, and flower petals all have different levels of opacity.
Once we have a fully populated 3D grid of all voxels in the scene, each with its own view-dependent color and density, we can generate any view of the scene we would like. The inner workings of cameras are beyond the scope of this work, but feel free to look into perspective projection on your own time to learn how a set of 3D points can be transformed into an image of pixels from any perspective. In short, once we produce the full 3D grid, our job is done, as now any view can be synthesized from the original set of images.
The obvious next question is how to acquire this dense grid? This is where the authors propose their solution. The authors use a Neural Network that takes the 3D coordinates of the voxel of interest and the desired viewing angle as input, and outputs the RGB color and density of that voxel. Beyond the traditional Neural Network architecture, the authors introduce positional encoding to the 3D position inputs to increase the model’s sensitivity to small changes in positions, and hierarchical volume sampling for computational efficiency. Each such Neural Network is trained end-to-end for each scene using the set of images that are provided, and can be queried repeatedly to populate the dense grid needed for view synthesis.
NeRF is an incredible technology and was a huge step forward in its field. It was among the first approaches to produce results that look accurate to the human eye, and thanks to the parameterization of Neural Networks is a very general method that can work with nearly any scene. That being said, NeRF has its downsides too. For starters, representing a scene using NeRF involves retraining the entire NeRF Neural Network from scratch to overfit it to the provided images. This alone requires minutes or hours of training for a single scene, and a large computational overhead. Additionally, NeRF fails when any component of the scene is in motion, as temporal dynamics are not intrinsically modeled by NeRF. Lastly, NeRF’s performance dramatically degrades when too few images are provided in training. Below is an example of NeRF’s sharp degradation as the number of images is reduced.

The fewer views of the scene we provide NeRF during training, the worse the reconstruction becomes. Eventually degredation "falls off a cliff" between 18 and 20 views.
While NeRF was a significant breakthrough in view synthesis, other works have since recognized that the trained NeRF Neural Network of each scene is a more efficient representation of the 3D space of that scene than any other modern methods used in 3D reconstruction at the time. This insight opened the door for using NeRF not just for view synthesis, but for any task that requires a good spatial understanding of its environment, as it is used in DFFs.
Foundational Model Image Features
While NeRF serves the purpose of learning a strong spatial prior, our running example of an Amazon robot still needs a strong semantic understanding of the contents in its scene. Fortunately, the features learned from foundational models trained on internet-scale data are perfect for this purpose. During the training of foundational vision models like DINO (Caron et al.) and CLIP (Radford et al.), the models learn useful representations of their inputs, and use these intermediate representations for all downstream tasks they’re trained on.
Since foundational vision models are trained on many diverse tasks and on enormous scales of data, the resulting representations they learn tend to be quite robust and expressive. In fact, the image features produced by foundational vision models are so powerful that they seem to exhibit an underlying understanding of what is happening in the image and the meaning of the objects visually present. Here is an example of image features extracted from an image using DINO, where the image features are visualized using PCA.
 |
 |
The DINO image features understand where one object ends, and another begins, and how they belong to different classes of objects.
While the Image Features from Foundational Models are incredibly powerful tools that can be used for all sorts of vision processing, they are quite expensive to produce and have their limitations. The first limitation is the cost to acquire these image features. Training foundational models requires an astronomical investment in computational resources, and a large set of curated data. This process is so involved, that in practice, very few organizations are willing to invest those resources beyond enormous companies in the ML field. For example, the foundational models referenced thus far belong to Meta, OpenAI, and Google. Secondly, vision encoders are limited to reasoning over 2D image data, or maybe 2D + Time video data. While this is useful for most applications, our Amazon robot needs to understand the physical world in 3D space. We must invest extra effort to use these powerful image features in 3D environments.
The strong semantic prior of the visual world is the last missing piece in our running example of the Amazon robot, and we will use it, in conjunction with NeRF, once more in DFFs.
Distilled Feature Fields (DFFs)
Distilled Feature Fields were originally introduced in Tschernezki et al. and Kobayashi et al. for image editing tasks. The idea is a fairly intuitive combination of NeRF and foundational models with strong image features. On their own, NeRF only learns a 3D spatial prior of the scene, and foundational models only learn a 2D semantic prior of their scenes, but combined, DFFs can learn a 3D spatial-semantic representation of their scenes.
This is accomplished by training the NeRF model, without modifications, on a whole new type of data. We still input (x, y, z, θ, 𝜙), which is the spatial coordinates of the voxel of interest and the viewing angle, into the NeRF Neural Network. However, during training, we no longer task the NeRF Neural Network with reconstructing the RGB color and density. Instead, we ask the Neural Network to reconstruct the RGB color, the density, and the 256-dimensional image feature of the voxel of interest.
You might ask: how do we acquire this 256-dimensional image feature for each voxel in the scene? This is where the foundational models come in. Before training the NeRF model, we first pass each of our different views of the scene into a foundational model, and extract the model’s representation of each view from the second-to-last layer. This gives us the image features for each view of the scene, which we can now use to train the NeRF model.
That’s it! We now trained a NeRF model not only to reconstruct the visual aspects of the scene from any view, but also to reconstruct the semantics of the scene from any view. It’s a 3D representation that both preserves the spatial and semantic meanings of the scene’s contents. Here is one such scene, where the color of each voxel is the PCA of that voxel’s image features from DFFs.

