Exploring EdgeGAN, Object Generation From Sketch
Latest GAN models like Dalle are already capable in generating high-resolution photorealistic images and imaginative scenes with different styles. However, rendering the model fully autonomous to generate a image might not always be the case. In real life, people often tend to only edit a part of the image. We realize that generating pure objects from sketch is helpful, such that it only generates what we want. In this project, we adapt and explore the model EdgeGAN[1].
Introduction
Partial image editing is by far a manual task. People depend on traditional tools like PhotoShop for a series of photo editing. Here we consider a simple case, what if we want to replace a horse in the photo with a sheep? Traditionally, people use lasso tool to outline the horse, remove it, crop the sheep from another image, place it to the right place, and spend a lot of time refining the conjunction. We realize that this task can be finished in a two-step manner by incorporating object generation from sketch and a inpainting model.
Our work focuses on the first step. Observing that EdgeGAN uses an image and its corresponding edge map for training, we claim that during inference time, manual sketch cannot achieve the same quality as edge map. Therefore, we first create a new training dataset by utilizing PhotoSketch[2], which transform the input image into a sketch-alike one. We then retrain the EdgeGAN model with the new dataset. As a result, we show that using both old and new datasets generates images of similar FID score. With human inspection, we found that the model trained with new dataset is more robust to sketch distortion while the model trained with old dataset generates images with better details. In order to exploit the strengths of both datasets, we also finetuned the pretrained model with our new dataset. We show that finetuned model surpasses the models trained from sketch and its performance is as competitive as the original one.
Besides experiments, we also present a jupyter notebook for interactive sketch drawing and image generation. In addition, we also work on a PyTorch implementation of EdgeGAN. However, after building the model, we cannot reproduce the result. We still list some of our thoughts and ideas in the last section. We extend this into a future work.
Related works
Sketch-Based Image Synthesis
Early sketch-based image synthesis approaches are based on image retrieval. Sketch2Photo [3] and PhotoSketcher [4] synthesize realistic images by compositing objects and backgrounds retrieved from a given sketch. These methods suffer from low preciseness and their results lack variation. After the publication of generative adversarial networks(GAN)[5], many works have adpated it for more diversified and precise sketch-based image generating tasks. Specifically, SketchyGAN[6] and ContextualGAN[7] have demonstrated the value of variant GANs for image generation from freehand sketches. Compared to the previous work, SketchyCOCO generates pure objects (without background), which is suitablt for our goal.
Sketch Datasets
There are only a few datasets of human-drawn sketches and they are generally small due to the effort needed to collect drawings. One of the most commonly used sketch dataset is the TU-Berlin dataset [8] which contains 20,000 human sketches spanning 250 categories. SketchyGAN[6] uses a newer dataset Sketchy, which spans 125 categories with a total of 75,471 sketches of 12,500 objects. However, all of the ground truth image in these dataset contains a lot of background information. Therefore, SketchyCOCO creates its own dataset. It use the segmentation information in COCO dataset [9] to extracts the pure object, and collect freehand sketch corresponding to each category.
Sketch vs Edge
For sketch-based image synthesis task, it is arguable that whether use sketch or edge map for training. Sketch is closer to natural freehand drawings that are used for inference while edge map can perserve more details. SketchyGAN [6] uses edge map at first and gradually add more sketch samples during training. It aims to help the model capture features first and then to be more robust. In the contrast, EdgeGAN[1] only uses edge map for training.
EdgeGAN Review
As shown in Fig.1, EdgeGAN has two channels: one including generator GE and discriminator DE for edge map generation, the other including generator GI and discriminator DI for image generation. Both GI and GE take the same noise vector together with an one-hot vector indicting a specific category as input. Discriminators DI and DE attempt to distinguish the generated images or edge maps from real distribution. Another discriminator DJ is used to encourage the generated fake image and the edge map depicting the same object by telling if the generated fake image matches the fake edge map, which takes the outputs of both GI and GE as input (the image and edge map are concatenated along the width dimension). The Edge Encoder is used to encourage the encoded attribute information of edge maps to be close to the noise vector fed to GI and GE through a L1 loss. The classifier is used to infer the category label of the output of GI , which is used to encourage the generated fake image to be recognized as the desired category via a focal loss.