The resulting representation encodes both spatial and semantic information. Each voxel's image feature output by NeRF is brought down to just 3 values using PCA, and those are shown as RGB colors in this image.
Naturally, DFFs inherit the strengths and weaknesses of both NeRF and foundational models. They still take a long time to train a single scene, and degrade in performance when given too few images, or when components in the scene are in motion. But the strengths of DFFs become more pronounced too. By providing many images of the same scene, and using all of them to create a single NeRF model, the resulting image features for each view dramatically increase in fidelity. Let’s recall how the DINO features of this image looked. Now, using DFFs, the reconstructed image features look dramatically better: something we could only accomplish with NeRF and foundational models in unison.
|
|
 |
DFFs use all views given to it to construct its image feature representation, and as a result can achieve much higher fidelity views than foundational models that only use a single view to construct their image features
Applications of DFFs
DFFs are powerful spatial and semantic representations of 3D scenes, but how can we make efficient use of them? We mentioned that they were originally introduced in image editing tasks, but recent work has successfully applied them to robotics tasks. Two works stand out as particularly relevant: F3RM (Shen et al.) and LERF-TOGO (Rashid et al.).
The first work, called F3RM, uses DFFs for robotic manipulation tasks. Their method involves training a DFF for each scene as described above, then using this 3D representation, in conjunction with a human demonstration, to perform robotic manipulation tasks. They acquire the human demonstrations using a VR headset and controllers, and develop a method utilizing the DFF to enable a robotic arm to perform the same task as the one in the demonstration, but in a totally different environment with new objects. Here, the semantic property of DFFs comes in handy, because often the user will demonstrate how to pick up a tall wine glass, and the robotic arm might be expected to pick up a short and wide coffee mug. These two cups don’t look particularly similar, but they have similar meanings, which lets F3RM generalize beyond visual appearances.

F3RM using DFFs for the task of robotic manipulation. Here it uses the DFF to pick up "Baymax" provided to it through a natural language query.
The next work, called LERF-TOGO, is similar to the first. It also aims to perform robotic manipulation tasks, but focuses on performing them safely, and unlike F3RM provides a text description of the desired task as opposed to a demonstration. Just like F3RM, this approach uses DFFs to understand where and what to grasp, but introduces an additional step to direct the robotic arm to grab the parts of the object that are meant to be grasped. For example, LERF-TOGO directs the robotic arm to pick up a frying pan or a knife by their handles, and not by the parts that might harm the robot.

LERF-TOGO using DFFs for the task of safe robotic manipulation. LERF-TOGO uses the DFF and a natural language query to grasp the rose from the stem and not the flower.
Additional Approaches
Since the success of DFFs, many works have tried to further improve performance, or remedy the weaknesses of existing approaches, some opting for entirely new strategies. There are many works in this field, but some stand out as particularly noteworthy.
One prominent work called Feature 3DGS by Zhou et al. considers working with Distilled Feature Fields, but achieves it through distilling the image features of DINO and other foundational models into a 3D Gaussian Splatting as opposed to a NeRF model. This approach has a number of benefits, but the most significant one is processing time. NeRF implicitly models the scene by using a Neural Network to be able to recover each voxel from the scene one at a time. In contrast, Gaussian Splatting provides an explicit model of the scene, and does so without needing to repeatedly sample from a Neural Network. As a result, this new approach is orders of magnitude faster, while still achieving comparable or better results.

Comparison between the RGB and Distilled Feature Fields of a scene reconstructed by NeRF and by 3D Gaussian Splatting. The RGB reconstructions look comparable to the human eye, but the 3D Gaussian Splatting Distilled Feature Field exhibits somewhat sharper contrast than the NeRF Distilled Feature Field
Another significant work called LangSplat by Qin et al. replaces LERF from the LERF-TOFO paper with a Gaussian Splatting equivalent. Just like before, replacing NeRF with Gaussian Splatting dramatically improves efficiency, and even mildly improves performance, all while retaining the Distilled Feature Field’s ability to be queried using natural language. A surprising byproduct of this switch is that LangSplat performs much better at semantic segmentation than its NeRF sibling.
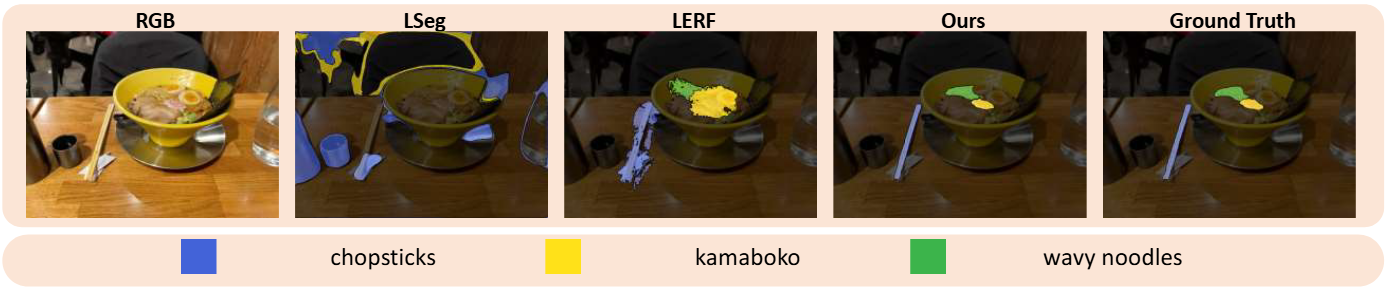
Comparison between LangSplat Distilled Feature Fields queried with natural language and LERF Distilled Feature Fields queried with the same natural language. LangSplat exhibits superior segmentation with far less noise than LERF. LangSplat looks far closer to the ground truth segmentation than it looks to its competition.
While these works show promise and address some of the weaknesses of NeRF, they also have weaknesses of their own. In general, 3DGS is far more memory intensive than NeRF, as often time scenes require the composition of hundreds of thousands or even millions of individual Gaussians. In that regard, Gaussian Splatting techniques essentially sacrifice memory usage over training and inference time. Secondly, Gaussian Splatting is entirely composed of individual Gaussian components, which can lead to a lack of smoothness when compared to NeRF. This is because NeRF directly learns a continuous volumetric radiance field, whereas the small gaps between the Gaussians of a 3DGS can become visible if you pay close attention.
Conclusion
In summary, we discussed a hypothetical Amazon warehouse robot and the capabilities it might need to perform its task. We delved into NeRF models that are excellent at learning the spatial structure of a scene, we talked about foundational models that extract powerful image features from 2D images, and explored Distilled Feature Fields that get the best of both worlds and create spatial-semantic representations of their scenes. In addition, we discussed some of the main benefits and drawbacks of these approaches. Lastly, we mentioned the modern-day applications of Distilled Feature Fields in robotics and elsewhere, and finally delved into future works that have since built atop DFFs. There is no doubt that strong vision models will play a huge role in the growth of the robotics field, and these methods represent some of the biggest strides forward researchers have made in the field to date.