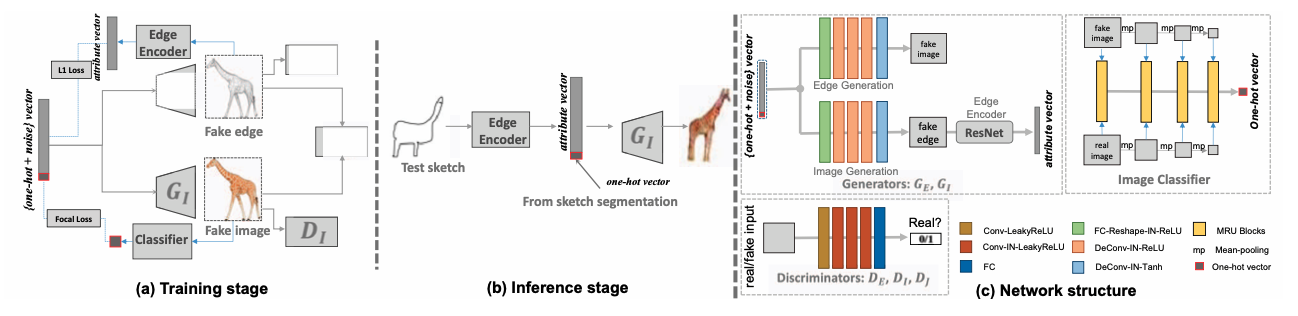
Approach
Dataset
As discussed in the previous section, using edge map or sketch for training has its own benefits. Fig.2 shows the data samples used in [6] (left) and [1] (right). We can see that SketchyGAN’s training set consists of crowd worker’s drawings, which are in poor quality. Using this dataset raise the difficulties during training. On the other hand, EdgeGAN’s training set uses purely edge map. The edge maps are too detailed, which even include the textual of fur. However, during inference time, it is impossible for human beings to draw a sketch like that.

Having observed these misalignments, we create our own dataset that uses more reasonable sketches for training. We are inspired by Sketch Your Own GAN [10], which uses PhotoSketch [2] to generate sketches that are more conformed to edge map. The original training set of [1] consists of 14 categories and around 30k data samples. Considering the training time, we only focus on 5 categories of them (dog, cat, zebra, giraffe, sheep) and transform them using PhotoSketch. The total number of training samples are 10272. Each sample is 3*64*128. Fig.3 demonstrates some examples of our dataset. As we can see, our data samples remove or abstract away textual informations. However, as we can see, it also removes most of the stripes of zebra. We will discuss more with this later.

Experiments
PyTorch Reimplementation
We spent the majority of time using PyTorch to reimplement the network. Our motivation is that many of the research nowadays use PyTorch instead of TensorFlow. Writing EdgeGAN with PyTorch helps deploy EdgeGAN with other models (the inpainting model as we initially consider) under same environment, which can be pipelined to complete the whole object replacing work. Then we could finetune the pipeline to achieve better results for the generation task.
Our code of PyTorch implementation can be found on https://github.com/WaichungLing/EdgeGAN_Pytorch.
Training
We trained the EdgeGAN model with our new training dataset. We trained three models with 100 epochs and a batch size of 64. Each model only differs in the learning rates, which are 1e-3, 2e-4(default), and 1e-5. We first manually inspected the results. We found that the 1e-5 model only generates vague outlines because of the small learning rate failed to drive the model to optimal. Therefore, we will drop this model from the following discussion. We also finetuned the pretrained model on our new dataset for 20 epochs with learning rate 1e-5.
FID Comparison
The Frechet Inception Distance score, or FID for short, is a metric that calculates the distance between feature vectors calculated for real and generated images [11]. The score summarizes how similar the two groups are in terms of statistics on computer vision features of the raw images calculated using the inception v3 model used for image classification. Lower scores indicate the two groups of images are more similar, or have more similar statistics, with a perfect score being 0.0 indicating that the two groups of images are identical.
We adapted FID as a metric to quantify the quality of synthesized images. We compared the output of each model with the ground truth images using the pytorch_fid tool.
Running The Project
When we were deploying the model, we found that there are many legacy codes and some intrinsic bugs. We raised an issue on GitHub for training customized dataset. We hope this help people facing the same issue. We also observe that EdgeGAN is written in TensorFlow 1.x and it depends on many obselete packages such as scipy.misc. We updated the code to be compatible with TensorFlow 2.x that supports the latest CUDA driver and replace scipy.misc with imageio. We also included several Python files to generate new dataset and a Jupyter notebook for interactive drawing. Our code can be found on https://github.com/WaichungLing/EdgeGAN_TF2
Interactive Notebook
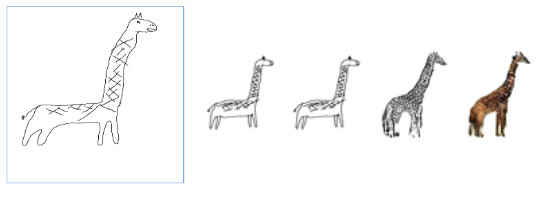
EdgeGAN can be designed to be interactive, accepting user’s drawing and generating the synthesized image. Running the Python file directly requires the user to somehow draw the sketch and save in the corresponding folder. The drawing part is especially inconvenient. Traditional drawing interface like OpenCV opens a new window therefore the user cannot finish the process of interaction with only one setup. We built a notebook with ipycanvas package, which allows user to sketch directly on a notebook cell. We then run the test model directly on the notebook to generate output. Fig.6 shows one of our sketch and the corresponding output.
Result
PyTorch Model Result
After finishing rewriting the model in PyTorch, we found there are misaligned behaviors in the training loss and our model fails to converge, although the architecture of the PyTorch model is perfectly identical to that of the original TensorFlow one,. Due to the time constraint, we are not able to debug and tune the whole PyTorch model. Here we list some of the challenges during reimplementation:
- Many code blocks of EdgeGAN are handwritten, after replacing it with PyTorch models, the bebavior is different.
- EdgeGAN uses complicated weight initialization and the activation different from case by case. We replace them by Xavier initialization and Prelu, which might lead to different result.
- EdgeGAN has many intrinsic bugs, such as misalignments in API calls lead to use default arguments. We are not able to debug all of these misuses.
- EdgeGAN uses gradient regularization, which we find is too strong. We replace it with L2-regularization but this needs parameter tuning.
TensorFlow Model Result Visualization
Below we report several successful and failure cases for the model in TensorFlow version. We consider an output to be successful if the output has correct position for each component (e.g. head and legs), the texture is correctly recovered (e.g. stripes of zebra), and the body ratio is maintained.
Successful cases
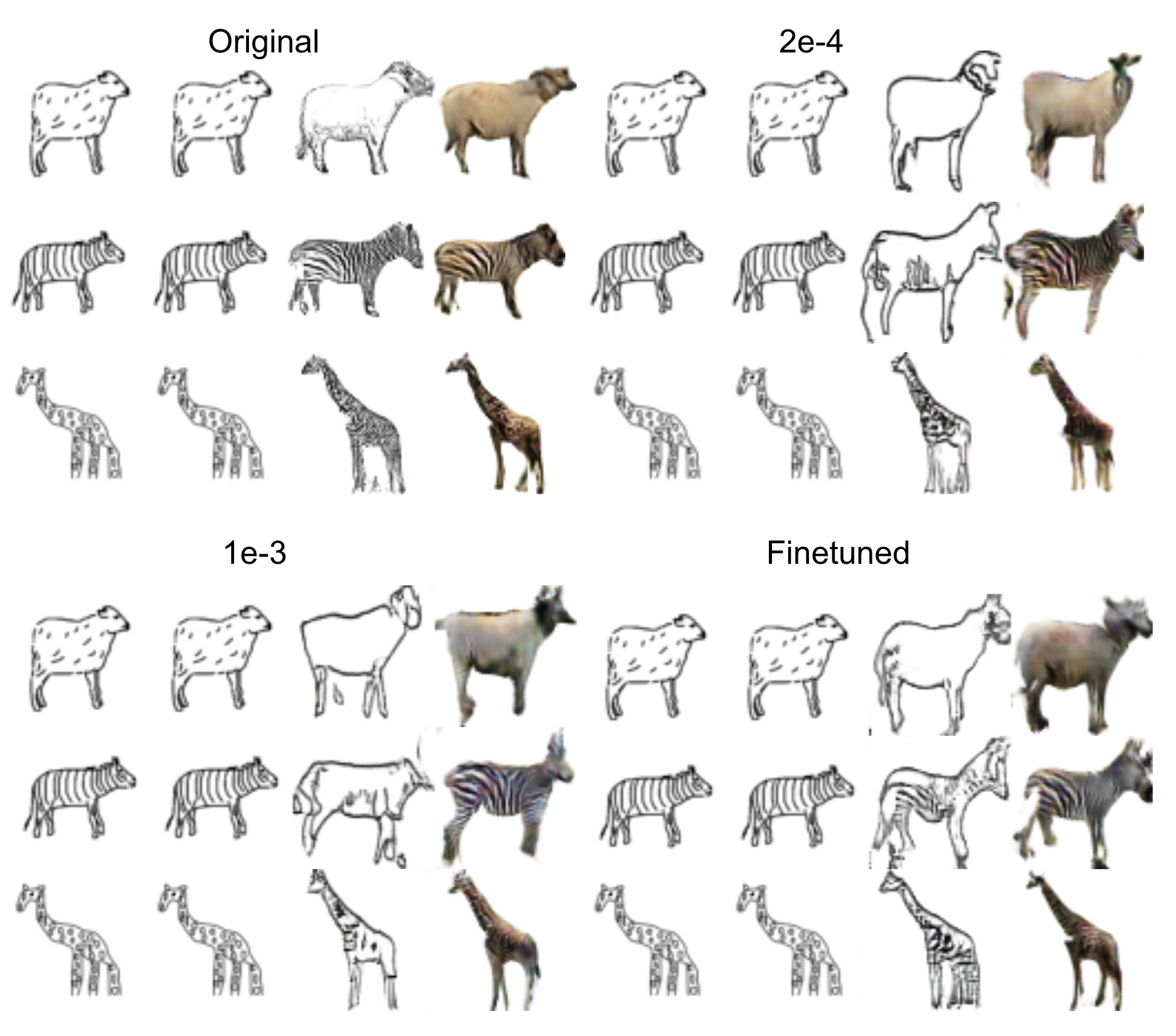
Training from sketch with new data vs the original one
Judging from the synthesized images of zebra, we can see that the original model’s generation is siginificantly affected by the incorrect body ratio of the sketch. This is because the original model was trained on edge maps which do not have as many variations as the sketch. The outputs of both 1e-3 and 2e-4 tend to retain the correct body ratio better. Although the synthesized images look decent, the corresponding edge map pinpoints some drawbacks of using our new data. Since our new data replace the edge maps with sketches, some details and textual information are dropped. This leads to that both 1e-3 and 2e-4 did a poor job in synthesizing the complicated parts like head. We can also observe several incomplete and artifact parts in the model using new dataset. We suspect that this is because the sketches in the training samples are fragmentary and thus misguide the model. We will discuss more on the dataset quality in the Discussion section.
Training from sketch with new data vs finetuned
We finetuned the pretrained model with our new dataset. From the edge map, we can see that finetuning keeps the detailed information. Therefore, compared to training from sketch, finetuned version better generate more detailed heads. On the contrary, affected by the quality of our sketch, finetuned model tends to generate more incomplete patches.
Failure cases
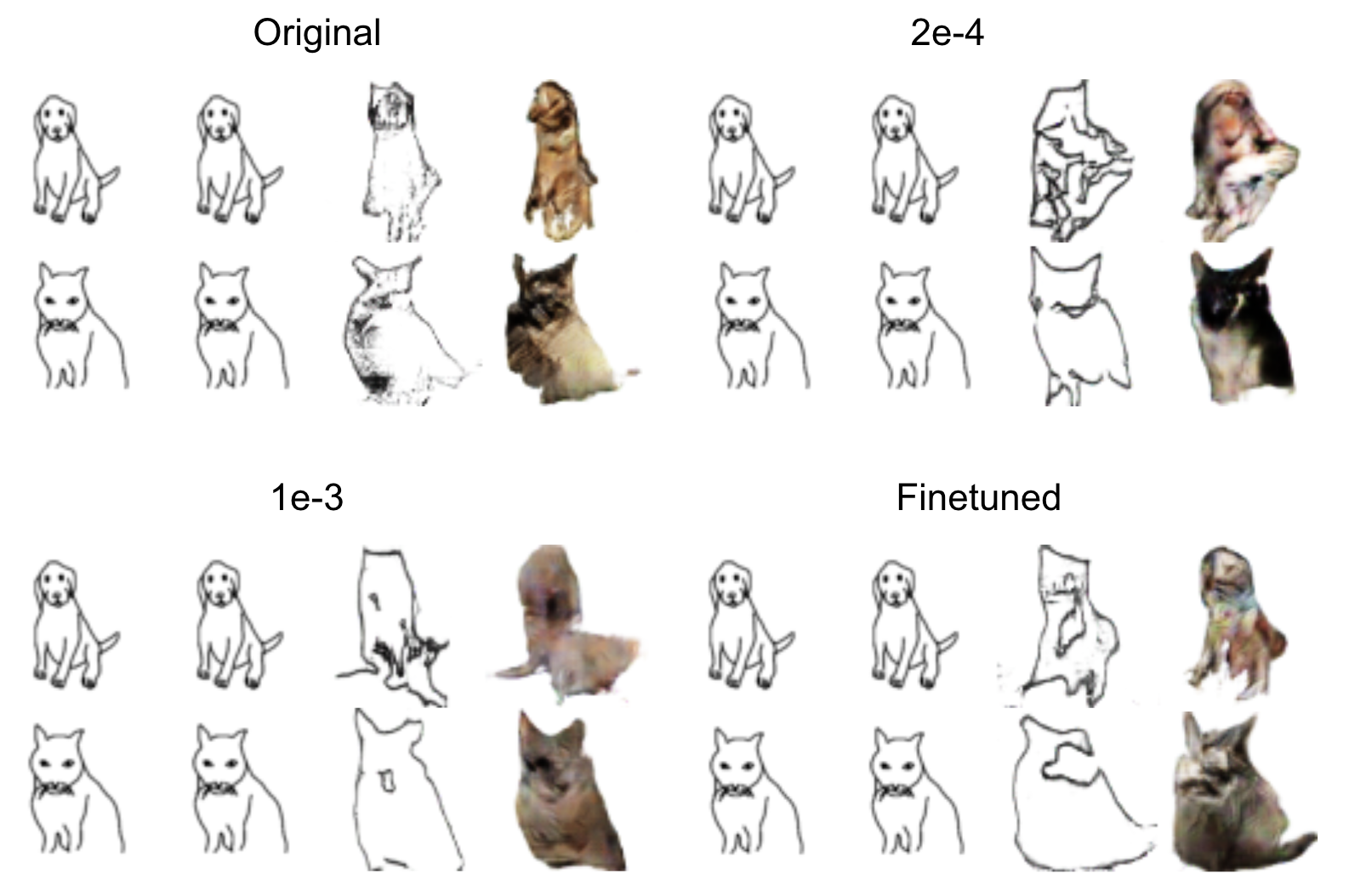
All four models did a poor job in synthesizing cats and dogs. There are two major reasons for this. First is cats’ and dogs’ generation requires more detailed information, making it a more difficult task. Second, the ground truth images of cats and dogs are already very poor. The cats and dogs images are much more diverse. Many of them are of weird orientations and poses, making the models fail to learn representative features.
FID scores

Table.1 shows the FID scores of four models. If we train with our new dataset from sketch, the best model 2e-4 is slightly larger than the original one. If we finetune the pretrained model, our new dataset can perform nearly as good as the original one. Although training with our new dataset does not surpass the original result, we have shown that training with sketch is not significantly worse than using edge map. It’s noticeble that the ground truth images we used are in poor quality. It may amplify the weakness of using sketches (incomplete or even lack of details). We expect that sketches can perform better with cleaner datasets, which we believe also enhance the quality of the final outputs.
Discussion
Dataset Quality
The ground truth images of both our new dataset and the one EdgeGAN used are from segmenting the COCO dataset. Fig.9 shows that some of the ground truth images are in poor quality. It might be distorted, incomplete, or vague in details. Therefore, we could not generate reasonable sketch from these samples. In the previous section, we discussed all of the models did a poor job in dogs and cats generation. After inspecting, we realized that the ground truth image of cats and dogs are relatively worse. For example, most of the cat images are black cats, whose details are barely distinguishable. We recognized that this is the first obstacle to train a high-quality EdgeGAN.

Generation diversity
When exploring the outputs of all models, we found that many different sketches end up with nearly identical image generations (See Fig.10). We suspect that the GAN model may be merely remembering some examples for each category and each orientation. Currently, the inputs and outputs are only in 64*64 resolution, at which we cannot see the detailed difference from images to images. We think it’s worthwhile to train the model in higher resolution and justify if the model generation is various enough.

PyTorch Reimplementation Takeaways
The key takeaways are that:
- Small inconsistency in sub-modules between PyTorch and TensorFlow can cause the model to produce completely different results.
- It is very difficult to replicate deep neural networks. Even though the same architecture can be reproduced, unrevealed hyper-parameters of the original model may cause the replication result to be different.
Conclusion
In this project, we tried to improve the performance of EdgeGAN. We reimplemented EdgeGAN in Pytorch version, although the training outcome of the Pytorch model was unsatisfactory due to inconsistency between Pytorch and TensorFlow. We generated our new sketch dataset using PhotoSketch to make our model generalize better. We trained our model with various learning rates and finetuned it. It turned out the finetuned model achieved slightly lower performance (evaluated in FID) tested on the test dataset than the original model, but we are expecting the finetuned model can potentially generalize better in the real world. We built the interface for EdgeGAN which can take users’ drawing as input and generate the corresponding object. In the future work, we will figure out the Pytorch version of EdgeGAN and pipeline it with impainting model to create a smoother flow of object generation from sketch.
Reference
[1] Gao, Chengying, et al. “Sketchycoco: Image generation from freehand scene sketches.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
[2] Li, Mengtian, et al. “Photo-sketching: Inferring contour drawings from images.” 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2019.
[3] Tao Chen, Ming-Ming Cheng, Ping Tan, Ariel Shamir, and Shi-Min Hu. Sketch2photo: Internet image montage. ACM transactions on graphics (TOG), 28(5):1–10, 2009.
[4] Mathias Eitz, Ronald Richter, Kristian Hildebrand, Tamy Boubekeur, and Marc Alexa. Photosketcher: interactive sketch-based image synthesis. IEEE Computer Graphics and Applications, 31(6):56–66, 2011.
[5] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
[6] Wengling Chen and James Hays. Sketchygan: Towards di- verse and realistic sketch to image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9416–9425, 2018.
[7] Yongyi Lu, Shangzhe Wu, Yu-Wing Tai, and Chi-Keung Tang. Image generation from sketch constraint using con- textual gan. In Proceedings of the European Conference on Computer Vision, pages 205–220, 2018.
[8] M. Eitz, J. Hays, and M. Alexa. How do humans sketch objects? ACM Transactions on Graphics (proceedings of SIGGRAPH), 31(4):44:1–44:10, 2012.
[9] Lin, Tsung-Yi, et al. “Microsoft coco: Common objects in context.” European conference on computer vision. Springer, Cham, 2014.
[10] Wang, Sheng-Yu, David Bau, and Jun-Yan Zhu. “Sketch your own gan.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[11] Yu, Yu, Weibin Zhang, and Yun Deng. “Frechet Inception Distance (FID) for Evaluating GANs.”
—